 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Night-time Semantic Segmentation with a Large Real Dataset
Mar 15, 2020
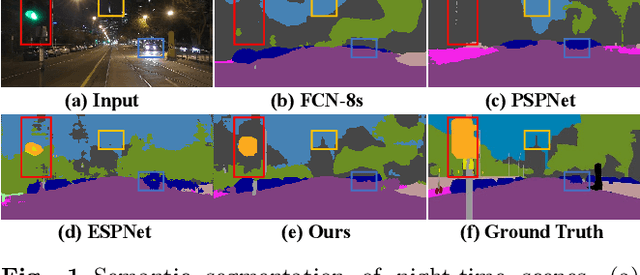
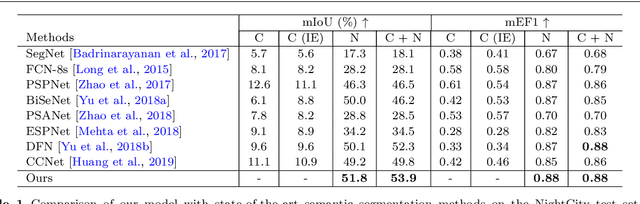
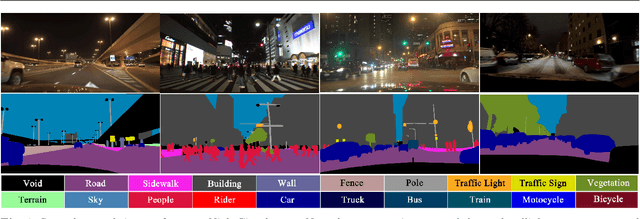
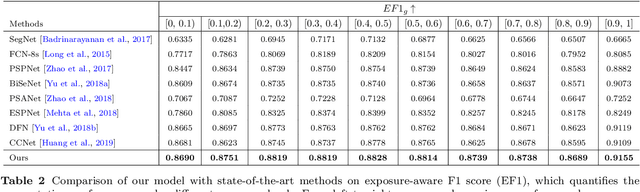
Although huge progress has been made on semantic segmentation in recent years, most existing works assume that the input images are captured in day-time with good lighting conditions. In this work, we aim to address the semantic segmentation problem of night-time scenes, which has two main challenges: 1) labeled night-time data are scarce, and 2) over- and under-exposures may co-occur in the input night-time images and are not explicitly modeled in existing semantic segmentation pipelines. To tackle the scarcity of night-time data, we collect a novel labeled dataset (named NightCity) of 4,297 real night-time images with ground truth pixel-level semantic annotations. To our knowledge, NightCity is the largest dataset for night-time semantic segmentation. In addition, we also propose an exposure-aware framework to address the night-time segmentation problem through augmenting the segmentation process with explicitly learned exposure features. Extensive experiments show that training on NightCity can significantly improve the performance of night-time semantic segmentation and that our exposure-aware model outperforms the state-of-the-art segmentation methods, yielding top performances on our benchmark dataset.
