 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ABCNet v2: Adaptive Bezier-Curve Network for Real-time End-to-end Text Spotting
May 08, 2021

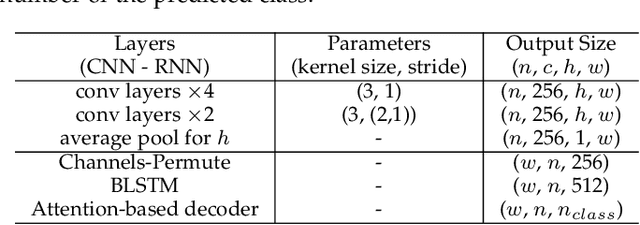


End-to-end text-spotting, which aims to integrate detection and recognition in a unified framework, has attracted increasing attention due to its simplicity of the two complimentary tasks. It remains an open problem especially when processing arbitrarily-shaped text instances. Previous methods can be roughly categorized into two groups: character-based and segmentation-based, which often require character-level annotations and/or complex post-processing due to the unstructured output. Here, we tackle end-to-end text spotting by presenting Adaptive Bezier Curve Network v2 (ABCNet v2). Our main contributions are four-fold: 1) For the first time, we adaptively fit arbitrarily-shaped text by a parameterized Bezier curve, which, compared with segmentation-based methods, can not only provide structured output but also controllable representation. 2) We design a novel BezierAlign layer for extracting accurate convolution features of a text instance of arbitrary shapes, significantly improving the precision of recognition over previous methods. 3) Different from previous methods, which often suffer from complex post-processing and sensitive hyper-parameters, our ABCNet v2 maintains a simple pipeline with the only post-processing non-maximum suppression (NMS). 4) As the performance of text recognition closely depends on feature alignment, ABCNet v2 further adopts a simple yet effective coordinate convolution to encode the position of the convolutional filters, which leads to a considerable improvement with negligible computation overhead. Comprehensive experiments conducted on various bilingual (English and Chinese) benchmark datasets demonstrate that ABCNet v2 can achieve state-of-the-art performance while maintaining very high efficiency.
A physics and data co-driven surrogate modeling approach for temperature field prediction on irregular geometric domain
Mar 15, 2022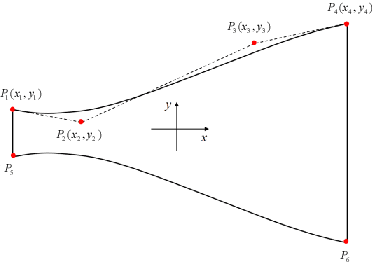
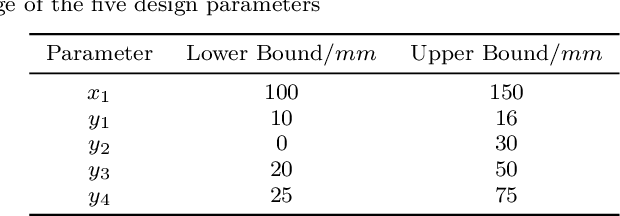
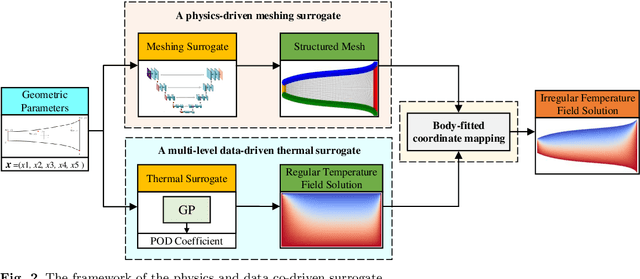
In the whole aircraft structural optimization loop, thermal analysis plays a very important role. But it faces a severe computational burden when directly applying traditional numerical analysis tools, especially when each optimization involves repetitive parameter modification and thermal analysis followed. Recently, with the fast development of deep learning, several Convolutional Neural Network (CNN) surrogate models have been introduced to overcome this obstacle. However, for temperature field prediction on irregular geometric domains (TFP-IGD), CNN can hardly be competent since most of them stem from processing for regular images. To alleviate this difficulty, we propose a novel physics and data co-driven surrogate modeling method. First, after adapting the Bezier curve in geometric parameterization, a body-fitted coordinate mapping is introduced to generate coordinate transforms between the irregular physical plane and regular computational plane. Second, a physics-driven CNN surrogate with partial differential equation (PDE) residuals as a loss function is utilized for fast meshing (meshing surrogate); then, we present a data-driven surrogate model based on the multi-level reduced-order method, aiming to learn solutions of temperature field in the above regular computational plane (thermal surrogate). Finally, combining the grid position information provided by the meshing surrogate with the scalar temperature field information provided by the thermal surrogate (combined model), we reach an end-to-end surrogate model from geometric parameters to temperature field prediction on an irregular geometric domain. Numerical results demonstrate that our method can significantly improve accuracy prediction on a smaller dataset while reducing the training time when compared with other CNN methods.
