 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BlendTorch: A Real-Time, Adaptive Domain Randomization Library
Oct 06, 2020
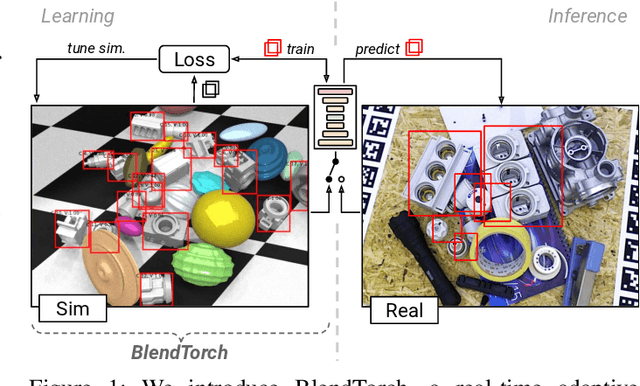
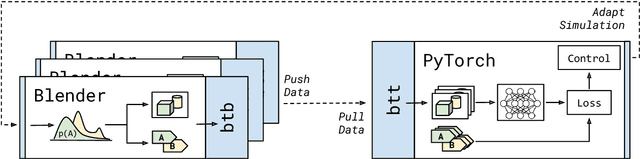

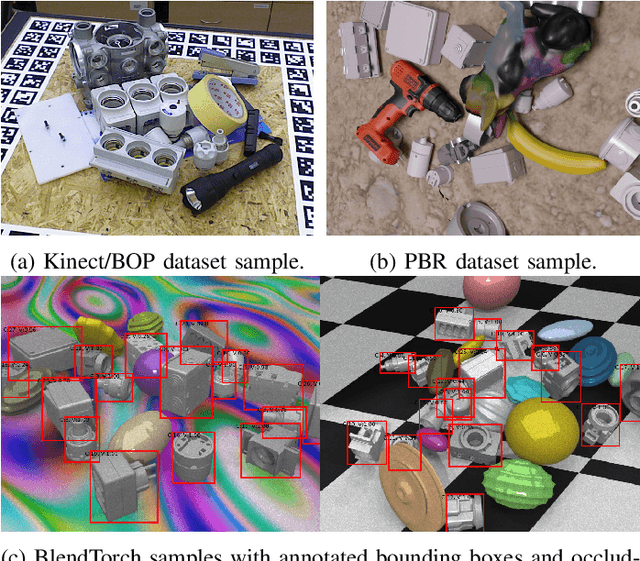
Solving complex computer vision tasks by deep learning techniques relies on large amounts of (supervised) image data, typically unavailable in industrial environments. The lack of training data starts to impede the successful transfer of state-of-the-art methods in computer vision to industrial applications. We introduce BlendTorch, an adaptive Domain Randomization (DR) library, to help creating infinite streams of synthetic training data. BlendTorch generates data by massively randomizing low-fidelity simulations and takes care of distributing artificial training data for model learning in real-time. We show that models trained with BlendTorch repeatedly perform better in an industrial object detection task than those trained on real or photo-realistic datasets.
