 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Agent Path Finding with Prioritized Communication Learning
Feb 10, 2022
Multi-agent pathfinding (MAPF) has been widely used to solve large-scale real-world problems, e.g., automation warehouses. The learning-based, fully decentralized framework has been introduced to alleviate real-time problems and simultaneously pursue optimal planning policy. However, existing methods might generate significantly more vertex conflicts (or collisions), which lead to a low success rate or more makespan. In this paper, we propose a PrIoritized COmmunication learning method (PICO), which incorporates the \textit{implicit} planning priorities into the communication topology within the decentralized multi-agent reinforcement learning framework. Assembling with the classic coupled planners, the implicit priority learning module can be utilized to form the dynamic communication topology, which also builds an effective collision-avoiding mechanism. PICO performs significantly better in large-scale MAPF tasks in success rates and collision rates than state-of-the-art learning-based planners.
An analysis of deep neural networks for predicting trends in time series data
Sep 16, 2020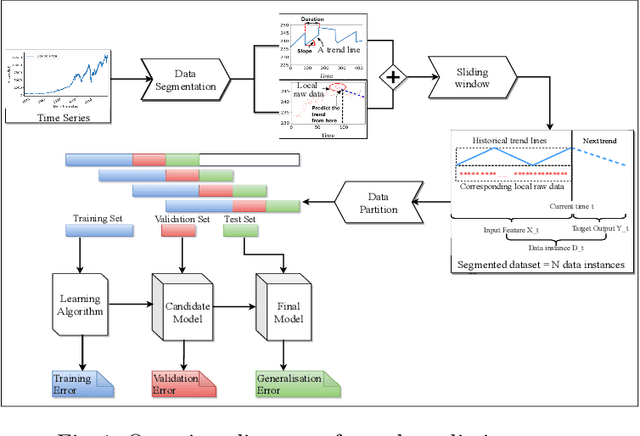

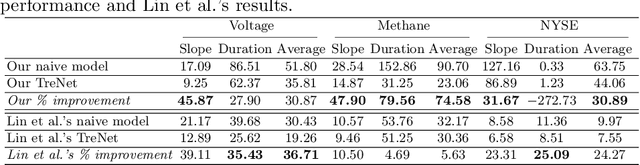
The emergence of small and portable smart sensors have opened up new opportunities for many applications, including automated factories, smart cities and connected healthcare, broadly referred to as the "Internet of Things (IoT)". These devices produce time series data. While deep neural networks (DNNs) has been widely applied to computer vision, natural language processing and speech recognition, there is limited research on DNNs for time series prediction. Machine learning (ML) applications for time series prediction has traditionally involved predicting the next value in the series. However, in certain applications, segmenting the time series into a sequence of trends and predicting the next trend is preferred. Recently, a hybrid DNN algorithm, TreNet was proposed for trend prediction. TreNet, which combines an LSTM that takes in trendlines and a CNN that takes in point data was shown to have superior performance for trend prediction when compared to other approaches. However, the study used a standard cross-validation method which does not take into account the sequential nature of time series. In this work, we reproduce TreNet using a walk-forward validation method, which is more appropriate to time series data. We compare the performance of the hybrid TreNet algorithm, on the same three data sets used in the original study, to vanilla MLP, LSTM, and CNN that take in point data, and also to traditional ML algorithms, i.e. the Random Forest (RF), Support Vector Regression and Gradient Boosting Machine. Our results differ significantly from those reported for the original TreNet. In general TreNet still performs better than the vanilla DNN models, but not substantially so as reported for the original TreNet. Furthermore, our results show that the RF algorithm performed substantially better than TreNet on the methane data set.
