 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Artificial Intelligence in Software Testing : Impact, Problems, Challenges and Prospect
Jan 14, 2022
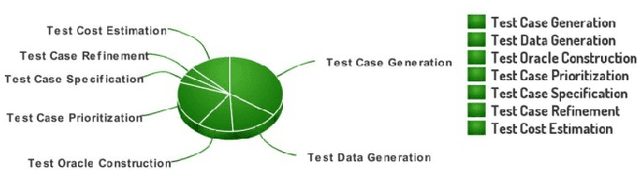
Artificial Intelligence (AI) is making a significant impact in multiple areas like medical, military, industrial, domestic, law, arts as AI is capable to perform several roles such as managing smart factories, driving autonomous vehicles, creating accurate weather forecasts, detecting cancer and personal assistants, etc. Software testing is the process of putting the software to test for some abnormal behaviour of the software. Software testing is a tedious, laborious and most time-consuming process. Automation tools have been developed that help to automate some activities of the testing process to enhance quality and timely delivery. Over time with the inclusion of continuous integration and continuous delivery (CI/CD) pipeline, automation tools are becoming less effective. The testing community is turning to AI to fill the gap as AI is able to check the code for bugs and errors without any human intervention and in a much faster way than humans. In this study, we aim to recognize the impact of AI technologies on various software testing activities or facets in the STLC. Further, the study aims to recognize and explain some of the biggest challenges software testers face while applying AI to testing. The paper also proposes some key contributions of AI in the future to the domain of software testing.
Efficient Information Diffusion in Time-Varying Graphs through Deep Reinforcement Learning
Nov 27, 2020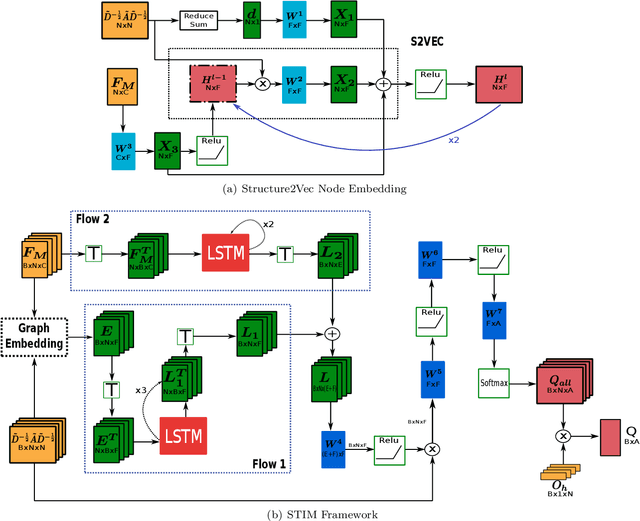
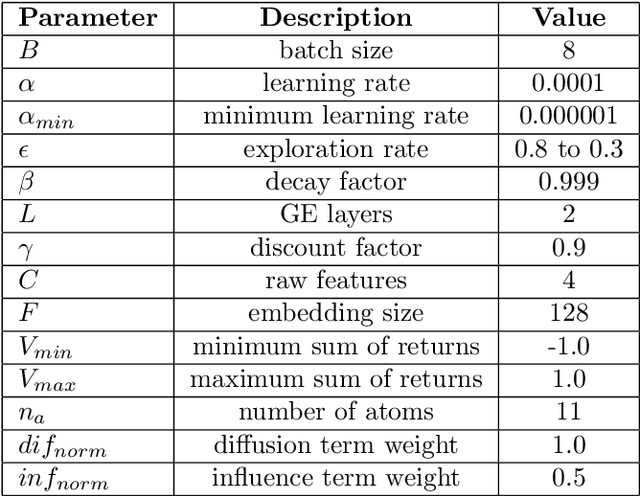
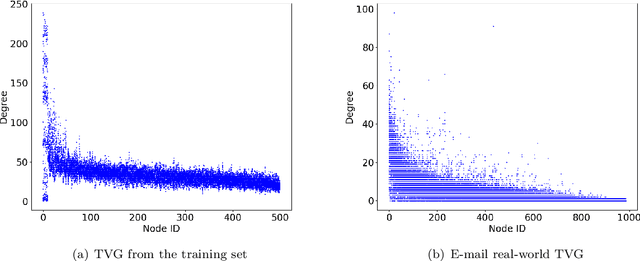

Network seeding for efficient information diffusion over time-varying graphs~(TVGs) is a challenging task with many real-world applications. There are several ways to model this spatio-temporal influence maximization problem, but the ultimate goal is to determine the best moment for a node to start the diffusion process. In this context, we propose Spatio-Temporal Influence Maximization~(STIM), a model trained with Reinforcement Learning and Graph Embedding over a set of artificial TVGs that is capable of learning the temporal behavior and connectivity pattern of each node, allowing it to predict the best moment to start a diffusion through the TVG. We also develop a special set of artificial TVGs used for training that simulate a stochastic diffusion process in TVGs, showing that the STIM network can learn an efficient policy even over a non-deterministic environment. STIM is also evaluated with a real-world TVG, where it also manages to efficiently propagate information through the nodes. Finally, we also show that the STIM model has a time complexity of $O(|E|)$. STIM, therefore, presents a novel approach for efficient information diffusion in TVGs, being highly versatile, where one can change the goal of the model by simply changing the adopted reward function.
