 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Comparative Study of Deep Reinforcement Learning-based Transferable Energy Management Strategies for Hybrid Electric Vehicles
Feb 22, 2022
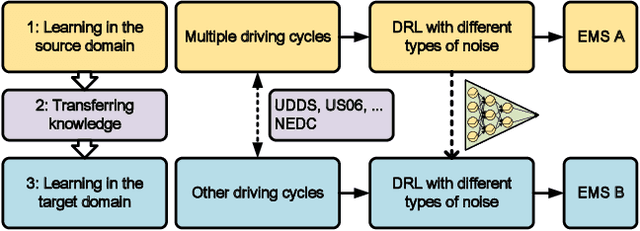
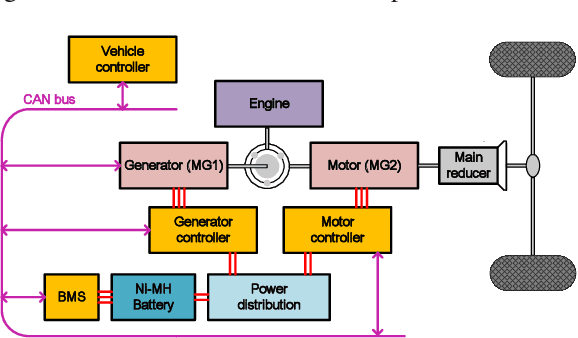
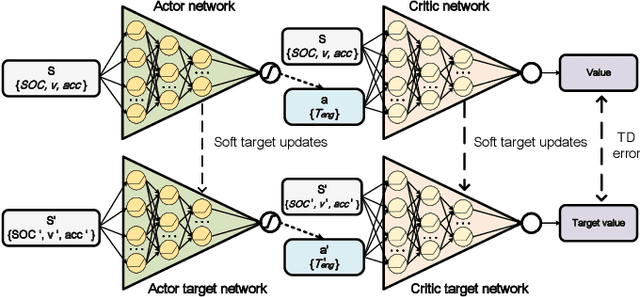
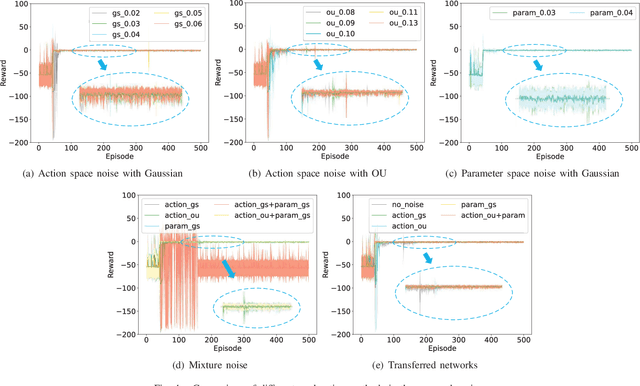
The deep reinforcement learning-based energy management strategies (EMS) has become a promising solution for hybrid electric vehicles (HEVs). When driving cycles are changed, the network will be retrained, which is a time-consuming and laborious task. A more efficient way of choosing EMS is to combine deep reinforcement learning (DRL) with transfer learning, which can transfer knowledge of one domain to the other new domain, making the network of the new domain reach convergence values quickly. Different exploration methods of RL, including adding action space noise and parameter space noise, are compared against each other in the transfer learning process in this work. Results indicate that the network added parameter space noise is more stable and faster convergent than the others. In conclusion, the best exploration method for transferable EMS is to add noise in the parameter space, while the combination of action space noise and parameter space noise generally performs poorly. Our code is available at https://github.com/BIT-XJY/RL-based-Transferable-EMS.git.