Enhancing Door Detection for Autonomous Mobile Robots with Environment-Specific Data Collection
Mar 08, 2022


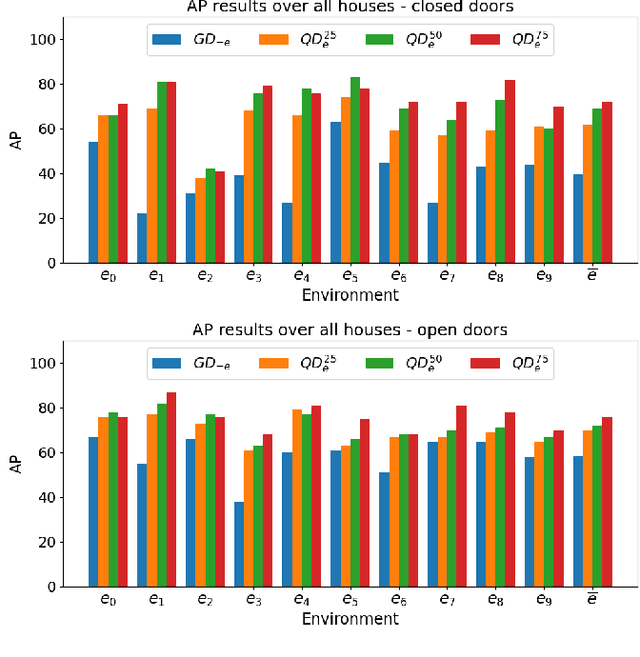
Door detection represents a fundamental capability for autonomous mobile robots employed in tasks involving indoor navigation. Recognizing the presence of a door and its status (open or closed) can induce a remarkable impact on the navigation performance, especially for dynamic settings where doors can enable or disable passages, hence changing the actual topology of the map. In this work, we address the problem of building a door detector module for an autonomous mobile robot deployed in a long-term scenario, namely operating in the same environment for a long time, thus observing the same set of doors from different points of view. First, we show how the mainstream approach for door detection, based on object recognition, falls short in considering the constrained perception setup typical of a mobile robot. Hence, we devise a method to build a dataset of images taken from a robot's perspective and we exploit it to obtain a door detector based on an established deep-learning object-recognition method. We then exploit the long-term assumption of our scenario to qualify the model on the robot working environment via fine-tuning with additional images acquired in the deployment environment. Our experimental analysis shows how this method can achieve good performance and highlights a trade-off between costs and benefits of the fine-tuning approach.