Density Ratio Estimation via Infinitesimal Classification
Nov 22, 2021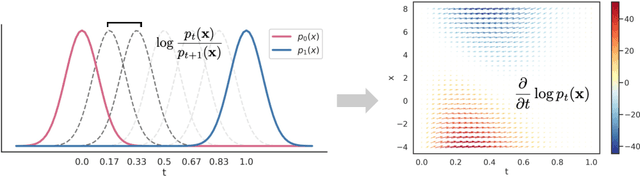
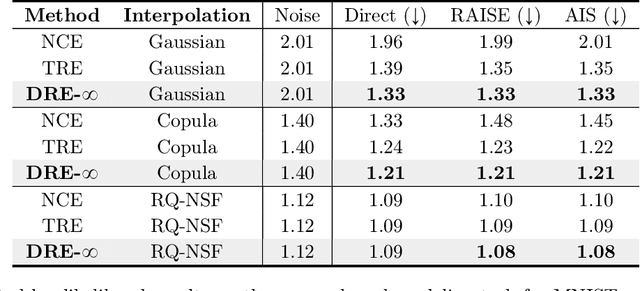

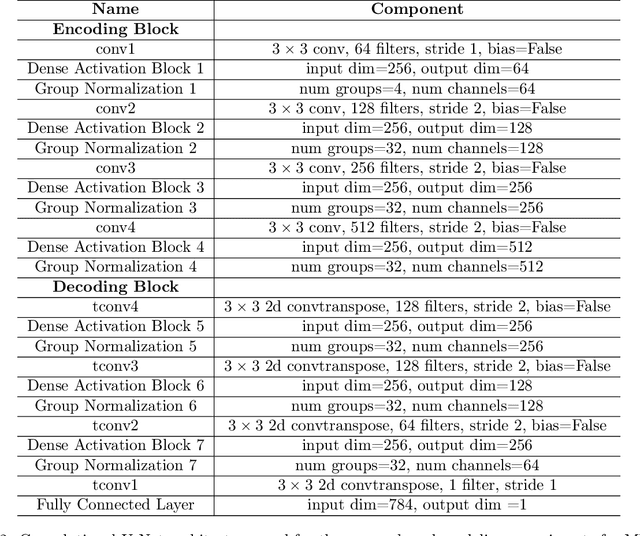
Density ratio estimation (DRE) is a fundamental machine learning technique for comparing two probability distributions. However, existing methods struggle in high-dimensional settings, as it is difficult to accurately compare probability distributions based on finite samples. In this work we propose DRE-\infty, a divide-and-conquer approach to reduce DRE to a series of easier subproblems. Inspired by Monte Carlo methods, we smoothly interpolate between the two distributions via an infinite continuum of intermediate bridge distributions. We then estimate the instantaneous rate of change of the bridge distributions indexed by time (the "time score") -- a quantity defined analogously to data (Stein) scores -- with a novel time score matching objective. Crucially, the learned time scores can then be integrated to compute the desired density ratio. In addition, we show that traditional (Stein) scores can be used to obtain integration paths that connect regions of high density in both distributions, improving performance in practice. Empirically, we demonstrate that our approach performs well on downstream tasks such as mutual information estimation and energy-based modeling on complex, high-dimensional datasets.
Planted Dense Subgraphs in Dense Random Graphs Can Be Recovered using Graph-based Machine Learning
Jan 05, 2022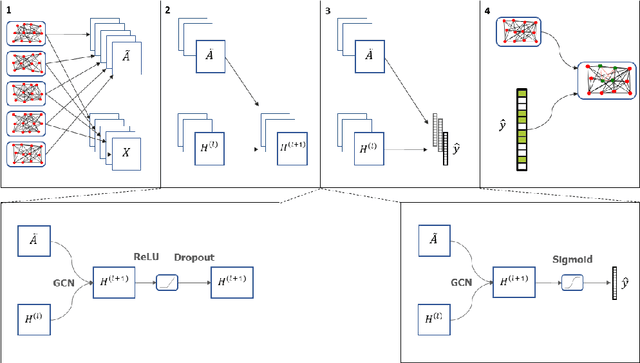
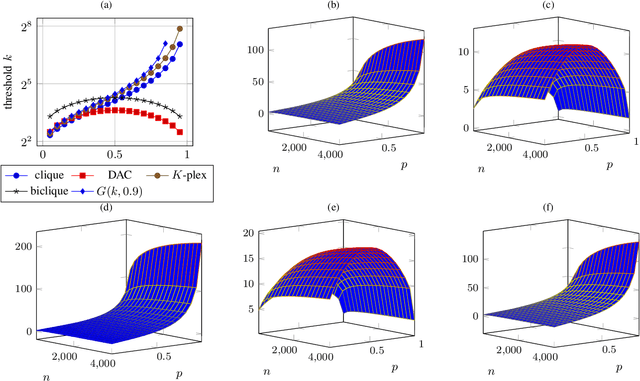
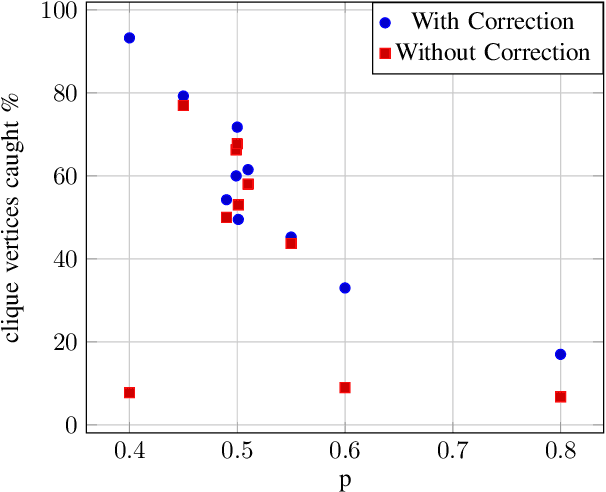
