 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Mining Robust Default Configurations for Resource-constrained AutoML
Feb 20, 2022
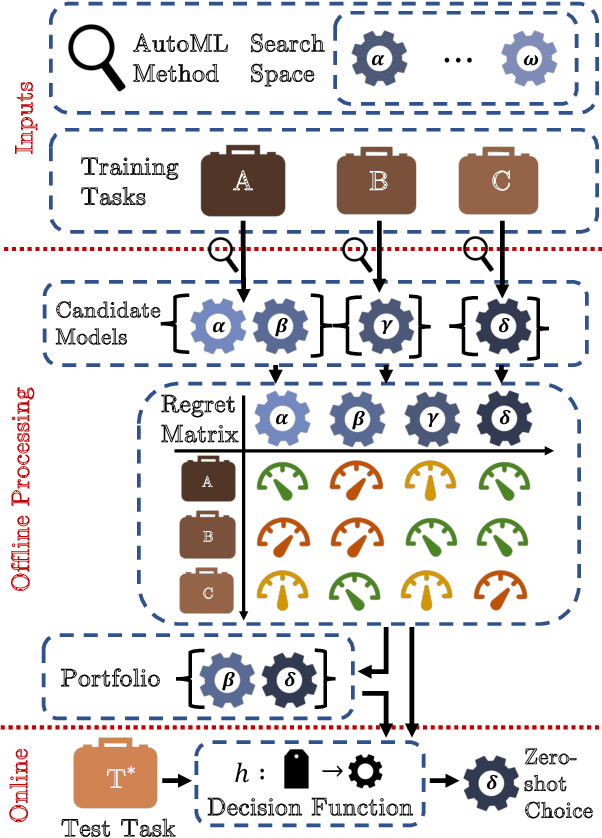
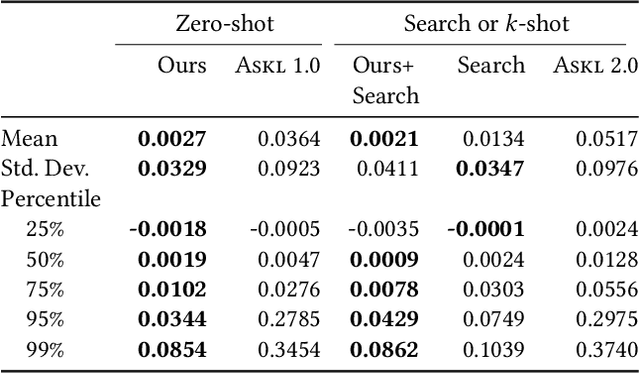
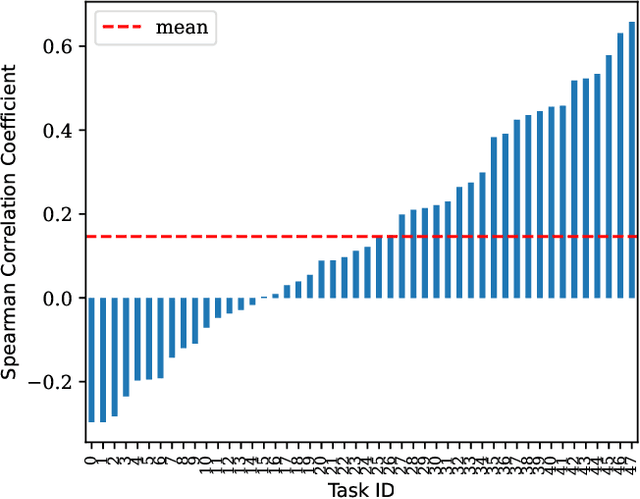
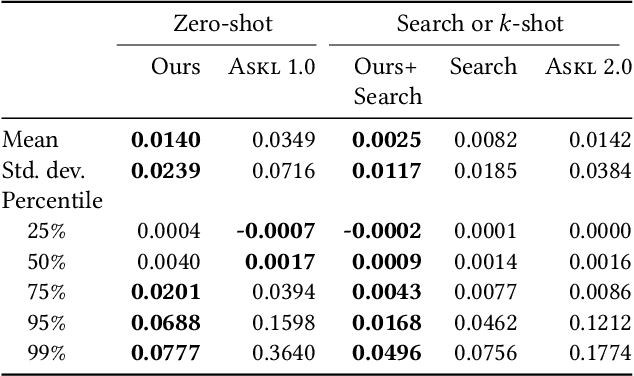
Automatic machine learning (AutoML) is a key enabler of the mass deployment of the next generation of machine learning systems. A key desideratum for future ML systems is the automatic selection of models and hyperparameters. We present a novel method of selecting performant configurations for a given task by performing offline autoML and mining over a diverse set of tasks. By mining the training tasks, we can select a compact portfolio of configurations that perform well over a wide variety of tasks, as well as learn a strategy to select portfolio configurations for yet-unseen tasks. The algorithm runs in a zero-shot manner, that is without training any models online except the chosen one. In a compute- or time-constrained setting, this virtually instant selection is highly performant. Further, we show that our approach is effective for warm-starting existing autoML platforms. In both settings, we demonstrate an improvement on the state-of-the-art by testing over 62 classification and regression datasets. We also demonstrate the utility of recommending data-dependent default configurations that outperform widely used hand-crafted defaults.