Query Processing on Tensor Computation Runtimes
Mar 03, 2022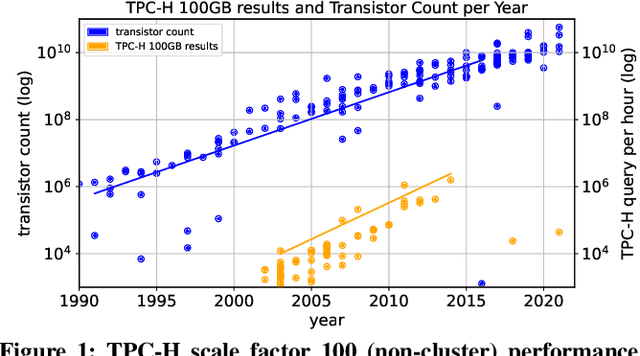

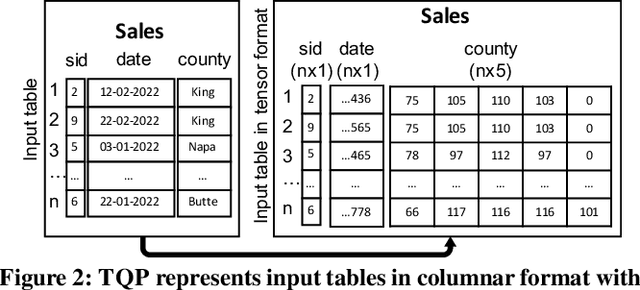
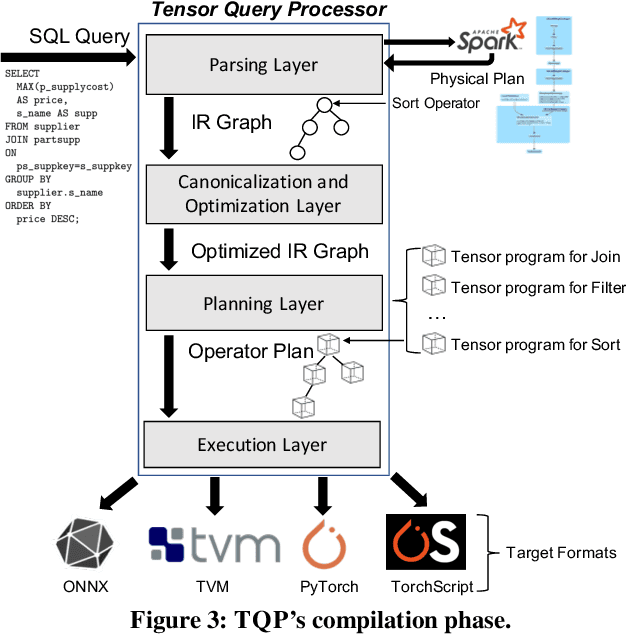
The huge demand for computation in artificial intelligence (AI) is driving unparalleled investments in new hardware and software systems for AI. This leads to an explosion in the number of specialized hardware devices, which are now part of the offerings of major cloud providers. Meanwhile, by hiding the low-level complexity through a tensor-based interface, tensor computation runtimes (TCRs) such as PyTorch allow data scientists to efficiently exploit the exciting capabilities offered by the new hardware. In this paper, we explore how databases can ride the wave of innovation happening in the AI space. Specifically, we present Tensor Query Processor (TQP): a SQL query processor leveraging the tensor interface of TCRs. TQP is able to efficiently run the full TPC-H benchmark by implementing novel algorithms for executing relational operators on the specialized tensor routines provided by TCRs. Meanwhile, TQP can target various hardware while only requiring a fraction of the usual development effort. Experiments show that TQP can improve query execution time by up to 20x over CPU-only systems, and up to 5x over specialized GPU solutions. Finally, TQP can accelerate queries mixing ML predictions and SQL end-to-end, and deliver up to 5x speedup over CPU baselines.
