 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Accurate Prediction and Uncertainty Estimation using Decoupled Prediction Interval Networks
Feb 19, 2022
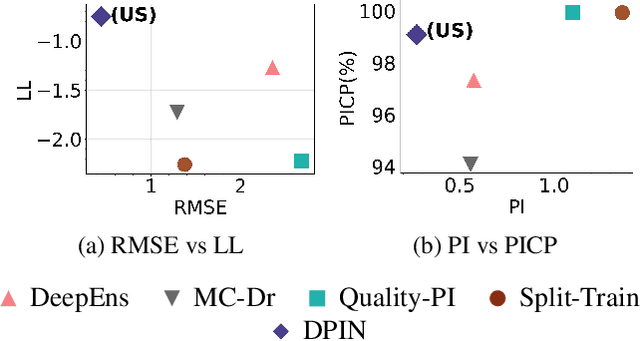
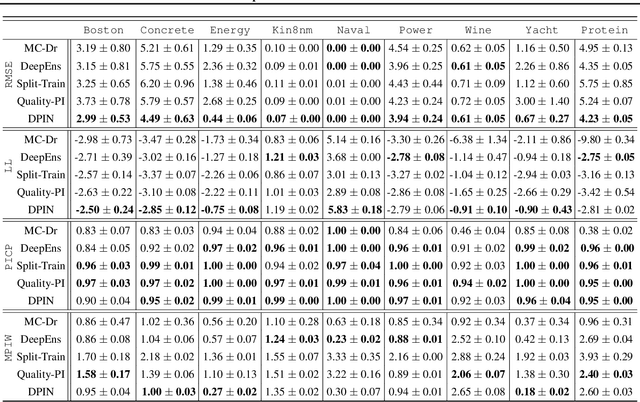
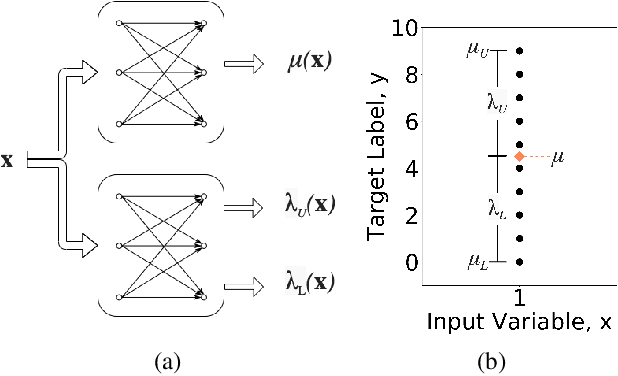
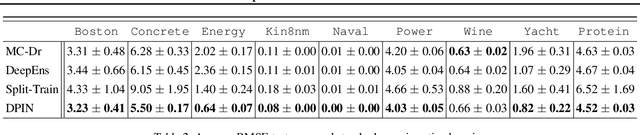
We propose a network architecture capable of reliably estimating uncertainty of regression based predictions without sacrificing accuracy. The current state-of-the-art uncertainty algorithms either fall short of achieving prediction accuracy comparable to the mean square error optimization or underestimate the variance of network predictions. We propose a decoupled network architecture that is capable of accomplishing both at the same time. We achieve this by breaking down the learning of prediction and prediction interval (PI) estimations into a two-stage training process. We use a custom loss function for learning a PI range around optimized mean estimation with a desired coverage of a proportion of the target labels within the PI range. We compare the proposed method with current state-of-the-art uncertainty quantification algorithms on synthetic datasets and UCI benchmarks, reducing the error in the predictions by 23 to 34% while maintaining 95% Prediction Interval Coverage Probability (PICP) for 7 out of 9 UCI benchmark datasets. We also examine the quality of our predictive uncertainty by evaluating on Active Learning and demonstrating 17 to 36% error reduction on UCI benchmarks.
