 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Supervised learning on heterogeneous, attributed entities interacting over time
Jul 22, 2020
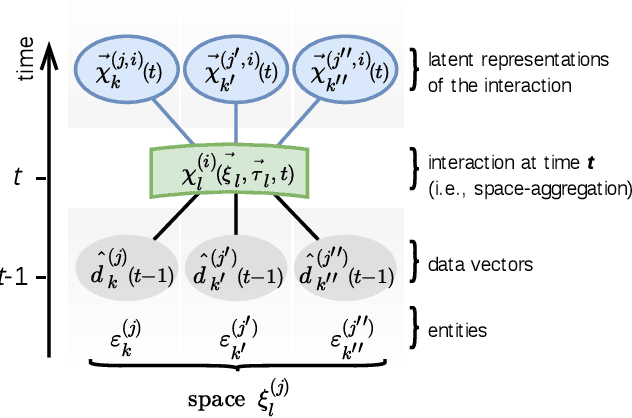
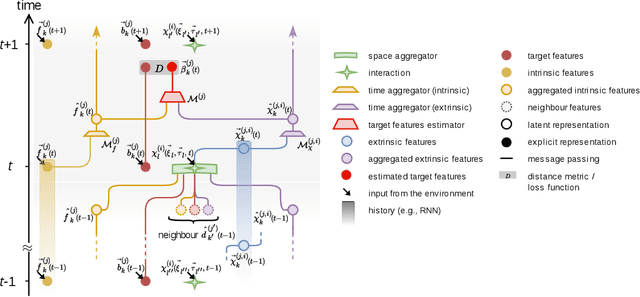
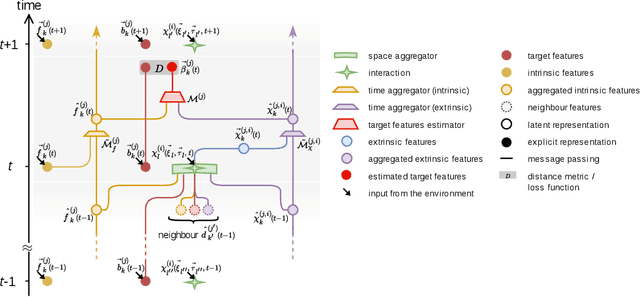

Most physical or social phenomena can be represented by ontologies where the constituent entities are interacting in various ways with each other and with their environment. Furthermore, those entities are likely heterogeneous and attributed with features that evolve dynamically in time as a response to their successive interactions. In order to apply machine learning on such entities, e.g., for classification purposes, one therefore needs to integrate the interactions into the feature engineering in a systematic way. This proposal shows how, to this end, the current state of graph machine learning remains inadequate and needs to be be augmented with a comprehensive feature engineering paradigm in space and time.
DNN Training Acceleration via Exploring GPGPU Friendly Sparsity
Mar 11, 2022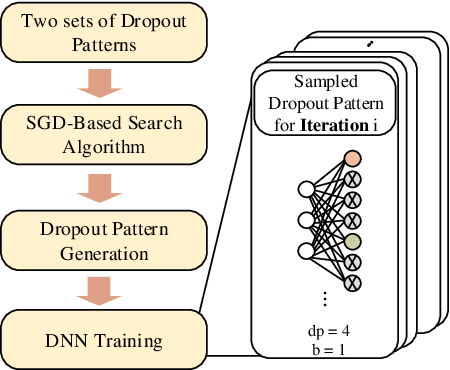
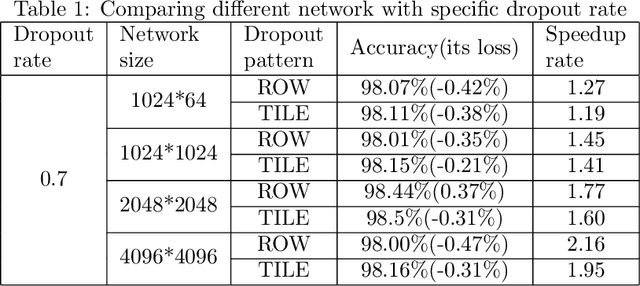
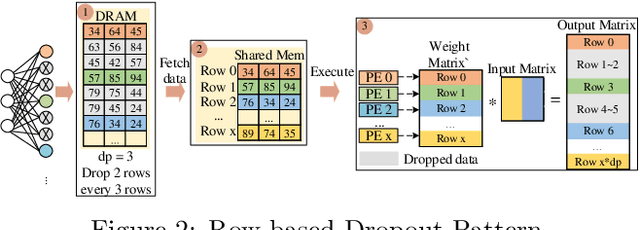
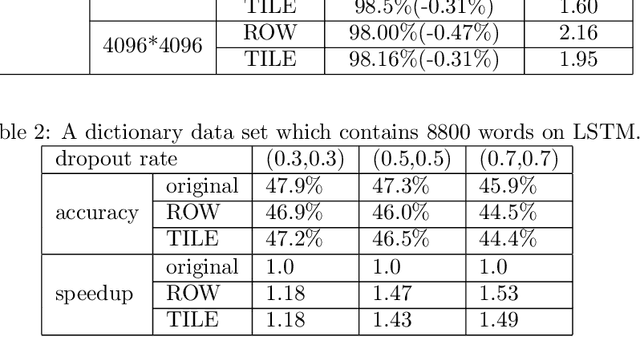
The training phases of Deep neural network~(DNN) consumes enormous processing time and energy. Compression techniques utilizing the sparsity of DNNs can effectively accelerate the inference phase of DNNs. However, it is hardly used in the training phase because the training phase involves dense matrix-multiplication using General-Purpose Computation on Graphics Processors (GPGPU), which endorse the regular and structural data layout. In this paper, we first propose the Approximate Random Dropout that replaces the conventional random dropout of neurons and synapses with a regular and online generated row-based or tile-based dropout patterns to eliminate the unnecessary computation and data access for the multilayer perceptron~(MLP) and long short-term memory~(LSTM). We then develop a SGD-based