 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Beyond the Policy Gradient Theorem for Efficient Policy Updates in Actor-Critic Algorithms
Feb 15, 2022


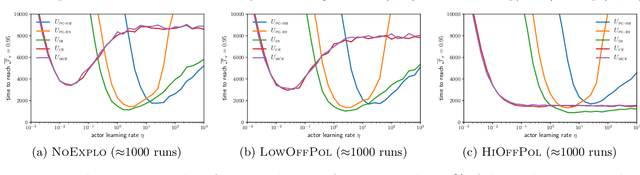
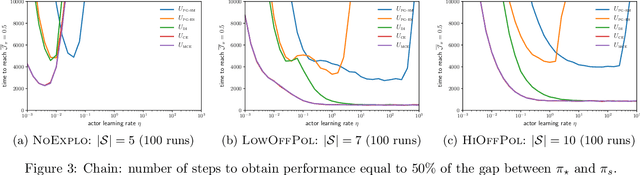
In Reinforcement Learning, the optimal action at a given state is dependent on policy decisions at subsequent states. As a consequence, the learning targets evolve with time and the policy optimization process must be efficient at unlearning what it previously learnt. In this paper, we discover that the policy gradient theorem prescribes policy updates that are slow to unlearn because of their structural symmetry with respect to the value target. To increase the unlearning speed, we study a novel policy update: the gradient of the cross-entropy loss with respect to the action maximizing $q$, but find that such updates may lead to a decrease in value. Consequently, we introduce a modified policy update devoid of that flaw, and prove its guarantees of convergence to global optimality in $\mathcal{O}(t^{-1})$ under classic assumptions. Further, we assess standard policy updates and our cross-entropy policy updates along six analytical dimensions. Finally, we empirically validate our theoretical findings.
Fast-R2D2: A Pretrained Recursive Neural Network based on Pruned CKY for Grammar Induction and Text Representation
Mar 01, 2022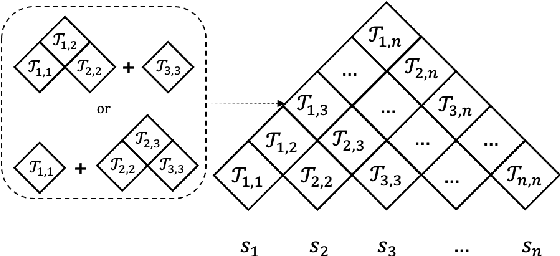
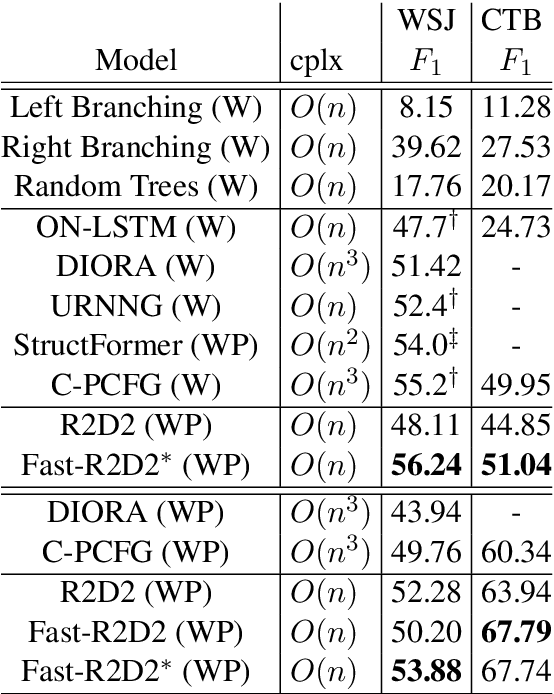

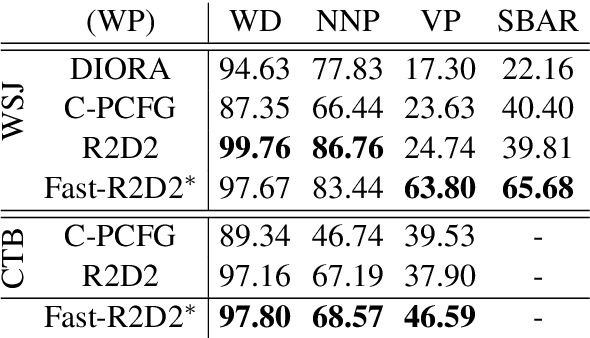
Recently CKY-based models show great potential in unsupervised grammar induction thanks to their human-like encoding paradigm, which runs recursively and hierarchically, but requires $O(n^3)$ time-complexity. Recursive Transformer based on Differentiable Trees (R2D2) makes it possible to scale to large language model pre-training even with complex tree encoder by introducing a heuristic pruning method. However, the rule-based pruning approach suffers from local optimum and slow inference issues. In this paper, we fix those issues in a unified method. We propose to use a top-down parser as a model-based pruning method, which also enables parallel