 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Survey of Cross-Modality Brain Image Synthesis
Feb 16, 2022
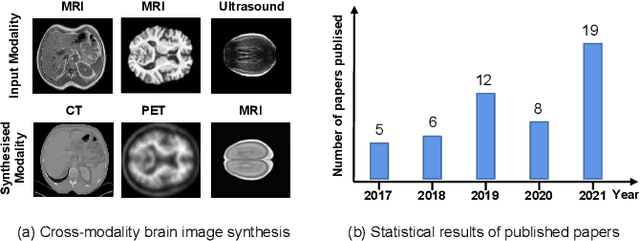
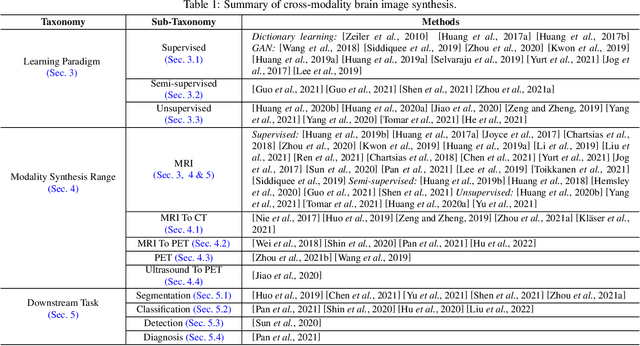
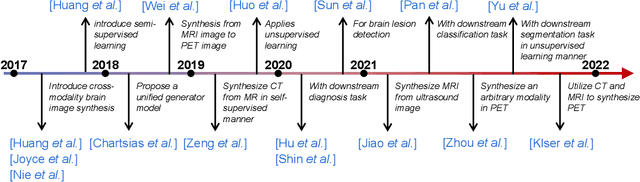
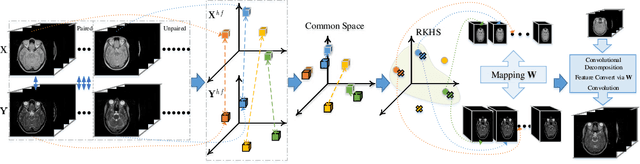
The existence of completely aligned and paired multi-modal neuroimaging data has proved its effectiveness in diagnosis of brain diseases. However, collecting the full set of well-aligned and paired data is impractical or even luxurious, since the practical difficulties may include high cost, long time acquisition, image corruption, and privacy issues. A realistic solution is to explore either an unsupervised learning or a semi-supervised learning to synthesize the absent neuroimaging data. In this paper, we tend to approach multi-modality brain image synthesis task from different perspectives, which include the level of supervision, the range of modality synthesis, and the synthesis-based downstream tasks. Particularly, we provide in-depth analysis on how cross-modality brain image synthesis can improve the performance of different downstream tasks. Finally, we evaluate the challenges and provide several open directions for this community. All resources are available at https://github.com/M-3LAB/awesome-multimodal-brain-image-systhesis
Elastica Models for Color Image Regularization
Mar 18, 2022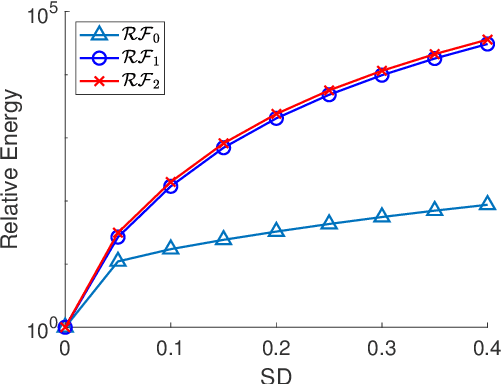
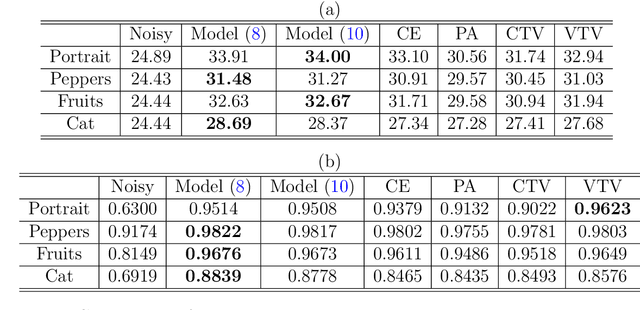

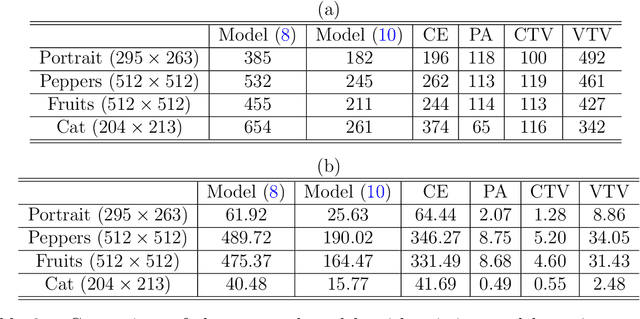
One classical approach to regularize color is to tream them as two dimensional surfaces embedded in a five dimensional spatial-chromatic space. In this case, a natural regularization term arises as the image surface area. Choosing the chromatic coordinates as dominating over the spatial ones, the image spatial coordinates could be thought of as a paramterization of the image surface manifold in a three dimensional color space. Minimizing the area of the image manifold leads to the Beltrami flow or mean curvature flow of the image surface in the 3D color space, while minimizing the elastica of the image surface yields an additional interesting regularization. Recently, the authors proposed a color elastica model, which minimizes both the surface area and elastica of the image manifold. In this paper, we propose to modify the color elastica and