 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Finite Sample Analysis of Two-Time-Scale Natural Actor-Critic Algorithm
Jan 26, 2021
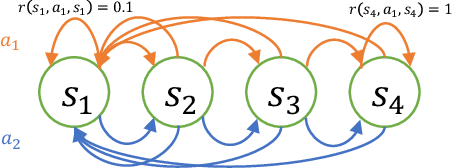
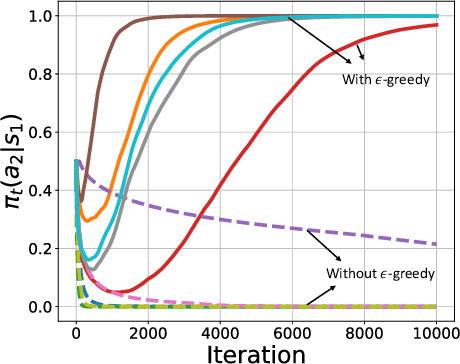
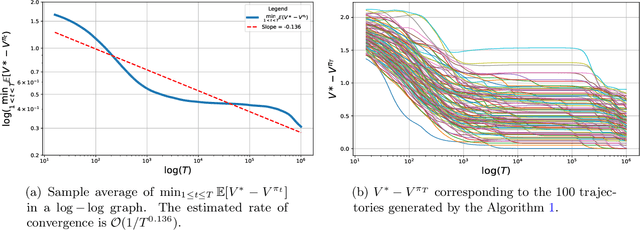
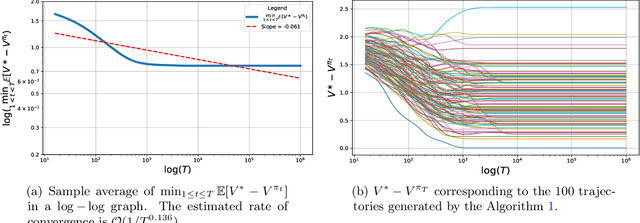
Actor-critic style two-time-scale algorithms are very popular in reinforcement learning, and have seen great empirical success. However, their performance is not completely understood theoretically. In this paper, we characterize the global convergence of an online natural actor-critic algorithm in the tabular setting using a single trajectory. Our analysis applies to very general settings, as we only assume that the underlying Markov chain is ergodic under all policies (the so-called Recurrence assumption). We employ $\epsilon$-greedy sampling in order to ensure enough exploration. For a fixed exploration parameter $\epsilon$, we show that the natural actor critic algorithm is $\mathcal{O}(\frac{1}{\epsilon T^{1/4}}+\epsilon)$ close to the global optimum after $T$ iterations of the algorithm. By carefully diminishing the exploration parameter $\epsilon$ as the iterations proceed, we also show convergence to the global optimum at a rate of $\mathcal{O}(1/T^{1/6})$.
