 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time-Independent Planning for Multiple Moving Agents
May 27, 2020
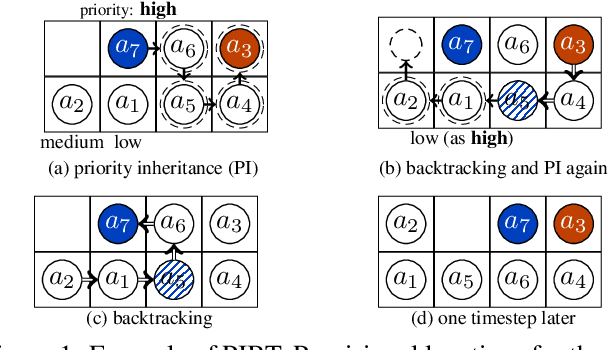

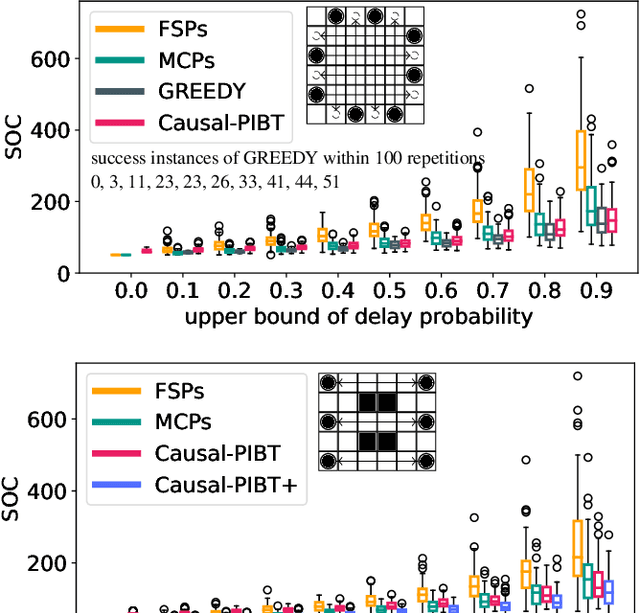
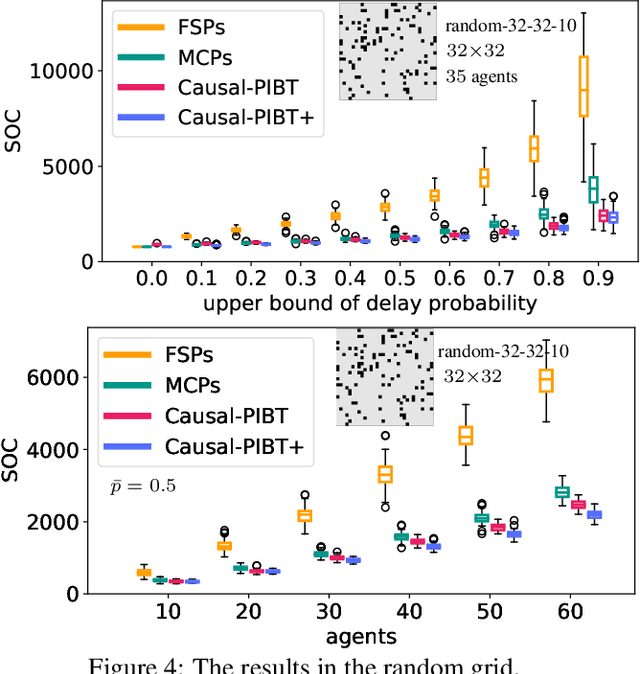
Typical Multi-agent Path Finding (MAPF) solvers assume that agents move synchronously, thus neglecting the reality gap in timing assumptions, e.g., delays caused by an imperfect execution of asynchronous moves. So far, two policies enforce a robust execution of MAPF plans taken as input, namely, either by forcing agents to synchronize, or by executing plans while preserving temporal dependencies. This paper proposes a third approach, called time-independent planning, which is both online and distributed. We represent reality as a transition system that changes configurations according to atomic actions of agents, and use it to generate a time-independent schedule. Empirical results in a simulated environment with stochastic delays of agents' moves support the validity of our proposal.