introduce two new models for color image regularization. The revised measures are motivated by the relations between the color elastica model, Euler's elastica model and the total variation model for gray level images. Compared to our previous color elastica model, the new models are direct extensions of Euler's elastica model to color images. The proposed models are nonlinear and challenging to minimize. To overcome this difficulty, two operator-splitting methods are suggested. Specifically, nonlinearities are decoupled by introducing new vector- and matrix-valued variables. Then, the minimization problems are converted to solving initial value problems which are time-discretized by operator splitting. Each subproblem, after splitting either, has a closed-form solution or can be solved efficiently. The effectiveness and advantages of the proposed models are demonstrated by comprehensive experiments. The benefits of incorporating the elastica of the image surface as regularization terms compared to common alternatives are empirically validated.
Monitoring and Anomaly Detection Actor-Critic Based Controlled Sensing
Jan 03, 2022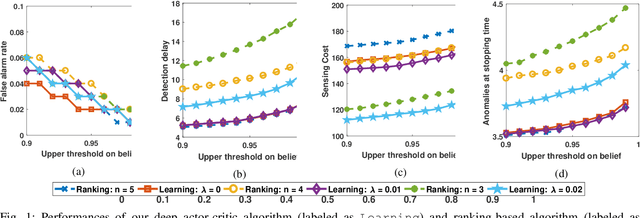
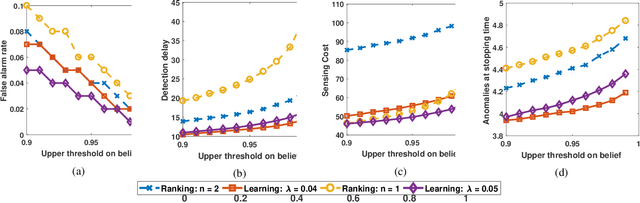
We address the problem of monitoring a set of binary stochastic processes and generating an alert when the number of anomalies among them exceeds a threshold. For this, the decision-maker selects and probes a subset of the processes to obtain noisy estimates of their states (normal or anomalous). Based on the received observations, the decisionmaker first determines whether to declare that the number of anomalies has exceeded the threshold or to continue taking observations. When the decision is to continue, it then decides whether to collect observations at the next time instant or defer it to a later time. If it chooses to collect observations, it further determines the subset of processes to be probed. To devise this three-step sequential decision-making process, we use a Bayesian formulation wherein we learn the posterior probability on the states of the processes. Using the posterior probability, we construct a Markov decision process and solve it using deep actor-critic reinforcement learning. Via numerical experiments, we demonstrate the superior performance of our algorithm compared to the traditional model-based algorithms.