Search Algorithm that produces the distribution of row-based or tile-based dropout patterns to compensate for the potential accuracy loss. Moreover, aiming at the convolution neural network~(CNN) training acceleration, we first explore the importance and sensitivity of input feature maps; and then propose the sensitivity-aware dropout method to dynamically drop the input feature maps based on their sensitivity so as to achieve greater forward and backward training acceleration while reserving better NN accuracy. To facilitate DNN programming, we build a DNN training computation framework that unifies the proposed techniques in the software stack. As a result, the GPGPU only needs to support the basic operator -- matrix multiplication and can achieve significant performance improvement regardless of DNN model.
Ensemble plasticity and network adaptability in SNNs
Mar 11, 2022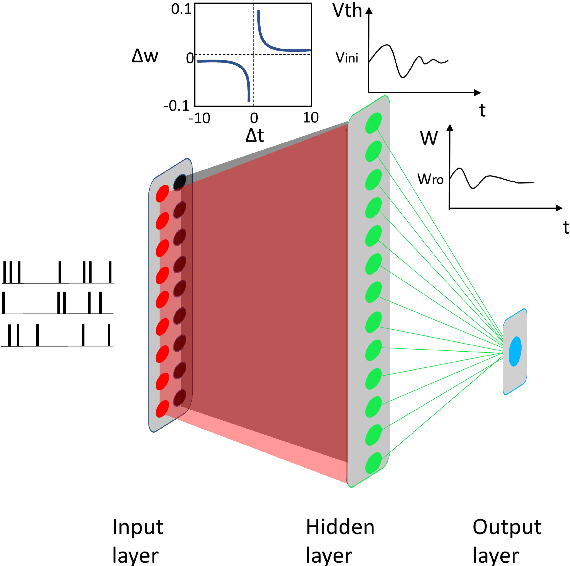
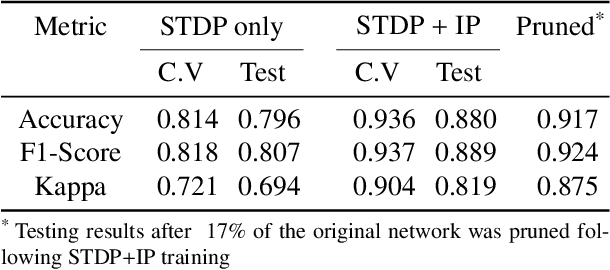
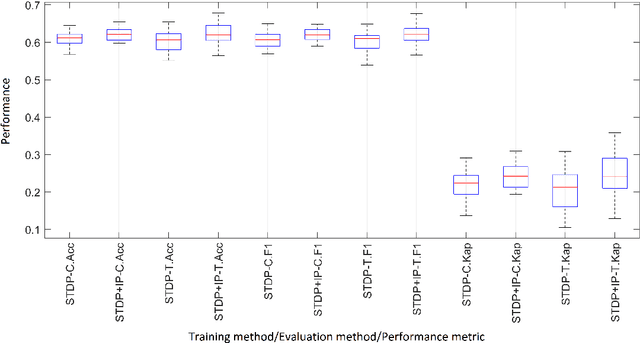
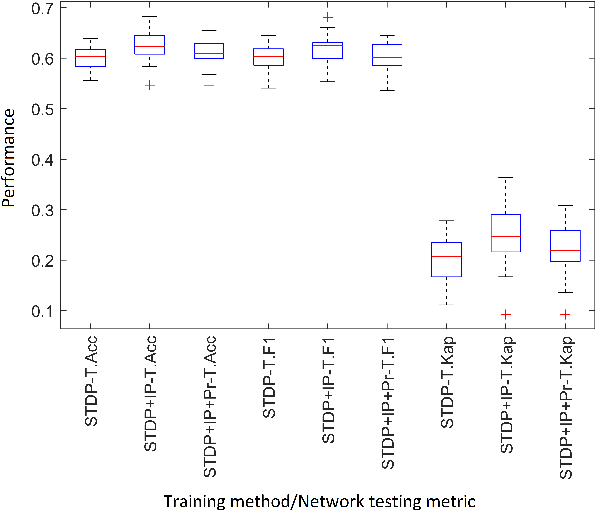
Artificial Spiking Neural Networks (ASNNs) promise greater information processing efficiency because of discrete event-based (i.e., spike) computation. Several Machine Learning (ML) applications use biologically inspired plasticity mechanisms as unsupervised learning techniques to increase the robustness of ASNNs while preserving efficiency. Spike Time Dependent Plasticity (STDP) and Intrinsic Plasticity (IP) (i.e., dynamic spiking threshold adaptation) are two such mechanisms that have been combined to form an ensemble learning method. However, it is not clear how this ensemble learning should be regulated based on spiking activity. Moreover, previous studies have attempted threshold based synaptic pruning following STDP, to increase inference efficiency at the cost of performance in ASNNs. However, this type of structural adaptation, that employs individual weight mechanisms, does not consider spiking activity for pruning which is a better representation of input stimuli. We