 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Improved Real-Time Face Recognition System at Low Resolution Based on Local Binary Pattern Histogram Algorithm and CLAHE
Apr 15, 2021
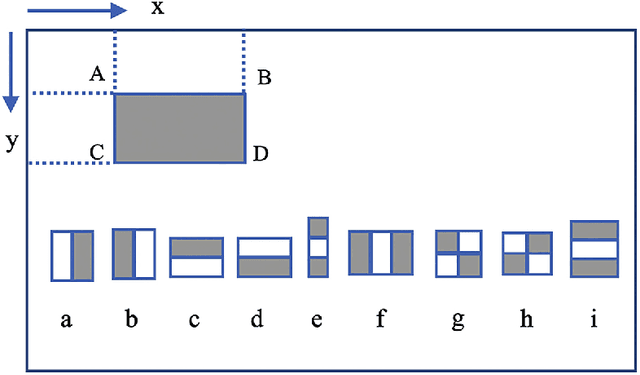

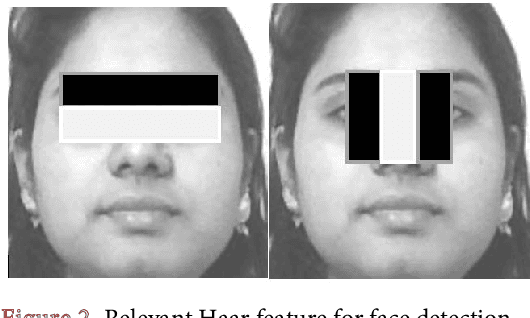
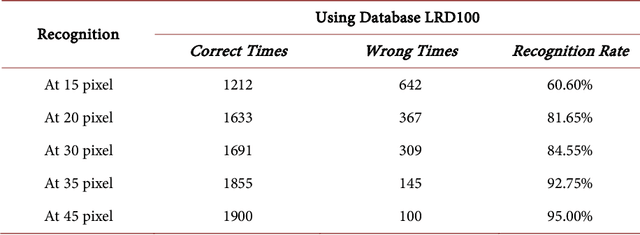
This research presents an improved real-time face recognition system at a low resolution of 15 pixels with pose and emotion and resolution variations. We have designed our datasets named LRD200 and LRD100, which have been used for training and classification. The face detection part uses the Viola-Jones algorithm, and the face recognition part receives the face image from the face detection part to process it using the Local Binary Pattern Histogram (LBPH) algorithm with preprocessing using contrast limited adaptive histogram equalization (CLAHE) and face alignment. The face database in this system can be updated via our custom-built standalone android app and automatic restarting of the training and recognition process with an updated database. Using our proposed algorithm, a real-time face recognition accuracy of 78.40% at 15 px and 98.05% at 45 px have been achieved using the LRD200 database containing 200 images per person. With 100 images per person in the database (LRD100) the achieved accuracies are 60.60% at 15 px and 95% at 45 px respectively. A facial deflection of about 30 degrees on either side from the front face showed an average face recognition precision of 72.25% - 81.85%. This face recognition system can be employed for law enforcement purposes, where the surveillance camera captures a low-resolution image because of the distance of a person from the camera. It can also be used as a surveillance system in airports, bus stations, etc., to reduce the risk of possible criminal threats.