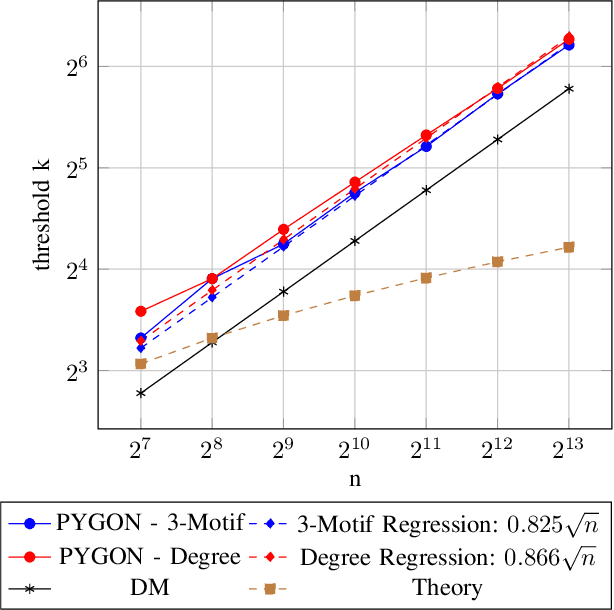
Multiple methods of finding the vertices belonging to a planted dense subgraph in a random dense $G(n, p)$ graph have been proposed, with an emphasis on planted cliques. Such methods can identify the planted subgraph in polynomial time, but are all limited to several subgraph structures. Here, we present PYGON, a graph neural network-based algorithm, which is insensitive to the structure of the planted subgraph. This is the first algorithm that uses advanced learning tools for recovering dense subgraphs. We show that PYGON can recover cliques of sizes $\Theta\left(\sqrt{n}\right)$, where $n$ is the size of the background graph, comparable with the state of the art. We also show that the same algorithm can recover multiple other planted subgraphs of size $\Theta\left(\sqrt{n}\right)$, in both directed and undirected graphs. We suggest a conjecture that no polynomial time PAC-learning algorithm can detect planted dense subgraphs with size smaller than $O\left(\sqrt{n}\right)$, even if in principle one could find dense subgraphs of logarithmic size.
Multi-class granular approximation by means of disjoint and adjacent fuzzy granules
Feb 15, 2022
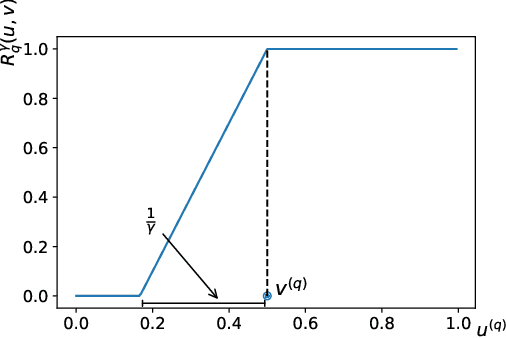
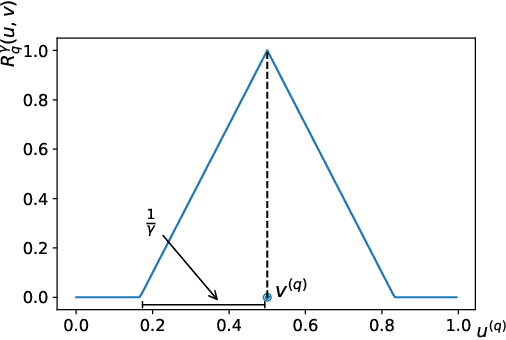
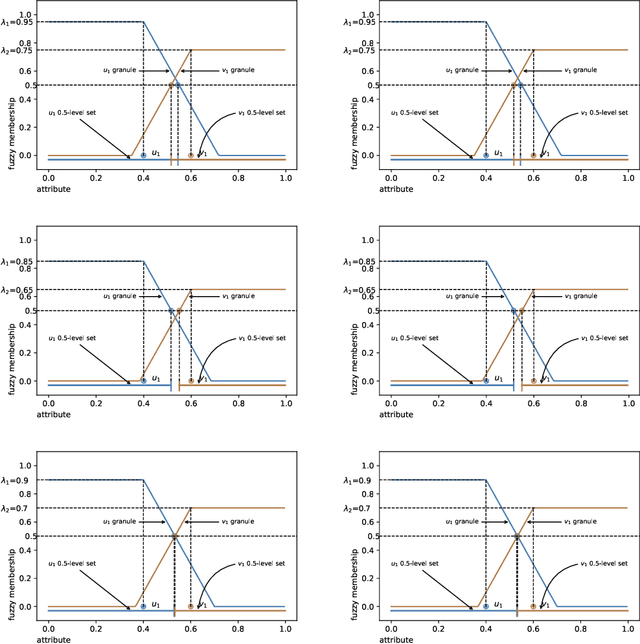
In granular computing, fuzzy sets can be approximated by granularly representable sets that are as close as possible to the original fuzzy set w.r.t. a given closeness measure. Such sets are called granular approximations. In this article, we introduce the concepts of disjoint and adjacent granules and we examine how the new definitions affect the granular