ViT-HGR: Vision Transformer-based Hand Gesture Recognition from High Density Surface EMG Signals
Jan 25, 2022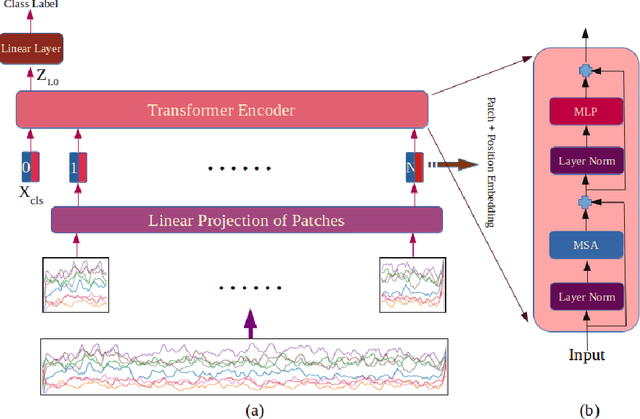
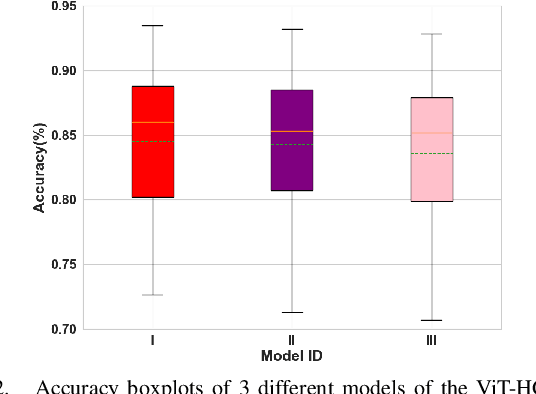
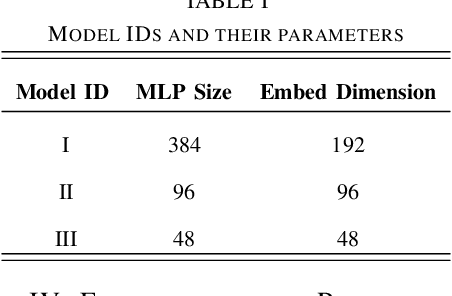
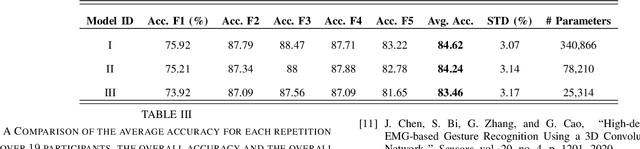
Recently, there has been a surge of significant interest on application of Deep Learning (DL) models to autonomously perform hand gesture recognition using surface Electromyogram (sEMG) signals. DL models are, however, mainly designed to be applied on sparse sEMG signals. Furthermore, due to their complex structure, typically, we are faced with memory constraints; require large training times and a large number of training samples, and; there is the need to resort to data augmentation and/or transfer learning. In this paper, for the first time (to the best of our knowledge), we investigate and design a Vision Transformer (ViT) based architecture to perform hand gesture recognition from High Density (HD-sEMG) signals. Intuitively speaking, we capitalize on the recent breakthrough role of the transformer architecture in tackling different complex problems together with its potential for employing more input parallelization via its attention mechanism. The proposed Vision Transformer-based Hand Gesture Recognition (ViT-HGR) framework can overcome the aforementioned training time problems and can accurately classify a large number of hand gestures from scratch without any need for data augmentation and/or transfer learning. The efficiency of the proposed ViT-HGR framework is evaluated using a recently-released HD-sEMG dataset consisting of 65 isometric hand gestures. Our experiments with 64-sample (31.25 ms) window size yield average test accuracy of 84.62 +/- 3.07%, where only 78, 210 number of parameters is utilized. The compact structure of the proposed ViT-based ViT-HGR framework (i.e., having significantly reduced number of trainable parameters) shows great potentials for its practical application for prosthetic control.