Robust Policy Learning over Multiple Uncertainty Sets
Feb 14, 2022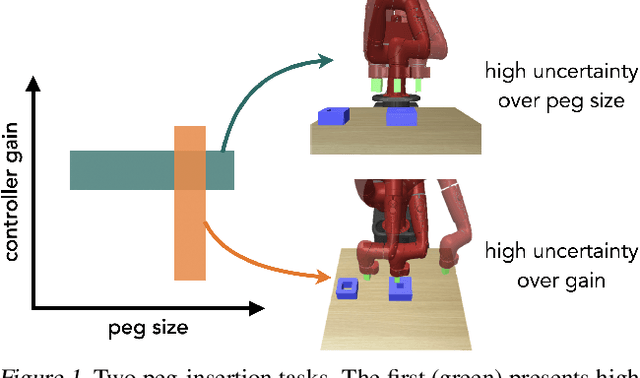
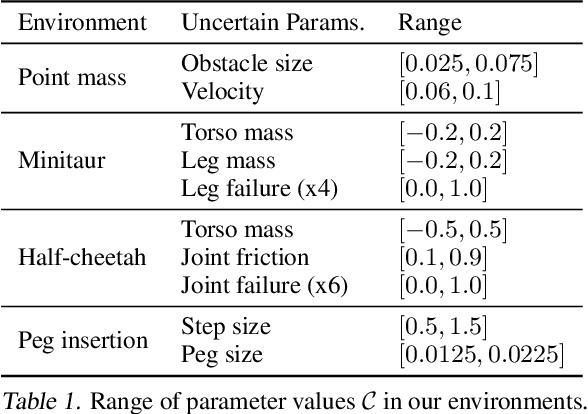
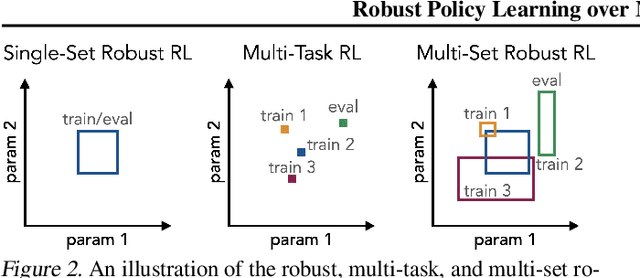

Reinforcement learning (RL) agents need to be robust to variations in safety-critical environments. While system identification methods provide a way to infer the variation from online experience, they can fail in settings where fast identification is not possible. Another dominant approach is robust RL which produces a policy that can handle worst-case scenarios, but these methods are generally designed to achieve robustness to a single uncertainty set that must be specified at train time. Towards a more general solution, we formulate the multi-set robustness problem to learn a policy robust to different perturbation sets. We then design an algorithm that enjoys the benefits of both system identification and robust RL: it reduces uncertainty where possible given a few interactions, but can still act robustly with respect to the remaining uncertainty. On a diverse set of control tasks, our approach demonstrates improved worst-case performance on new environments compared to prior methods based on system identification and on robust RL alone.
The iCanClean Algorithm: How to Remove Artifacts using Reference Noise Recordings
Jan 27, 2022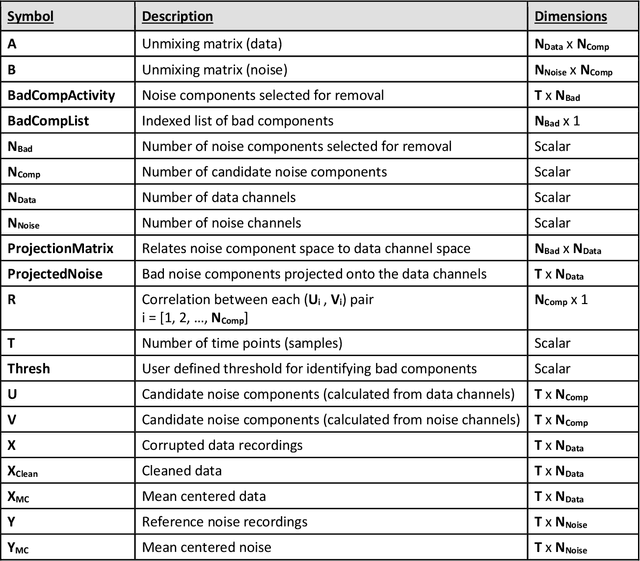
Data recordings are often corrupted by noise, and it can be difficult to isolate clean data of interest. For example, mobile electroencephalography is commonly corrupted by motion artifact, which limits its use in real-world settings. Here, we describe a novel noise-canceling algorithm that uses canonical correlation analysis to find and remove subspaces of corrupted data recordings that are most strongly correlated with subspaces of reference noise recordings. The algorithm, termed iCanClean, is computationally efficient, which may be useful for real-time applications, such as brain computer interfaces. In future work, we will quantify the algorithm's performance and compare it with alternative cleaning methods.