Effect of Active and Passive Protective Soft Skins on Collision Forces in Human-robot Collaboration
Mar 18, 2022
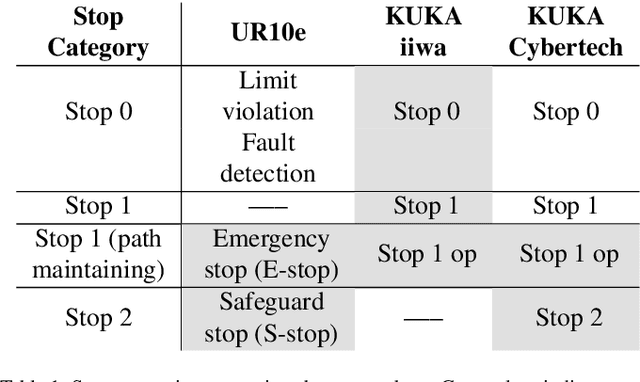
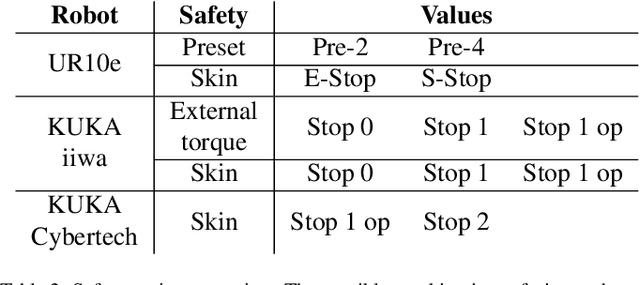
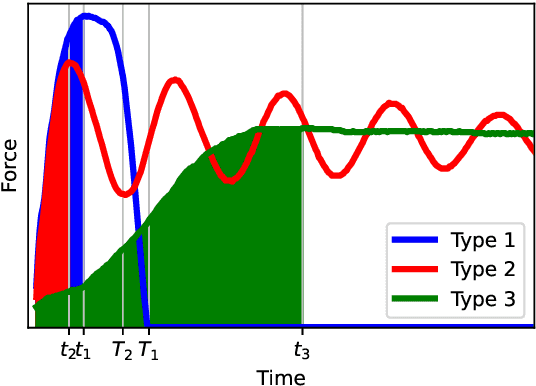
Soft electronic skins are one of the means to turn an industrial manipulator into a collaborative robot. For manipulators that are already fit for physical human-robot collaboration, soft skins can make them safer. In this work, we study the after impact behavior of two collaborative manipulators (UR10e and KUKA LBR iiwa) and one classical industrial manipulator (KUKA Cybertech), in the presence or absence of an industrial protective skin (AIRSKIN). In addition, we isolate the effects of the passive padding and the active contribution of the sensor to robot reaction. We present a total of 2250 collision measurements and study the impact force, contact duration, clamping force, and impulse. The dataset is publicly available. We summarize our results as follows. For transient collisions, the passive skin properties lowered the impact forces by about 40 %. During quasi-static contact, the effect of skin covers -- active or passive -- cannot be isolated from the collision detection and reaction by the collaborative robots. Important effects of the stop categories triggered by the active protective skin were found. We systematically compare the different settings and the empirically established safe velocities with prescriptions by the ISO/TS 15066. In some cases, up to the quadruple of the ISO/TS 15066 prescribed velocity can comply with the impact force limits and thus be considered safe. We propose an extension of the formulas relating impact force and permissible velocity that take into account the stiffness and compressible thickness of the protective cover, leading to better predictions of the collision forces. At the same time, this work emphasizes the need for in situ measurements as all the factors we studied -- presence of active/passive skin, safety stop settings, robot collision reaction, impact direction, and, of course, velocity -- have effects on the force evolution after impact.