Learning continuous-time PDEs from sparse data with graph neural networks
Jun 16, 2020
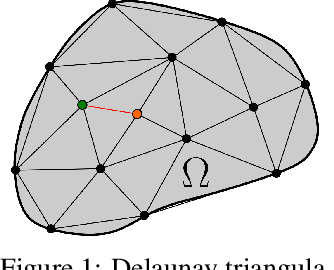
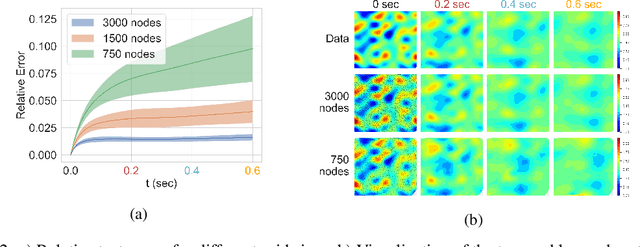
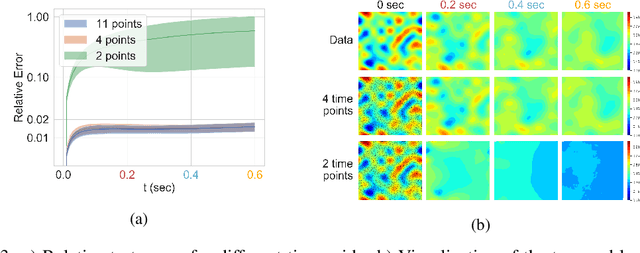
The behavior of many dynamical systems follow complex, yet still unknown partial differential equations (PDEs). While several machine learning methods have been proposed to learn PDEs directly from data, previous methods are limited to discrete-time approximations or make the limiting assumption of the observations arriving at regular grids. We propose a general continuous-time differential model for dynamical systems whose governing equations are parameterized by message passing graph neural networks. The model admits arbitrary space and time discretizations, which removes constraints on the locations of observation points and time intervals between the observations. The model is trained with continuous-time adjoint method enabling efficient neural PDE inference. We demonstrate the model's ability to work with unstructured grids, arbitrary time steps, and noisy observations. We compare our method with existing approaches on several well-known physical systems that involve first and higher-order PDEs with state-of-the-art predictive performance.
Environment Generation for Zero-Shot Compositional Reinforcement Learning
Jan 21, 2022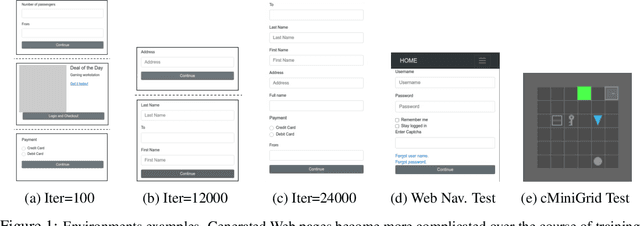
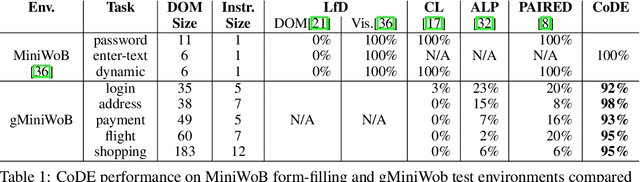

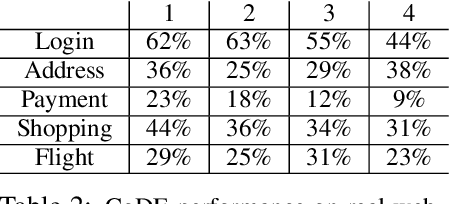
Many real-world problems are compositional - solving them requires completing interdependent sub-tasks, either in series or in parallel, that can be represented as a dependency graph. Deep reinforcement learning (RL) agents often struggle to learn such complex tasks due to the long time horizons and sparse rewards. To address this problem, we present Compositional Design of Environments (CoDE), which trains a Generator agent to automatically build a series of compositional tasks tailored to the RL agent's current skill level. This automatic curriculum not only enables the agent to learn more complex tasks than it could have otherwise, but also selects tasks where the agent's performance is weak, enhancing its robustness and ability to generalize zero-shot to unseen tasks at test-time. We analyze why current environment generation techniques are insufficient for the problem of generating compositional tasks, and propose a new algorithm that addresses these issues. Our results assess learning and generalization across multiple compositional tasks, including the real-world problem of learning to navigate and interact with web pages. We learn to generate environments composed of multiple pages or rooms, and train RL agents capable of completing wide-range of complex tasks in those environments. We contribute two new benchmark frameworks for generating compositional tasks, compositional MiniGrid and gMiniWoB for web navigation.CoDE yields 4x higher success rate than the strongest baseline, and demonstrates strong performance of real websites learned on 3500 primitive tasks.
