 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GrIPS: Gradient-free, Edit-based Instruction Search for Prompting Large Language Models
Mar 14, 2022




Providing natural language instructions in prompts is a useful new paradigm for improving task performance of large language models in a zero-shot setting. Recent work has aimed to improve such prompts via manual rewriting or gradient-based tuning. However, manual rewriting is time-consuming and requires subjective interpretation, while gradient-based tuning can be extremely computationally demanding for large models and requires full access to model weights, which may not be available for API-based models. In this work, we introduce Gradient-free Instructional Prompt Search (GrIPS), a gradient-free, edit-based search approach for improving task instructions for large language models. GrIPS takes in instructions designed for humans and automatically returns an improved, edited prompt, while allowing for API-based tuning. The instructions in our search are iteratively edited using four operations (delete, add, swap, paraphrase) on text at the phrase-level. With InstructGPT models, GrIPS improves the average task performance by up to 4.30 percentage points on eight classification tasks from the Natural-Instructions dataset. We see improvements for both instruction-only prompts and for k-shot example+instruction prompts. Notably, GrIPS outperforms manual rewriting following the guidelines in Mishra et al. (2022) and also outperforms purely example-based prompts while controlling for the available compute and data budget. Lastly, we provide qualitative analysis of the edited instructions across several scales of GPT models. Our code is available at: https://github.com/archiki/GrIPS
S3T: Self-Supervised Pre-training with Swin Transformer for Music Classification
Feb 21, 2022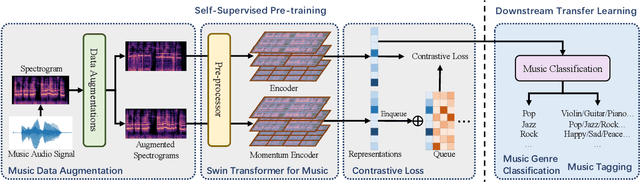
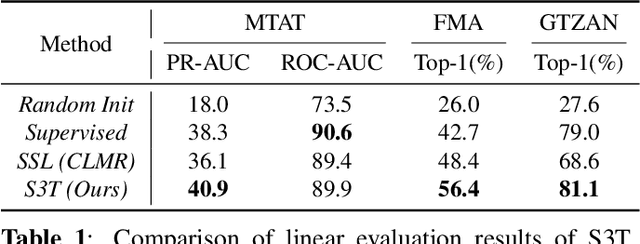
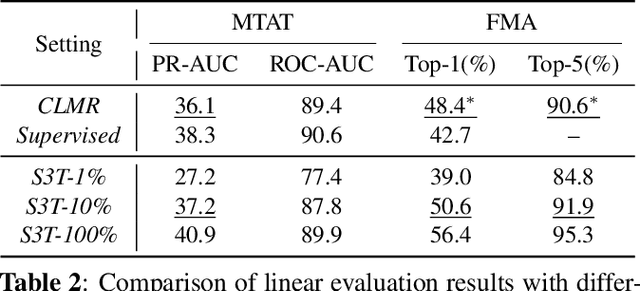
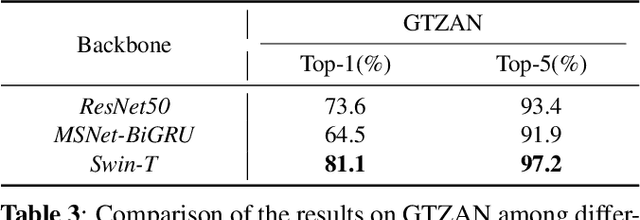
In this paper, we propose S3T, a self-supervised pre-training method with Swin Transformer for music classification, aiming to learn meaningful music representations from massive easily accessible unlabeled music data. S3T introduces a momentum-based paradigm, MoCo, with Swin Transformer as its feature extractor to music time-frequency domain. For better music representations learning, S3T contributes a music data augmentation pipeline and two specially designed pre-processors. To our knowledge, S3T is the first method combining the Swin Transformer with a self-supervised learning method for music classification. We evaluate S3T on music genre classification and music tagging tasks with linear classifiers trained on learned representations. Experimental results show that S3T outperforms the previous self-supervised method (CLMR) by 12.5 percents top-1 accuracy and 4.8 percents PR-AUC on two tasks respectively, and also surpasses the task-specific state-of-the-art supervised methods. Besides, S3T shows advances in label efficiency using only 10% labeled data exceeding CLMR on both tasks with 100% labeled data.
