 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
How News Evolves? Modeling News Text and Coverage using Graphs and Hawkes Process
Nov 18, 2021
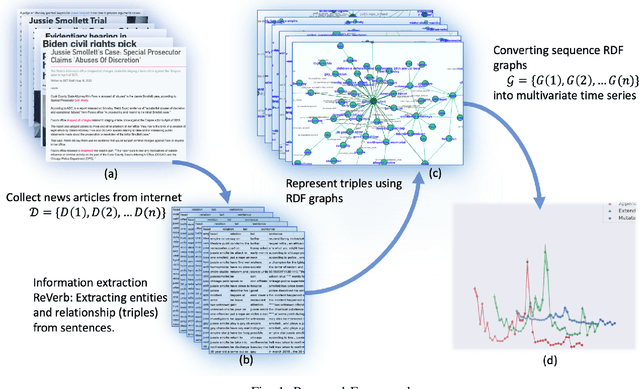
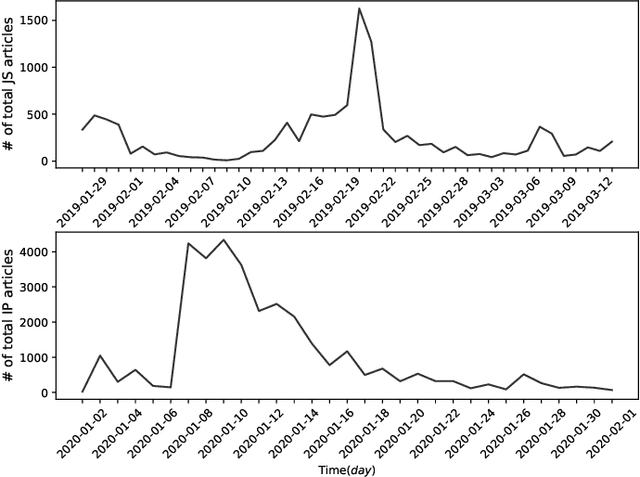
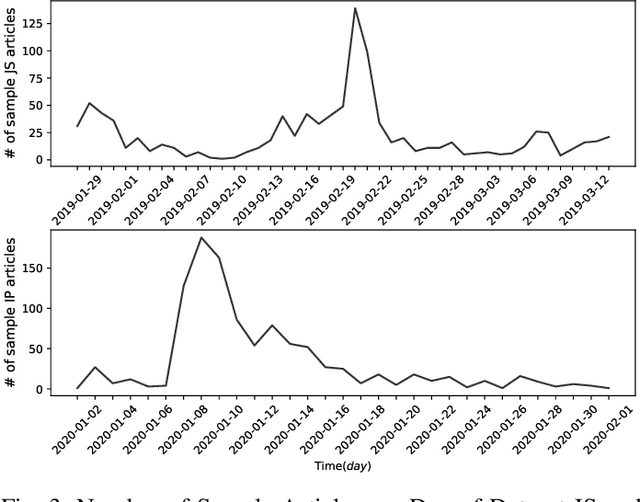
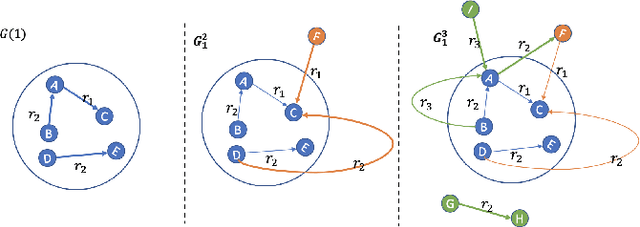
Monitoring news content automatically is an important problem. The news content, unlike traditional text, has a temporal component. However, few works have explored the combination of natural language processing and dynamic system models. One reason is that it is challenging to mathematically model the nuances of natural language. In this paper, we discuss how we built a novel dataset of news articles collected over time. Then, we present a method of converting news text collected over time to a sequence of directed multi-graphs, which represent semantic triples (Subject ! Predicate ! Object). We model the dynamics of specific topological changes from these graphs using discrete-time Hawkes processes. With our real-world data, we show that analyzing the structures of the graphs and the discrete-time Hawkes process model can yield insights on how the news events were covered and how to predict how it may be covered in the future.