encoding during inference. Typically, our parser casts parsing as a split point scoring task, which first scores all split points for a given sentence, and then recursively splits a span into two by picking a split point with the highest score in the current span. The reverse order of the splits is considered as the order of pruning in R2D2 encoder. Beside the bi-directional language model loss, we also optimize the parser by minimizing the KL distance between tree probabilities from parser and R2D2. Our experiments show that our Fast-R2D2 improves performance significantly in grammar induction and achieves competitive results in downstream classification tasks.
Multi-Vehicle Control in Roundabouts using Decentralized Game-Theoretic Planning
Jan 08, 2022
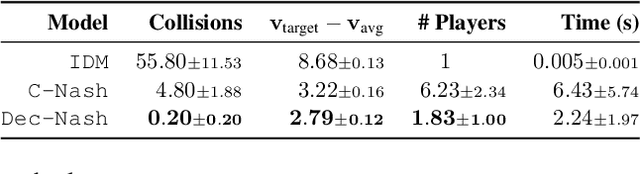
Safe navigation in dense, urban driving environments remains an open problem and an active area of research. Unlike typical predict-then-plan approaches, game-theoretic planning considers how one vehicle's plan will affect the actions of another. Recent work has demonstrated significant improvements in the time required to find local Nash equilibria in general-sum games with nonlinear objectives and constraints. When applied trivially to driving, these works assume all vehicles in a scene play a game together, which can result in intractable computation times for dense traffic. We formulate a decentralized approach to game-theoretic planning by assuming that agents only play games within their observational vicinity, which we believe to be a more reasonable assumption for human driving. Games are played in parallel for all strongly connected components of an interaction graph, significantly reducing the number of players and constraints in each game, and therefore the time required for planning. We demonstrate that our approach can achieve collision-free, efficient driving in urban environments by comparing performance against an adaptation of the Intelligent Driver Model and centralized game-theoretic planning when navigating roundabouts in the INTERACTION dataset. Our implementation is available at http://github.com/sisl/DecNashPlanning.