Siamese Neural Encoders for Long-Term Indoor Localization with Mobile Devices
Nov 28, 2021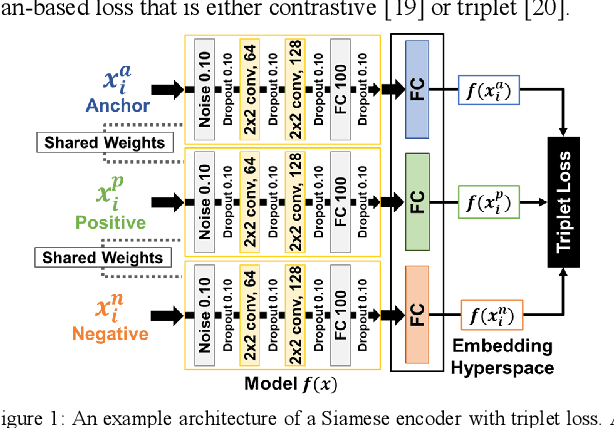
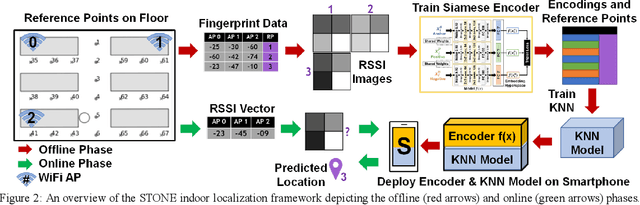
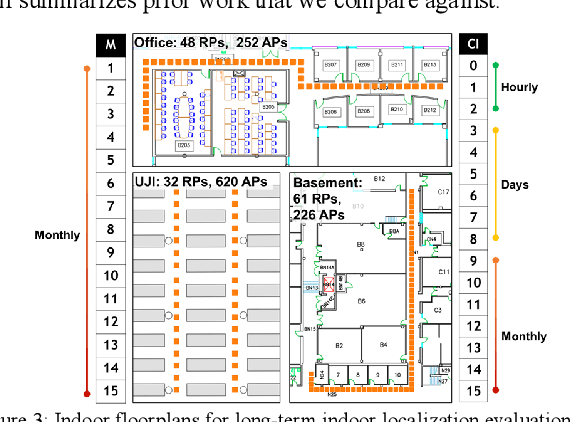
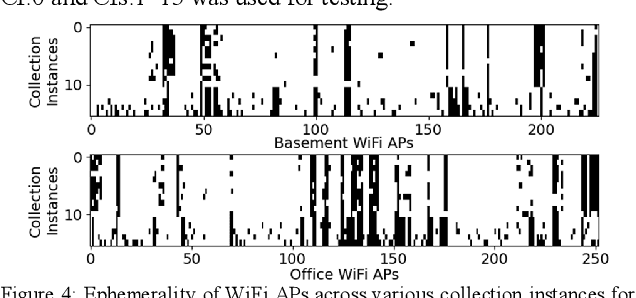
Fingerprinting-based indoor localization is an emerging application domain for enhanced positioning and tracking of people and assets within indoor locales. The superior pairing of ubiquitously available WiFi signals with computationally capable smartphones is set to revolutionize the area of indoor localization. However, the observed signal characteristics from independently maintained WiFi access points vary greatly over time. Moreover, some of the WiFi access points visible at the initial deployment phase may be replaced or removed over time. These factors are often ignored in indoor localization frameworks and cause gradual and catastrophic degradation of localization accuracy post-deployment (over weeks and months). To overcome these challenges, we propose a Siamese neural encoder-based framework that offers up to 40% reduction in degradation of localization accuracy over time compared to the state-of-the-art in the area, without requiring any retraining.
Don't Lie to Me! Robust and Efficient Explainability with Verified Perturbation Analysis
Feb 15, 2022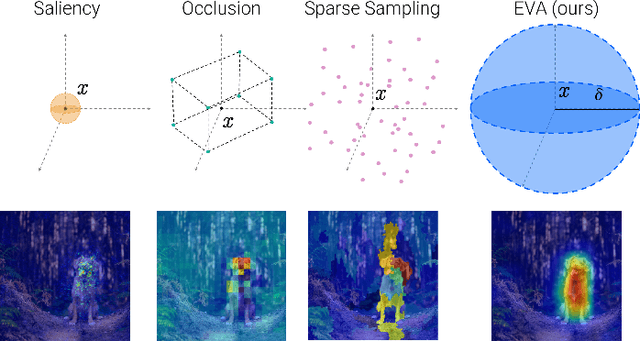
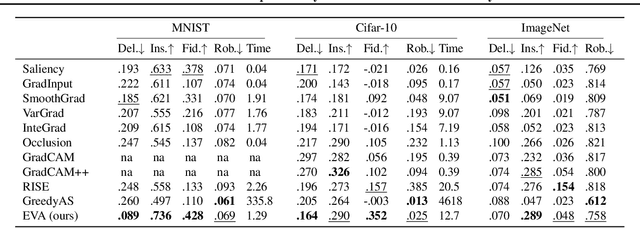
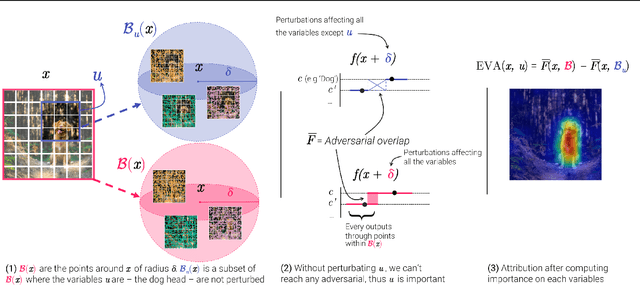
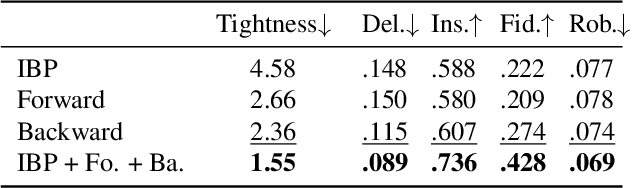
A variety of methods have been proposed to try to explain how deep neural networks make their decisions. Key to those approaches is the need to sample the pixel space efficiently in order to derive importance maps. However, it has been shown that the sampling methods used to date introduce biases and other artifacts, leading to inaccurate estimates of the importance of individual pixels and severely limit the reliability of current explainability methods. Unfortunately, the alternative -- to exhaustively sample the image space is computationally prohibitive. In this paper, we introduce EVA (Explaining using Verified perturbation Analysis) -- the first explainability method guarantee to have an exhaustive exploration of a perturbation space. Specifically, we leverage the beneficial properties of verified perturbation analysis -- time efficiency, tractability and guaranteed complete coverage of a manifold -- to efficiently characterize the input variables that are most likely to drive the model decision. We evaluate the approach systematically and demonstrate state-of-the-art results on multiple benchmarks.
