 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HighMMT: Towards Modality and Task Generalization for High-Modality Representation Learning
Mar 04, 2022

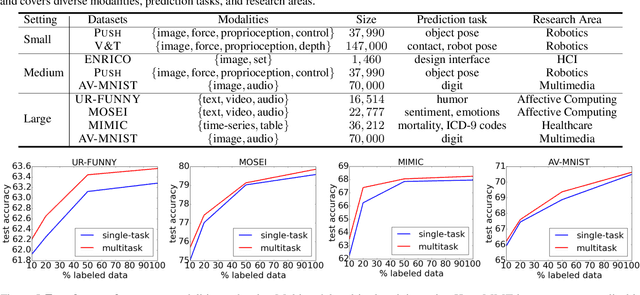
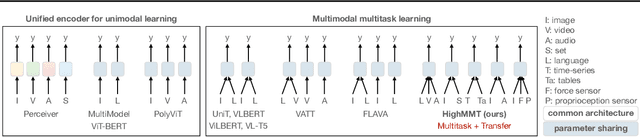
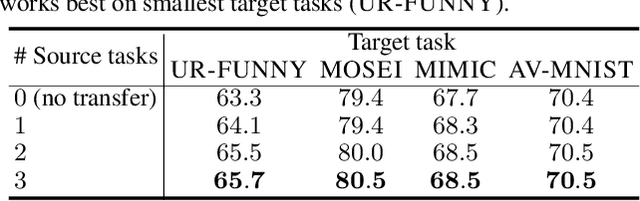
Learning multimodal representations involves discovering correspondences and integrating information from multiple heterogeneous sources of data. While recent research has begun to explore the design of more general-purpose multimodal models (contrary to prior focus on domain and modality-specific architectures), these methods are still largely focused on a small set of modalities in the language, vision, and audio space. In order to accelerate generalization towards diverse and understudied modalities, we investigate methods for high-modality (a large set of diverse modalities) and partially-observable (each task only defined on a small subset of modalities) scenarios. To tackle these challenges, we design a general multimodal model that enables multitask and transfer learning: multitask learning with shared parameters enables stable parameter counts (addressing scalability), and cross-modal transfer learning enables information sharing across modalities and tasks (addressing partial observability). Our resulting model generalizes across text, image, video, audio, time-series, sensors, tables, and set modalities from different research areas, improves the tradeoff between performance and efficiency, transfers to new modalities and tasks, and reveals surprising insights on the nature of information sharing in multitask models. We release our code and benchmarks which we hope will present a unified platform for subsequent theoretical and empirical analysis: https://github.com/pliang279/HighMMT.