SOTER on ROS: A Run-Time Assurance Framework on the Robot Operating System
Aug 21, 2020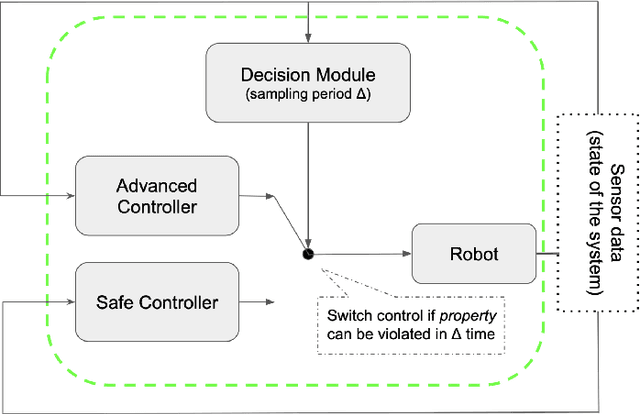
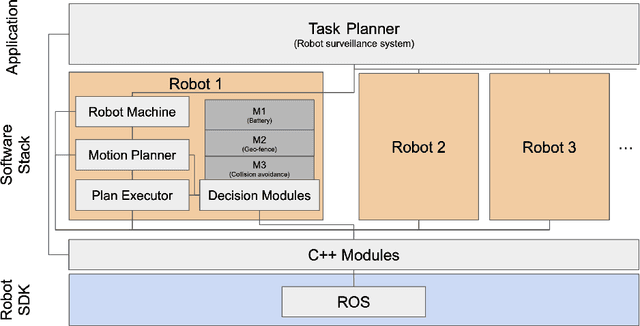

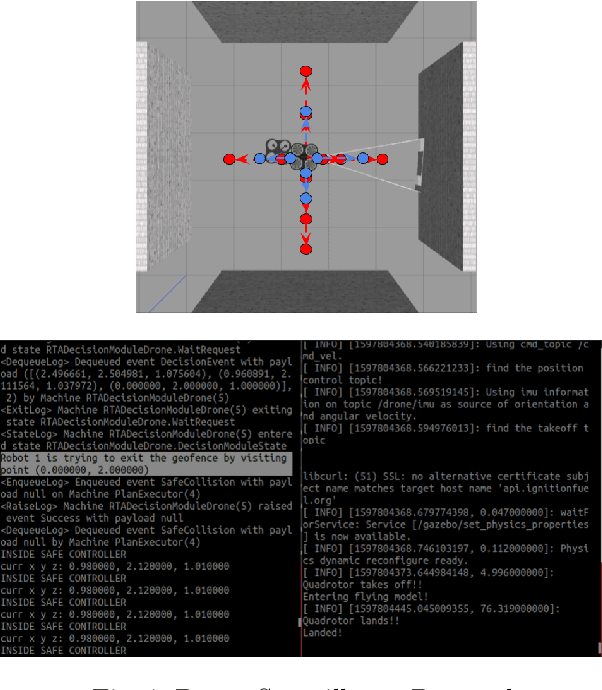
We present an implementation of SOTER, a run-time assurance framework for building safe distributed mobile robotic (DMR) systems, on top of the Robot Operating System (ROS). The safety of DMR systems cannot always be guaranteed at design time, especially when complex, off-the-shelf components are used that cannot be verified easily. SOTER addresses this by providing a language-based approach for run-time assurance for DMR systems. SOTER implements the reactive robotic software using the language P, a domain-specific language designed for implementing asynchronous event-driven systems, along with an integrated run-time assurance system that allows programmers to use unfortified components but still provide safety guarantees. We describe an implementation of SOTER for ROS and demonstrate its efficacy using a multi-robot surveillance case study, with multiple run-time assurance modules. Through rigorous simulation, we show that SOTER enabled systems ensure safety, even when using unknown and untrusted components.