IDP-Z3: a reasoning engine for FO(.)
Feb 01, 2022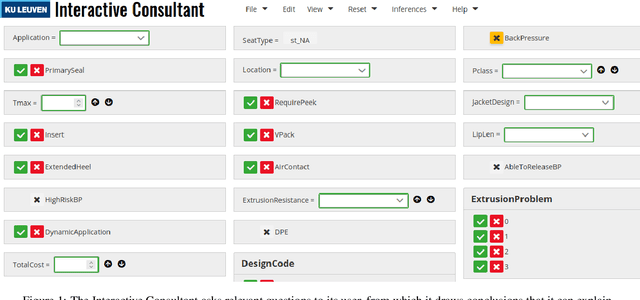



FO(.) (aka FO-dot) is a language that extends classical first-order logic with constructs to allow complex knowledge to be represented in a natural and elaboration-tolerant way. IDP-Z3 is a new reasoning engine for the FO(.) language: it can perform a variety of generic computational tasks using knowledge represented in FO(.). It supersedes IDP3, its predecessor, with new capabilities such as support for linear arithmetic over reals and quantification over concepts. We present four knowledge-intensive industrial use cases, and show that IDP-Z3 delivers real value to its users at low development costs: it supports interactive applications in a variety of problem domains, with a response time typically below 3 seconds.
Deep Layer-wise Networks Have Closed-Form Weights
Feb 07, 2022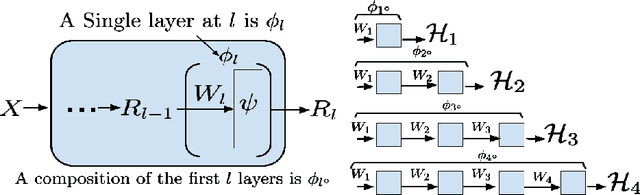
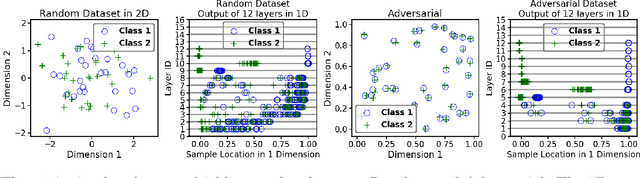
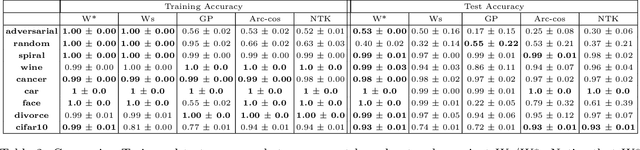
There is currently a debate within the neuroscience community over the likelihood of the brain performing backpropagation (BP). To better mimic the brain, training a network \textit{one layer at a time} with only a "single forward pass" has been proposed as an alternative to bypass BP; we refer to these networks as "layer-wise" networks. We continue the work on layer-wise networks by answering two outstanding questions. First, $\textit{do they have a closed-form solution?}$ Second, $\textit{how do we know when to stop adding more layers?}$ This work proves that the Kernel Mean Embedding is the closed-form weight that achieves the network global optimum while driving these networks to converge towards a highly desirable kernel for classification; we call it the $\textit{Neural Indicator Kernel}$.
