 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spirit Distillation: Precise Real-time Semantic Segmentation of Road Scenes with Insufficient Data
Apr 17, 2021
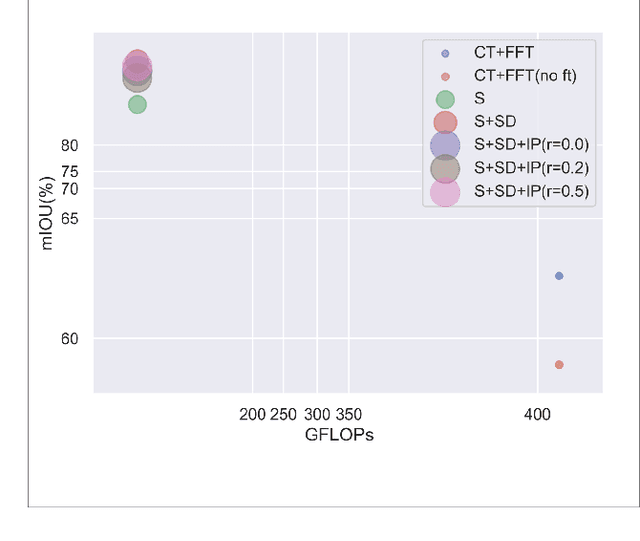
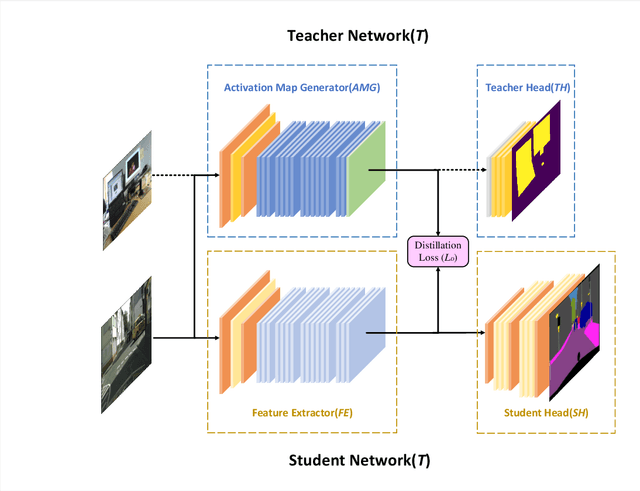
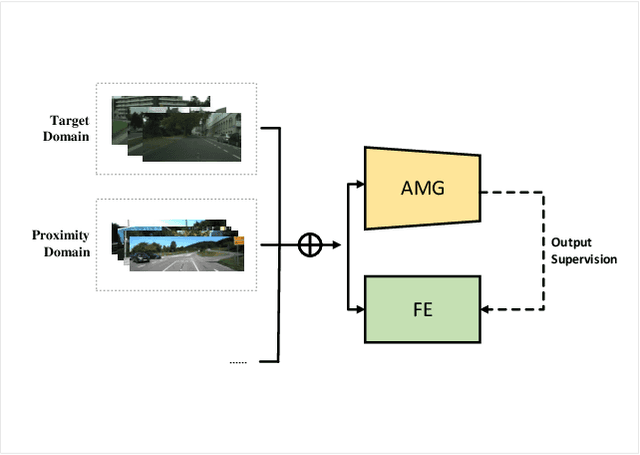
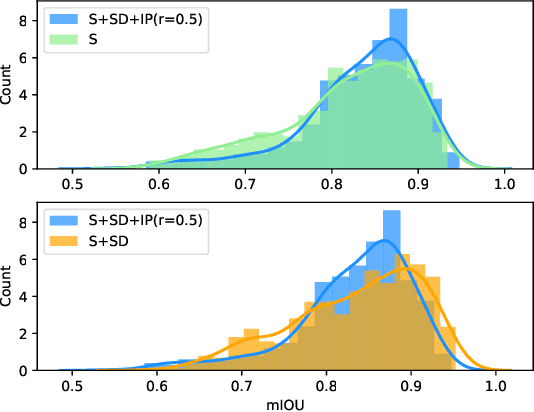
Semantic segmentation of road scenes is one of the key technologies for realizing autonomous driving scene perception, and the effectiveness of deep Convolutional Neural Networks(CNNs) for this task has been demonstrated. State-of-art CNNs for semantic segmentation suffer from excessive computations as well as large-scale training data requirement. Inspired by the ideas of Fine-tuning-based Transfer Learning (FTT) and feature-based knowledge distillation, we propose a new knowledge distillation method for cross-domain knowledge transference and efficient data-insufficient network training, named Spirit Distillation(SD), which allow the student network to mimic the teacher network to extract general features, so that a compact and accurate student network can be trained for real-time semantic segmentation of road scenes. Then, in order to further alleviate the trouble of insufficient data and improve the robustness of the student, an Enhanced Spirit Distillation (ESD) method is proposed, which commits to exploit a more comprehensive general features extraction capability by considering images from both the target and the proximity domains as input. To our knowledge, this paper is a pioneering work on the application of knowledge distillation to few-shot learning. Persuasive experiments conducted on Cityscapes semantic segmentation with the prior knowledge transferred from COCO2017 and KITTI demonstrate that our methods can train a better student network (mIOU and high-precision accuracy boost by 1.4% and 8.2% respectively, with 78.2% segmentation variance) with only 41.8% FLOPs (see Fig. 1).