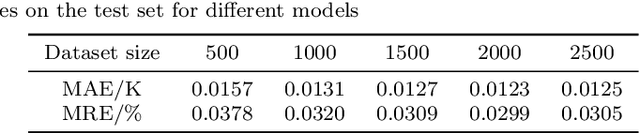
Exploring Structural Sparsity in Neural Image Compression
Feb 10, 2022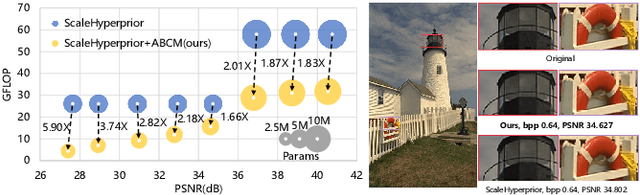
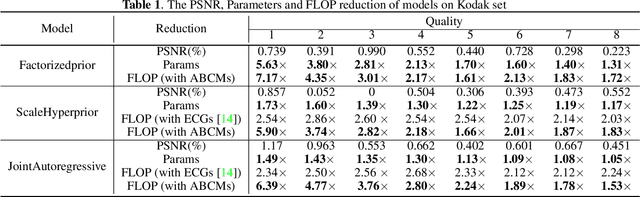

Neural image compression have reached or out-performed traditional methods (such as JPEG, BPG, WebP). However,their sophisticated network structures with cascaded convolution layers bring heavy computational burden for practical deployment. In this paper, we explore the structural sparsity in neural image compression network to obtain real-time acceleration without any specialized hardware design or algorithm. We propose a simple plug-in adaptive binary channel masking(ABCM) to judge the importance of each convolution channel and introduce sparsity during training. During inference, the unimportant channels are pruned to obtain slimmer network and less computation. We implement our method into three neural image compression networks with different entropy models to verify its effectiveness and generalization, the experiment results show that up to 7x computation reduction and 3x acceleration can be achieved with negligible performance drop.
Spirit Distillation: Precise Real-time Semantic Segmentation of Road Scenes with Insufficient Data
Apr 17, 2021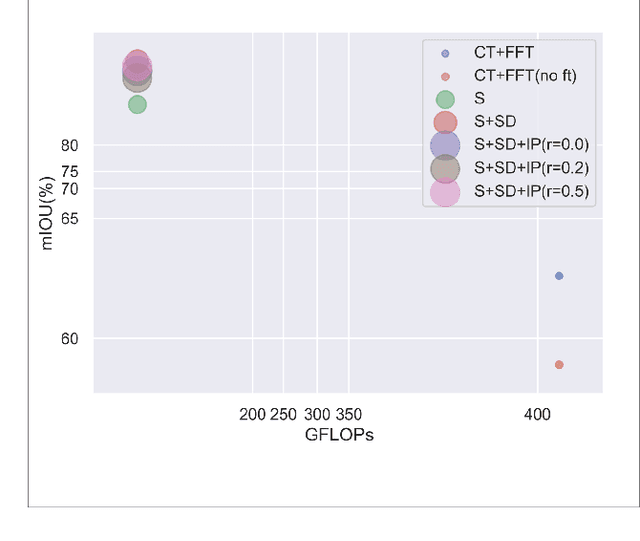
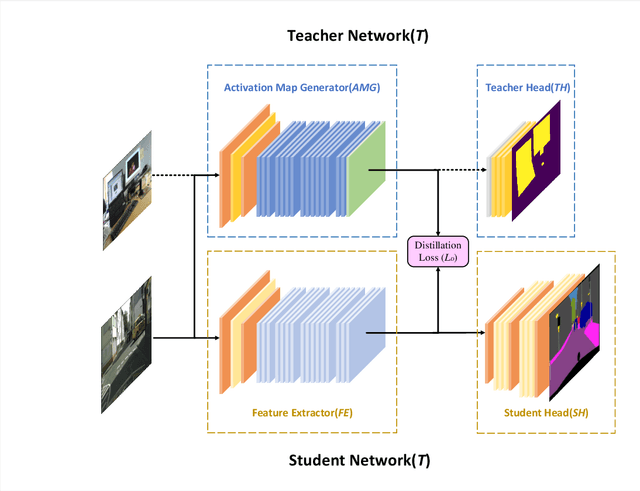
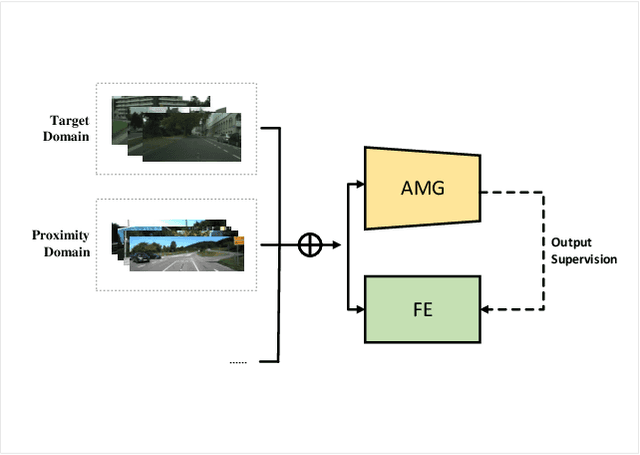
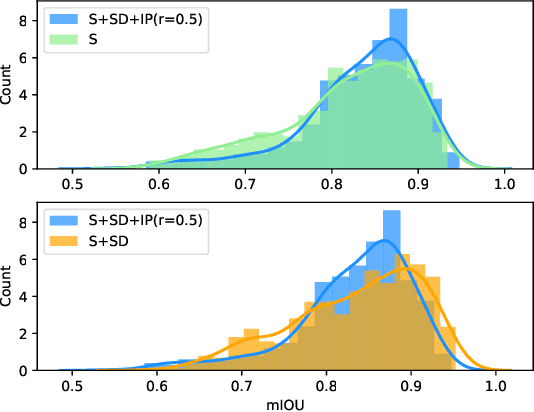
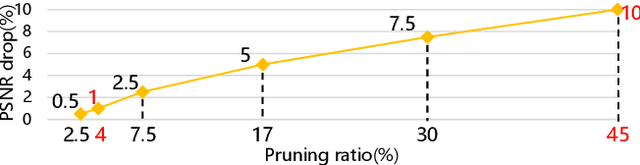
Semantic segmentation of road scenes is one of the key technologies for realizing autonomous driving scene perception, and the effectiveness of deep Convolutional Neural Networks(CNNs) for this task has been demonstrated. State-of-art CNNs for semantic segmentation suffer from excessive computations as well as large-scale training data requirement. Inspired by the ideas of Fine-tuning-based Transfer Learning (FTT) and feature-based knowledge distillation, we propose a new knowledge distillation method for cross-domain knowledge transference and efficient data-insufficient network training, named Spirit