 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Submodlib: A Submodular Optimization Library
Feb 23, 2022
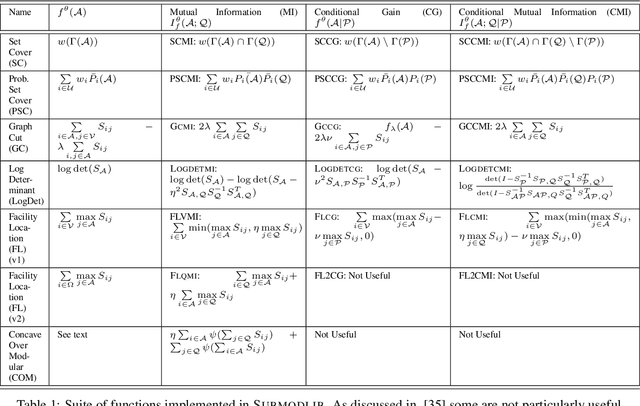

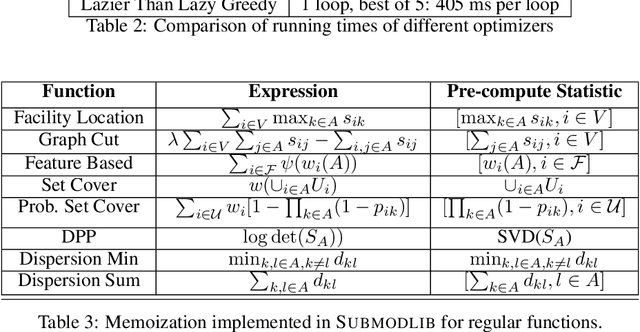
Submodular functions are a special class of set functions which naturally model the notion of representativeness, diversity, coverage etc. and have been shown to be computationally very efficient. A lot of past work has applied submodular optimization to find optimal subsets in various contexts. Some examples include data summarization for efficient human consumption, finding effective smaller subsets of training data to reduce the model development time (training, hyper parameter tuning), finding effective subsets of unlabeled data to reduce the labeling costs, etc. A recent work has also leveraged submodular functions to propose submodular information measures which have been found to be very useful in solving the problems of guided subset selection and guided summarization. In this work, we present Submodlib which is an open-source, easy-to-use, efficient and scalable Python library for submodular optimization with a C++ optimization engine. Submodlib finds its application in summarization, data subset selection, hyper parameter tuning, efficient training and more. Through a rich API, it offers a great deal of flexibility in the way it can be used. Source of Submodlib is available at https://github.com/decile-team/submodlib.
ArgSciChat: A Dataset for Argumentative Dialogues on Scientific Papers
Feb 18, 2022

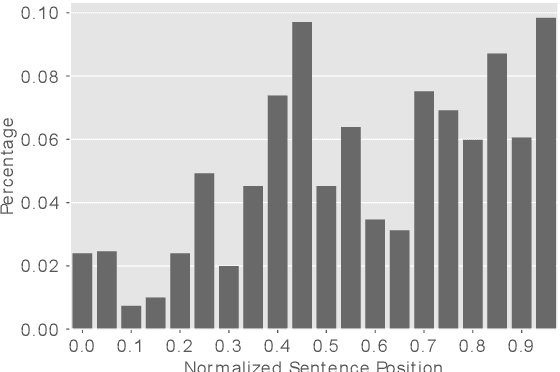
The applications of conversational agents for scientific disciplines (as expert domains) are understudied due to the lack of dialogue data to train such agents. While most data collection frameworks, such as Amazon Mechanical Turk, foster data collection for generic domains by connecting crowd workers and task designers, these frameworks are not much optimized for data collection in expert domains. Scientists are rarely present in these frameworks due to their limited time budget. Therefore, we introduce a novel framework to collect dialogues between scientists as domain experts on scientific papers. Our framework lets scientists present their scientific papers as groundings for dialogues and participate in dialogue they like its paper title. We use our framework to collect a novel argumentative dialogue dataset, ArgSciChat. It consists of 498 messages collected from 41 dialogues on 20 scientific papers. Alongside extensive analysis on ArgSciChat, we evaluate a recent conversational agent on our dataset. Experimental results show that this agent poorly performs on ArgSciChat, motivating further research on argumentative scientific agents. We release our framework and the dataset.