Spectrum Surveying: Active Radio Map Estimation with Autonomous UAVs
Jan 11, 2022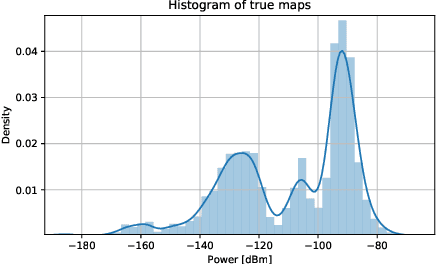
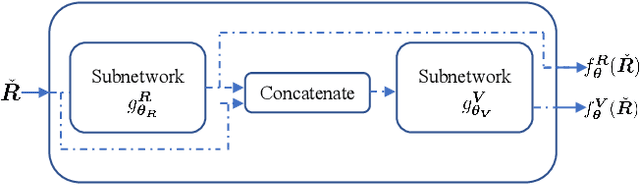
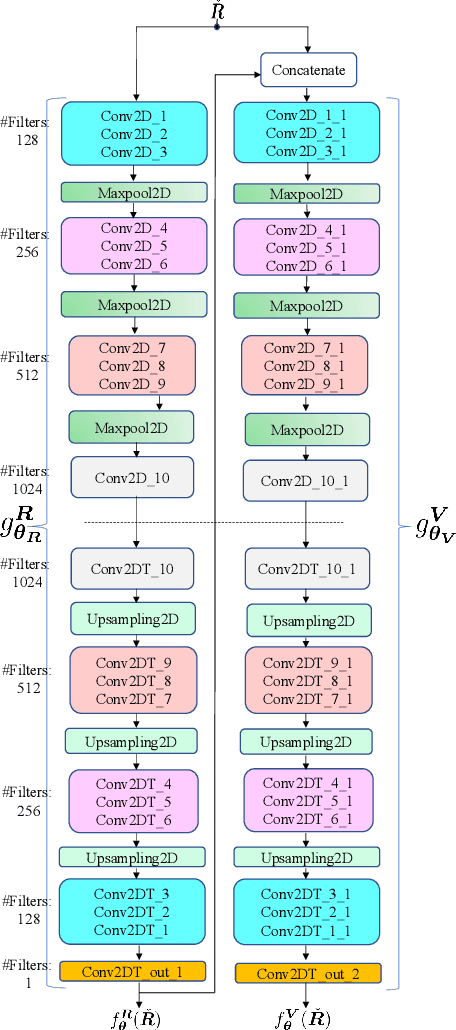
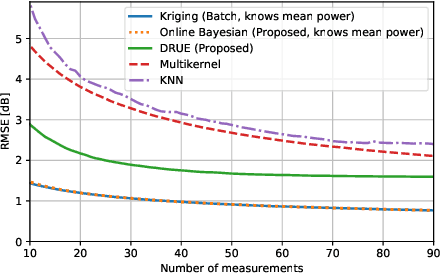
Radio maps find numerous applications in wireless communications and mobile robotics tasks, including resource allocation, interference coordination, and mission planning. Although numerous techniques have been proposed to construct radio maps from spatially distributed measurements, the locations of such measurements are assumed predetermined beforehand. In contrast, this paper proposes spectrum surveying, where a mobile robot such as an unmanned aerial vehicle (UAV) collects measurements at a set of locations that are actively selected to obtain high-quality map estimates in a short surveying time. This is performed in two steps. First, two novel algorithms, a model-based online Bayesian estimator and a data-driven deep learning algorithm, are devised for updating a map estimate and an uncertainty metric that indicates the informativeness of measurements at each possible location. These algorithms offer complementary benefits and feature constant complexity per measurement. Second, the uncertainty metric is used to plan the trajectory of the UAV to gather measurements at the most informative locations. To overcome the combinatorial complexity of this problem, a dynamic programming approach is proposed to obtain lists of waypoints through areas of large uncertainty in linear time. Numerical experiments conducted on a realistic dataset confirm that the proposed scheme constructs accurate radio maps quickly.