Distillation(SD), which allow the student network to mimic the teacher network to extract general features, so that a compact and accurate student network can be trained for real-time semantic segmentation of road scenes. Then, in order to further alleviate the trouble of insufficient data and improve the robustness of the student, an Enhanced Spirit Distillation (ESD) method is proposed, which commits to exploit a more comprehensive general features extraction capability by considering images from both the target and the proximity domains as input. To our knowledge, this paper is a pioneering work on the application of knowledge distillation to few-shot learning. Persuasive experiments conducted on Cityscapes semantic segmentation with the prior knowledge transferred from COCO2017 and KITTI demonstrate that our methods can train a better student network (mIOU and high-precision accuracy boost by 1.4% and 8.2% respectively, with 78.2% segmentation variance) with only 41.8% FLOPs (see Fig. 1).
Improving Ant Colony Optimization Efficiency for Solving Large TSP Instances
Mar 04, 2022
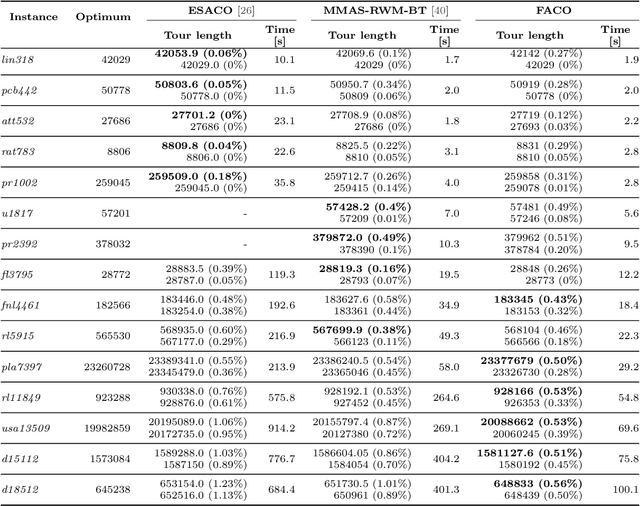
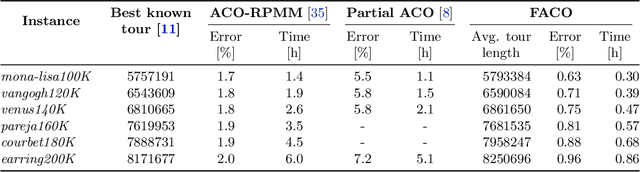
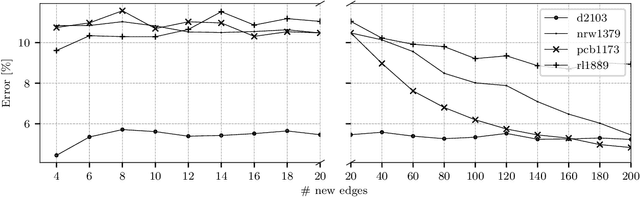
Ant Colony Optimization (ACO) is a family of nature-inspired metaheuristics often applied to finding approximate solutions to difficult optimization problems. Despite being significantly faster than exact methods, the ACOs can still be prohibitively slow, especially if compared to basic problem-specific heuristics. As recent research has shown, it is possible to significantly improve the performance through algorithm refinements and careful parallel implementation benefiting from multi-core CPUs and dedicated accelerators. In this paper, we present a novel ACO variant, namely the Focused ACO (FACO). One of the core elements of the FACO is a mechanism for controlling the number of differences between a newly constructed and a selected previous solution. The mechanism results in a more focused search process, allowing to find improvements while preserving the quality