 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Prediction of speech intelligibility with DNN-based performance measures
Mar 17, 2022
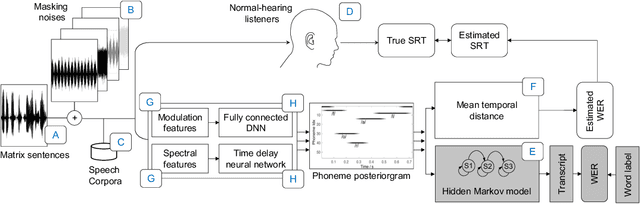


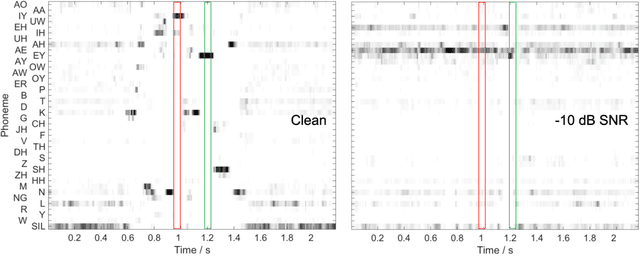
This paper presents a speech intelligibility model based on automatic speech recognition (ASR), combining phoneme probabilities from deep neural networks (DNN) and a performance measure that estimates the word error rate from these probabilities. This model does not require the clean speech reference nor the word labels during testing as the ASR decoding step, which finds the most likely sequence of words given phoneme posterior probabilities, is omitted. The model is evaluated via the root-mean-squared error between the predicted and observed speech reception thresholds from eight normal-hearing listeners. The recognition task consists of identifying noisy words from a German matrix sentence test. The speech material was mixed with eight noise maskers covering different modulation types, from speech-shaped stationary noise to a single-talker masker. The prediction performance is compared to five established models and an ASR-model using word labels. Two combinations of features and networks were tested. Both include temporal information either at the feature level (amplitude modulation filterbanks and a feed-forward network) or captured by the architecture (mel-spectrograms and a time-delay deep neural network, TDNN). The TDNN model is on par with the DNN while reducing the number of parameters by a factor of 37; this optimization allows parallel streams on dedicated hearing aid hardware as a forward-pass can be computed within the 10ms of each frame. The proposed model performs almost as well as the label-based model and produces more accurate predictions than the baseline models.
Online Self-Calibration for Visual-Inertial Navigation Systems: Models, Analysis and Degeneracy
Jan 29, 2022

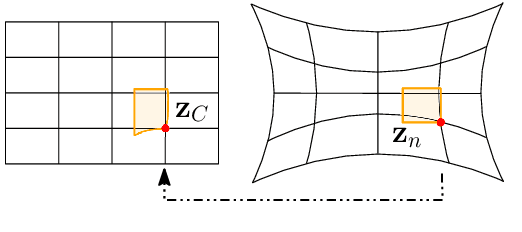
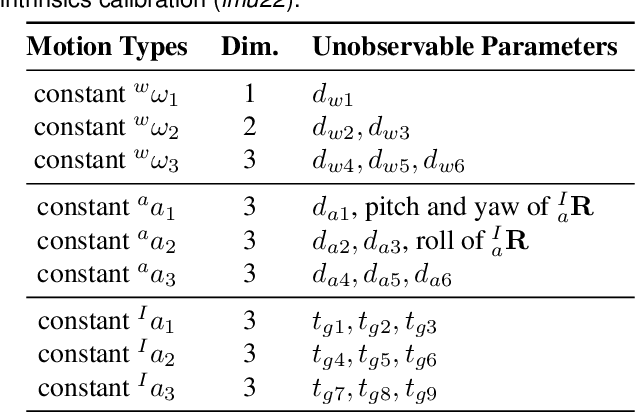
In this paper, we study in-depth the problem of online self-calibration for robust and accurate visual-inertial state estimation. In particular, we first perform a complete observability analysis for visual-inertial navigation systems (VINS) with full calibration of sensing parameters, including IMU and camera intrinsics and IMU-camera spatial-temporal extrinsic calibration, along with readout time of rolling shutter (RS) cameras (if used). We investigate different inertial model variants containing IMU intrinsic parameters that encompass most commonly used models for low-cost inertial sensors. The observability analysis results prove that VINS with full sensor calibration has four unobservable directions, corresponding to the system's global yaw and translation, while all sensor calibration parameters are observable given fully-excited 6-axis motion. Moreover, we, for the first time, identify primitive degenerate motions for IMU and camera intrinsic calibration. Each degenerate motion profile will cause a set of calibration parameters to be unobservable and any combination of these degenerate motions are still degenerate. Extensive Monte-Carlo simulations and real-world experiments are performed to validate both the observability analysis and identified degenerate motions, showing that online self-calibration improves system accuracy and robustness to calibration inaccuracies. We compare the proposed online self-calibration on commonly-used IMUs against the state-of-art offline calibration toolbox Kalibr, and show that the proposed system achieves better consistency and repeatability. Based on our analysis and experimental evaluations, we also provide practical guidelines for how to perform online IMU-camera sensor self-calibration.
