 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fast and explainable clustering based on sorting
Feb 03, 2022
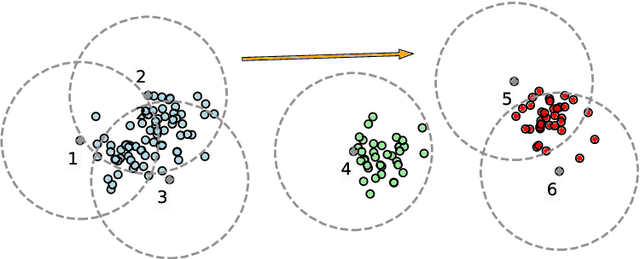
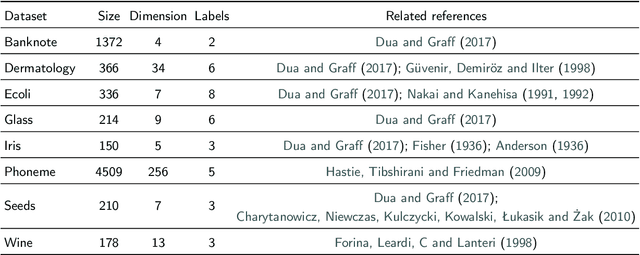
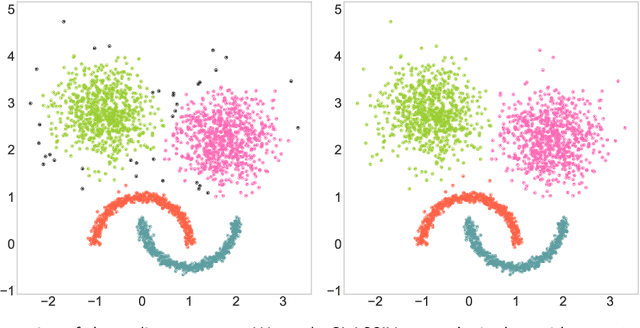
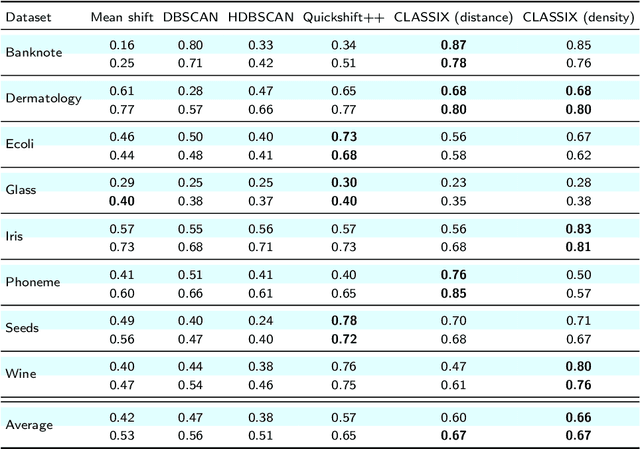
We introduce a fast and explainable clustering method called CLASSIX. It consists of two phases, namely a greedy aggregation phase of the sorted data into groups of nearby data points, followed by the merging of groups into clusters. The algorithm is controlled by two scalar parameters, namely a distance parameter for the aggregation and another parameter controlling the minimal cluster size. Extensive experiments are conducted to give a comprehensive evaluation of the clustering performance on synthetic and real-world datasets, with various cluster shapes and low to high feature dimensionality. Our experiments demonstrate that CLASSIX competes with state-of-the-art clustering algorithms. The algorithm has linear space complexity and achieves near linear time complexity on a wide range of problems. Its inherent simplicity allows for the generation of intuitive explanations of the computed clusters.