Attention-gated convolutional neural networks for off-resonance correction of spiral real-time MRI
Feb 14, 2021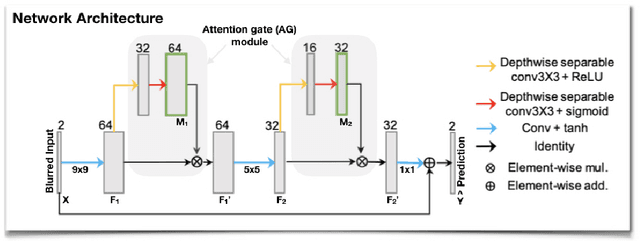
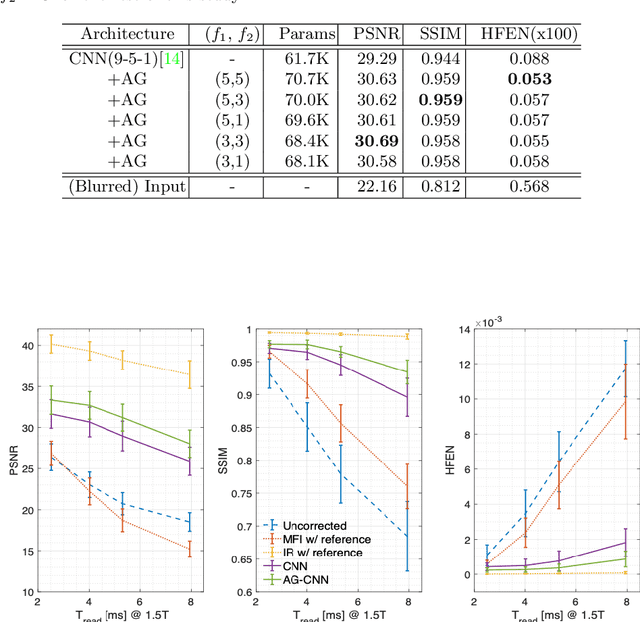

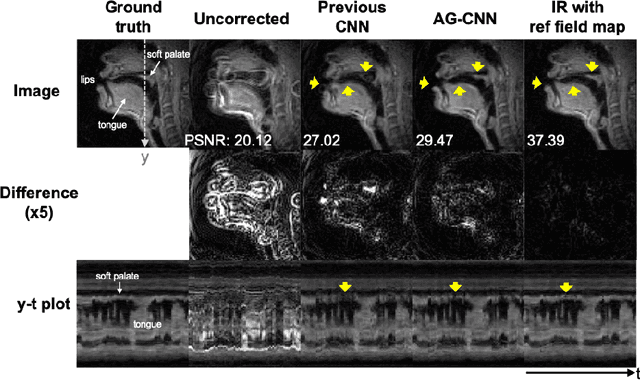
Spiral acquisitions are preferred in real-time MRI because of their efficiency, which has made it possible to capture vocal tract dynamics during natural speech. A fundamental limitation of spirals is blurring and signal loss due to off-resonance, which degrades image quality at air-tissue boundaries. Here, we present a new CNN-based off-resonance correction method that incorporates an attention-gate mechanism. This leverages spatial and channel relationships of filtered outputs and improves the expressiveness of the networks. We demonstrate improved performance with the attention-gate, on 1.5 Tesla spiral speech RT-MRI, compared to existing off-resonance correction methods.