Time-Independent Planning for Multiple Moving Agents
May 27, 2020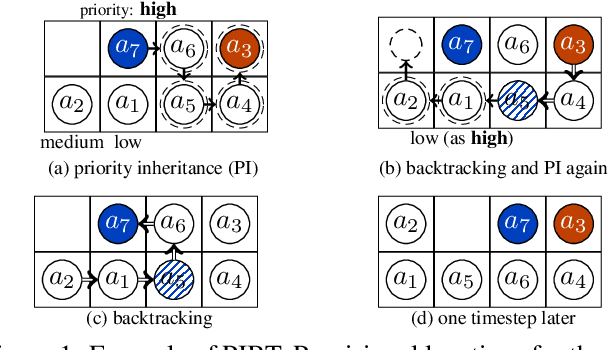

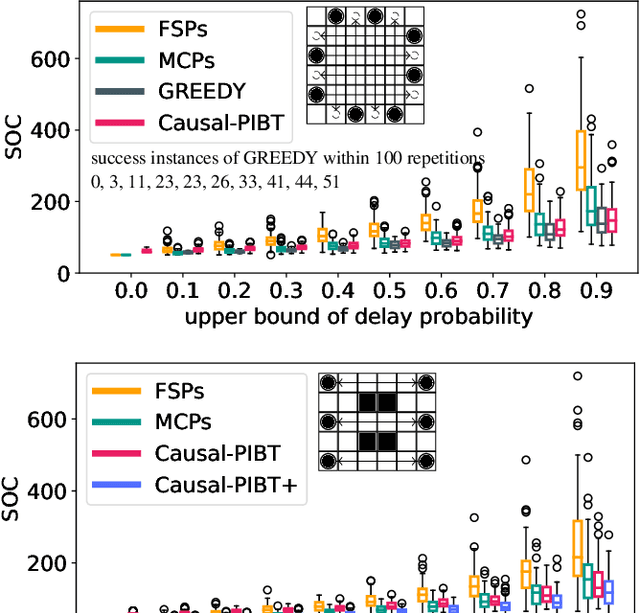
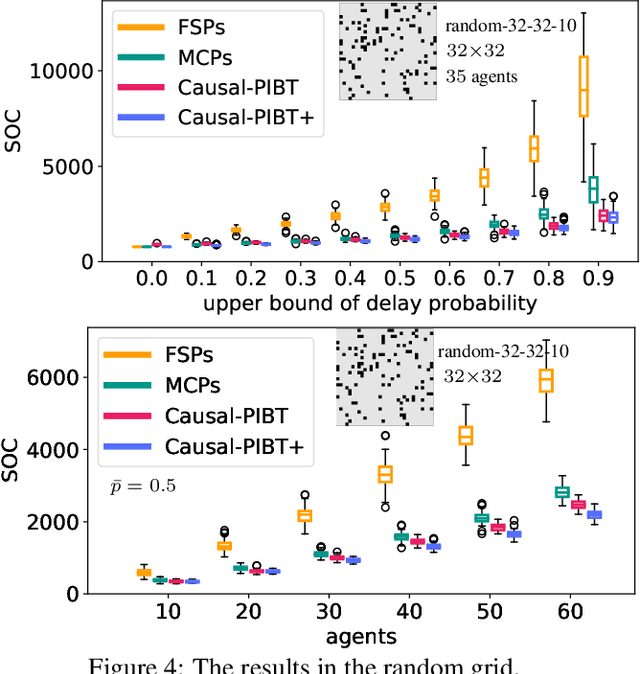
Typical Multi-agent Path Finding (MAPF) solvers assume that agents move synchronously, thus neglecting the reality gap in timing assumptions, e.g., delays caused by an imperfect execution of asynchronous moves. So far, two policies enforce a robust execution of MAPF plans taken as input, namely, either by forcing agents to synchronize, or by executing plans while preserving temporal dependencies. This paper proposes a third approach, called time-independent planning, which is both online and distributed. We represent reality as a transition system that changes configurations according to atomic actions of agents, and use it to generate a time-independent schedule. Empirical results in a simulated environment with stochastic delays of agents' moves support the validity of our proposal.