ECONet: Efficient Convolutional Online Likelihood Network for Scribble-based Interactive Segmentation
Jan 12, 2022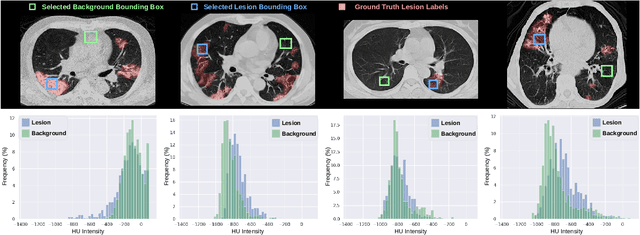

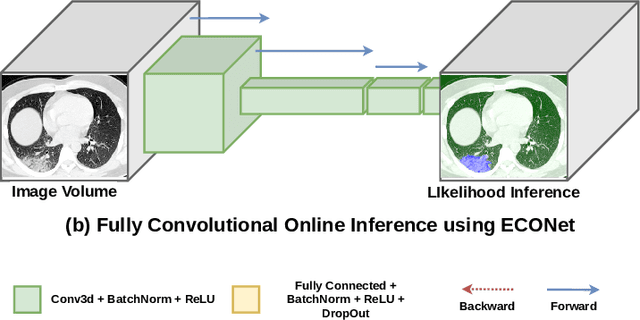
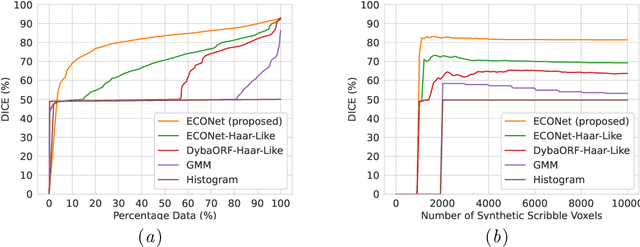
Automatic segmentation of lung lesions associated with COVID-19 in CT images requires large amount of annotated volumes. Annotations mandate expert knowledge and are time-intensive to obtain through fully manual segmentation methods. Additionally, lung lesions have large inter-patient variations, with some pathologies having similar visual appearance as healthy lung tissues. This poses a challenge when applying existing semi-automatic interactive segmentation techniques for data labelling. To address these challenges, we propose an efficient convolutional neural networks (CNNs) that can be learned online while the annotator provides scribble-based interaction. To accelerate learning from only the samples labelled through user-interactions, a patch-based approach is used for training the network. Moreover, we use weighted cross-entropy loss to address the class imbalance that may result from user-interactions. During online inference, the learned network is applied to the whole input volume using a fully convolutional approach. We compare our proposed method with state-of-the-art and show that it outperforms existing methods on the task of annotating lung lesions associated with COVID-19, achieving 16% higher Dice score while reducing execution time by 3$\times$ and requiring 9000 lesser scribbles-based labelled voxels. Due to the online learning aspect, our approach adapts quickly to user input, resulting in high quality segmentation labels. Source code will be made available upon acceptance.