of the existing solution. An additional benefit is a more efficient integration with a problem-specific local search. Computational study based on a range of the Traveling Salesman Problem instances shows that the FACO outperforms the state-of-the-art ACOs when solving large TSP instances. Specifically, the FACO required less than an hour of an 8-core commodity CPU time to find high-quality solutions (within 1% from the best-known results) for TSP Art Instances ranging from 100000 to 200000 nodes.
* 28 pages, 10 figures, 5 tables
Oracle-Efficient Online Learning for Beyond Worst-Case Adversaries
Mar 08, 2022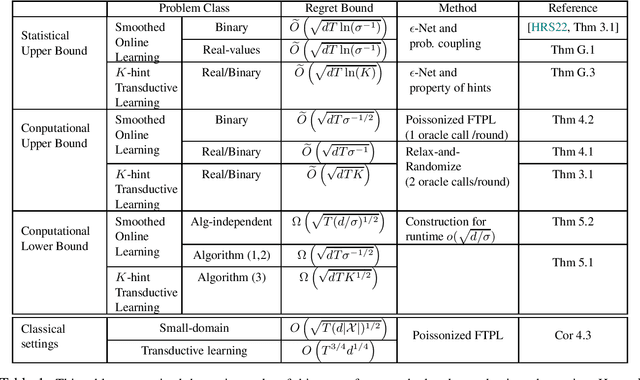
In this paper, we study oracle-efficient algorithms for beyond worst-case analysis of online learning. We focus on two settings. First, the smoothed analysis setting of [RST11, HRS21] where an adversary is constrained to generating samples from distributions whose density is upper bounded by $1/\sigma$ times the uniform density. Second, the setting of $K$-hint transductive learning, where the learner is given access to $K$ hints per time step that are guaranteed to include the true instance. We give the first known oracle-efficient algorithms for both settings that depend only on the VC dimension of the class and parameters $\sigma$ and $K$ that capture the power of the adversary. {In particular, we achieve oracle-efficient regret bounds of $ O ( \sqrt{T d\sigma^{-1/2}} ) $} and $ O ( \sqrt{T d K } )$ respectively for these setting. For the smoothed analysis setting, our results give the first oracle-efficient algorithm for online learning with smoothed adversaries [HRS21]. This contrasts the computational separation between online learning with worst-case adversaries and offline learning established by [HK16]. Our algorithms also achieve improved bounds for worst-case setting with small domains. In particular, we give an oracle-efficient algorithm with regret of $O ( \sqrt{T(d \vert{\mathcal{X}})\vert^{1/2} })$, which is a refinement of the earlier $O ( \sqrt{T\vert{\mathcal{X}}\vert })$ bound by [DS16].