approximations. First, we show that the new concepts are important for binary classification problems since they help to keep decision regions separated (disjoint granules) and at the same time to cover as much as possible of the attribute space (adjacent granules). Later, we consider granular approximations for multi-class classification problems leading to the definition of a multi-class granular approximation. Finally, we show how to efficiently calculate multi-class granular approximations for {\L}ukasiewicz fuzzy connectives. We also provide graphical illustrations for a better understanding of the introduced concepts.
Mungojerrie: Reinforcement Learning of Linear-Time Objectives
Jun 18, 2021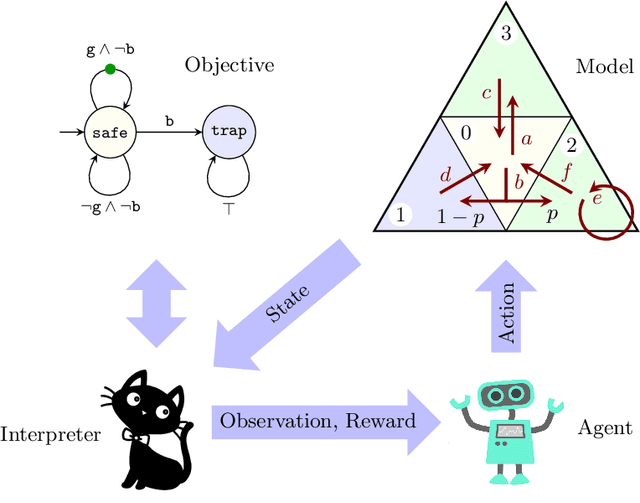

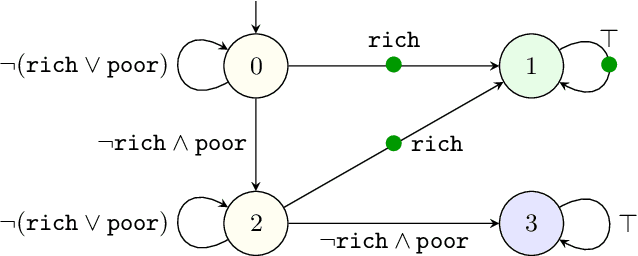

Reinforcement learning synthesizes controllers without prior knowledge of the system. At each timestep, a reward is given. The controllers optimize the discounted sum of these rewards. Applying this class of algorithms requires designing a reward scheme, which is typically done manually. The designer must ensure that their intent is accurately captured. This may not be trivial, and is prone to error. An alternative to this manual programming, akin to programming directly in assembly, is to specify the objective in a formal language and have it "compiled" to a reward scheme. Mungojerrie (https://plv.colorado.edu/mungojerrie/) is a tool for testing reward schemes for $\omega$-regular objectives on finite models. The tool contains reinforcement learning algorithms and a probabilistic model checker. Mungojerrie supports models specified in PRISM and $\omega$-automata specified in HOA.