Learning Conditional Variational Autoencoders with Missing Covariates
Mar 02, 2022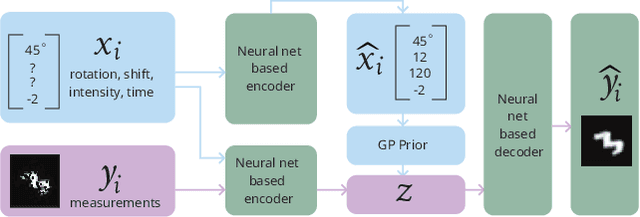
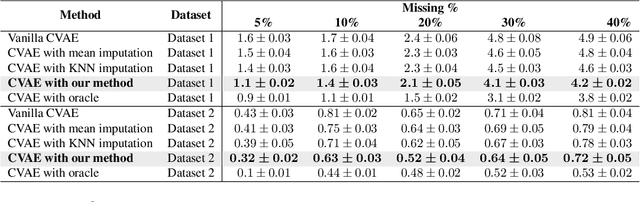
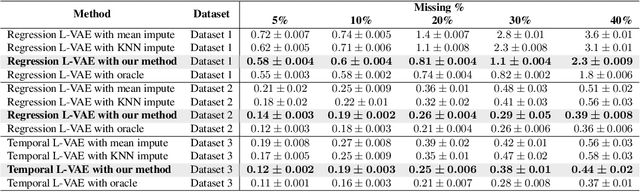
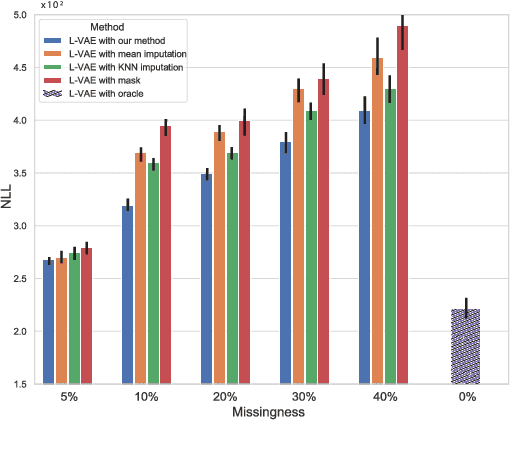
Conditional variational autoencoders (CVAEs) are versatile deep generative models that extend the standard VAE framework by conditioning the generative model with auxiliary covariates. The original CVAE model assumes that the data samples are independent, whereas more recent conditional VAE models, such as the Gaussian process (GP) prior VAEs, can account for complex correlation structures across all data samples. While several methods have been proposed to learn standard VAEs from partially observed datasets, these methods fall short for conditional VAEs. In this work, we propose a method to learn conditional VAEs from datasets in which auxiliary covariates can contain missing values as well. The proposed method augments the conditional VAEs with a prior distribution for the missing covariates and estimates their posterior using amortised variational inference. At training time, our method marginalises the uncertainty associated with the missing covariates while simultaneously maximising the evidence lower bound. We develop computationally efficient methods to learn CVAEs and GP prior VAEs that are compatible with mini-batching. Our experiments on simulated datasets as well as on a clinical trial study show that the proposed method outperforms previous methods in learning conditional VAEs from non-temporal, temporal, and longitudinal datasets.
On Federated Learning with Energy Harvesting Clients
Feb 12, 2022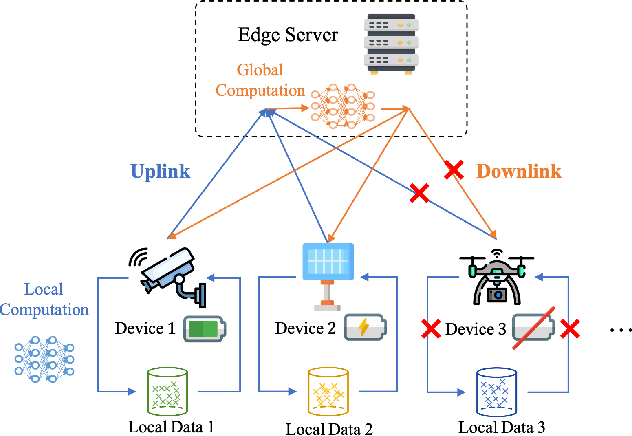
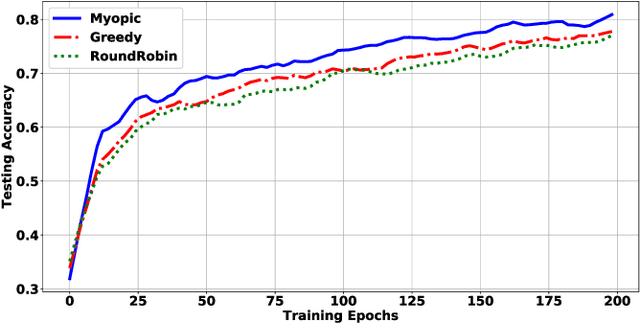
Catering to the proliferation of Internet of Things devices and distributed machine learning at the edge, we propose an energy harvesting federated learning (EHFL) framework in this paper. The introduction of EH implies that a client's availability to participate in any FL round cannot be guaranteed, which complicates the theoretical analysis. We derive novel convergence bounds that capture the impact of time-varying device availabilities due to the random EH characteristics of the participating clients, for both parallel and local stochastic gradient descent (SGD) with non-convex loss functions. The results suggest that having a uniform client scheduling that maximizes the minimum number of clients throughout the FL process is desirable, which is further corroborated by the numerical experiments using a real-world FL task and a state-of-the-art EH scheduler.