Continual Learning from Demonstration of Robotic Skills
Feb 15, 2022
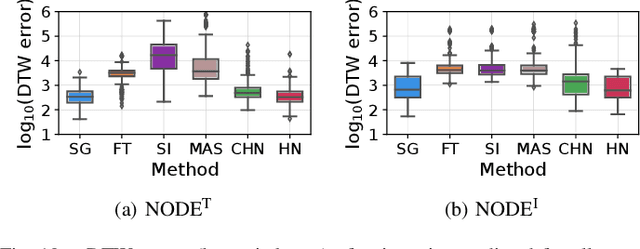

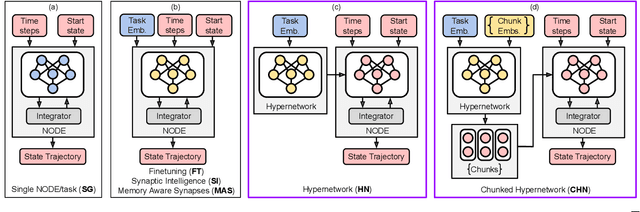
Methods for teaching motion skills to robots focus on training for a single skill at a time. Robots capable of learning from demonstration can considerably benefit from the added ability to learn new movements without forgetting past knowledge. To this end, we propose an approach for continual learning from demonstration using hypernetworks and neural ordinary differential equation solvers. We empirically demonstrate the effectiveness of our approach in remembering long sequences of trajectory learning tasks without the need to store any data from past demonstrations. Our results show that hypernetworks outperform other state-of-the-art regularization-based continual learning approaches for learning from demonstration. In our experiments, we use the popular LASA trajectory benchmark, and a new dataset of kinesthetic demonstrations that we introduce in this paper called the HelloWorld dataset. We evaluate our approach using both trajectory error metrics and continual learning metrics, and we propose two new continual learning metrics. Our code, along with the newly collected dataset, is available at https://github.com/sayantanauddy/clfd.
ViNTER: Image Narrative Generation with Emotion-Arc-Aware Transformer
Feb 15, 2022
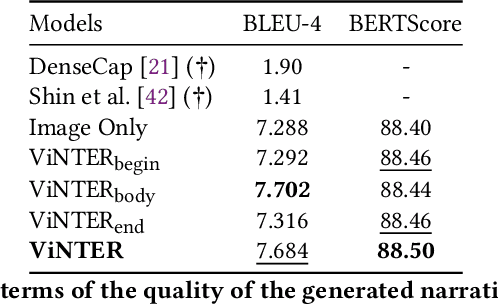
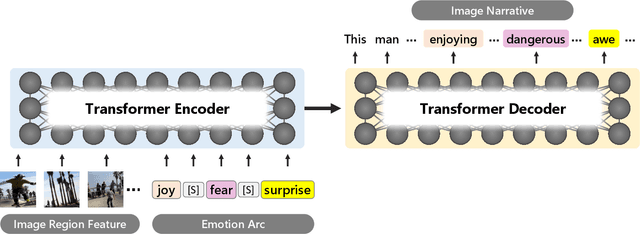
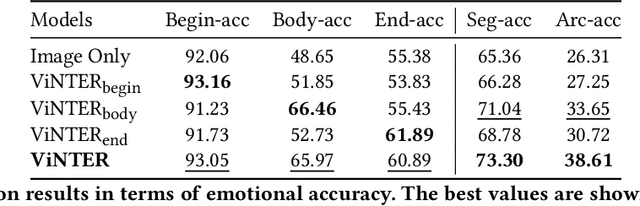
Image narrative generation describes the creation of stories regarding the content of image data from a subjective viewpoint. Given the importance of the subjective feelings of writers, characters, and readers in storytelling, image narrative generation methods must consider human emotion, which is their major difference from descriptive caption generation tasks. The development of automated methods to generate story-like text associated with images may be considered to be of considerable social significance, because stories serve essential functions both as entertainment and also for many practical purposes such as education and advertising. In this study, we propose a model called ViNTER (Visual Narrative Transformer with Emotion arc Representation) to generate image narratives that focus on time series representing varying emotions as "emotion arcs," to take advantage of recent advances in multimodal Transformer-based pre-trained models. We present experimental results of both manual and automatic evaluations, which demonstrate the effectiveness of the proposed emotion-aware approach to image narrative generation.