* 8 pages, 4 figures, 1 table
Learning a Single Neuron for Non-monotonic Activation Functions
Feb 16, 2022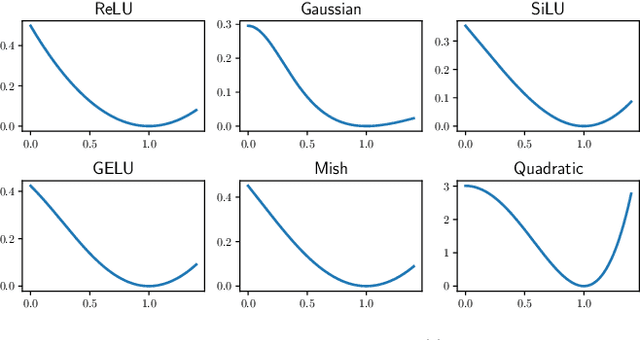
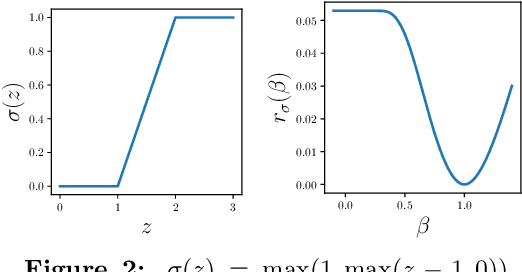
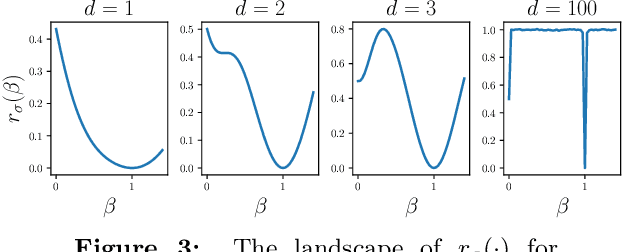
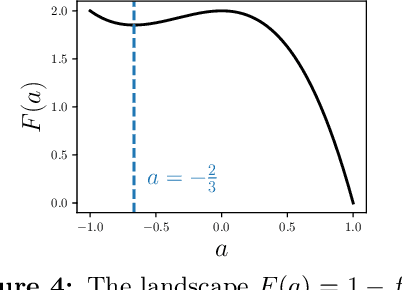
We study the problem of learning a single neuron $\mathbf{x}\mapsto \sigma(\mathbf{w}^T\mathbf{x})$ with gradient descent (GD). All the existing positive results are limited to the case where $\sigma$ is monotonic. However, it is recently observed that non-monotonic activation functions outperform the traditional monotonic ones in many applications. To fill this gap, we establish learnability without assuming monotonicity. Specifically, when the input distribution is the standard Gaussian, we show that mild conditions on $\sigma$ (e.g., $\sigma$ has a dominating linear part) are sufficient to guarantee the learnability in polynomial time and polynomial samples. Moreover, with a stronger assumption on the activation function, the condition of input distribution can be relaxed to a non-degeneracy of the marginal distribution. We remark that our conditions on $\sigma$ are satisfied by practical non-monotonic activation functions, such as SiLU/Swish and GELU. We also discuss how our positive results are related to existing negative results on training two-layer neural networks.
Last-Iterate Convergence of Saddle Point Optimizers via High-Resolution Differential Equations
Dec 27, 2021
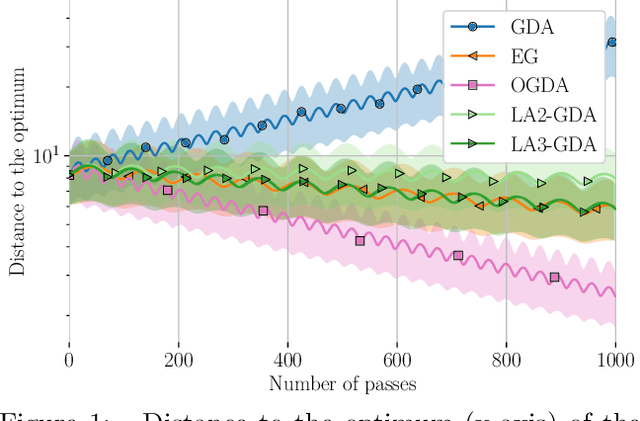

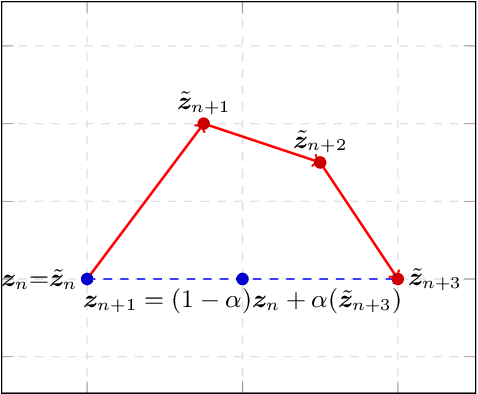
Several widely-used first-order saddle point optimization methods yield an identical continuous-time ordinary differential equation (ODE) to that of the Gradient Descent Ascent (GDA) method when derived naively. However, their convergence properties are very different even on simple bilinear games. We use a technique from fluid dynamics called High-Resolution Differential Equations (HRDEs) to design ODEs of several saddle point optimization methods. On bilinear games, the convergence properties of the derived HRDEs correspond to that of the starting discrete methods. Using these techniques, we show that the HRDE of Optimistic Gradient Descent Ascent (OGDA) has last-iterate convergence for general monotone variational inequalities. To our knowledge, this is the first continuous-time dynamics shown to converge for such a general setting. Moreover, we provide the rates for the best-iterate convergence of the OGDA method, relying solely on the first-order smoothness of the monotone operator.