Optimising hadronic collider simulations using amplitude neural networks
Feb 09, 2022
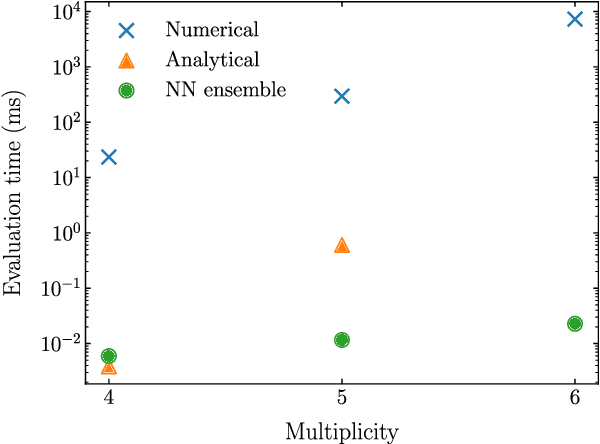
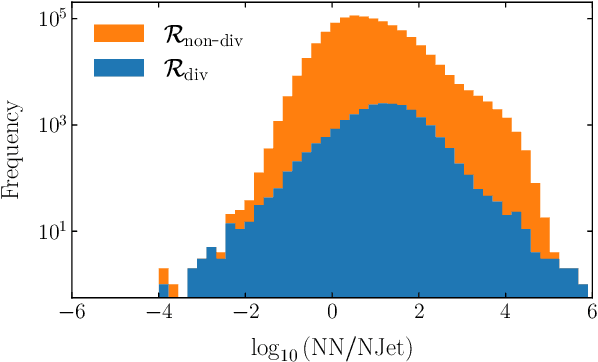
Precision phenomenological studies of high-multiplicity scattering processes at collider experiments present a substantial theoretical challenge and are vitally important ingredients in experimental measurements. Machine learning technology has the potential to dramatically optimise simulations for complicated final states. We investigate the use of neural networks to approximate matrix elements, studying the case of loop-induced diphoton production through gluon fusion. We train neural network models on one-loop amplitudes from the NJet C++ library and interface them with the Sherpa Monte Carlo event generator to provide the matrix element within a realistic hadronic collider simulation. Computing some standard observables with the models and comparing to conventional techniques, we find excellent agreement in the distributions and a reduced total simulation time by a factor of thirty.
A Composable Framework for Policy Design, Learning, and Transfer Toward Safe and Efficient Industrial Insertion
Mar 06, 2022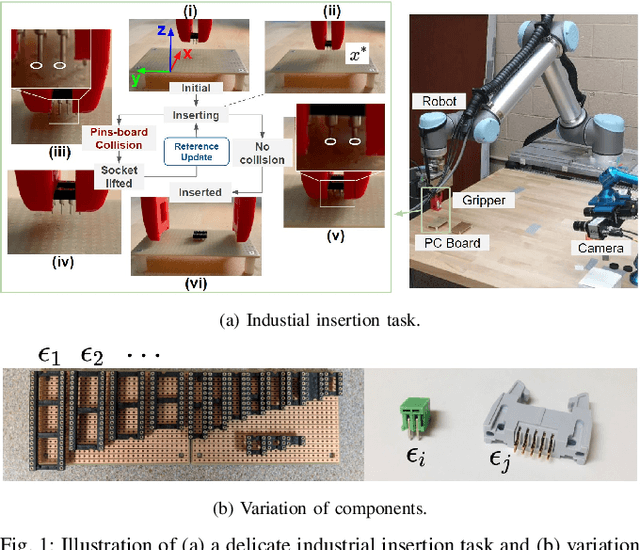
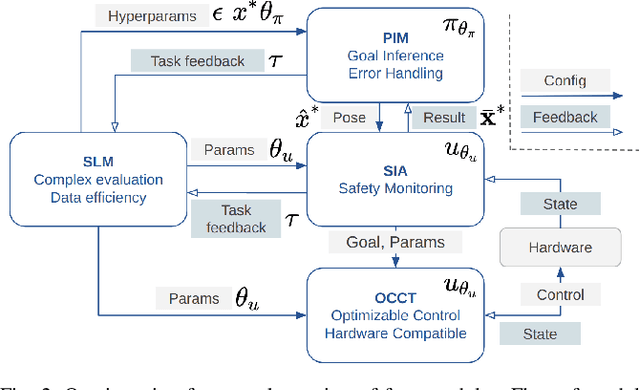
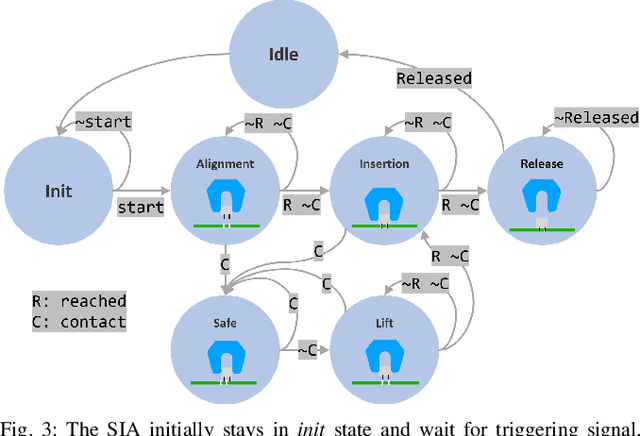
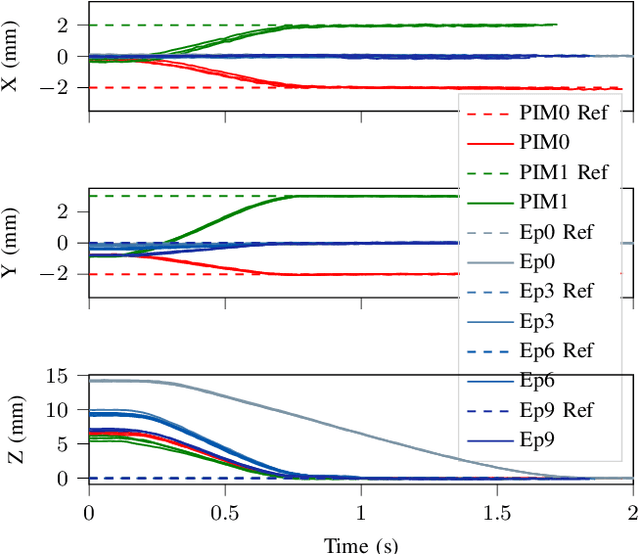
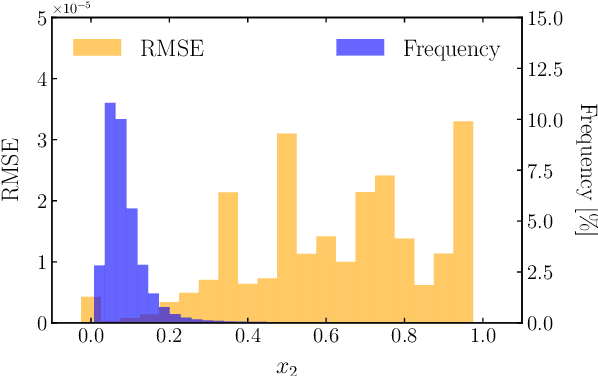
Delicate industrial insertion tasks (e.g., PC board assembly) remain challenging for industrial robots. The challenges include low error tolerance, delicacy of the components, and large task variations with respect to the components to be inserted. To deliver a feasible robotic solution for these insertion tasks, we also need to account for hardware limits of existing robotic systems and minimize the integration effort. This paper proposes a composable framework for efficient integration of a safe insertion policy on existing robotic platforms to accomplish these insertion tasks. The policy has an interpretable modularized design and can be learned efficiently on hardware and transferred to new tasks easily. In particular, the policy includes a safe insertion agent as a baseline policy for insertion, an optimal configurable Cartesian tracker as an interface to robot hardware, a probabilistic inference module to handle component variety and insertion errors, and a safe learning module to optimize the parameters in the aforementioned modules to achieve the best performance on designated hardware. The experiment results on a UR10 robot show that the proposed framework achieves safety (for the delicacy of components), accuracy (for low tolerance), robustness (against perception error and component defection), adaptability and transferability (for task variations), as well as task efficiency during execution plus data and time efficiency during learning.
