 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Augmenting Neural Networks with Priors on Function Values
Feb 21, 2022




The need for function estimation in label-limited settings is common in the natural sciences. At the same time, prior knowledge of function values is often available in these domains. For example, data-free biophysics-based models can be informative on protein properties, while quantum-based computations can be informative on small molecule properties. How can we coherently leverage such prior knowledge to help improve a neural network model that is quite accurate in some regions of input space -- typically near the training data -- but wildly wrong in other regions? Bayesian neural networks (BNN) enable the user to specify prior information only on the neural network weights, not directly on the function values. Moreover, there is in general no clear mapping between these. Herein, we tackle this problem by developing an approach to augment BNNs with prior information on the function values themselves. Our probabilistic approach yields predictions that rely more heavily on the prior information when the epistemic uncertainty is large, and more heavily on the neural network when the epistemic uncertainty is small.
Double Thompson Sampling in Finite stochastic Games
Feb 21, 2022We consider the trade-off problem between exploration and exploitation under finite discounted Markov Decision Process, where the state transition matrix of the underlying environment stays unknown. We propose a double Thompson sampling reinforcement learning algorithm(DTS) to solve this kind of problem. This algorithm achieves a total regret bound of $\tilde{\mathcal{O}}(D\sqrt{SAT})$\footnote{The symbol $\tilde{\mathcal{O}}$ means $\mathcal{O}$ with log factors ignored} in time horizon $T$ with $S$ states, $A$ actions and diameter $D$. DTS consists of two parts, the first part is the traditional part where we apply the posterior sampling method on transition matrix based on prior distribution. In the second part, we employ a count-based posterior update method to balance between the local optimal action and the long-term optimal action in order to find the global optimal game value. We established a regret bound of $\tilde{\mathcal{O}}(\sqrt{T}/S^{2})$. Which is by far the best regret bound for finite discounted Markov Decision Process to our knowledge. Numerical results proves the efficiency and superiority of our approach.
Uni4Eye: Unified 2D and 3D Self-supervised Pre-training via Masked Image Modeling Transformer for Ophthalmic Image Classification
Mar 09, 2022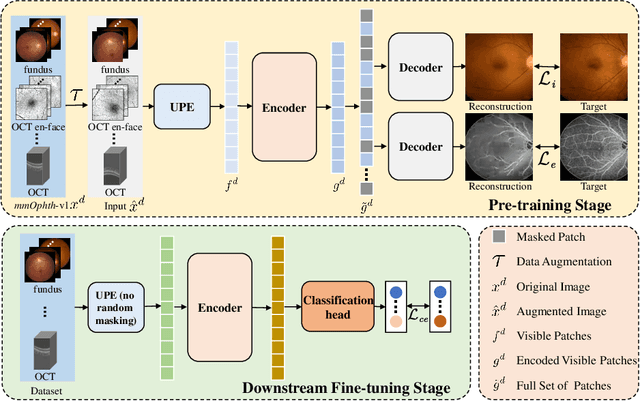
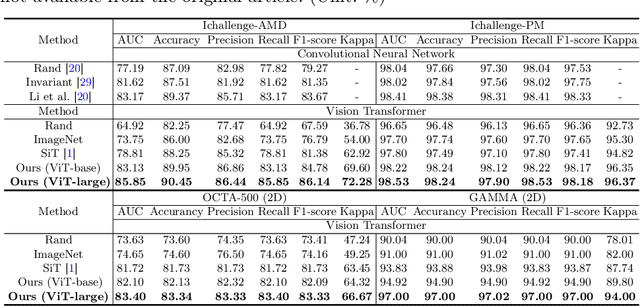
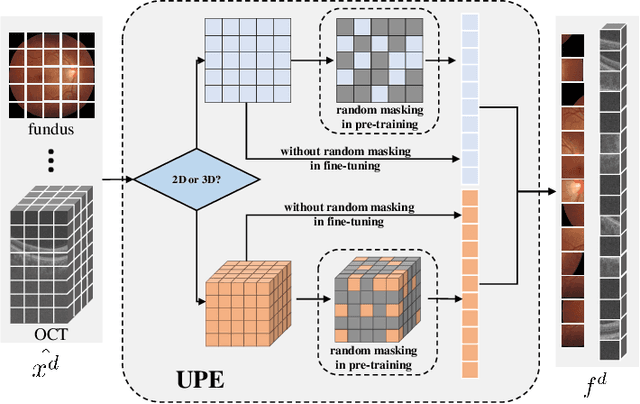
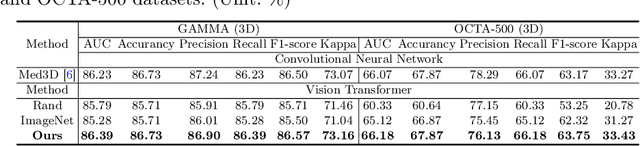