Do autoencoders need a bottleneck for anomaly detection?
Feb 25, 2022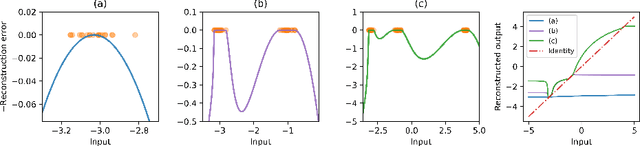



A common belief in designing deep autoencoders (AEs), a type of unsupervised neural network, is that a bottleneck is required to prevent learning the identity function. Learning the identity function renders the AEs useless for anomaly detection. In this work, we challenge this limiting belief and investigate the value of non-bottlenecked AEs. The bottleneck can be removed in two ways: (1) overparameterising the latent layer, and (2) introducing skip connections. However, limited works have reported on the use of one of the ways. For the first time, we carry out extensive experiments covering various combinations of bottleneck removal schemes, types of AEs and datasets. In addition, we propose the infinitely-wide AEs as an extreme example of non-bottlenecked AEs. Their improvement over the baseline implies learning the identity function is not trivial as previously assumed. Moreover, we find that non-bottlenecked architectures (highest AUROC=0.857) can outperform their bottlenecked counterparts (highest AUROC=0.696) on the popular task of CIFAR (inliers) vs SVHN (anomalies), among other tasks, shedding light on the potential of developing non-bottlenecked AEs for improving anomaly detection.
StyleHEAT: One-Shot High-Resolution Editable Talking Face Generation via Pre-trained StyleGAN
Mar 17, 2022
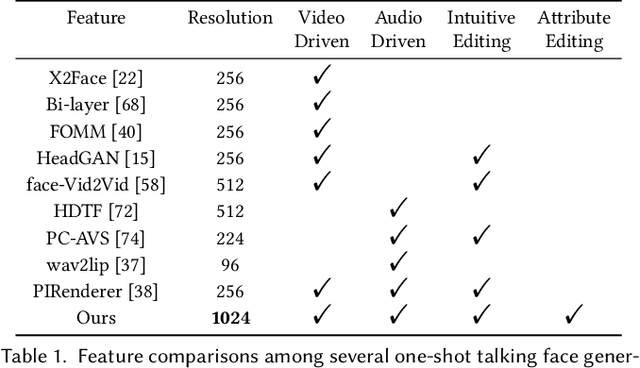

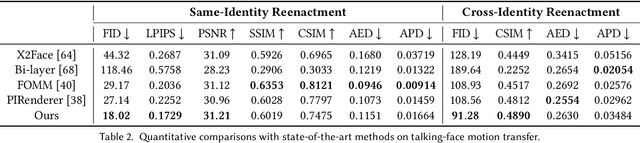
One-shot talking face generation aims at synthesizing a high-quality talking face video from an arbitrary portrait image, driven by a video or an audio segment. One challenging quality factor is the resolution of the output video: higher resolution conveys more details. In this work, we investigate the latent feature space of a pre-trained StyleGAN and discover some excellent spatial transformation properties. Upon the observation, we explore the possibility of using a pre-trained StyleGAN to break through the resolution limit of training datasets. We propose a novel unified framework based on a pre-trained StyleGAN that enables a set of powerful functionalities, i.e., high-resolution video generation, disentangled control by driving video or audio, and flexible face editing. Our framework elevates the resolution of the synthesized talking face to 1024*1024 for the first time, even though the training dataset has a lower resolution. We design a video-based motion generation module and an audio-based one, which can be plugged into the framework either individually or jointly to drive the video generation. The predicted motion is used to transform the latent features of StyleGAN for visual animation. To compensate for the transformation distortion, we propose a calibration network as well as a domain loss to refine the features. Moreover, our framework allows two types of facial editing, i.e., global editing via GAN inversion and intuitive editing based on 3D morphable models. Comprehensive experiments show superior video quality, flexible controllability, and editability over state-of-the-art methods.