ChemTab: A Physics Guided Chemistry Modeling Framework
Feb 20, 2022Modeling of turbulent combustion system requires modeling the underlying chemistry and the turbulent flow. Solving both systems simultaneously is computationally prohibitive. Instead, given the difference in scales at which the two sub-systems evolve, the two sub-systems are typically (re)solved separately. Popular approaches such as the Flamelet Generated Manifolds (FGM) use a two-step strategy where the governing reaction kinetics are pre-computed and mapped to a low-dimensional manifold, characterized by a few reaction progress variables (model reduction) and the manifold is then "looked-up" during the run-time to estimate the high-dimensional system state by the flow system. While existing works have focused on these two steps independently, we show that joint learning of the progress variables and the look-up model, can yield more accurate results. We propose a deep neural network architecture, called ChemTab, customized for the joint learning task and experimentally demonstrate its superiority over existing state-of-the-art methods.
Autoencoding Word Representations through Time for Semantic Change Detection
Apr 28, 2020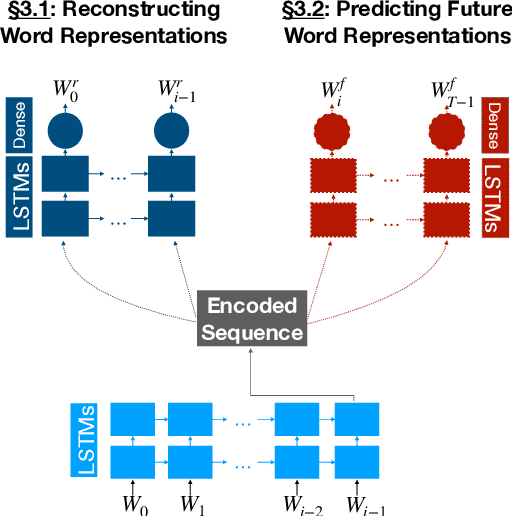
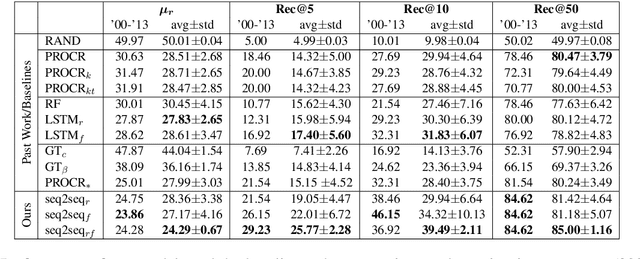
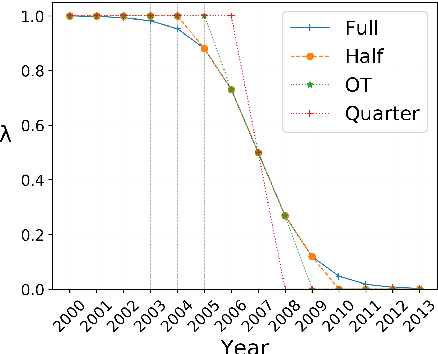
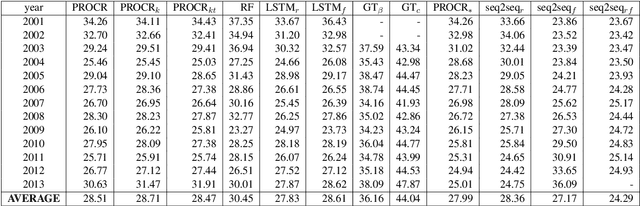
Semantic change detection concerns the task of identifying words whose meaning has changed over time. The current state-of-the-art detects the level of semantic change in a word by comparing its vector representation in two distinct time periods, without considering its evolution through time. In this work, we propose three variants of sequential models for detecting semantically shifted words, effectively accounting for the changes in the word representations over time, in a temporally sensitive manner. Through extensive experimentation