Heterogeneous Transformer: A Scale Adaptable Neural Network Architecture for Device Activity Detection
Dec 19, 2021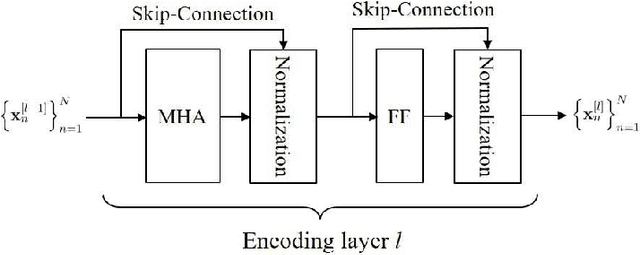
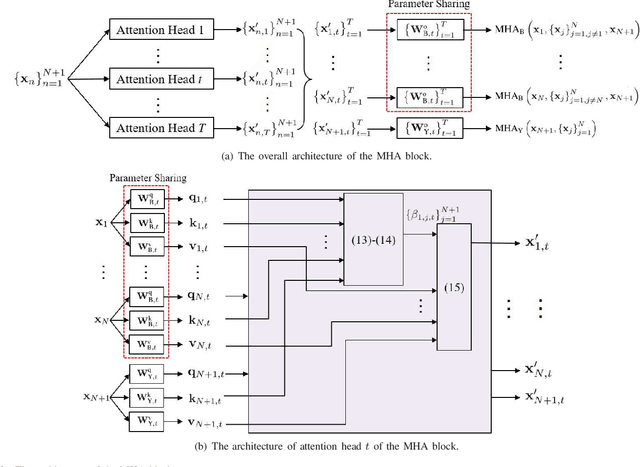
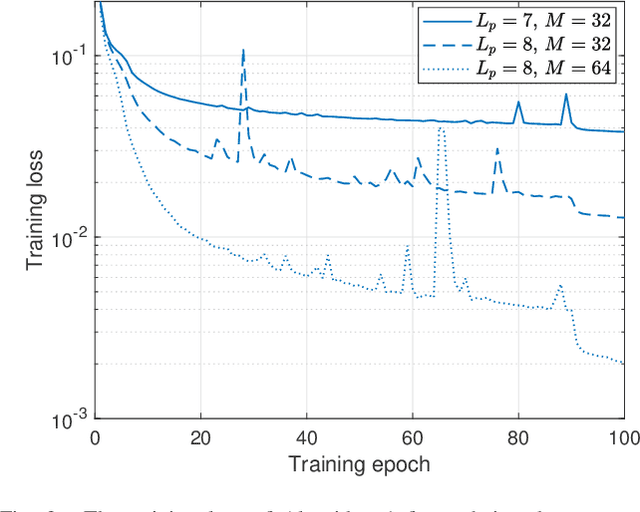
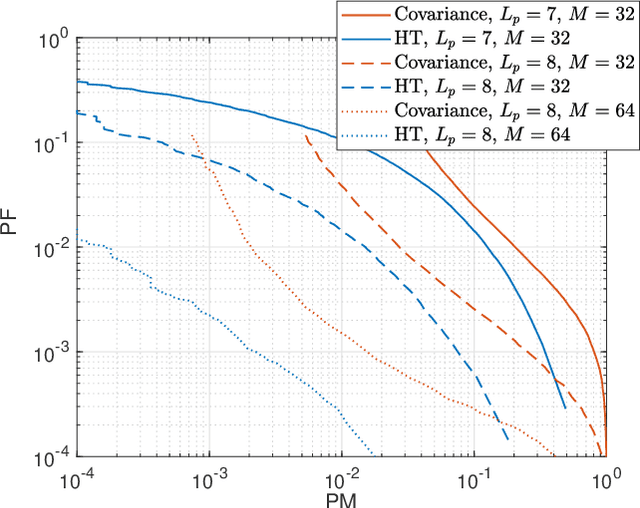
To support the modern machine-type communications, a crucial task during the random access phase is device activity detection, which is to detect the active devices from a large number of potential devices based on the received signal at the access point. By utilizing the statistical properties of the channel, state-of-the-art covariance based methods have been demonstrated to achieve better activity detection performance than compressed sensing based methods. However, covariance based methods require to solve a high dimensional nonconvex optimization problem by updating the estimate of the activity status of each device sequentially. Since the number of updates is proportional to the device number, the computational complexity and delay make the iterative updates difficult for real-time implementation especially when the device number scales up. Inspired by the success of deep learning for real-time inference, this paper proposes a learning based method with a customized heterogeneous transformer architecture for device activity detection. By adopting an attention mechanism in the architecture design, the proposed method is able to extract the relevance between device pilots and received signal, is permutation equivariant with respect to devices, and is scale adaptable to different numbers of devices. Simulation results demonstrate that the proposed method achieves better activity detection performance with much shorter computation time than state-of-the-art covariance approach, and generalizes well to different numbers of devices, BS-antennas, and different signal-to-noise ratios.