Efficient Information Diffusion in Time-Varying Graphs through Deep Reinforcement Learning
Nov 27, 2020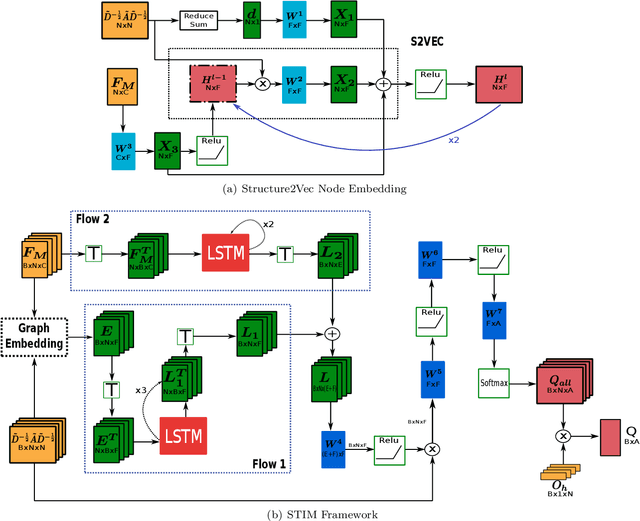
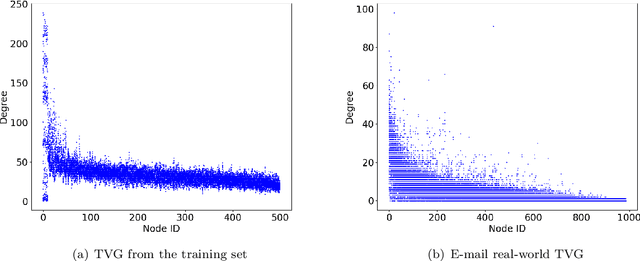

Network seeding for efficient information diffusion over time-varying graphs~(TVGs) is a challenging task with many real-world applications. There are several ways to model this spatio-temporal influence maximization problem, but the ultimate goal is to determine the best moment for a node to start the diffusion process. In this context, we propose Spatio-Temporal Influence Maximization~(STIM), a model trained with Reinforcement Learning and Graph Embedding over a set of artificial TVGs that is capable of learning the temporal behavior and connectivity pattern of each node, allowing it to predict the best moment to start a diffusion through the TVG. We also develop a special set of artificial TVGs used for training that simulate a stochastic diffusion process in TVGs, showing that the STIM network can learn an efficient policy even over a non-deterministic environment. STIM is also evaluated with a real-world TVG, where it also manages to efficiently propagate information through the nodes. Finally, we also show that the STIM model has a time complexity of $O(|E|)$. STIM, therefore, presents a novel approach for efficient information diffusion in TVGs, being highly versatile, where one can change the goal of the model by simply changing the adopted reward function.
A low-rank ensemble Kalman filter for elliptic observations
Mar 10, 2022
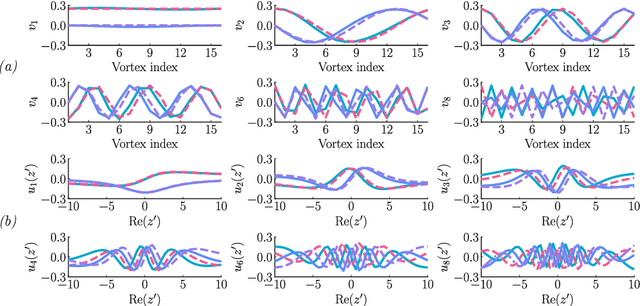
We propose a regularization method for ensemble Kalman filtering (EnKF) with elliptic observation operators. Commonly used EnKF regularization methods suppress state correlations at long distances. For observations described by elliptic partial differential equations, such as the pressure Poisson equation (PPE) in incompressible fluid flows, distance localization cannot be applied, as we cannot disentangle slowly decaying physical interactions from spurious long-range correlations. This is particularly true for the PPE, in which distant vortex elements couple nonlinearly to induce pressure. Instead, these inverse problems have a low effective dimension: low-dimensional projections of the observations strongly inform a low-dimensional subspace of the state space. We derive a low-rank factorization of the Kalman gain based on the spectrum of the Jacobian of the observation operator. The identified eigenvectors generalize the source and target modes of the multipole expansion, independently of the underlying spatial distribution of the problem. Given rapid spectral decay, inference can be performed in the low-dimensional subspace spanned by the dominant eigenvectors. This low-rank EnKF is assessed on dynamical systems with Poisson observation operators, where we seek to estimate the positions and strengths of point singularities over time from potential or pressure observations. We also comment on the broader applicability of this approach to elliptic inverse problems outside the context of filtering.