Noisy Low-rank Matrix Optimization: Geometry of Local Minima and Convergence Rate
Mar 08, 2022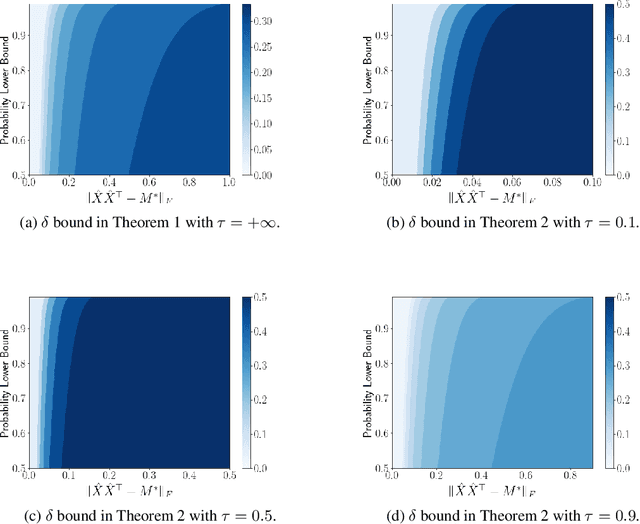
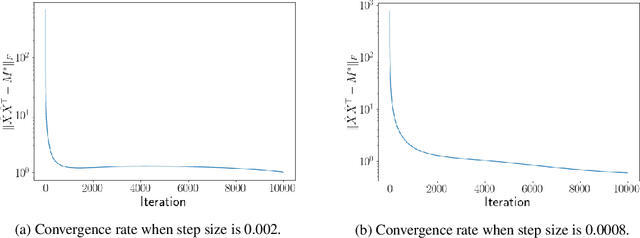
This paper is concerned with low-rank matrix optimization, which has found a wide range of applications in machine learning. This problem in the special case of matrix sense has been studied extensively through the notion of Restricted Isometry Property (RIP), leading to a wealth of results on the geometric landscape of the problem and the convergence rate of common algorithms. However, the existing results are not able to handle the problem with a general objective function subject to noisy data. In this paper, we address this problem by developing a mathematical framework that can deal with random corruptions to general objective functions, where the noise model is arbitrary. We prove that as long as the RIP constant of the noiseless objective is less than $1/3$, any spurious local solution of the noisy optimization problem must be close to the ground truth solution. By working through the strict saddle property, we also show that an approximate solution can be found in polynomial time. We characterize the geometry of the spurious local minima of the problem in a local region around the ground truth in the case when the RIP constant is greater than $1/3$. This paper offers the first set of results on the global and local optimization landscapes of general low-rank optimization problems under arbitrary random corruptions.
ART-Point: Improving Rotation Robustness of Point Cloud Classifiers via Adversarial Rotation
Mar 08, 2022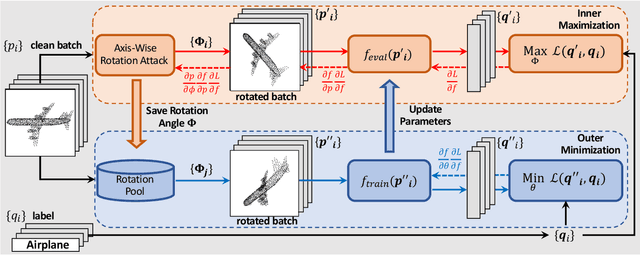