Systematic Comparison of Path Planning Algorithms using PathBench
Mar 07, 2022
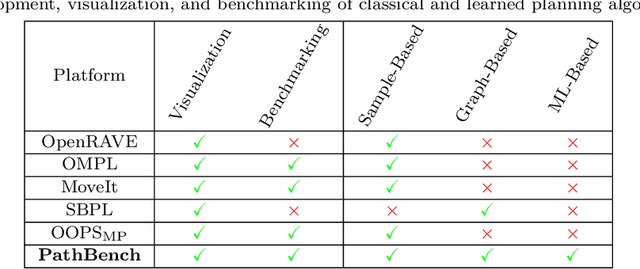
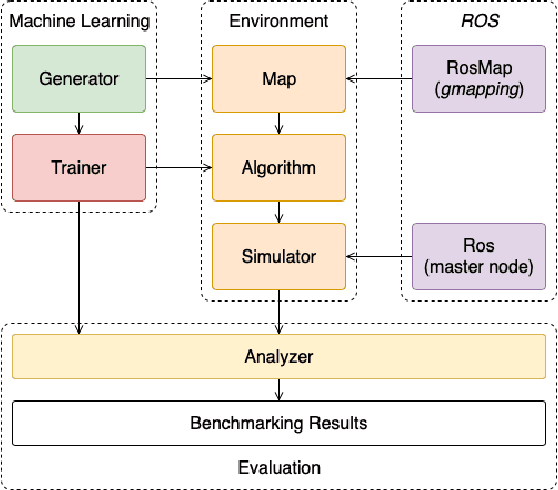
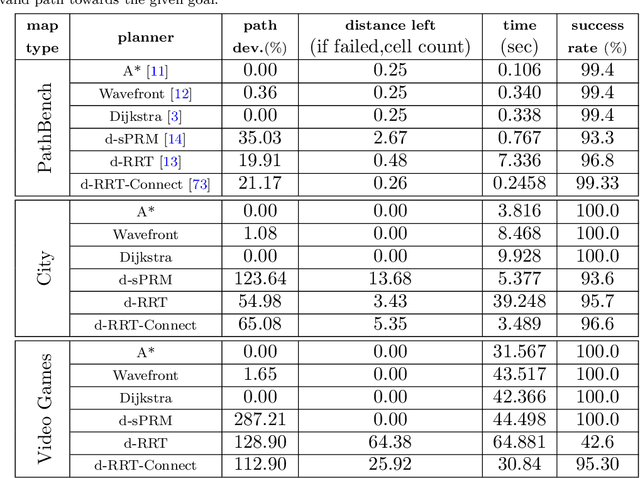
Path planning is an essential component of mobile robotics. Classical path planning algorithms, such as wavefront and rapidly-exploring random tree (RRT) are used heavily in autonomous robots. With the recent advances in machine learning, development of learning-based path planning algorithms has been experiencing rapid growth. An unified path planning interface that facilitates the development and benchmarking of existing and new algorithms is needed. This paper presents PathBench, a platform for developing, visualizing, training, testing, and benchmarking of existing and future, classical and learning-based path planning algorithms in 2D and 3D grid world environments. Many existing path planning algorithms are supported; e.g. A*, Dijkstra, waypoint planning networks, value iteration networks, gated path planning networks; and integrating new algorithms is easy and clearly specified. The benchmarking ability of PathBench is explored in this paper by comparing algorithms across five different hardware systems and three different map types, including built-in PathBench maps, video game maps, and maps from real world databases. Metrics, such as path length, success rate, and computational time, were used to evaluate algorithms. Algorithmic analysis was also performed on a real world robot to demonstrate PathBench's support for Robot Operating System (ROS). PathBench is open source.