* Since this version is similar to an older version, I should have updated the older version instead of creating a new version. I will now retract this version, and update a previous version to this. See arXiv:2006.08539
Optimal Allocation of Real-Time-Bidding and Direct Campaigns
Jun 12, 2020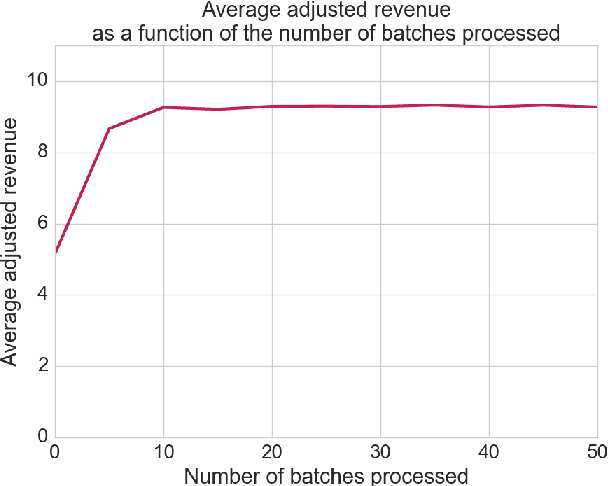
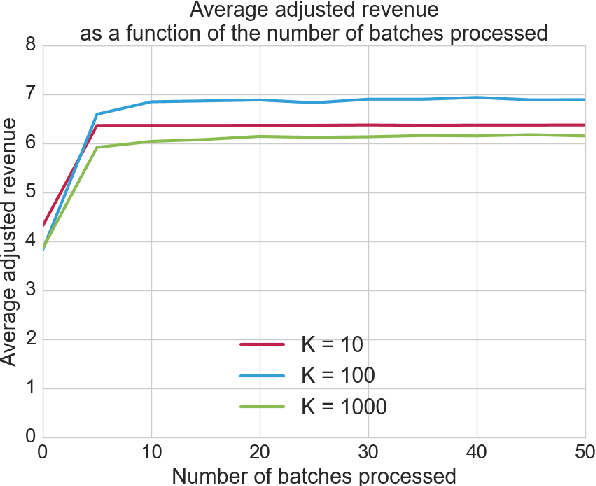
In this paper, we consider the problem of optimizing the revenue a web publisher gets through real-time bidding (i.e. from ads sold in real-time auctions) and direct (i.e. from ads sold through contracts agreed in advance). We consider a setting where the publisher is able to bid in the real-time bidding auction for each impression. If it wins the auction, it chooses a direct campaign to deliver and displays the corresponding ad. This paper presents an algorithm to build an optimal strategy for the publisher to deliver its direct campaigns while maximizing its real-time bidding revenue. The optimal strategy gives a formula to determine the publisher bid as well as a way to choose the direct campaign being delivered if the publisher bidder wins the auction, depending on the impression characteristics. The optimal strategy can be estimated on past auctions data. The algorithm scales with the number of campaigns and the size of the dataset. This is a very important feature, as in practice