envisaged that plasticity-based spike-regulation and spike-based pruning will result in ASSNs that perform better in low resource situations. In this paper, a novel ensemble learning method based on entropy and network activation is introduced, which is amalgamated with a spike-rate neuron pruning technique, operated exclusively using spiking activity. Two electroencephalography (EEG) datasets are used as the input for classification experiments with a three-layer feed forward ASNN trained using one-pass learning. During the learning process, we observed neurons assembling into a hierarchy of clusters based on spiking rate. It was discovered that pruning lower spike-rate neuron clusters resulted in increased generalization or a predictable decline in performance.
Evolving Constructions for Balanced, Highly Nonlinear Boolean Functions
Feb 17, 2022
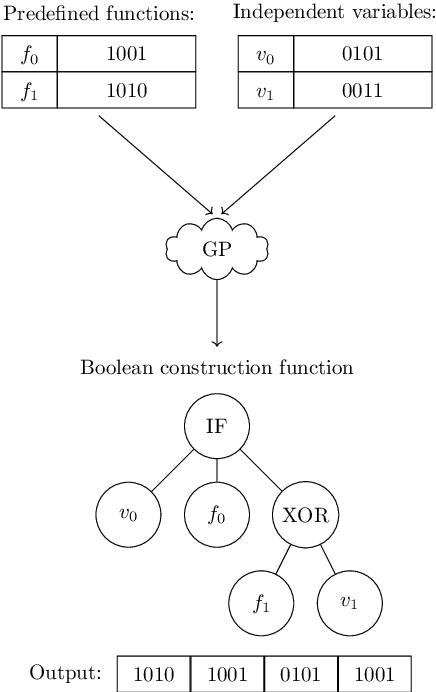
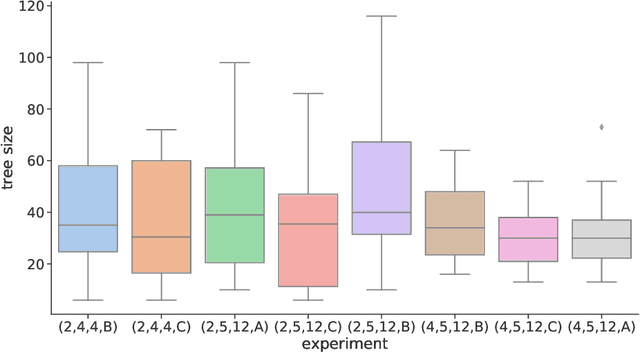

Finding balanced, highly nonlinear Boolean functions is a difficult problem where it is not known what nonlinearity values are possible to be reached in general. At the same time, evolutionary computation is successfully used to evolve specific Boolean function instances, but the approach cannot easily scale for larger Boolean function sizes. Indeed, while evolving smaller Boolean functions is almost trivial, larger sizes become increasingly difficult, and evolutionary algorithms perform suboptimally. In this work, we ask whether genetic programming (GP) can evolve constructions resulting in balanced Boolean functions with high nonlinearity. This question is especially interesting as there are only a few known such constructions. Our results show that GP can find constructions that generalize well, i.e., result in the required functions for multiple tested sizes. Further, we show that GP evolves many equivalent constructions under different syntactic representations. Interestingly, the simplest solution found by GP is a particular case of the well-known indirect sum construction.