ECG synthesis with Neural ODE and GAN models
Oct 30, 2021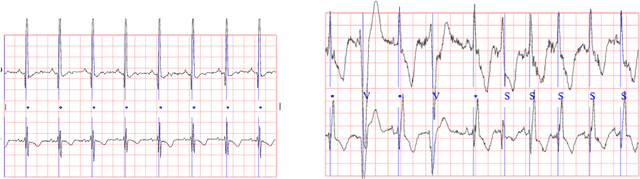

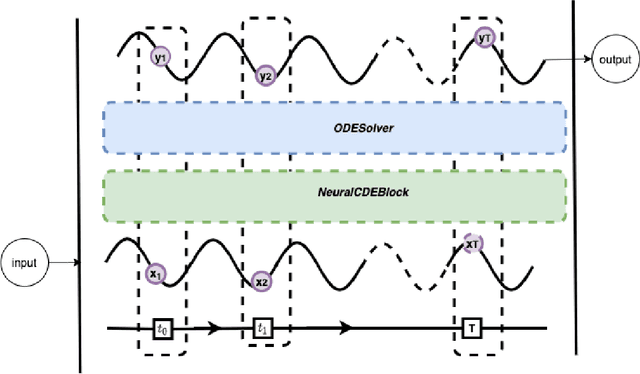
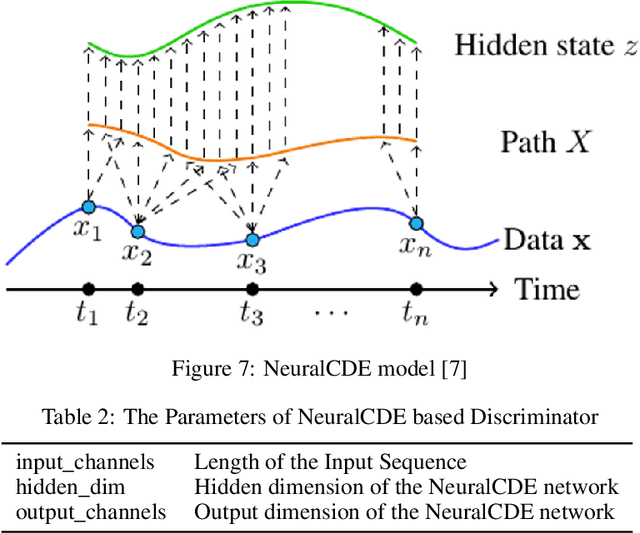
Continuous medical time series data such as ECG is one of the most complex time series due to its dynamic and high dimensional characteristics. In addition, due to its sensitive nature, privacy concerns and legal restrictions, it is often even complex to use actual data for different medical research. As a result, generating continuous medical time series is a very critical research area. Several research works already showed that the ability of generative adversarial networks (GANs) in the case of continuous medical time series generation is promising. Most medical data generation works, such as ECG synthesis, are mainly driven by the GAN model and its variation. On the other hand, Some recent work on Neural Ordinary Differential Equation (Neural ODE) demonstrates its strength against informative missingness, high dimension as well as dynamic nature of continuous time series. Instead of considering continuous-time series as a discrete-time sequence, Neural ODE can train continuous time series in real-time continuously. In this work, we used Neural ODE based model to generate synthetic sine waves and synthetic ECG. We introduced a new technique to design the generative adversarial network with Neural ODE based Generator and Discriminator. We developed three new models to synthesise continuous medical data. Different evaluation metrics are then used to quantitatively assess the quality of generated synthetic data for real-world applications and data analysis. Another goal of this work is to combine the strength of GAN and Neural ODE to generate synthetic continuous medical time series data such as ECG. We also evaluated both the GAN model and the Neural ODE model to understand the comparative efficiency of models from the GAN and Neural ODE family in medical data synthesis.