A large-scale labeled dataset is a key factor for the success of supervised deep learning in computer vision. However, a limited number of annotated data is very common, especially in ophthalmic image analysis, since manual annotation is time-consuming and labor-intensive. Self-supervised learning (SSL) methods bring huge opportunities for better utilizing unlabeled data, as they do not need massive annotations. With an attempt to use as many as possible unlabeled ophthalmic images, it is necessary to break the dimension barrier, simultaneously making use of both 2D and 3D images. In this paper, we propose a universal self-supervised Transformer framework, named Uni4Eye, to discover the inherent image property and capture domain-specific feature embedding in ophthalmic images. Uni4Eye can serve as a global feature extractor, which builds its basis on a Masked Image Modeling task with a Vision Transformer (ViT) architecture. We employ a Unified Patch Embedding module to replace the origin patch embedding module in ViT for jointly processing both 2D and 3D input images. Besides, we design a dual-branch multitask decoder module to simultaneously perform two reconstruction tasks on the input image and its gradient map, delivering discriminative representations for better convergence. We evaluate the performance of our pre-trained Uni4Eye encoder by fine-tuning it on six downstream ophthalmic image classification tasks. The superiority of Uni4Eye is successfully established through comparisons to other state-of-the-art SSL pre-training methods.
Practical No-box Adversarial Attacks with Training-free Hybrid Image Transformation
Mar 09, 2022


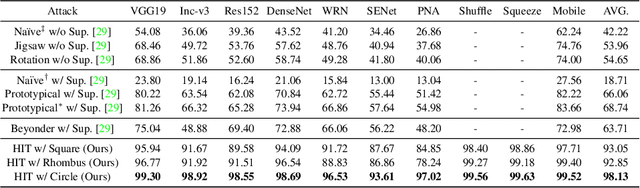
In recent years, the adversarial vulnerability of deep neural networks (DNNs) has raised increasing attention. Among all the threat models, no-box attacks are the most practical but extremely challenging since they neither rely on any knowledge of the target model or similar substitute model, nor access the dataset for training a new substitute model. Although a recent method has attempted such an attack in a loose sense, its performance is not good enough and computational overhead of training is expensive. In this paper, we move a step forward and show the existence of a \textbf{training-free} adversarial perturbation under the no-box threat model, which can be successfully used to attack different DNNs in real-time. Motivated by our observation that high-frequency component (HFC) domains in low-level features and plays a crucial role in classification, we attack an image mainly by manipulating its frequency components. Specifically, the perturbation is manipulated by suppression of the original HFC and adding of noisy HFC. We empirically and experimentally analyze the requirements of effective noisy HFC and show that it should be regionally homogeneous, repeating and dense. Extensive experiments on the ImageNet dataset demonstrate the effectiveness of our proposed no-box method. It attacks ten well-known models with a success rate of \textbf{98.13\%} on average, which outperforms state-of-the-art no-box attacks by \textbf{29.39\%}. Furthermore, our method is even competitive to mainstream transfer-based black-box attacks.