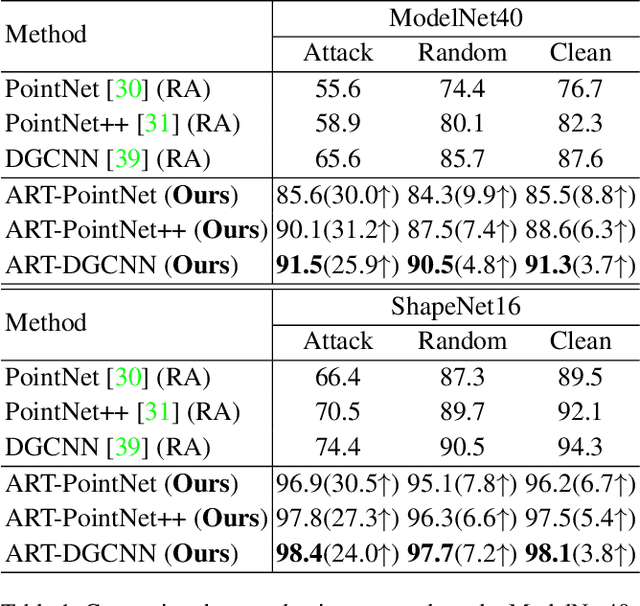
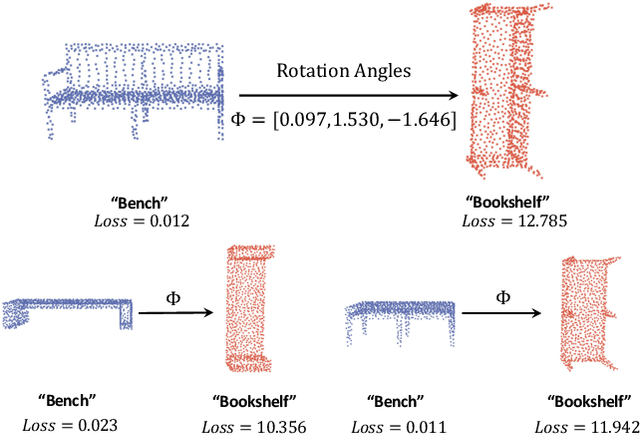
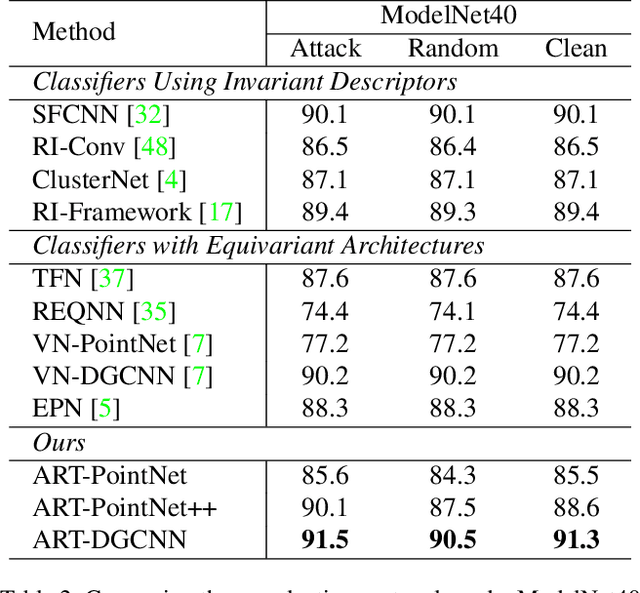
Point cloud classifiers with rotation robustness have been widely discussed in the 3D deep learning community. Most proposed methods either use rotation invariant descriptors as inputs or try to design rotation equivariant networks. However, robust models generated by these methods have limited performance under clean aligned datasets due to modifications on the original classifiers or input space. In this study, for the first time, we show that the rotation robustness of point cloud classifiers can also be acquired via adversarial training with better performance on both rotated and clean datasets. Specifically, our proposed framework named ART-Point regards the rotation of the point cloud as an attack and improves rotation robustness by training the classifier on inputs with Adversarial RoTations. We contribute an axis-wise rotation attack that uses back-propagated gradients of the pre-trained model to effectively find the adversarial rotations. To avoid model over-fitting on adversarial inputs, we construct rotation pools that leverage the transferability of adversarial rotations among samples to increase the diversity of training data. Moreover, we propose a fast one-step optimization to efficiently reach the final robust model. Experiments show that our proposed rotation attack achieves a high success rate and ART-Point can be used on most existing classifiers to improve the rotation robustness while showing better performance on clean datasets than state-of-the-art methods.