Multi-Model Federated Learning
Jan 07, 2022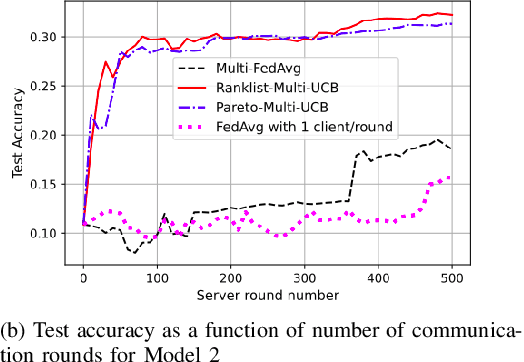
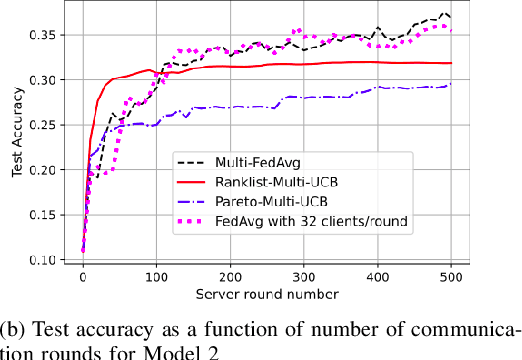
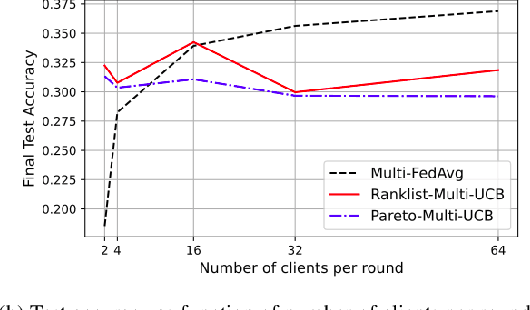
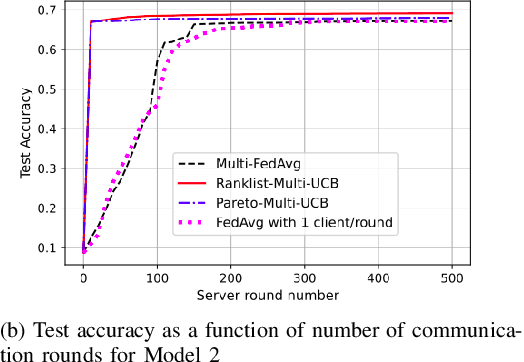
Federated learning is a form of distributed learning with the key challenge being the non-identically distributed nature of the data in the participating clients. In this paper, we extend federated learning to the setting where multiple unrelated models are trained simultaneously. Specifically, every client is able to train any one of M models at a time and the server maintains a model for each of the M models which is typically a suitably averaged version of the model computed by the clients. We propose multiple policies for assigning learning tasks to clients over time. In the first policy, we extend the widely studied FedAvg to multi-model learning by allotting models to clients in an i.i.d. stochastic manner. In addition, we propose two new policies for client selection in a multi-model federated setting which make decisions based on current local losses for each client-model pair. We compare the performance of the policies on tasks involving synthetic and real-world data and characterize the performance of the proposed policies. The key take-away from our work is that the proposed multi-model policies perform better or at least as good as single model training using FedAvg.
Effect of Active and Passive Protective Soft Skins on Collision Forces in Human-robot Collaboration
Mar 18, 2022
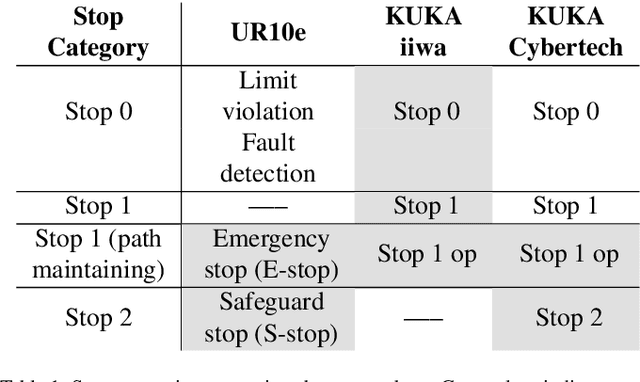
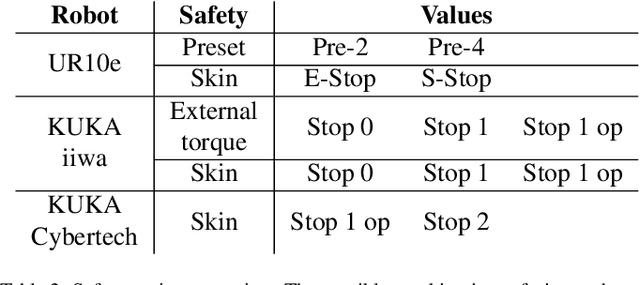
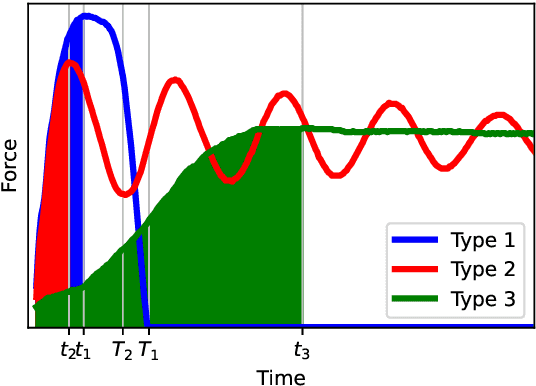
Soft electronic skins are one of the means to turn an industrial manipulator into a collaborative robot. For manipulators that are already fit for physical human-robot collaboration, soft skins can make them safer. In this work, we study the after impact behavior of two collaborative manipulators (UR10e and KUKA LBR iiwa) and one classical industrial manipulator (KUKA Cybertech), in the presence or absence of an industrial protective skin (AIRSKIN). In addition, we isolate the effects of the passive padding and the active contribution of the sensor to robot reaction. We present a total of 2250 collision measurements and study the impact force, contact duration, clamping force, and impulse. The dataset is publicly available. We summarize