Ranking of Communities in Multiplex Spatiotemporal Models of Brain Dynamics
Mar 17, 2022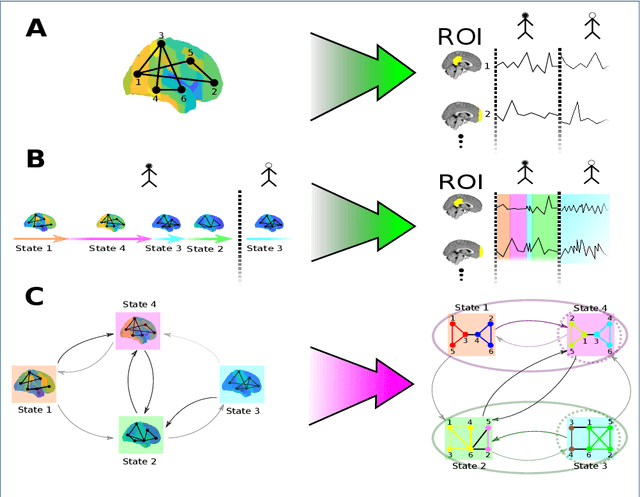

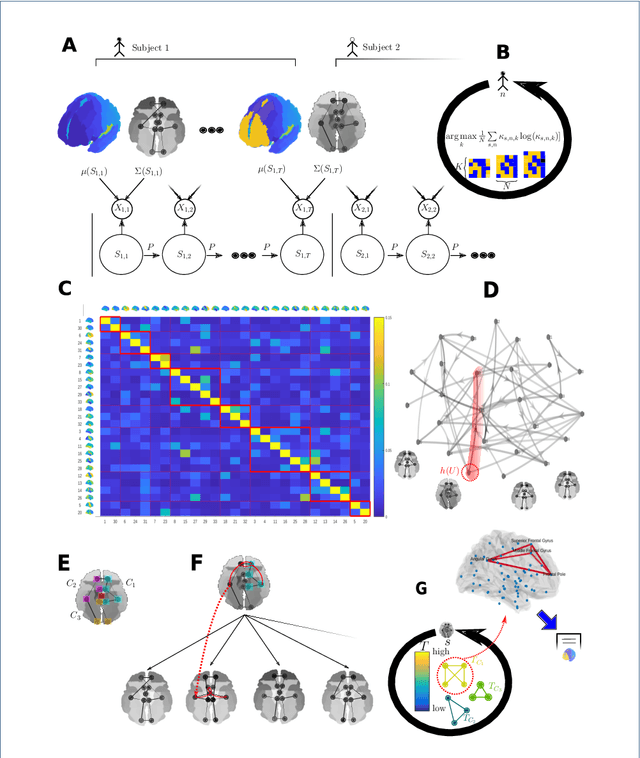
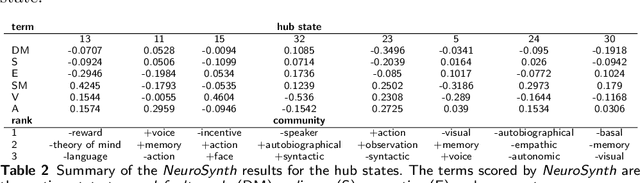
As a relatively new field, network neuroscience has tended to focus on aggregate behaviours of the brain averaged over many successive experiments or over long recordings in order to construct robust brain models. These models are limited in their ability to explain dynamic state changes in the brain which occurs spontaneously as a result of normal brain function. Hidden Markov Models (HMMs) trained on neuroimaging time series data have since arisen as a method to produce dynamical models that are easy to train but can be difficult to fully parametrise or analyse. We propose an interpretation of these neural HMMs as multiplex brain state graph models we term Hidden Markov Graph Models (HMGMs). This interpretation allows for dynamic brain activity to be analysed using the full repertoire of network analysis techniques. Furthermore, we propose a general method for selecting HMM hyperparameters in the absence of external data, based on the principle of maximum entropy, and use this to select the number of layers in the multiplex model. We produce a new tool for determining important communities of brain regions using a spatiotemporal random walk-based procedure that takes advantage of the underlying Markov structure of the model. Our analysis of real multi-subject fMRI data provides new results that corroborate the modular processing hypothesis of the brain at rest as well as contributing new evidence of functional overlap between and within dynamic brain state communities. Our analysis pipeline provides a way to characterise dynamic network activity of the brain under novel behaviours or conditions.