Evaluating data augmentation for financial time series classification
Oct 28, 2020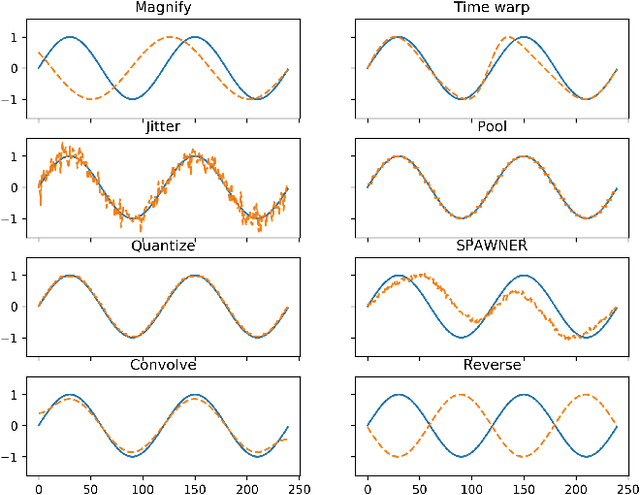
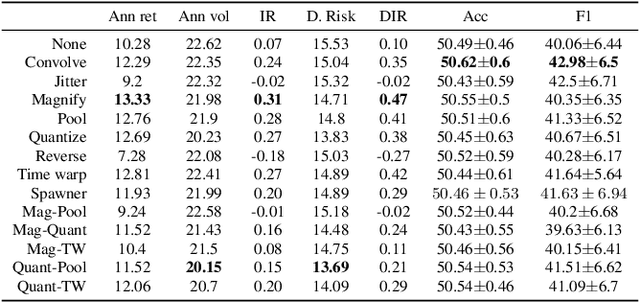
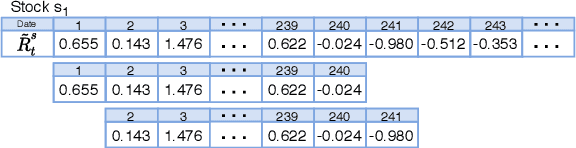
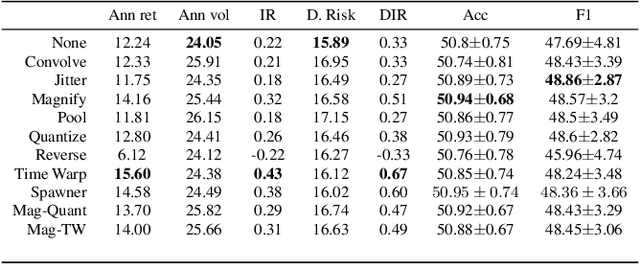
Data augmentation methods in combination with deep neural networks have been used extensively in computer vision on classification tasks, achieving great success; however, their use in time series classification is still at an early stage. This is even more so in the field of financial prediction, where data tends to be small, noisy and non-stationary. In this paper we evaluate several augmentation methods applied to stocks datasets using two state-of-the-art deep learning models. The results show that several augmentation methods significantly improve financial performance when used in combination with a trading strategy. For a relatively small dataset ($\approx30K$ samples), augmentation methods achieve up to $400\%$ improvement in risk adjusted return performance; for a larger stock dataset ($\approx300K$ samples), results show up to $40\%$ improvement.
Towards Effective and Robust Neural Trojan Defenses via Input Filtering
Mar 08, 2022


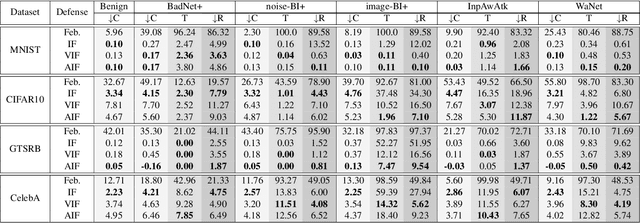
Trojan attacks on deep neural networks are both dangerous and surreptitious. Over the past few years, Trojan attacks have advanced from using only a single input-agnostic trigger and targeting only one class to using multiple, input-specific triggers and targeting multiple classes. However, Trojan defenses have not caught up with this development. Most defense methods still make out-of-date assumptions about Trojan triggers and target classes, thus, can be easily circumvented by modern Trojan attacks. To deal with this problem, we propose two novel "filtering" defenses called Variational Input Filtering (VIF) and Adversarial Input Filtering (AIF) which leverage lossy data compression and adversarial learning respectively to effectively purify all potential Trojan triggers in the input at run time without making assumptions about the number of triggers/target classes or the input dependence property of triggers. In addition, we introduce a new defense mechanism called "Filtering-then-Contrasting" (FtC) which helps avoid the drop in classification accuracy on clean data caused by "filtering", and combine it with VIF/AIF to derive new defenses of this kind. Extensive experimental results and ablation studies show that our proposed defenses significantly outperform well-known baseline defenses in mitigating five advanced Trojan attacks including two recent state-of-the-art while being quite robust to small amounts of training data and large-norm triggers.