The Frost Hollow Experiments: Pavlovian Signalling as a Path to Coordination and Communication Between Agents
Mar 17, 2022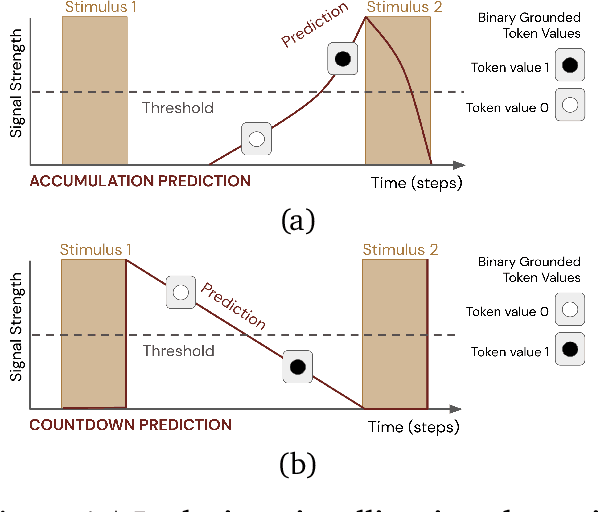

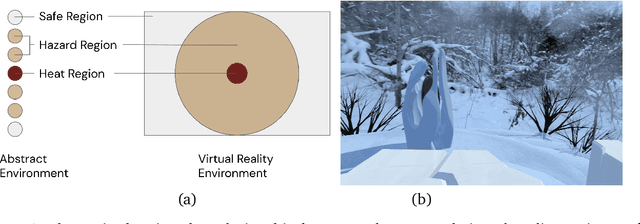
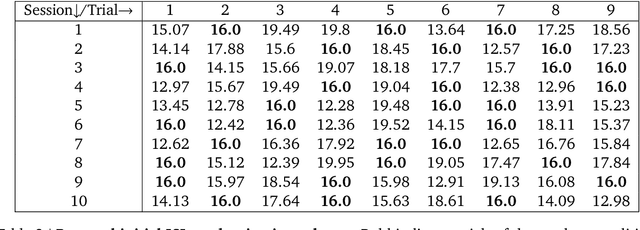
Learned communication between agents is a powerful tool when approaching decision-making problems that are hard to overcome by any single agent in isolation. However, continual coordination and communication learning between machine agents or human-machine partnerships remains a challenging open problem. As a stepping stone toward solving the continual communication learning problem, in this paper we contribute a multi-faceted study into what we term Pavlovian signalling -- a process by which learned, temporally extended predictions made by one agent inform decision-making by another agent with different perceptual access to their shared environment. We seek to establish how different temporal processes and representational choices impact Pavlovian signalling between learning agents. To do so, we introduce a partially observable decision-making domain we call the Frost Hollow. In this domain a prediction learning agent and a reinforcement learning agent are coupled into a two-part decision-making system that seeks to acquire sparse reward while avoiding time-conditional hazards. We evaluate two domain variations: 1) machine prediction and control learning in a linear walk, and 2) a prediction learning machine interacting with a human participant in a virtual reality environment. Our results showcase the speed of learning for Pavlovian signalling, the impact that different temporal representations do (and do not) have on agent-agent coordination, and how temporal aliasing impacts agent-agent and human-agent interactions differently. As a main contribution, we establish Pavlovian signalling as a natural bridge between fixed signalling paradigms and fully adaptive communication learning. Our results therefore point to an actionable, constructivist path towards continual communication learning between reinforcement learning agents, with potential impact in a range of real-world settings.
Designing Effective Sparse Expert Models
Feb 17, 2022
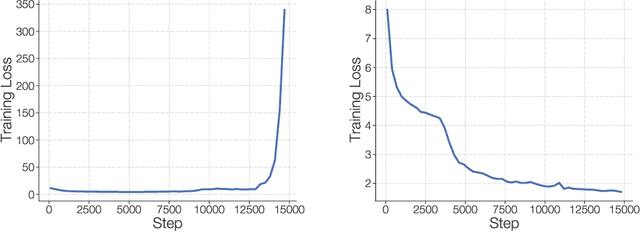

Scale has opened new frontiers in natural language processing -- but at a high cost. In response, Mixture-of-Experts (MoE) and Switch Transformers have been proposed as an energy efficient path to even larger and more capable language models. But advancing the state-of-the-art across a broad set of natural language tasks has been hindered by training instabilities and uncertain quality during fine-tuning. Our work focuses on these issues and acts as a design guide. We conclude by scaling a sparse model to 269B parameters, with a computational cost comparable to a 32B dense encoder-decoder Transformer (Stable and Transferable Mixture-of-Experts or ST-MoE-32B). For the first time, a sparse model achieves state-of-the-art performance in transfer learning, across a diverse set of tasks including reasoning (SuperGLUE, ARC Easy, ARC Challenge), summarization (XSum, CNN-DM), closed book question answering (WebQA, Natural Questions), and adversarially constructed tasks (Winogrande, ANLI R3).