* Journal, Optics and Photonics Journal
6D Pose Estimation with Combined Deep Learning and 3D Vision Techniques for a Fast and Accurate Object Grasping
Nov 11, 2021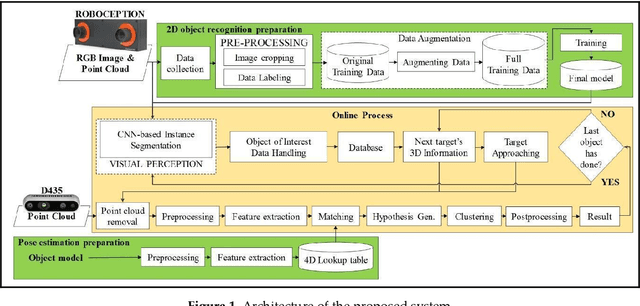
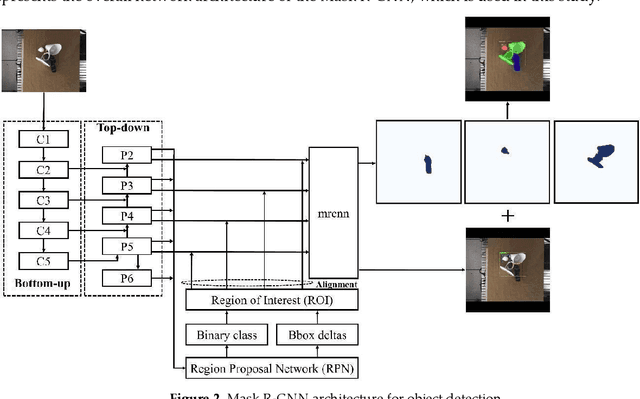
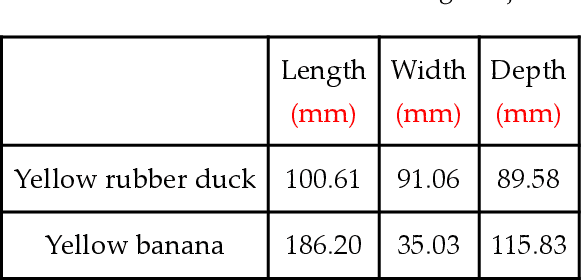
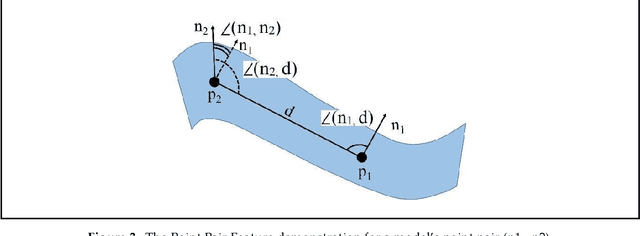
Real-time robotic grasping, supporting a subsequent precise object-in-hand operation task, is a priority target towards highly advanced autonomous systems. However, such an algorithm which can perform sufficiently-accurate grasping with time efficiency is yet to be found. This paper proposes a novel method with a 2-stage approach that combines a fast 2D object recognition using a deep neural network and a subsequent accurate and fast 6D pose estimation based on Point Pair Feature framework to form a real-time 3D object recognition and grasping solution capable of multi-object class scenes. The proposed solution has a potential to perform robustly on real-time applications, requiring both efficiency and accuracy. In order to validate our method, we conducted extensive and thorough experiments involving laborious preparation of our own dataset. The experiment results show that the proposed method scores 97.37% accuracy in 5cm5deg metric and 99.37% in Average Distance metric. Experiment results have shown an overall 62% relative improvement (5cm5deg metric) and 52.48% (Average Distance metric) by using the proposed method. Moreover, the pose estimation execution also showed an average improvement of 47.6% in running time. Finally, to illustrate the overall efficiency of the system in real-time operations, a pick-and-place robotic experiment is conducted and has shown a convincing success rate with 90% of accuracy. This experiment video is available at https://sites.google.com/view/dl-ppf6dpose/.