Self-Promoted Supervision for Few-Shot Transformer
Mar 14, 2022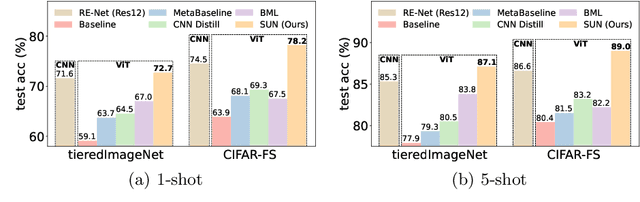
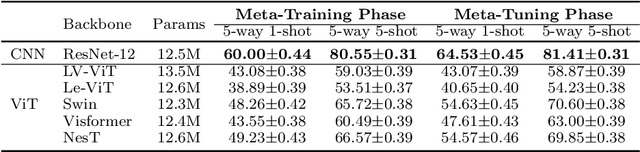
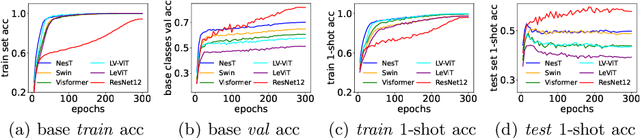
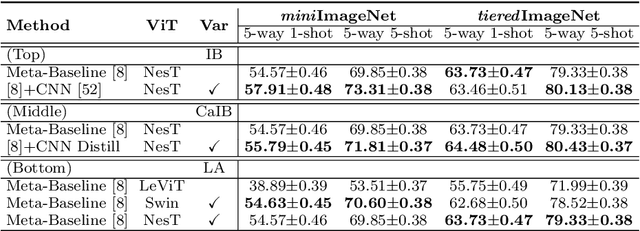
The few-shot learning ability of vision transformers (ViTs) is rarely investigated though heavily desired. In this work, we empirically find that with the same few-shot learning frameworks, e.g., Meta-Baseline, replacing the widely used CNN feature extractor with a ViT model often severely impairs few-shot classification performance. Moreover, our empirical study shows that in the absence of inductive bias, ViTs often learn the dependencies among input tokens slowly under few-shot learning regime where only a few labeled training data are available, which largely contributes to the above performance degradation. To alleviate this issue, for the first time, we propose a simple yet effective few-shot training framework for ViTs, namely Self-promoted sUpervisioN (SUN). Specifically, besides the conventional global supervision for global semantic learning, SUN further pretrains the ViT on the few-shot learning dataset and then uses it to generate individual location-specific supervision for guiding each patch token. This location-specific supervision tells the ViT which patch tokens are similar or dissimilar and thus accelerates token dependency learning. Moreover, it models the local semantics in each patch token to improve the object grounding and recognition capability which helps learn generalizable patterns. To improve the quality of location-specific supervision, we further propose two techniques:~1) background patch filtration to filtrate background patches out and assign them into an extra background class; and 2) spatial-consistent augmentation to introduce sufficient diversity for data augmentation while keeping the accuracy of the generated local supervisions. Experimental results show that SUN using ViTs significantly surpasses other few-shot learning frameworks with ViTs and is the first one that achieves higher performance than those CNN state-of-the-arts.