Improving the quality control of seismic data through active learning
Jan 17, 2022
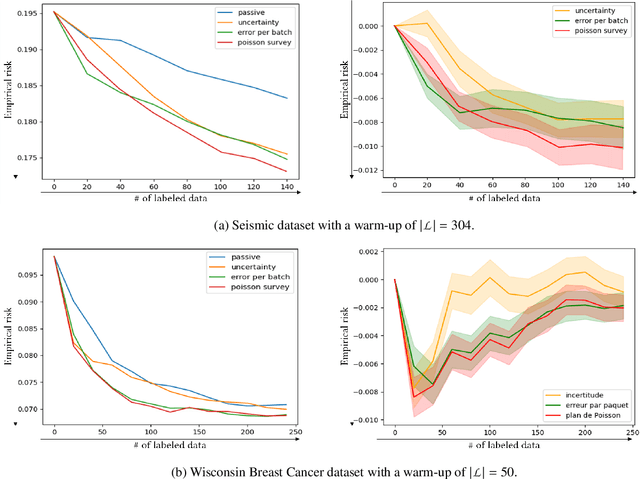
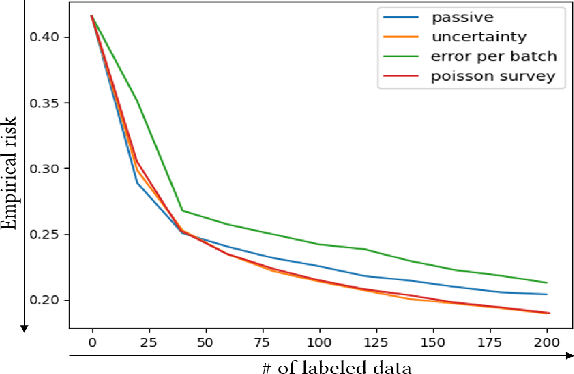
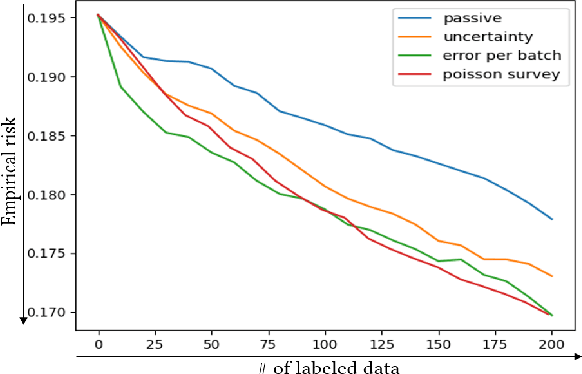
In image denoising problems, the increasing density of available images makes an exhaustive visual inspection impossible and therefore automated methods based on machine-learning must be deployed for this purpose. This is particulary the case in seismic signal processing. Engineers/geophysicists have to deal with millions of seismic time series. Finding the sub-surface properties useful for the oil industry may take up to a year and is very costly in terms of computing/human resources. In particular, the data must go through different steps of noise attenuation. Each denoise step is then ideally followed by a quality control (QC) stage performed by means of human expertise. To learn a quality control classifier in a supervised manner, labeled training data must be available, but collecting the labels from human experts is extremely time-consuming. We therefore propose a novel active learning methodology to sequentially select the most relevant data, which are then given back to a human expert for labeling. Beyond the application in geophysics, the technique we promote in this paper, based on estimates of the local error and its uncertainty, is generic. Its performance is supported by strong empirical evidence, as illustrated by the numerical experiments presented in this article, where it is compared to alternative active learning strategies both on synthetic and real seismic datasets.