Increasing loudness in audio signals: a perceptually motivated approach to preserve audio quality
Feb 16, 2022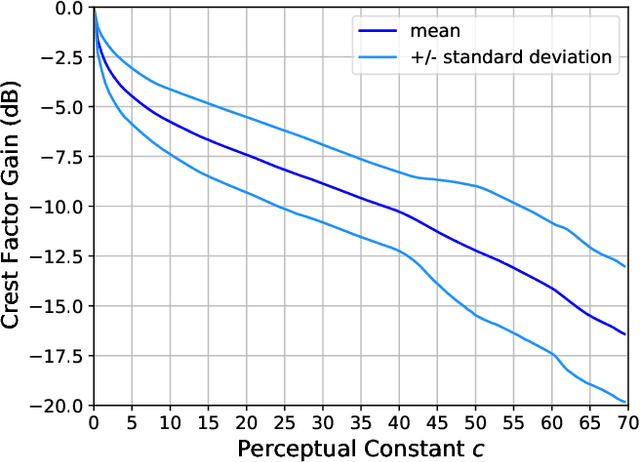
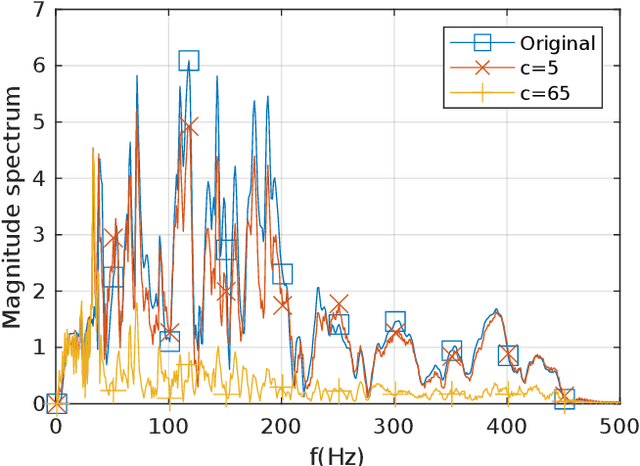
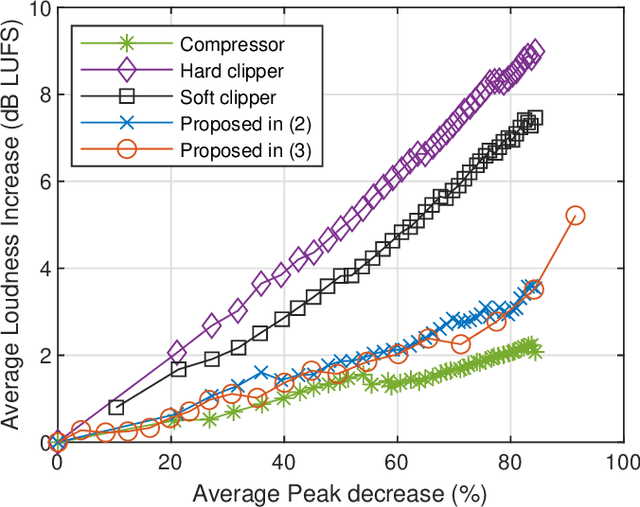
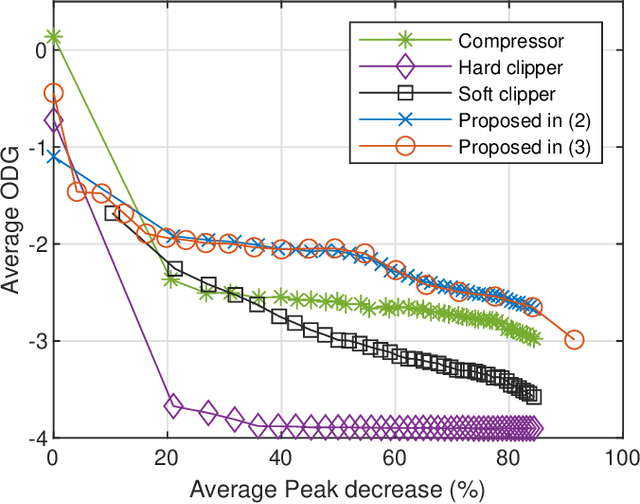
We present a method to maintain the subjective perception of volume of audio signals and, at the same time, reduce their absolute peak value. We focus on achieving this without compromising the perceived audio quality. This is specially useful, for example, to maximize the perceived reproduction level of loudspeakers where simply amplifying the signal amplitude, and hence their peak value, is limited due to already constrained physical designs. In particular, we minimize the absolute peak value subject to a constraint based on auditory masking. This limits the perceptual difference between the original and the modified signals. Moreover, this constraint can be tuned and allows to control the resulting audio quality. We show results comparing loudness and audio quality as a function of peak reduction. These results suggest that our method presents the best trade-off between loudness and audio quality when compared against classical methods based on compression and clipping.