Disentangling modes with crossover instantaneous frequencies by synchrosqueezed chirplet transforms, from theory to application
Dec 03, 2021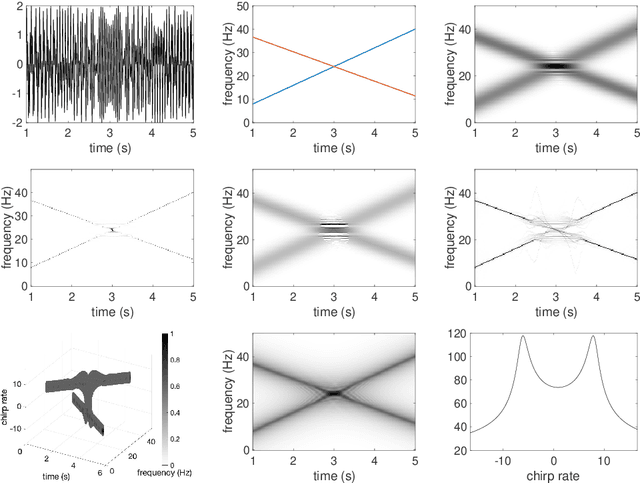
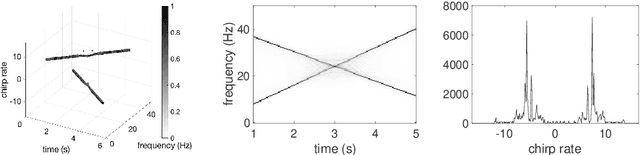
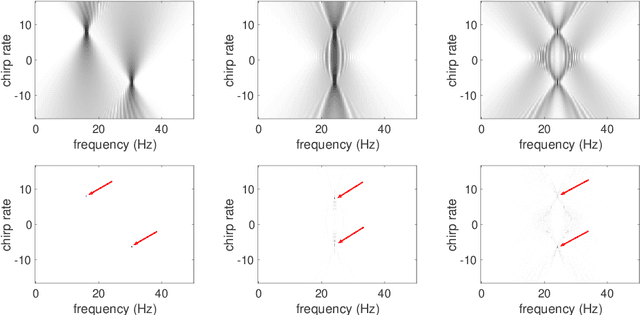
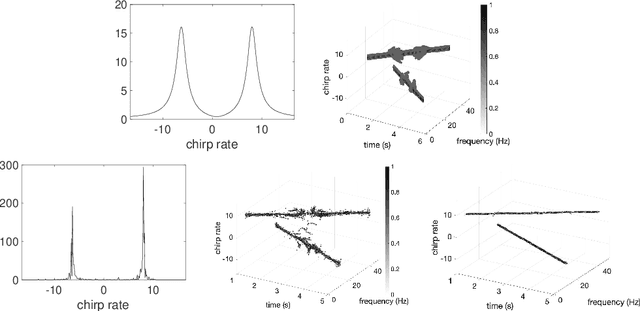
Analysis of signals with oscillatory modes with crossover instantaneous frequencies is a challenging problem in time series analysis. One way to handle this problem is lifting the 2-dimensional time-frequency representation to a 3-dimensional representation, called time-frequency-chirp rate (TFC) representation, by adding one extra chirp rate parameter so that crossover frequencies are disentangles in higher dimension. The chirplet transform is an algorithm for this lifting idea. However, in practice we found that it has a stronger "blurring" effect in the chirp rate axis, which limits its application in real world data. Moreover, to our knowledge, we have limited mathematical understanding of the chirplet transform in the literature. Motivated by real world data challenges, in this paper, we propose the synchrosqueezed chirplet transform (SCT) that gives a concentrated TFC representation that the contrast is enhanced so that one can distinguish different modes even with crossover instantaneous frequencies. We also analyze chirplet transform and provide theoretical guarantee of SCT.