TEScalib: Targetless Extrinsic Self-Calibration of LiDAR and Stereo Camera for Automated Driving Vehicles with Uncertainty Analysis
Feb 28, 2022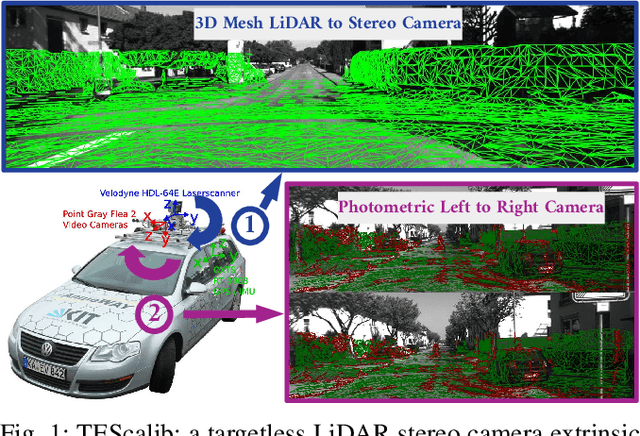
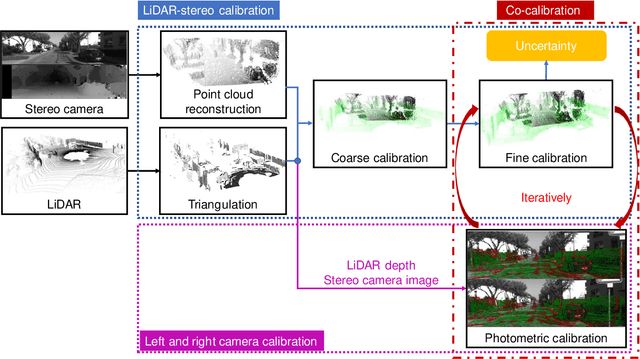
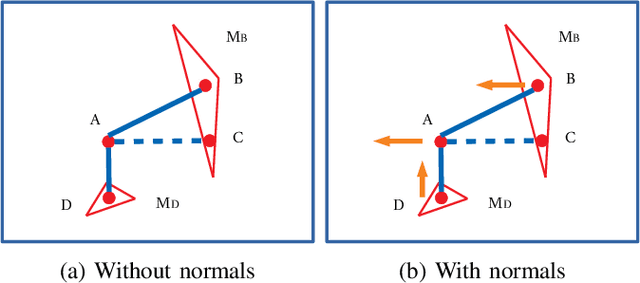
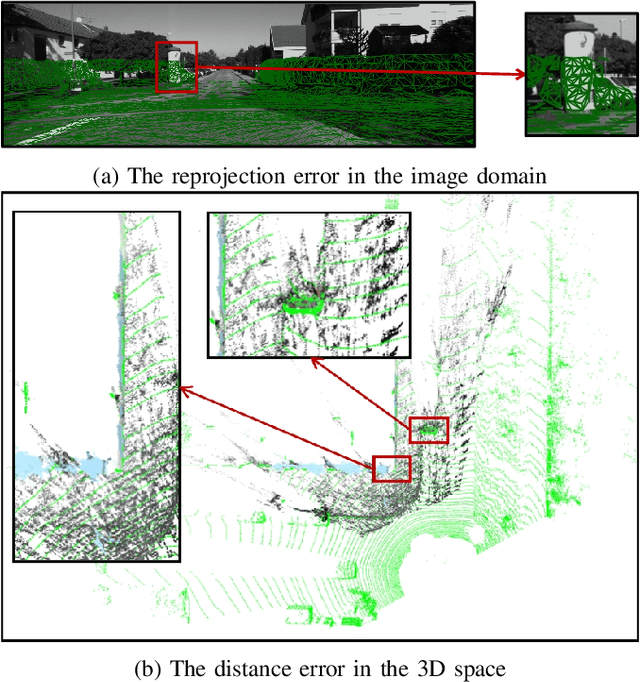
In this paper, we present TEScalib, a novel extrinsic self-calibration approach of LiDAR and stereo camera using the geometric and photometric information of surrounding environments without any calibration targets for automated driving vehicles. Since LiDAR and stereo camera are widely used for sensor data fusion on automated driving vehicles, their extrinsic calibration is highly important. However, most of the LiDAR and stereo camera calibration approaches are mainly target-based and therefore time consuming. Even the newly developed targetless approaches in last years are either inaccurate or unsuitable for driving platforms. To address those problems, we introduce TEScalib. By applying a 3D mesh reconstruction-based point cloud registration, the geometric information is used to estimate the LiDAR to stereo camera extrinsic parameters accurately and robustly. To calibrate the stereo camera, a photometric error function is builded and the LiDAR depth is involved to transform key points from one camera to another. During driving, these two parts are processed iteratively. Besides that, we also propose an uncertainty analysis for reflecting the reliability of the estimated extrinsic parameters. Our TEScalib approach evaluated on the KITTI dataset achieves very promising results.
