 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SmartON: Just-in-Time Active Event Detection on Energy Harvesting Systems
Mar 01, 2021
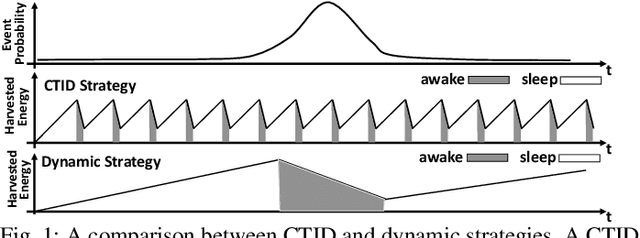
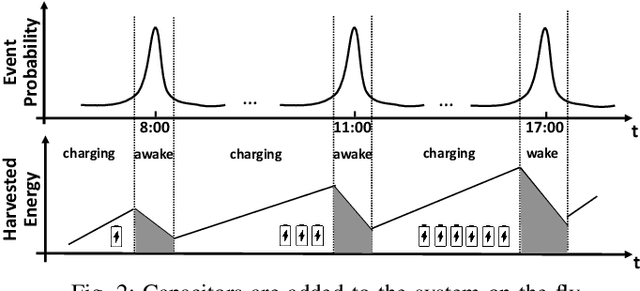
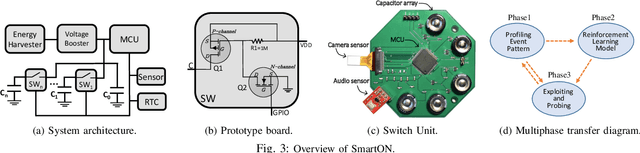
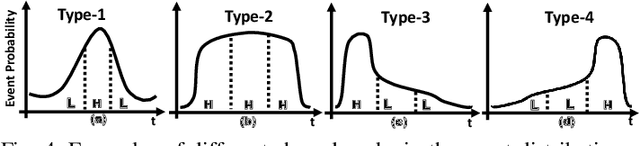
We propose SmartON, a batteryless system that learns to wake up proactively at the right moment in order to detect events of interest. It does so by adapting the duty cycle to match the distribution of event arrival times under the constraints of harvested energy. While existing energy harvesting systems either wake up periodically at a fixed rate to sense and process the data, or wake up only in accordance with the availability of the energy source, SmartON employs a three-phase learning framework to learn the energy harvesting pattern as well as the pattern of events at run-time, and uses that knowledge to wake itself up when events are most likely to occur. The three-phase learning framework enables rapid adaptation to environmental changes in both short and long terms. Being able to remain asleep more often than a CTID (charging-then-immediate-discharging) wake-up system and adapt to the event pattern, SmartON is able to reduce energy waste, increase energy efficiency, and capture more events. To realize SmartON we have developed a dedicated hardware platform whose power management module activates capacitors on-the-fly to dynamically increase its storage capacitance. We conduct both simulation-driven and real-system experiments to demonstrate that SmartON captures 1X--7X more events and is 8X--17X more energy-efficient than a CTID system.