a publisher may have thousands of active direct campaigns at the same time and would like to estimate an optimal strategy on billions of auctions. The algorithm is a key component of a system which is being developed, and which will be deployed on thousands of web publishers worldwide, helping them to serve efficiently billions of ads a day to hundreds of millions of visitors.
PREVIS -- A Combined Machine Learning and Visual Interpolation Approach for Interactive Reverse Engineering in Assembly Quality Control
Jan 25, 2022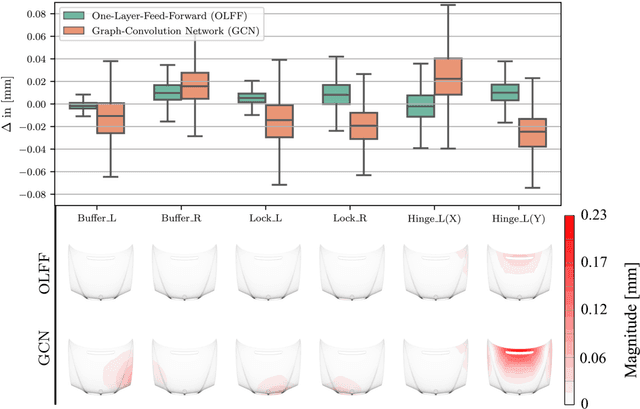
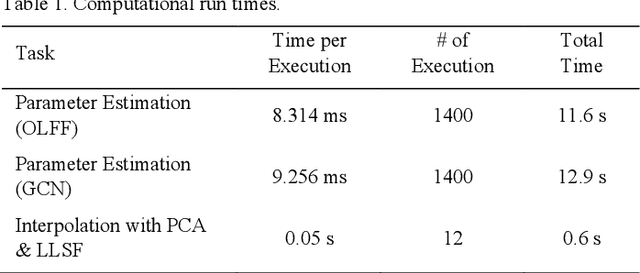
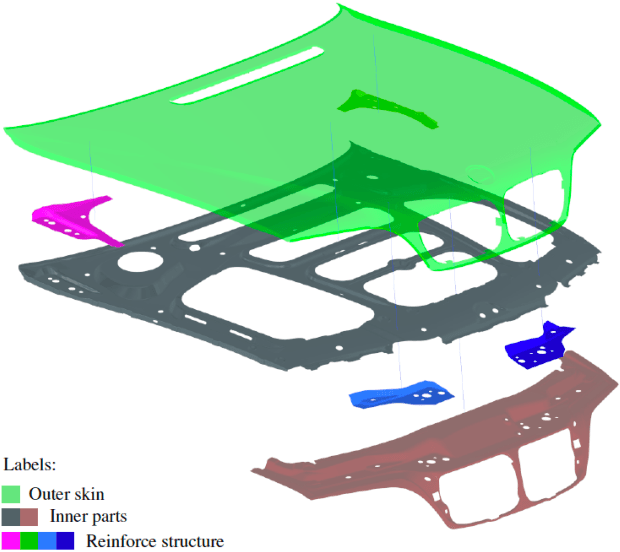
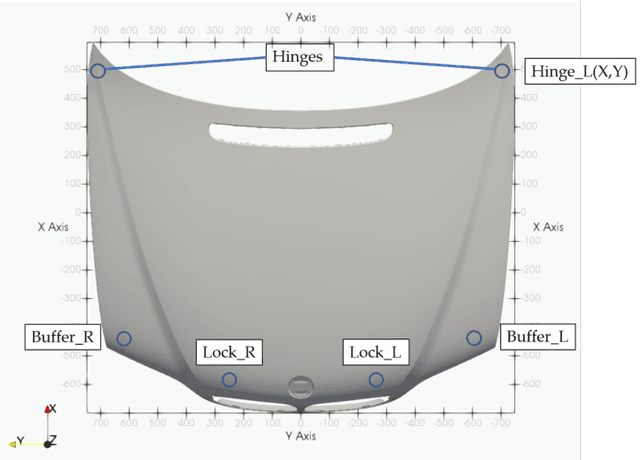
We present PREVIS, a visual analytics tool, enhancing machine learning performance analysis in engineering applications. The presented toolchain allows for a direct comparison of regression models. In addition, we provide a methodology to visualize the impact of regression errors on the underlying field of interest in the original domain, the part geometry, via exploiting standard interpolation methods. Further, we allow a real-time preview of user-driven parameter changes in the displacement field via visual interpolation. This allows for fast and accountable online change management. We demonstrate the effectiveness with an ex-ante optimization of an automotive engine hood.