Learning based Age of Information Minimization in UAV-relayed IoT Networks
Mar 08, 2022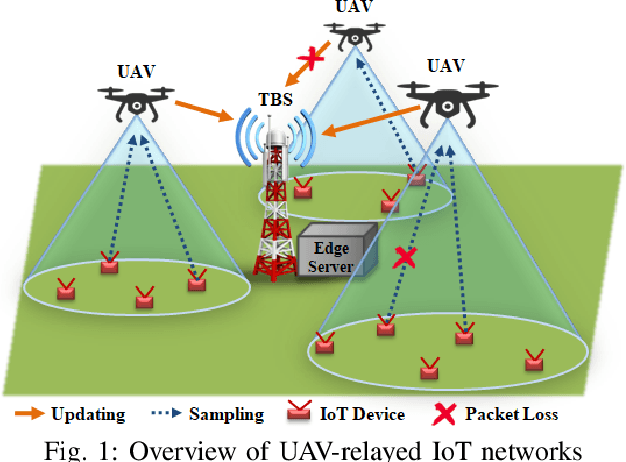
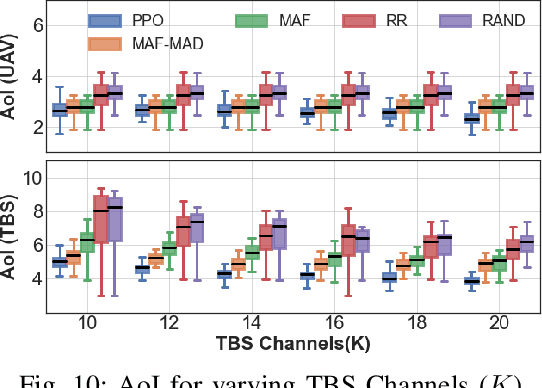
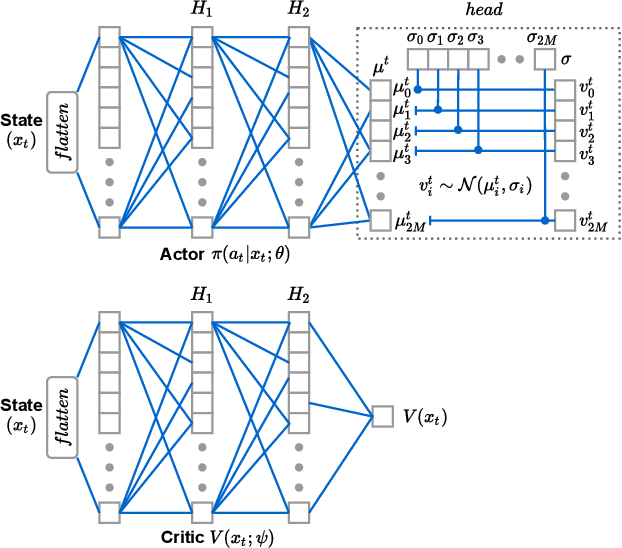
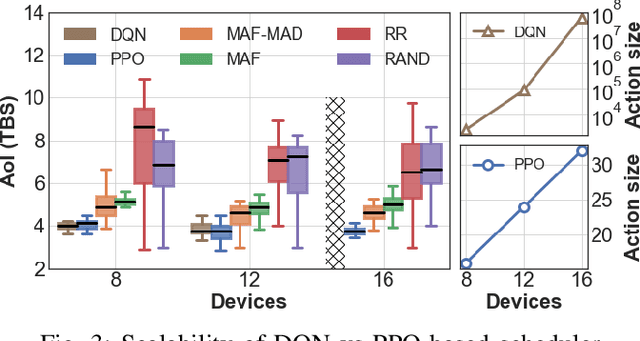
Unmanned Aerial Vehicles (UAVs) are used as aerial base-stations to relay time-sensitive packets from IoT devices to the nearby terrestrial base-station (TBS). Scheduling of packets in such UAV-relayed IoT-networks to ensure fresh (or up-to-date) IoT devices' packets at the TBS is a challenging problem as it involves two simultaneous steps of (i) sampling of packets generated at IoT devices by the UAVs [hop-1] and (ii) updating of sampled packets from UAVs to the TBS [hop-2]. To address this, we propose Age-of-Information (AoI) scheduling algorithms for two-hop UAV-relayed IoT-networks. First, we propose a low-complexity AoI scheduler, termed, MAF-MAD that employs Maximum AoI First (MAF) policy for sampling of IoT devices at UAV (hop-1) and Maximum AoI Difference (MAD) policy for updating sampled packets from UAV to the TBS (hop-2). We prove that MAF-MAD is the optimal AoI scheduler under ideal conditions (lossless wireless channels and generate-at-will traffic-generation at IoT devices). On the contrary, for general conditions (lossy channel conditions and varying periodic traffic-generation at IoT devices), a deep reinforcement learning algorithm, namely, Proximal Policy Optimization (PPO)-based scheduler is proposed. Simulation results show that the proposed PPO-based scheduler outperforms other schedulers like MAF-MAD, MAF, and round-robin in all considered general scenarios.
MDT-Net: Multi-domain Transfer by Perceptual Supervision for Unpaired Images in OCT Scan
Mar 12, 2022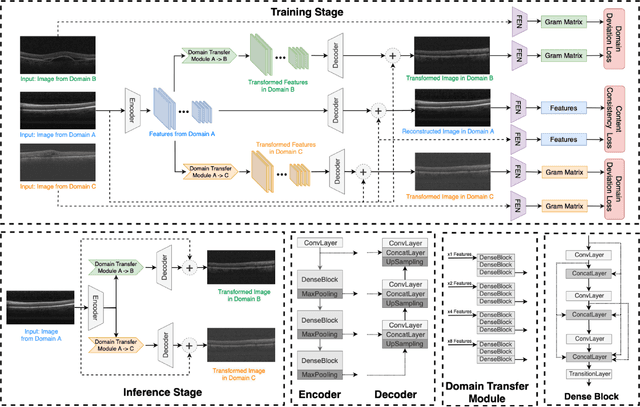
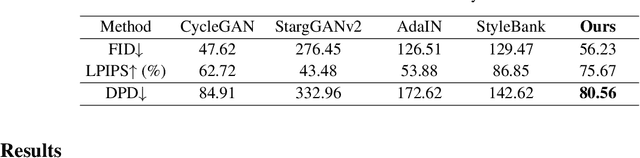
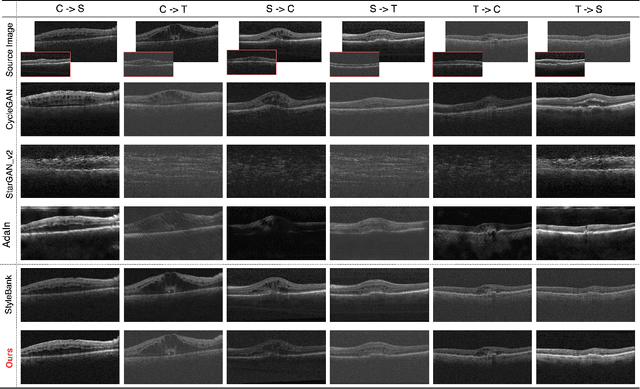
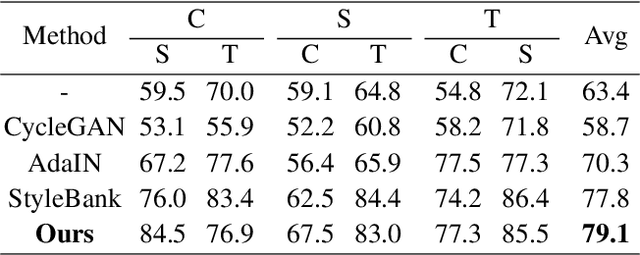
Deep learning models tend to underperform in the presence of domain shifts. Domain transfer has recently emerged as a promising approach wherein images exhibiting a domain shift are transformed into other domains for augmentation or adaptation. However, with the absence of paired and annotated images, most domain transfer methods mainly rely on adversarial networks and weak cycle consistency, which could result in incomplete domain transfer or poor adherence to the original image content. In this paper, we introduce MDT-Net to address the limitations above through a multi-domain transfer model based on perceptual supervision. Specifically, our model consists of an encoder-decoder network, which aims to preserve anatomical structures, and multiple domain-specific transfer modules, which guide the domain transition through feature transformation. During the inference, MDT-Net can directly transfer images from the source domain to multiple target domains at one time without any reference image. To demonstrate the performance of MDT-Net, we evaluate it on RETOUCH dataset, comprising OCT scans from three different scanner devices (domains), for multi-domain transfer. We also take the transformed results as additional training images for fluid segmentation in OCT scans in the tasks of domain adaptation and data augmentation. Experimental results show that MDT-Net can outperform other domain transfer models qualitatively and quantitatively. Furthermore, the significant improvement in dice scores over multiple segmentation models also demonstrates the effectiveness and efficiency of our proposed method.