Scaling Laws Under the Microscope: Predicting Transformer Performance from Small Scale Experiments
Feb 13, 2022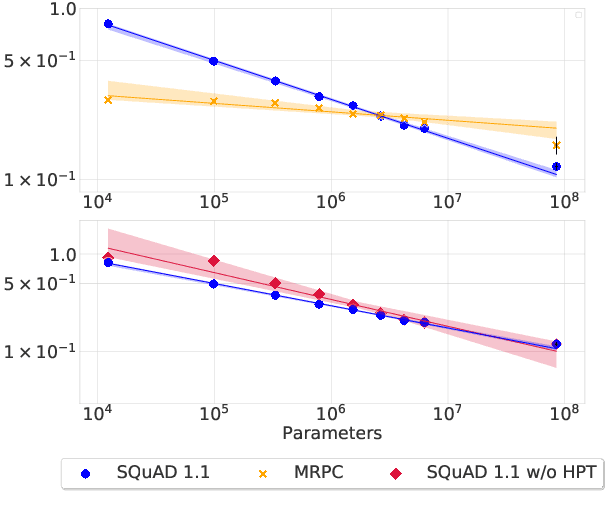
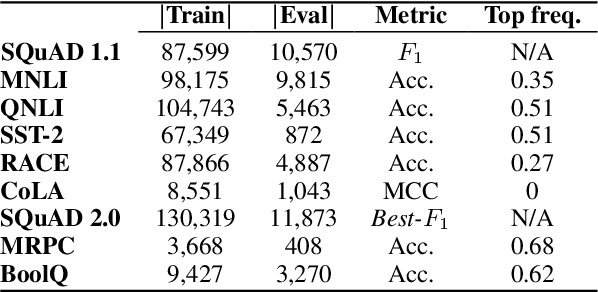
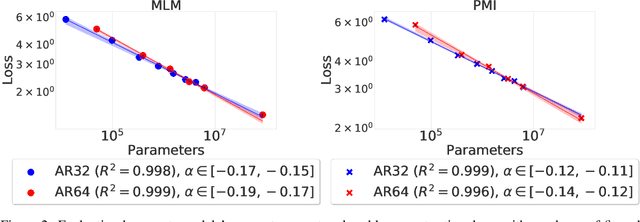
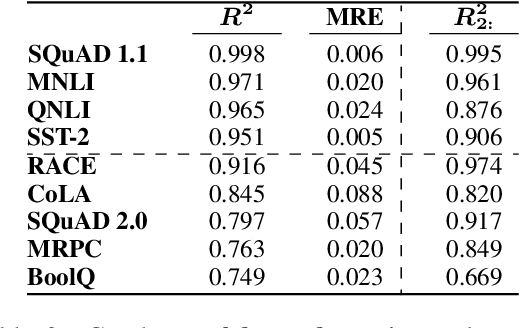
Neural scaling laws define a predictable relationship between a model's parameter count and its performance after training in the form of a power law. However, most research to date has not explicitly investigated whether scaling laws can be used to accelerate model development. In this work, we perform such an empirical investigation across a wide range of language understanding tasks, starting from models with as few as 10K parameters, and evaluate downstream performance across 9 language understanding tasks. We find that scaling laws emerge at finetuning time in some NLP tasks, and that they can also be exploited for debugging convergence when training large models. Moreover, for tasks where scaling laws exist, they can be used to predict the performance of larger models, which enables effective model selection. However, revealing scaling laws requires careful hyperparameter tuning and multiple runs for the purpose of uncertainty estimation, which incurs additional overhead, partially offsetting the computational benefits.
GMC -- Geometric Multimodal Contrastive Representation Learning
Feb 08, 2022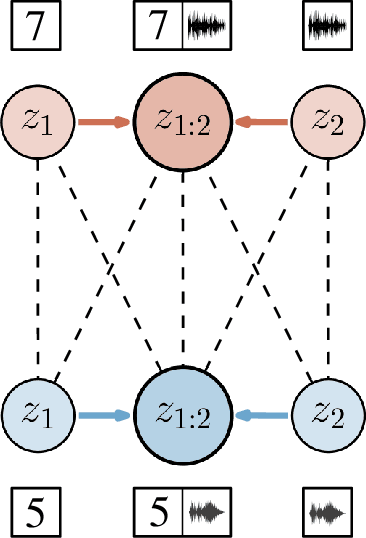



Learning representations of multimodal data that are both informative and robust to missing modalities at test time remains a challenging problem due to the inherent heterogeneity of data obtained from different channels. To address it, we present a novel Geometric Multimodal Contrastive (GMC) representation learning method comprised of two main components: i) a two-level architecture consisting of modality-specific base encoder, allowing to process an arbitrary number of modalities to an intermediate representation of fixed dimensionality, and a shared projection head, mapping the intermediate representations to a latent representation space; ii) a multimodal contrastive loss function that encourages the geometric alignment of the learned representations. We experimentally demonstrate that GMC representations are semantically rich and achieve state-of-the-art performance with missing modality information on three different learning problems including prediction and reinforcement learning tasks.