Towards Real-time Drowsiness Detection for Elderly Care
Oct 21, 2020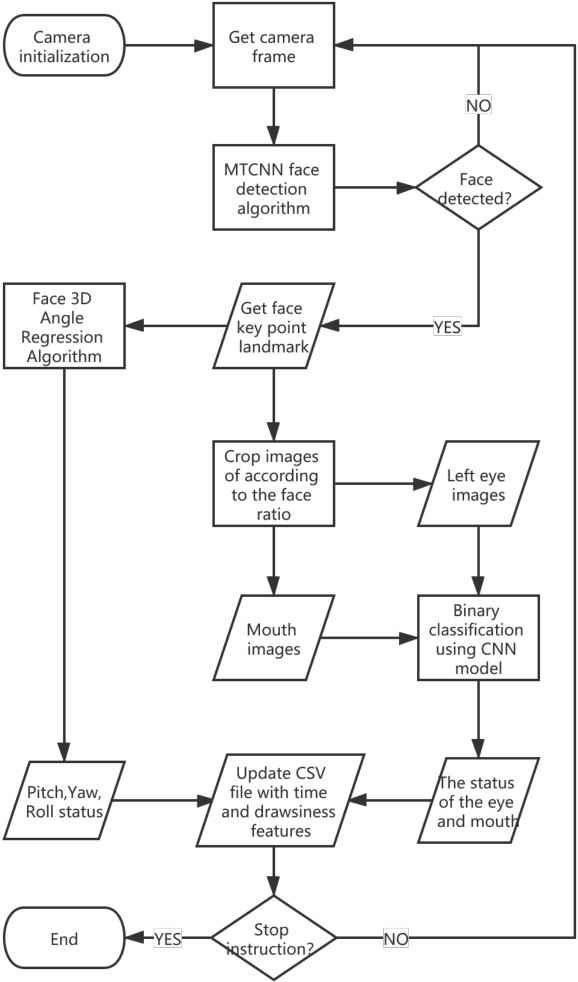
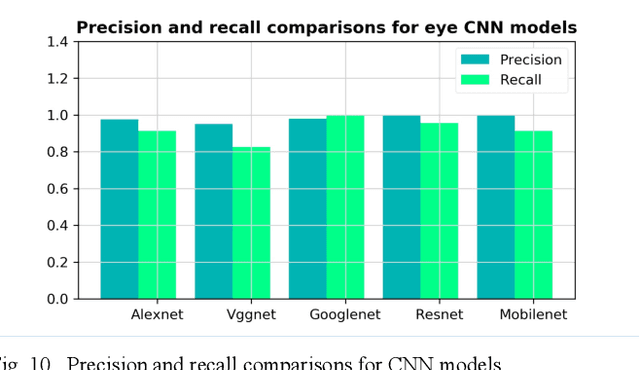

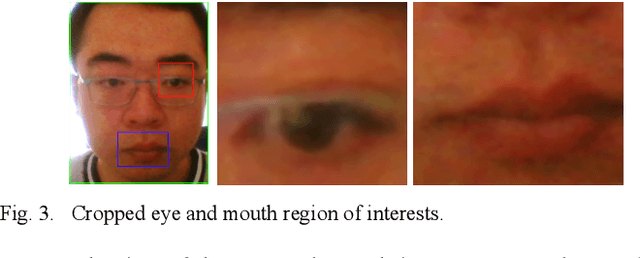
The primary focus of this paper is to produce a proof of concept for extracting drowsiness information from videos to help elderly living on their own. To quantify yawning, eyelid and head movement over time, we extracted 3000 images from captured videos for training and testing of deep learning models integrated with OpenCV library. The achieved classification accuracy for eyelid and mouth open/close status were between 94.3%-97.2%. Visual inspection of head movement from videos with generated 3D coordinate overlays, indicated clear spatiotemporal patterns in collected data (yaw, roll and pitch). Extraction methodology of the drowsiness information as timeseries is applicable to other contexts including support for prior work in privacy-preserving augmented coaching, sport rehabilitation, and integration with big data platform in healthcare.