under various settings with both synthetic and real data we showcase the importance of sequential modelling of word vectors through time for detecting the words whose semantics have changed the most. Finally, we take a step towards comparing different approaches in a quantitative manner, demonstrating that the temporal modelling of word representations yields a clear-cut advantage in performance.
Dense Voxel Fusion for 3D Object Detection
Mar 02, 2022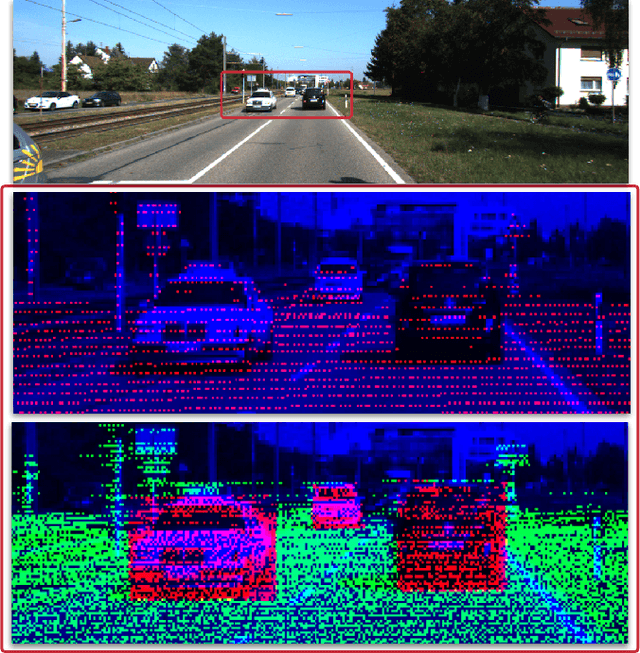
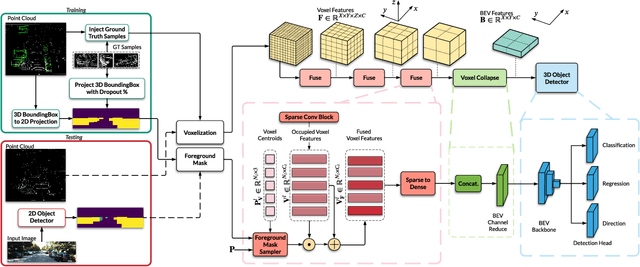
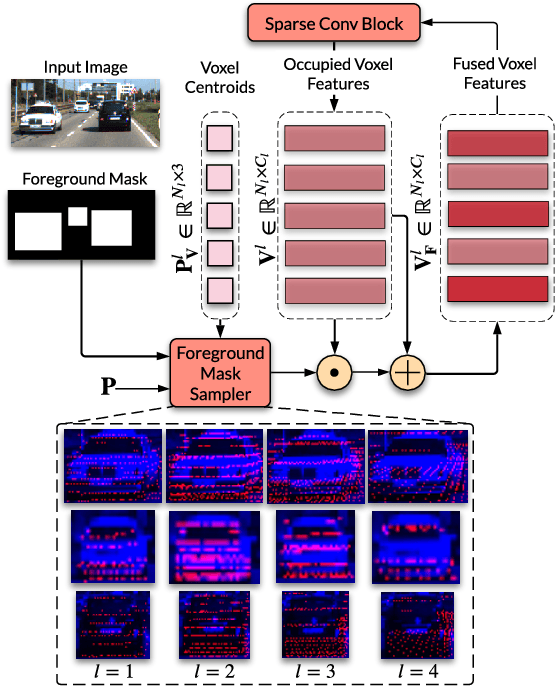
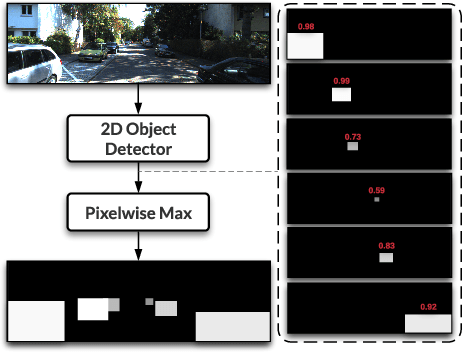
Camera and LiDAR sensor modalities provide complementary appearance and geometric information useful for detecting 3D objects for autonomous vehicle applications. However, current fusion models underperform state-of-art LiDAR-only methods on 3D object detection benchmarks. Our proposed solution, Dense Voxel Fusion (DVF) is a sequential fusion method that generates multi-scale multi-modal dense voxel feature representations, improving expressiveness in low point density regions. To enhance multi-modal learning, we train directly with ground truth 2D bounding box labels, avoiding noisy, detector-specific, 2D predictions. Additionally, we use LiDAR ground truth sampling to simulate missed 2D detections and to accelerate training convergence. Both DVF and the multi-modal training approaches can be applied to any voxel-based LiDAR backbone without introducing additional learnable parameters. DVF outperforms existing sparse fusion detectors, ranking $1^{st}$ among all published fusion methods on KITTI's 3D car detection benchmark at the time of submission and significantly improves 3D vehicle detection performance of voxel-based methods on the Waymo Open Dataset. We also show that our proposed multi-modal training strategy results in better generalization compared to training using erroneous 2D predictions.