Efficiently Maintaining Next Basket Recommendations under Additions and Deletions of Baskets and Items
Jan 27, 2022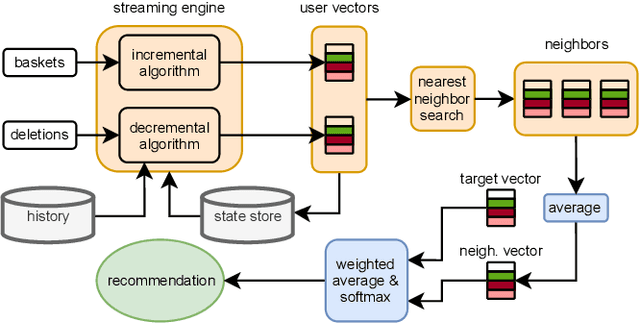

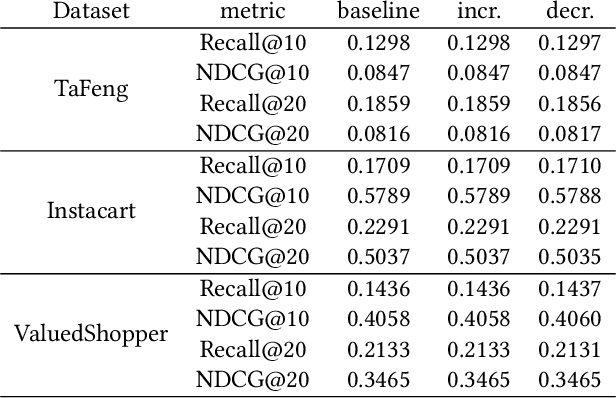
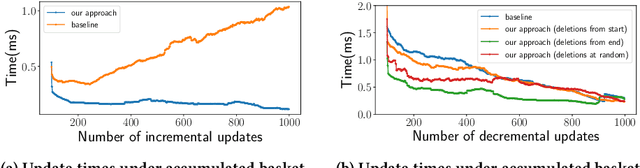
Recommender systems play an important role in helping people find information and make decisions in today's increasingly digitalized societies. However, the wide adoption of such machine learning applications also causes concerns in terms of data privacy. These concerns are addressed by the recent "General Data Protection Regulation" (GDPR) in Europe, which requires companies to delete personal user data upon request when users enforce their "right to be forgotten". Many researchers argue that this deletion obligation does not only apply to the data stored in primary data stores such as relational databases but also requires an update of machine learning models whose training set included the personal data to delete. We explore this direction in the context of a sequential recommendation task called Next Basket Recommendation (NBR), where the goal is to recommend a set of items based on a user's purchase history. We design efficient algorithms for incrementally and decrementally updating a state-of-the-art next basket recommendation model in response to additions and deletions of user baskets and items. Furthermore, we discuss an efficient, data-parallel implementation of our method in the Spark Structured Streaming system. We evaluate our implementation on a variety of real-world datasets, where we investigate the impact of our update techniques on several ranking metrics and measure the time to perform model updates. Our results show that our method provides constant update time efficiency with respect to an additional user basket in the incremental case, and linear efficiency in the decremental case where we delete existing baskets. With modest computational resources, we are able to update models with a latency of around 0.2~milliseconds regardless of the history size in the incremental case, and less than one millisecond in the decremental case.
Safe Reinforcement Learning for Legged Locomotion
Mar 05, 2022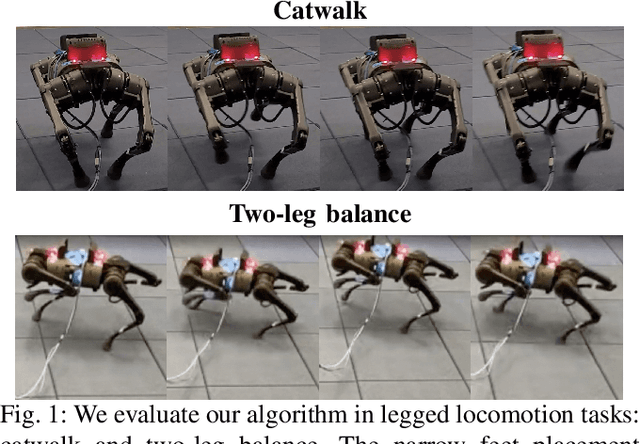
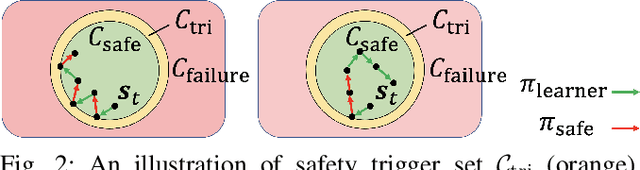


Designing control policies for legged locomotion is complex due to the under-actuated and non-continuous robot dynamics. Model-free reinforcement learning provides promising tools to tackle this challenge. However, a major bottleneck of applying model-free reinforcement learning in real world is safety. In this paper, we propose a safe reinforcement learning framework that switches between a safe recovery policy that prevents the robot from entering unsafe states, and a learner policy