 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Instance-aware multi-object self-supervision for monocular depth prediction
Mar 02, 2022
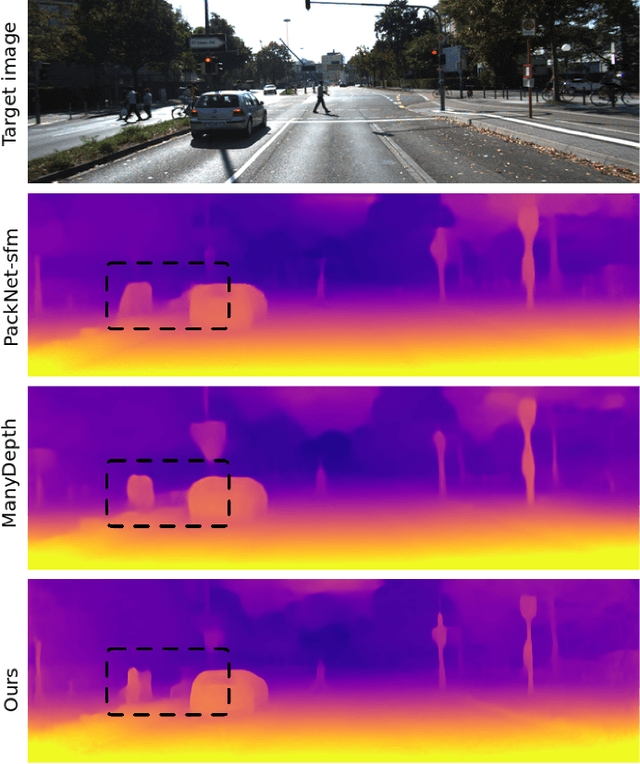
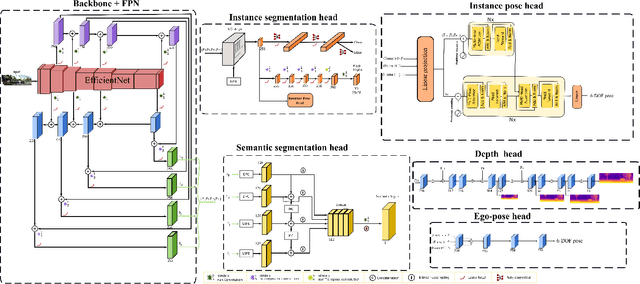
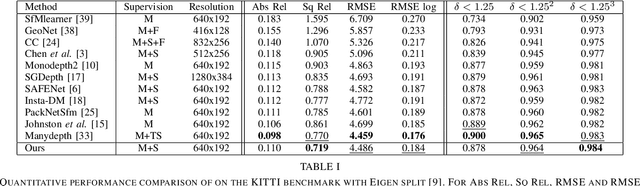
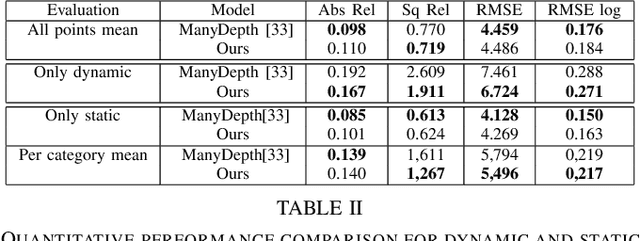
This paper proposes a self-supervised monocular image-to-depth prediction framework that is trained with an end-to-end photometric loss that handles not only 6-DOF camera motion but also 6-DOF moving object instances. Self-supervision is performed by warping the images across a video sequence using depth and scene motion including object instances. One novelty of the proposed method is the use of a multi-head attention of the transformer network that matches moving objects across time and models their interaction and dynamics. This enables accurate and robust pose estimation for each object instance. Most image-to-depth predication frameworks make the assumption of rigid scenes, which largely degrades their performance with respect to dynamic objects. Only a few SOTA papers have accounted for dynamic objects. The proposed method is shown to largely outperform these methods on standard benchmarks and the impact of the dynamic motion on these benchmarks is exposed. Furthermore, the proposed image-to-depth prediction framework is also shown to outperform SOTA video-to-depth prediction frameworks.