TaSPM: Targeted Sequential Pattern Mining
Feb 26, 2022
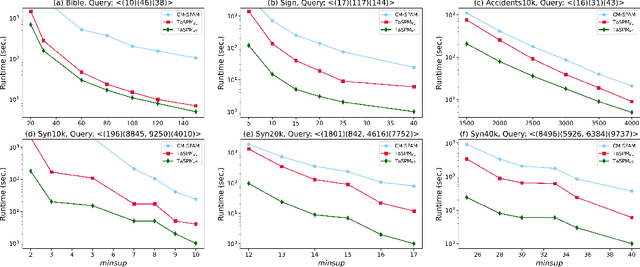
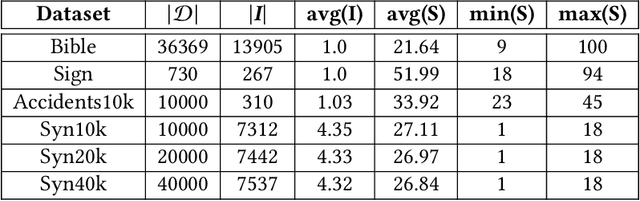
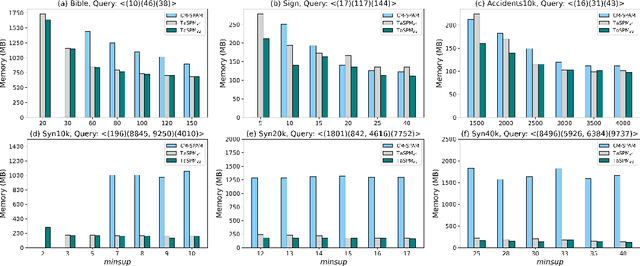
Sequential pattern mining (SPM) is an important technique of pattern mining, which has many applications in reality. Although many efficient sequential pattern mining algorithms have been proposed, there are few studies can focus on target sequences. Targeted querying sequential patterns can not only reduce the number of sequences generated by SPM, but also improve the efficiency of users in performing pattern analysis. The current algorithms available on targeted sequence querying are based on specific scenarios and cannot be generalized to other applications. In this paper, we formulate the problem of targeted sequential pattern mining and propose a generic framework namely TaSPM, based on the fast CM-SPAM algorithm. What's more, to improve the efficiency of TaSPM on large-scale datasets and multiple-items-based sequence datasets, we propose several pruning strategies to reduce meaningless operations in mining processes. Totally four pruning strategies are designed in TaSPM, and hence it can terminate unnecessary pattern extensions quickly and achieve better performance. Finally, we conduct extensive experiments on different datasets to compare the existing SPM algorithms with TaSPM. Experiments show that the novel targeted mining algorithm TaSPM can achieve faster running time and less memory consumption.