IDCAIS: Inter-Defender Collision-Aware Interception Strategy against Multiple Attackers
Dec 22, 2021
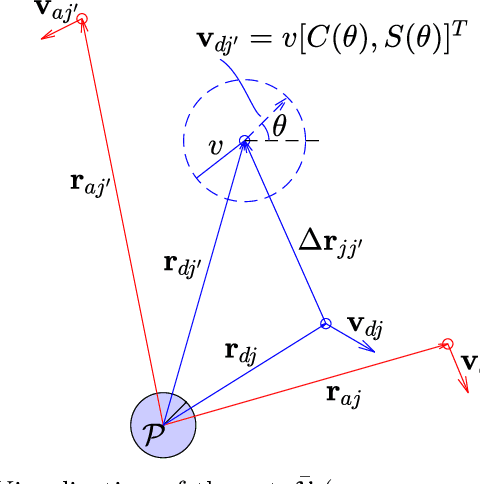
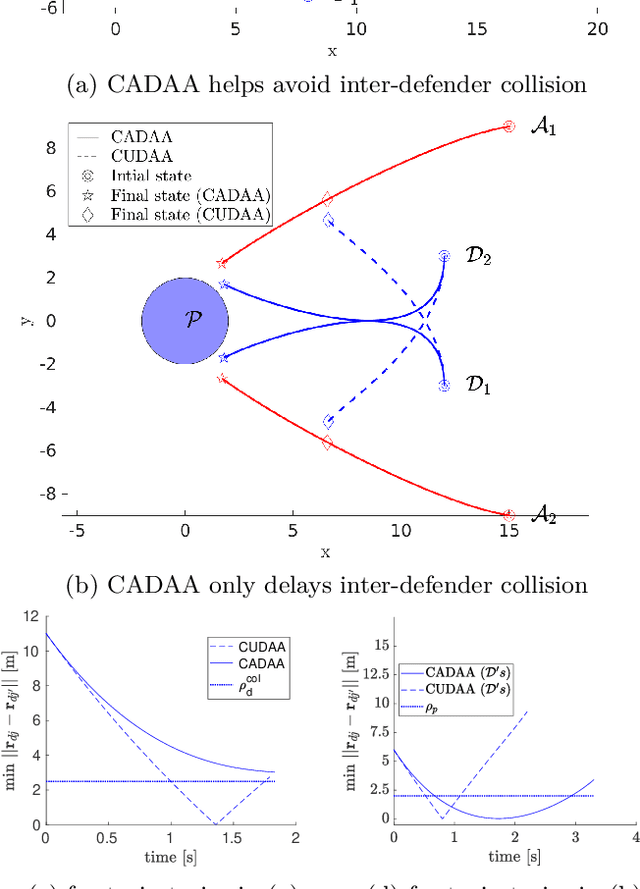
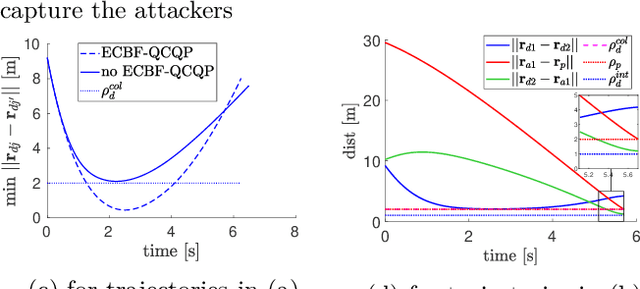
This paper presents an Inter-Defender Collision-Aware Interception Strategy (IDCAIS) for defenders to intercept attackers in order to defend a protected area, such that each defender also avoids collision with other defenders. In particular, the defenders are assigned to intercept attackers using a mixed-integer quadratic program (MIQP) that: 1)minimizes the sum of times taken by defenders to capture the attackers under time-optimal control, and2) helps eliminate or delay possible future collisions among the defenders on the optimal trajectories. To prevent inevitable collisions on optimal trajectories or collisions arising due to time-sub-optimal behavior by the attackers, a minimally augmented control using exponential control barrier function (ECBF) is provided. Simulations show the efficacy of the approach.