PageRank Algorithm using Eigenvector Centrality -- New Approach
Jan 13, 2022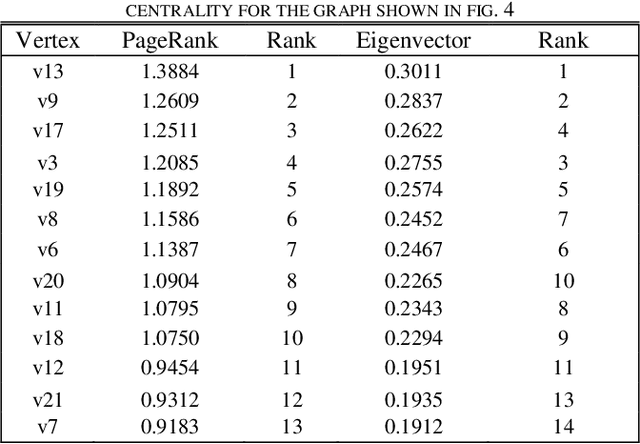
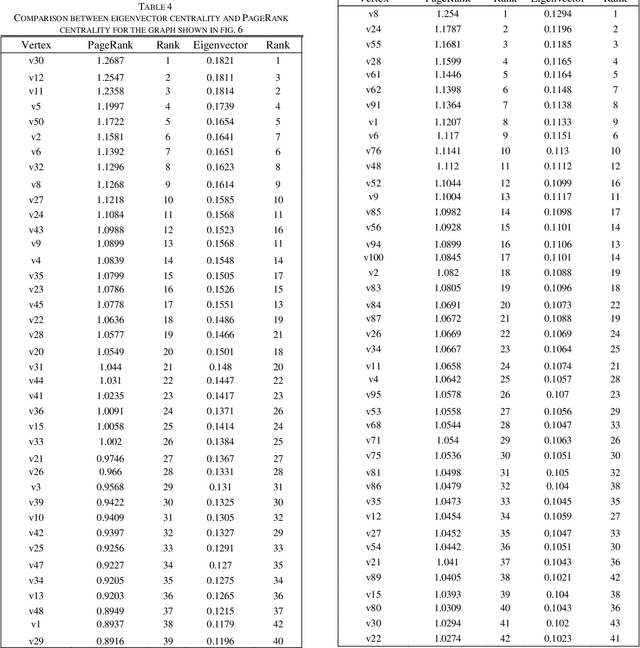
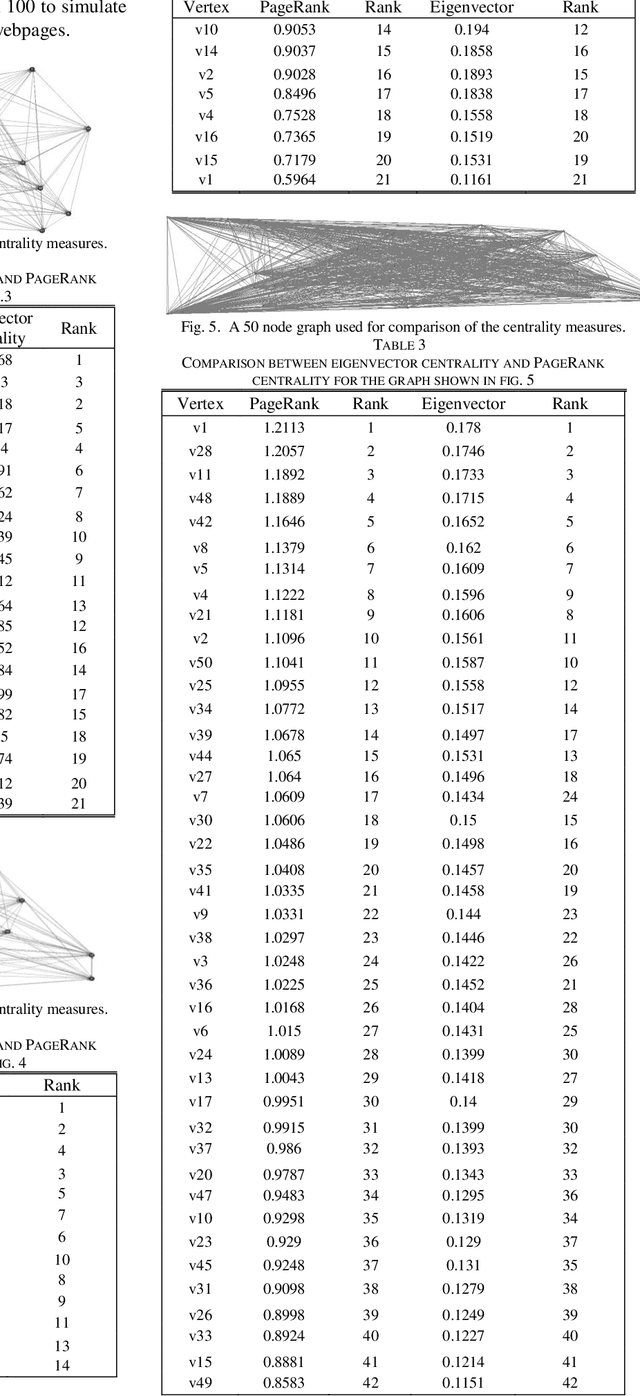
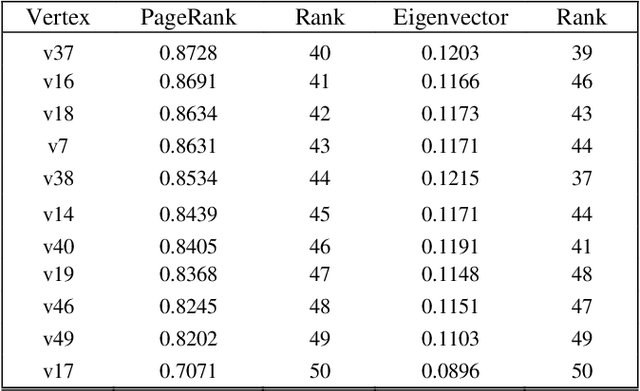
The purpose of the research is to find a centrality measure that can be used in place of PageRank and to find out the conditions where we can use it in place of PageRank. After analysis and comparison of graphs with a large number of nodes using Spearman's Rank Coefficient Correlation, the conclusion is evident that Eigenvector can be safely used in place of PageRank in directed networks to improve the performance in terms of the time complexity.
Joint Sensing and Communication Rates Control for Energy Efficient Mobile Crowd Sensing
Jan 29, 2022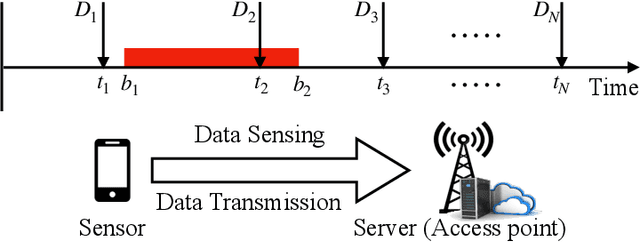
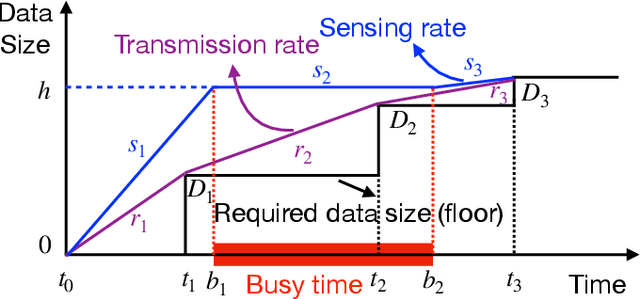
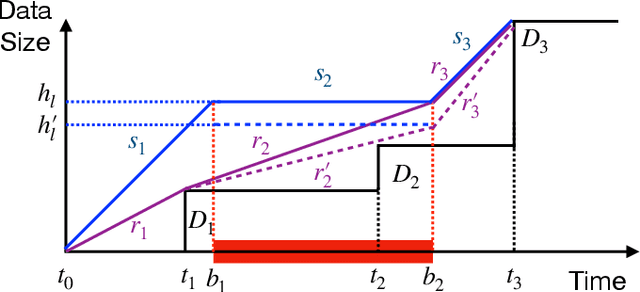
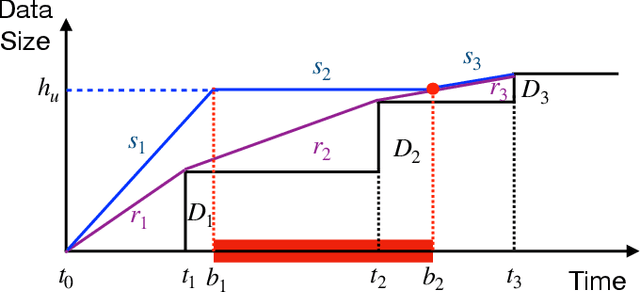