L2C2: Locally Lipschitz Continuous Constraint towards Stable and Smooth Reinforcement Learning
Feb 15, 2022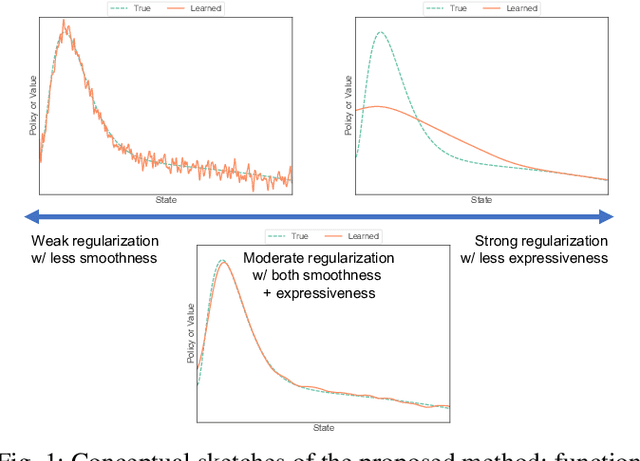
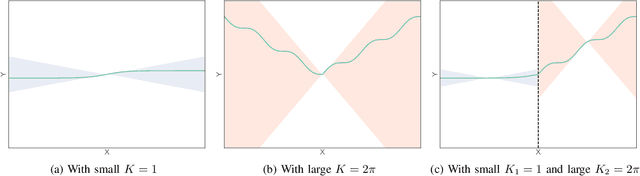
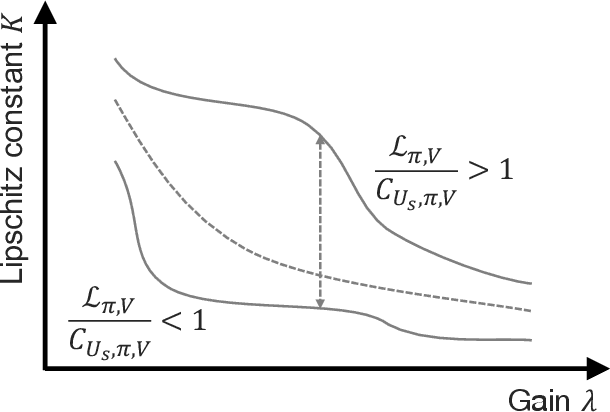
This paper proposes a new regularization technique for reinforcement learning (RL) towards making policy and value functions smooth and stable. RL is known for the instability of the learning process and the sensitivity of the acquired policy to noise. Several methods have been proposed to resolve these problems, and in summary, the smoothness of policy and value functions learned mainly in RL contributes to these problems. However, if these functions are extremely smooth, their expressiveness would be lost, resulting in not obtaining the global optimal solution. This paper therefore considers RL under local Lipschitz continuity constraint, so-called L2C2. By designing the spatio-temporal locally compact space for L2C2 from the state transition at each time step, the moderate smoothness can be achieved without loss of expressiveness. Numerical noisy simulations verified that the proposed L2C2 outperforms the task performance while smoothing out the robot action generated from the learned policy.