ECG beats classification via online sparse dictionary and time pyramid matching
Aug 15, 2020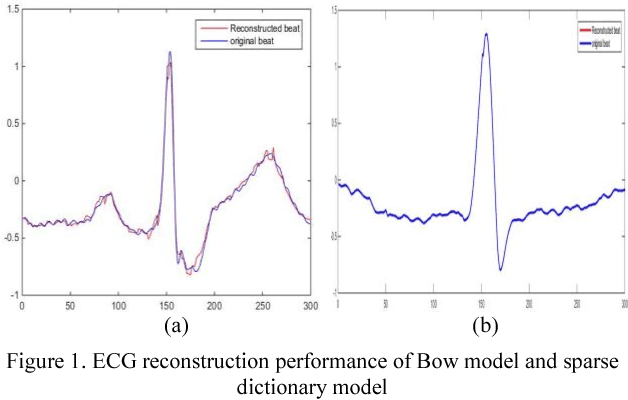
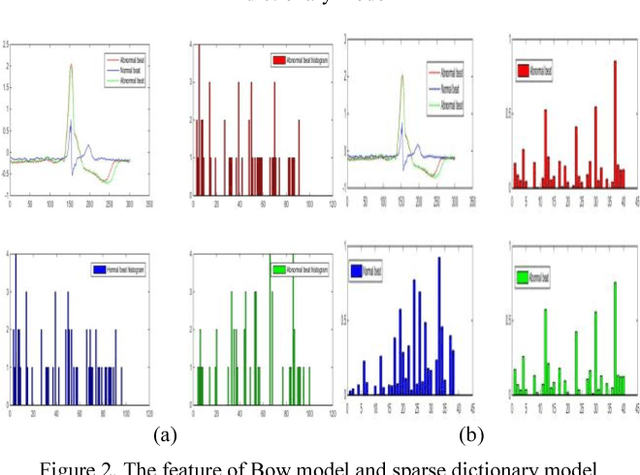
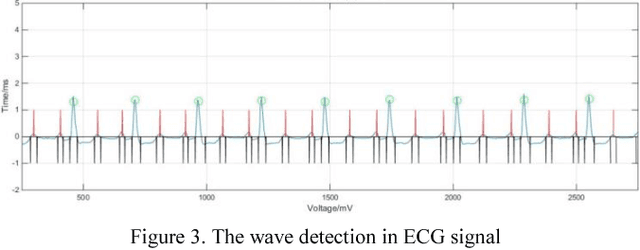
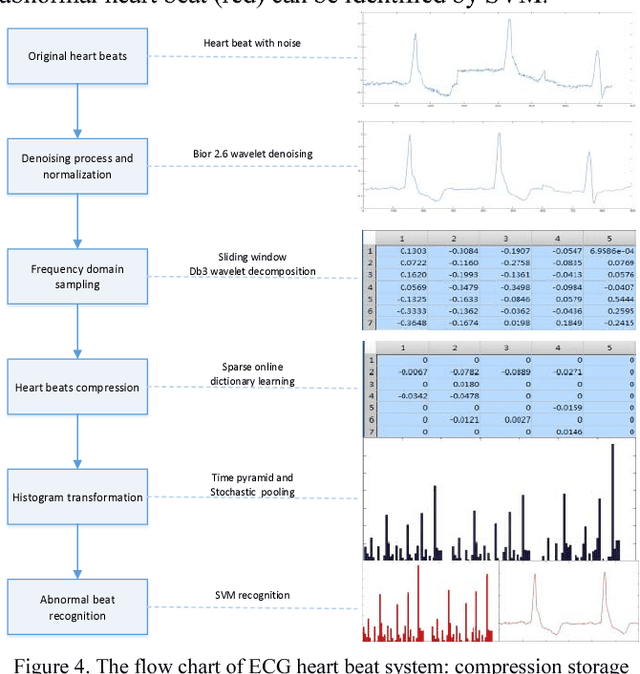
Recently, the Bag-Of-Word (BOW) algorithm provides efficient features and promotes the accuracy of the ECG classification system. However, BOW algorithm has two shortcomings: (1). it has large quantization errors and poor reconstruction performance; (2). it loses heart beat's time information, and may provide confusing features for different kinds of heart beats. Furthermore, ECG classification system can be used for long time monitoring and analysis of cardiovascular patients, while a huge amount of data will be produced, so we urgently need an efficient compression algorithm. In view of the above problems, we use the wavelet feature to construct the sparse dictionary, which lower the quantization error to a minimum. In order to reduce the complexity of our algorithm and adapt to large-scale heart beats operation, we combine the Online Dictionary Learning with Feature-sign algorithm to update the dictionary and coefficients. Coefficients matrix is used to represent ECG beats, which greatly reduces the memory consumption, and solve the problem of quantitative error simultaneously. Finally, we construct the pyramid to match coefficients of each ECG beat. Thus, we obtain the features that contain the beat time information by time stochastic pooling. It is efficient to solve the problem of losing time information. The experimental results show that: on the one hand, the proposed algorithm has advantages of high reconstruction performance for BOW, this storage method is high fidelity and low memory consumption; on the other hand, our algorithm yields highest accuracy in ECG beats classification; so this method is more suitable for large-scale heart beats data storage and classification.