Benchmark Assessment for DeepSpeed Optimization Library
Feb 12, 2022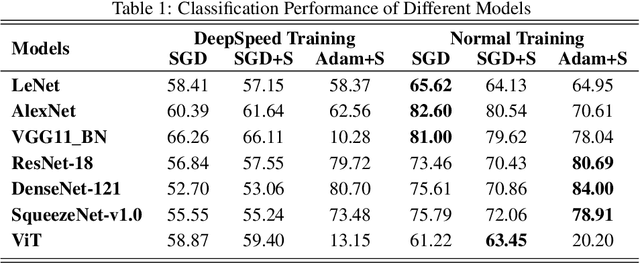
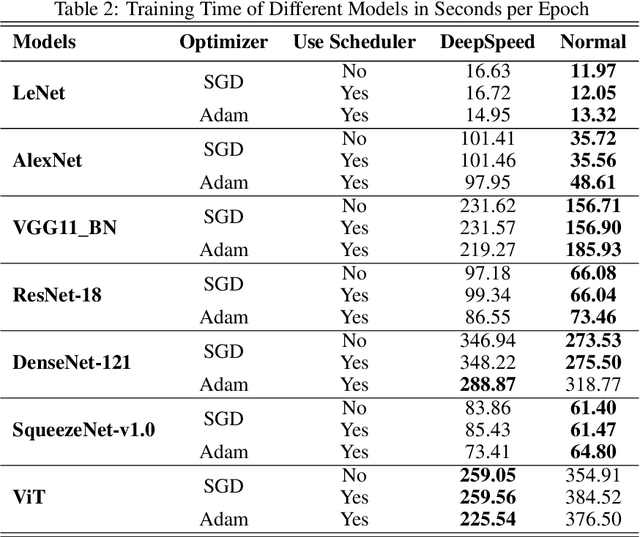
Deep Learning (DL) models are widely used in machine learning due to their performance and ability to deal with large datasets while producing high accuracy and performance metrics. The size of such datasets and the complexity of DL models cause such models to be complex, consuming large amount of resources and time to train. Many recent libraries and applications are introduced to deal with DL complexity and efficiency issues. In this paper, we evaluated one example, Microsoft DeepSpeed library through classification tasks. DeepSpeed public sources reported classification performance metrics on the LeNet architecture. We extended this through evaluating the library on several modern neural network architectures, including convolutional neural networks (CNNs) and Vision Transformer (ViT). Results indicated that DeepSpeed, while can make improvements in some of those cases, it has no or negative impact on others.