Ensemble and Multimodal Approach for Forecasting Cryptocurrency Price
Feb 12, 2022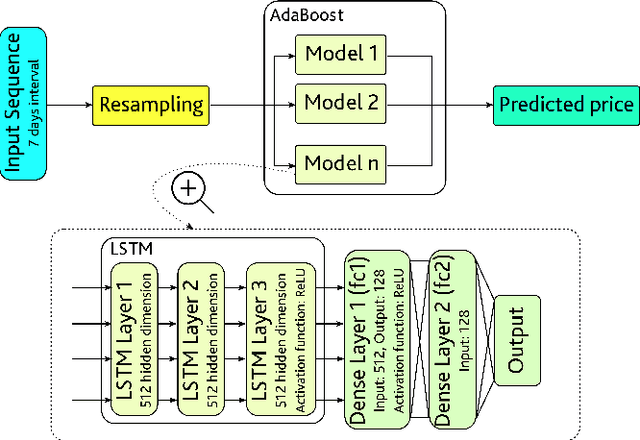
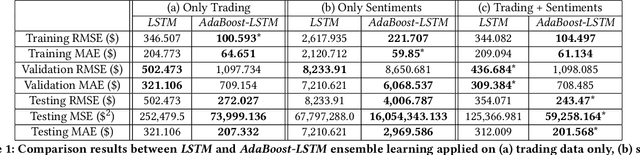
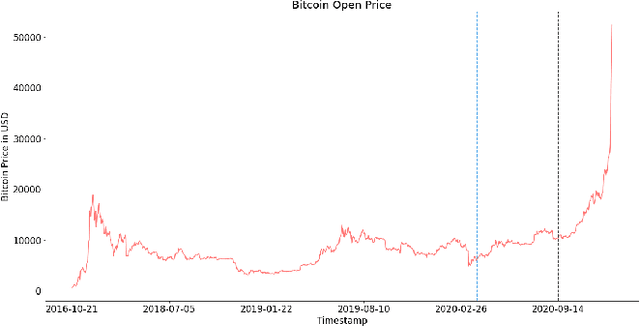
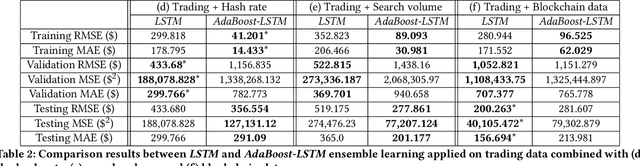
Since the birth of Bitcoin in 2009, cryptocurrencies have emerged to become a global phenomenon and an important decentralized financial asset. Due to this decentralization, the value of these digital currencies against fiat currencies is highly volatile over time. Therefore, forecasting the crypto-fiat currency exchange rate is an extremely challenging task. For reliable forecasting, this paper proposes a multimodal AdaBoost-LSTM ensemble approach that employs all modalities which derive price fluctuation such as social media sentiments, search volumes, blockchain information, and trading data. To better support investment decision making, the approach forecasts also the fluctuation distribution. The conducted extensive experiments demonstrated the effectiveness of relying on multimodalities instead of only trading data. Further experiments demonstrate the outperformance of the proposed approach compared to existing tools and methods with a 19.29% improvement.
Analysis of Langevin Monte Carlo from Poincaré to Log-Sobolev
Dec 23, 2021

Classically, the continuous-time Langevin diffusion converges exponentially fast to its stationary distribution $\pi$ under the sole assumption that $\pi$ satisfies a Poincar\'e inequality. Using this fact to provide guarantees for the discrete-time Langevin Monte Carlo (LMC) algorithm, however, is considerably more challenging due to the need for working with chi-squared or R\'enyi divergences, and prior works have largely focused on strongly log-concave targets. In this work, we provide the first convergence guarantees for LMC assuming that $\pi$ satisfies either a Lata{\l}a--Oleszkiewicz or modified log-Sobolev inequality, which interpolates between the Poincar\'e and log-Sobolev settings. Unlike prior works, our results allow for weak smoothness and do not require convexity or dissipativity conditions.