Deep Reinforcement Learning Based Dynamic Route Planning for Minimizing Travel Time
Nov 03, 2020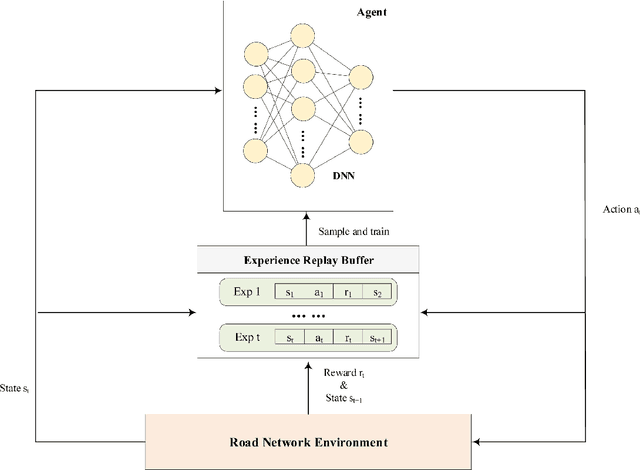
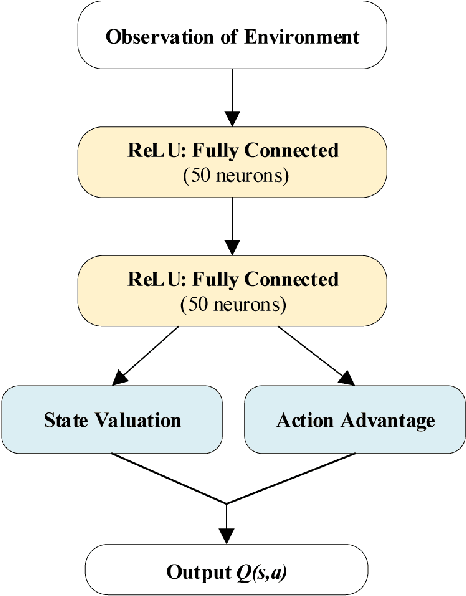
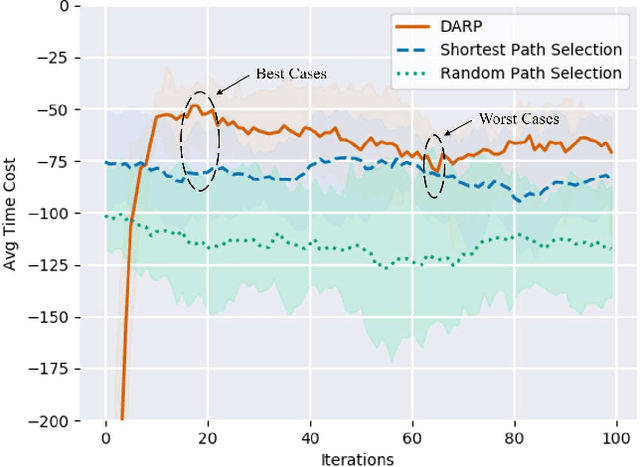
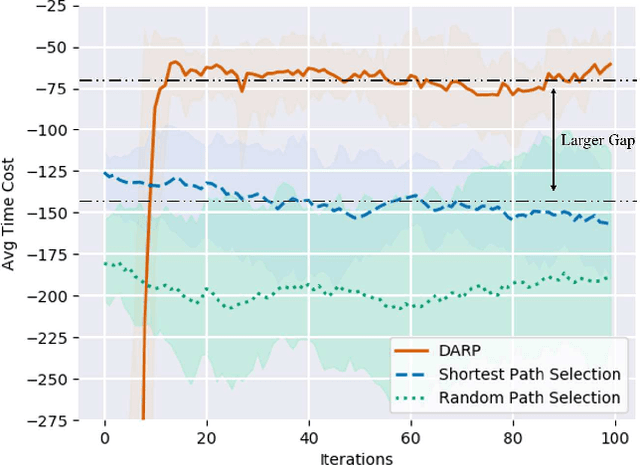
Route planning is important in transportation. Existing works focus on finding the shortest path solution or using metrics such as safety and energy consumption to determine the planning. It is noted that most of these studies rely on prior knowledge of road network, which may be not available in certain situations. In this paper, we design a route planning algorithm based on deep reinforcement learning (DRL) for pedestrians. We use travel time consumption as the metric, and plan the route by predicting pedestrian flow in the road network. We put an agent, which is an intelligent robot, on a virtual map. Different from previous studies, our approach assumes that the agent does not need any prior information about road network, but simply relies on the interaction with the environment. We propose a dynamically adjustable route planning (DARP) algorithm, where the agent learns strategies through a dueling deep Q network to avoid congested roads. Simulation results show that the DARP algorithm saves 52% of the time under congestion condition when compared with traditional shortest path planning algorithms.