our results as follows. For transient collisions, the passive skin properties lowered the impact forces by about 40 %. During quasi-static contact, the effect of skin covers -- active or passive -- cannot be isolated from the collision detection and reaction by the collaborative robots. Important effects of the stop categories triggered by the active protective skin were found. We systematically compare the different settings and the empirically established safe velocities with prescriptions by the ISO/TS 15066. In some cases, up to the quadruple of the ISO/TS 15066 prescribed velocity can comply with the impact force limits and thus be considered safe. We propose an extension of the formulas relating impact force and permissible velocity that take into account the stiffness and compressible thickness of the protective cover, leading to better predictions of the collision forces. At the same time, this work emphasizes the need for in situ measurements as all the factors we studied -- presence of active/passive skin, safety stop settings, robot collision reaction, impact direction, and, of course, velocity -- have effects on the force evolution after impact.
Beyond the Policy Gradient Theorem for Efficient Policy Updates in Actor-Critic Algorithms
Feb 15, 2022

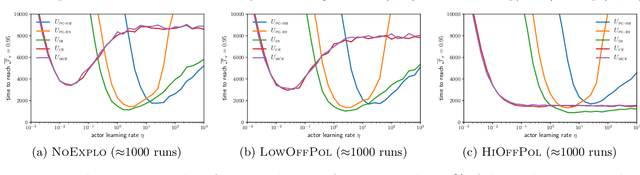
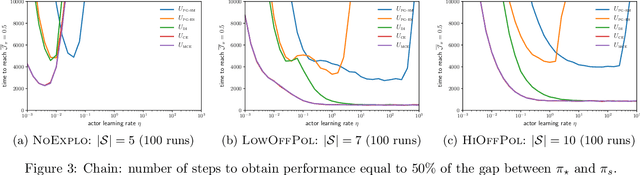
In Reinforcement Learning, the optimal action at a given state is dependent on policy decisions at subsequent states. As a consequence, the learning targets evolve with time and the policy optimization process must be efficient at unlearning what it previously learnt. In this paper, we discover that the policy gradient theorem prescribes policy updates that are slow to unlearn because of their structural symmetry with respect to the value target. To increase the unlearning speed, we study a novel policy update: the gradient of the cross-entropy loss with respect to the action maximizing $q$, but find that such updates may lead to a decrease in value. Consequently, we introduce a modified policy update devoid of that flaw, and prove its guarantees of convergence to global optimality in $\mathcal{O}(t^{-1})$ under classic assumptions. Further, we assess standard policy updates and our cross-entropy policy updates along six analytical dimensions. Finally, we empirically validate our theoretical findings.