NeRF-Pose: A First-Reconstruct-Then-Regress Approach for Weakly-supervised 6D Object Pose Estimation
Mar 09, 2022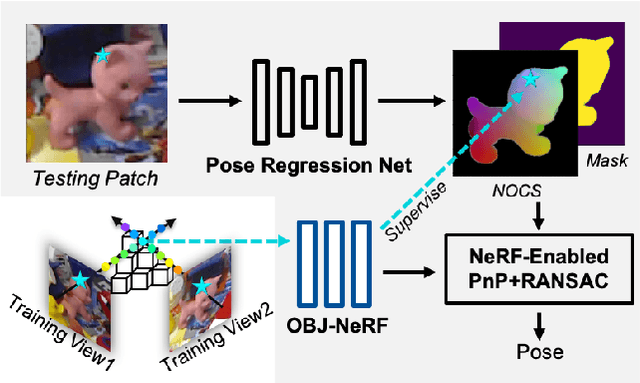
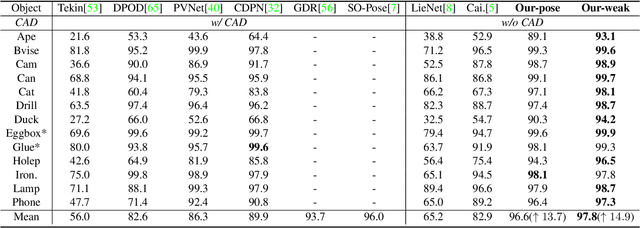
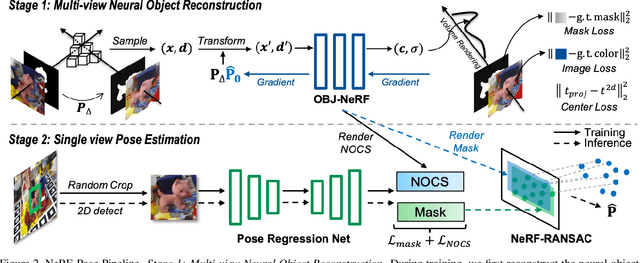
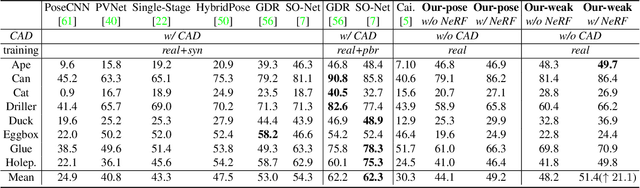
Pose estimation of 3D objects in monocular images is a fundamental and long-standing problem in computer vision. Existing deep learning approaches for 6D pose estimation typically rely on the assumption of availability of 3D object models and 6D pose annotations. However, precise annotation of 6D poses in real data is intricate, time-consuming and not scalable, while synthetic data scales well but lacks realism. To avoid these problems, we present a weakly-supervised reconstruction-based pipeline, named NeRF-Pose, which needs only 2D object segmentation and known relative camera poses during training. Following the first-reconstruct-then-regress idea, we first reconstruct the objects from multiple views in the form of an implicit neural representation. Then, we train a pose regression network to predict pixel-wise 2D-3D correspondences between images and the reconstructed model. At inference, the approach only needs a single image as input. A NeRF-enabled PnP+RANSAC algorithm is used to estimate stable and accurate pose from the predicted correspondences. Experiments on LineMod and LineMod-Occlusion show that the proposed method has state-of-the-art accuracy in comparison to the best 6D pose estimation methods in spite of being trained only with weak labels. Besides, we extend the Homebrewed DB dataset with more real training images to support the weakly supervised task and achieve compelling results on this dataset. The extended dataset and code will be released soon.