Thinking the Fusion Strategy of Multi-reference Face Reenactment
Feb 22, 2022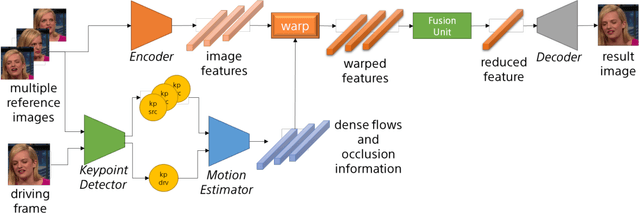

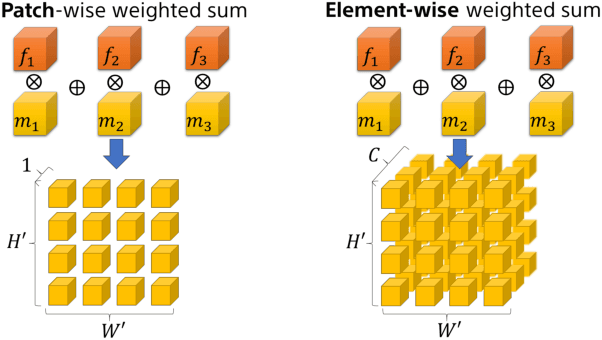
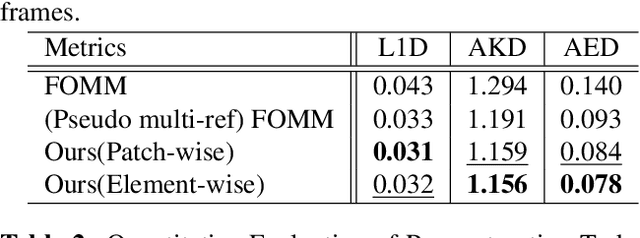
In recent advances of deep generative models, face reenactment -manipulating and controlling human face, including their head movement-has drawn much attention for its wide range of applicability. Despite its strong expressiveness, it is inevitable that the models fail to reconstruct or accurately generate unseen side of the face of a given single reference image. Most of existing methods alleviate this problem by learning appearances of human faces from large amount of data and generate realistic texture at inference time. Rather than completely relying on what generative models learn, we show that simple extension by using multiple reference images significantly improves generation quality. We show this by 1) conducting the reconstruction task on publicly available dataset, 2) conducting facial motion transfer on our original dataset which consists of multi-person's head movement video sequences, and 3) using a newly proposed evaluation metric to validate that our method achieves better quantitative results.
A Novel Deep ML Architecture by Integrating Visual Simultaneous Localization and Mapping (vSLAM) into Mask R-CNN for Real-time Surgical Video Analysis
Mar 31, 2021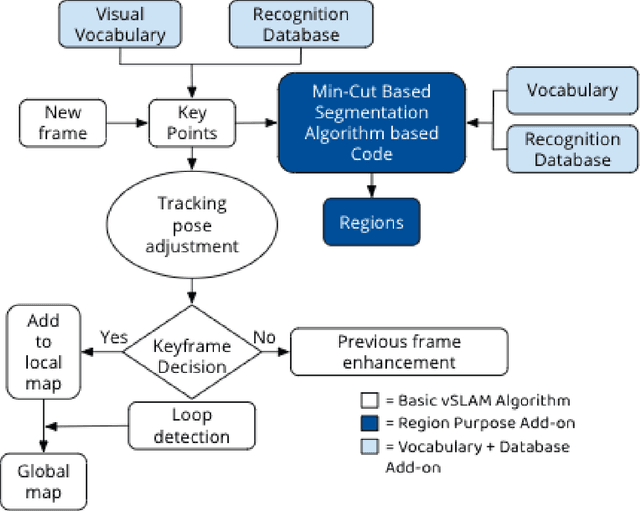
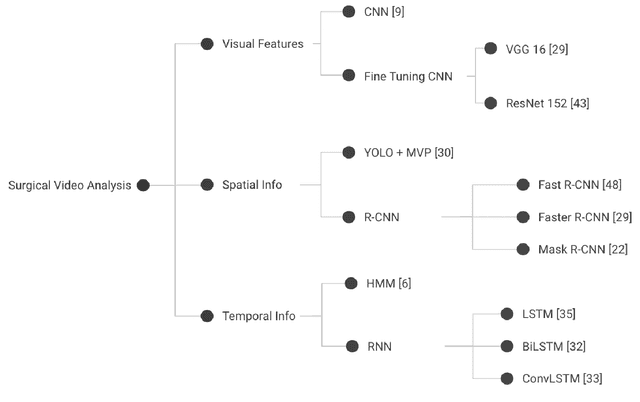
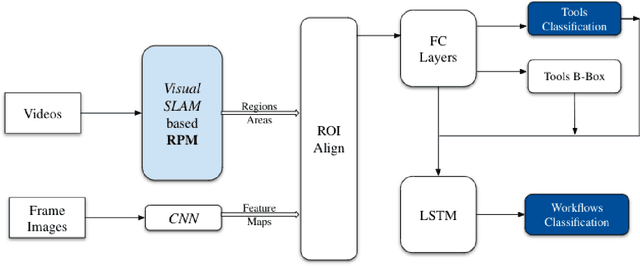
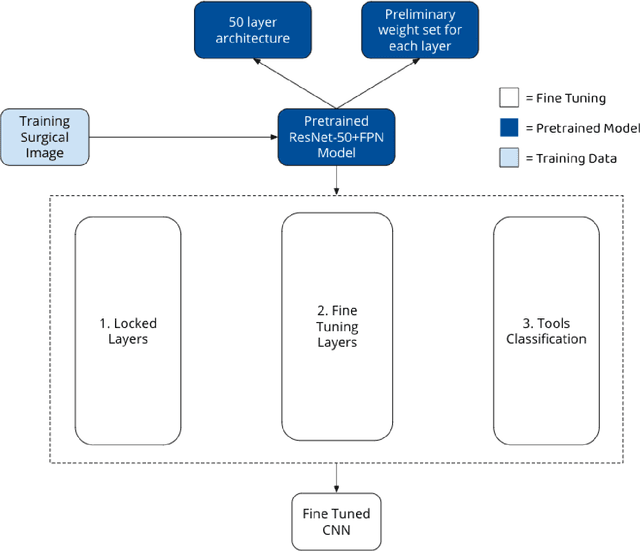