Force-matching Coarse-Graining without Forces
Mar 21, 2022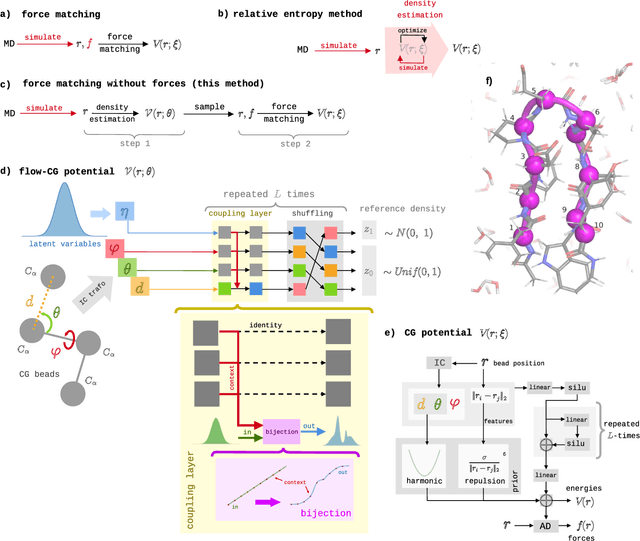
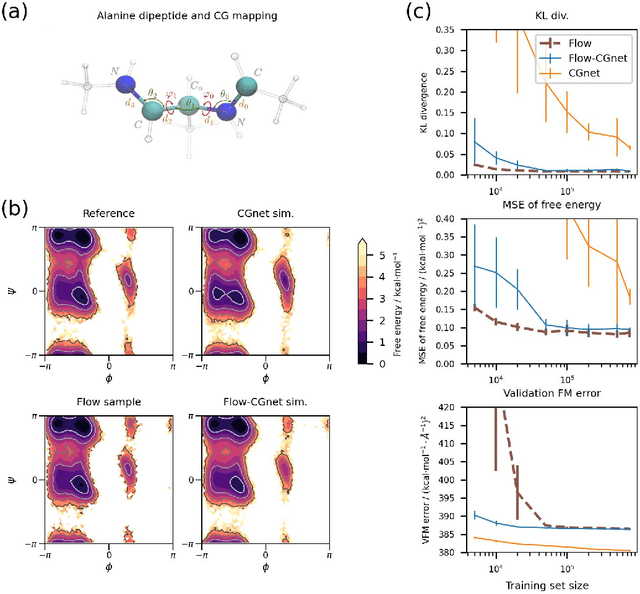
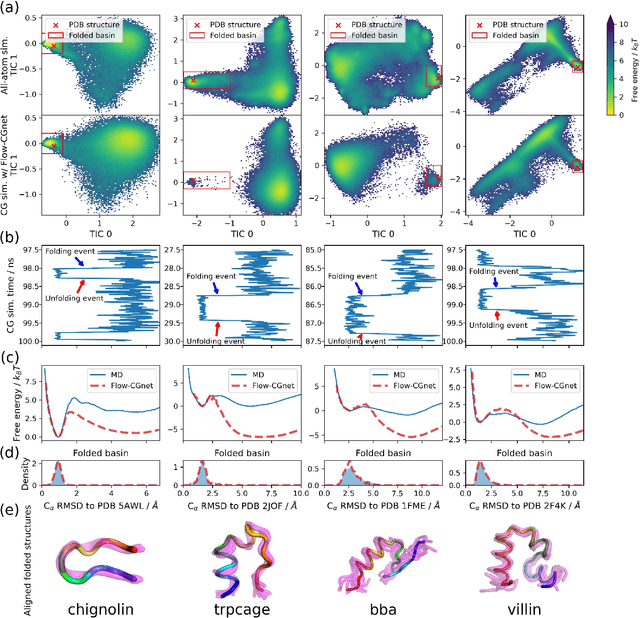
Coarse-grained (CG) molecular simulations have become a standard tool to study molecular processes on time-~and length-scales inaccessible to all-atom simulations. Learning CG force fields from all-atom data has mainly relied on force-matching and relative entropy minimization. Force-matching is straightforward to implement but requires the forces on the CG particles to be saved during all-atom simulation, and because these instantaneous forces depend on all degrees of freedom, they provide a very noisy signal that makes training the CG force field data inefficient. Relative entropy minimization does not require forces to be saved and is more data-efficient, but requires the CG model to be re-simulated during the iterative training procedure, which can make the training procedure extremely costly or lead to failure to converge. Here we present \emph{flow-matching}, a new training method for CG force fields that combines the advantages of force-matching and relative entropy minimization by leveraging normalizing flows, a generative deep learning method. Flow-matching first trains a normalizing flow to represent the CG probability density by using relative entropy minimization without suffering from the re-simulation problem because flows can directly sample from the equilibrium distribution they represent. Subsequently, the forces of the flow are used to train a CG force field by matching the coarse-grained forces directly, which is a much easier problem than traditional force-matching as it does not suffer from the noise problem. Besides not requiring forces, flow-matching also outperforms classical force-matching by an order of magnitude in terms of data efficiency and produces CG models that can capture the folding and unfolding of small proteins.
Advanced service data provisioning in ROF-based mobile backhauls/fronthauls
Jan 31, 2022A new cost-efficient concept to realize a real-time monitoring of quality-of-service metrics and other service data in 5G and beyond access network using a separate return channel based on a vertical cavity surface emitting laser in the optical injection locked mode that simultaneously operates as an optical transmitter and as a resonant cavity enhanced photodetector, is proposed and discussed. The feasibility and efficiency of the proposed approach are confirmed by a proof-of-concept experiment when optically transceiving high-speed digital signal with multi-position quadrature amplitude modulation of a radio-frequency carrier.