Towards Bi-directional Skip Connections in Encoder-Decoder Architectures and Beyond
Mar 17, 2022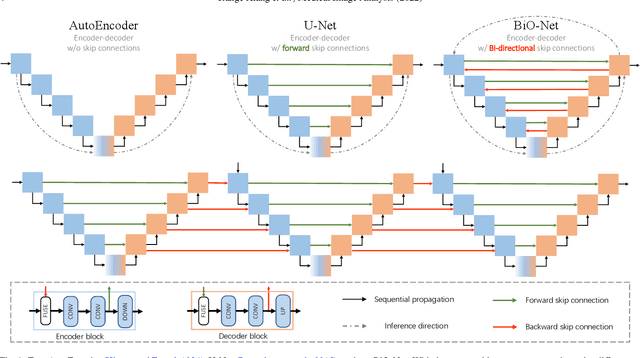
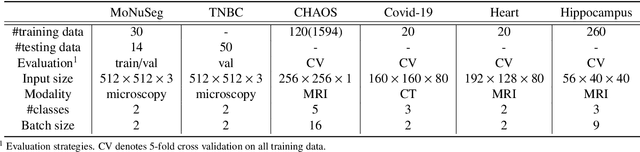
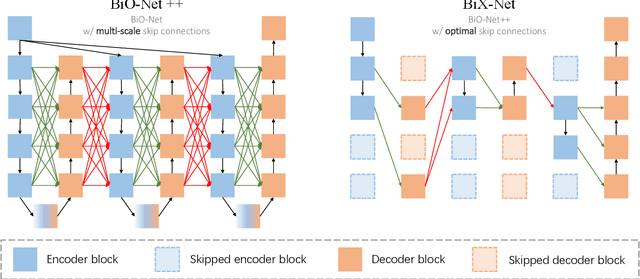
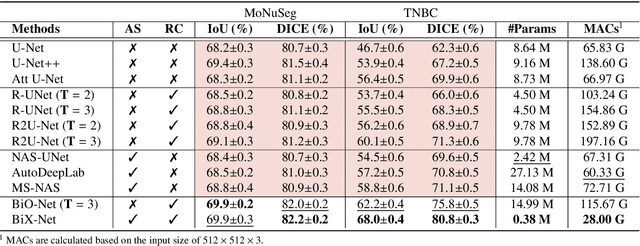
U-Net, as an encoder-decoder architecture with forward skip connections, has achieved promising results in various medical image analysis tasks. Many recent approaches have also extended U-Net with more complex building blocks, which typically increase the number of network parameters considerably. Such complexity makes the inference stage highly inefficient for clinical applications. Towards an effective yet economic segmentation network design, in this work, we propose backward skip connections that bring decoded features back to the encoder. Our design can be jointly adopted with forward skip connections in any encoder-decoder architecture forming a recurrence structure without introducing extra parameters. With the backward skip connections, we propose a U-Net based network family, namely Bi-directional O-shape networks, which set new benchmarks on multiple public medical imaging segmentation datasets. On the other hand, with the most plain architecture (BiO-Net), network computations inevitably increase along with the pre-set recurrence time. We have thus studied the deficiency bottleneck of such recurrent design and propose a novel two-phase Neural Architecture Search (NAS) algorithm, namely BiX-NAS, to search for the best multi-scale bi-directional skip connections. The ineffective skip connections are then discarded to reduce computational costs and speed up network inference. The finally searched BiX-Net yields the least network complexity and outperforms other state-of-the-art counterparts by large margins. We evaluate our methods on both 2D and 3D segmentation tasks in a total of six datasets. Extensive ablation studies have also been conducted to provide a comprehensive analysis for our proposed methods.