A Unified Transformer Framework for Group-based Segmentation: Co-Segmentation, Co-Saliency Detection and Video Salient Object Detection
Mar 11, 2022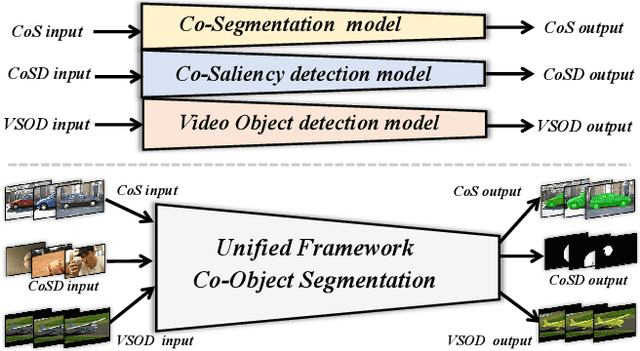
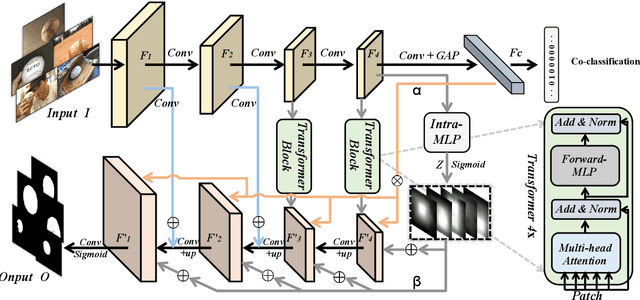
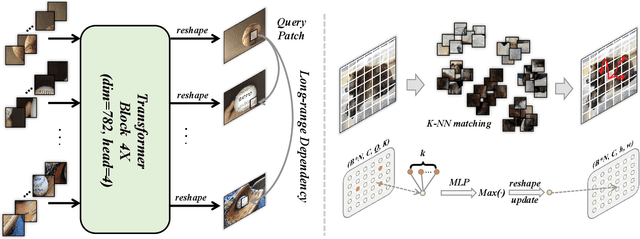
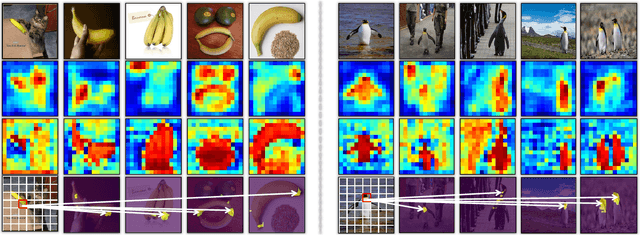
Humans tend to mine objects by learning from a group of images or several frames of video since we live in a dynamic world. In the computer vision area, many researches focus on co-segmentation (CoS), co-saliency detection (CoSD) and video salient object detection (VSOD) to discover the co-occurrent objects. However, previous approaches design different networks on these similar tasks separately, and they are difficult to apply to each other, which lowers the upper bound of the transferability of deep learning frameworks. Besides, they fail to take full advantage of the cues among inter- and intra-feature within a group of images. In this paper, we introduce a unified framework to tackle these issues, term as UFO (Unified Framework for Co-Object Segmentation). Specifically, we first introduce a transformer block, which views the image feature as a patch token and then captures their long-range dependencies through the self-attention mechanism. This can help the network to excavate the patch structured similarities among the relevant objects. Furthermore, we propose an intra-MLP learning module to produce self-mask to enhance the network to avoid partial activation. Extensive experiments on four CoS benchmarks (PASCAL, iCoseg, Internet and MSRC), three CoSD benchmarks (Cosal2015, CoSOD3k, and CocA) and four VSOD benchmarks (DAVIS16, FBMS, ViSal and SegV2) show that our method outperforms other state-of-the-arts on three different tasks in both accuracy and speed by using the same network architecture , which can reach 140 FPS in real-time.