BEATS: An Open-Source, High-Precision, Multi-Channel EEG Acquisition Tool System
Mar 04, 2022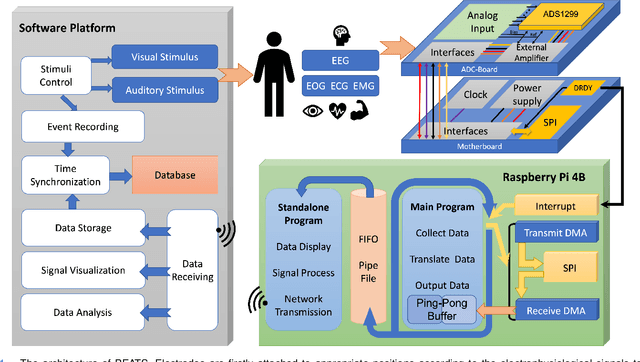
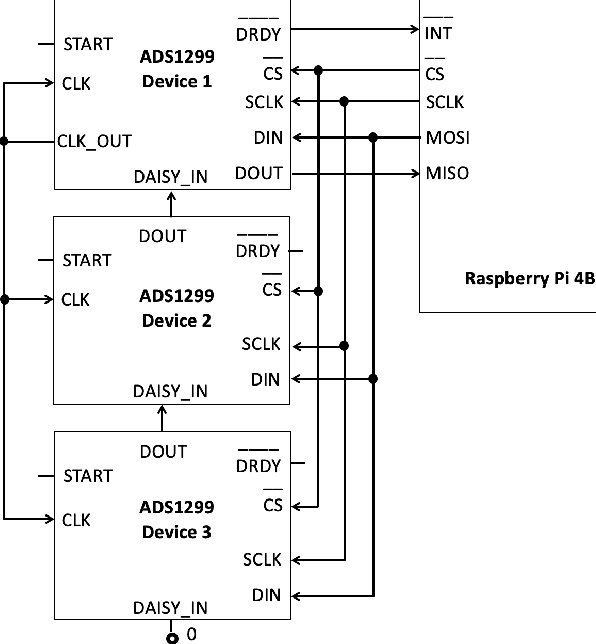

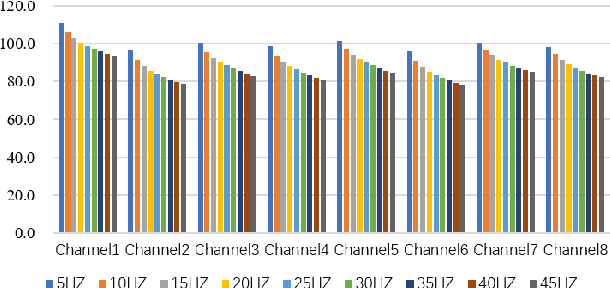
Stable and accurate electroencephalogram (EEG) signal acquisition is fundamental in non-invasive brain-computer interface (BCI) technology. Commonly used EEG acquisition system's hardware and software are usually closed-source. Its inability to flexible expansion and secondary development is a major obstacle to real-time BCI research. This paper presents an open-source, high-precision, multi-channel EEG Acquisition Tool System developed by Beijing University of Posts and Telecommunications named BEATS. It implements a comprehensive system from hardware to software, composes of analog front-end, microprocessor, and software platform. BEATS is capable of collecting multi-channel micro-volt EEG signals up to 4000 $Hz$ with wireless transmission. And it adopts a pluggable structure and easy-to-access materials, which can easily support rapid prototyping, portability, and scalability. Some underlying techniques like direct memory access, interrupt, first in first out are used to ensure the precision and stability of the program at the microsecond level. Compared to state-of-the-art systems, BEATS maintains a relatively high channel number when acquiring data at a high sampling rate, while being quick to set up and use, making it ideal for a wide range of BCI scenarios or long-term daily monitoring. Schematics, source code, and other materials of BEATS are available at https://github.com/bingzant/BEATS.