Imbedding Deep Neural Networks
Feb 15, 2022
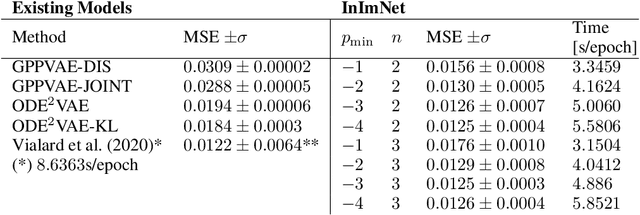
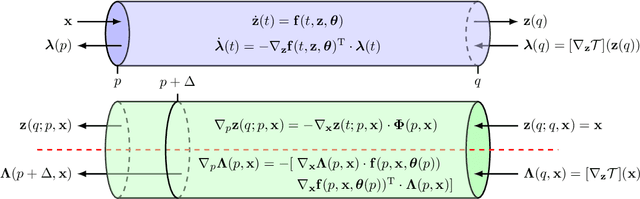
Continuous-depth neural networks, such as Neural ODEs, have refashioned the understanding of residual neural networks in terms of non-linear vector-valued optimal control problems. The common solution is to use the adjoint sensitivity method to replicate a forward-backward pass optimisation problem. We propose a new approach which explicates the network's `depth' as a fundamental variable, thus reducing the problem to a system of forward-facing initial value problems. This new method is based on the principle of `Invariant Imbedding' for which we prove a general solution, applicable to all non-linear, vector-valued optimal control problems with both running and terminal loss. Our new architectures provide a tangible tool for inspecting the theoretical--and to a great extent unexplained--properties of network depth. They also constitute a resource of discrete implementations of Neural ODEs comparable to classes of imbedded residual neural networks. Through a series of experiments, we show the competitive performance of the proposed architectures for supervised learning and time series prediction.
RMBR: A Regularized Minimum Bayes Risk Reranking Framework for Machine Translation
Mar 01, 2022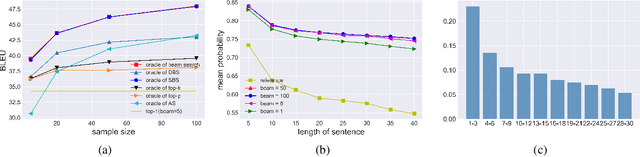
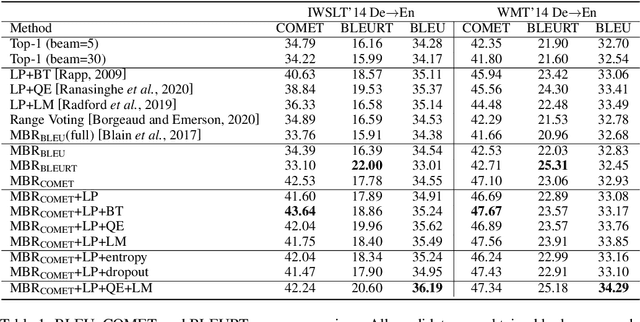
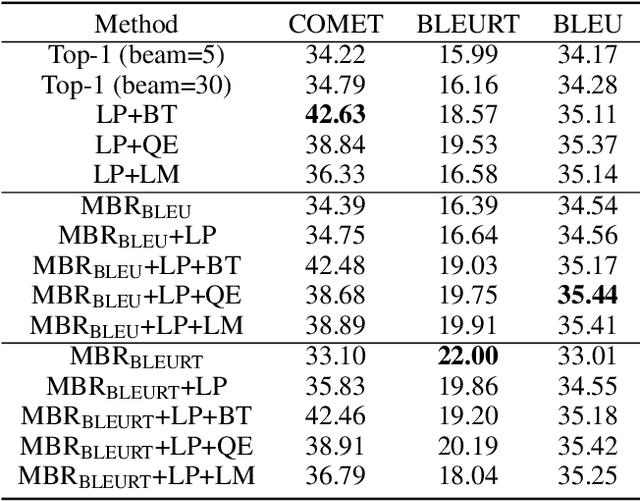
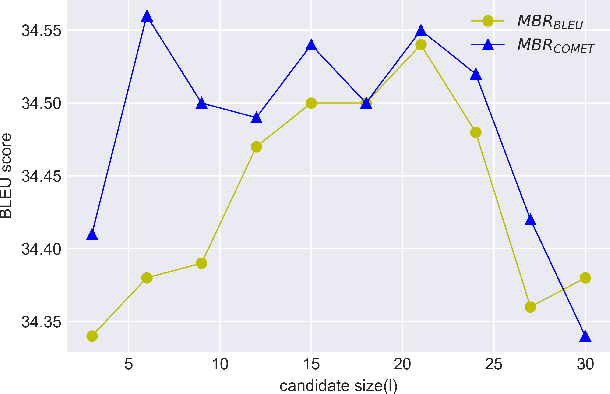
Beam search is the most widely used decoding method for neural machine translation (NMT). In practice, the top-1 candidate with the highest log-probability among the n candidates is selected as the preferred one. However, this top-1 candidate may not be the best overall translation among the n-best list. Recently, Minimum Bayes Risk (MBR) decoding has been proposed to improve the quality for NMT, which seeks for a consensus translation that is closest on average to other candidates from the n-best list. We argue that MBR still suffers from the following problems: The utility function only considers the lexical-level similarity between candidates; The expected utility considers the entire n-best list which is time-consuming and inadequate candidates in the tail list may hurt the performance; Only the relationship between candidates is considered. To solve these issues, we design a regularized MBR reranking framework (RMBR), which considers