Exoplanet Characterization using Conditional Invertible Neural Networks
Jan 31, 2022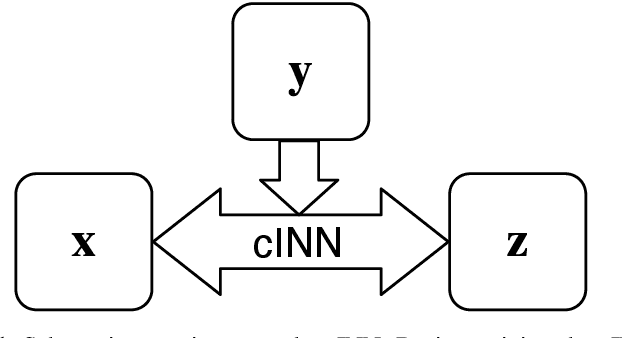

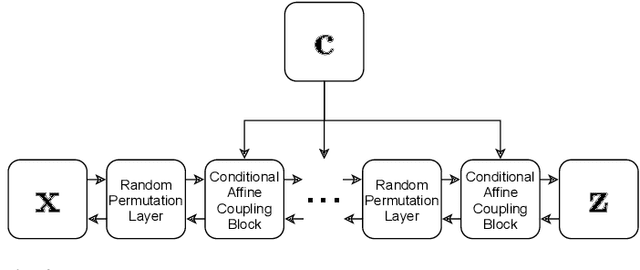
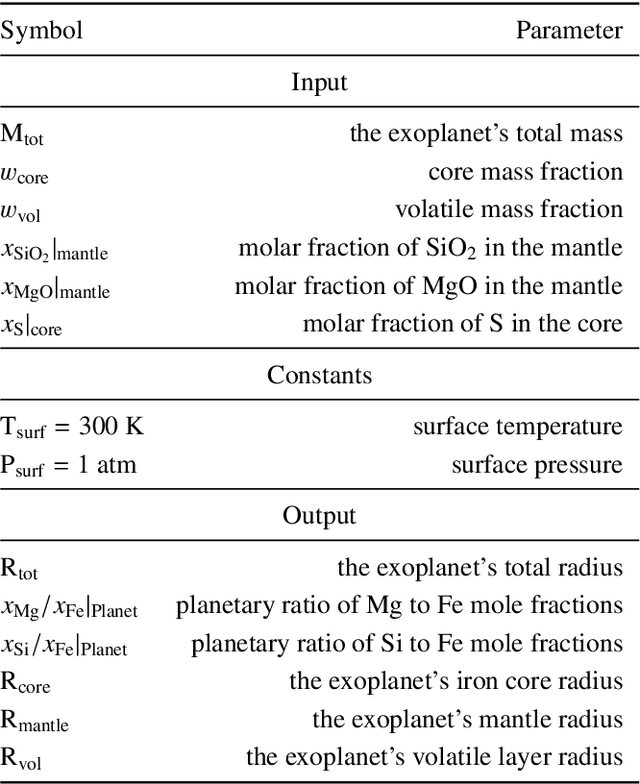
The characterization of an exoplanet's interior is an inverse problem, which requires statistical methods such as Bayesian inference in order to be solved. Current methods employ Markov Chain Monte Carlo (MCMC) sampling to infer the posterior probability of planetary structure parameters for a given exoplanet. These methods are time consuming since they require the calculation of a large number of planetary structure models. To speed up the inference process when characterizing an exoplanet, we propose to use conditional invertible neural networks (cINNs) to calculate the posterior probability of the internal structure parameters. cINNs are a special type of neural network which excel in solving inverse problems. We constructed a cINN using FrEIA, which was then trained on a database of $5.6\cdot 10^6$ internal structure models to recover the inverse mapping between internal structure parameters and observable features (i.e., planetary mass, planetary radius and composition of the host star). The cINN method was compared to a Metropolis-Hastings MCMC. For that we repeated the characterization of the exoplanet K2-111 b, using both the MCMC method and the trained cINN. We show that the inferred posterior probability of the internal structure parameters from both methods are very similar, with the biggest differences seen in the exoplanet's water content. Thus cINNs are a possible alternative to the standard time-consuming sampling methods. Indeed, using cINNs allows for orders of magnitude faster inference of an exoplanet's composition than what is possible using an MCMC method, however, it still requires the computation of a large database of internal structures to train the cINN. Since this database is only computed once, we found that using a cINN is more efficient than an MCMC, when more than 10 exoplanets are characterized using the same cINN.