Model-free Reinforcement Learning for Content Caching at the Wireless Edge via Restless Bandits
Feb 26, 2022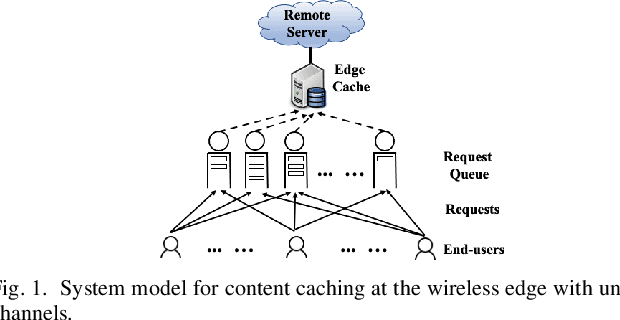
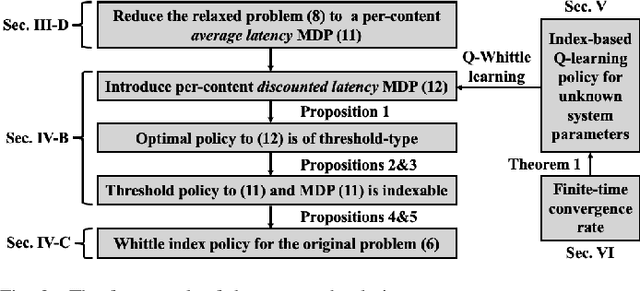
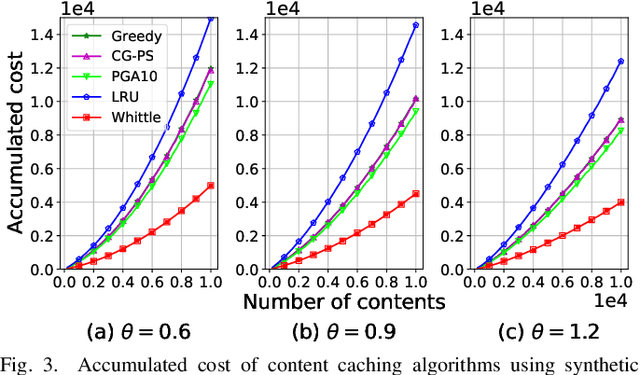
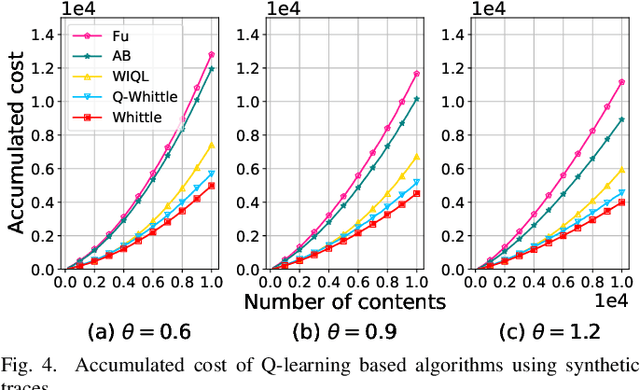
An explosive growth in the number of on-demand content requests has imposed significant pressure on current wireless network infrastructure. To enhance the perceived user experience, and support latency-sensitive applications, edge computing has emerged as a promising computing paradigm. The performance of a wireless edge depends on contents that are cached. In this paper, we consider the problem of content caching at the wireless edge with unreliable channels to minimize average content request latency. We formulate this problem as a restless bandit problem, which is provably hard to solve. We begin by investigating a discounted counterpart, and prove that it admits an optimal policy of the threshold-type. We then show that the result also holds for the average latency problem. Using these structural results, we establish the indexability of the problem, and employ Whittle index policy to minimize average latency. Since system parameters such as content request rate are often unknown, we further develop a model-free reinforcement learning algorithm dubbed Q-Whittle learning that relies on our index policy. We also derive a bound on its finite-time convergence rate. Simulation results using real traces demonstrate that our proposed algorithms yield excellent empirical performance.
Asian Giant Hornet Control based on Image Processing and Biological Dispersal
Nov 26, 2021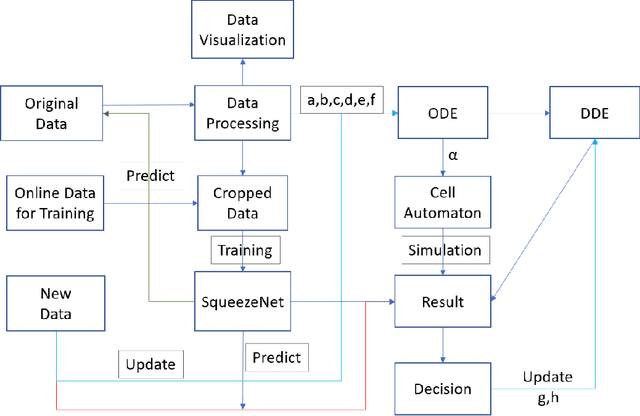


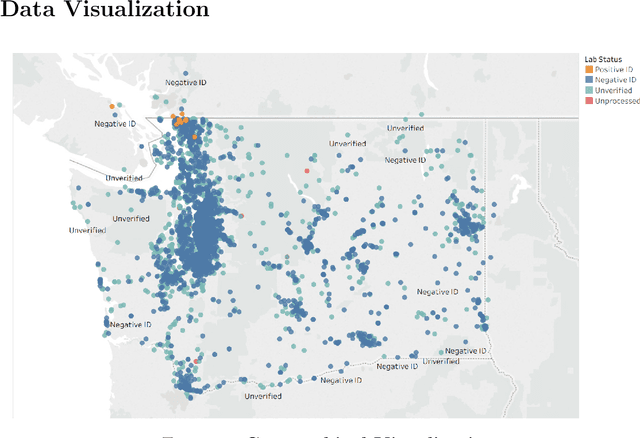
The Asian giant hornet (AGH) appeared in Washington State appears to have a potential danger of bioinvasion. Washington State has collected public photos and videos of detected insects for verification and further investigation. In this paper, we analyze AGH using data analysis,statistics, discrete mathematics, and deep learning techniques to process the data to controlAGH spreading.First, we visualize the geographical distribution of insects in Washington State. Then we investigate insect populations to varying months of the year and different days of a month.Third, we employ wavelet analysis to examine the periodic spread of AGH. Fourth, we apply ordinary differential equations to examine AGH numbers at the different natural growthrate and reaction speed and output the potential propagation coefficient. Next, we leverage cellular automaton combined with the potential propagation coefficient to simulate the geographical spread under changing potential propagation. To update the model, we use delayed differential equations to simulate human intervention. We use the time difference between detection time and submission time to determine the unit of time to delay time. After that, we construct a lightweight CNN called SqueezeNet and assess its classification performance. We then relate several non-reference image quality metrics, including NIQE, image gradient, entropy, contrast, and TOPSIS to judge the cause of misclassification. Furthermore, we build a Random Forest classifier to identify positive and negative samples based on image qualities only. We also display the feature importance and conduct an error analysis. Besides, we present sensitivity analysis to verify the robustness of our models. Finally, we show the strengths and weaknesses of our model and derives the conclusions.