Spectrum Surveying: Active Radio Map Estimation with Autonomous UAVs
Jan 13, 2022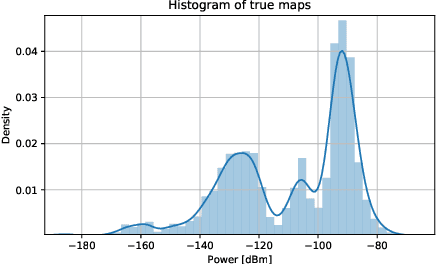
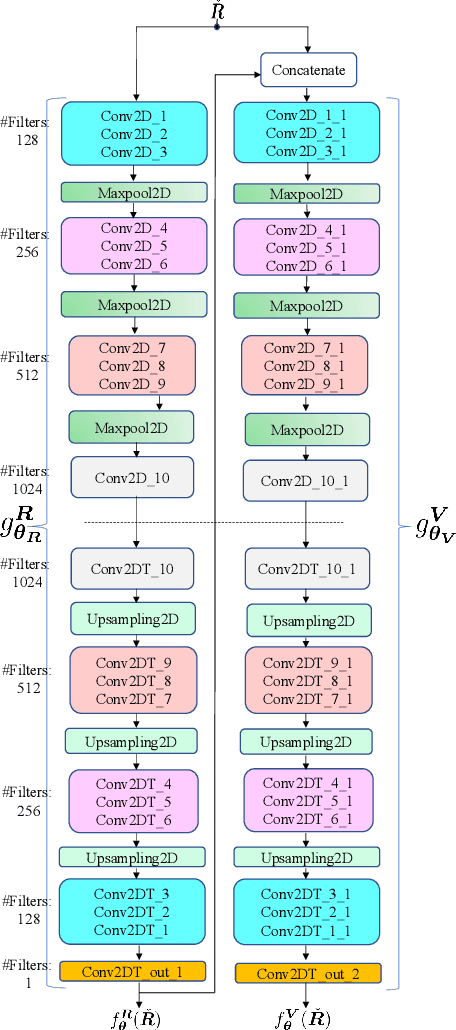
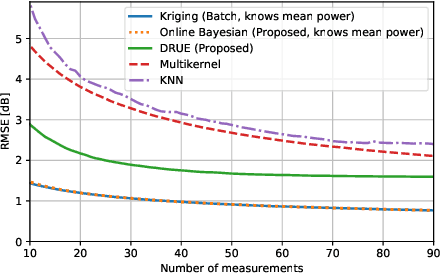
Radio maps find numerous applications in wireless communications and mobile robotics tasks, including resource allocation, interference coordination, and mission planning. Although numerous techniques have been proposed to construct radio maps from spatially distributed measurements, the locations of such measurements are assumed predetermined beforehand. In contrast, this paper proposes spectrum surveying, where a mobile robot such as an unmanned aerial vehicle (UAV) collects measurements at a set of locations that are actively selected to obtain high-quality map estimates in a short surveying time. This is performed in two steps. First, two novel algorithms, a model-based online Bayesian estimator and a data-driven deep learning algorithm, are devised for updating a map estimate and an uncertainty metric that indicates the informativeness of measurements at each possible location. These algorithms offer complementary benefits and feature constant complexity per measurement. Second, the uncertainty metric is used to plan the trajectory of the UAV to gather measurements at the most informative locations. To overcome the combinatorial complexity of this problem, a dynamic programming approach is proposed to obtain lists of waypoints through areas of large uncertainty in linear time. Numerical experiments conducted on a realistic dataset confirm that the proposed scheme constructs accurate radio maps quickly.