Mining Robust Default Configurations for Resource-constrained AutoML
Feb 20, 2022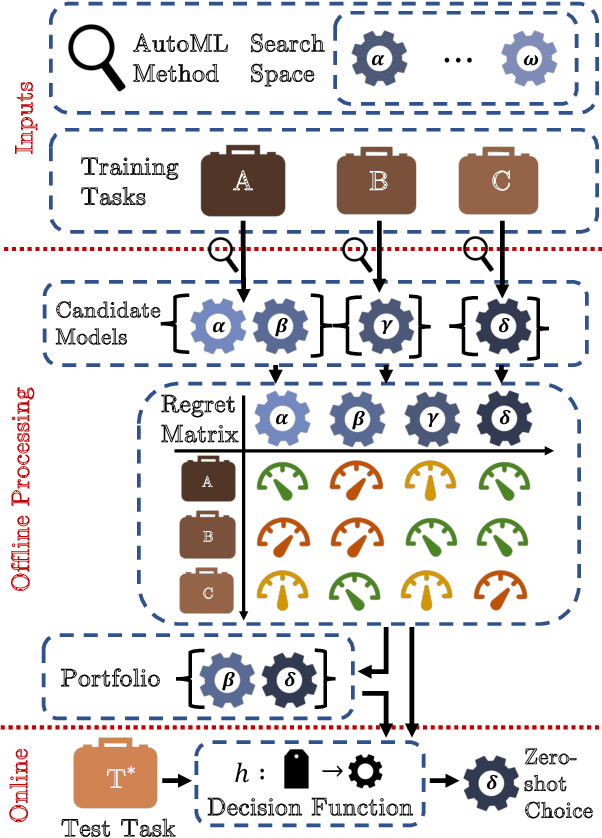
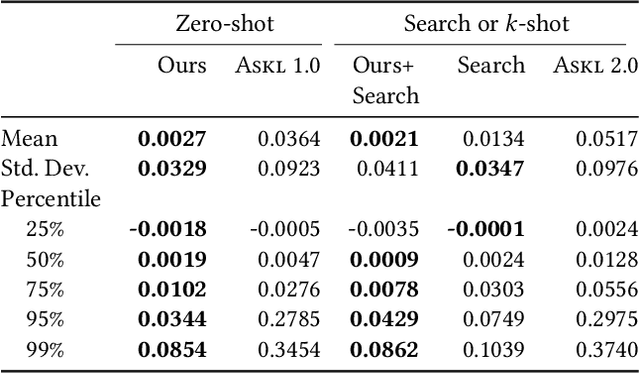
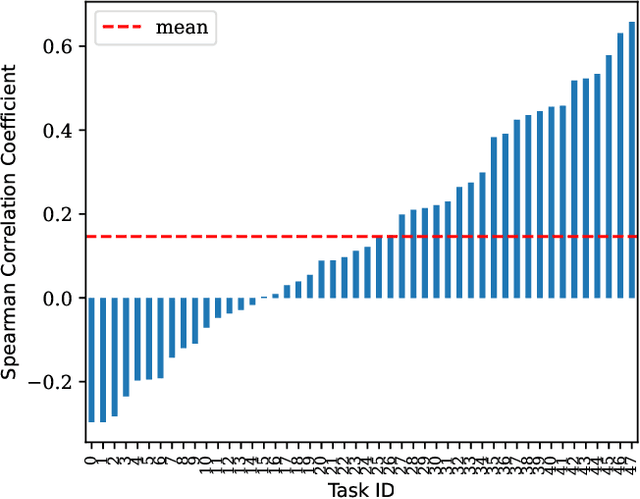
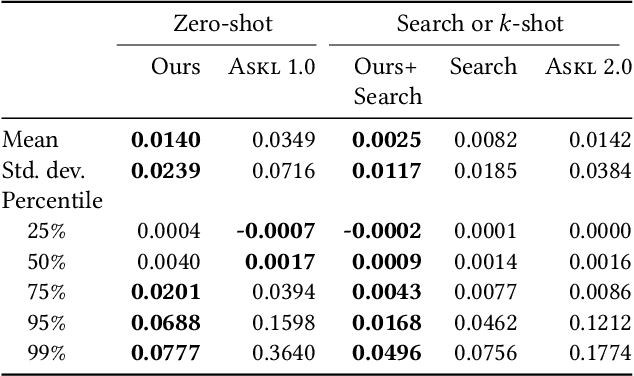
Automatic machine learning (AutoML) is a key enabler of the mass deployment of the next generation of machine learning systems. A key desideratum for future ML systems is the automatic selection of models and hyperparameters. We present a novel method of selecting performant configurations for a given task by performing offline autoML and mining over a diverse set of tasks. By mining the training tasks, we can select a compact portfolio of configurations that perform well over a wide variety of tasks, as well as learn a strategy to select portfolio configurations for yet-unseen tasks. The algorithm runs in a zero-shot manner, that is without training any models online except the chosen one. In a compute- or time-constrained setting, this virtually instant selection is highly performant. Further, we show that our approach is effective for warm-starting existing autoML platforms. In both settings, we demonstrate an improvement on the state-of-the-art by testing over 62 classification and regression datasets. We also demonstrate the utility of recommending data-dependent default configurations that outperform widely used hand-crafted defaults.