Seven million people suffer complications after surgery each year. With sufficient surgical training and feedback, half of these complications could be prevented. Automatic surgical video analysis, especially for minimally invasive surgery, plays a key role in training and review, with increasing interests from recent studies on tool and workflow detection. In this research, a novel machine learning architecture, RPM-CNN, is created to perform real-time surgical video analysis. This architecture, for the first time, integrates visual simultaneous localization and mapping (vSLAM) into Mask R-CNN. Spatio-temporal information, in addition to the visual features, is utilized to increase the accuracy to 96.8 mAP for tool detection and 97.5 mean Jaccard for workflow detection, surpassing all previous works via the same benchmark dataset. As a real-time prediction, the RPM-CNN model reaches a 50 FPS runtime performance speed, 10x faster than region based CNN, by modeling the spatio-temporal information directly from surgical videos during the vSLAM 3D mapping. Additionally, this novel Region Proposal Module (RPM) replaces the region proposal network (RPN) in Mask R-CNN, accurately placing bounding-boxes and lessening the annotation requirement. In principle, this architecture integrates the best of both worlds, inclusive of 1) vSLAM on object detection, through focusing on geometric information for region proposals and 2) CNN on object recognition, through focusing on semantic information for image classification; the integration of these two technologies into one joint training process opens a new door in computer vision. Furthermore, to apply RPM-CNN's real-time top performance to the real world, a Microsoft HoloLens 2 application is developed to provide an augmented reality (AR) based solution for both surgical training and assistance.