StyleHEAT: One-Shot High-Resolution Editable Talking Face Generation via Pre-trained StyleGAN
Mar 17, 2022
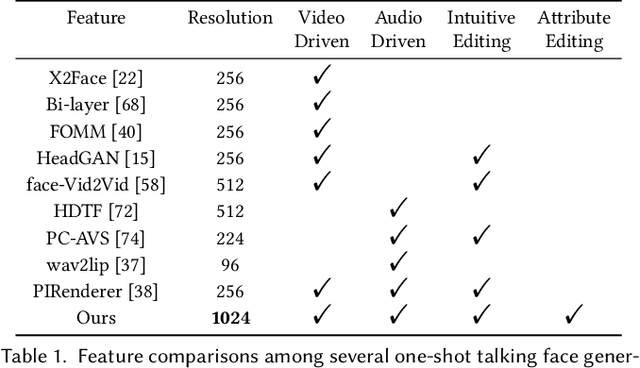

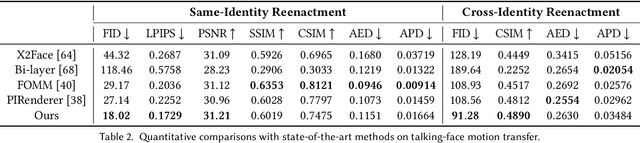
One-shot talking face generation aims at synthesizing a high-quality talking face video from an arbitrary portrait image, driven by a video or an audio segment. One challenging quality factor is the resolution of the output video: higher resolution conveys more details. In this work, we investigate the latent feature space of a pre-trained StyleGAN and discover some excellent spatial transformation properties. Upon the observation, we explore the possibility of using a pre-trained StyleGAN to break through the resolution limit of training datasets. We propose a novel unified framework based on a pre-trained StyleGAN that enables a set of powerful functionalities, i.e., high-resolution video generation, disentangled control by driving video or audio, and flexible face editing. Our framework elevates the resolution of the synthesized talking face to 1024*1024 for the first time, even though the training dataset has a lower resolution. We design a video-based motion generation module and an audio-based one, which can be plugged into the framework either individually or jointly to drive the video generation. The predicted motion is used to transform the latent features of StyleGAN for visual animation. To compensate for the transformation distortion, we propose a calibration network as well as a domain loss to refine the features. Moreover, our framework allows two types of facial editing, i.e., global editing via GAN inversion and intuitive editing based on 3D morphable models. Comprehensive experiments show superior video quality, flexible controllability, and editability over state-of-the-art methods.