that is optimized to complete the task. The safe recovery policy takes over the control when the learner policy violates safety constraints, and hands over the control back when there are no future safety violations. We design the safe recovery policy so that it ensures safety of legged locomotion while minimally intervening in the learning process. Furthermore, we theoretically analyze the proposed framework and provide an upper bound on the task performance. We verify the proposed framework in four locomotion tasks on a simulated and real quadrupedal robot: efficient gait, catwalk, two-leg balance, and pacing. On average, our method achieves 48.6% fewer falls and comparable or better rewards than the baseline methods in simulation. When deployed it on real-world quadruped robot, our training pipeline enables 34% improvement in energy efficiency for the efficient gait, 40.9% narrower of the feet placement in the catwalk, and two times more jumping duration in the two-leg balance. Our method achieves less than five falls over the duration of 115 minutes of hardware time.
Adversarial samples for deep monocular 6D object pose estimation
Mar 05, 2022


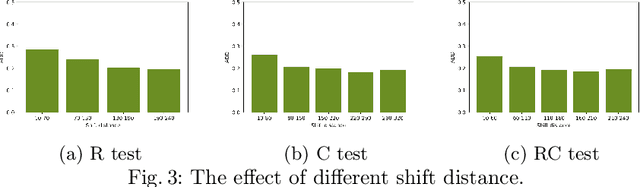
Estimating 6D object pose from an RGB image is important for many real-world applications such as autonomous driving and robotic grasping. Recent deep learning models have achieved significant progress on this task but their robustness received little research attention. In this work, for the first time, we study adversarial samples that can fool deep learning models with imperceptible perturbations to input image. In particular, we propose a Unified 6D pose estimation Attack, namely U6DA, which can successfully attack several state-of-the-art (SOTA) deep learning models for 6D pose estimation. The key idea of our U6DA is to fool the models to predict wrong results for object instance localization and shape that are essential for correct 6D pose estimation. Specifically, we explore a transfer-based black-box attack to 6D pose estimation. We design the U6DA loss to guide the generation of adversarial examples, the loss aims to shift the segmentation attention map away from its original position. We show that the generated adversarial samples are not only effective for direct 6D pose estimation models, but also are able to attack two-stage models regardless of their robust RANSAC modules. Extensive experiments were conducted to demonstrate the effectiveness, transferability, and anti-defense capability of our U6DA on large-scale public benchmarks. We also introduce a new U6DA-Linemod dataset for robustness study of the 6D pose estimation task. Our codes and dataset will be available at \url{https://github.com/cuge1995/U6DA}.