Dynamic Underwater Acoustic Channel Tracking for Correlated Rapidly Time-varying Channels
Mar 01, 2021
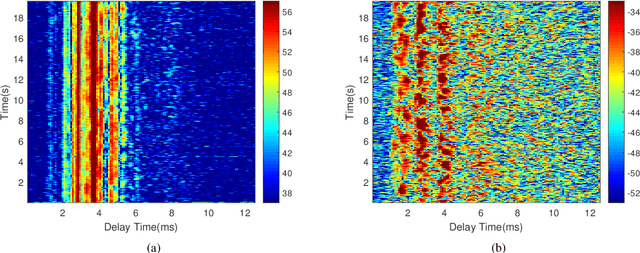
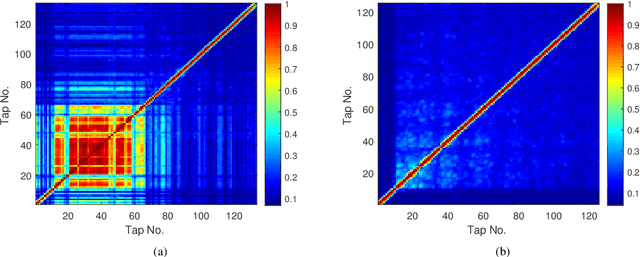
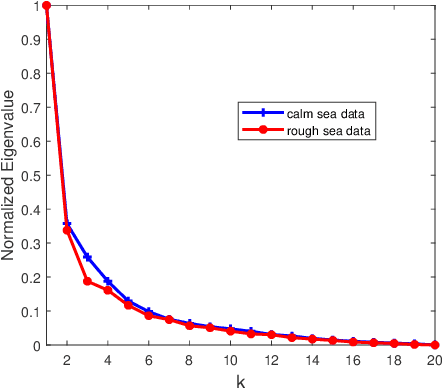
In this work, we focus on the model-mismatch problem for model-based subspace channel tracking in the correlated underwater acoustic channel. A model based on the underwater acoustic channel's correlation can be used as the state-space model in the Kalman filter to improve the underwater acoustic channel tracking compared that without a model. Even though the data support the assumption that the model is slow-varying and uncorrelated to some degree, to improve the tracking performance further, we can not ignore the model-mismatch problem because most channel models encounter this problem in the underwater acoustic channel. Therefore, in this work, we provide a dynamic time-variant state-space model for underwater acoustic channel tracking. This model is tolerant to the slight correlation after decorrelation. Moreover, a forward-backward Kalman filter is combined to further improve the tracking performance. The performance of our proposed algorithm is demonstrated with the same at-sea data as that used for conventional channel tracking. Compared with the conventional algorithms, the proposed algorithm shows significant improvement, especially in rough sea conditions in which the channels are fast-varying.