A Multidisciplinary Approach to Optimal Communication and Flight Operation of High Altitude Long Endurance Platform
Mar 01, 2022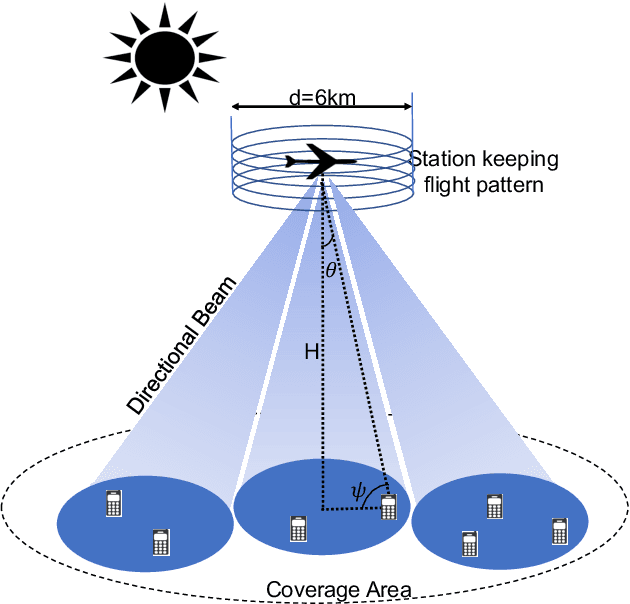
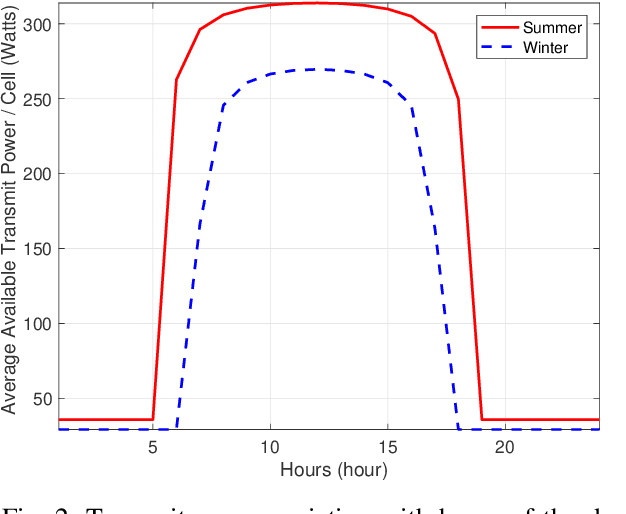
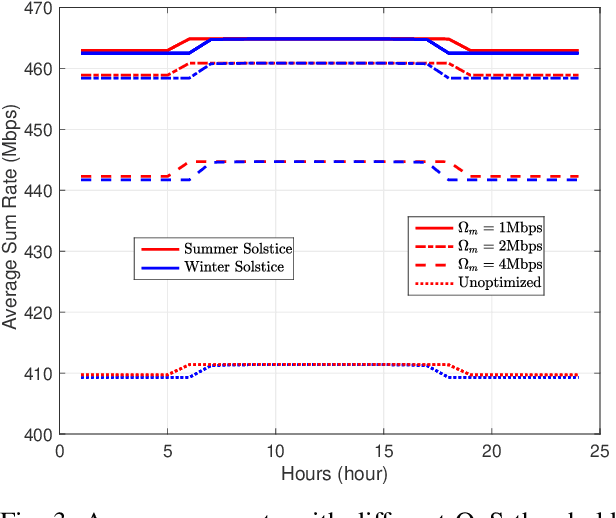
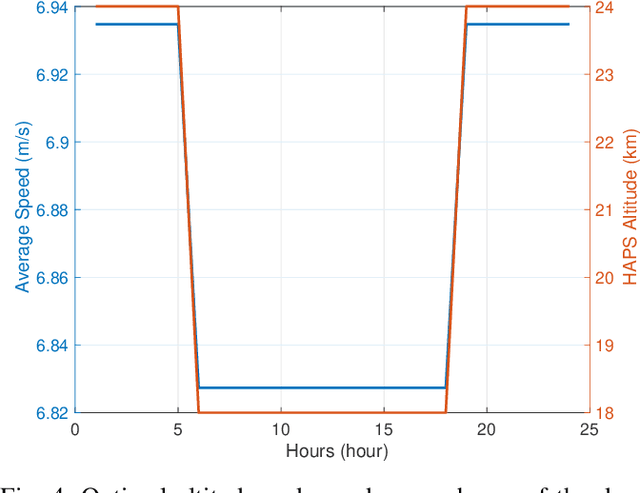
Aerial communication platforms especially stratospheric high altitude pseudo-satellite (HAPS) has the potential to provide/catalyze advanced mobile wireless communication services with its ubiquitous connectivity and ultra-wide coverage radius. Recently, HAPS has gained immense popularity - achieved primarily through self-sufficient energy systems - to render long endurance characteristics. The photo voltaic cells mounted on the aircraft harvest solar energy during the day, which is partially used for communication and station keeping, whereas, the excess is stored in the rechargeable batteries for the night time operation. We carried out an adroit power budgeting to ascertain if the available solar power can simultaneously and efficiently self-sustain the requisite propulsion and communication power expense. We propose an energy optimum trajectory for station-keeping flight and non-orthogonal multiple access (NOMA) for users in multicells served by the directional beams from HAPS communication system. We design optimal power allocation for downlink (DL) NOMA users along with the ideal position and speed of flight with the aim to maximize sum data rate during the day and minimize power expenditure during the night while ensuring quality of service. Our findings reveal the significance of joint design of communication and aerodynamics parameters for optimum energy utilization and resource allocation.