Complementary Time-Frequency Domain Networks for Dynamic Parallel MR Image Reconstruction
Dec 22, 2020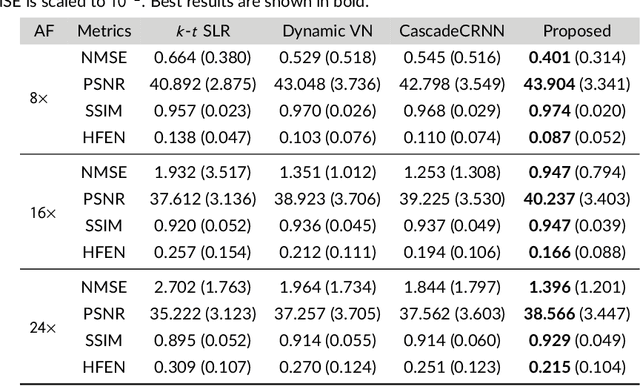
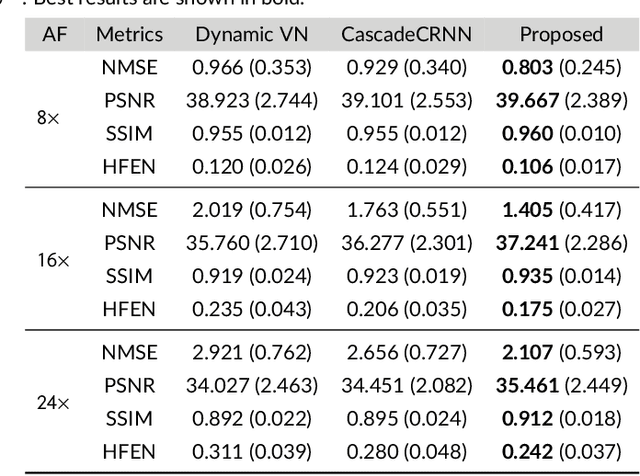
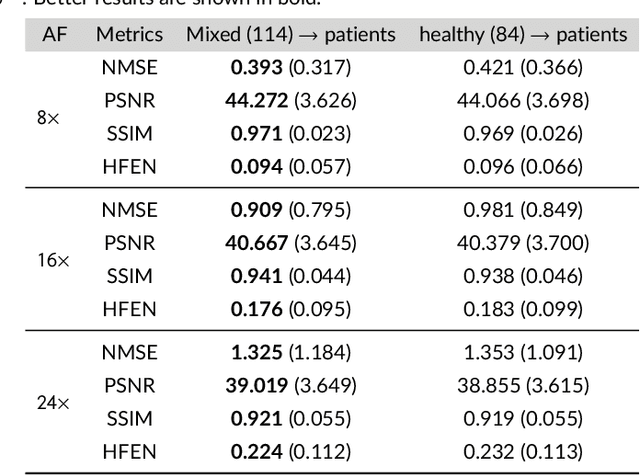
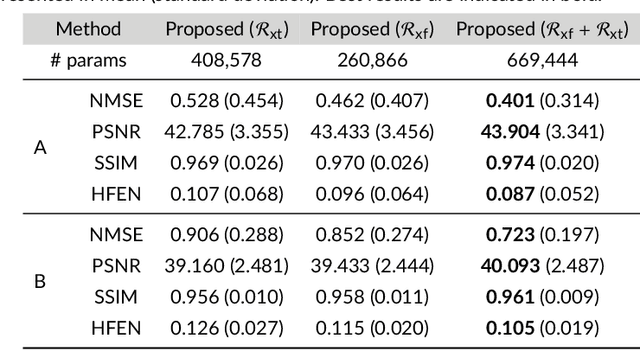
Purpose: To introduce a novel deep learning based approach for fast and high-quality dynamic multi-coil MR reconstruction by learning a complementary time-frequency domain network that exploits spatio-temporal correlations simultaneously from complementary domains. Theory and Methods: Dynamic parallel MR image reconstruction is formulated as a multi-variable minimisation problem, where the data is regularised in combined temporal Fourier and spatial (x-f) domain as well as in spatio-temporal image (x-t) domain. An iterative algorithm based on variable splitting technique is derived, which alternates among signal de-aliasing steps in x-f and x-t spaces, a closed-form point-wise data consistency step and a weighted coupling step. The iterative model is embedded into a deep recurrent neural network which learns to recover the image via exploiting spatio-temporal redundancies in complementary domains. Results: Experiments were performed on two datasets of highly undersampled multi-coil short-axis cardiac cine MRI scans. Results demonstrate that our proposed method outperforms the current state-of-the-art approaches both quantitatively and qualitatively. The proposed model can also generalise well to data acquired from a different scanner and data with pathologies that were not seen in the training set. Conclusion: The work shows the benefit of reconstructing dynamic parallel MRI in complementary time-frequency domains with deep neural networks. The method can effectively and robustly reconstruct high-quality images from highly undersampled dynamic multi-coil data ($16 \times$ and $24 \times$ yielding 15s and 10s scan times respectively) with fast reconstruction speed (2.8s). This could potentially facilitate achieving fast single-breath-hold clinical 2D cardiac cine imaging.