Tricks and Plugins to GBM on Images and Sequences
Mar 01, 2022
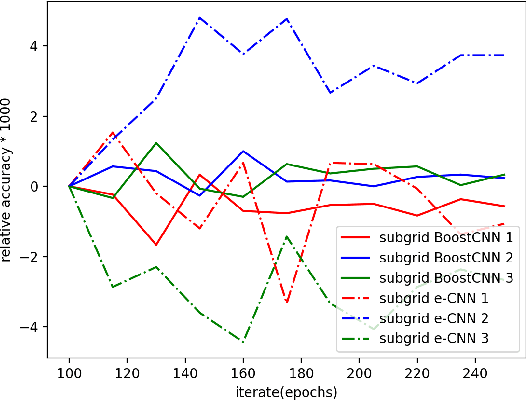

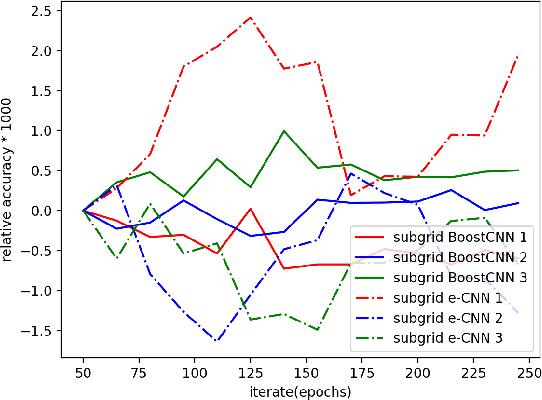
Convolutional neural networks (CNNs) and transformers, which are composed of multiple processing layers and blocks to learn the representations of data with multiple abstract levels, are the most successful machine learning models in recent years. However, millions of parameters and many blocks make them difficult to be trained, and sometimes several days or weeks are required to find an ideal architecture or tune the parameters. Within this paper, we propose a new algorithm for boosting Deep Convolutional Neural Networks (BoostCNN) to combine the merits of dynamic feature selection and BoostCNN, and another new family of algorithms combining boosting and transformers. To learn these new models, we introduce subgrid selection and importance sampling strategies and propose a set of algorithms to incorporate boosting weights into a deep learning architecture based on a least squares objective function. These algorithms not only reduce the required manual effort for finding an appropriate network architecture but also result in superior performance and lower running time. Experiments show that the proposed methods outperform benchmarks on several fine-grained classification tasks.
Meta Reinforcement Learning for Adaptive Control: An Offline Approach
Mar 17, 2022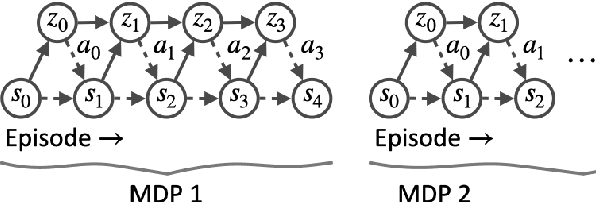
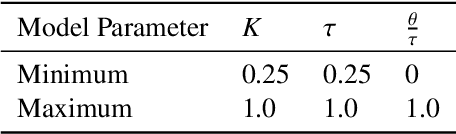
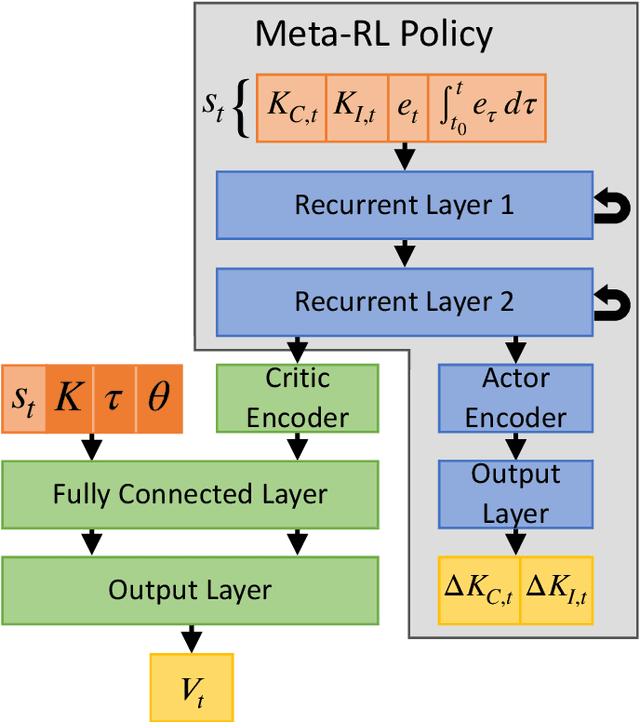
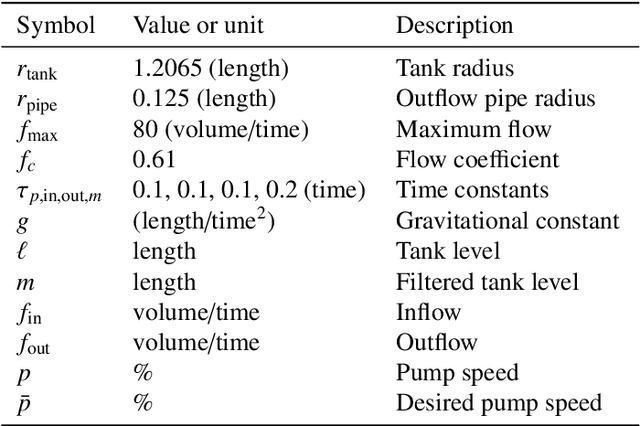
Meta-learning is a branch of machine learning which trains neural network models to synthesize a wide variety of data in order to rapidly solve new problems. In process control, many systems have similar and well-understood dynamics, which suggests it is feasible to create a generalizable controller through meta-learning. In this work, we formulate a meta reinforcement learning (meta-RL) control strategy that takes advantage of known, offline information for training, such as the system gain or time constant, yet efficiently controls novel systems in a completely model-free fashion. Our meta-RL agent has a recurrent structure that accumulates "context" for its current dynamics through a hidden state variable. This end-to-end architecture enables the agent to automatically adapt to