Autoencoding Word Representations through Time for Semantic Change Detection
Apr 28, 2020
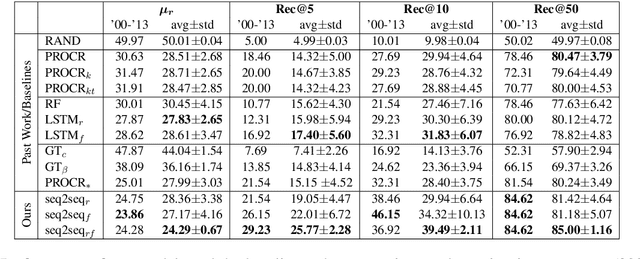
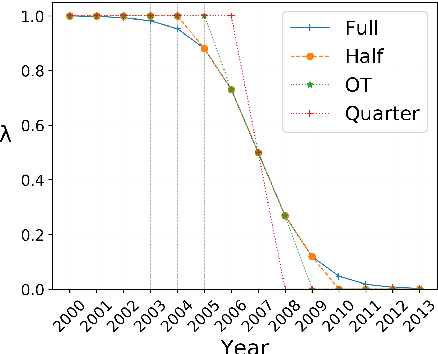
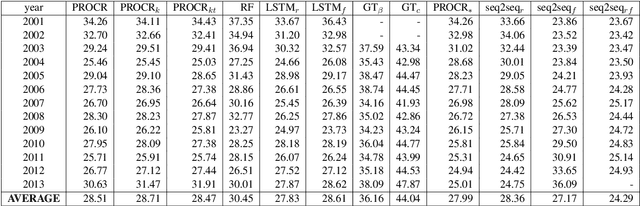
Semantic change detection concerns the task of identifying words whose meaning has changed over time. The current state-of-the-art detects the level of semantic change in a word by comparing its vector representation in two distinct time periods, without considering its evolution through time. In this work, we propose three variants of sequential models for detecting semantically shifted words, effectively accounting for the changes in the word representations over time, in a temporally sensitive manner. Through extensive experimentation under various settings with both synthetic and real data we showcase the importance of sequential modelling of word vectors through time for detecting the words whose semantics have changed the most. Finally, we take a step towards comparing different approaches in a quantitative manner, demonstrating that the temporal modelling of word representations yields a clear-cut advantage in performance.
ADVISE: ADaptive Feature Relevance and VISual Explanations for Convolutional Neural Networks
Mar 02, 2022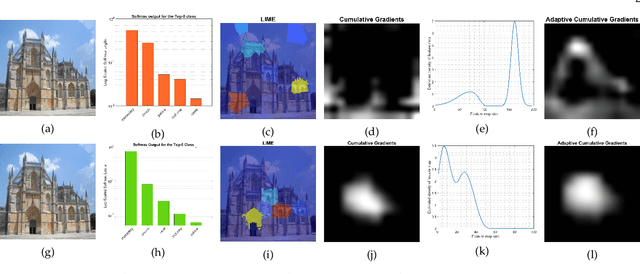
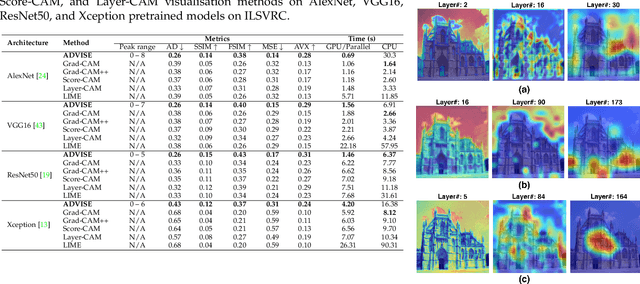
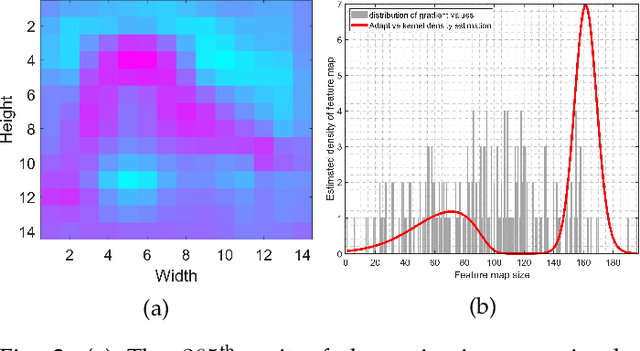
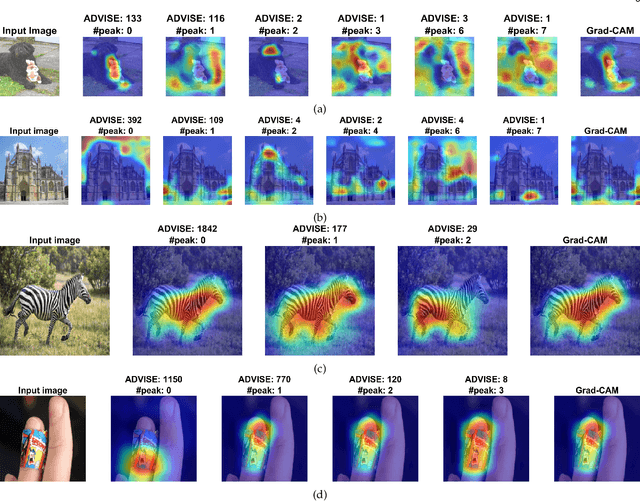