$\text{ISS}_2$: An Extension of Iterative Source Steering Algorithm for Majorization-Minimization-Based Independent Vector Analysis
Feb 02, 2022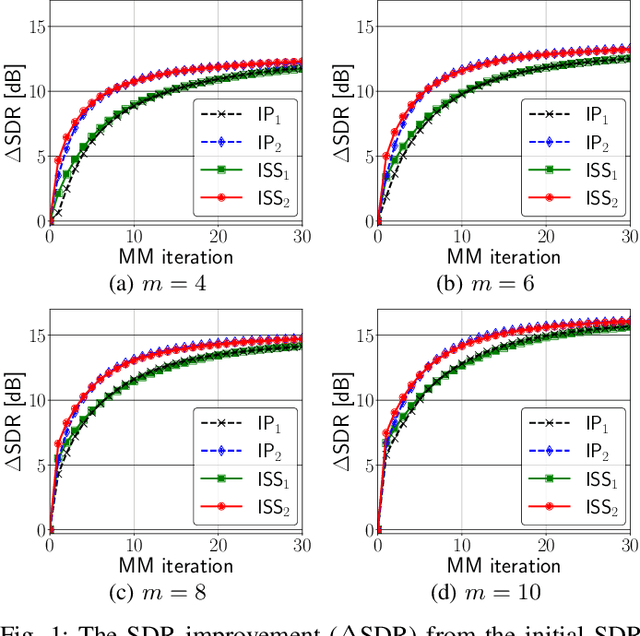
A majorization-minimization (MM) algorithm for independent vector analysis optimizes a separation matrix $W = [w_1, \ldots, w_m]^h \in \mathbb{C}^{m \times m}$ by minimizing a surrogate function of the form $\mathcal{L}(W) = \sum_{i = 1}^m w_i^h V_i w_i - \log | \det W |^2$, where $m \in \mathbb{N}$ is the number of sensors and positive definite matrices $V_1,\ldots,V_m \in \mathbb{C}^{m \times m}$ are constructed in each MM iteration. For $m \geq 3$, no algorithm has been found to obtain a global minimum of $\mathcal{L}(W)$. Instead, block coordinate descent (BCD) methods with closed-form update formulas have been developed for minimizing $\mathcal{L}(W)$ and shown to be effective. One such BCD is called iterative projection (IP) that updates one or two rows of $W$ in each iteration. Another BCD is called iterative source steering (ISS) that updates one column of the mixing matrix $A = W^{-1}$ in each iteration. Although the time complexity per iteration of ISS is $m$ times smaller than that of IP, the conventional ISS converges slower than the current fastest IP (called $\text{IP}_2$) that updates two rows of $W$ in each iteration. We here extend this ISS to $\text{ISS}_2$ that can update two columns of $A$ in each iteration while maintaining its small time complexity. To this end, we provide a unified way for developing new ISS type methods from which $\text{ISS}_2$ as well as the conventional ISS can be immediately obtained in a systematic manner. Numerical experiments to separate reverberant speech mixtures show that our $\text{ISS}_2$ converges in fewer MM iterations than the conventional ISS, and is comparable to $\text{IP}_2$.