Do autoencoders need a bottleneck for anomaly detection?
Feb 25, 2022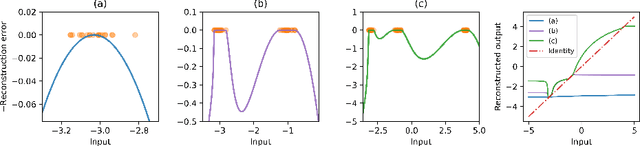



A common belief in designing deep autoencoders (AEs), a type of unsupervised neural network, is that a bottleneck is required to prevent learning the identity function. Learning the identity function renders the AEs useless for anomaly detection. In this work, we challenge this limiting belief and investigate the value of non-bottlenecked AEs. The bottleneck can be removed in two ways: (1) overparameterising the latent layer, and (2) introducing skip connections. However, limited works have reported on the use of one of the ways. For the first time, we carry out extensive experiments covering various combinations of bottleneck removal schemes, types of AEs and datasets. In addition, we propose the infinitely-wide AEs as an extreme example of non-bottlenecked AEs. Their improvement over the baseline implies learning the identity function is not trivial as previously assumed. Moreover, we find that non-bottlenecked architectures (highest AUROC=0.857) can outperform their bottlenecked counterparts (highest AUROC=0.696) on the popular task of CIFAR (inliers) vs SVHN (anomalies), among other tasks, shedding light on the potential of developing non-bottlenecked AEs for improving anomaly detection.
A low-rank ensemble Kalman filter for elliptic observations
Mar 10, 2022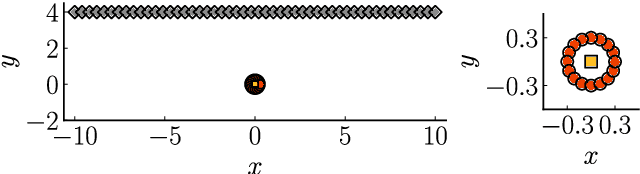
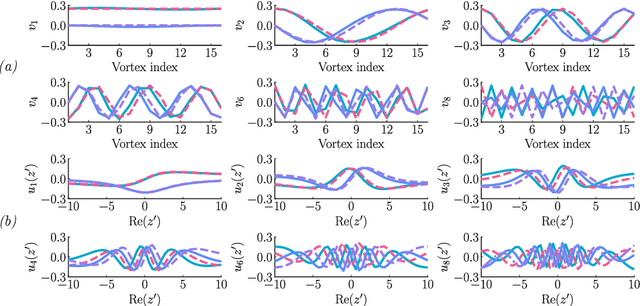
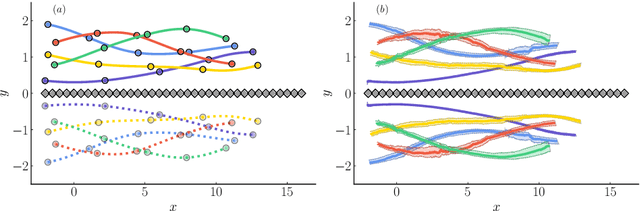
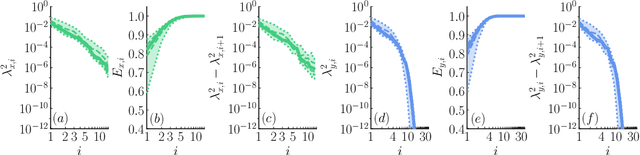
We propose a regularization method for ensemble Kalman filtering (EnKF) with elliptic observation operators. Commonly used EnKF regularization methods suppress state correlations at long distances. For observations described by elliptic partial differential equations, such as the pressure Poisson equation (PPE) in incompressible fluid flows, distance localization cannot be applied, as we cannot disentangle slowly decaying physical interactions from spurious long-range correlations. This is particularly true for the PPE, in which distant vortex elements couple nonlinearly to induce pressure. Instead, these inverse problems have a low effective dimension: low-dimensional projections of the observations strongly inform a low-dimensional subspace of the state space. We derive a low-rank factorization of the Kalman gain based on the spectrum of the Jacobian of the observation operator. The identified eigenvectors generalize the source and target modes of the multipole expansion, independently of the underlying spatial distribution of the problem. Given rapid spectral decay, inference can be performed in the low-dimensional subspace spanned by the dominant eigenvectors. This low-rank EnKF is assessed on dynamical systems with Poisson observation operators, where we seek to estimate the positions and strengths of point singularities over time from potential or pressure observations. We also comment on the broader applicability of this approach to elliptic inverse problems outside the context of filtering.