* Part of the Special Issue on Community Structure in Networks 2021 (35 Pages, first 22 for main text)
Deep Residual Reinforcement Learning based Autonomous Blimp Control
Mar 10, 2022
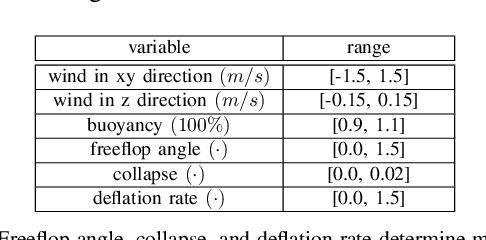
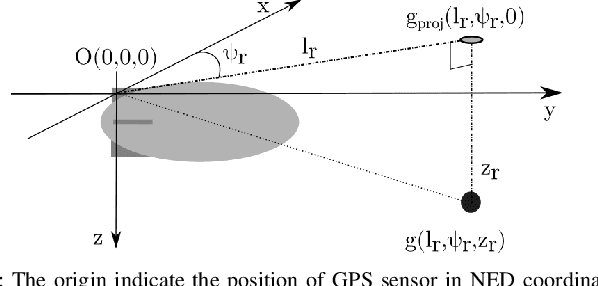
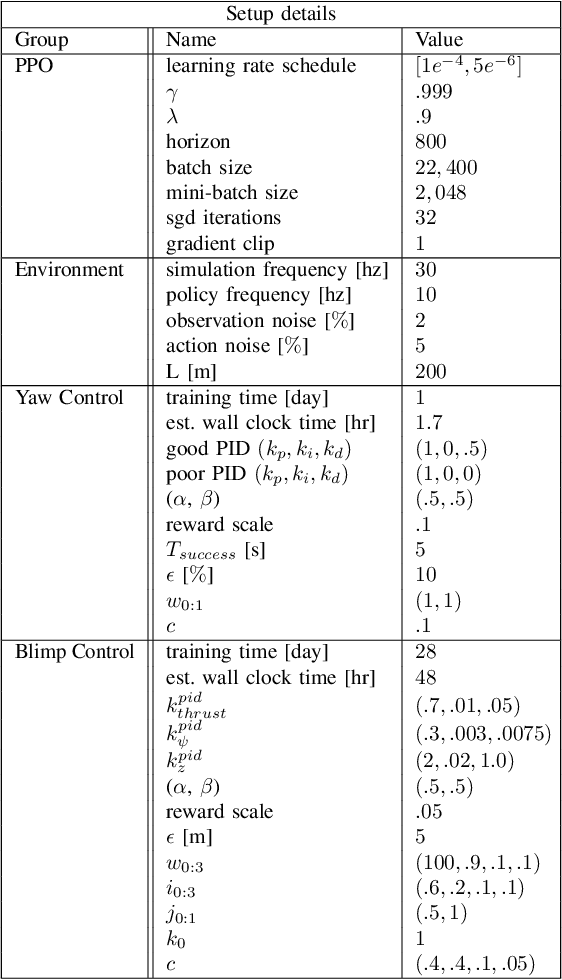
Blimps are well suited to perform long-duration aerial tasks as they are energy efficient, relatively silent and safe. To address the blimp navigation and control task, in previous work we developed a hardware and software-in-the-loop framework and a PID-based controller for large blimps in the presence of wind disturbance. However, blimps have a deformable structure and their dynamics are inherently non-linear and time-delayed, making PID controllers difficult to tune. Thus, often resulting in large tracking errors. Moreover, the buoyancy of a blimp is constantly changing due to variations in ambient temperature and pressure. To address these issues, in this paper we present a learning-based framework based on deep residual reinforcement learning (DRRL), for the blimp control task. Within this framework, we first employ a PID controller to provide baseline performance. Subsequently, the DRRL agent learns to modify the PID decisions by interaction with the environment. We demonstrate in simulation that DRRL agent consistently improves the PID performance. Through rigorous simulation experiments, we show that the agent is robust to changes in wind speed and buoyancy. In real-world experiments, we demonstrate that the agent, trained only in simulation, is sufficiently robust to control an actual blimp in windy conditions. We openly provide the source code of our approach at https://github.com/ robot-perception-group/AutonomousBlimpDRL.