Achieving Reliable Human Assessment of Open-Domain Dialogue Systems
Mar 11, 2022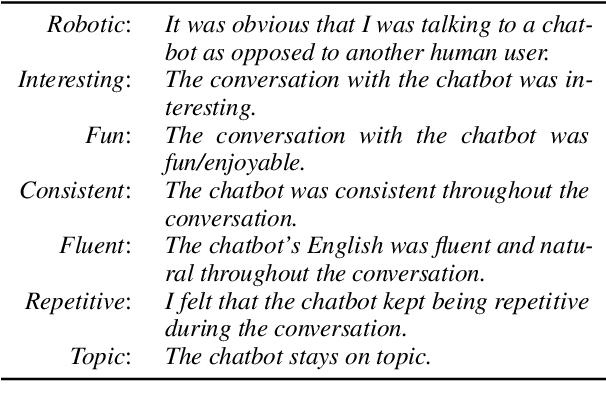

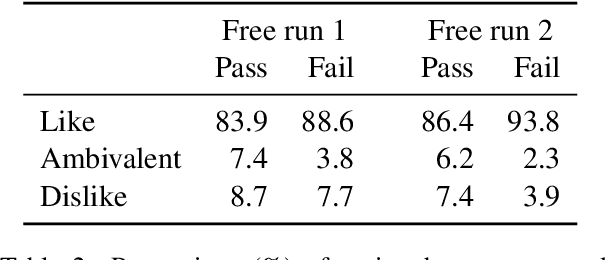
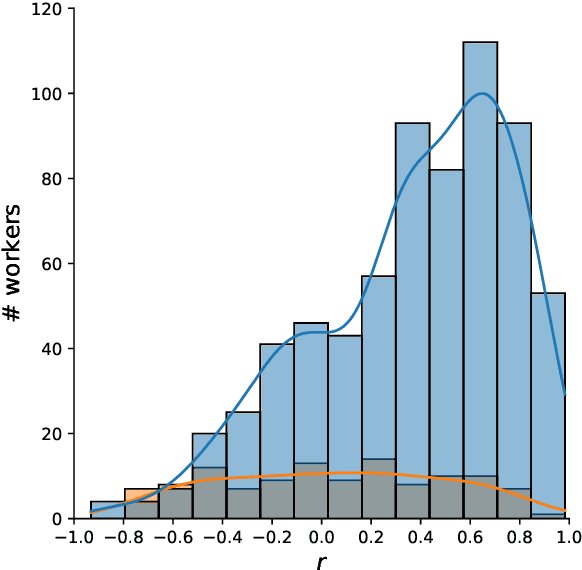
Evaluation of open-domain dialogue systems is highly challenging and development of better techniques is highlighted time and again as desperately needed. Despite substantial efforts to carry out reliable live evaluation of systems in recent competitions, annotations have been abandoned and reported as too unreliable to yield sensible results. This is a serious problem since automatic metrics are not known to provide a good indication of what may or may not be a high-quality conversation. Answering the distress call of competitions that have emphasized the urgent need for better evaluation techniques in dialogue, we present the successful development of human evaluation that is highly reliable while still remaining feasible and low cost. Self-replication experiments reveal almost perfectly repeatable results with a correlation of $r=0.969$. Furthermore, due to the lack of appropriate methods of statistical significance testing, the likelihood of potential improvements to systems occurring due to chance is rarely taken into account in dialogue evaluation, and the evaluation we propose facilitates application of standard tests. Since we have developed a highly reliable evaluation method, new insights into system performance can be revealed. We therefore include a comparison of state-of-the-art models (i) with and without personas, to measure the contribution of personas to conversation quality, as well as (ii) prescribed versus freely chosen topics. Interestingly with respect to personas, results indicate that personas do not positively contribute to conversation quality as expected.
DARL1N: Distributed multi-Agent Reinforcement Learning with One-hop Neighbors
Feb 18, 2022



Most existing multi-agent reinforcement learning (MARL) methods are limited in the scale of problems they can handle. Particularly, with the increase of the number of agents, their training costs grow exponentially. In this paper, we address this limitation by introducing a scalable MARL method called Distributed multi-Agent Reinforcement Learning with One-hop Neighbors (DARL1N). DARL1N is an off-policy actor-critic method that breaks the curse of dimensionality by decoupling the global interactions among agents and restricting information exchanges to one-hop neighbors. Each agent optimizes its action value and policy functions over a one-hop neighborhood, significantly reducing the learning complexity, yet maintaining expressiveness by training with varying numbers and states of neighbors. This structure allows us to formulate a distributed learning framework to further speed up the training procedure. Comparisons with state-of-the-art MARL methods show that DARL1N significantly reduces training time without sacrificing policy quality and is scalable as the number of agents increases.