The Semantic Adjacency Criterion in Time Intervals Mining
Jan 11, 2021
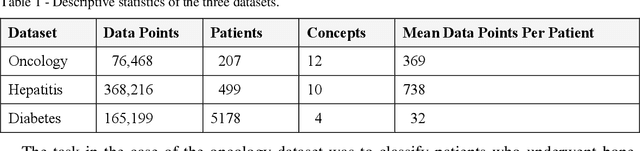
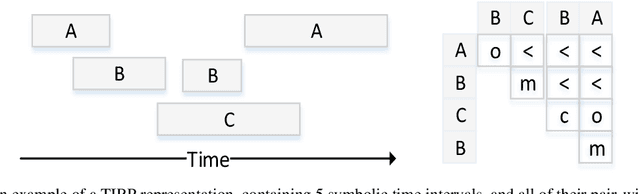
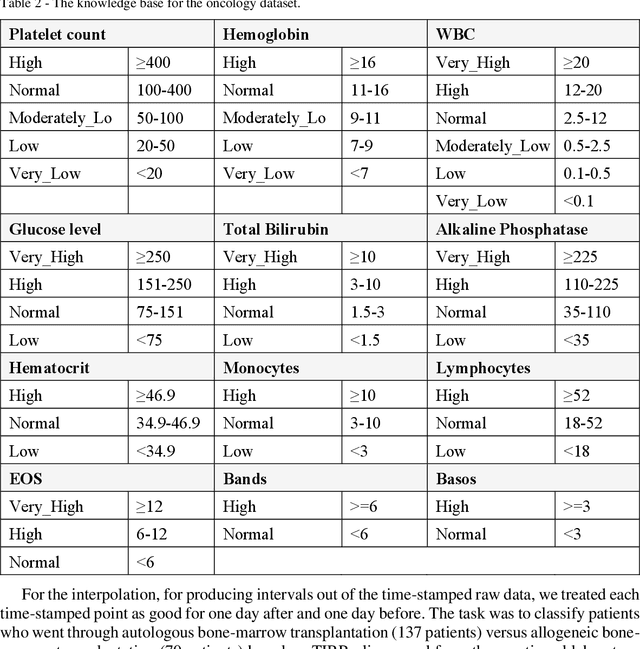
Frequent temporal patterns discovered in time-interval-based multivariate data, although syntactically correct, might be non-transparent: For some pattern instances, there might exist intervals for the same entity that contradict the pattern's usual meaning. We conjecture that non-transparent patterns are also less useful as classification or prediction features. We propose a new pruning constraint during a frequent temporal-pattern discovery process, the Semantic Adjacency Criterion [SAC], which exploits domain knowledge to filter out patterns that contain potentially semantically contradictory components. We have defined three SAC versions, and tested their effect in three medical domains. We embedded these criteria in a frequent-temporal-pattern discovery framework. Previously, we had informally presented the SAC principle and showed that using it to prune patterns enhances the repeatability of their discovery in the same clinical domain. Here, we define formally the semantics of three SAC variations, and compare the use of the set of pruned patterns to the use of the complete set of discovered patterns, as features for classification and prediction tasks in three different medical domains. We induced four classifiers for each task, using four machine-learning methods: Random Forests, Naive Bayes, SVM, and Logistic Regression. The features were frequent temporal patterns discovered in each data set. SAC-based temporal pattern-discovery reduced by up to 97% the number of discovered patterns and by up to 98% the discovery runtime. But the classification and prediction performance of the reduced SAC-based pattern-based features set, was as good as when using the complete set. Using SAC can significantly reduce the number of discovered frequent interval-based temporal patterns, and the corresponding computational effort, without losing classification or prediction performance.