BlendTorch: A Real-Time, Adaptive Domain Randomization Library
Oct 06, 2020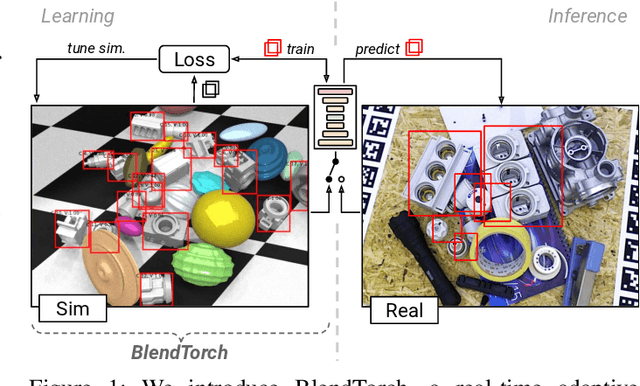

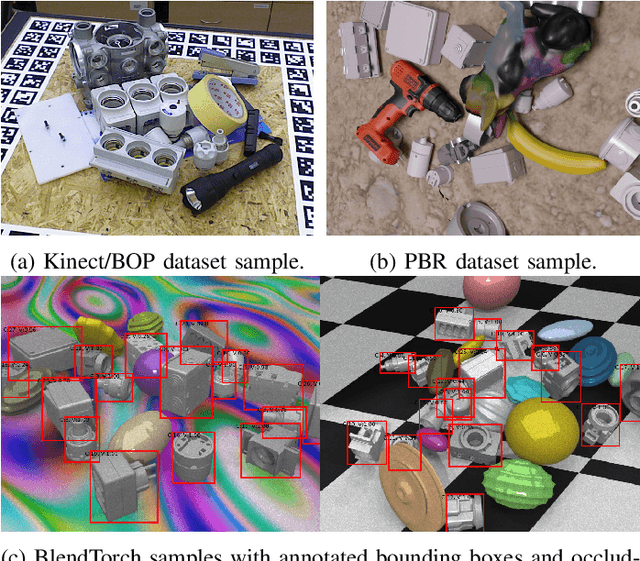
Solving complex computer vision tasks by deep learning techniques relies on large amounts of (supervised) image data, typically unavailable in industrial environments. The lack of training data starts to impede the successful transfer of state-of-the-art methods in computer vision to industrial applications. We introduce BlendTorch, an adaptive Domain Randomization (DR) library, to help creating infinite streams of synthetic training data. BlendTorch generates data by massively randomizing low-fidelity simulations and takes care of distributing artificial training data for model learning in real-time. We show that models trained with BlendTorch repeatedly perform better in an industrial object detection task than those trained on real or photo-realistic datasets.
ECG beats classification via online sparse dictionary and time pyramid matching
Aug 15, 2020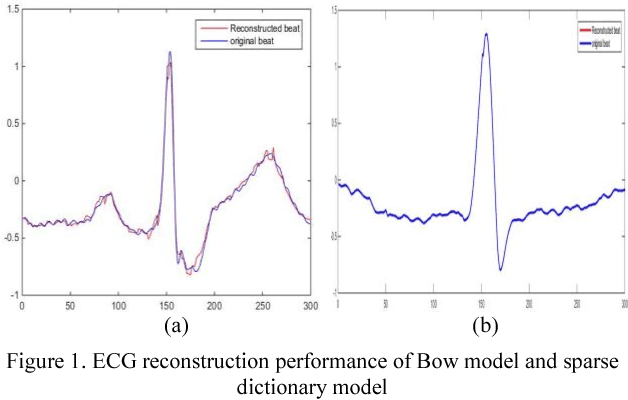
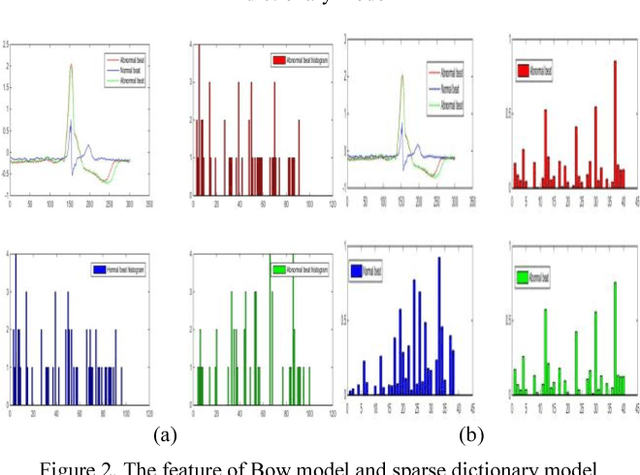
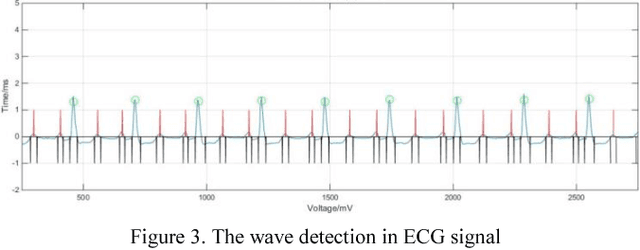
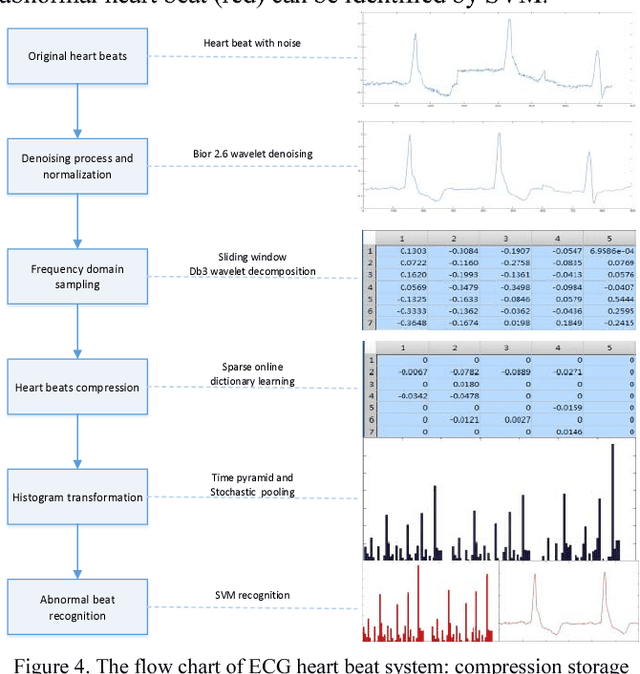
Recently, the Bag-Of-Word (BOW) algorithm provides efficient features and promotes the accuracy of the ECG classification system. However, BOW algorithm has two shortcomings: (1). it has large quantization errors and poor reconstruction performance; (2). it loses heart beat's time information, and may provide confusing features for different kinds of heart beats. Furthermore, ECG classification system can be used for long time monitoring and analysis of cardiovascular patients, while a huge amount of data will be produced, so we urgently need an efficient compression algorithm. In view of the above problems, we use the wavelet feature to construct the sparse dictionary, which lower the quantization error to a minimum. In order to reduce the complexity of our algorithm and adapt to large-scale heart beats operation, we combine the Online Dictionary Learning with Feature-sign algorithm to update the dictionary and coefficients. Coefficients matrix is used to