SOTER on ROS: A Run-Time Assurance Framework on the Robot Operating System
Aug 21, 2020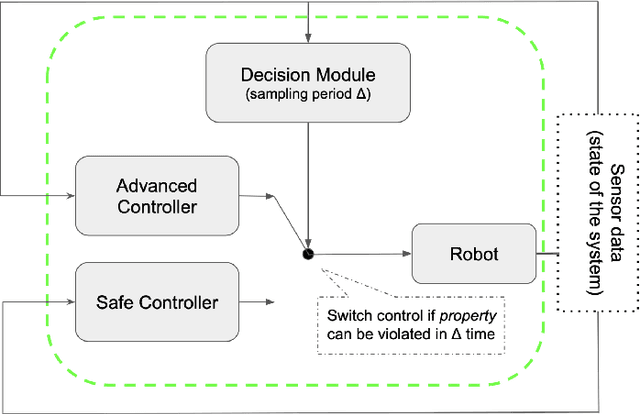
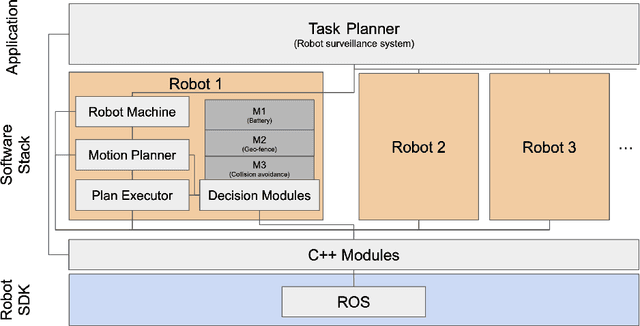

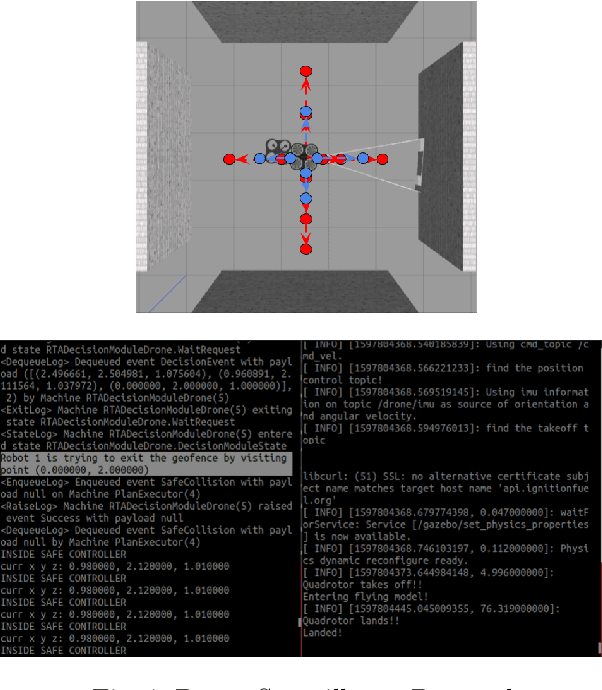
We present an implementation of SOTER, a run-time assurance framework for building safe distributed mobile robotic (DMR) systems, on top of the Robot Operating System (ROS). The safety of DMR systems cannot always be guaranteed at design time, especially when complex, off-the-shelf components are used that cannot be verified easily. SOTER addresses this by providing a language-based approach for run-time assurance for DMR systems. SOTER implements the reactive robotic software using the language P, a domain-specific language designed for implementing asynchronous event-driven systems, along with an integrated run-time assurance system that allows programmers to use unfortified components but still provide safety guarantees. We describe an implementation of SOTER for ROS and demonstrate its efficacy using a multi-robot surveillance case study, with multiple run-time assurance modules. Through rigorous simulation, we show that SOTER enabled systems ensure safety, even when using unknown and untrusted components.