Driven by the fast development of Internet of Things (IoT) applications, tremendous data need to be collected by sensors and passed to the servers for further process. As a promising solution, the mobile crowd sensing (MCS) enables controllable sensing and transmission processes for multiple types of data in a single device. To achieve the energy efficient MCS, the data sensing and transmission over a long-term time duration should be designed accounting for the differentiated requirements of IoT tasks including data size and delay tolerance. The said design is achieved by jointly optimizing the sensing and transmission rates, which leads to a complex optimization problem due to the restraining relationship between the controlling variables as well as the existence of busy time interval during which no data can be sensed. To deal with such problem, a vital concept namely height is introduced, based on which the classical string-pulling algorithms can be applied for obtaining the corresponding optimal sensing and transmission rates. Therefore, the original rates optimization problem can be converted to a searching problem for the optimal height. Based on the property of the objective function, the upper and lower bounds of the area where the optimal height lies in are derived. The whole searching area is further divided into a series of sub-areas due to the format change of the objective function with the varying heights. Finally, the optimal height in each sub-area is obtained based on the convexity of the objective function and the global optimal height is further determined by comparing the local optimums. The above solving approach is further extended for the case with limited data buffer capacity of the server. Simulations are conducted to evaluate the performance of the proposed design.
An Evolutionary Game for Mobile User Access Mode Selection in sub-$6$ GHz/mmWave Cellular Networks
Jan 10, 2022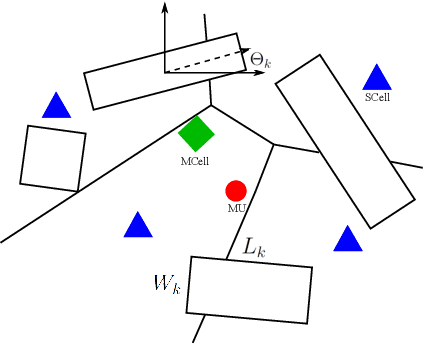
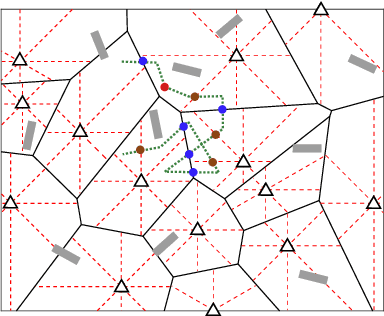
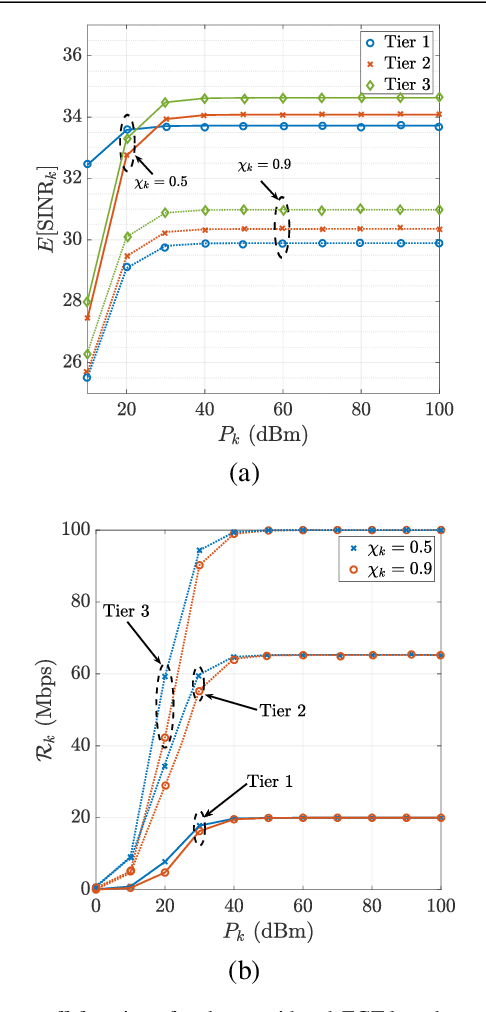
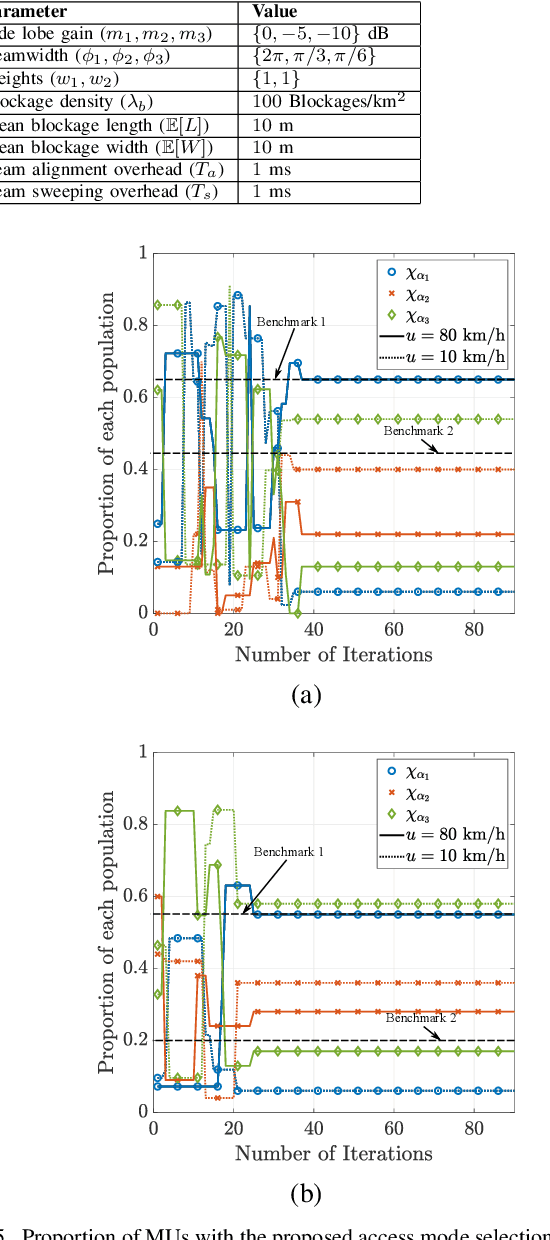
By utilizing the combination of two powerful tools i.e., stochastic geometry (SG) and evolutionary game theory (EGT), in this paper, we study the problem of mobile user (MU) mode selection in heterogeneous sub-$6$ GHz/millimeter wave (mmWave) cellular networks. Particularly, by using SG tools, we first propose an analytical framework to assess the performance of the considered networks in terms of average signal-to-interference-plus-noise (SINR) ratio, average rate, and mobility-induced time overhead, for scenarios with user mobility{.} According to the SG-based framework, an EGT-based approach is presented to solve the problem of access mode selection. Specifically, two EGT-based models are considered, where for each MU its utility function depends on the average SINR and the average rate, respectively, while the time overhead is considered as a penalty term. A distributed algorithm is proposed to reach the evolutionary equilibrium, where the existence and stability of the equilibrium is theoretically analyzed and proved. Moreover, we extend the formulation by considering information delay exchange and evaluate its impact on the convergence of the proposed algorithm. Our results reveal that the proposed technique can offer better spectral efficiency and connectivity in heterogeneous sub-$6$ GHz/mmWave cellular networks with mobility, compared with the conventional access mode selection techniques.