Submodlib: A Submodular Optimization Library
Feb 23, 2022
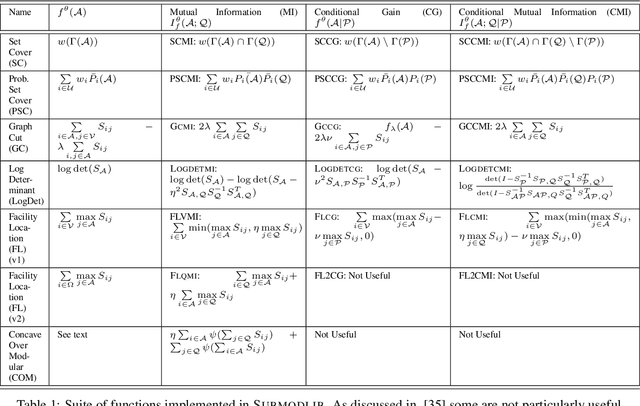

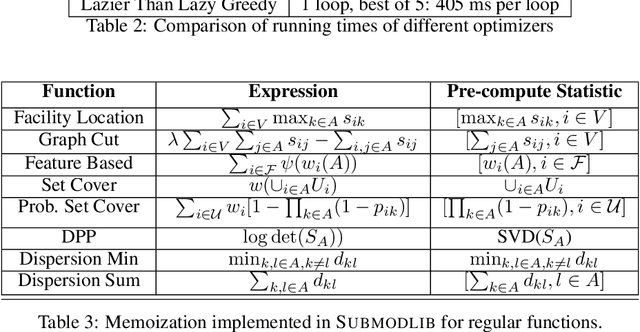
Submodular functions are a special class of set functions which naturally model the notion of representativeness, diversity, coverage etc. and have been shown to be computationally very efficient. A lot of past work has applied submodular optimization to find optimal subsets in various contexts. Some examples include data summarization for efficient human consumption, finding effective smaller subsets of training data to reduce the model development time (training, hyper parameter tuning), finding effective subsets of unlabeled data to reduce the labeling costs, etc. A recent work has also leveraged submodular functions to propose submodular information measures which have been found to be very useful in solving the problems of guided subset selection and guided summarization. In this work, we present Submodlib which is an open-source, easy-to-use, efficient and scalable Python library for submodular optimization with a C++ optimization engine. Submodlib finds its application in summarization, data subset selection, hyper parameter tuning, efficient training and more. Through a rich API, it offers a great deal of flexibility in the way it can be used. Source of Submodlib is available at https://github.com/decile-team/submodlib.