semantic-based similarity and computes the expected utility for each candidate by truncating the list. We expect the proposed framework to further consider the translation quality and model uncertainty of each candidate. Thus the proposed quality regularizer and uncertainty regularizer are incorporated into the framework. Extensive experiments on multiple translation tasks demonstrate the effectiveness of our method.
Long Document Summarization with Top-down and Bottom-up Inference
Mar 15, 2022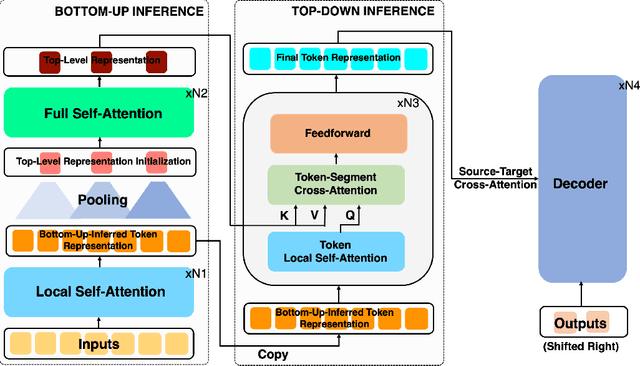
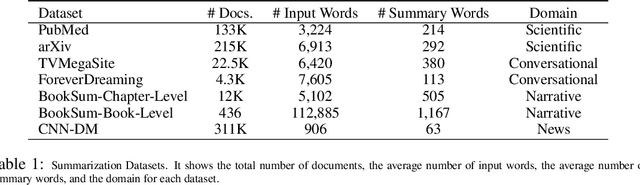
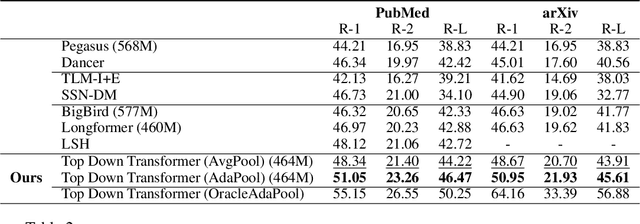

Text summarization aims to condense long documents and retain key information. Critical to the success of a summarization model is the faithful inference of latent representations of words or tokens in the source documents. Most recent models infer the latent representations with a transformer encoder, which is purely bottom-up. Also, self-attention-based inference models face the challenge of quadratic complexity with respect to sequence length. We propose a principled inference framework to improve summarization models on these two aspects. Our framework assumes a hierarchical latent structure of a document where the top-level captures the long range dependency at a coarser time scale and the bottom token level preserves the details. Critically, this hierarchical structure enables token representations to be updated in both a bottom-up and top-down manner. In the bottom-up pass, token representations are inferred with local self-attention to leverage its efficiency. Top-down correction is then applied to allow tokens to capture long-range dependency. We demonstrate the effectiveness of the proposed framework on a diverse set of summarization datasets, including narrative, conversational, scientific documents and news. Our model achieves (1) competitive or better performance on short documents with higher memory and compute efficiency, compared to full attention transformers, and (2) state-of-the-art performance on a wide range of long document summarization benchmarks, compared to recent efficient transformers. We also show that our model can summarize an entire book and achieve competitive performance using $0.27\%$ parameters (464M vs. 175B) and much less training data, compared to a recent GPT-3-based model. These results indicate the general applicability and benefits of the proposed framework.