To equip Convolutional Neural Networks (CNNs) with explainability, it is essential to interpret how opaque models take specific decisions, understand what causes the errors, improve the architecture design, and identify unethical biases in the classifiers. This paper introduces ADVISE, a new explainability method that quantifies and leverages the relevance of each unit of the feature map to provide better visual explanations. To this end, we propose using adaptive bandwidth kernel density estimation to assign a relevance score to each unit of the feature map with respect to the predicted class. We also propose an evaluation protocol to quantitatively assess the visual explainability of CNN models. We extensively evaluate our idea in the image classification task using AlexNet, VGG16, ResNet50, and Xception pretrained on ImageNet. We compare ADVISE with the state-of-the-art visual explainable methods and show that the proposed method outperforms competing approaches in quantifying feature-relevance and visual explainability while maintaining competitive time complexity. Our experiments further show that ADVISE fulfils the sensitivity and implementation independence axioms while passing the sanity checks. The implementation is accessible for reproducibility purposes on https://github.com/dehshibi/ADVISE.
Signal Decomposition Using Masked Proximal Operators
Mar 02, 2022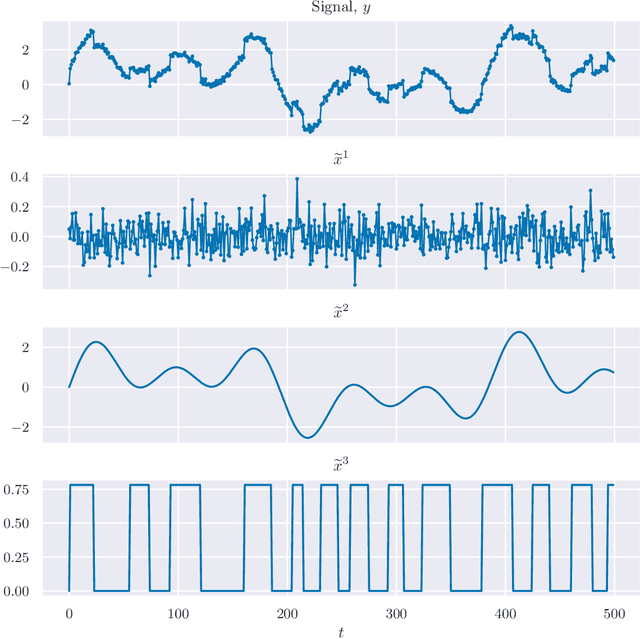