changes in the process dynamics. Moreover, the same agent can be deployed on systems with previously unseen nonlinearities and timescales. In tests reported here, the meta-RL agent was trained entirely offline, yet produced excellent results in novel settings. A key design element is the ability to leverage model-based information offline during training, while maintaining a model-free policy structure for interacting with novel environments. To illustrate the approach, we take the actions proposed by the meta-RL agent to be changes to gains of a proportional-integral controller, resulting in a generalized, adaptive, closed-loop tuning strategy. Meta-learning is a promising approach for constructing sample-efficient intelligent controllers.
Deep Learning for Underwater Fish-Habitat Monitoring: A Survey
Mar 14, 2022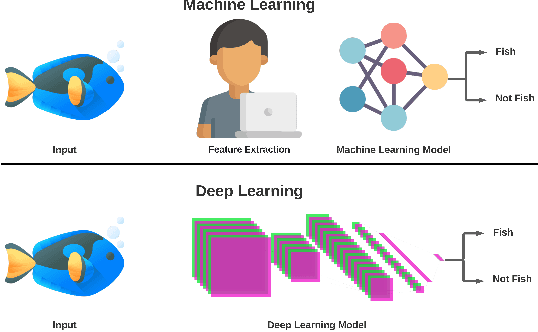
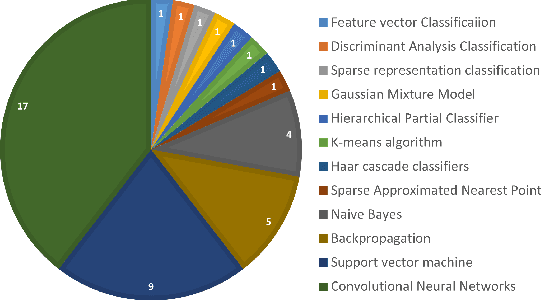
Marine scientists use remote underwater video recording to survey fish species in their natural habitats. This helps them understand and predict how fish respond to climate change, habitat degradation, and fishing pressure. This information is essential for developing sustainable fisheries for human consumption, and for preserving the environment. However, the enormous volume of collected videos makes extracting useful information a daunting and time-consuming task for a human. A promising method to address this problem is the cutting-edge Deep Learning (DL) technology.DL can help marine scientists parse large volumes of video promptly and efficiently, unlocking niche information that cannot be obtained using conventional manual monitoring methods. In this paper, we provide an overview of the key concepts of DL, while presenting a survey of literature on fish habitat monitoring with a focus on underwater fish classification. We also discuss the main challenges faced when developing DL for underwater image processing and propose approaches to address them. Finally, we provide insights into the marine habitat monitoring research domain and shed light on what the future of DL for underwater image processing may hold. This paper aims to inform a wide range of readers from marine scientists who would like to apply DL in their research to computer scientists who would like to survey state-of-the-art DL-based underwater fish habitat monitoring literature.