Deep Task-Based Analog-to-Digital Conversion
Jan 29, 2022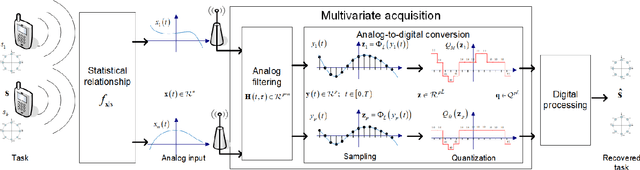
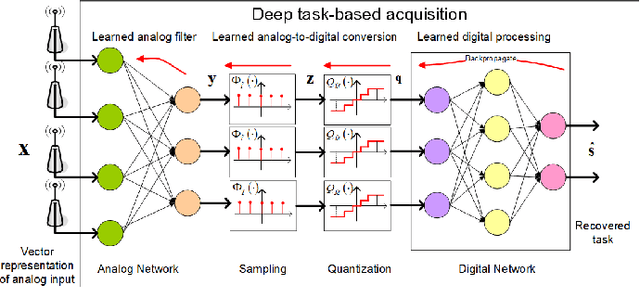
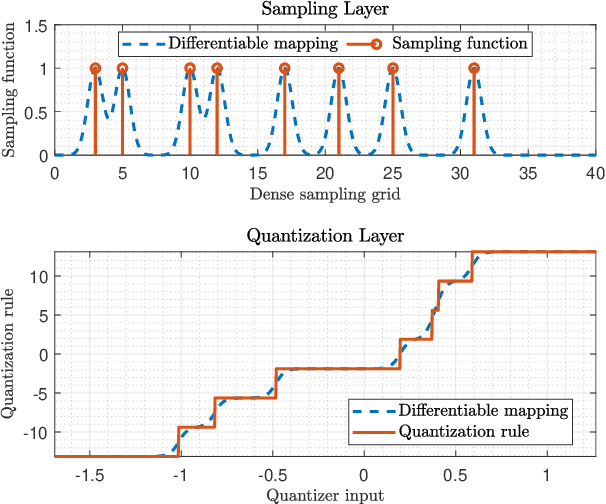
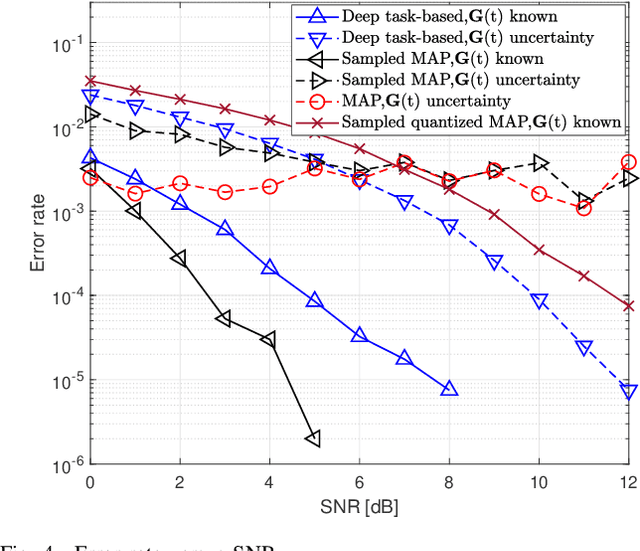
Analog-to-digital converters (ADCs) allow physical signals to be processed using digital hardware. Their conversion consists of two stages: Sampling, which maps a continuous-time signal into discrete-time, and quantization, i.e., representing the continuous-amplitude quantities using a finite number of bits. ADCs typically implement generic uniform conversion mappings that are ignorant of the task for which the signal is acquired, and can be costly when operating in high rates and fine resolutions. In this work we design task-oriented ADCs which learn from data how to map an analog signal into a digital representation such that the system task can be efficiently carried out. We propose a model for sampling and quantization that facilitates the learning of non-uniform mappings from data. Based on this learnable ADC mapping, we present a mechanism for optimizing a hybrid acquisition system comprised of analog combining, tunable ADCs with fixed rates, and digital processing, by jointly learning its components end-to-end. Then, we show how one can exploit the representation of hybrid acquisition systems as deep network to optimize the sampling rate and quantization rate given the task by utilizing Bayesian meta-learning techniques. We evaluate the proposed deep task-based ADC in two case studies: the first considers symbol detection in multi-antenna digital receivers, where multiple analog signals are simultaneously acquired in order to recover a set of discrete information symbols. The second application is the beamforming of analog channel data acquired in ultrasound imaging. Our numerical results demonstrate that the proposed approach achieves performance which is comparable to operating with high sampling rates and fine resolution quantization, while operating with reduced overall bit rate.