Learning to Reformulate for Linear Programming
Jan 17, 2022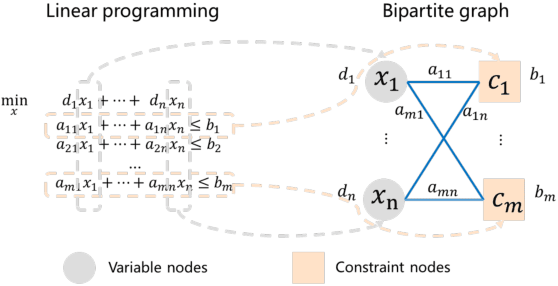

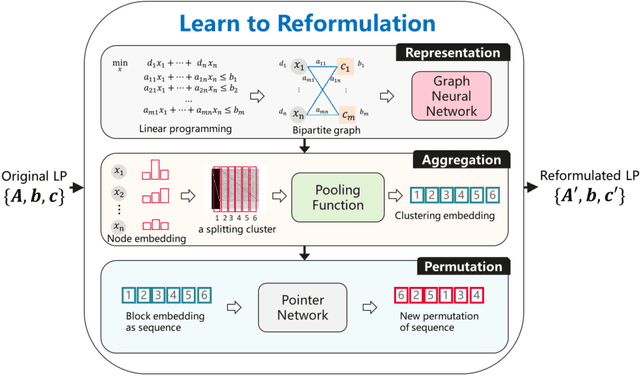
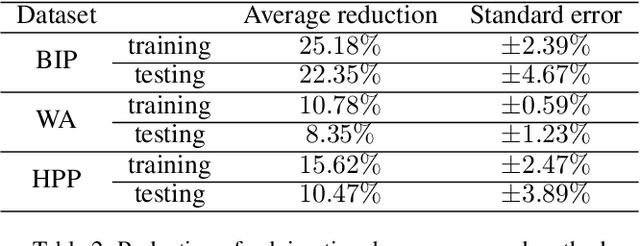
It has been verified that the linear programming (LP) is able to formulate many real-life optimization problems, which can obtain the optimum by resorting to corresponding solvers such as OptVerse, Gurobi and CPLEX. In the past decades, a serial of traditional operation research algorithms have been proposed to obtain the optimum of a given LP in a fewer solving time. Recently, there is a trend of using machine learning (ML) techniques to improve the performance of above solvers. However, almost no previous work takes advantage of ML techniques to improve the performance of solver from the front end, i.e., the modeling (or formulation). In this paper, we are the first to propose a reinforcement learning-based reformulation method for LP to improve the performance of solving process. Using an open-source solver COIN-OR LP (CLP) as an environment, we implement the proposed method over two public research LP datasets and one large-scale LP dataset collected from practical production planning scenario. The evaluation results suggest that the proposed method can effectively reduce both the solving iteration number ($25\%\downarrow$) and the solving time ($15\%\downarrow$) over above datasets in average, compared to directly solving the original LP instances.