Autoencoding Word Representations through Time for Semantic Change Detection
Apr 28, 2020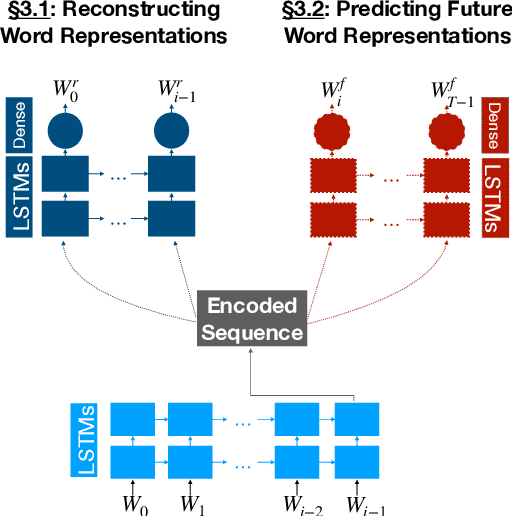
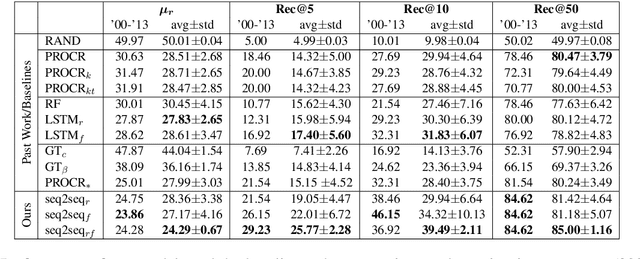
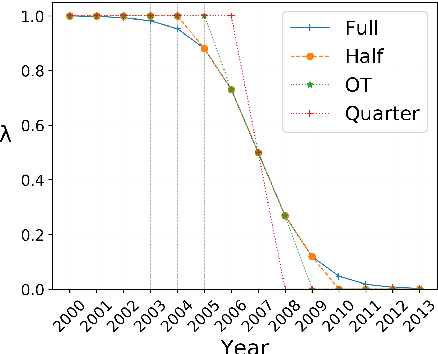
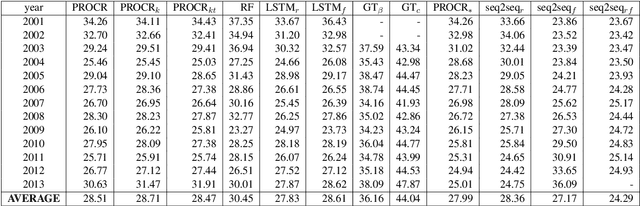
Semantic change detection concerns the task of identifying words whose meaning has changed over time. The current state-of-the-art detects the level of semantic change in a word by comparing its vector representation in two distinct time periods, without considering its evolution through time. In this work, we propose three variants of sequential models for detecting semantically shifted words, effectively accounting for the changes in the word representations over time, in a temporally sensitive manner. Through extensive experimentation under various settings with both synthetic and real data we showcase the importance of sequential modelling of word vectors through time for detecting the words whose semantics have changed the most. Finally, we take a step towards comparing different approaches in a quantitative manner, demonstrating that the temporal modelling of word representations yields a clear-cut advantage in performance.
The Concordance Index decomposition: a measure for a deeper understanding of survival prediction models
Mar 02, 2022
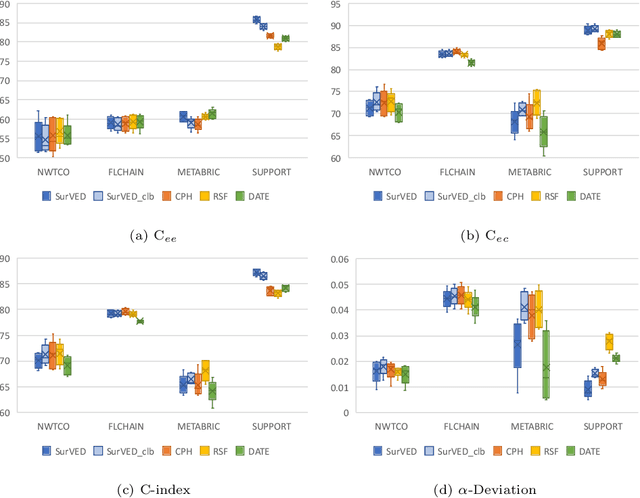
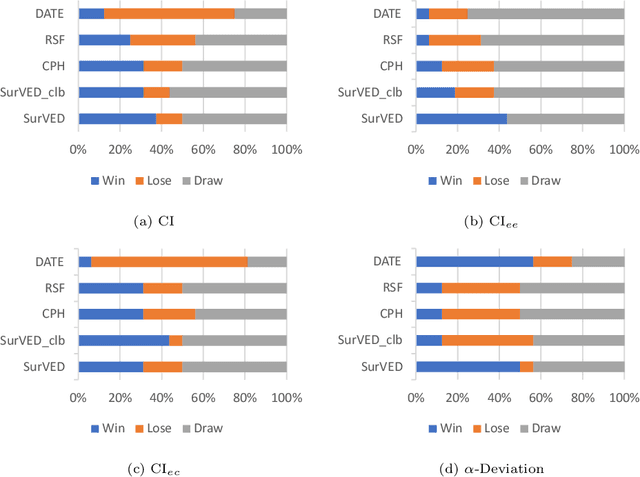

The Concordance Index (C-index) is a commonly used metric in Survival Analysis to evaluate how good a prediction model is. This paper proposes a decomposition of the C-Index into a weighted harmonic mean of two quantities: one for ranking observed events versus other observed events, and the other for ranking observed events versus censored cases. This decomposition allows a more fine-grained analysis of the pros and cons of survival prediction methods. The utility of the decomposition is demonstrated using three benchmark survival analysis models (Cox Proportional Hazard, Random Survival Forest, and Deep Adversarial Time-to-Event Network) together with a new variational generative neural-network-based method (SurVED), which is also proposed in this paper. The demonstration is done on four publicly available datasets with varying censoring levels. The analysis with the C-index decomposition shows that all methods essentially perform equally well when the censoring level is high because of the dominance of the term measuring the ranking of events versus censored cases. In contrast, some methods deteriorate when the censoring level decreases because they do not rank the events versus other events well.