Meta-learning with GANs for anomaly detection, with deployment in high-speed rail inspection system
Feb 11, 2022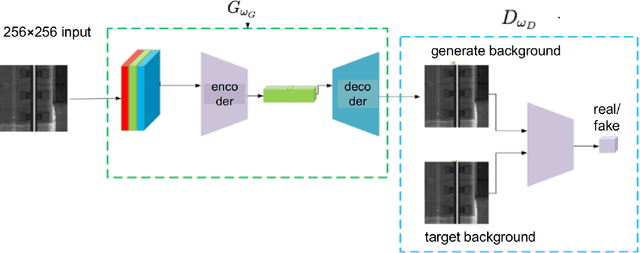
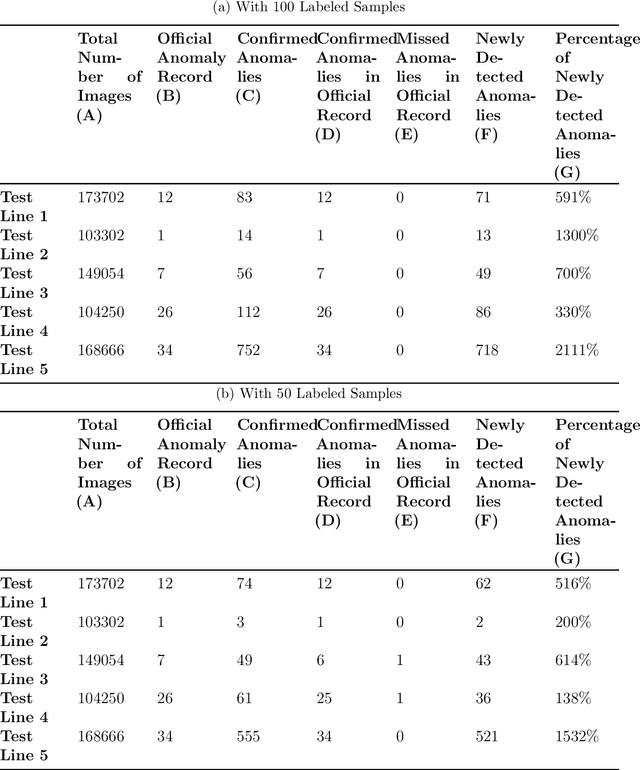
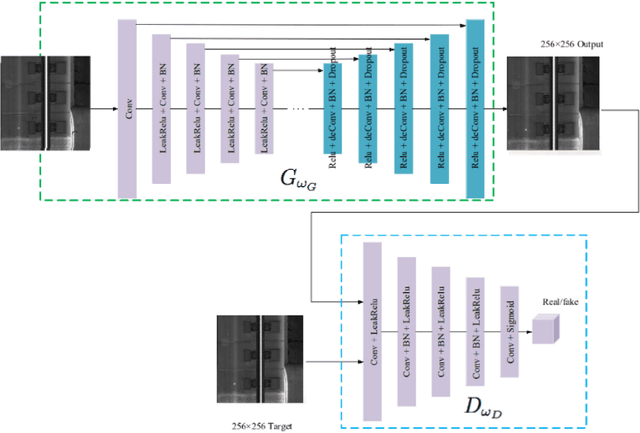
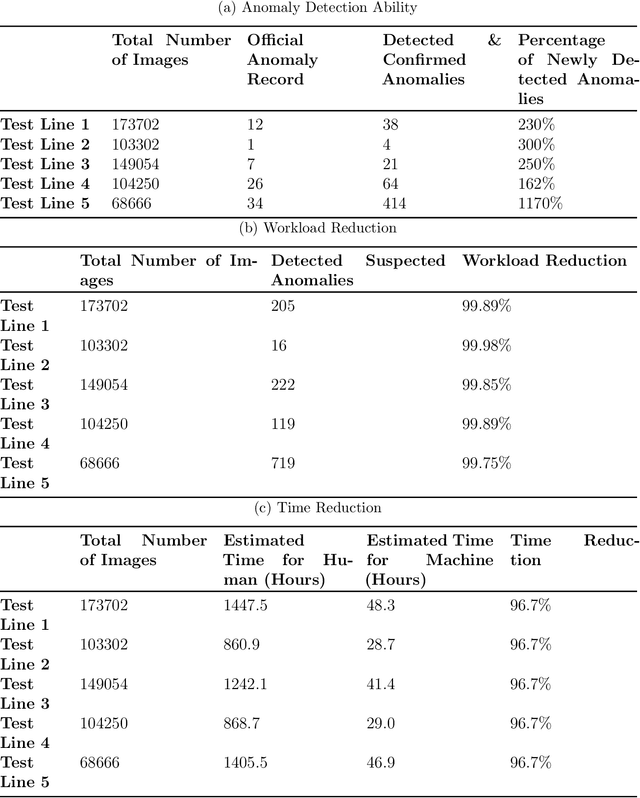
Anomaly detection has been an active research area with a wide range of potential applications. Key challenges for anomaly detection in the AI era with big data include lack of prior knowledge of potential anomaly types, highly complex and noisy background in input data, scarce abnormal samples, and imbalanced training dataset. In this work, we propose a meta-learning framework for anomaly detection to deal with these issues. Within this framework, we incorporate the idea of generative adversarial networks (GANs) with appropriate choices of loss functions including structural similarity index measure (SSIM). Experiments with limited labeled data for high-speed rail inspection demonstrate that our meta-learning framework is sharp and robust in identifying anomalies. Our framework has been deployed in five high-speed railways of China since 2021: it has reduced more than 99.7% workload and saved 96.7% inspection time.