Real Time Detection of Small Objects
Apr 14, 2020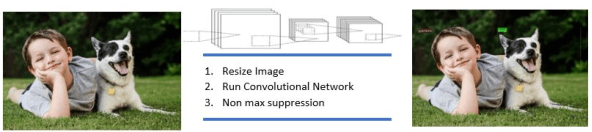
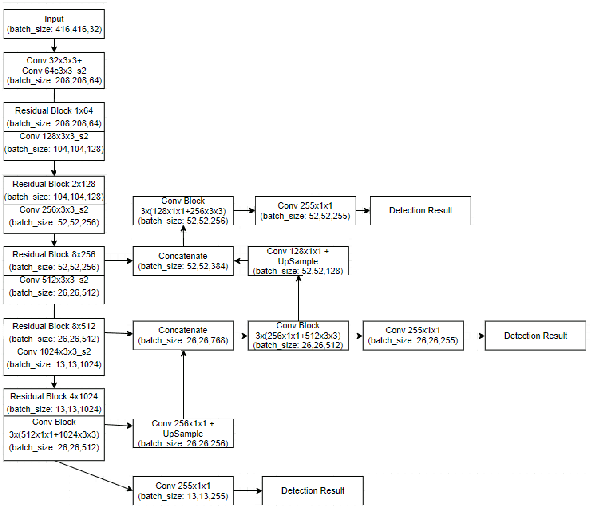
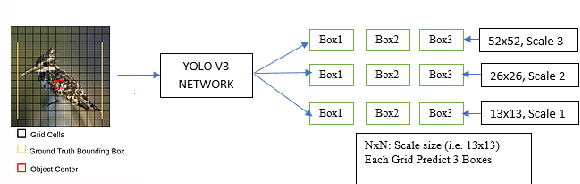
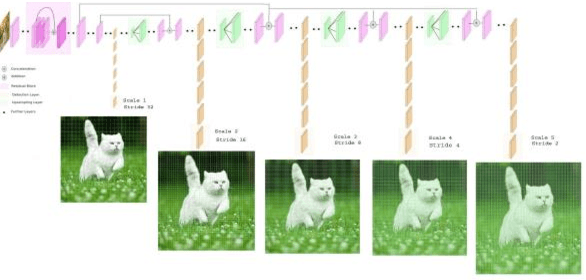
The existing real time object detection algorithm is based on the deep neural network of convolution need to perform multilevel convolution and pooling operations on the entire image to extract a deep semantic characteristic of the image. The detection models perform better for large objects. However, these models do not detect small objects with low resolution and noise, because the features of existing models do not fully represent the essential features of small objects after repeated convolution operations. We have introduced a novel real time detection algorithm which employs upsampling and skip connection to extract multiscale features at different convolution levels in a learning task resulting a remarkable performance in detecting small objects. The detection precision of the model is shown to be higher and faster than that of the state-of-the-art models.