Using the Order of Tomographic Slices as a Prior for Neural Networks Pre-Training
Mar 17, 2022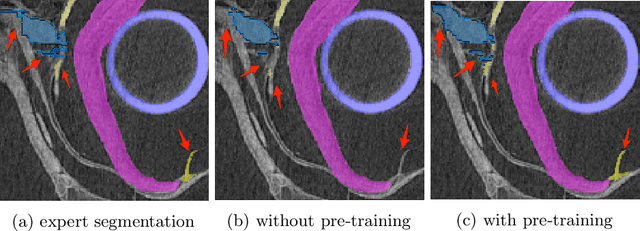
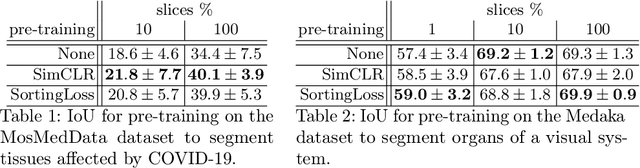
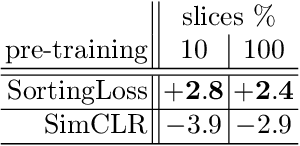
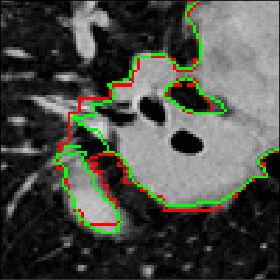
The technical advances in Computed Tomography (CT) allow to obtain immense amounts of 3D data. For such datasets it is very costly and time-consuming to obtain the accurate 3D segmentation markup to train neural networks. The annotation is typically done for a limited number of 2D slices, followed by an interpolation. In this work, we propose a pre-training method SortingLoss. It performs pre-training on slices instead of volumes, so that a model could be fine-tuned on a sparse set of slices, without the interpolation step. Unlike general methods (e.g. SimCLR or Barlow Twins), the task specific methods (e.g. Transferable Visual Words) trade broad applicability for quality benefits by imposing stronger assumptions on the input data. We propose a relatively mild assumption -- if we take several slices along some axis of a volume, structure of the sample presented on those slices, should give a strong clue to reconstruct the correct order of those slices along the axis. Many biomedical datasets fulfill this requirement due to the specific anatomy of a sample and pre-defined alignment of the imaging setup. We examine the proposed method on two datasets: medical CT of lungs affected by COVID-19 disease, and high-resolution synchrotron-based full-body CT of model organisms (Medaka fish). We show that the proposed method performs on par with SimCLR, while working 2x faster and requiring 1.5x less memory. In addition, we present the benefits in terms of practical scenarios, especially the applicability to the pre-training of large models and the ability to localize samples within volumes in an unsupervised setup.
Learning in Restless Bandits under Exogenous Global Markov Process
Dec 17, 2021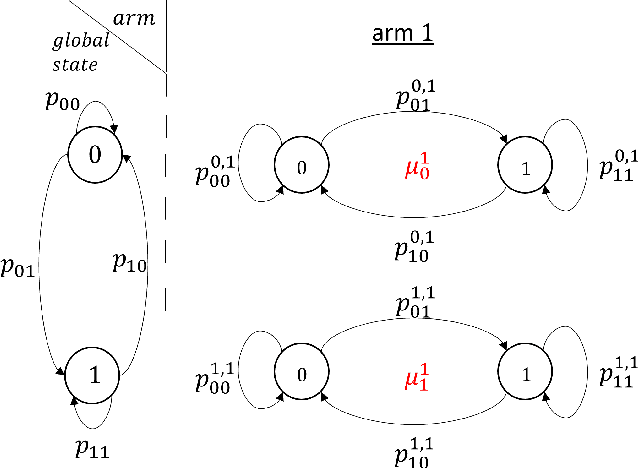
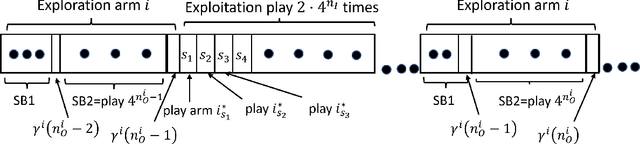
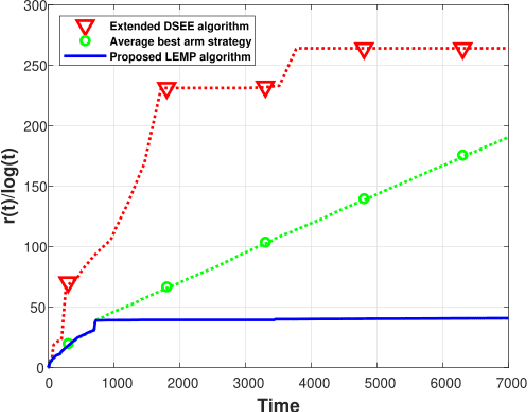
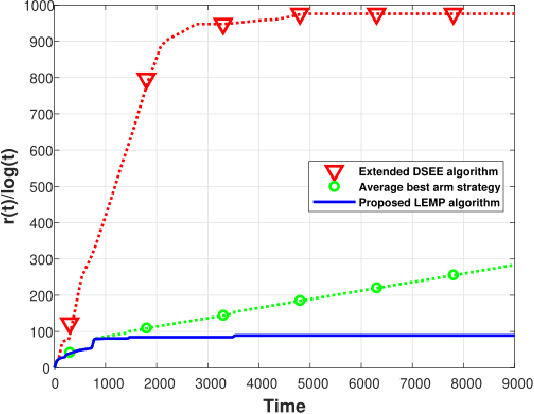