Practical Evaluation of Adversarial Robustness via Adaptive Auto Attack
Mar 10, 2022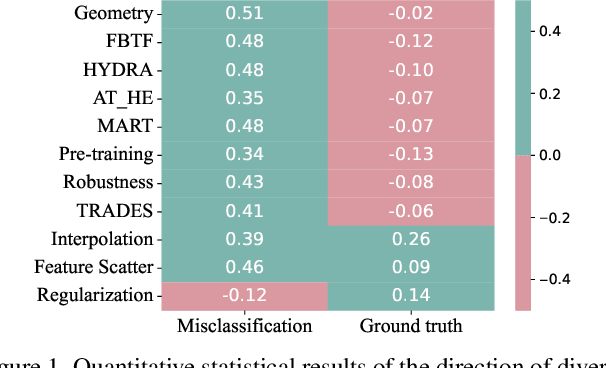
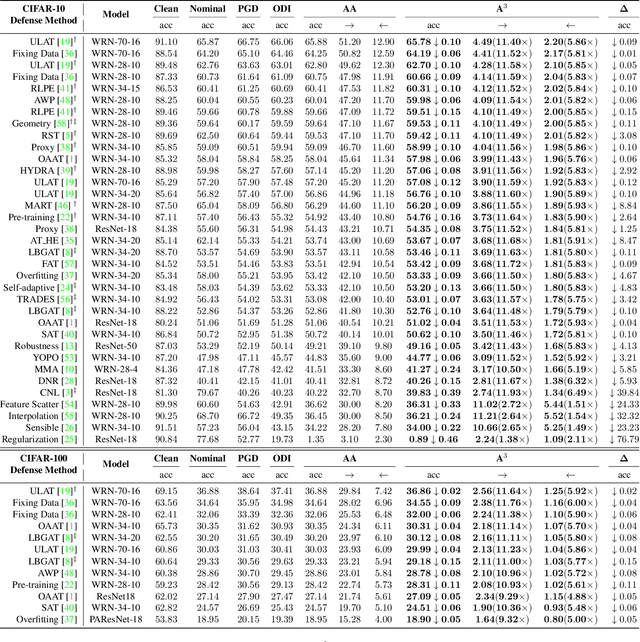
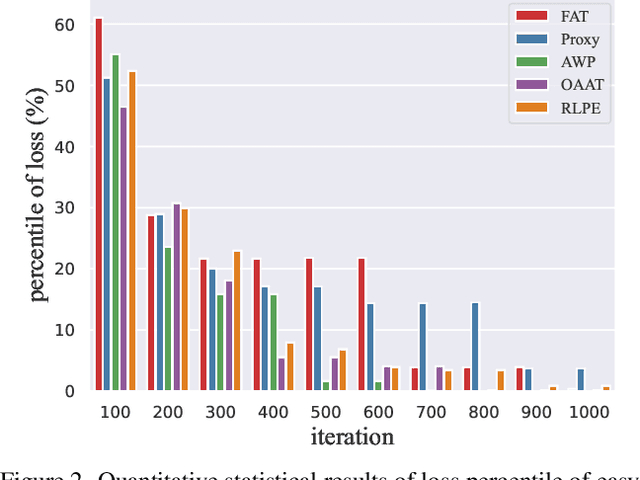
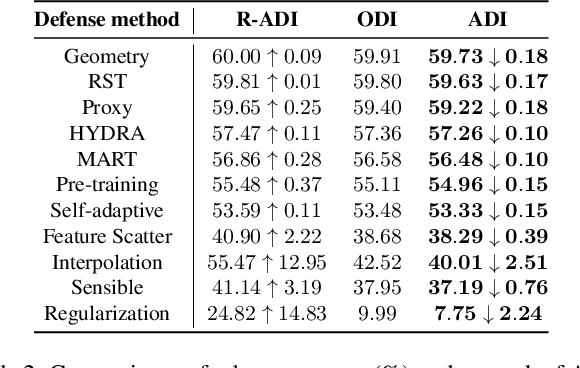
Defense models against adversarial attacks have grown significantly, but the lack of practical evaluation methods has hindered progress. Evaluation can be defined as looking for defense models' lower bound of robustness given a budget number of iterations and a test dataset. A practical evaluation method should be convenient (i.e., parameter-free), efficient (i.e., fewer iterations) and reliable (i.e., approaching the lower bound of robustness). Towards this target, we propose a parameter-free Adaptive Auto Attack (A$^3$) evaluation method which addresses the efficiency and reliability in a test-time-training fashion. Specifically, by observing that adversarial examples to a specific defense model follow some regularities in their starting points, we design an Adaptive Direction Initialization strategy to speed up the evaluation. Furthermore, to approach the lower bound of robustness under the budget number of iterations, we propose an online statistics-based discarding strategy that automatically identifies and abandons hard-to-attack images. Extensive experiments demonstrate the effectiveness of our A$^3$. Particularly, we apply A$^3$ to nearly 50 widely-used defense models. By consuming much fewer iterations than existing methods, i.e., $1/10$ on average (10$\times$ speed up), we achieve lower robust accuracy in all cases. Notably, we won $\textbf{first place}$ out of 1681 teams in CVPR 2021 White-box Adversarial Attacks on Defense Models competitions with this method. Code is available at: $\href{https://github.com/liuye6666/adaptive_auto_attack}{https://github.com/liuye6666/adaptive\_auto\_attack}$