RePOSE: Real-Time Iterative Rendering and Refinement for 6D Object Pose Estimation
Apr 01, 2021
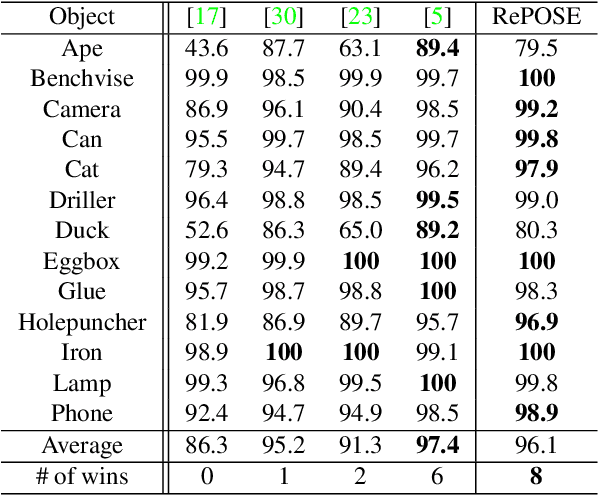
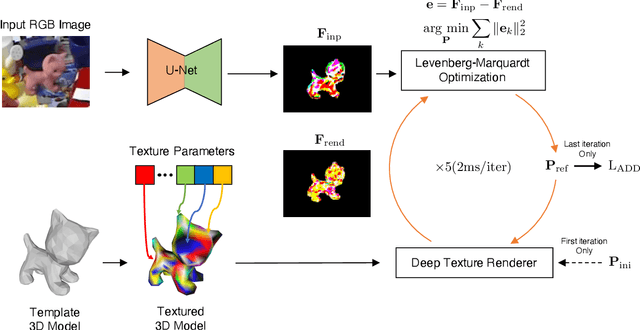
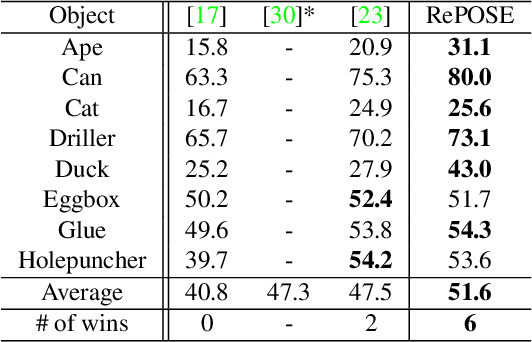
The use of iterative pose refinement is a critical processing step for 6D object pose estimation, and its performance depends greatly on one's choice of image representation. Image representations learned via deep convolutional neural networks (CNN) are currently the method of choice as they are able to robustly encode object keypoint locations. However, CNN-based image representations are computational expensive to use for iterative pose refinement, as they require that image features are extracted using a deep network, once for the input image and multiple times for rendered images during the refinement process. Instead of using a CNN to extract image features from a rendered RGB image, we propose to directly render a deep feature image. We call this deep texture rendering, where a shallow multi-layer perceptron is used to directly regress a view invariant image representation of an object. Using an estimate of the pose and deep texture rendering, our system can render an image representation in under 1ms. This image representation is optimized such that it makes it easier to perform nonlinear 6D pose estimation by adding a differentiable Levenberg-Marquardt optimization network and back-propagating the 6D pose alignment error. We call our method, RePOSE, a Real-time Iterative Rendering and Refinement algorithm for 6D POSE estimation. RePOSE runs at 71 FPS and achieves state-of-the-art accuracy of 51.6% on the Occlusion LineMOD dataset - a 4.1% absolute improvement over the prior art, and comparable performance on the YCB-Video dataset with a much faster runtime than the other pose refinement methods.
ArgSciChat: A Dataset for Argumentative Dialogues on Scientific Papers
Feb 18, 2022

The applications of conversational agents for scientific disciplines (as expert domains) are understudied due to the lack of dialogue data to train such agents. While most data collection frameworks, such as Amazon Mechanical Turk, foster data collection for generic domains by connecting crowd workers and task designers, these frameworks are not much optimized for data collection in expert domains. Scientists are rarely present in these frameworks due to their limited time budget. Therefore, we introduce a novel framework to collect dialogues between scientists as domain experts on scientific papers. Our framework lets scientists present their scientific papers as groundings for dialogues and participate in dialogue they like its paper title. We use our framework to collect a novel argumentative dialogue dataset, ArgSciChat. It consists of 498 messages collected from 41 dialogues on 20 scientific papers. Alongside extensive analysis on ArgSciChat, we evaluate a recent conversational agent on our dataset. Experimental results show that this agent poorly performs on ArgSciChat, motivating further research on argumentative scientific agents. We release our framework and the dataset.