Siamese Neural Encoders for Long-Term Indoor Localization with Mobile Devices
Nov 28, 2021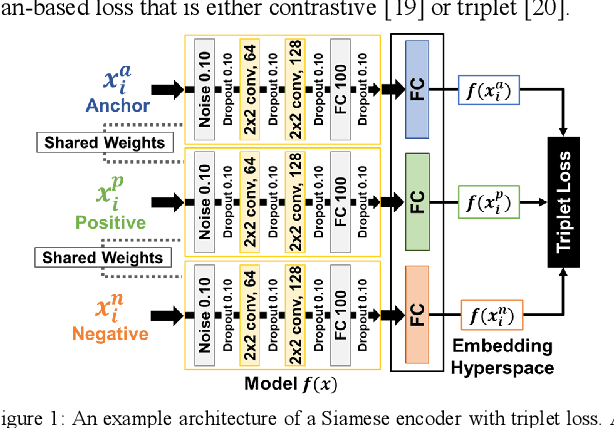
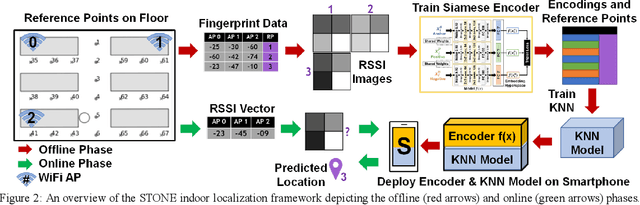
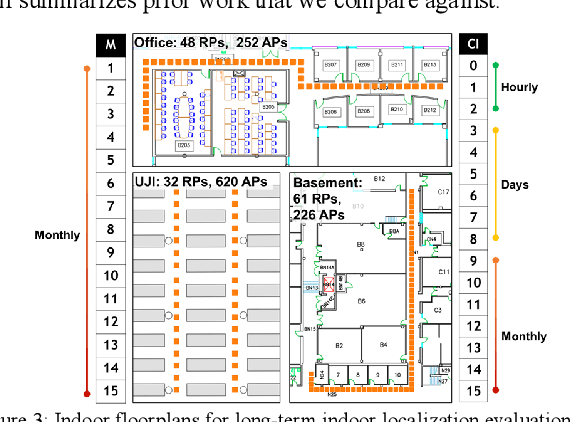
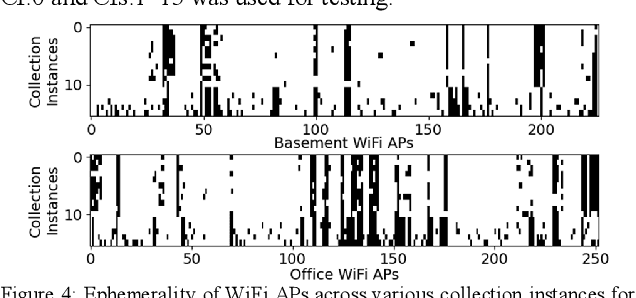
Fingerprinting-based indoor localization is an emerging application domain for enhanced positioning and tracking of people and assets within indoor locales. The superior pairing of ubiquitously available WiFi signals with computationally capable smartphones is set to revolutionize the area of indoor localization. However, the observed signal characteristics from independently maintained WiFi access points vary greatly over time. Moreover, some of the WiFi access points visible at the initial deployment phase may be replaced or removed over time. These factors are often ignored in indoor localization frameworks and cause gradual and catastrophic degradation of localization accuracy post-deployment (over weeks and months). To overcome these challenges, we propose a Siamese neural encoder-based framework that offers up to 40% reduction in degradation of localization accuracy over time compared to the state-of-the-art in the area, without requiring any retraining.