Tomographic Muon Imaging of the Great Pyramid of Giza
Feb 16, 2022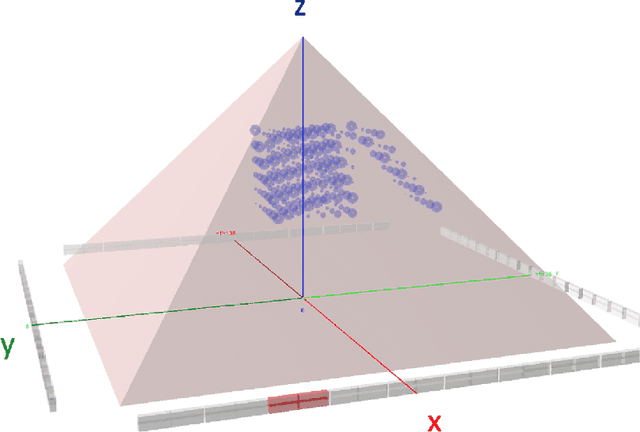
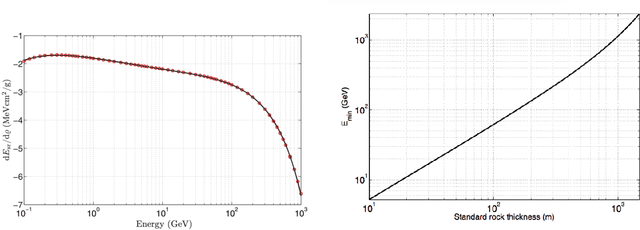
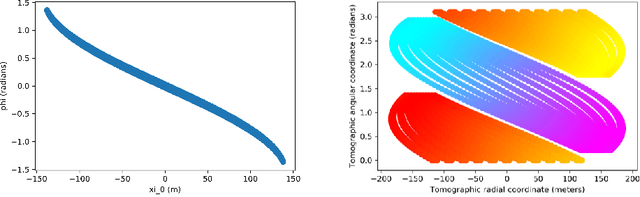
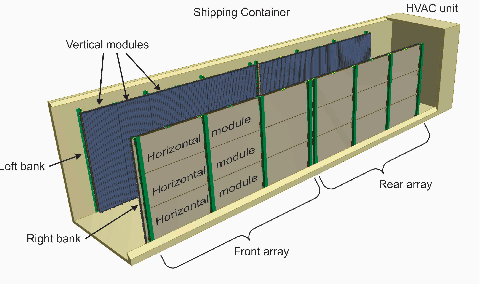
The pyramids of the Giza plateau have fascinated visitors since ancient times and are the last of the Seven Wonders of the ancient world still standing. It has been half a century since Luiz Alvarez and his team used cosmic-ray muon imaging to look for hidden chambers in Khafres Pyramid. Advances in instrumentation for High-Energy Physics (HEP) allowed a new survey, ScanPyramids, to make important new discoveries at the Great Pyramid (Khufu) utilizing the same basic technique that the Alvarez team used, but now with modern instrumentation. The Exploring the Great Pyramid Mission plans to field a very-large muon telescope system that will be transformational with respect to the field of cosmic-ray muon imaging. We plan to field a telescope system that has upwards of 100 times the sensitivity of the equipment that has recently been used at the Great Pyramid, will image muons from nearly all angles and will, for the first time, produce a true tomographic image of such a large structure.
Data augmentation through multivariate scenario forecasting in Data Centers using Generative Adversarial Networks
Jan 12, 2022
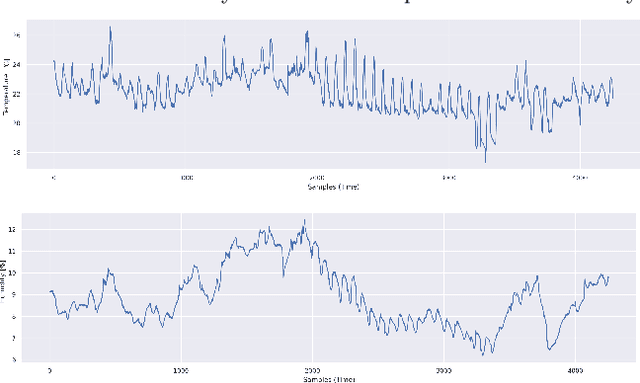
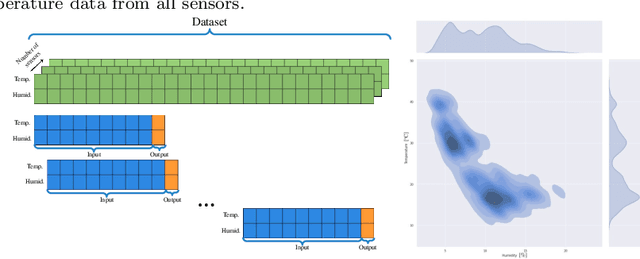

The Cloud paradigm is at a critical point in which the existing energy-efficiency techniques are reaching a plateau, while the computing resources demand at Data Center facilities continues to increase exponentially. The main challenge in achieving a global energy efficiency strategy based on Artificial Intelligence is that we need massive amounts of data to feed the algorithms. Nowadays, any optimization strategy must begin with data. However, companies with access to these large amounts of data decide not to share them because it could compromise their security. This paper proposes a time-series data augmentation methodology based on synthetic scenario forecasting within the Data Center. For this purpose, we will implement a powerful generative algorithm: Generative Adversarial Networks (GANs). The