Spike time displacement based error backpropagation in convolutional spiking neural networks
Aug 31, 2021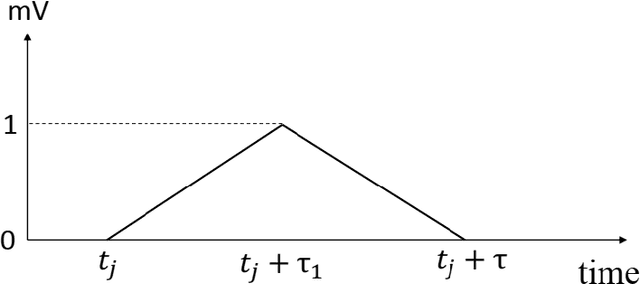
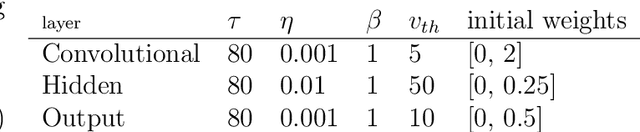
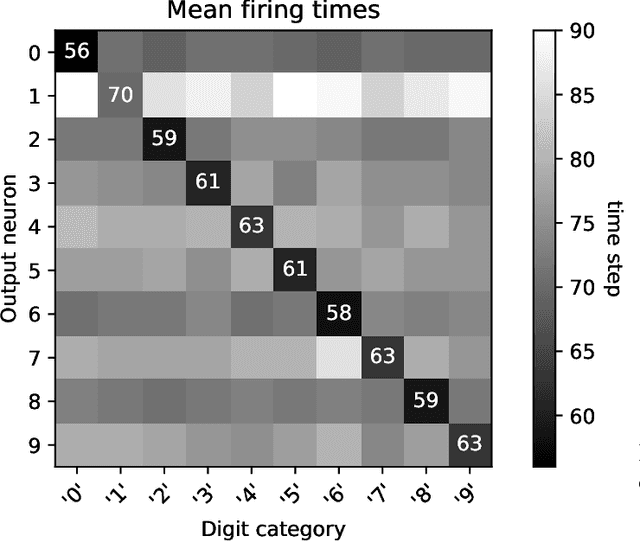

We recently proposed the STiDi-BP algorithm, which avoids backward recursive gradient computation, for training multi-layer spiking neural networks (SNNs) with single-spike-based temporal coding. The algorithm employs a linear approximation to compute the derivative of the spike latency with respect to the membrane potential and it uses spiking neurons with piecewise linear postsynaptic potential to reduce the computational cost and the complexity of neural processing. In this paper, we extend the STiDi-BP algorithm to employ it in deeper and convolutional architectures. The evaluation results on the image classification task based on two popular benchmarks, MNIST and Fashion-MNIST datasets with the accuracies of respectively 99.2% and 92.8%, confirm that this algorithm has been applicable in deep SNNs. Another issue we consider is the reduction of memory storage and computational cost. To do so, we consider a convolutional SNN (CSNN) with two sets of weights: real-valued weights that are updated in the backward pass and their signs, binary weights, that are employed in the feedforward process. We evaluate the binary CSNN on two datasets of MNIST and Fashion-MNIST and obtain acceptable performance with a negligible accuracy drop with respect to real-valued weights (about $0.6%$ and $0.8%$ drops, respectively).
Evaluating data augmentation for financial time series classification
Oct 28, 2020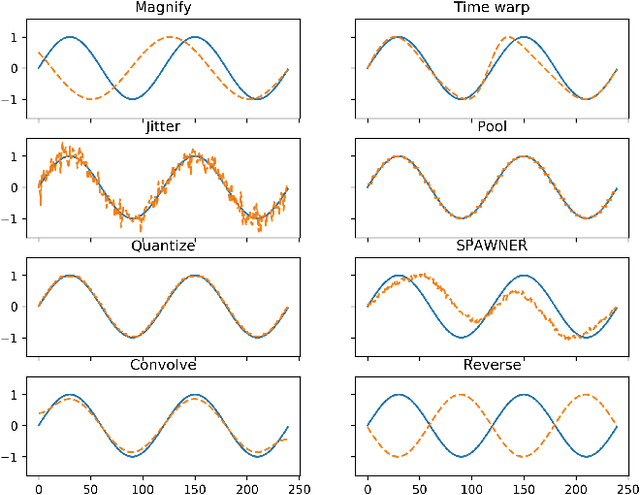
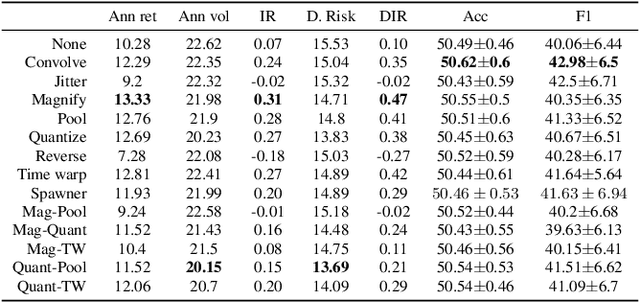
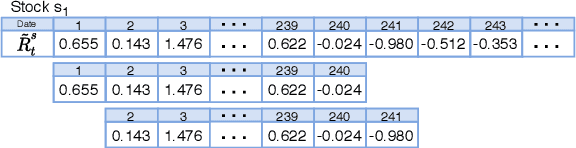
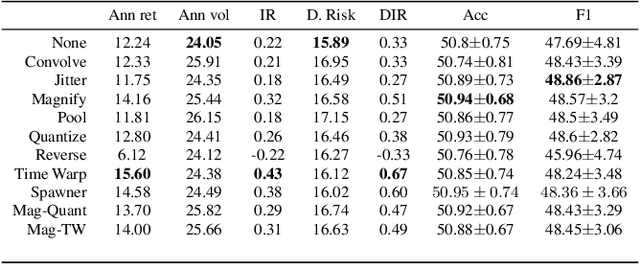
Data augmentation methods in combination with deep neural networks have been used extensively in computer vision on classification tasks, achieving great success; however, their use in time series classification is still at an early stage. This is even more so in the field of financial prediction, where data tends to be small, noisy and non-stationary. In this paper we evaluate several augmentation methods applied to stocks datasets using two state-of-the-art deep learning models. The results show that several augmentation methods significantly improve financial performance when used in combination with a trading strategy. For a relatively small dataset ($\approx30K$ samples), augmentation methods achieve up to $400\%$ improvement in risk adjusted return performance; for a larger stock dataset ($\approx300K$ samples), results show up to $40\%$ improvement.