student dangerous behavior detection in school
Feb 19, 2022
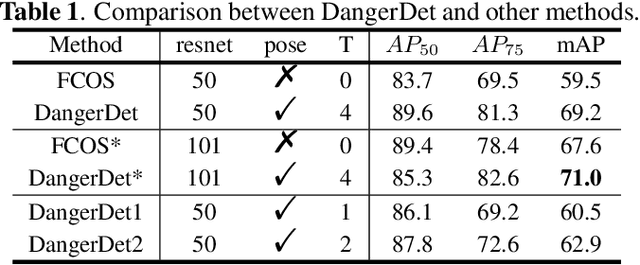
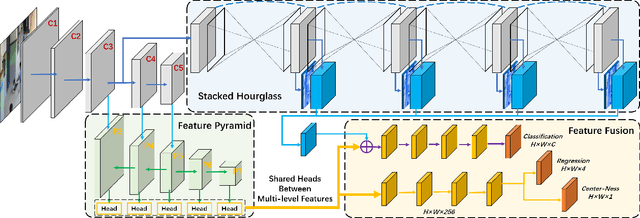
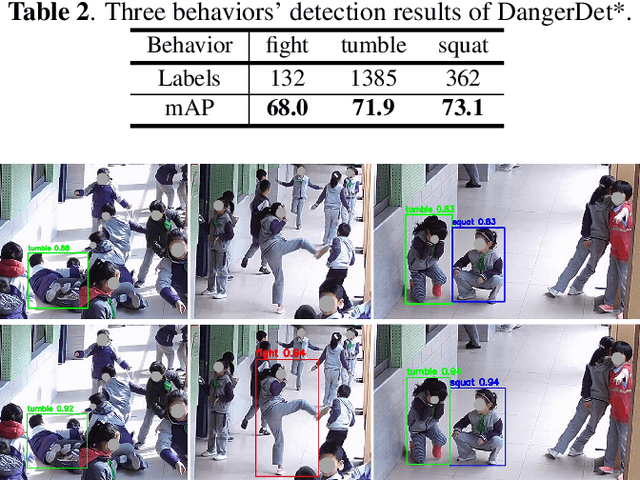
Video surveillance systems have been installed to ensure the student safety in schools. However, discovering dangerous behaviors, such as fighting and falling down, usually depends on untimely human observations. In this paper, we focus on detecting dangerous behaviors of students automatically, which faces numerous challenges, such as insufficient datasets, confusing postures, keyframes detection and prompt response. To address these challenges, we first build a danger behavior dataset with locations and labels from surveillance videos, and transform action recognition of long videos to an object detection task that avoids keyframes detection. Then, we propose a novel end-to-end dangerous behavior detection method, named DangerDet, that combines multi-scale body features and keypoints-based pose features. We could improve the accuracy of behavior classification due to the highly correlation between pose and behavior. On our dataset, DangerDet achieves 71.0\% mAP with about 11 FPS. It keeps a better balance between the accuracy and time cost.
Evaluating data augmentation for financial time series classification
Oct 28, 2020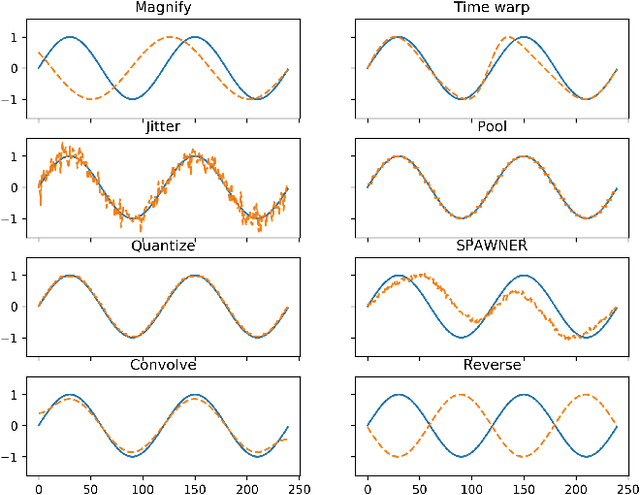
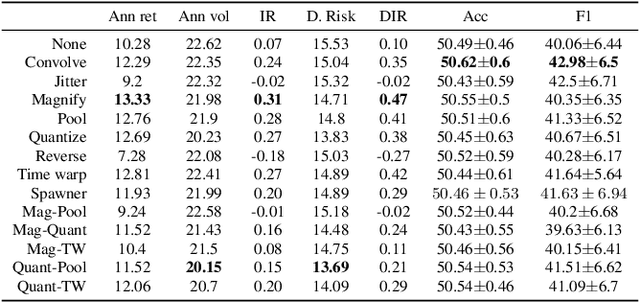
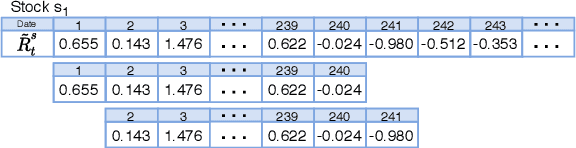
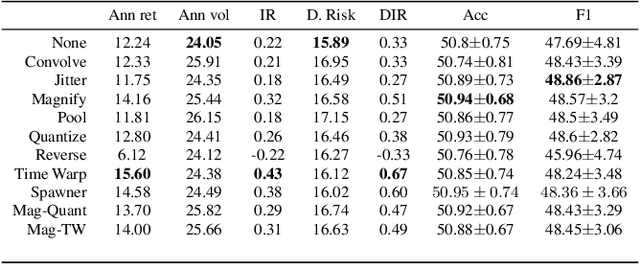
Data augmentation methods in combination with deep neural networks have been used extensively in computer vision on classification tasks, achieving great success; however, their use in time series classification is still at an early stage. This is even more so in the field of financial prediction, where data tends to be small, noisy and non-stationary. In this paper we evaluate several augmentation methods applied to stocks datasets using two state-of-the-art deep learning models. The results show that several augmentation methods significantly improve financial performance when used in combination with a trading strategy. For a relatively small dataset ($\approx30K$ samples), augmentation methods achieve up to $400\%$ improvement in risk adjusted return performance; for a larger stock dataset ($\approx300K$ samples), results show up to $40\%$ improvement.