GenderedNews: Une approche computationnelle des écarts de représentation des genres dans la presse française
Mar 07, 2022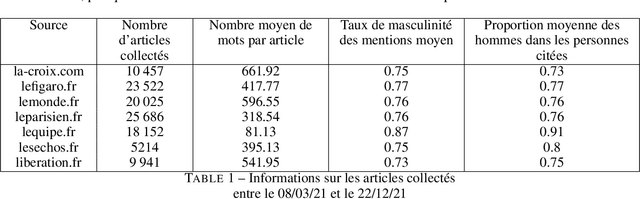
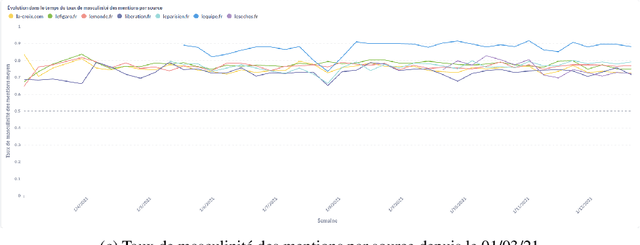
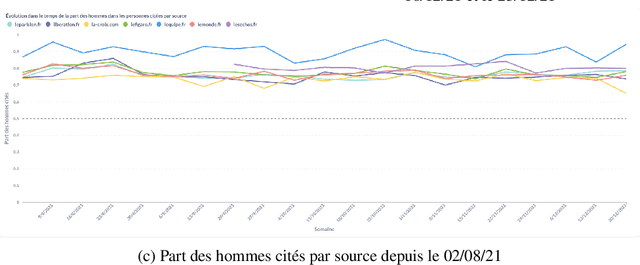
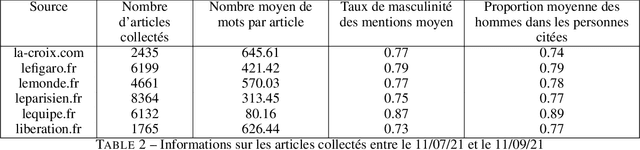
In this article, we present {\it GenderedNews} (\url{https://gendered-news.imag.fr}), an online dashboard which gives weekly measures of gender imbalance in French online press. We use Natural Language Processing (NLP) methods to quantify gender inequalities in the media, in the wake of global projects like the Global Media Monitoring Project. Such projects are instrumental in highlighting gender imbalance in the media and its very slow evolution. However, their generalisation is limited by their sampling and cost in terms of time, data and staff. Automation allows us to offer complementary measures to quantify inequalities in gender representation. We understand representation as the presence and distribution of men and women mentioned and quoted in the news -- as opposed to representation as stereotypification. In this paper, we first review different means adopted by previous studies on gender inequality in the media : qualitative content analysis, quantitative content analysis and computational methods. We then detail the methods adopted by {\it GenderedNews} and the two metrics implemented: the masculinity rate of mentions and the proportion of men quoted in online news. We describe the data collected daily (seven main titles of French online news media) and the methodology behind our metrics, as well as a few visualisations. We finally propose to illustrate possible analysis of our data by conducting an in-depth observation of a sample of two months of our database.
The Semantic Adjacency Criterion in Time Intervals Mining
Jan 11, 2021
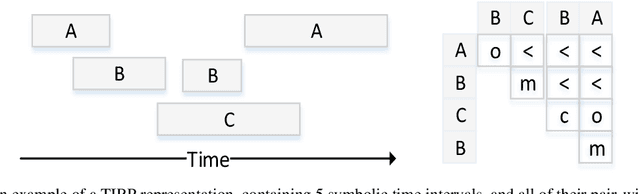
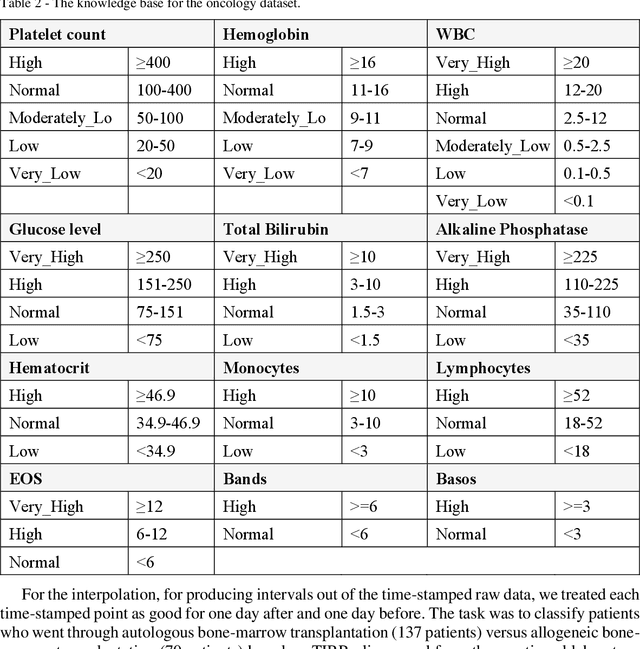
Frequent temporal patterns discovered in time-interval-based multivariate data, although syntactically correct, might be non-transparent: For some pattern instances, there might exist intervals for the same entity that contradict the pattern's usual meaning. We conjecture that non-transparent patterns are also less useful as classification or prediction features. We propose a new pruning constraint during a frequent temporal-pattern discovery process, the Semantic Adjacency Criterion [SAC], which exploits domain knowledge to filter out patterns that contain potentially semantically contradictory components. We have defined three SAC versions, and tested their effect in three medical domains. We embedded these criteria in a frequent-temporal-pattern discovery framework. Previously, we had informally presented the SAC principle and showed that using it to prune patterns enhances the repeatability of their discovery in the same clinical domain. Here, we define formally the semantics of three SAC variations, and compare the use of the set of pruned patterns to the use of the complete set of discovered patterns, as features for classification and prediction tasks in three different medical domains. We induced four classifiers for each task, using four machine-learning methods: Random Forests, Naive Bayes, SVM, and Logistic Regression. The features were frequent temporal patterns discovered in each data set. SAC-based temporal pattern-discovery reduced by up to 97% the number of discovered patterns and by up to 98% the discovery runtime. But the classification and prediction performance of the reduced SAC-based pattern-based features set, was as good as when using the complete set. Using SAC can significantly reduce the number of discovered frequent interval-based temporal patterns, and the corresponding computational effort, without losing classification or prediction performance.