Neural Data-Dependent Transform for Learned Image Compression
Mar 09, 2022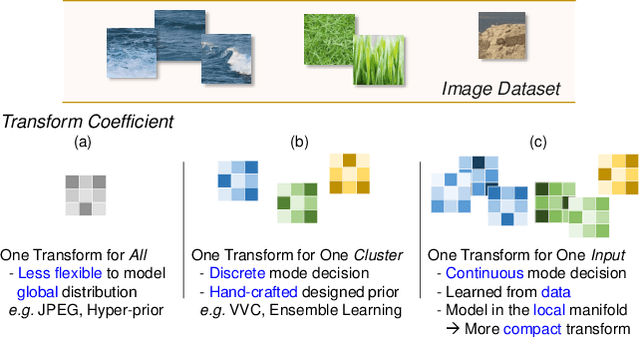
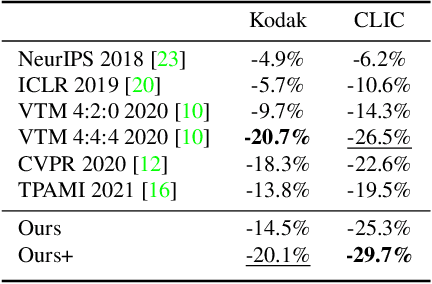
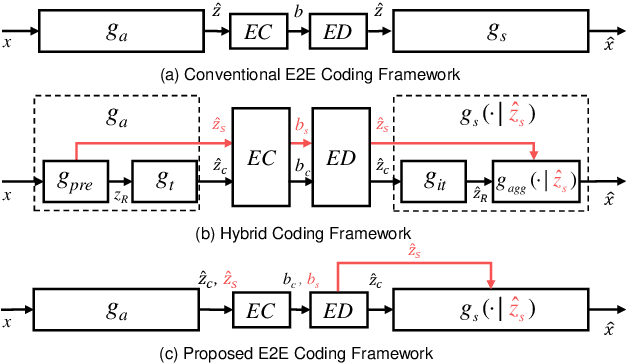
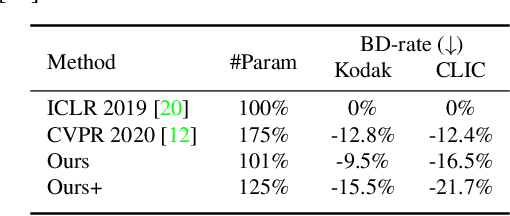
Learned image compression has achieved great success due to its excellent modeling capacity, but seldom further considers the Rate-Distortion Optimization (RDO) of each input image. To explore this potential in the learned codec, we make the first attempt to build a neural data-dependent transform and introduce a continuous online mode decision mechanism to jointly optimize the coding efficiency for each individual image. Specifically, apart from the image content stream, we employ an additional model stream to generate the transform parameters at the decoder side. The presence of a model stream enables our model to learn more abstract neural-syntax, which helps cluster the latent representations of images more compactly. Beyond the transform stage, we also adopt neural-syntax based post-processing for the scenarios that require higher quality reconstructions regardless of extra decoding overhead. Moreover, the involvement of the model stream further makes it possible to optimize both the representation and the decoder in an online way, i.e. RDO at the testing time. It is equivalent to a continuous online mode decision, like coding modes in the traditional codecs, to improve the coding efficiency based on the individual input image. The experimental results show the effectiveness of the proposed neural-syntax design and the continuous online mode decision mechanism, demonstrating the superiority of our method in coding efficiency compared to the latest conventional standard Versatile Video Coding (VVC) and other state-of-the-art learning-based methods.