ABCNet v2: Adaptive Bezier-Curve Network for Real-time End-to-end Text Spotting
May 08, 2021
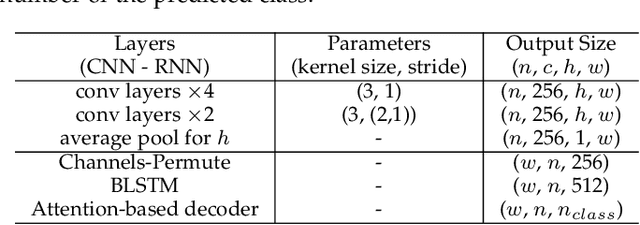


End-to-end text-spotting, which aims to integrate detection and recognition in a unified framework, has attracted increasing attention due to its simplicity of the two complimentary tasks. It remains an open problem especially when processing arbitrarily-shaped text instances. Previous methods can be roughly categorized into two groups: character-based and segmentation-based, which often require character-level annotations and/or complex post-processing due to the unstructured output. Here, we tackle end-to-end text spotting by presenting Adaptive Bezier Curve Network v2 (ABCNet v2). Our main contributions are four-fold: 1) For the first time, we adaptively fit arbitrarily-shaped text by a parameterized Bezier curve, which, compared with segmentation-based methods, can not only provide structured output but also controllable representation. 2) We design a novel BezierAlign layer for extracting accurate convolution features of a text instance of arbitrary shapes, significantly improving the precision of recognition over previous methods. 3) Different from previous methods, which often suffer from complex post-processing and sensitive hyper-parameters, our ABCNet v2 maintains a simple pipeline with the only post-processing non-maximum suppression (NMS). 4) As the performance of text recognition closely depends on feature alignment, ABCNet v2 further adopts a simple yet effective coordinate convolution to encode the position of the convolutional filters, which leads to a considerable improvement with negligible computation overhead. Comprehensive experiments conducted on various bilingual (English and Chinese) benchmark datasets demonstrate that ABCNet v2 can achieve state-of-the-art performance while maintaining very high efficiency.