We consider an extension to the restless multi-armed bandit (RMAB) problem with unknown arm dynamics, where an unknown exogenous global Markov process governs the rewards distribution of each arm. Under each global state, the rewards process of each arm evolves according to an unknown Markovian rule, which is non-identical among different arms. At each time, a player chooses an arm out of $N$ arms to play, and receives a random reward from a finite set of reward states. The arms are restless, that is, their local state evolves regardless of the player's actions. Motivated by recent studies on related RMAB settings, the regret is defined as the reward loss with respect to a player that knows the dynamics of the problem, and plays at each time $t$ the arm that maximizes the expected immediate value. The objective is to develop an arm-selection policy that minimizes the regret. To that end, we develop the Learning under Exogenous Markov Process (LEMP) algorithm. We analyze LEMP theoretically and establish a finite-sample bound on the regret. We show that LEMP achieves a logarithmic regret order with time. We further analyze LEMP numerically and present simulation results that support the theoretical findings and demonstrate that LEMP significantly outperforms alternative algorithms.
DNN Training Acceleration via Exploring GPGPU Friendly Sparsity
Mar 11, 2022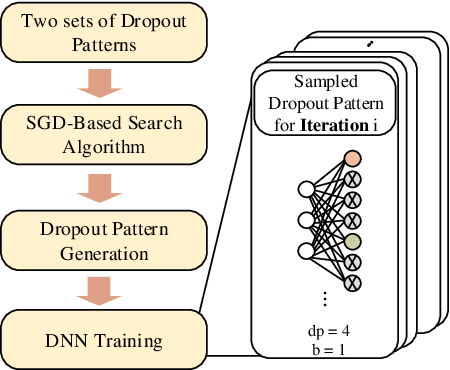
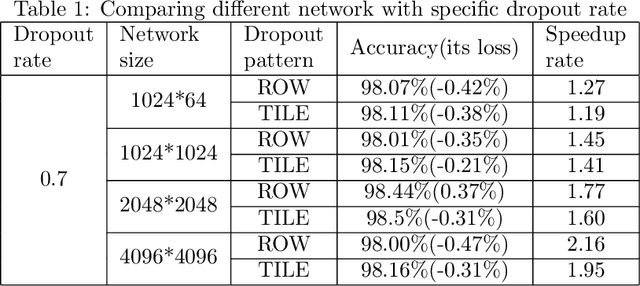
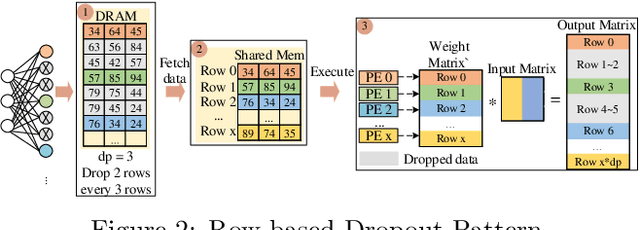
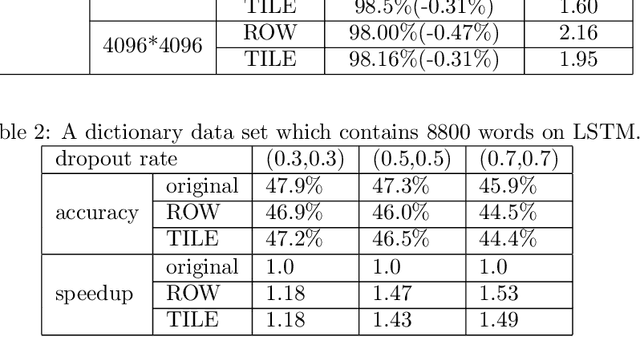
The training phases of Deep neural network~(DNN) consumes enormous processing time and energy. Compression techniques utilizing the sparsity of DNNs can effectively accelerate the inference phase of DNNs. However, it is hardly used in the training phase because the training phase involves dense matrix-multiplication using General-Purpose Computation on Graphics Processors (GPGPU), which endorse the regular and structural data layout. In this paper, we first propose the Approximate Random Dropout that replaces the conventional random dropout of neurons and synapses with a regular and online generated row-based or tile-based dropout patterns to eliminate the unnecessary computation and data access for the multilayer perceptron~(MLP) and long short-term memory~(LSTM). We then develop a SGD-based Search