An Empirical Survey of Data Augmentation for Time Series Classification with Neural Networks
Jul 31, 2020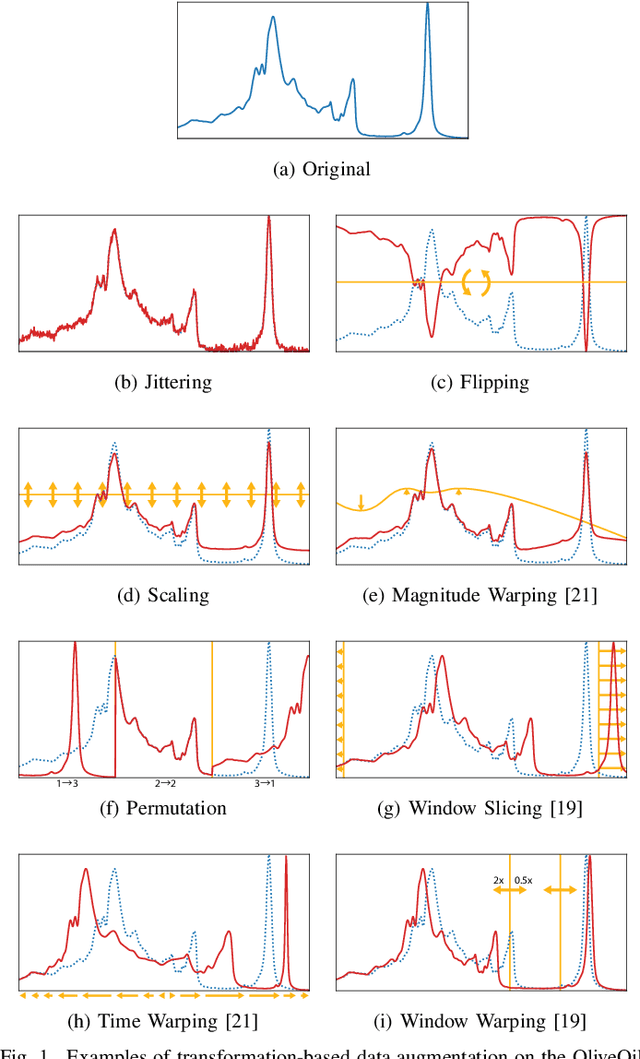
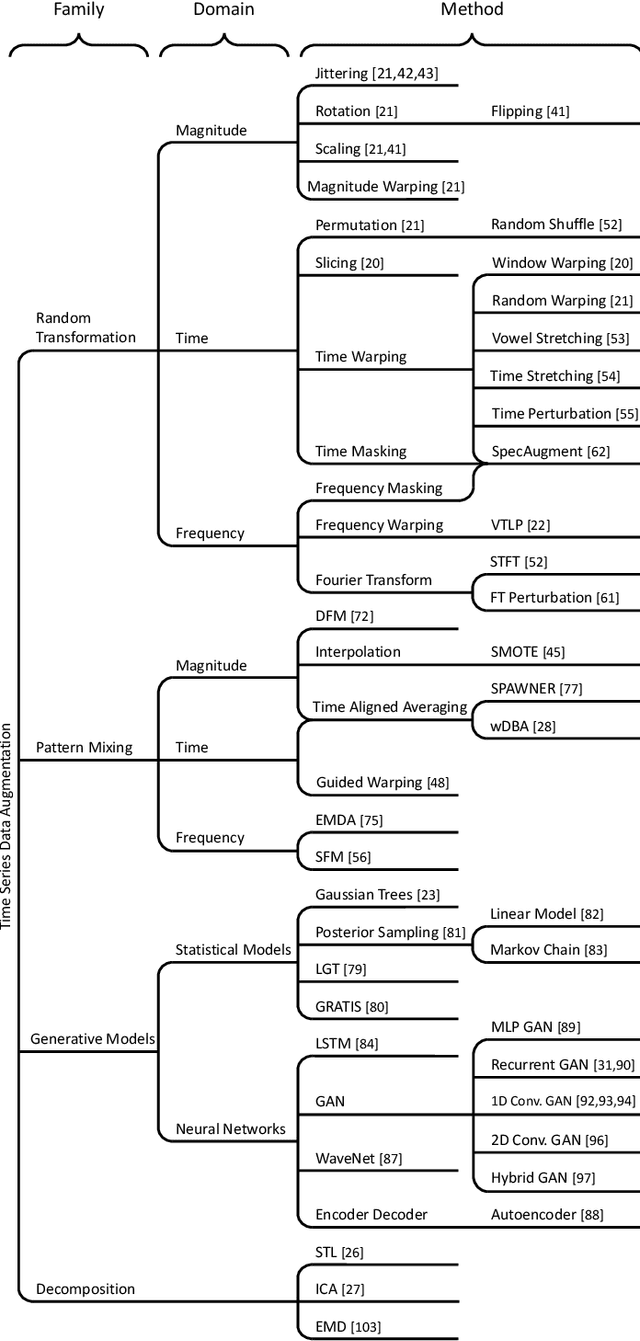
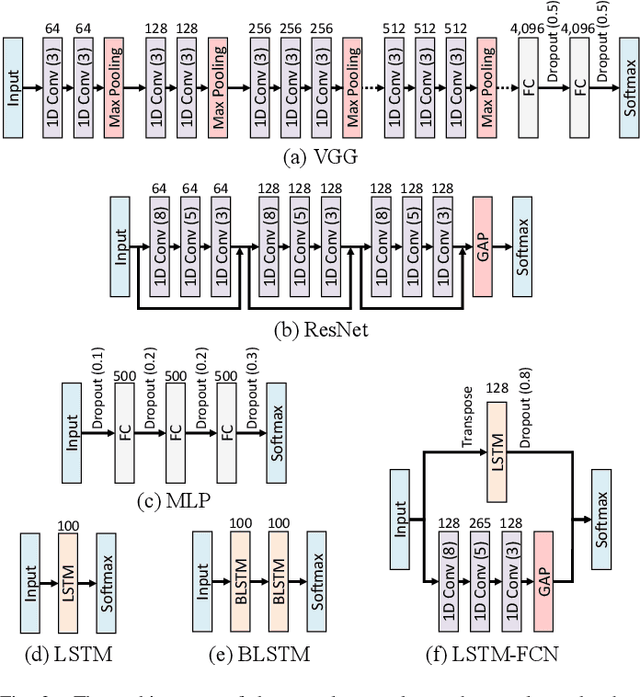
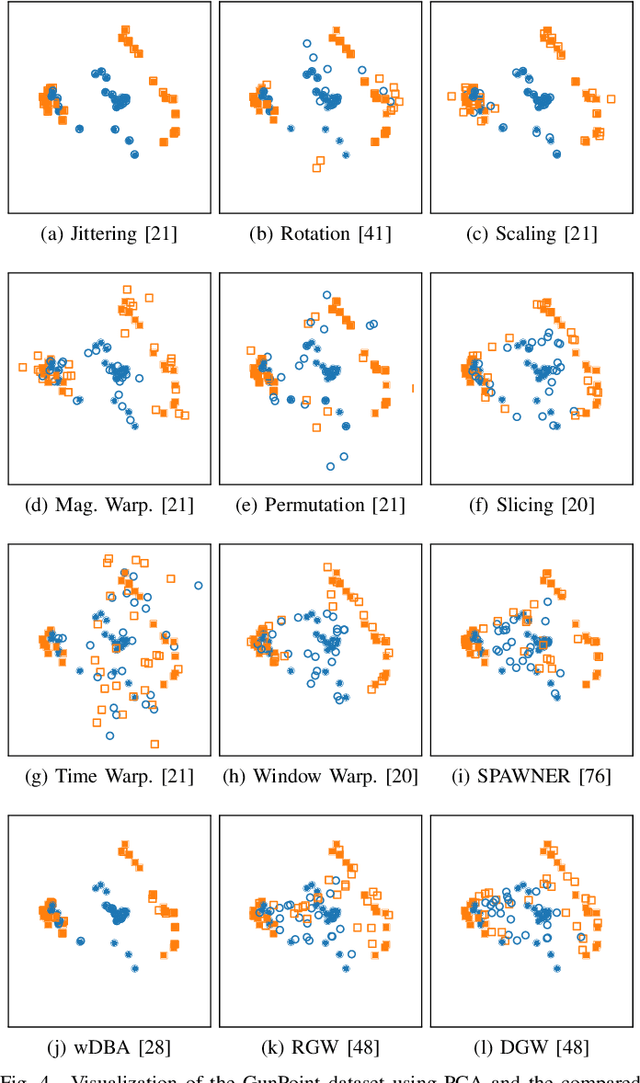
In recent times, deep artificial neural networks have achieved many successes in pattern recognition. Part of this success is the reliance on big data to increase generalization. However, in the field of time series recognition, many datasets are often very small. One method of addressing this problem is through the use of data augmentation. In this paper, we survey data augmentation techniques for time series and their application to time series classification with neural networks. We outline four families of time series data augmentation, including transformation-based methods, pattern mixing, generative models, and decomposition methods, and detail their taxonomy. Furthermore, we empirically evaluate 12 time series data augmentation methods on 128 time series classification datasets with 6 different types of neural networks. Through the results, we are able to analyze the characteristics, advantages and disadvantages, and recommendations of each data augmentation method. This survey aims to help in the selection of time series data augmentation for neural network applications.