Deep Distributional Time Series Models and the Probabilistic Forecasting of Intraday Electricity Prices
Oct 05, 2020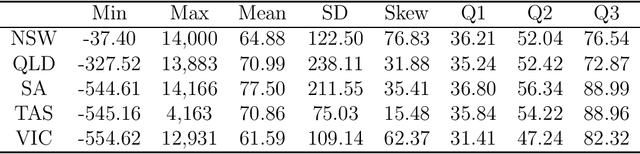
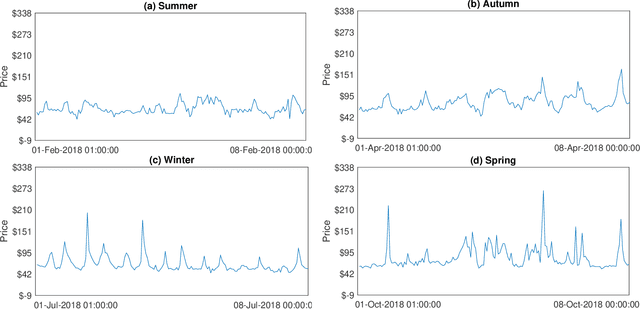
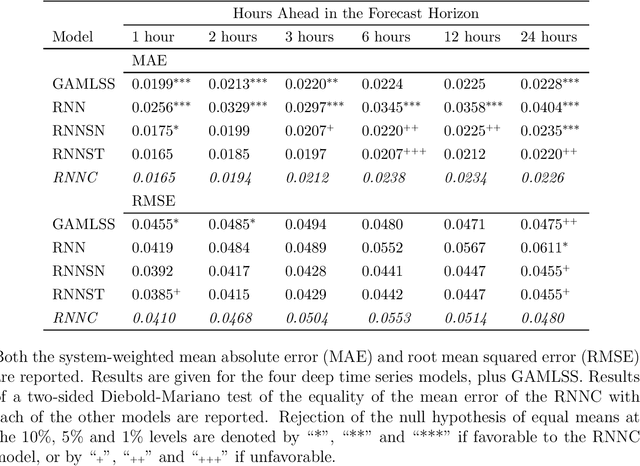
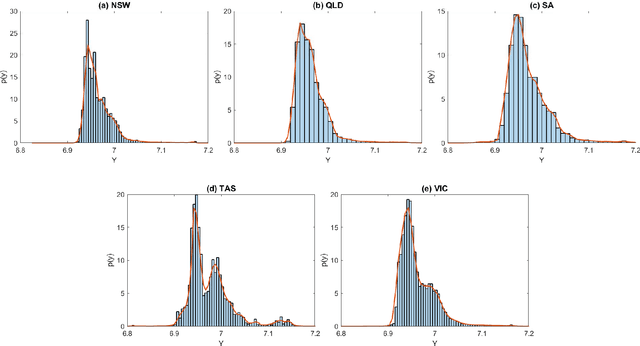
Recurrent neural networks (RNNs) with rich feature vectors of past values can provide accurate point forecasts for series that exhibit complex serial dependence. We propose two approaches to constructing deep time series probabilistic models based on a variant of RNN called an echo state network (ESN). The first is where the output layer of the ESN has stochastic disturbances and a shrinkage prior for additional regularization. The second approach employs the implicit copula of an ESN with Gaussian disturbances, which is a deep copula process on the feature space. Combining this copula with a non-parametrically estimated marginal distribution produces a deep distributional time series model. The resulting probabilistic forecasts are deep functions of the feature vector and also marginally calibrated. In both approaches, Bayesian Markov chain Monte Carlo methods are used to estimate the models and compute forecasts. The proposed deep time series models are suitable for the complex task of forecasting intraday electricity prices. Using data from the Australian National Electricity Market, we show that our models provide accurate probabilistic price forecasts. Moreover, the models provide a flexible framework for incorporating probabilistic forecasts of electricity demand as additional features. We demonstrate that doing so in the deep distributional time series model in particular, increases price forecast accuracy substantially.