Reproducing Personalised Session Search over the AOL Query Log
Jan 21, 2022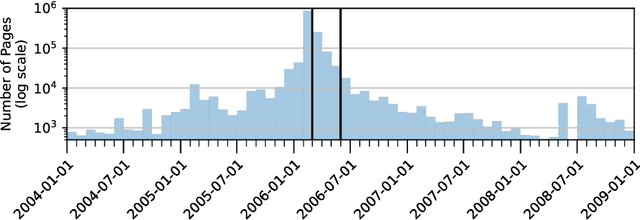
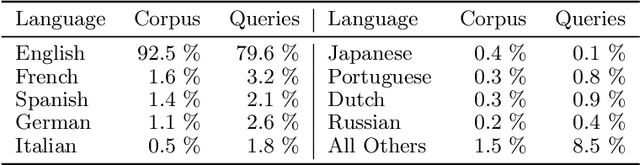
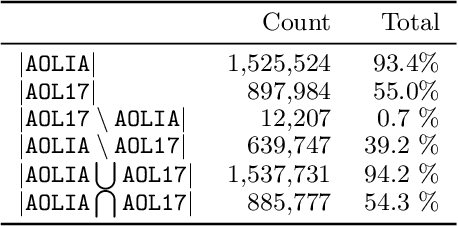
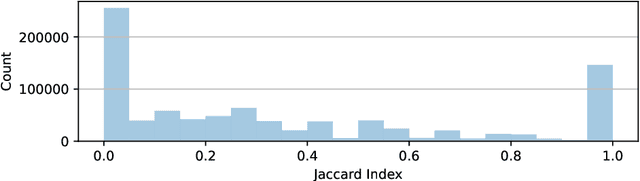
Despite its troubled past, the AOL Query Log continues to be an important resource to the research community -- particularly for tasks like search personalisation. When using the query log these ranking experiments, little attention is usually paid to the document corpus. Recent work typically uses a corpus containing versions of the documents collected long after the log was produced. Given that web documents are prone to change over time, we study the differences present between a version of the corpus containing documents as they appeared in 2017 (which has been used by several recent works) and a new version we construct that includes documents close to as they appeared at the time the query log was produced (2006). We demonstrate that this new version of the corpus has a far higher coverage of documents present in the original log (93%) than the 2017 version (55%). Among the overlapping documents, the content often differs substantially. Given these differences, we re-conduct session search experiments that originally used the 2017 corpus and find that when using our corpus for training or evaluation, system performance improves. We place the results in context by introducing recent adhoc ranking baselines. We also confirm the navigational nature of the queries in the AOL corpus by showing that including the URL substantially improves performance across a variety of models. Our version of the corpus can be easily reconstructed by other researchers and is included in the ir-datasets package.