When SIMPLE is better than complex: A case study on deep learning for predicting Bugzilla issue close time
Jan 15, 2021

Is deep learning over-hyped? Where are the case studies that compare state-of-the-art deep learners with simpler options? In response to this gap in the literature, this paper offers one case study on using deep learning to predict issue close time in Bugzilla. We report here that a SIMPLE extension to a decades-old feedforward neural network works better than the more recent, and more elaborate, "long-short term memory" deep learning (which are currently popular in the SE literature). SIMPLE is a combination of a fast feedforward network and a hyper-parameter optimizer. SIMPLE runs in 3 seconds while the newer algorithms take 6 hours to terminate. Since it runs so fast, it is more amenable to being tuned by our optimizer. This paper reports results seen after running SIMPLE on issue close time data from 45,364 issues raised in Chromium, Eclipse, and Firefox projects from January 2010 to March 2016. In our experiments, this SIMPLEr tuning approach achieves significantly better predictors for issue close time than the more complex deep learner. These better and SIMPLEr results can be generated 2,700 times faster than if using a state-of-the-art deep learner. From this result, we make two conclusions. Firstly, for predicting issue close time, we would recommend SIMPLE over complex deep learners. Secondly, before analysts try very sophisticated (but very slow) algorithms, they might achieve better results, much sooner, by applying hyper-parameter optimization to simple (but very fast) algorithms.
RRL:Regional Rotation Layer in Convolutional Neural Networks
Feb 25, 2022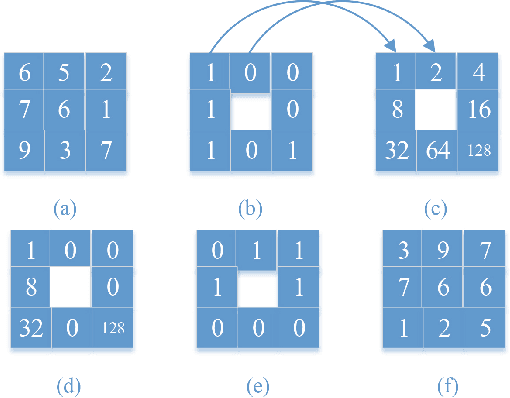
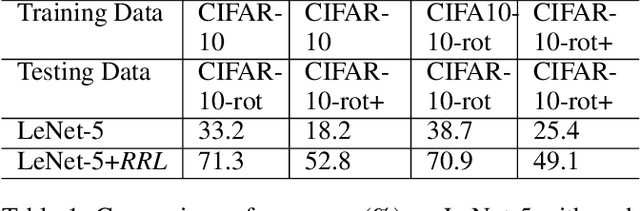
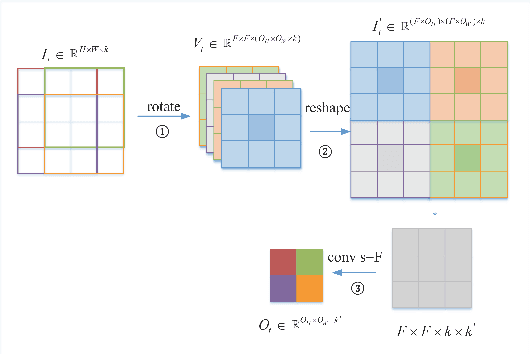
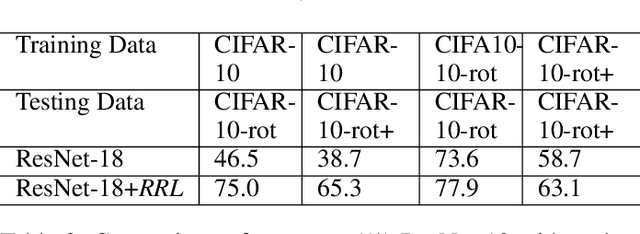
Convolutional Neural Networks (CNNs) perform very well in image classification and object detection in recent years, but even the most advanced models have limited rotation invariance. Known solutions include the enhancement of training data and the increase of rotation invariance by globally merging the rotation equivariant features. These methods either increase the workload of training or increase the number of model parameters. To address this problem, this paper proposes a module that can be inserted into the existing networks, and directly incorporates the rotation invariance into the feature extraction layers of the CNNs. This module does not have learnable parameters and will not increase the complexity of the model. At the same time, only by training the upright data, it can perform well on the rotated testing set. These advantages will be suitable for fields such as biomedicine and astronomy where it is difficult to obtain upright samples or the target has no directionality. Evaluate our module with LeNet-5, ResNet-18 and tiny-yolov3, we get impressive results.