Spirit Distillation: Precise Real-time Semantic Segmentation of Road Scenes with Insufficient Data
Apr 17, 2021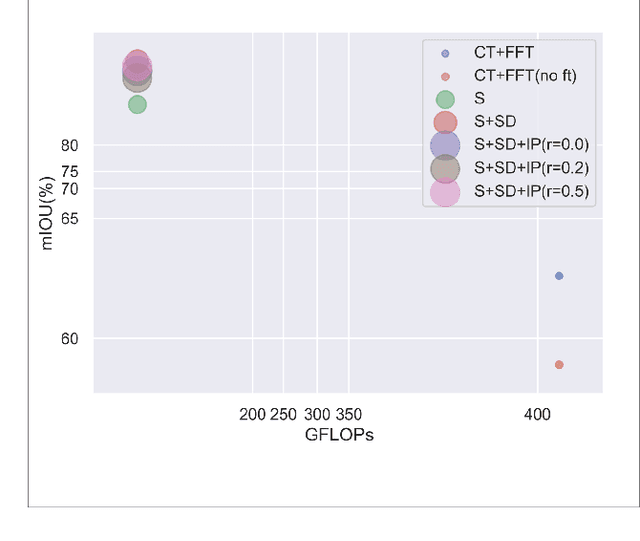
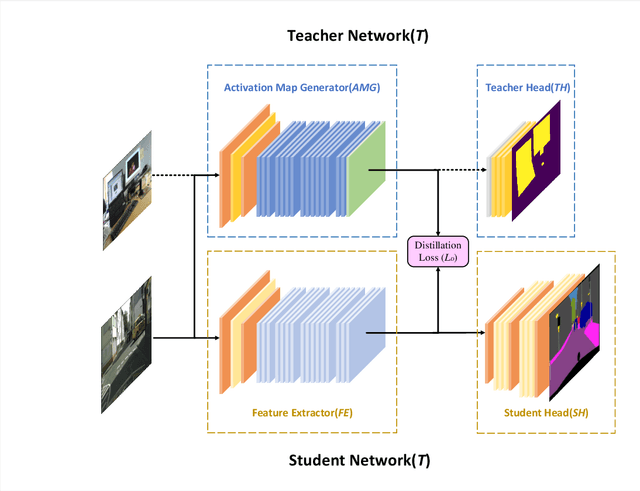
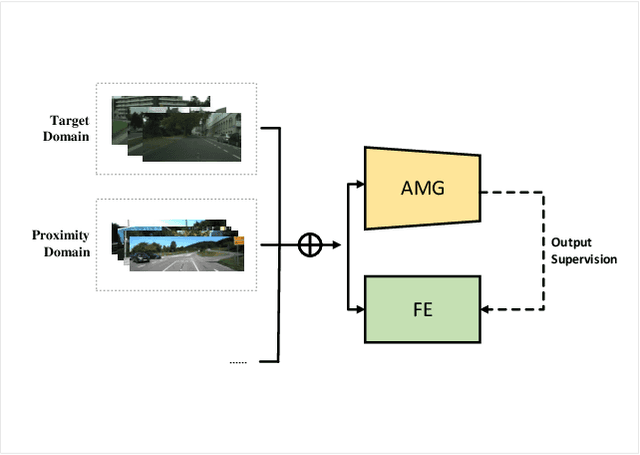
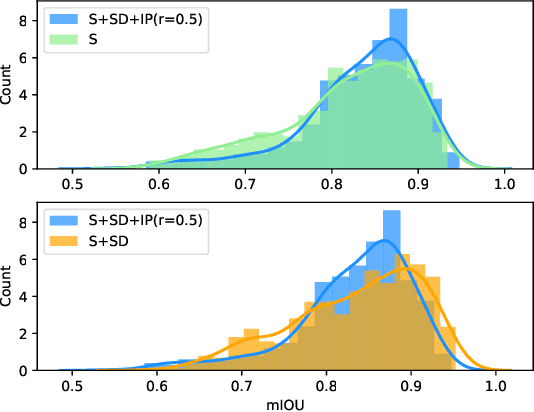
Semantic segmentation of road scenes is one of the key technologies for realizing autonomous driving scene perception, and the effectiveness of deep Convolutional Neural Networks(CNNs) for this task has been demonstrated. State-of-art CNNs for semantic segmentation suffer from excessive computations as well as large-scale training data requirement. Inspired by the ideas of Fine-tuning-based Transfer Learning (FTT) and feature-based knowledge distillation, we propose a new knowledge distillation method for cross-domain knowledge transference and efficient data-insufficient network training, named Spirit Distillation(SD), which allow the student network to mimic the teacher network to extract general features, so that a compact and accurate student network can be trained for real-time semantic segmentation of road scenes. Then, in order to further alleviate the trouble of insufficient data and improve the robustness of the student, an Enhanced Spirit Distillation (ESD) method is proposed, which commits to exploit a more comprehensive general features extraction capability by considering images from both the target and the proximity domains as input. To our knowledge, this paper is a pioneering work on the application of knowledge distillation to few-shot learning. Persuasive experiments conducted on Cityscapes semantic segmentation with the prior knowledge transferred from COCO2017 and KITTI demonstrate that our methods can train a better student network (mIOU and high-precision accuracy boost by 1.4% and 8.2% respectively, with 78.2% segmentation variance) with only 41.8% FLOPs (see Fig. 1).