Non-Convex Joint Community Detection and Group Synchronization via Generalized Power Method
Dec 28, 2021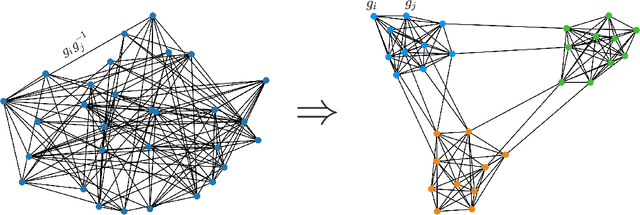

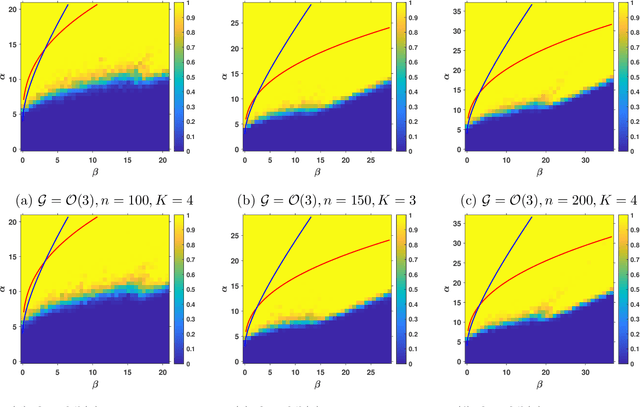
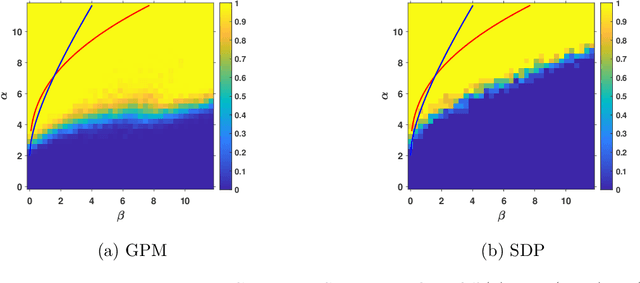
This paper proposes a Generalized Power Method (GPM) to tackle the problem of community detection and group synchronization simultaneously in a direct non-convex manner. Under the stochastic group block model (SGBM), theoretical analysis indicates that the algorithm is able to exactly recover the ground truth in $O(n\log^2n)$ time, sharply outperforming the benchmark method of semidefinite programming (SDP) in $O(n^{3.5})$ time. Moreover, a lower bound of parameters is given as a necessary condition for exact recovery of GPM. The new bound breaches the information-theoretic threshold for pure community detection under the stochastic block model (SBM), thus demonstrating the superiority of our simultaneous optimization algorithm over the trivial two-stage method which performs the two tasks in succession. We also conduct numerical experiments on GPM and SDP to evidence and complement our theoretical analysis.