Towards Real-time Drowsiness Detection for Elderly Care
Oct 21, 2020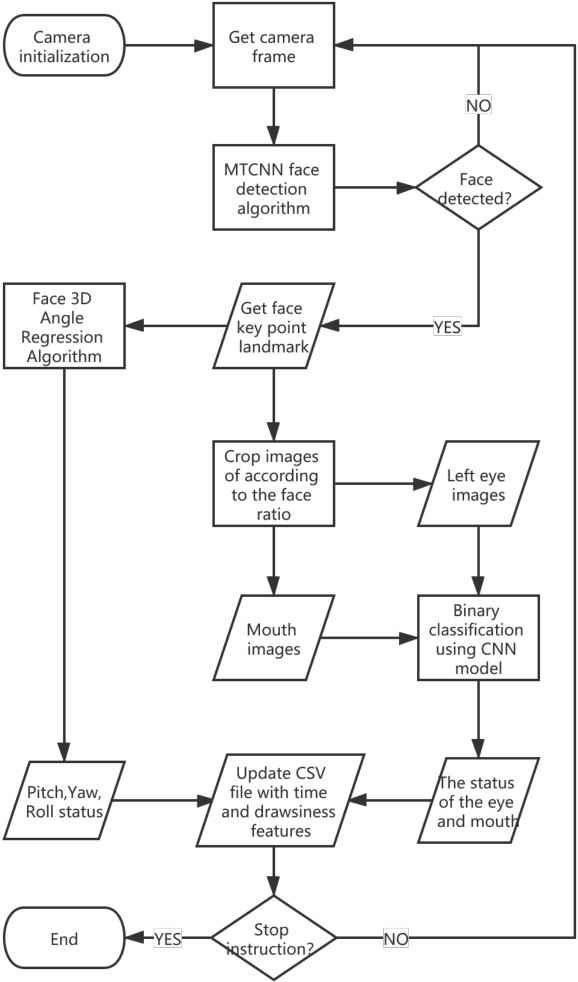
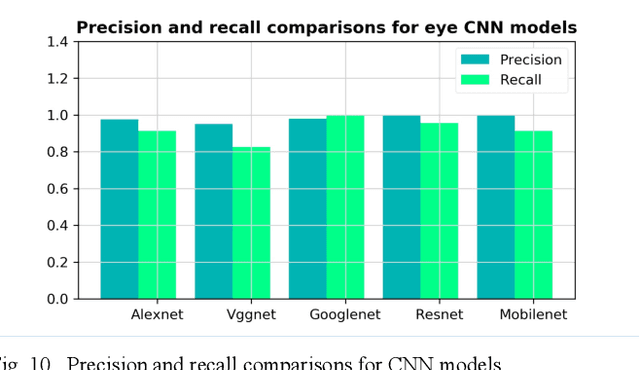

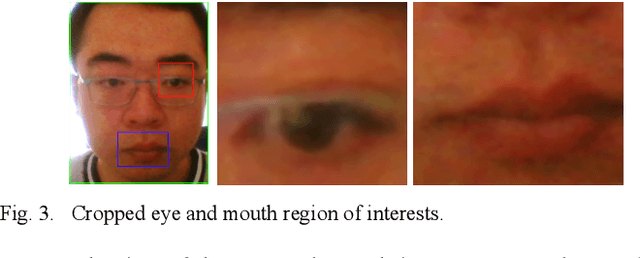
The primary focus of this paper is to produce a proof of concept for extracting drowsiness information from videos to help elderly living on their own. To quantify yawning, eyelid and head movement over time, we extracted 3000 images from captured videos for training and testing of deep learning models integrated with OpenCV library. The achieved classification accuracy for eyelid and mouth open/close status were between 94.3%-97.2%. Visual inspection of head movement from videos with generated 3D coordinate overlays, indicated clear spatiotemporal patterns in collected data (yaw, roll and pitch). Extraction methodology of the drowsiness information as timeseries is applicable to other contexts including support for prior work in privacy-preserving augmented coaching, sport rehabilitation, and integration with big data platform in healthcare.