Memory Efficient Tries for Sequential Pattern Mining
Feb 06, 2022The rapid and continuous growth of data has increased the need for scalable mining algorithms in unsupervised learning and knowledge discovery. In this paper, we focus on Sequential Pattern Mining (SPM), a fundamental topic in knowledge discovery that faces a well-known memory bottleneck. We examine generic dataset modeling techniques and show how they can be used to improve SPM algorithms in time and memory usage. In particular, we develop trie-based dataset models and associated mining algorithms that can represent as well as effectively mine orders of magnitude larger datasets compared to the state of the art. Numerical results on real-life large-size test instances show that our algorithms are also faster and more memory efficient in practice.
Night-time Semantic Segmentation with a Large Real Dataset
Mar 15, 2020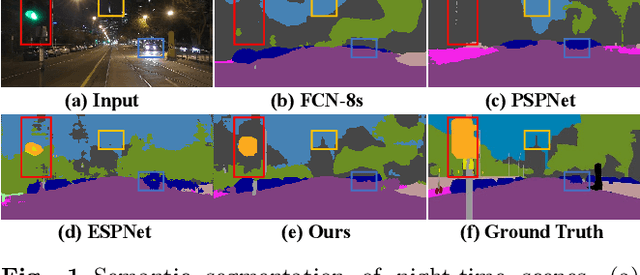
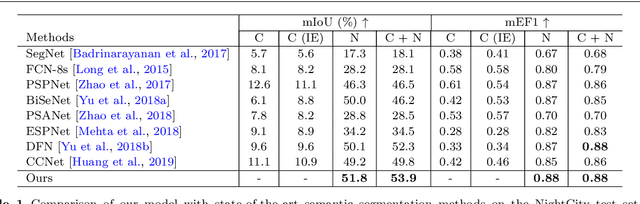
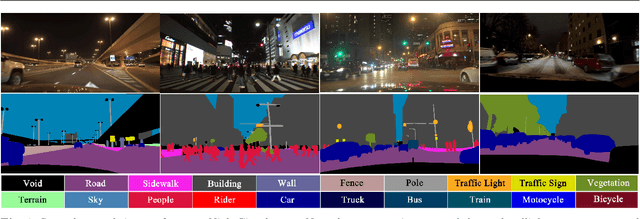
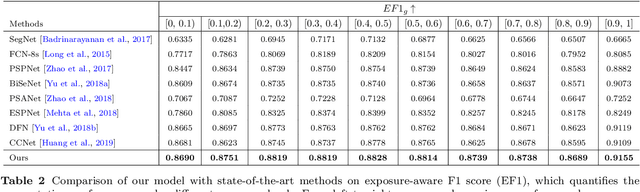
Although huge progress has been made on semantic segmentation in recent years, most existing works assume that the input images are captured in day-time with good lighting conditions. In this work, we aim to address the semantic segmentation problem of night-time scenes, which has two main challenges: 1) labeled night-time data are scarce, and 2) over- and under-exposures may co-occur in the input night-time images and are not explicitly modeled in existing semantic segmentation pipelines. To tackle the scarcity of night-time data, we collect a novel labeled dataset (named NightCity) of 4,297 real night-time images with ground truth pixel-level semantic annotations. To our knowledge, NightCity is the largest dataset for night-time semantic segmentation. In addition, we also propose an exposure-aware framework to address the night-time segmentation problem through augmenting the segmentation process with explicitly learned exposure features. Extensive experiments show that training on NightCity can significantly improve the performance of night-time semantic segmentation and that our exposure-aware model outperforms the state-of-the-art segmentation methods, yielding top performances on our benchmark dataset.