Toward Data-Driven STAP Radar
Jan 26, 2022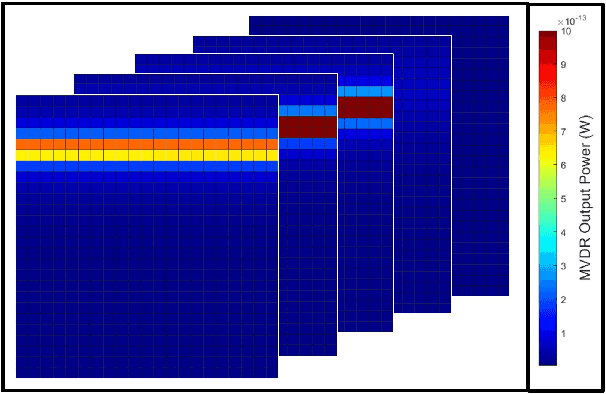
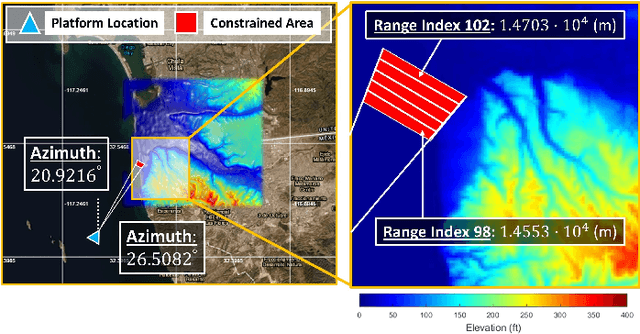
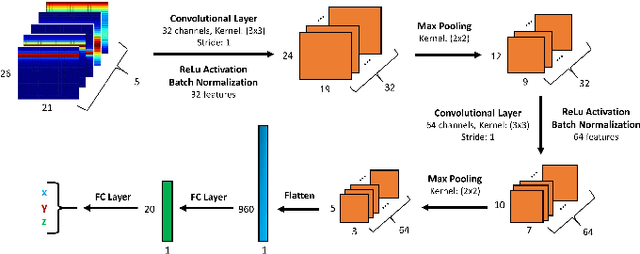
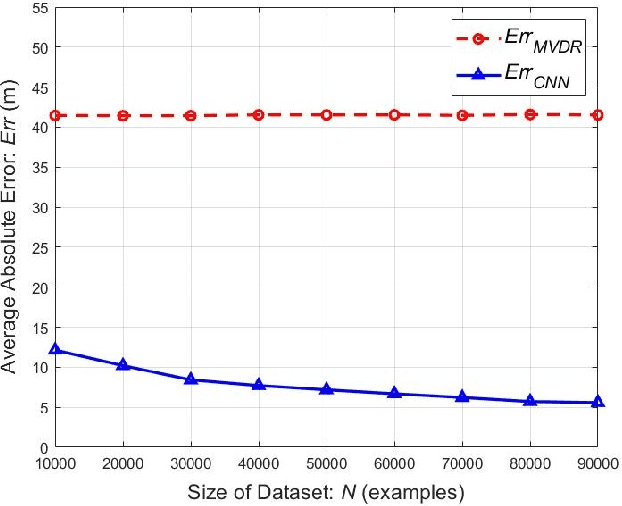
Using an amalgamation of techniques from classical radar, computer vision, and deep learning, we characterize our ongoing data-driven approach to space-time adaptive processing (STAP) radar. We generate a rich example dataset of received radar signals by randomly placing targets of variable strengths in a predetermined region using RFView, a site-specific radio frequency modeling and simulation tool developed by ISL Inc. For each data sample within this region, we generate heatmap tensors in range, azimuth, and elevation of the output power of a minimum variance distortionless response (MVDR) beamformer, which can be replaced with a desired test statistic. These heatmap tensors can be thought of as stacked images, and in an airborne scenario, the moving radar creates a sequence of these time-indexed image stacks, resembling a video. Our goal is to use these images and videos to detect targets and estimate their locations, a procedure reminiscent of computer vision algorithms for object detection$-$namely, the Faster Region-Based Convolutional Neural Network (Faster R-CNN). The Faster R-CNN consists of a proposal generating network for determining regions of interest (ROI), a regression network for positioning anchor boxes around targets, and an object classification algorithm; it is developed and optimized for natural images. Our ongoing research will develop analogous tools for heatmap images of radar data. In this regard, we will generate a large, representative adaptive radar signal processing database for training and testing, analogous in spirit to the COCO dataset for natural images. As a preliminary example, we present a regression network in this paper for estimating target locations to demonstrate the feasibility of and significant improvements provided by our data-driven approach.