Dynamic Based Estimator for UAVs with Real-time Identification Using DNN and the Modified Relay Feedback Test
Jun 14, 2021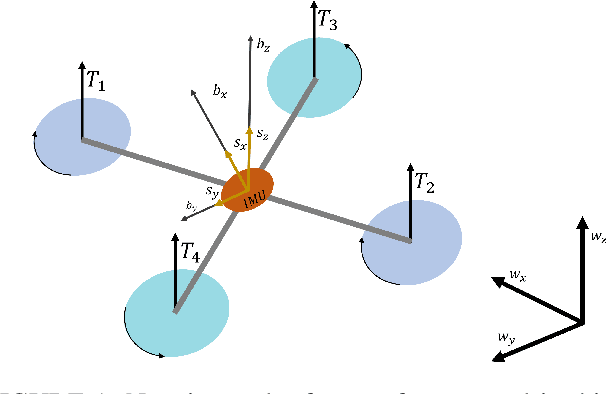
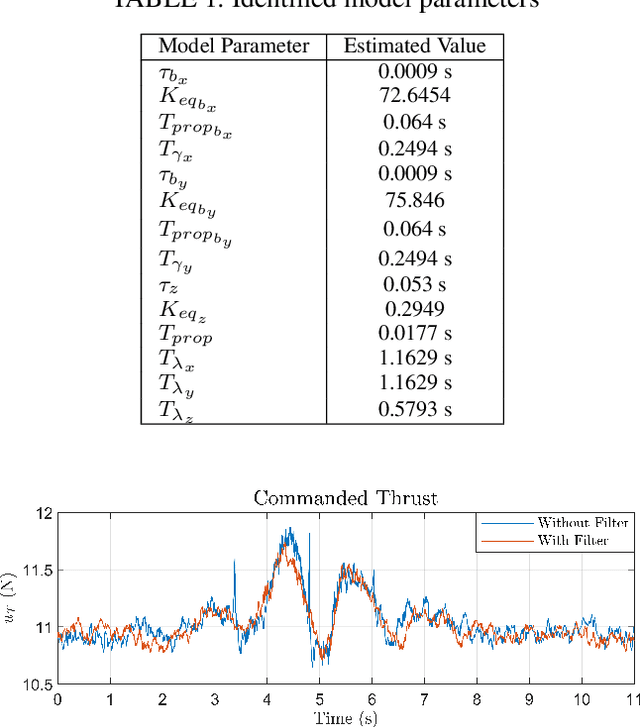
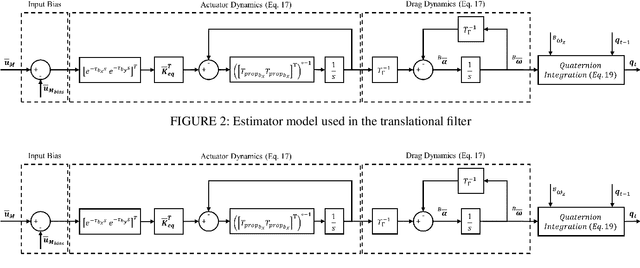
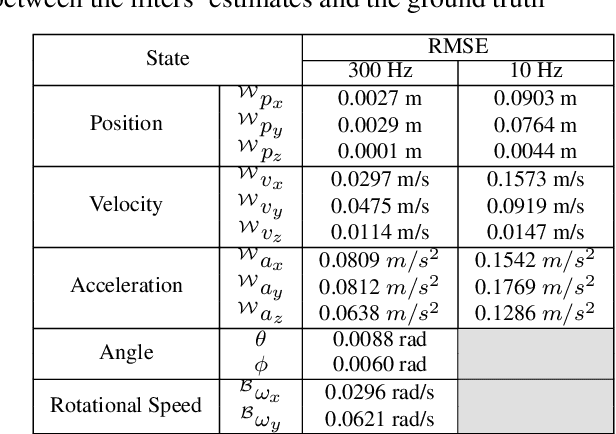
Control performance of Unmanned Aerial Vehicles (UAVs) is directly affected by their ability to estimate their states accurately. With the increasing popularity of autonomous UAV solutions in real world applications, it is imperative to develop robust adaptive estimators that can ameliorate sensor noises in low-cost UAVs. Utilizing the knowledge of UAV dynamics in estimation can provide significant advantages, but remains challenging due to the complex and expensive pre-flight experiments required to obtain UAV dynamic parameters. In this paper, we propose two decoupled dynamic model based Extended Kalman Filters for UAVs, that provide high rate estimates for position, and velocity of rotational and translational states, as well as filtered inertial acceleration. The dynamic model parameters are estimated online using the Deep Neural Network and Modified Relay Feedback Test (DNN-MRFT) framework, without requiring any prior knowledge of the UAV physical parameters. The designed filters with real-time identified process model parameters are tested experimentally and showed two advantages. Firstly, smooth and lag-free estimates of the UAV rotational speed and inertial acceleration are obtained, and used to improve the closed loop system performance, reducing the controller action by over 6 %. Secondly, the proposed approach enabled the UAV to track aggressive trajectories with low rate position measurements, a task usually infeasible under those conditions. The experimental data shows that we achieved estimation performance matching other methods that requires full knowledge of the UAV parameters.