OrchestRAN: Network Automation through Orchestrated Intelligence in the Open RAN
Jan 14, 2022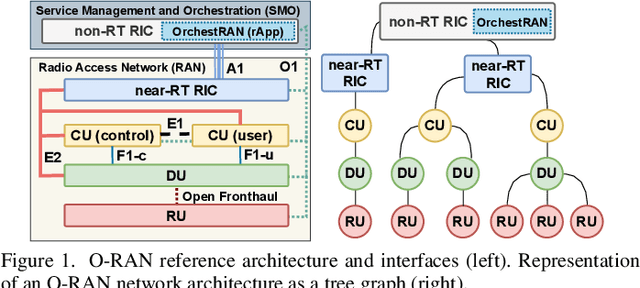
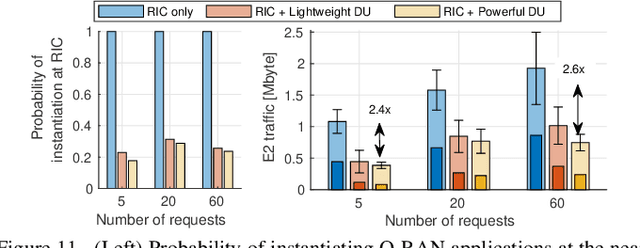
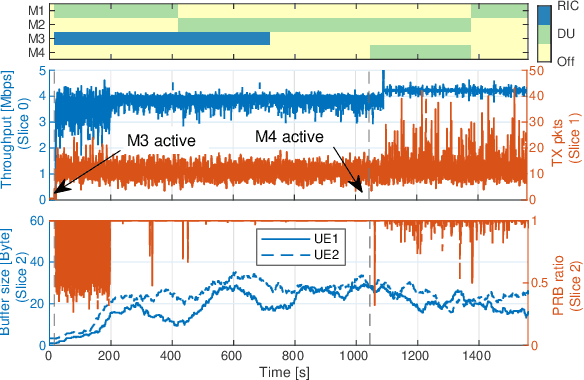
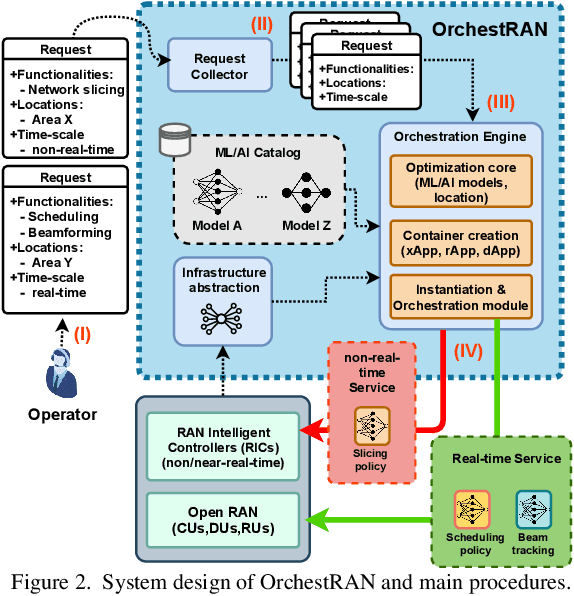
The next generation of cellular networks will be characterized by softwarized, open, and disaggregated architectures exposing analytics and control knobs to enable network intelligence. How to realize this vision, however, is largely an open problem. In this paper, we take a decisive step forward by presenting and prototyping OrchestRAN, a novel orchestration framework that embraces and builds upon the Open RAN paradigm to provide a practical solution to these challenges. OrchestRAN has been designed to execute in the non-real-time RAN Intelligent Controller (RIC) and allows Network Operators (NOs) to specify high-level control/inference objectives (i.e., adapt scheduling, and forecast capacity in near-real-time for a set of base stations in Downtown New York). OrchestRAN automatically computes the optimal set of data-driven algorithms and their execution location to achieve intents specified by the NOs while meeting the desired timing requirements. We show that the problem of orchestrating intelligence in Open RAN is NP-hard, and design low-complexity solutions to support real-world applications. We prototype OrchestRAN and test it at scale on Colosseum. Our experimental results on a network with 7 base stations and 42 users demonstrate that OrchestRAN is able to instantiate data-driven services on demand with minimal control overhead and latency.