represent ECG beats, which greatly reduces the memory consumption, and solve the problem of quantitative error simultaneously. Finally, we construct the pyramid to match coefficients of each ECG beat. Thus, we obtain the features that contain the beat time information by time stochastic pooling. It is efficient to solve the problem of losing time information. The experimental results show that: on the one hand, the proposed algorithm has advantages of high reconstruction performance for BOW, this storage method is high fidelity and low memory consumption; on the other hand, our algorithm yields highest accuracy in ECG beats classification; so this method is more suitable for large-scale heart beats data storage and classification.
* 7 pages,5 figure
A Multidisciplinary Approach to Optimal Communication and Flight Operation of High Altitude Long Endurance Platform
Mar 01, 2022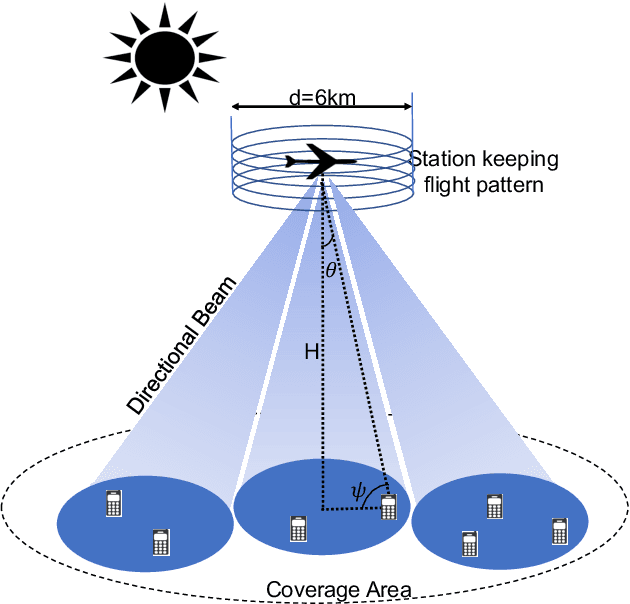
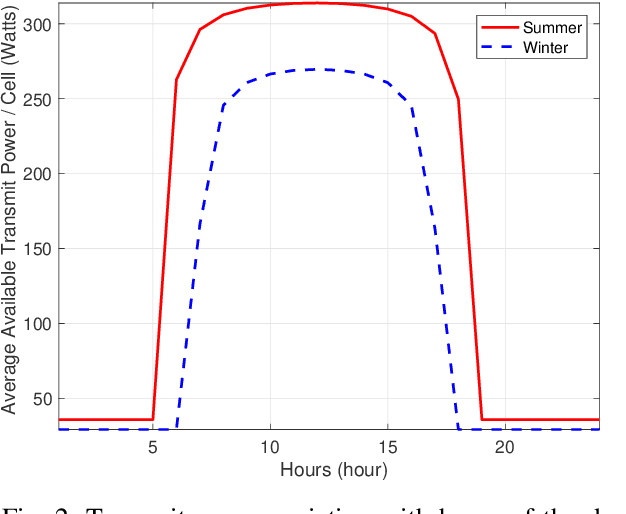
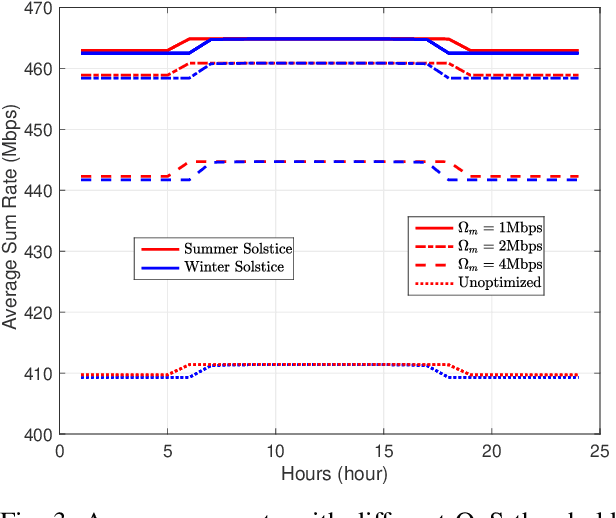
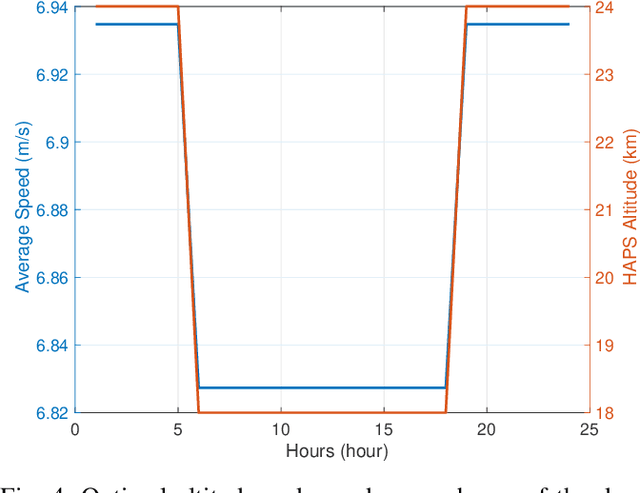
Aerial communication platforms especially stratospheric high altitude pseudo-satellite (HAPS) has the potential to provide/catalyze advanced mobile wireless communication services with its ubiquitous connectivity and ultra-wide coverage radius. Recently, HAPS has gained immense popularity - achieved primarily through self-sufficient energy systems - to render long endurance characteristics. The photo voltaic cells mounted on the aircraft harvest solar energy during the day, which is partially used for communication and station keeping, whereas, the excess is stored in the rechargeable batteries for the night time operation. We carried out an adroit power budgeting to ascertain if the available solar power can simultaneously and efficiently self-sustain the requisite propulsion and communication power expense. We propose an energy optimum trajectory for station-keeping flight and non-orthogonal multiple access (NOMA) for users in multicells served by the directional beams from HAPS communication system. We design optimal power allocation for downlink (DL) NOMA users along with the ideal position and speed of flight with the aim to maximize sum data rate during the day and minimize power expenditure during the night while ensuring quality of service. Our findings reveal the significance of joint design of communication and aerodynamics parameters for optimum energy utilization and resource allocation.