* 7 pages,5 figure
Uni4Eye: Unified 2D and 3D Self-supervised Pre-training via Masked Image Modeling Transformer for Ophthalmic Image Classification
Mar 12, 2022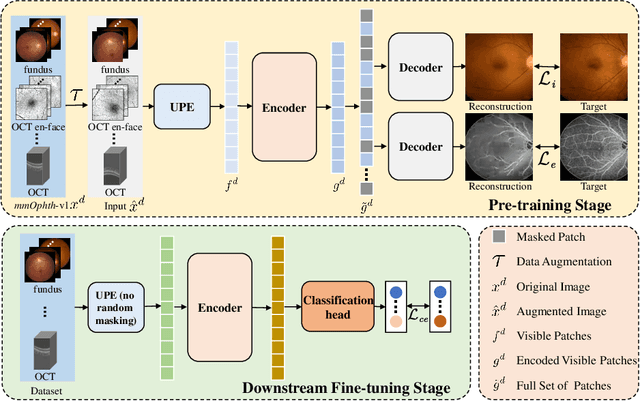
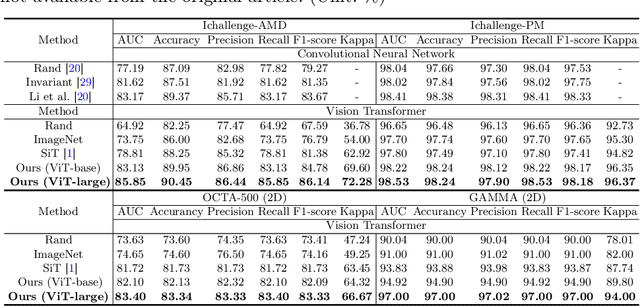
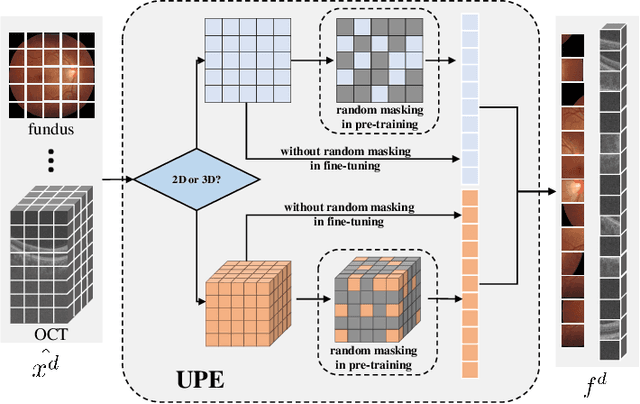
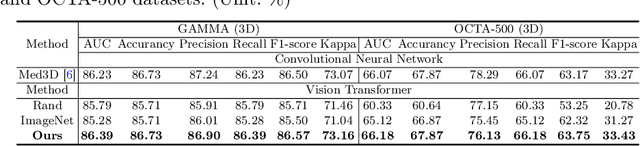
A large-scale labeled dataset is a key factor for the success of supervised deep learning in computer vision. However, a limited number of annotated data is very common, especially in ophthalmic image analysis, since manual annotation is time-consuming and labor-intensive. Self-supervised learning (SSL) methods bring huge opportunities for better utilizing unlabeled data, as they do not need massive annotations. With an attempt to use as many as possible unlabeled ophthalmic images, it is necessary to break the dimension barrier, simultaneously making use of both 2D and 3D images. In this paper, we propose a universal self-supervised Transformer framework, named Uni4Eye, to discover the inherent image property and capture domain-specific feature embedding in ophthalmic images. Uni4Eye can serve as a global feature extractor, which builds its basis on a Masked Image Modeling task with a Vision Transformer (ViT) architecture. We employ a Unified Patch Embedding module to replace the origin patch embedding module in ViT for jointly processing both 2D and 3D input images. Besides, we design a dual-branch multitask decoder module to simultaneously perform two reconstruction tasks on the input image and its gradient map, delivering discriminative representations for better convergence. We evaluate the performance of our pre-trained Uni4Eye encoder by fine-tuning it on six downstream ophthalmic image classification tasks. The superiority of Uni4Eye is successfully established through comparisons to other state-of-the-art SSL pre-training methods.