Audio-visual Generalised Zero-shot Learning with Cross-modal Attention and Language
Mar 07, 2022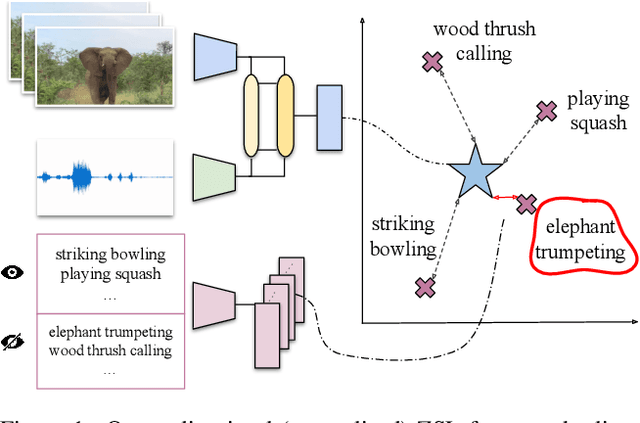
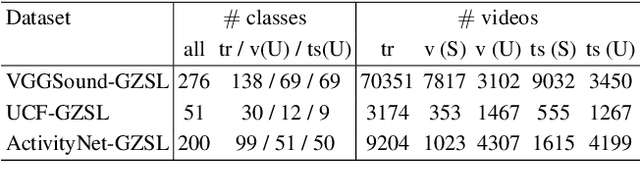
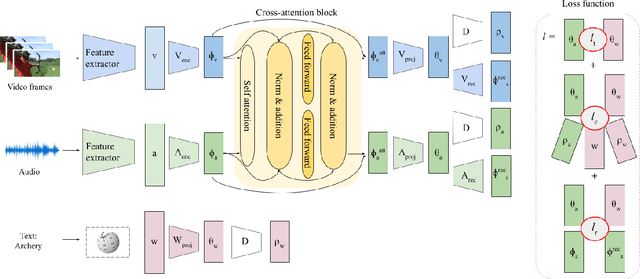
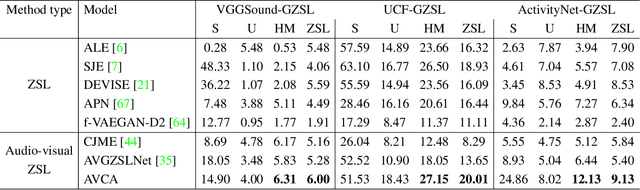
Learning to classify video data from classes not included in the training data, i.e. video-based zero-shot learning, is challenging. We conjecture that the natural alignment between the audio and visual modalities in video data provides a rich training signal for learning discriminative multi-modal representations. Focusing on the relatively underexplored task of audio-visual zero-shot learning, we propose to learn multi-modal representations from audio-visual data using cross-modal attention and exploit textual label embeddings for transferring knowledge from seen classes to unseen classes. Taking this one step further, in our generalised audio-visual zero-shot learning setting, we include all the training classes in the test-time search space which act as distractors and increase the difficulty while making the setting more realistic. Due to the lack of a unified benchmark in this domain, we introduce a (generalised) zero-shot learning benchmark on three audio-visual datasets of varying sizes and difficulty, VGGSound, UCF, and ActivityNet, ensuring that the unseen test classes do not appear in the dataset used for supervised training of the backbone deep models. Comparing multiple relevant and recent methods, we demonstrate that our proposed AVCA model achieves state-of-the-art performance on all three datasets. Code and data will be available at \url{https://github.com/ExplainableML/AVCA-GZSL}.