* 7 pages, 8 figures
Speaker Representation Learning using Global Context Guided Channel and Time-Frequency Transformations
Sep 09, 2020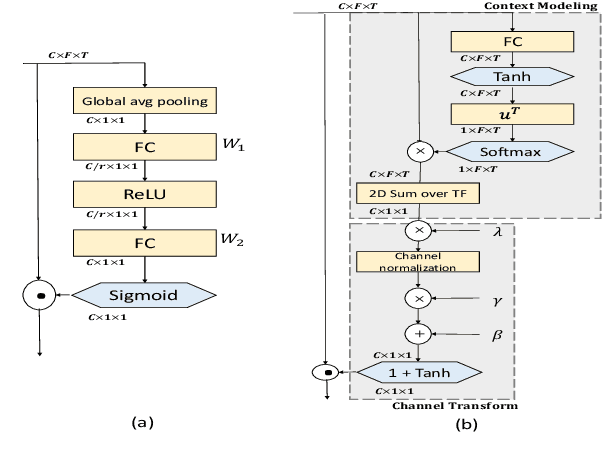
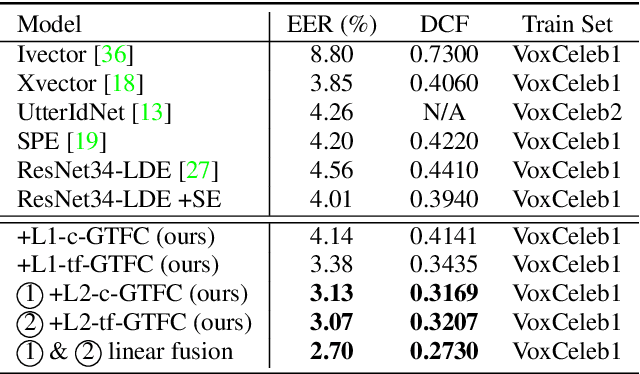
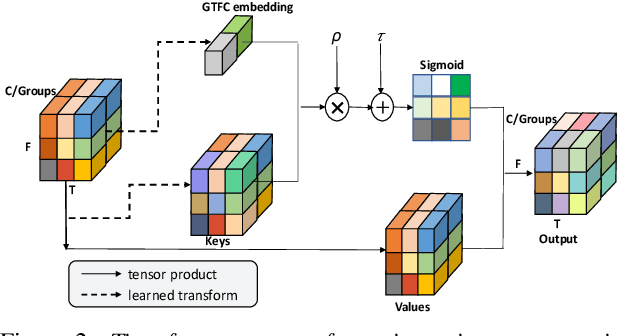
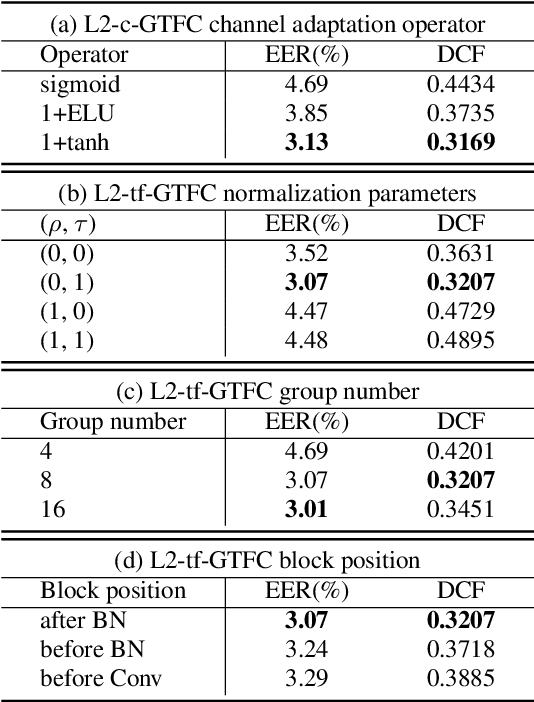
In this study, we propose the global context guided channel and time-frequency transformations to model the long-range, non-local time-frequency dependencies and channel variances in speaker representations. We use the global context information to enhance important channels and recalibrate salient time-frequency locations by computing the similarity between the global context and local features. The proposed modules, together with a popular ResNet based model, are evaluated on the VoxCeleb1 dataset, which is a large scale speaker verification corpus collected in the wild. This lightweight block can be easily incorporated into a CNN model with little additional computational costs and effectively improves the speaker verification performance compared to the baseline ResNet-LDE model and the Squeeze&Excitation block by a large margin. Detailed ablation studies are also performed to analyze various factors that may impact the performance of the proposed modules. We find that by employing the proposed L2-tf-GTFC transformation block, the Equal Error Rate decreases from 4.56% to 3.07%, a relative 32.68% reduction, and a relative 27.28% improvement in terms of the DCF score. The results indicate that our proposed global context guided transformation modules can efficiently improve the learned speaker representations by achieving time-frequency and channel-wise feature recalibration.