Bi-Manual Manipulation and Attachment via Sim-to-Real Reinforcement Learning
Mar 15, 2022
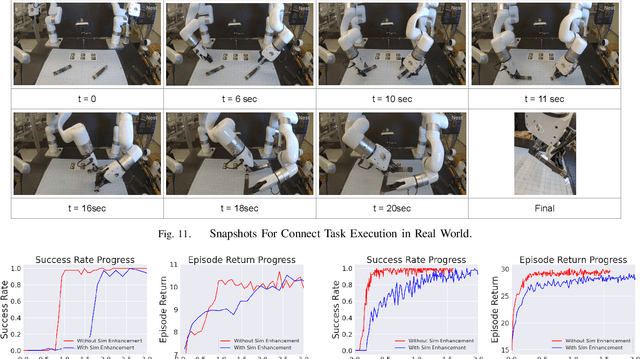
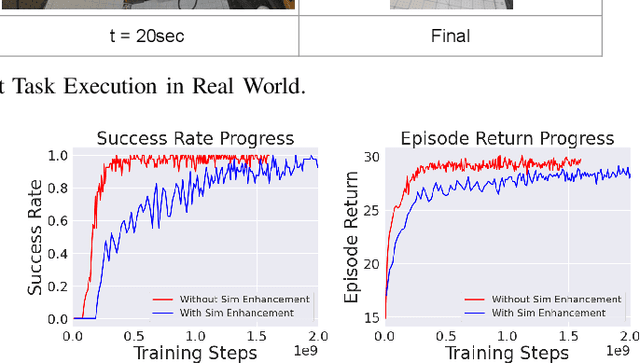
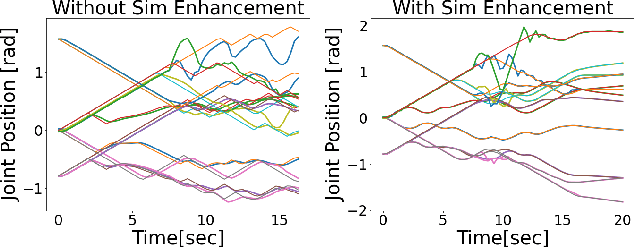
Most successes in robotic manipulation have been restricted to single-arm robots, which limits the range of solvable tasks to pick-and-place, insertion, and objects rearrangement. In contrast, dual and multi arm robot platforms unlock a rich diversity of problems that can be tackled, such as laundry folding and executing cooking skills. However, developing controllers for multi-arm robots is complexified by a number of unique challenges, such as the need for coordinated bimanual behaviors, and collision avoidance amongst robots. Given these challenges, in this work we study how to solve bi-manual tasks using reinforcement learning (RL) trained in simulation, such that the resulting policies can be executed on real robotic platforms. Our RL approach results in significant simplifications due to using real-time (4Hz) joint-space control and directly passing unfiltered observations to neural networks policies. We also extensively discuss modifications to our simulated environment which lead to effective training of RL policies. In addition to designing control algorithms, a key challenge is how to design fair evaluation tasks for bi-manual robots that stress bimanual coordination, while removing orthogonal complicating factors such as high-level perception. In this work, we design a Connect Task, where the aim is for two robot arms to pick up and attach two blocks with magnetic connection points. We validate our approach with two xArm6 robots and 3D printed blocks with magnetic attachments, and find that our system has 100% success rate at picking up blocks, and 65% success rate at the Connect Task.