Hierarchical Linear Dynamical System for Representing Notes from Recorded Audio
Feb 27, 2022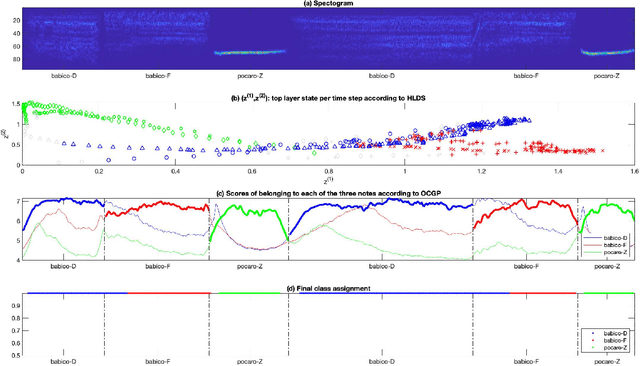
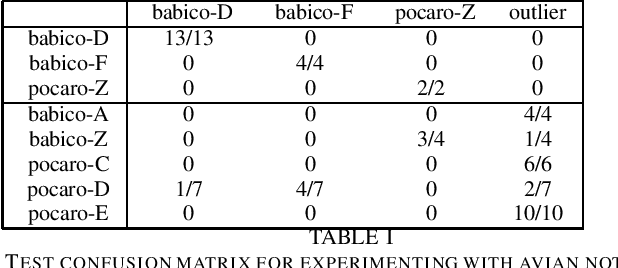
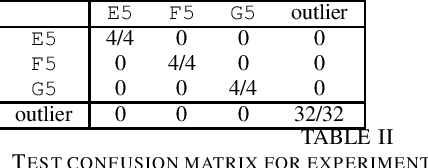
We seek to develop simultaneous segmentation and classification of notes from audio recordings in presence of outliers. The selected architecture for modeling time series is hierarchical linear dynamical system (HLDS). We propose a novel method for its parameter setting. HLDS can potentially be employed in two ways: 1) simultaneous segmentation and clustering for exploring data, i.e. finding unknown notes, 2) simultaneous segmentation and classification of audio recording for finding the notes of interest in the presence of outliers. We adapted HLDS for the second purpose since it is an easier task and still a challenging problem, e.g. in the field of bioacoustics. Each test clip has the same notes (but different instances) as of the training clip and also contain outlier notes. At test, it is automatically decided to which class of interest a note belongs to if any. Two applications of this work are to the fields of bioacoustics for detection of animal sounds in audio field recordings and also to musicology. Experiments have been conducted for segmentation and classification of both avian and musical notes from recorded audio.
Myriad: a real-world testbed to bridge trajectory optimization and deep learning
Feb 22, 2022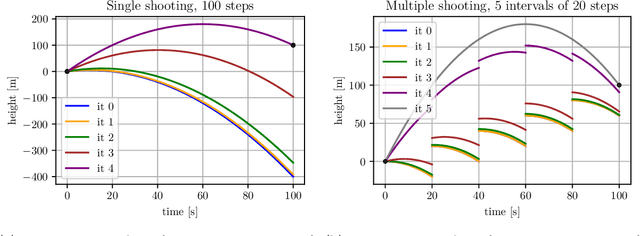
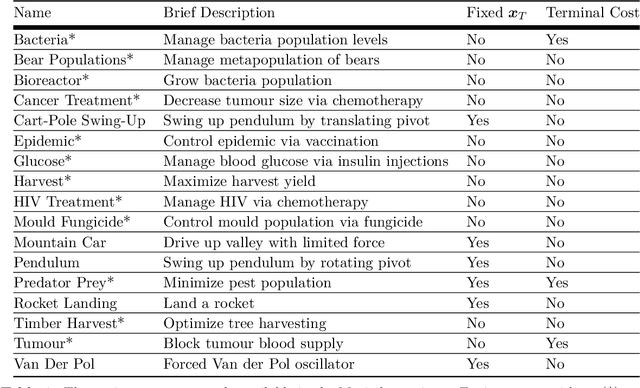
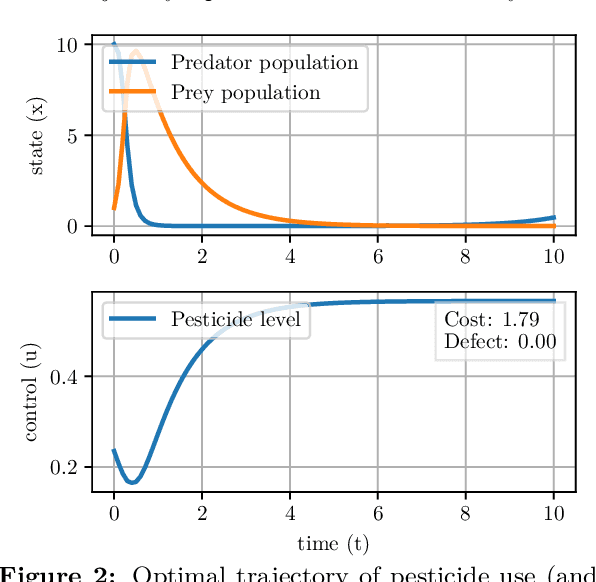

We present Myriad, a testbed written in JAX for learning and planning in real-world continuous environments. The primary contributions of Myriad are threefold. First, Myriad provides machine learning practitioners access to trajectory optimization techniques for application within a typical automatic differentiation workflow. Second, Myriad presents many real-world optimal control problems, ranging from biology to medicine to engineering, for use by the machine learning community. Formulated in continuous space and time, these environments retain some of the complexity of real-world systems often abstracted away by standard benchmarks. As such, Myriad strives to serve as a stepping stone towards application of modern machine learning techniques for impactful real-world tasks. Finally, we use the Myriad repository to showcase a novel approach for learning and control tasks. Trained in a fully end-to-end fashion, our model leverages an implicit planning module over neural ordinary differential equations, enabling simultaneous learning and planning with complex environment dynamics.