Convolutional-Recurrent Neural Network Proxy for Robust Optimization and Closed-Loop Reservoir Management
Mar 14, 2022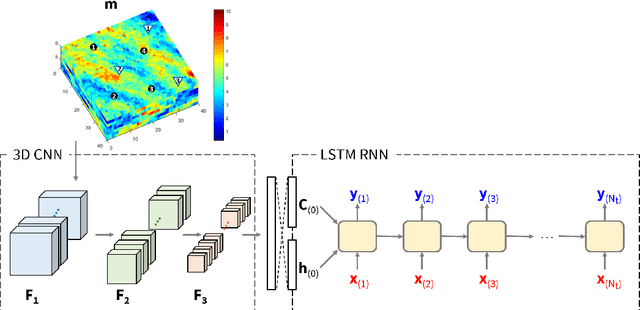

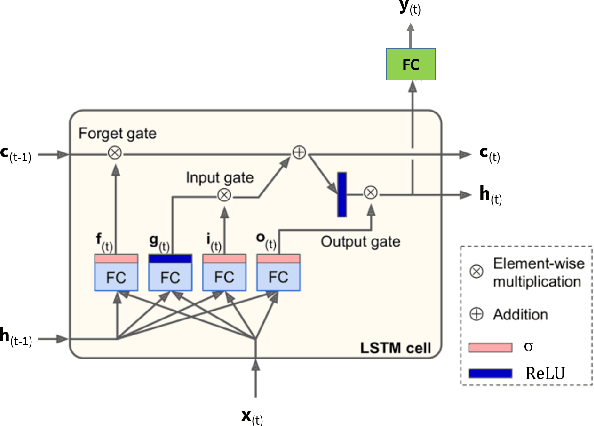
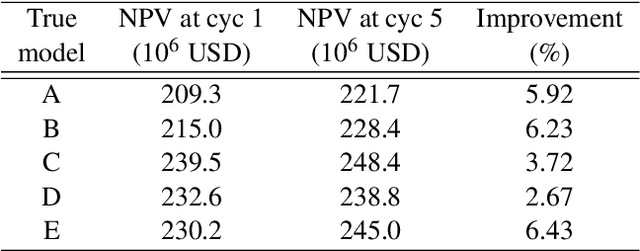
Production optimization under geological uncertainty is computationally expensive, as a large number of well control schedules must be evaluated over multiple geological realizations. In this work, a convolutional-recurrent neural network (CNN-RNN) proxy model is developed to predict well-by-well oil and water rates, for given time-varying well bottom-hole pressure (BHP) schedules, for each realization in an ensemble. This capability enables the estimation of the objective function and nonlinear constraint values required for robust optimization. The proxy model represents an extension of a recently developed long short-term memory (LSTM) RNN proxy designed to predict well rates for a single geomodel. A CNN is introduced here to processes permeability realizations, and this provides the initial states for the RNN. The CNN-RNN proxy is trained using simulation results for 300 different sets of BHP schedules and permeability realizations. We demonstrate proxy accuracy for oil-water flow through multiple realizations of 3D multi-Gaussian permeability models. The proxy is then incorporated into a closed-loop reservoir management (CLRM) workflow, where it is used with particle swarm optimization and a filter-based method for nonlinear constraint satisfaction. History matching is achieved using an adjoint-gradient-based procedure. The proxy model is shown to perform well in this setting for five different (synthetic) `true' models. Improved net present value along with constraint satisfaction and uncertainty reduction are observed with CLRM. For the robust production optimization steps, the proxy provides O(100) runtime speedup over simulation-based optimization.
Achieving Reliable Human Assessment of Open-Domain Dialogue Systems
Mar 11, 2022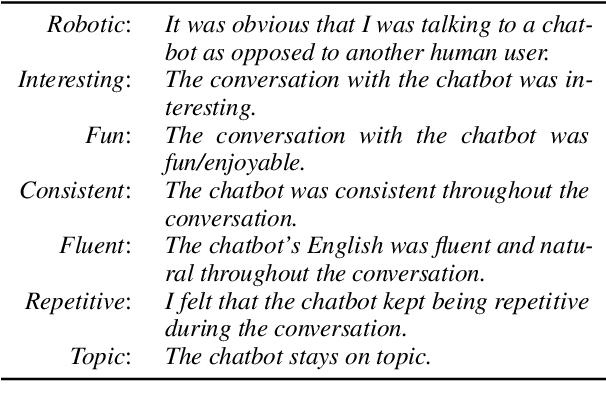

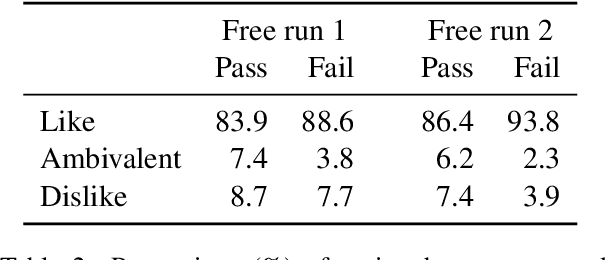
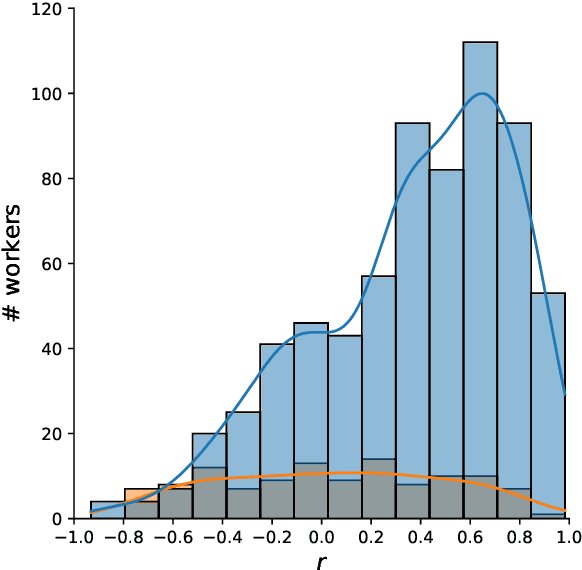
Evaluation of open-domain dialogue systems is highly challenging and development of better techniques is highlighted time and again as desperately needed. Despite substantial efforts to carry out reliable live evaluation of systems in recent competitions, annotations have been abandoned and reported as too unreliable to yield sensible results. This is a serious problem since automatic metrics are not known to provide a good indication of what may or may not be a high-quality conversation. Answering the distress call of competitions that have emphasized the urgent need for better evaluation techniques in