Towards hardware Implementation of WTA for CPG-based control of a Spiking Robotic Arm
Feb 14, 2022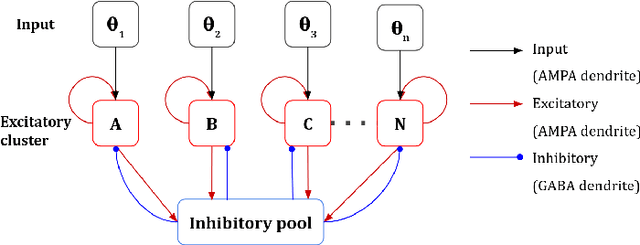
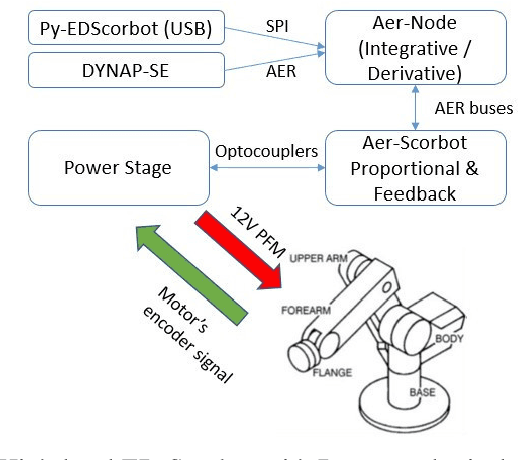
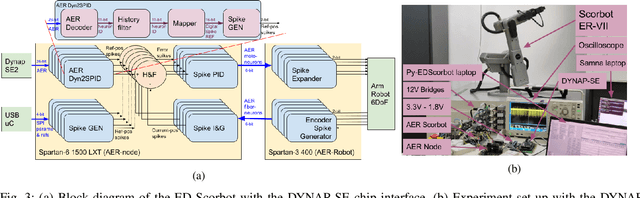
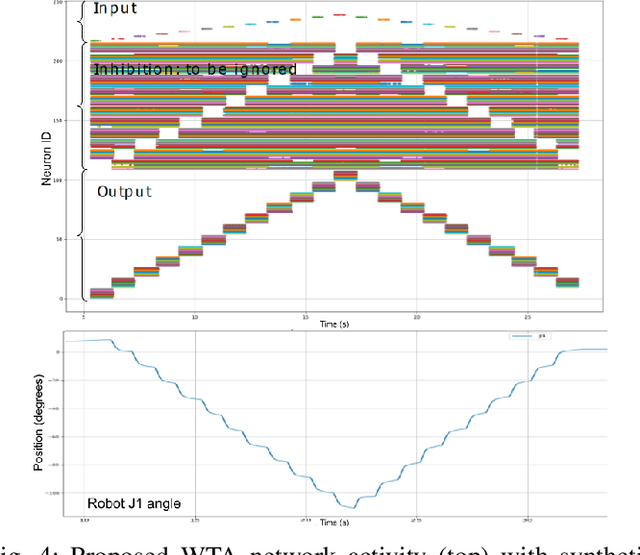
Biological nervous systems typically perform the control of numerous degrees of freedom for example in animal limbs. Neuromorphic engineers study these systems by emulating them in hardware for a deeper understanding and its possible application to solve complex problems in engineering and robotics. Central-Pattern-Generators (CPGs) are part of neuro-controllers, typically used at their last steps to produce rhythmic patterns for limbs movement. Different patterns and gaits typically compete through winner-take-all (WTA) circuits to produce the right movements. In this work we present a WTA circuit implemented in a Spiking-Neural-Network (SNN) processor to produce such patterns for controlling a robotic arm in real-time. The robot uses spike-based proportional-integrativederivative (SPID) controllers to keep a commanded joint position from the winner population of neurons of the WTA circuit. Experiments demonstrate the feasibility of robotic control with spiking circuits following brain-inspiration.