Hands-free Telelocomotion of a Wheeled Humanoid toward Dynamic Mobile Manipulation via Teleoperation
Mar 07, 2022
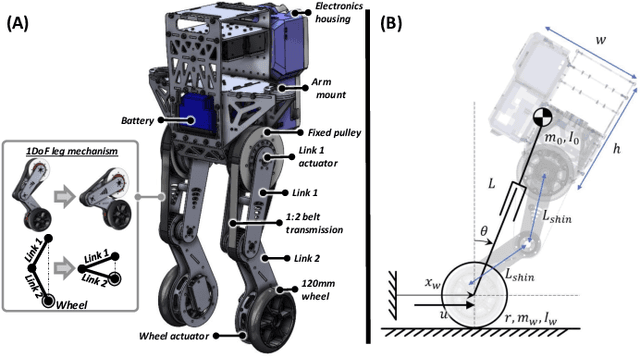
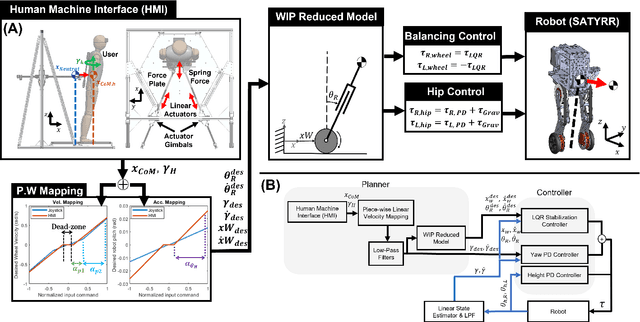
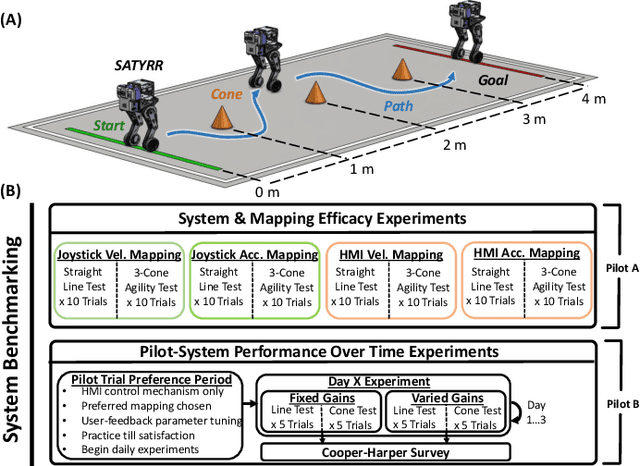
Robotic systems that can dynamically combine manipulation and locomotion could facilitate dangerous or physically demanding labor. For instance, firefighter humanoid robots could leverage their body by leaning against collapsed building rubble to push it aside. Here we introduce a teleoperation system that targets the realization of these tasks using human whole-body motor skills. We describe a new wheeled humanoid platform, SATYRR, and a novel hands-free teleoperation architecture using a whole-body Human Machine Interface (HMI). This system enables telelocomotion of the humanoid robot using the operator body motion, freeing their arms for manipulation tasks. In this study we evaluate the efficacy of the proposed system on hardware, and explore the control of SATYRR using two teleoperation mappings that map the operators body pitch and twist to the robot velocity or acceleration. Through experiments and user feedback we showcase our preliminary findings of the pilot-system response. Results suggest that the HMI is capable of effectively telelocomoting SATYRR, that pilot preferences should dictate the appropriate motion mapping and gains, and finally that the pilot can better learn to control the system over time. This study represents a fundamental step towards the realization of combined manipulation and locomotion via teleoperation.