Quantum Deep Learning for Mutant COVID-19 Strain Prediction
Mar 04, 2022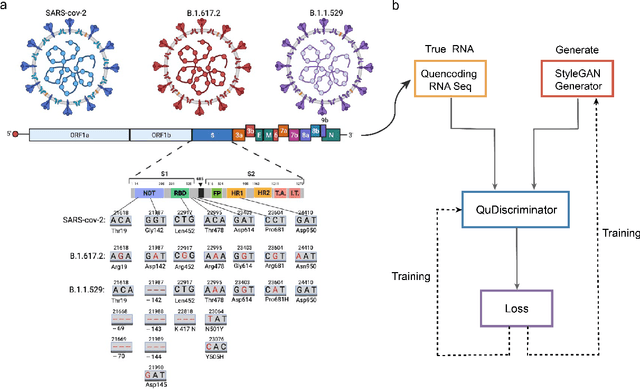
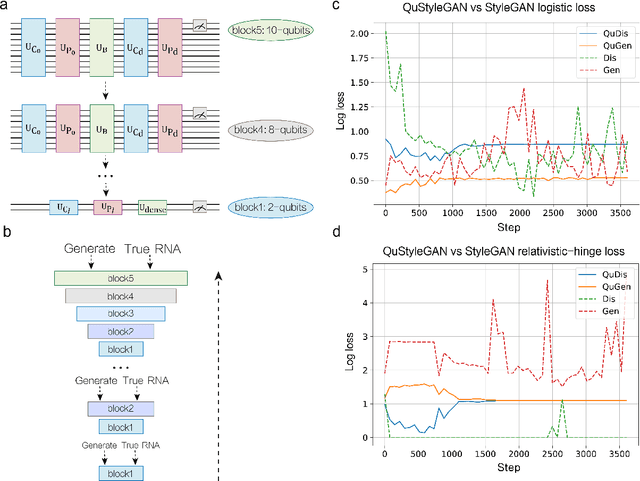
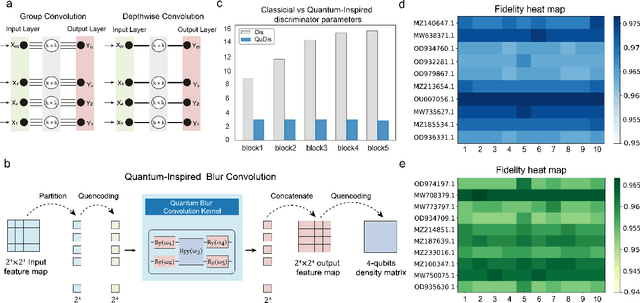
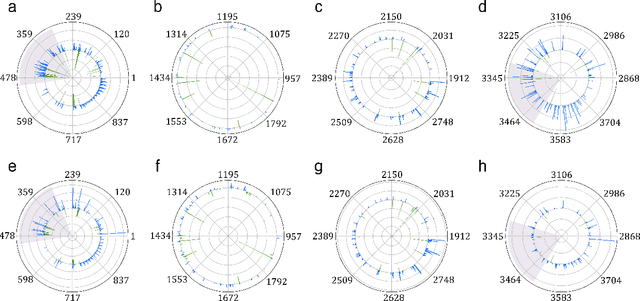
New COVID-19 epidemic strains like Delta and Omicron with increased transmissibility and pathogenicity emerge and spread across the whole world rapidly while causing high mortality during the pandemic period. Early prediction of possible variants (especially spike protein) of COVID-19 epidemic strains based on available mutated SARS-CoV-2 RNA sequences may lead to early prevention and treatment. Here, combining the advantage of quantum and quantum-inspired algorithms with the wide application of deep learning, we propose a development tool named DeepQuantum, and use this software to realize the goal of predicting spike protein variation structure of COVID-19 epidemic strains. In addition, this hybrid quantum-classical model for the first time achieves quantum-inspired blur convolution similar to classical depthwise convolution and also successfully applies quantum progressive training with quantum circuits, both of which guarantee that our model is the quantum counterpart of the famous style-based GAN. The results state that the fidelities of random generating spike protein variation structure are always beyond 96% for Delta, 94% for Omicron. The training loss curve is more stable and converges better with multiple loss functions compared with the corresponding classical algorithm. At last, evidences that quantum-inspired algorithms promote the classical deep learning and hybrid models effectively predict the mutant strains are strong.