Topological EEG Nonlinear Dynamics Analysis for Emotion Recognition
Mar 14, 2022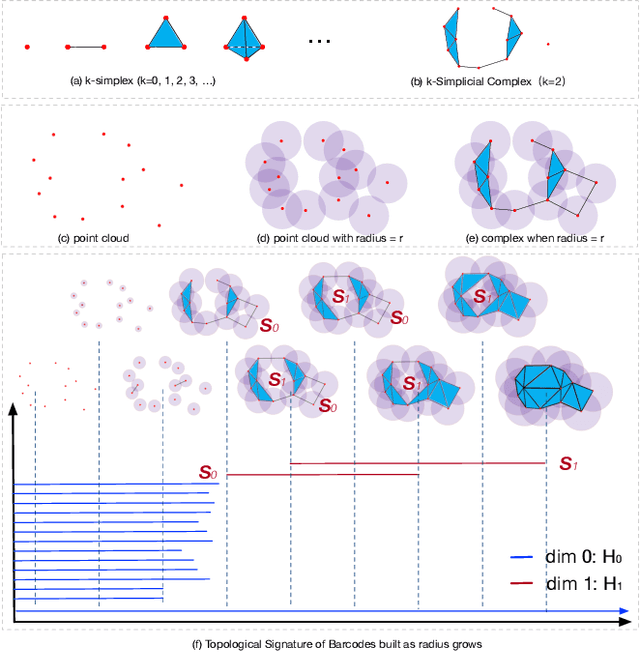
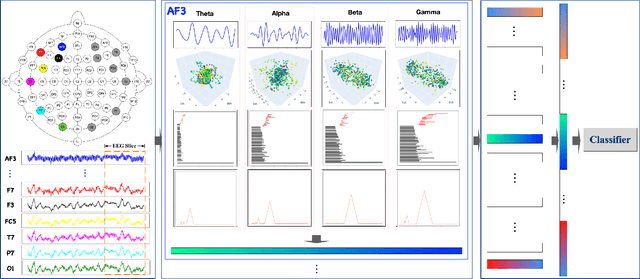
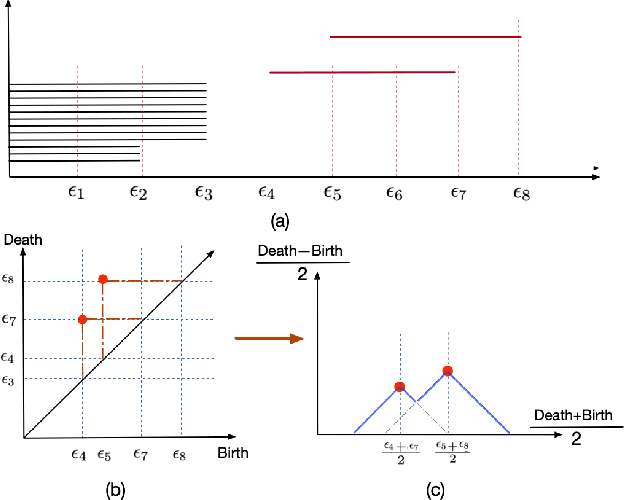
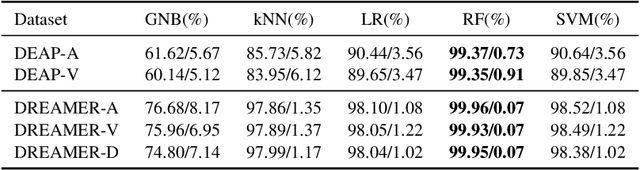
Emotional recognition through exploring the electroencephalography (EEG) characteristics has been widely performed in recent studies. Nonlinear analysis and feature extraction methods for understanding the complex dynamical phenomena are associated with the EEG patterns of different emotions. The phase space reconstruction is a typical nonlinear technique to reveal the dynamics of the brain neural system. Recently, the topological data analysis (TDA) scheme has been used to explore the properties of space, which provides a powerful tool to think over the phase space. In this work, we proposed a topological EEG nonlinear dynamics analysis approach using the phase space reconstruction (PSR) technique to convert EEG time series into phase space, and the persistent homology tool explores the topological properties of the phase space. We perform the topological analysis of EEG signals in different rhythm bands to build emotion feature vectors, which shows high distinguishing ability. We evaluate the approach with two well-known benchmark datasets, the DEAP and DREAMER datasets. The recognition results achieved accuracies of 99.37% and 99.35% in arousal and valence classification tasks with DEAP, and 99.96%, 99.93%, and 99.95% in arousal, valence, and dominance classifications tasks with DREAMER, respectively. The performances are supposed to be outperformed current state-of-art approaches in DREAMER (improved by 1% to 10% depends on temporal length), while comparable to other related works evaluated in DEAP. The proposed work is the first investigation in the emotion recognition oriented EEG topological feature analysis, which brought a novel insight into the brain neural system nonlinear dynamics analysis and feature extraction.