Generative Planning for Temporally Coordinated Exploration in Reinforcement Learning
Jan 24, 2022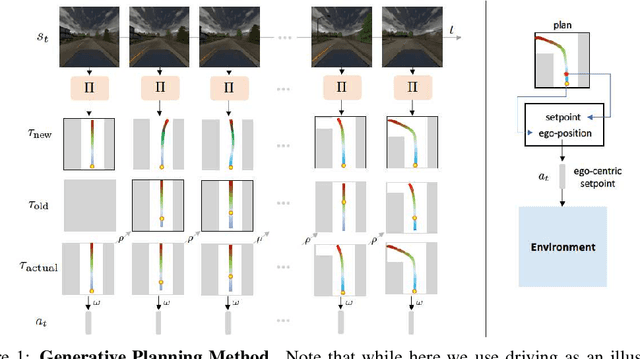

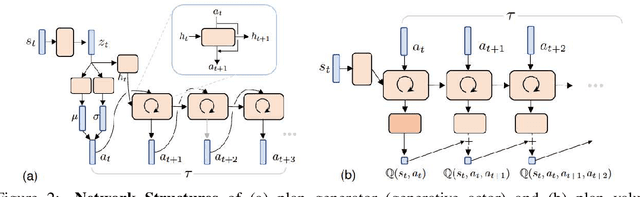
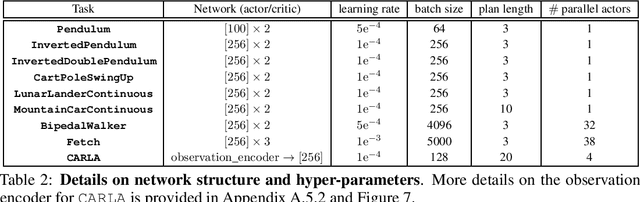
Standard model-free reinforcement learning algorithms optimize a policy that generates the action to be taken in the current time step in order to maximize expected future return. While flexible, it faces difficulties arising from the inefficient exploration due to its single step nature. In this work, we present Generative Planning method (GPM), which can generate actions not only for the current step, but also for a number of future steps (thus termed as generative planning). This brings several benefits to GPM. Firstly, since GPM is trained by maximizing value, the plans generated from it can be regarded as intentional action sequences for reaching high value regions. GPM can therefore leverage its generated multi-step plans for temporally coordinated exploration towards high value regions, which is potentially more effective than a sequence of actions generated by perturbing each action at single step level, whose consistent movement decays exponentially with the number of exploration steps. Secondly, starting from a crude initial plan generator, GPM can refine it to be adaptive to the task, which, in return, benefits future explorations. This is potentially more effective than commonly used action-repeat strategy, which is non-adaptive in its form of plans. Additionally, since the multi-step plan can be interpreted as the intent of the agent from now to a span of time period into the future, it offers a more informative and intuitive signal for interpretation. Experiments are conducted on several benchmark environments and the results demonstrated its effectiveness compared with several baseline methods.