A Collision-Free MPC for Whole-Body Dynamic Locomotion and Manipulation
Feb 24, 2022
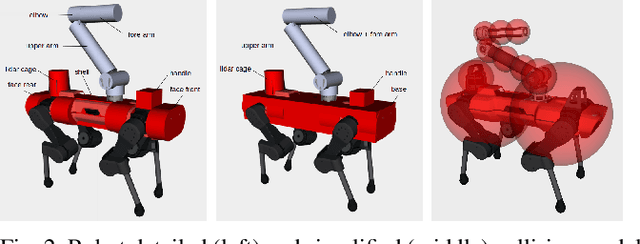


In this paper, we present a real-time whole-body planner for collision-free legged mobile manipulation. We enforce both self-collision and environment-collision avoidance as soft constraints within a Model Predictive Control (MPC) scheme that solves a multi-contact optimal control problem. By penalizing the signed distances among a set of representative primitive collision bodies, the robot is able to safely execute a variety of dynamic maneuvers while preventing any self-collisions. Moreover, collision-free navigation and manipulation in both static and dynamic environments are made viable through efficient queries of distances and their gradients via a euclidean signed distance field. We demonstrate through a comparative study that our approach only slightly increases the computational complexity of the MPC planning. Finally, we validate the effectiveness of our framework through a set of hardware experiments involving dynamic mobile manipulation tasks with potential collisions, such as locomotion balancing with the swinging arm, weight throwing, and autonomous door opening.
Balancing Consumer and Business Value of Recommender Systems: A Simulation-based Analysis
Mar 10, 2022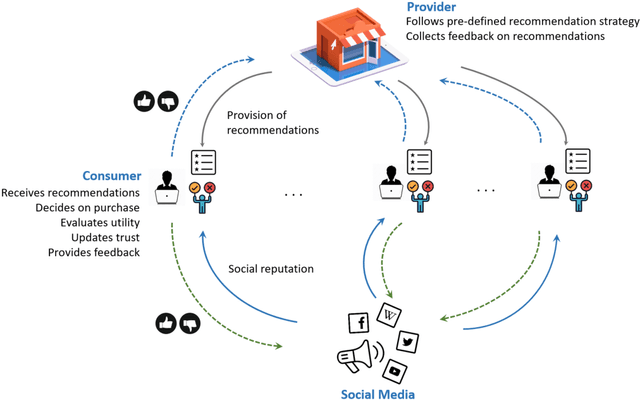

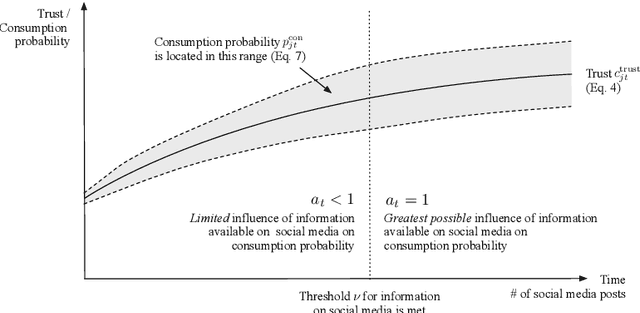
Automated recommendations can nowadays be found on many online platforms, and such recommendations can create substantial value for consumers and providers. Often, however, not all recommendable items have the same profit margin, and providers might thus be tempted to promote items that maximize their profit. In the short run, consumers might accept non-optimal recommendations, but they may lose their trust in the long run. Ultimately, this leads to the problem of designing balanced recommendation strategies, which consider both consumer and provider value and lead to sustained business success. This work proposes a simulation framework based on Agent-based Modeling designed to help providers explore longitudinal dynamics of different recommendation strategies. In our model, consumer agents receive recommendations from providers, and the perceived quality of the recommendations influences the consumers' trust over time. In addition, we consider network effects where positive and negative experiences are shared with others on social media. Simulations with our framework show that balanced strategies that consider both stakeholders indeed lead to stable consumer trust and sustained profitability. We also find that social media can reinforce phenomena like the loss of trust in the case of negative experiences. To ensure reproducibility and foster future research, we publicly share our flexible simulation framework.