Supervised learning on heterogeneous, attributed entities interacting over time
Jul 22, 2020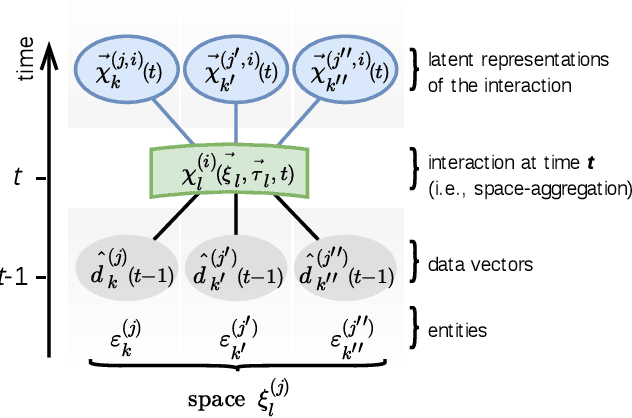
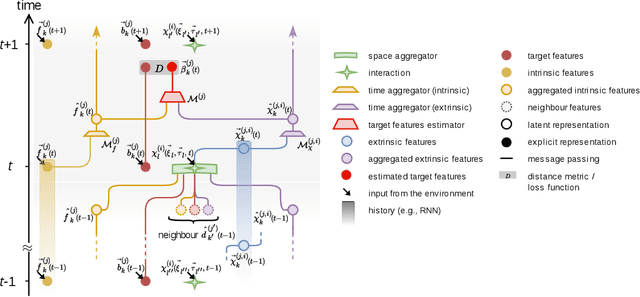

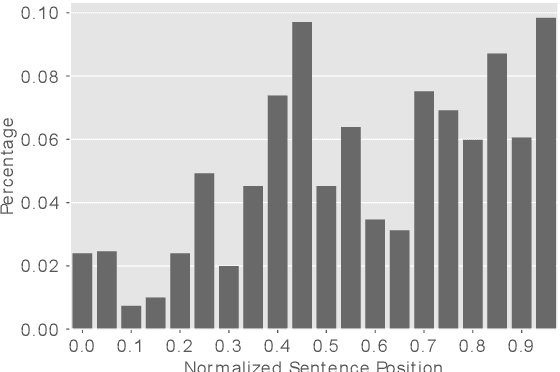
Most physical or social phenomena can be represented by ontologies where the constituent entities are interacting in various ways with each other and with their environment. Furthermore, those entities are likely heterogeneous and attributed with features that evolve dynamically in time as a response to their successive interactions. In order to apply machine learning on such entities, e.g., for classification purposes, one therefore needs to integrate the interactions into the feature engineering in a systematic way. This proposal shows how, to this end, the current state of graph machine learning remains inadequate and needs to be be augmented with a comprehensive feature engineering paradigm in space and time.
Targeted Data Poisoning Attack on News Recommendation System by Content Perturbation
Mar 10, 2022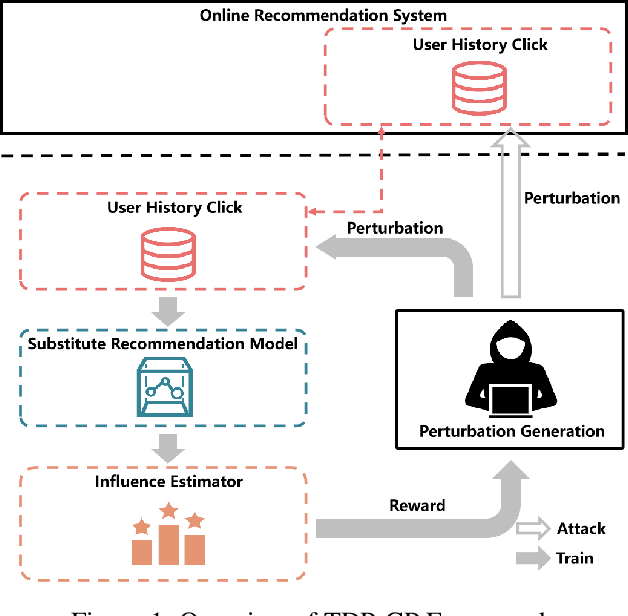
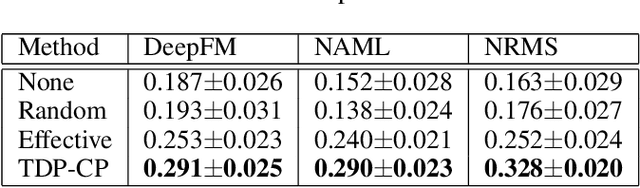
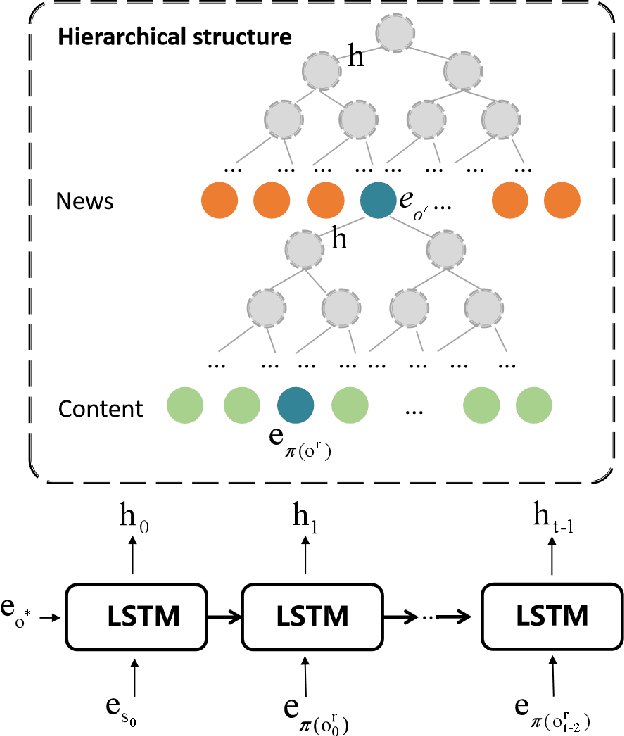
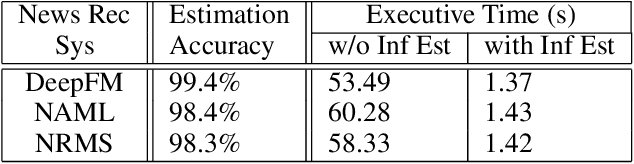
News Recommendation System(NRS) has become a fundamental technology to many online news services. Meanwhile, several studies show that recommendation systems(RS) are vulnerable to data poisoning attacks, and the attackers have the ability to mislead the system to perform as their desires. A widely studied attack approach, injecting fake users, can be applied on the NRS when the NRS is treated the same as the other systems whose items are fixed. However, in the NRS, as each item (i.e. news) is more informative, we propose a novel approach to poison the NRS, which is to perturb contents of some browsed news that results in the manipulation of the rank of the target news. Intuitively, an attack is useless if it is highly likely to be caught, i.e., exposed. To address this, we introduce a notion of the exposure risk and propose a novel problem of attacking a history news dataset by means of perturbations where the goal is to maximize the manipulation of the target news rank while keeping the risk of exposure under a given budget. We design a reinforcement learning framework, called TDP-CP, which contains a two-stage hierarchical model to reduce the searching space. Meanwhile, influence estimation is also applied to save the time on retraining the NRS for rewards. We test the performance of TDP-CP under three NRSs and on different target news. Our experiments show that TDP-CP can increase the rank of the target news successfully with a limited exposure budget.