Algorithm that produces the distribution of row-based or tile-based dropout patterns to compensate for the potential accuracy loss. Moreover, aiming at the convolution neural network~(CNN) training acceleration, we first explore the importance and sensitivity of input feature maps; and then propose the sensitivity-aware dropout method to dynamically drop the input feature maps based on their sensitivity so as to achieve greater forward and backward training acceleration while reserving better NN accuracy. To facilitate DNN programming, we build a DNN training computation framework that unifies the proposed techniques in the software stack. As a result, the GPGPU only needs to support the basic operator -- matrix multiplication and can achieve significant performance improvement regardless of DNN model.
Artificial Intelligence in Software Testing : Impact, Problems, Challenges and Prospect
Jan 14, 2022
Artificial Intelligence (AI) is making a significant impact in multiple areas like medical, military, industrial, domestic, law, arts as AI is capable to perform several roles such as managing smart factories, driving autonomous vehicles, creating accurate weather forecasts, detecting cancer and personal assistants, etc. Software testing is the process of putting the software to test for some abnormal behaviour of the software. Software testing is a tedious, laborious and most time-consuming process. Automation tools have been developed that help to automate some activities of the testing process to enhance quality and timely delivery. Over time with the inclusion of continuous integration and continuous delivery (CI/CD) pipeline, automation tools are becoming less effective. The testing community is turning to AI to fill the gap as AI is able to check the code for bugs and errors without any human intervention and in a much faster way than humans. In this study, we aim to recognize the impact of AI technologies on various software testing activities or facets in the STLC. Further, the study aims to recognize and explain some of the biggest challenges software testers face while applying AI to testing. The paper also proposes some key contributions of AI in the future to the domain of software testing.