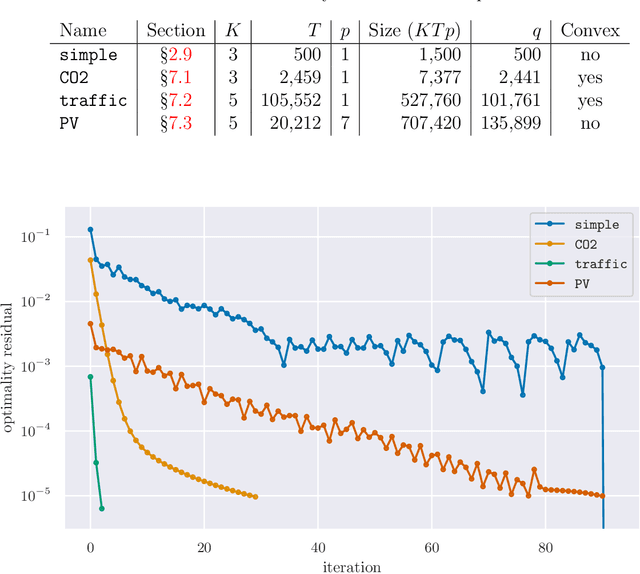
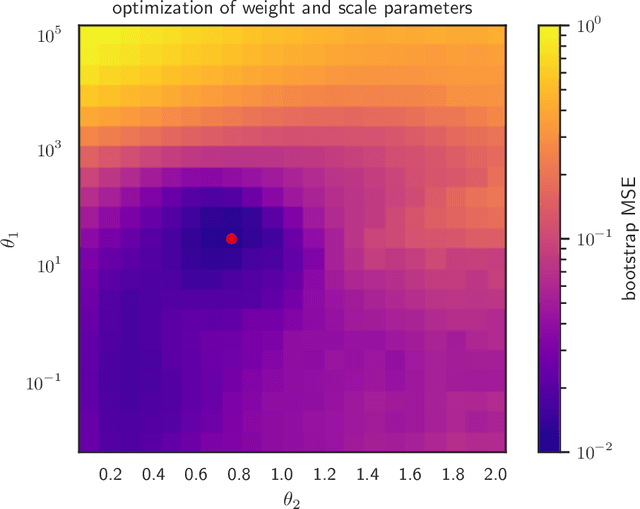
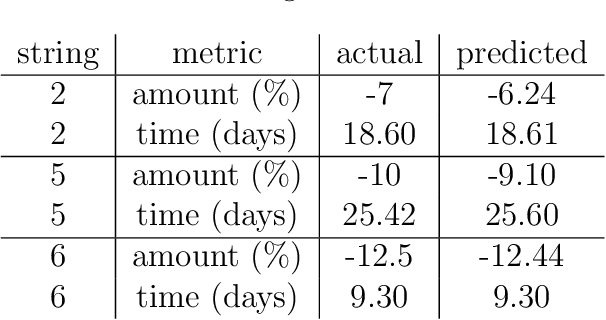
We consider the well-studied problem of decomposing a vector time series signal into components with different characteristics, such as smooth, periodic, nonnegative, or sparse. We propose a simple and general framework in which the components are defined by loss functions (which include constraints), and the signal decomposition is carried out by minimizing the sum of losses of the components (subject to the constraints). When each loss function is the negative log-likelihood of a density for the signal component, our method coincides with maximum a posteriori probability (MAP) estimation; but it also includes many other interesting cases. We give two distributed optimization methods for computing the decomposition, which find the optimal decomposition when the component class loss functions are convex, and are good heuristics when they are not. Both methods require only the masked proximal operator of each of the component loss functions, a generalization of the well-known proximal operator that handles missing entries in its argument. Both methods are distributed, i.e., handle each component separately. We derive tractable methods for evaluating the masked proximal operators of some loss functions that, to our knowledge, have not appeared in the literature.