Deep Movement Primitives: toward Breast Cancer Examination Robot
Feb 14, 2022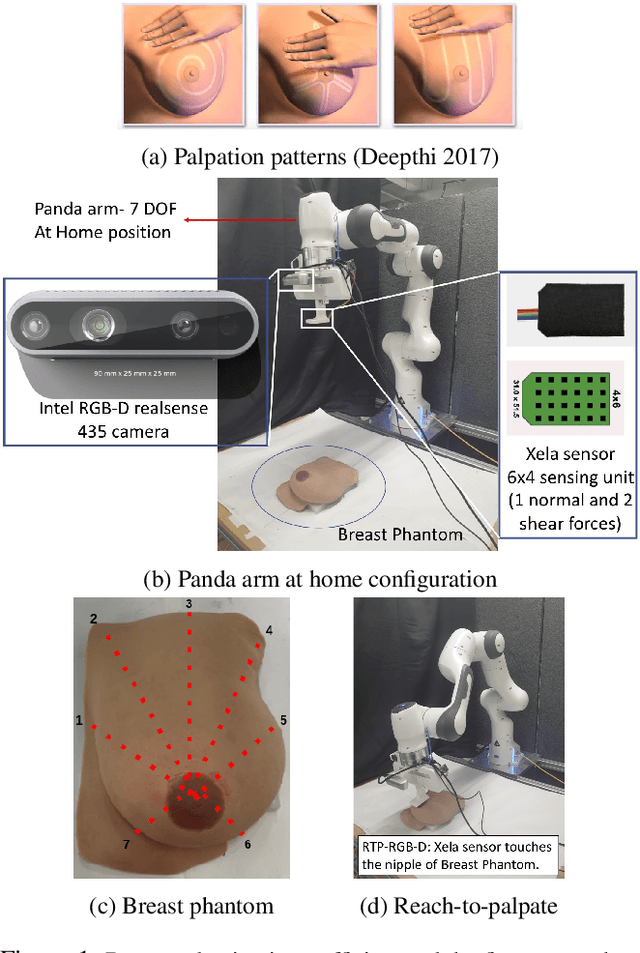
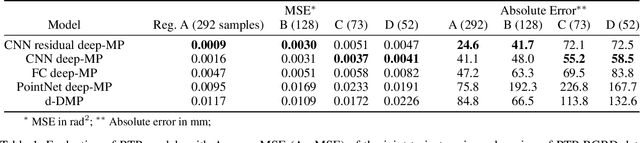
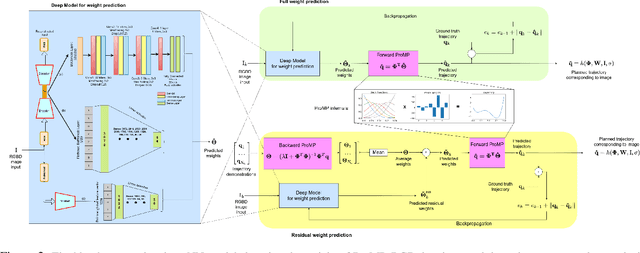
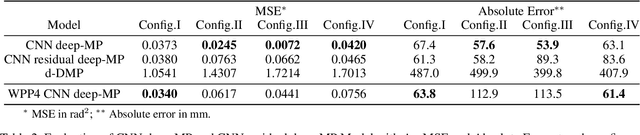
Breast cancer is the most common type of cancer worldwide. A robotic system performing autonomous breast palpation can make a significant impact on the related health sector worldwide. However, robot programming for breast palpating with different geometries is very complex and unsolved. Robot learning from demonstrations (LfD) reduces the programming time and cost. However, the available LfD are lacking the modelling of the manipulation path/trajectory as an explicit function of the visual sensory information. This paper presents a novel approach to manipulation path/trajectory planning called deep Movement Primitives that successfully generates the movements of a manipulator to reach a breast phantom and perform the palpation. We show the effectiveness of our approach by a series of real-robot experiments of reaching and palpating a breast phantom. The experimental results indicate our approach outperforms the state-of-the-art method.