A Decentralized Communication Framework based on Dual-Level Recurrence for Multi-Agent Reinforcement Learning
Feb 22, 2022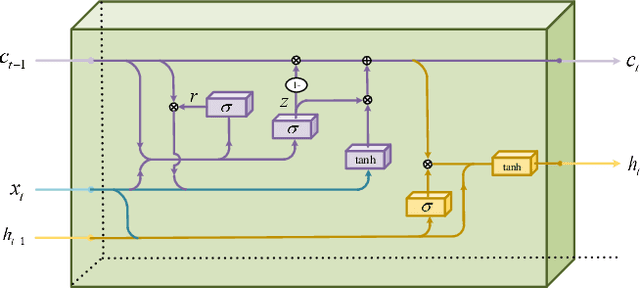
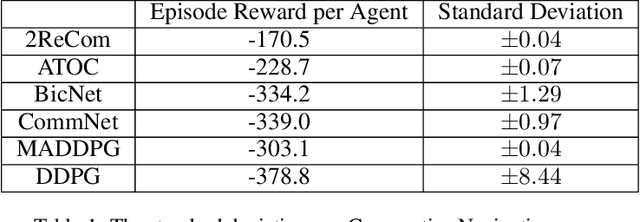
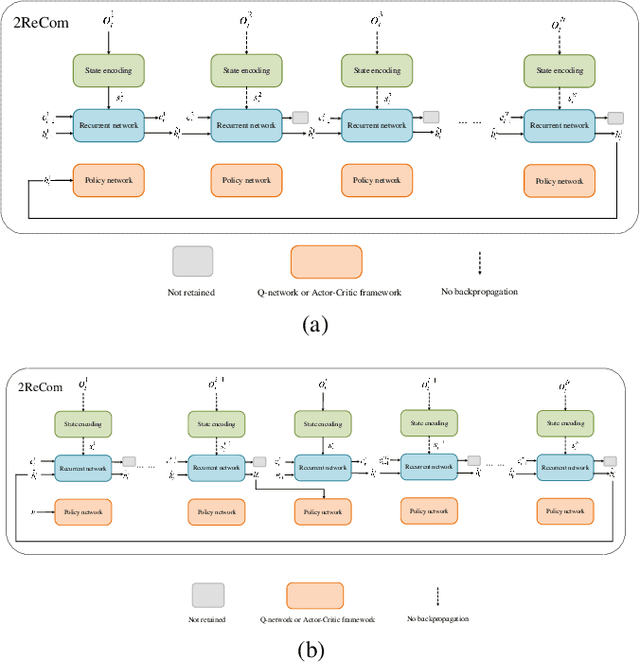
We propose a model enabling decentralized multiple agents to share their perception of environment in a fair and adaptive way. In our model, both the current message and historical observation are taken into account, and they are handled in the same recurrent model but in different forms. We present a dual-level recurrent communication framework for multi-agent systems, in which the first recurrence occurs in the communication sequence and is used to transmit communication data among agents, while the second recurrence is based on the time sequence and combines the historical observations for each agent. The developed communication flow separates communication messages from memories but allows agents to share their historical observations by the dual-level recurrence. This design makes agents adapt to changeable communication objects, while the communication results are fair to these agents. We provide a sufficient discussion about our method in both partially observable and fully observable environments. The results of several experiments suggest our method outperforms the existing decentralized communication frameworks and the corresponding centralized training method.