Optimal Algorithms for Decentralized Stochastic Variational Inequalities
Feb 06, 2022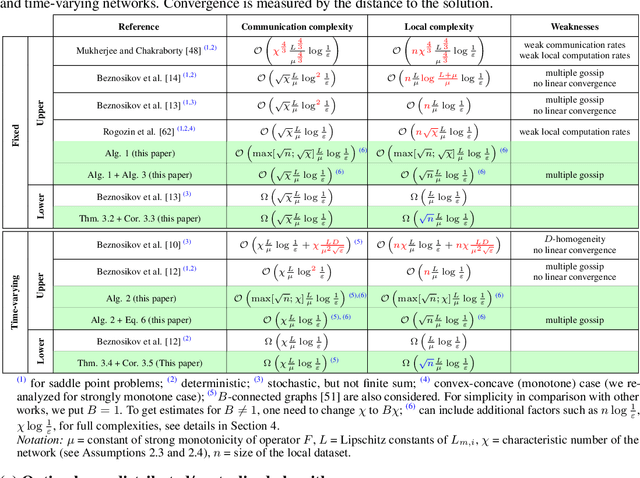
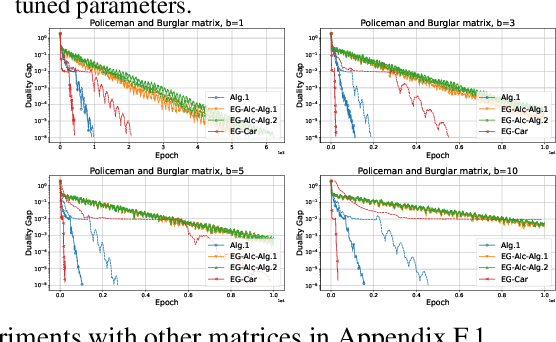
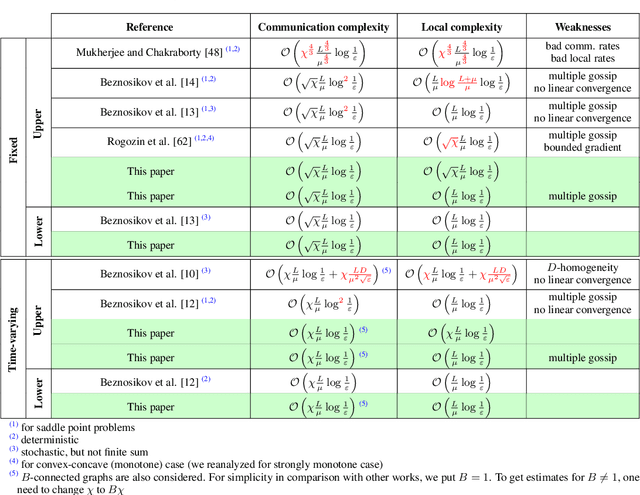
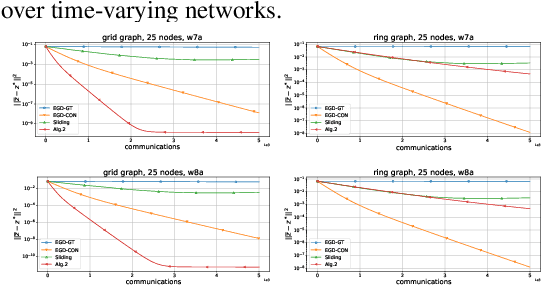
Variational inequalities are a formalism that includes games, minimization, saddle point, and equilibrium problems as special cases. Methods for variational inequalities are therefore universal approaches for many applied tasks, including machine learning problems. This work concentrates on the decentralized setting, which is increasingly important but not well understood. In particular, we consider decentralized stochastic (sum-type) variational inequalities over fixed and time-varying networks. We present lower complexity bounds for both communication and local iterations and construct optimal algorithms that match these lower bounds. Our algorithms are the best among the available literature not only in the decentralized stochastic case, but also in the decentralized deterministic and non-distributed stochastic cases. Experimental results confirm the effectiveness of the presented algorithms.