ESAN: Efficient Sentiment Analysis Network of A-Shares Research Reports for Stock Price Prediction
Dec 03, 2021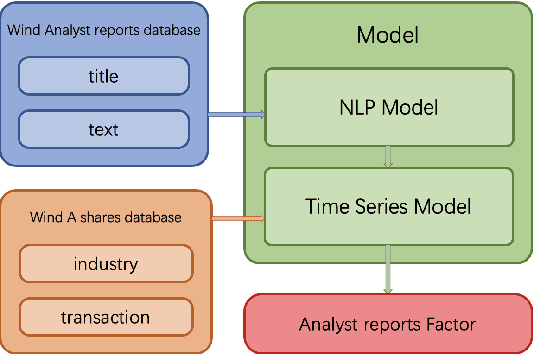
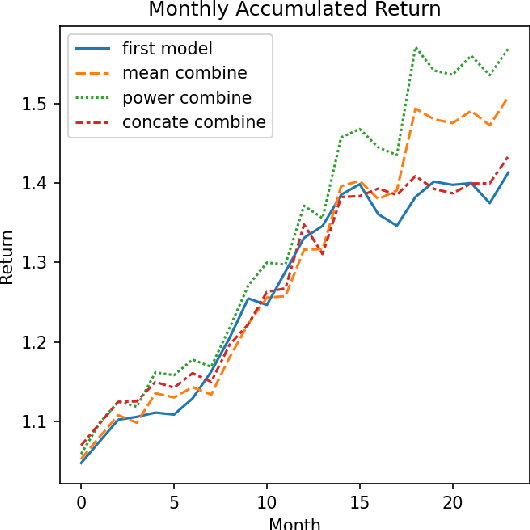
In this paper, we are going to develop a natural language processing model to help us to predict stocks in the long term. The whole network includes two modules. The first module is a natural language processing model which seeks out reliable factors from input reports. While the other is a time-series forecasting model which takes the factors as input and aims to predict stocks earnings yield. To indicate the efficiency of our model to combine the sentiment analysis module and the time-series forecasting module, we name our method ESAN.
When is the Convergence Time of Langevin Algorithms Dimension Independent? A Composite Optimization Viewpoint
Oct 05, 2021There has been a surge of works bridging MCMC sampling and optimization, with a specific focus on translating non-asymptotic convergence guarantees for optimization problems into the analysis of Langevin algorithms in MCMC sampling. A conspicuous distinction between the convergence analysis of Langevin sampling and that of optimization is that all known convergence rates for Langevin algorithms depend on the dimensionality of the problem, whereas the convergence rates for optimization are dimension-free for convex problems. Whether a dimension independent convergence rate can be achieved by Langevin algorithm is thus a long-standing open problem. This paper provides an affirmative answer to this problem for large classes of either Lipschitz or smooth convex problems with normal priors. By viewing Langevin algorithm as composite optimization, we develop a new analysis technique that leads to dimension independent convergence rates for such problems.
Ensemble Methods for Survival Data with Time-Varying Covariates
May 31, 2020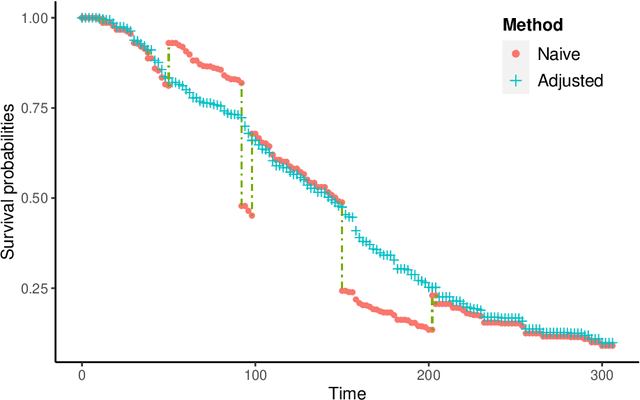
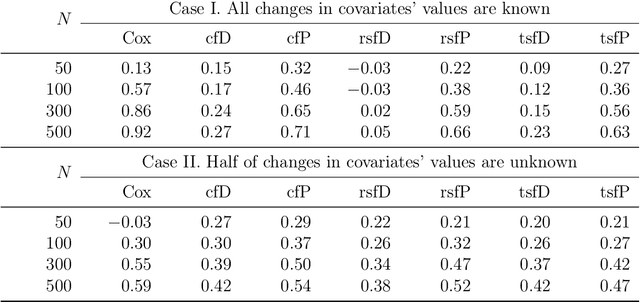
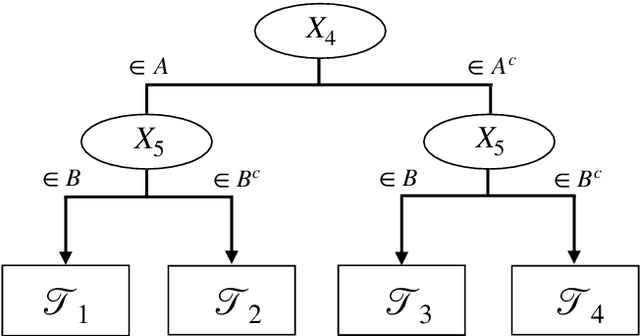
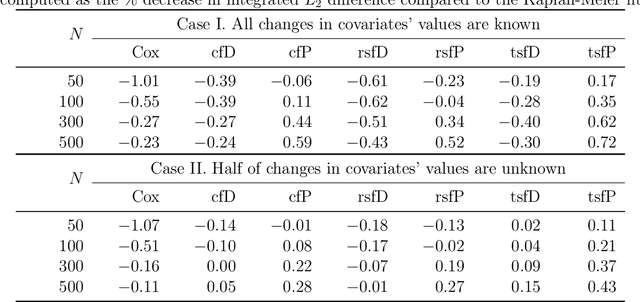