Optimal-Horizon Model-Predictive Control with Differential Dynamic Programming
Nov 17, 2021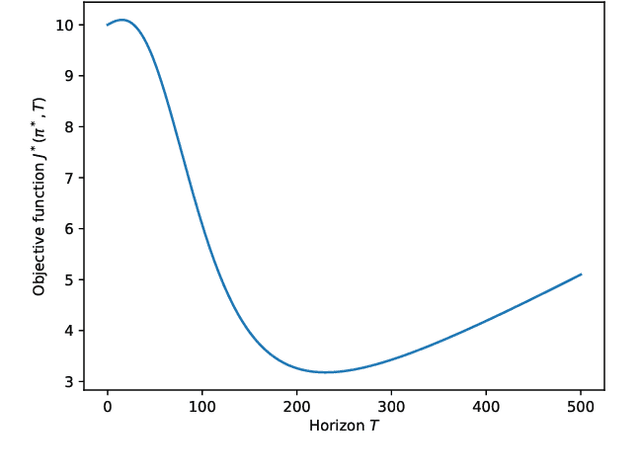
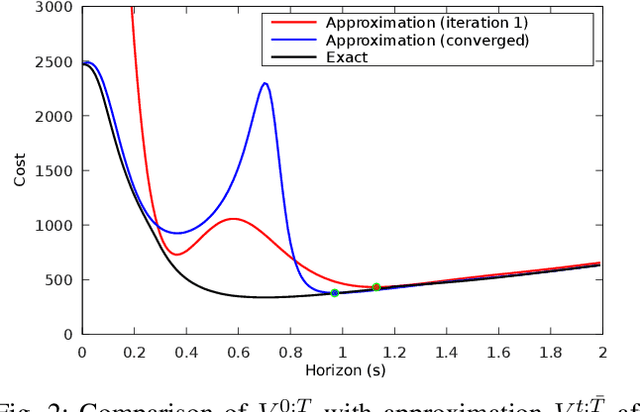

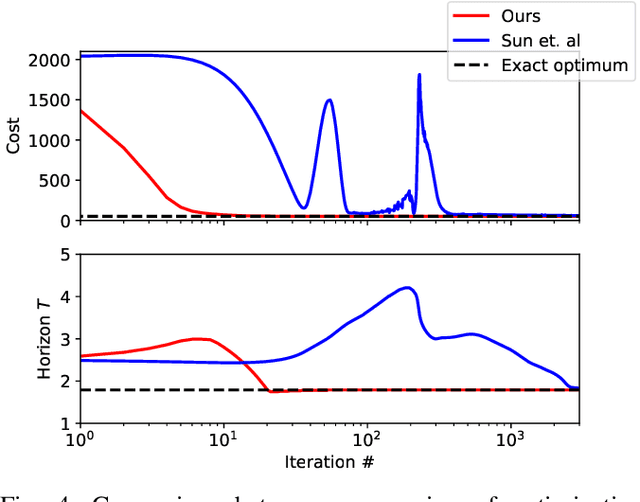
We present an algorithm, based on the Differential Dynamic Programming framework, to handle trajectory optimization problems in which the horizon is determined online rather than fixed a priori. This algorithm exhibits exact one-step convergence for linear, quadratic, time-invariant problems and is fast enough for real-time nonlinear model-predictive control. We show derivations for the nonlinear algorithm in the discrete-time case, and apply this algorithm to a variety of nonlinear problems. Finally, we show the efficacy of the optimal-horizon model-predictive control scheme compared to a standard MPC controller, on an obstacle-avoidance problem with planar robots.
SLRNet: Semi-Supervised Semantic Segmentation Via Label Reuse for Human Decomposition Images
Feb 24, 2022



Semantic segmentation is a challenging computer vision task demanding a significant amount of pixel-level annotated data. Producing such data is a time-consuming and costly process, especially for domains with a scarcity of experts, such as medicine or forensic anthropology. While numerous semi-supervised approaches have been developed to make the most from the limited labeled data and ample amount of unlabeled data, domain-specific real-world datasets often have characteristics that both reduce the effectiveness of off-the-shelf state-of-the-art methods and also provide opportunities to create new methods that exploit these characteristics. We propose and evaluate a semi-supervised method that reuses available labels for unlabeled images of a dataset by exploiting existing similarities, while dynamically weighting the impact of these reused labels in the training process. We evaluate our method on a large dataset of human decomposition images and find that our method, while conceptually simple, outperforms state-of-the-art consistency and pseudo-labeling-based methods for the segmentation of this dataset. This paper includes graphic content of human decomposition.