There's no difference: Convolutional Neural Networks for transient detection without template subtraction
Mar 14, 2022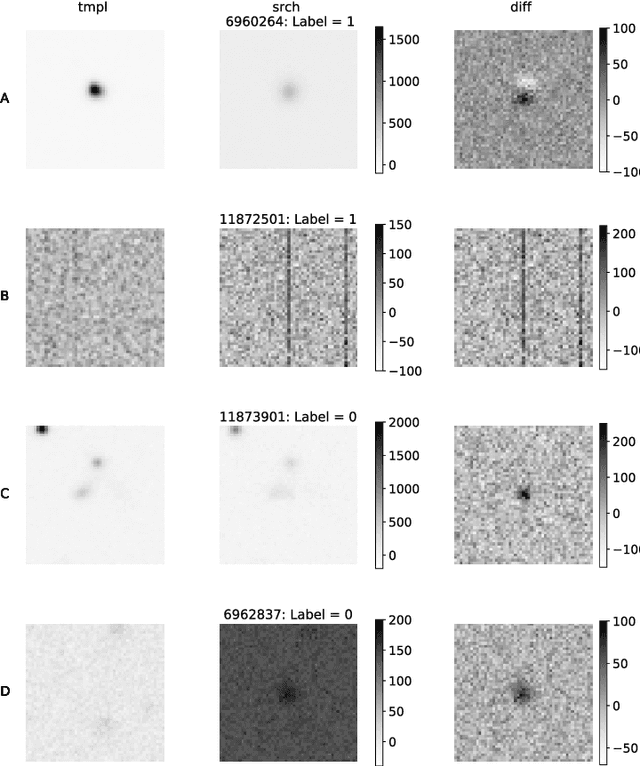
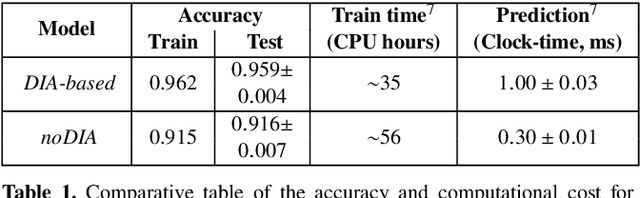
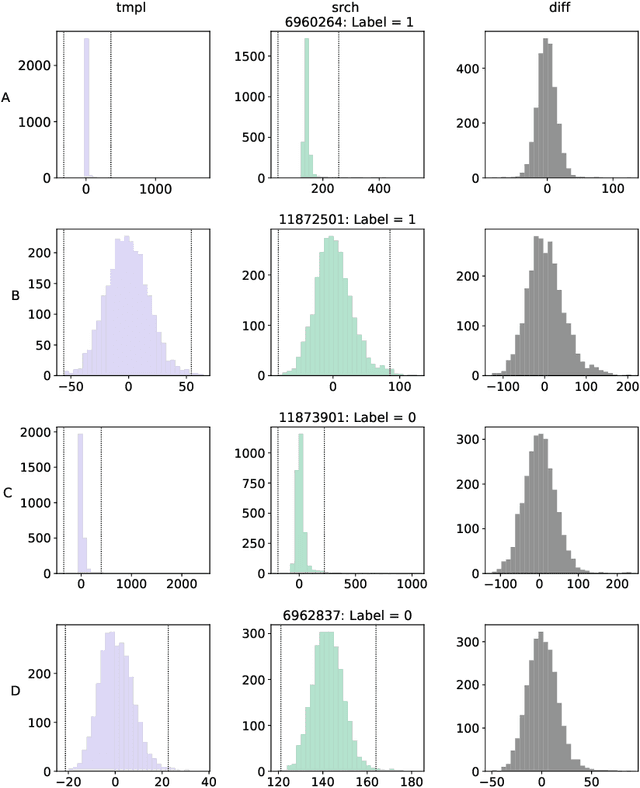

We present a Convolutional Neural Network (CNN) model for the separation of astrophysical transients from image artifacts, a task known as "real-bogus" classification, that does not rely on Difference Image Analysis (DIA) which is a computationally expensive process involving image matching on small spatial scales in large volumes of data. We explore the use of CNNs to (1) automate the "real-bogus" classification, (2) reduce the computational costs of transient discovery. We compare the efficiency of two CNNs with similar architectures, one that uses "image triplets" (templates, search, and the corresponding difference image) and one that adopts a similar architecture but takes as input the template and search only. Without substantially changing the model architecture or retuning the hyperparameters to the new input, we observe only a small decrease in model efficiency (97% to 92% accuracy). We further investigate how the model that does not receive the difference image learns the required information from the template and search by exploring the saliency maps. Our work demonstrates that (1) CNNs are excellent models for "real-bogus" classification that rely exclusively on the imaging data and require no feature engineering task; (2) high-accuracy models can be built without the need to construct difference images. Since once trained, neural networks can generate predictions at minimal computational costs, we argue that future implementations of this methodology could dramatically reduce the computational costs in the detection of genuine transients in synoptic surveys like Rubin Observatory's Legacy Survey of Space and Time by bypassing the DIA step entirely.