Joint Sensing and Communication Rates Control for Energy Efficient Mobile Crowd Sensing
Jan 29, 2022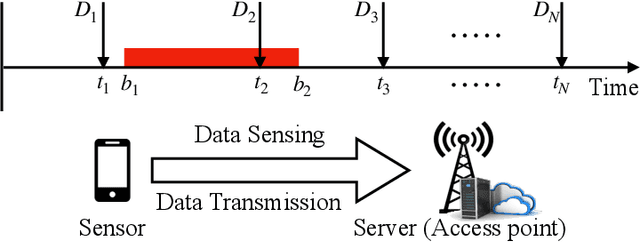
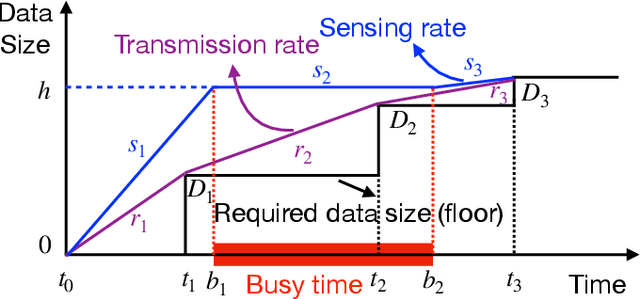
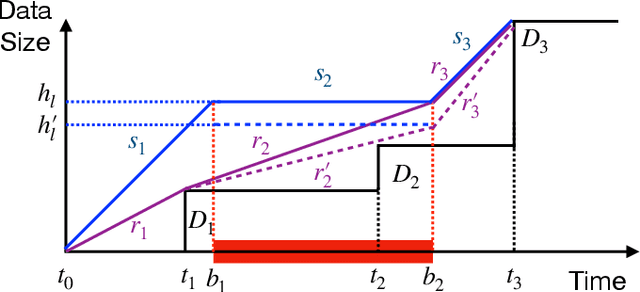
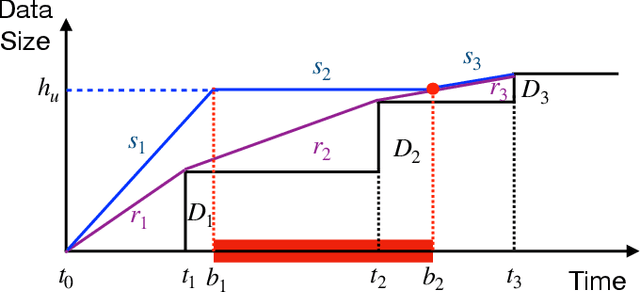
Driven by the fast development of Internet of Things (IoT) applications, tremendous data need to be collected by sensors and passed to the servers for further process. As a promising solution, the mobile crowd sensing (MCS) enables controllable sensing and transmission processes for multiple types of data in a single device. To achieve the energy efficient MCS, the data sensing and transmission over a long-term time duration should be designed accounting for the differentiated requirements of IoT tasks including data size and delay tolerance. The said design is achieved by jointly optimizing the sensing and transmission rates, which leads to a complex optimization problem due to the restraining relationship between the controlling variables as well as the existence of busy time interval during which no data can be sensed. To deal with such problem, a vital concept namely height is introduced, based on which the classical string-pulling algorithms can be applied for obtaining the corresponding optimal sensing and transmission rates. Therefore, the original rates optimization problem can be converted to a searching problem for the optimal height. Based on the property of the objective function, the upper and lower bounds of the area where the optimal height lies in are derived. The whole searching area is further divided into a series of sub-areas due to the format change of the objective function with the varying heights. Finally, the optimal height in each sub-area is obtained based on the convexity of the objective function and the global optimal height is further determined by comparing the local optimums. The above solving approach is further extended for the case with limited data buffer capacity of the server. Simulations are conducted to evaluate the performance of the proposed design.