use of GANs will allow us to handle multivariate data and data from different natures (e.g., categorical). On the other hand, adapting Data Centers' operational management to the occurrence of sporadic anomalies is complicated due to the reduced frequency of failures in the system. Therefore, we also propose a methodology to increase the generated data variability by introducing on-demand anomalies. We validated our approach using real data collected from an operating Data Center, successfully obtaining forecasts of random scenarios with several hours of prediction. Our research will help to optimize the energy consumed in Data Centers, although the proposed methodology can be employed in any similar time-series-like problem.
Sample and Communication-Efficient Decentralized Actor-Critic Algorithms with Finite-Time Analysis
Sep 08, 2021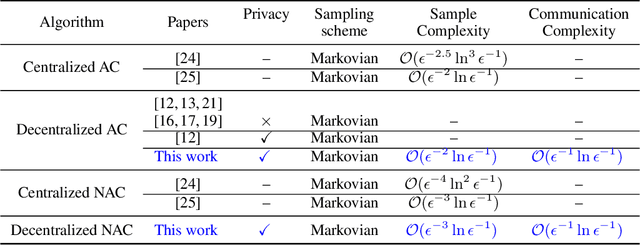
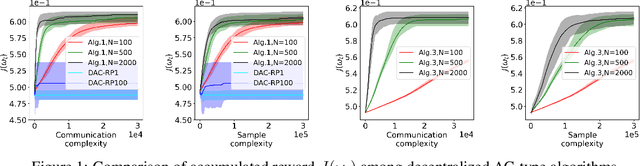
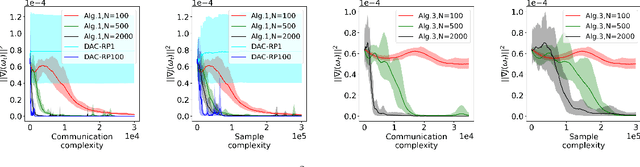
Actor-critic (AC) algorithms have been widely adopted in decentralized multi-agent systems to learn the optimal joint control policy. However, existing decentralized AC algorithms either do not preserve the privacy of agents or are not sample and communication-efficient. In this work, we develop two decentralized AC and natural AC (NAC) algorithms that are private, and sample and communication-efficient. In both algorithms, agents share noisy information to preserve privacy and adopt mini-batch updates to improve sample and communication efficiency. Particularly for decentralized NAC, we develop a decentralized Markovian SGD algorithm with an adaptive mini-batch size to efficiently compute the natural policy gradient. Under Markovian sampling and linear function approximation, we prove the proposed decentralized AC and NAC algorithms achieve the state-of-the-art sample complexities $\mathcal{O}\big(\epsilon^{-2}\ln(\epsilon^{-1})\big)$ and $\mathcal{O}\big(\epsilon^{-3}\ln(\epsilon^{-1})\big)$, respectively, and the same small communication complexity $\mathcal{O}\big(\epsilon^{-1}\ln(\epsilon^{-1})\big)$. Numerical experiments demonstrate that the proposed algorithms achieve lower sample and communication complexities than the existing decentralized AC algorithm.