We propose two new survival forests for survival data with time-varying covariates. They are generalizations of random survival forest and conditional inference forest -- the traditional survival forests for right-censored data with time-invariant covariates. We investigate the properties of these new forests, as well as that of the recently-proposed transformation forest, and compare their performances with that of the Cox model via a comprehensive simulation study. In particular, the simulations compare the performance of the forests when all changes in the covariates' values are known with the case when not all changes are known. We also study the forests under the proportional hazards setting as well as the non-proportional hazards setting, where the forests based on log-rank splitting tend to perform worse than does the transformation forest. We then provide guidance for choosing among the modeling methods. Finally, we show that the performance of the survival forests for time-invariant covariate data is broadly similar to that found for time-varying covariate data.
Adversarial Fine-tuning for Backdoor Defense: Connect Adversarial Examples to Triggered Samples
Feb 13, 2022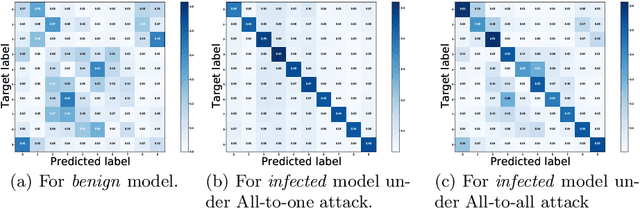

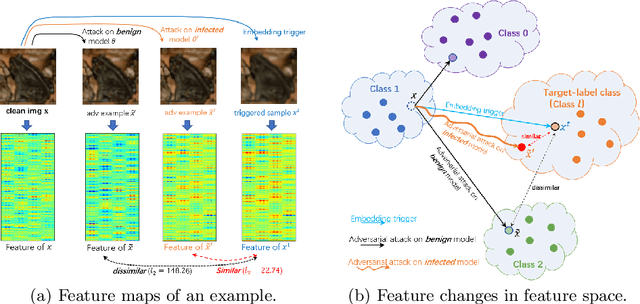

Deep neural networks (DNNs) are known to be vulnerable to backdoor attacks, i.e., a backdoor trigger planted at training time, the infected DNN model would misclassify any testing sample embedded with the trigger as target label. Due to the stealthiness of backdoor attacks, it is hard either to detect or erase the backdoor from infected models. In this paper, we propose a new Adversarial Fine-Tuning (AFT) approach to erase backdoor triggers by leveraging adversarial examples of the infected model. For an infected model, we observe that its adversarial examples have similar behaviors as its triggered samples. Based on such observation, we design the AFT to break the foundation of the backdoor attack (i.e., the strong correlation between a trigger and a target label). We empirically show that, against 5 state-of-the-art backdoor attacks, AFT can effectively erase the backdoor triggers without obvious performance degradation on clean samples, which significantly outperforms existing defense methods.