Hierarchical Policy Learning for Mechanical Search
Feb 28, 2022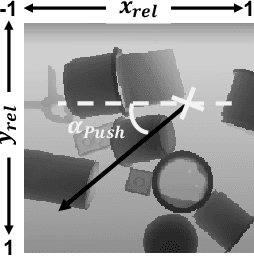

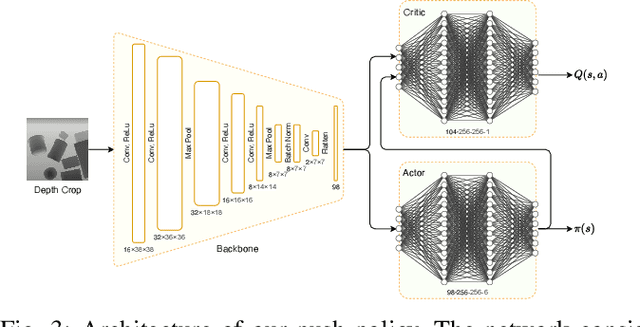
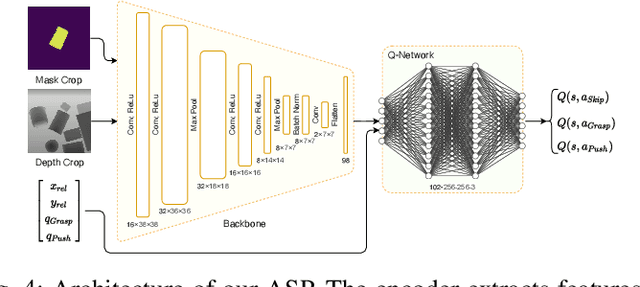
Retrieving objects from clutters is a complex task, which requires multiple interactions with the environment until the target object can be extracted. These interactions involve executing action primitives like grasping or pushing as well as setting priorities for the objects to manipulate and the actions to execute. Mechanical Search (MS) is a framework for object retrieval, which uses a heuristic algorithm for pushing and rule-based algorithms for high-level planning. While rule-based policies profit from human intuition in how they work, they usually perform sub-optimally in many cases. Deep reinforcement learning (RL) has shown great performance in complex tasks such as taking decisions through evaluating pixels, which makes it suitable for training policies in the context of object-retrieval. In this work, we first formulate the MS problem in a principled formulation as a hierarchical POMDP. Based on this formulation, we propose a hierarchical policy learning approach for the MS problem. For demonstration, we present two main parameterized sub-policies: a push policy and an action selection policy. When integrated into the hierarchical POMDP's policy, our proposed sub-policies increase the success rate of retrieving the target object from less than 32% to nearly 80%, while reducing the computation time for push actions from multiple seconds to less than 10 milliseconds.
DNS: Determinantal Point Process Based Neural Network Sampler for Ensemble Reinforcement Learning
Feb 06, 2022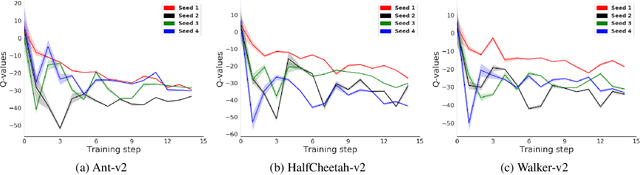
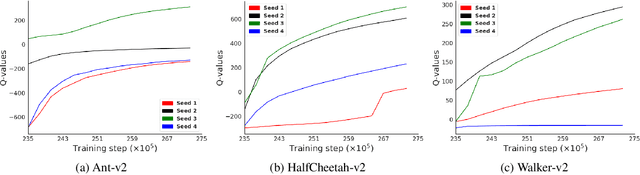
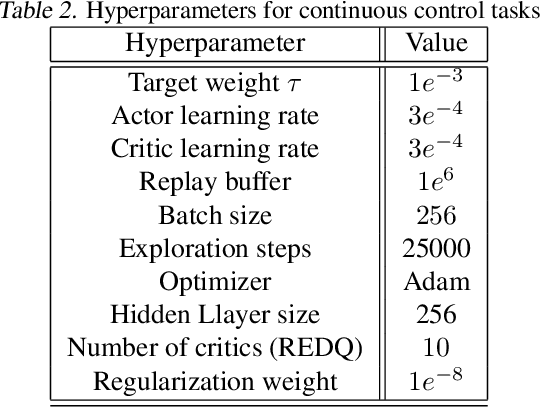
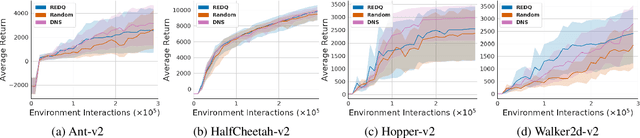
Application of ensemble of neural networks is becoming an imminent tool for advancing the state-of-the-art in deep reinforcement learning algorithms. However, training these large numbers of neural networks in the ensemble has an exceedingly high computation cost which may become a hindrance in training large-scale systems. In this paper, we propose DNS: a Determinantal Point Process based Neural Network Sampler that specifically uses k-dpp to sample a subset of neural networks for backpropagation at every training step thus significantly reducing the training time and computation cost. We integrated DNS in REDQ for continuous control tasks and evaluated on MuJoCo environments. Our experiments show that DNS augmented REDQ outperforms baseline REDQ in terms of average cumulative reward and achieves this using less than 50% computation when measured in FLOPS.