PageRank Algorithm using Eigenvector Centrality -- New Approach
Jan 18, 2022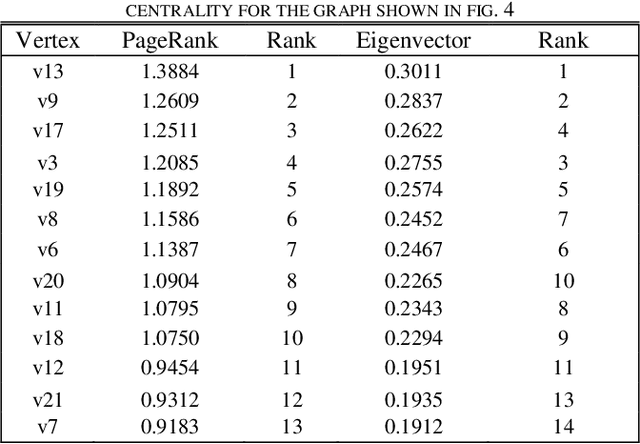
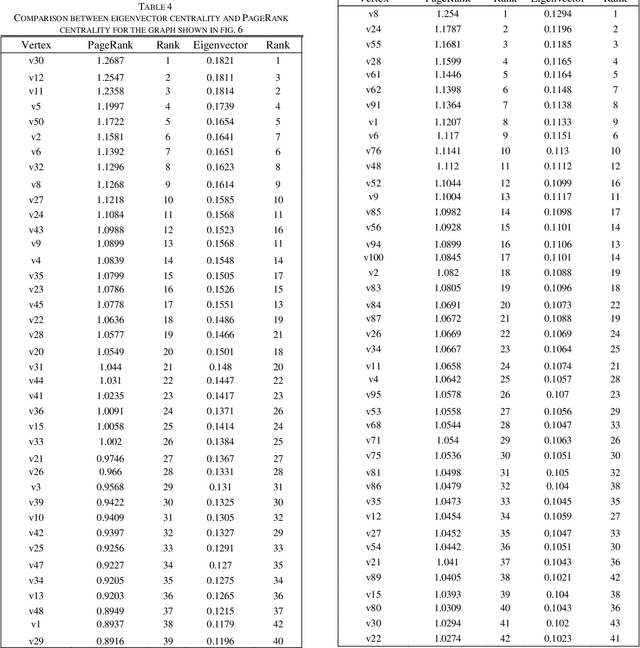
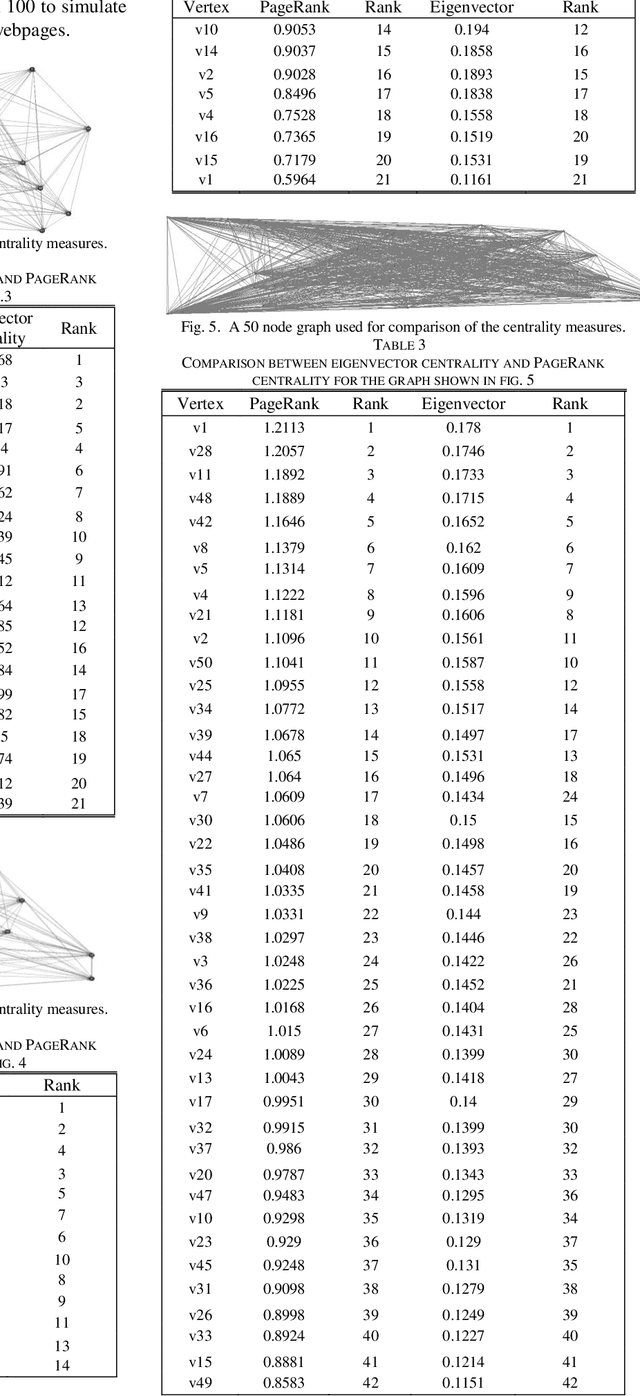
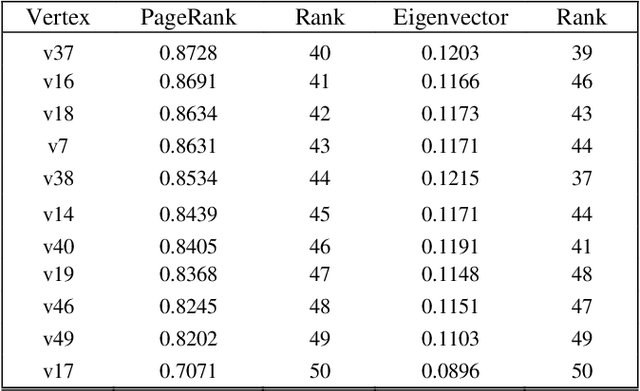
The purpose of the research is to find a centrality measure that can be used in place of PageRank and to find out the conditions where we can use it in place of PageRank. After analysis and comparison of graphs with a large number of nodes using Spearman's Rank Coefficient Correlation, the conclusion is evident that Eigenvector can be safely used in place of PageRank in directed networks to improve the performance in terms of the time complexity.