Learning robust perceptive locomotion for quadrupedal robots in the wild
Jan 20, 2022Legged robots that can operate autonomously in remote and hazardous environments will greatly increase opportunities for exploration into under-explored areas. Exteroceptive perception is crucial for fast and energy-efficient locomotion: perceiving the terrain before making contact with it enables planning and adaptation of the gait ahead of time to maintain speed and stability. However, utilizing exteroceptive perception robustly for locomotion has remained a grand challenge in robotics. Snow, vegetation, and water visually appear as obstacles on which the robot cannot step~-- or are missing altogether due to high reflectance. Additionally, depth perception can degrade due to difficult lighting, dust, fog, reflective or transparent surfaces, sensor occlusion, and more. For this reason, the most robust and general solutions to legged locomotion to date rely solely on proprioception. This severely limits locomotion speed, because the robot has to physically feel out the terrain before adapting its gait accordingly. Here we present a robust and general solution to integrating exteroceptive and proprioceptive perception for legged locomotion. We leverage an attention-based recurrent encoder that integrates proprioceptive and exteroceptive input. The encoder is trained end-to-end and learns to seamlessly combine the different perception modalities without resorting to heuristics. The result is a legged locomotion controller with high robustness and speed. The controller was tested in a variety of challenging natural and urban environments over multiple seasons and completed an hour-long hike in the Alps in the time recommended for human hikers.
Adaptive Information Belief Space Planning
Jan 28, 2022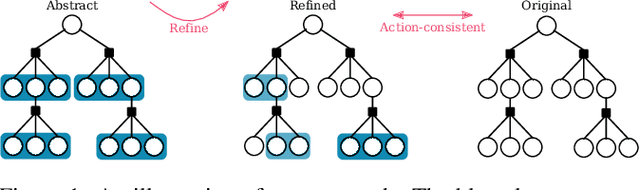
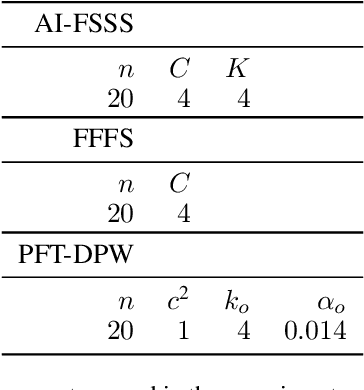
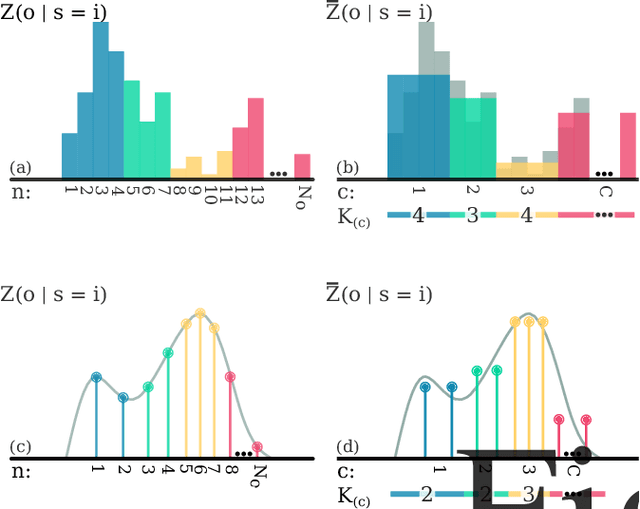
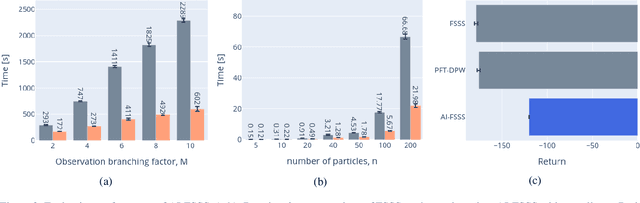
Reasoning about uncertainty is vital in many real-life autonomous systems. However, current state-of-the-art planning algorithms cannot either reason about uncertainty explicitly, or do so with a high computational burden. Here, we focus on making informed decisions efficiently, using reward functions that explicitly deal with uncertainty. We formulate an approximation, namely an abstract observation model, that uses an aggregation scheme to alleviate computational costs. We derive bounds on the expected information-theoretic reward function and, as a consequence, on the value function. We then propose a method to refine aggregation to achieve identical action selection with a fraction of the computational time.