Adaptive Information Belief Space Planning
Jan 28, 2022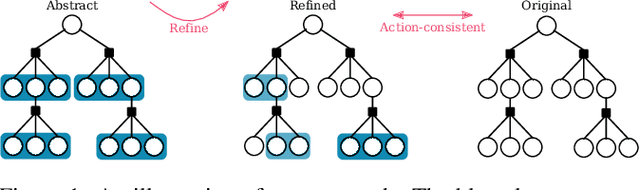
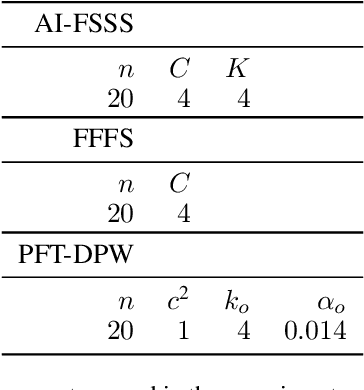
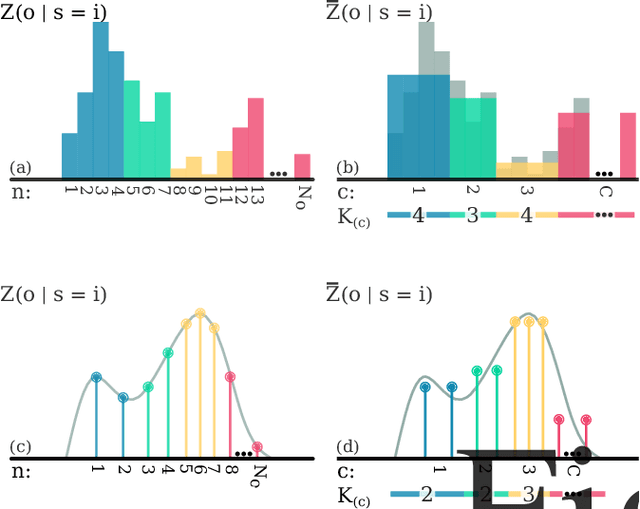
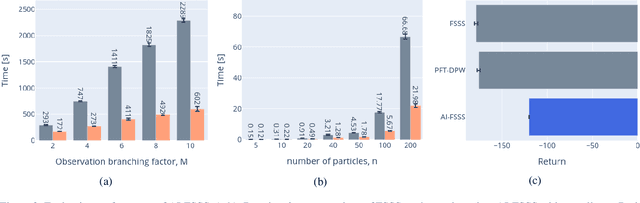
Reasoning about uncertainty is vital in many real-life autonomous systems. However, current state-of-the-art planning algorithms cannot either reason about uncertainty explicitly, or do so with a high computational burden. Here, we focus on making informed decisions efficiently, using reward functions that explicitly deal with uncertainty. We formulate an approximation, namely an abstract observation model, that uses an aggregation scheme to alleviate computational costs. We derive bounds on the expected information-theoretic reward function and, as a consequence, on the value function. We then propose a method to refine aggregation to achieve identical action selection with a fraction of the computational time.