Multi-Agent Broad Reinforcement Learning for Intelligent Traffic Light Control
Mar 08, 2022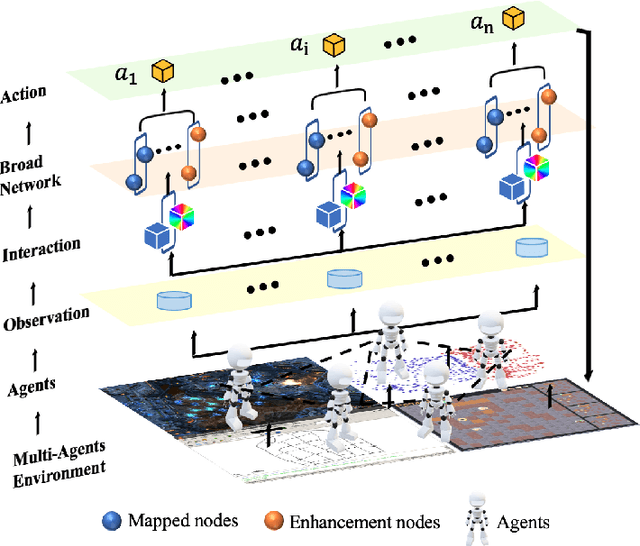
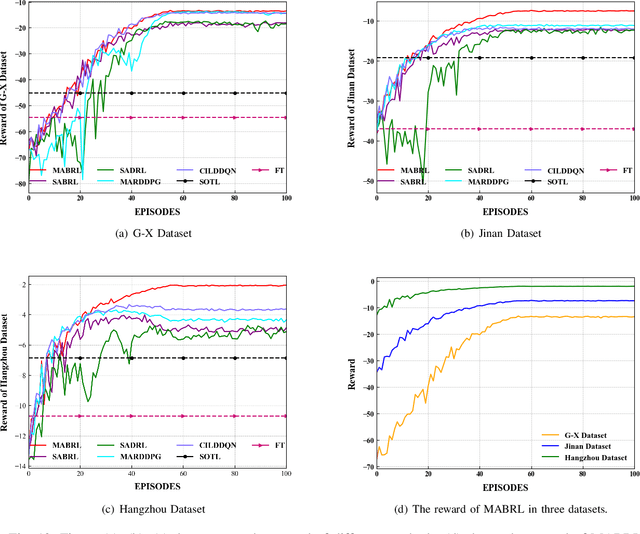
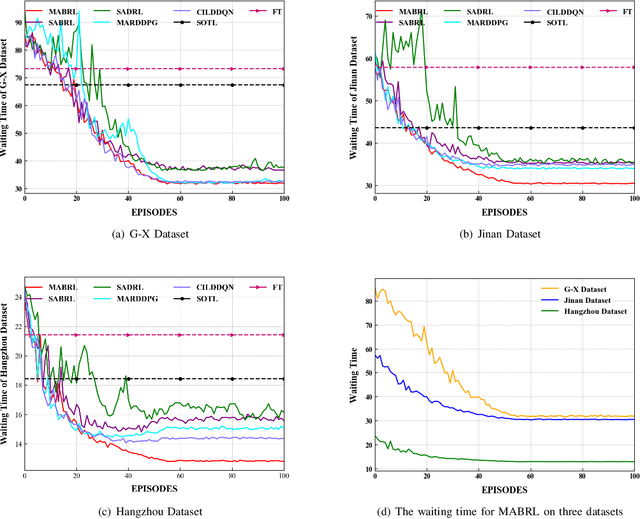
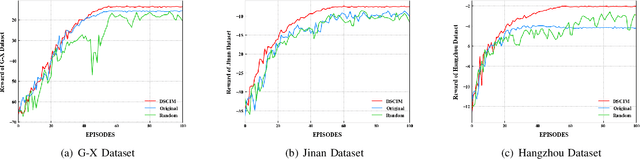
Intelligent Traffic Light Control System (ITLCS) is a typical Multi-Agent System (MAS), which comprises multiple roads and traffic lights.Constructing a model of MAS for ITLCS is the basis to alleviate traffic congestion. Existing approaches of MAS are largely based on Multi-Agent Deep Reinforcement Learning (MADRL). Although the Deep Neural Network (DNN) of MABRL is effective, the training time is long, and the parameters are difficult to trace. Recently, Broad Learning Systems (BLS) provided a selective way for learning in the deep neural networks by a flat network. Moreover, Broad Reinforcement Learning (BRL) extends BLS in Single Agent Deep Reinforcement Learning (SADRL) problem with promising results. However, BRL does not focus on the intricate structures and interaction of agents. Motivated by the feature of MADRL and the issue of BRL, we propose a Multi-Agent Broad Reinforcement Learning (MABRL) framework to explore the function of BLS in MAS. Firstly, unlike most existing MADRL approaches, which use a series of deep neural networks structures, we model each agent with broad networks. Then, we introduce a dynamic self-cycling interaction mechanism to confirm the "3W" information: When to interact, Which agents need to consider, What information to transmit. Finally, we do the experiments based on the intelligent traffic light control scenario. We compare the MABRL approach with six different approaches, and experimental results on three datasets verify the effectiveness of MABRL.