QoS-SLA-Aware Artificial Intelligence Adaptive Genetic Algorithm for Multi-Request Offloading in Integrated Edge-Cloud Computing System for the Internet of Vehicles
Jan 21, 2022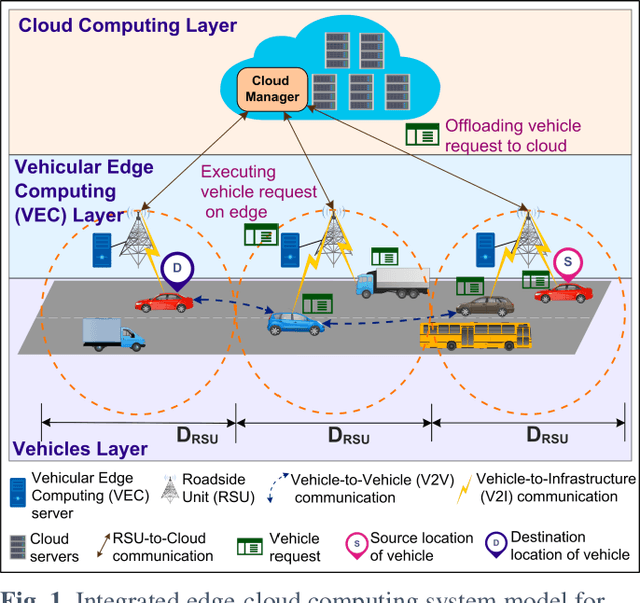
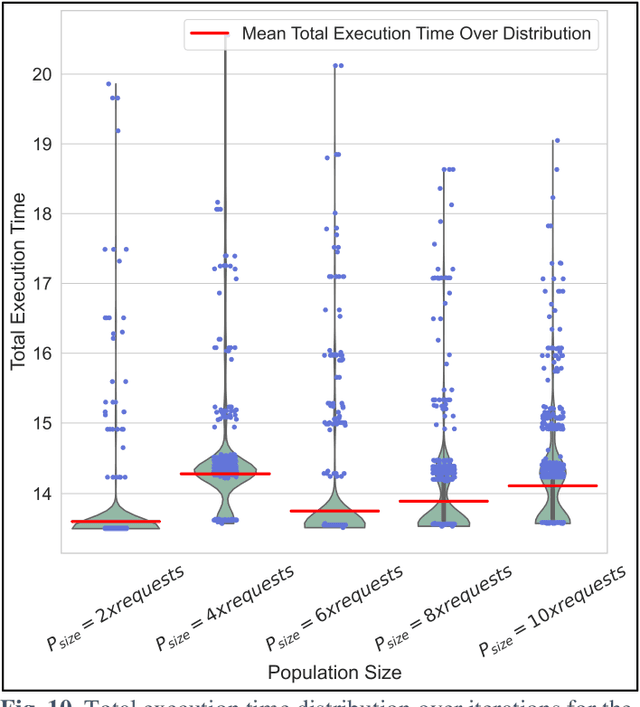
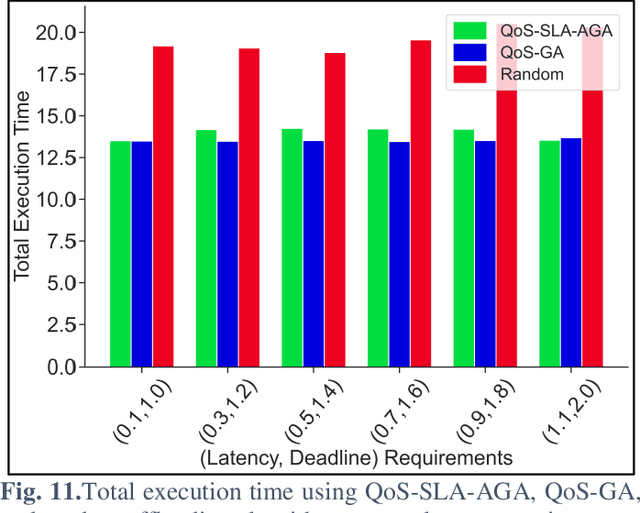
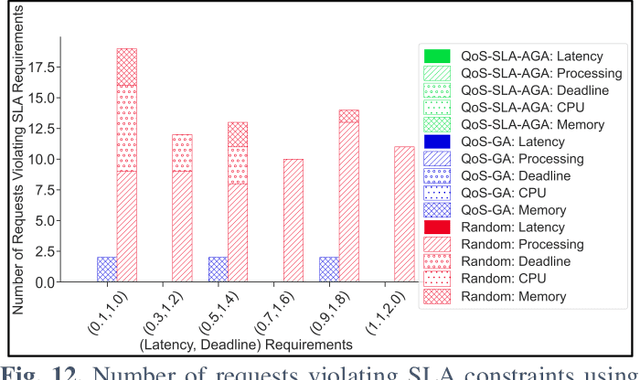
Internet of Vehicles (IoV) over Vehicular Ad-hoc Networks (VANETS) is an emerging technology enabling the development of smart cities applications for safer, efficient, and pleasant travel. These applications have stringent requirements expressed in Service Level Agreements (SLAs). Considering vehicles limited computational and storage capabilities, applications requests are offloaded into an integrated edge-cloud computing system. Existing offloading solutions focus on optimizing applications Quality of Service (QoS) while respecting a single SLA constraint. They do not consider the impact of overlapped requests processing. Very few contemplate the varying speed of a vehicle. This paper proposes a novel Artificial Intelligence (AI) QoS-SLA-aware genetic algorithm (GA) for multi-request offloading in a heterogeneous edge-cloud computing system, considering the impact of overlapping requests processing and dynamic vehicle speed. The objective of the optimization algorithm is to improve the applications' Quality of Service (QoS) by minimizing the total execution time. The proposed algorithm integrates an adaptive penalty function to assimilate the SLAs constraints in terms of latency, processing time, deadline, CPU, and memory requirements. Numerical experiments and comparative analysis are achieved between our proposed QoS-SLA-aware GA, random, and GA baseline approaches. The results show that the proposed algorithm executes the requests 1.22 times faster on average compared to the random approach with 59.9% less SLA violations. While the GA baseline approach increases the performance of the requests by 1.14 times, it has 19.8% more SLA violations than our approach.