Time-Series Regeneration with Convolutional Recurrent Generative Adversarial Network for Remaining Useful Life Estimation
Jan 11, 2021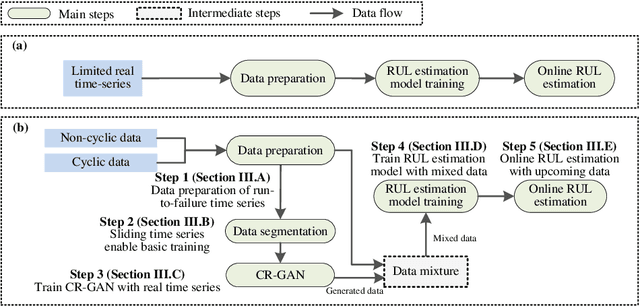
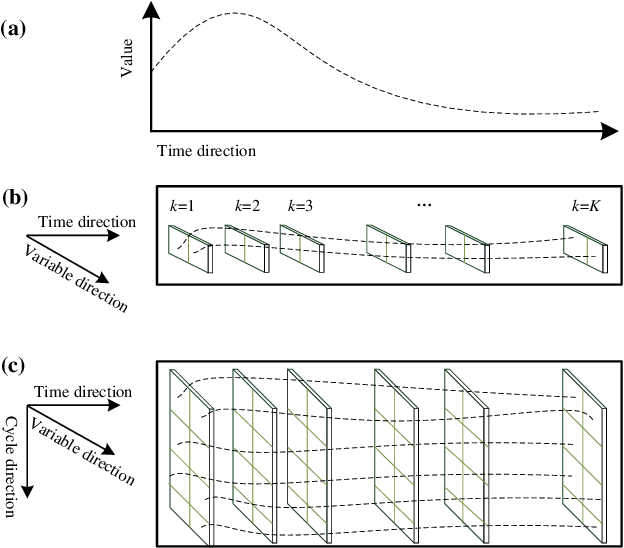
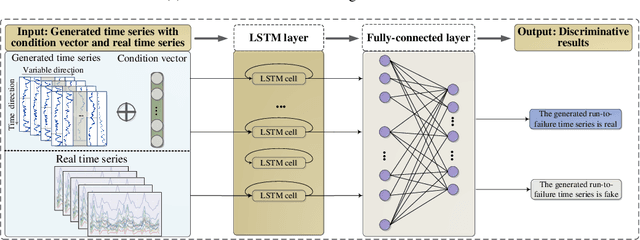
For health prognostic task, ever-increasing efforts have been focused on machine learning-based methods, which are capable of yielding accurate remaining useful life (RUL) estimation for industrial equipment or components without exploring the degradation mechanism. A prerequisite ensuring the success of these methods depends on a wealth of run-to-failure data, however, run-to-failure data may be insufficient in practice. That is, conducting a substantial amount of destructive experiments not only is high costs, but also may cause catastrophic consequences. Out of this consideration, an enhanced RUL framework focusing on data self-generation is put forward for both non-cyclic and cyclic degradation patterns for the first time. It is designed to enrich data from a data-driven way, generating realistic-like time-series to enhance current RUL methods. First, high-quality data generation is ensured through the proposed convolutional recurrent generative adversarial network (CR-GAN), which adopts a two-channel fusion convolutional recurrent neural network. Next, a hierarchical framework is proposed to combine generated data into current RUL estimation methods. Finally, the efficacy of the proposed method is verified through both non-cyclic and cyclic degradation systems. With the enhanced RUL framework, an aero-engine system following non-cyclic degradation has been tested using three typical RUL models. State-of-art RUL estimation results are achieved by enhancing capsule network with generated time-series. Specifically, estimation errors evaluated by the index score function have been reduced by 21.77%, and 32.67% for the two employed operating conditions, respectively. Besides, the estimation error is reduced to zero for the Lithium-ion battery system, which presents cyclic degradation.