dialogue, we present the successful development of human evaluation that is highly reliable while still remaining feasible and low cost. Self-replication experiments reveal almost perfectly repeatable results with a correlation of $r=0.969$. Furthermore, due to the lack of appropriate methods of statistical significance testing, the likelihood of potential improvements to systems occurring due to chance is rarely taken into account in dialogue evaluation, and the evaluation we propose facilitates application of standard tests. Since we have developed a highly reliable evaluation method, new insights into system performance can be revealed. We therefore include a comparison of state-of-the-art models (i) with and without personas, to measure the contribution of personas to conversation quality, as well as (ii) prescribed versus freely chosen topics. Interestingly with respect to personas, results indicate that personas do not positively contribute to conversation quality as expected.
HighMMT: Towards Modality and Task Generalization for High-Modality Representation Learning
Mar 04, 2022
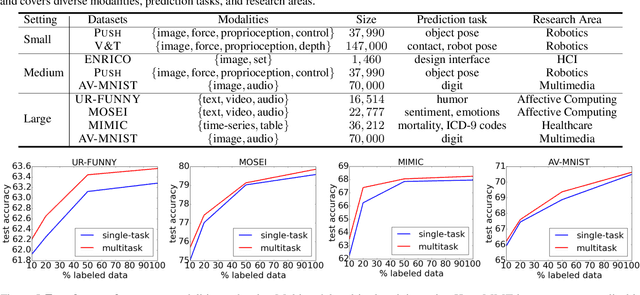
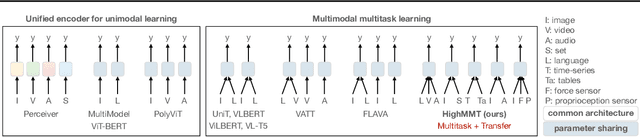
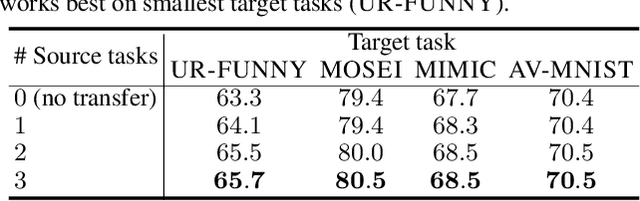
Learning multimodal representations involves discovering correspondences and integrating information from multiple heterogeneous sources of data. While recent research has begun to explore the design of more general-purpose multimodal models (contrary to prior focus on domain and modality-specific architectures), these methods are still largely focused on a small set of modalities in the language, vision, and audio space. In order to accelerate generalization towards diverse and understudied modalities, we investigate methods for high-modality (a large set of diverse modalities) and partially-observable (each task only defined on a small subset of modalities) scenarios. To tackle these challenges, we design a general multimodal model that enables multitask and transfer learning: multitask learning with shared parameters enables stable parameter counts (addressing scalability), and cross-modal transfer learning enables information sharing across modalities and tasks (addressing partial observability). Our resulting model generalizes across text, image, video, audio, time-series, sensors, tables, and set modalities from different research areas, improves the tradeoff between performance and efficiency, transfers to new modalities and tasks, and reveals surprising insights on the nature of information sharing in multitask models. We release our code and benchmarks which we hope will present a unified platform for subsequent theoretical and empirical analysis: https://github.com/pliang279/HighMMT.