Ensemble plasticity and network adaptability in SNNs
Mar 11, 2022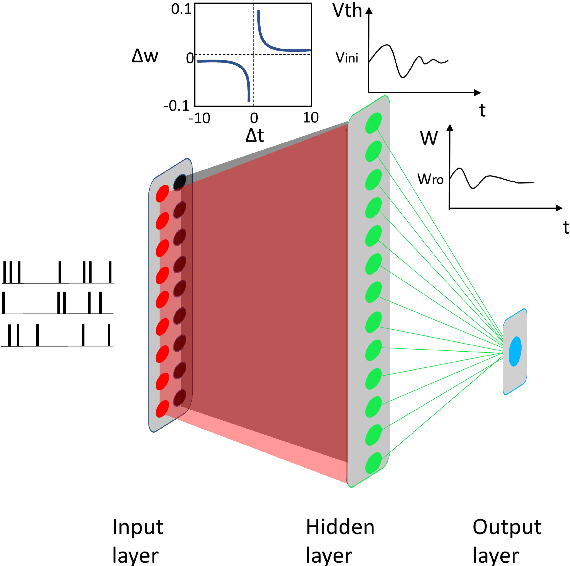
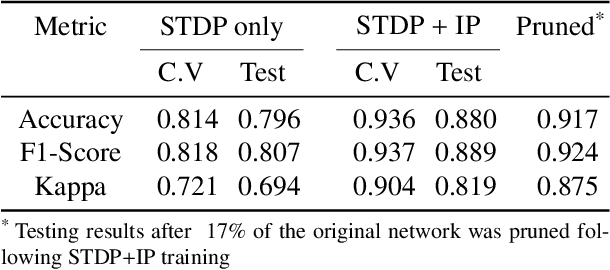
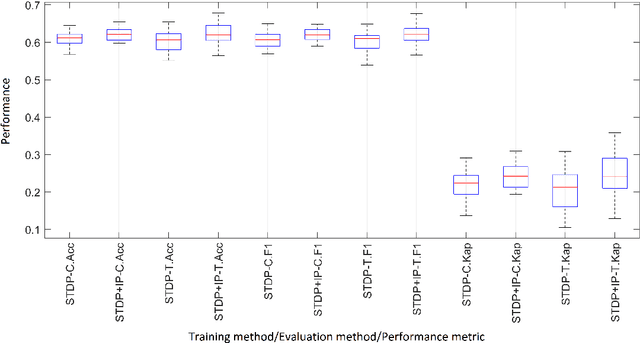
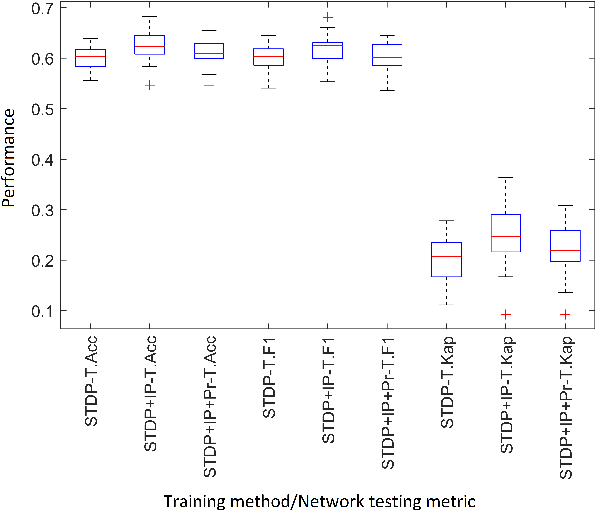
Artificial Spiking Neural Networks (ASNNs) promise greater information processing efficiency because of discrete event-based (i.e., spike) computation. Several Machine Learning (ML) applications use biologically inspired plasticity mechanisms as unsupervised learning techniques to increase the robustness of ASNNs while preserving efficiency. Spike Time Dependent Plasticity (STDP) and Intrinsic Plasticity (IP) (i.e., dynamic spiking threshold adaptation) are two such mechanisms that have been combined to form an ensemble learning method. However, it is not clear how this ensemble learning should be regulated based on spiking activity. Moreover, previous studies have attempted threshold based synaptic pruning following STDP, to increase inference efficiency at the cost of performance in ASNNs. However, this type of structural adaptation, that employs individual weight mechanisms, does not consider spiking activity for pruning which is a better representation of input stimuli. We envisaged that plasticity-based spike-regulation and spike-based pruning will result in ASSNs that perform better in low resource situations. In this paper, a novel ensemble learning method based on entropy and network activation is introduced, which is amalgamated with a spike-rate neuron pruning technique, operated exclusively using spiking activity. Two electroencephalography (EEG) datasets are used as the input for classification experiments with a three-layer feed forward ASNN trained using one-pass learning. During the learning process, we observed neurons assembling into a hierarchy of clusters based on spiking rate. It was discovered that pruning lower spike-rate neuron clusters resulted in increased generalization or a predictable decline in performance.