Online Caching with Optimistic Learning
Feb 22, 2022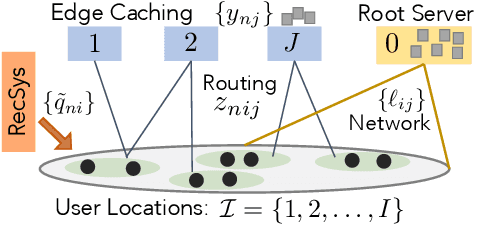
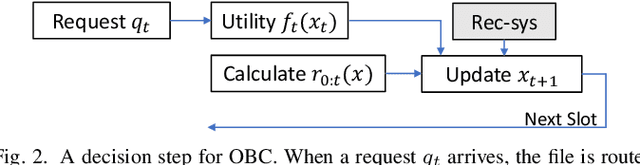
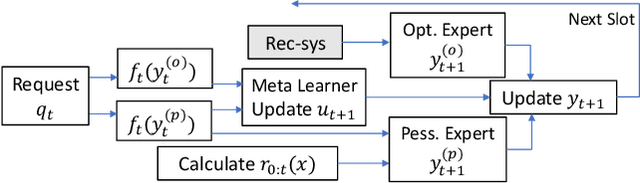
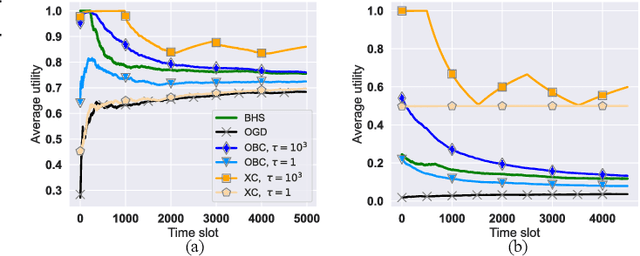
The design of effective online caching policies is an increasingly important problem for content distribution networks, online social networks and edge computing services, among other areas. This paper proposes a new algorithmic toolbox for tackling this problem through the lens of optimistic online learning. We build upon the Follow-the-Regularized-Leader (FTRL) framework which is developed further here to include predictions for the file requests, and we design online caching algorithms for bipartite networks with fixed-size caches or elastic leased caches subject to time-average budget constraints. The predictions are provided by a content recommendation system that influences the users viewing activity, and hence can naturally reduce the caching network's uncertainty about future requests. We prove that the proposed optimistic learning caching policies can achieve sub-zero performance loss (regret) for perfect predictions, and maintain the best achievable regret bound $O(\sqrt T)$ even for arbitrary-bad predictions. The performance of the proposed algorithms is evaluated with detailed trace-driven numerical tests.
A Simple Hash-Based Early Exiting Approach For Language Understanding and Generation
Mar 03, 2022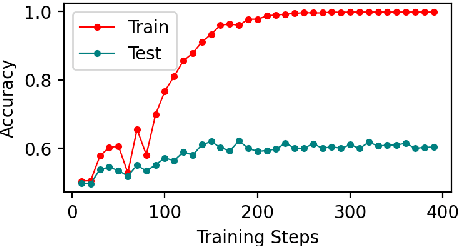
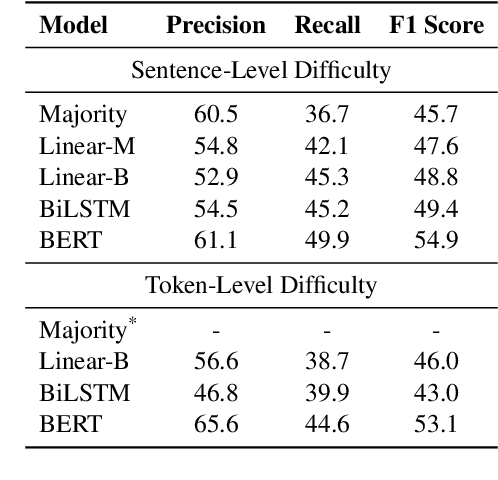
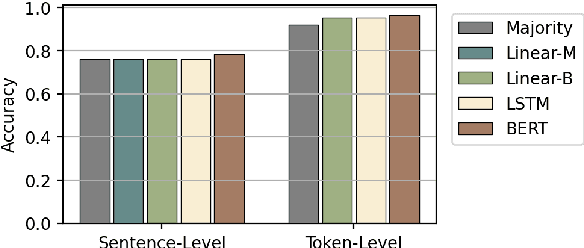
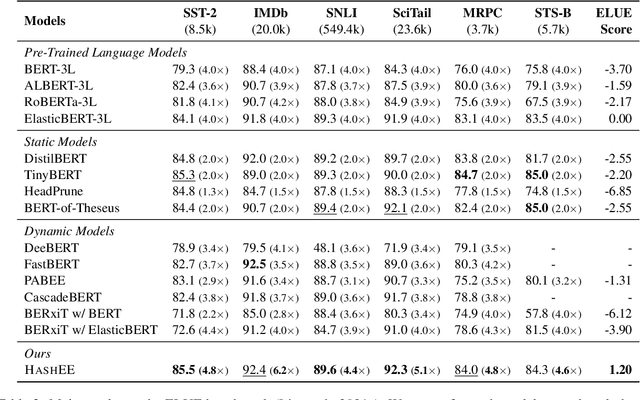
Early exiting allows instances to exit at different layers according to the estimation of difficulty. Previous works usually adopt heuristic metrics such as the entropy of internal outputs to measure instance difficulty, which suffers from generalization and threshold-tuning. In contrast, learning to exit, or learning to predict instance difficulty is a more appealing way. Though some effort has been devoted to employing such "learn-to-exit" modules, it is still unknown whether and how well the instance difficulty can be learned. As a response, we first conduct experiments on the learnability of instance difficulty, which demonstrates that modern neural models perform poorly on predicting instance difficulty. Based on this observation, we propose a simple-yet-effective Hash-based Early Exiting approach (HashEE) that replaces the learn-to-exit modules with hash functions to assign each token to a fixed exiting layer. Different from previous methods, HashEE requires no internal classifiers nor extra parameters, and therefore is more efficient. Experimental results on classification, regression, and generation tasks demonstrate that HashEE can achieve higher performance with fewer FLOPs and inference time compared with previous state-of-the-art early exiting methods.