A Methodology for a Scalable, Collaborative, and Resource-Efficient Platform to Facilitate Healthcare AI Research
Dec 13, 2021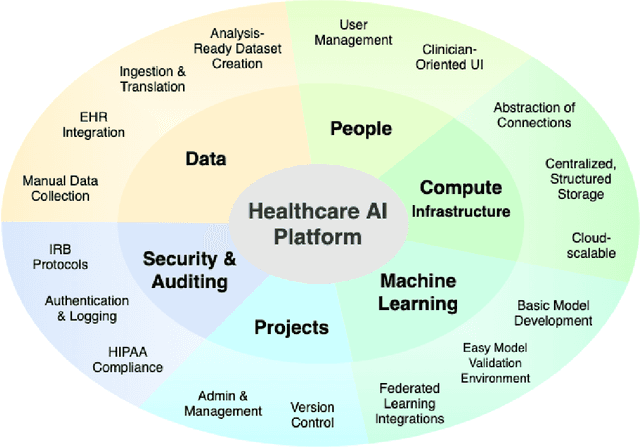
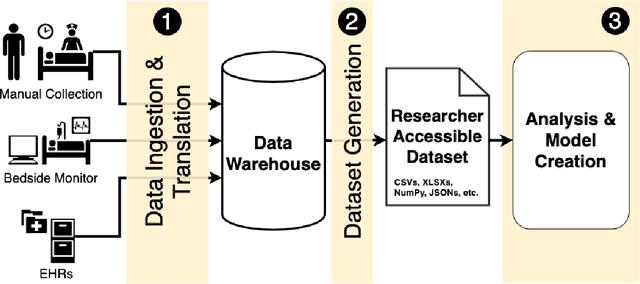
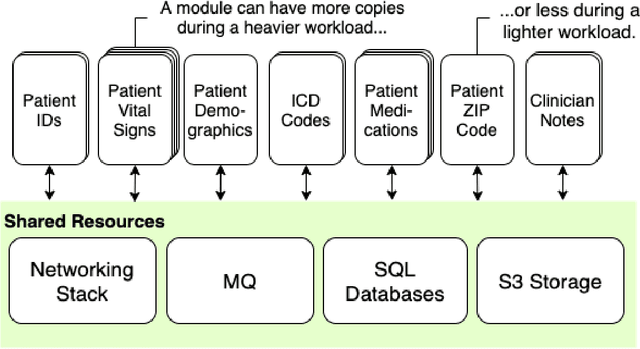
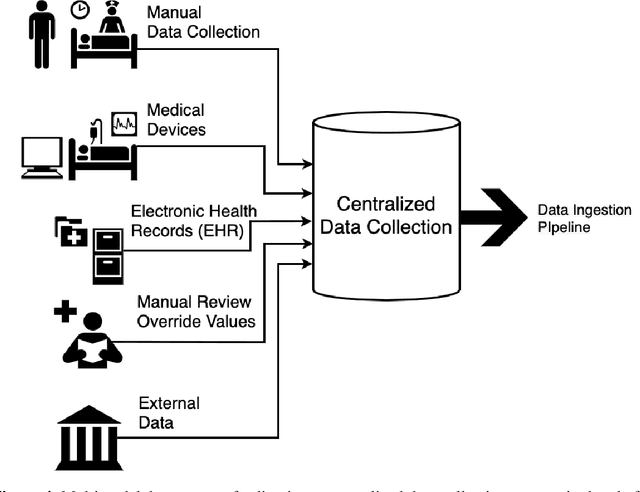
Healthcare AI holds the potential to increase patient safety, augment efficiency and improve patient outcomes, yet research is often limited by data access, cohort curation, and tooling for analysis. Collection and translation of electronic health record data, live data, and real-time high resolution device data can be challenging and time-consuming. The development of real-world AI tools requires overcoming challenges in data acquisition, scarce hospital resources and high needs for data governance. These bottlenecks may result in resource-heavy needs and long delays in research and development of AI systems. We present a system and methodology to accelerate data acquisition, dataset development and analysis, and AI model development. We created an interactive platform that relies on a scalable microservice backend. This system can ingest 15,000 patient records per hour, where each record represents thousands of multimodal measurements, text notes, and high resolution data. Collectively, these records can approach a terabyte of data. The system can further perform cohort generation and preliminary dataset analysis in 2-5 minutes. As a result, multiple users can collaborate simultaneously to iterate on datasets and models in real time. We anticipate that this approach will drive real-world AI model development, and, in the long run, meaningfully improve healthcare delivery.