All You Need is LUV: Unsupervised Collection of Labeled Images using Invisible UV Fluorescent Indicators
Mar 09, 2022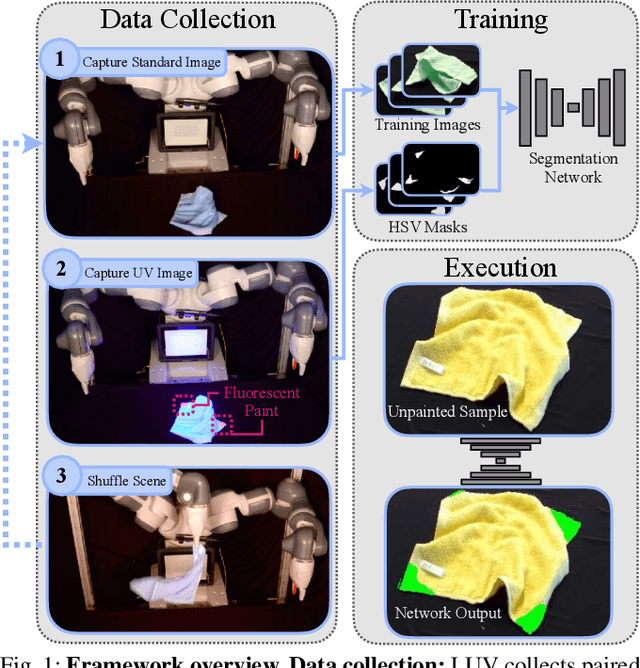



Large-scale semantic image annotation is a significant challenge for learning-based perception systems in robotics. Current approaches often rely on human labelers, which can be expensive, or simulation data, which can visually or physically differ from real data. This paper proposes Labels from UltraViolet (LUV), a novel framework that enables rapid, labeled data collection in real manipulation environments without human labeling. LUV uses transparent, ultraviolet-fluorescent paint with programmable ultraviolet LEDs to collect paired images of a scene in standard lighting and UV lighting to autonomously extract segmentation masks and keypoints via color segmentation. We apply LUV to a suite of diverse robot perception tasks to evaluate its labeling quality, flexibility, and data collection rate. Results suggest that LUV is 180-2500 times faster than a human labeler across the tasks. We show that LUV provides labels consistent with human annotations on unpainted test images. The networks trained on these labels are used to smooth and fold crumpled towels with 83% success rate and achieve 1.7mm position error with respect to human labels on a surgical needle pose estimation task. The low cost of LUV makes it ideal as a lightweight replacement for human labeling systems, with the one-time setup costs at $300 equivalent to the cost of collecting around 200 semantic segmentation labels on Amazon Mechanical Turk. Code, datasets, visualizations, and supplementary material can be found at https://sites.google.com/berkeley.edu/luv