KC-TSS: An Algorithm for Heterogeneous Robot Teams Performing Resilient Target Search
Mar 02, 2022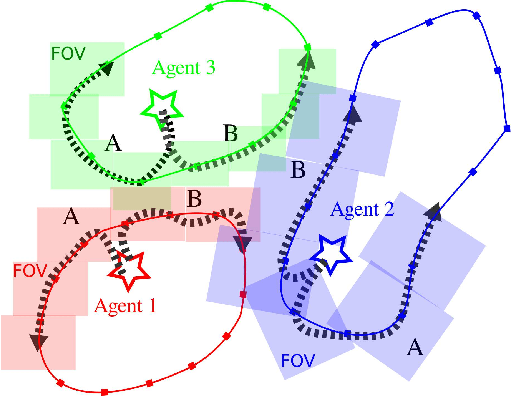
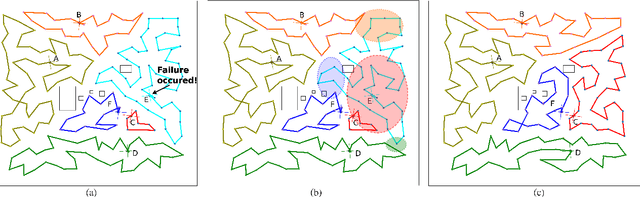
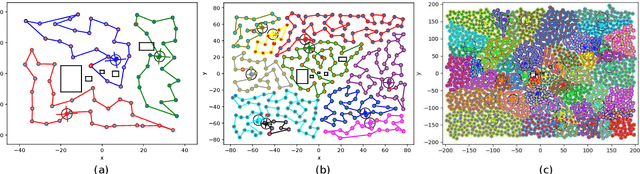
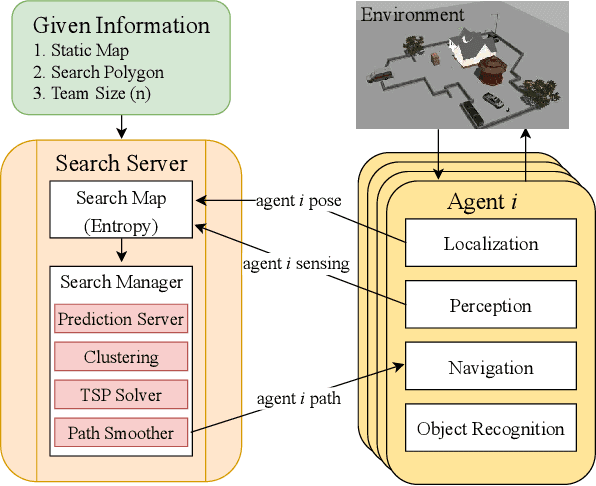
This paper proposes KC-TSS: K-Clustered-Traveling Salesman Based Search, a failure resilient path planning algorithm for heterogeneous robot teams performing target search in human environments. We separate the sample path generation problem into Heterogeneous Clustering and multiple Traveling Salesman Problems. This allows us to provide high-quality candidate paths (i.e. minimal backtracking, overlap) to an Information-Theoretic utility function for each agent. First, we generate waypoint candidates from map knowledge and a target prediction model. All of these candidates are clustered according to the number of agents and their ability to cover space, or coverage competency. Each agent solves a Traveling Salesman Problem (TSP) instance over their assigned cluster and then candidates are fed to a utility function for path selection. We perform extensive Gazebo simulations and preliminary deployment of real robots in indoor search and simulated rescue scenarios with static targets. We compare our proposed method against a state-of-the-art algorithm and show that ours is able to outperform it in mission time. Our method provides resilience in the event of single or multi teammate failure by recomputing global team plans online.