 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HighMMT: Towards Modality and Task Generalization for High-Modality Representation Learning
Mar 04, 2022

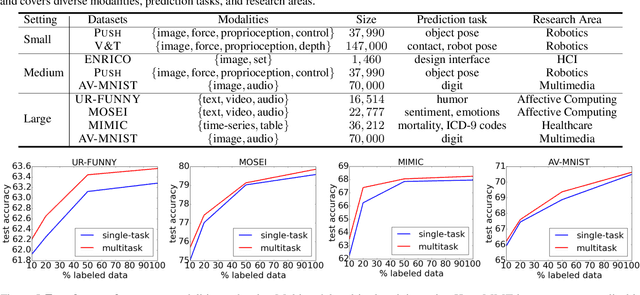
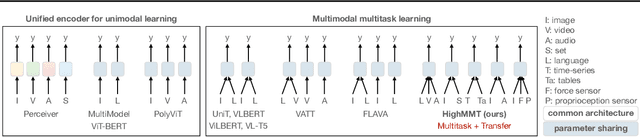
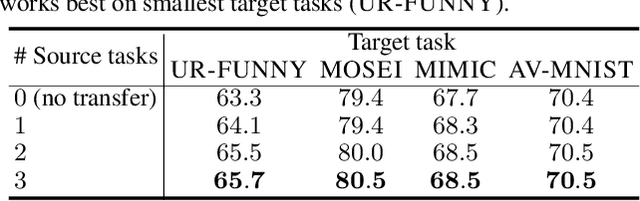
Learning multimodal representations involves discovering correspondences and integrating information from multiple heterogeneous sources of data. While recent research has begun to explore the design of more general-purpose multimodal models (contrary to prior focus on domain and modality-specific architectures), these methods are still largely focused on a small set of modalities in the language, vision, and audio space. In order to accelerate generalization towards diverse and understudied modalities, we investigate methods for high-modality (a large set of diverse modalities) and partially-observable (each task only defined on a small subset of modalities) scenarios. To tackle these challenges, we design a general multimodal model that enables multitask and transfer learning: multitask learning with shared parameters enables stable parameter counts (addressing scalability), and cross-modal transfer learning enables information sharing across modalities and tasks (addressing partial observability). Our resulting model generalizes across text, image, video, audio, time-series, sensors, tables, and set modalities from different research areas, improves the tradeoff between performance and efficiency, transfers to new modalities and tasks, and reveals surprising insights on the nature of information sharing in multitask models. We release our code and benchmarks which we hope will present a unified platform for subsequent theoretical and empirical analysis: https://github.com/pliang279/HighMMT.
There's no difference: Convolutional Neural Networks for transient detection without template subtraction
Mar 14, 2022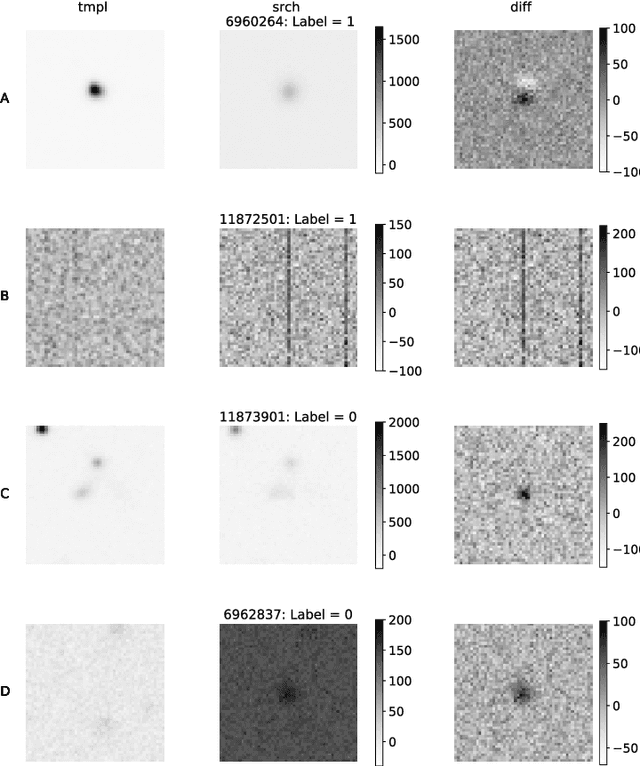
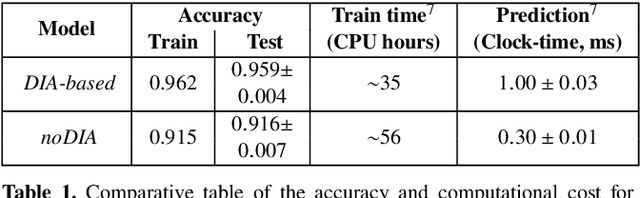

We present a Convolutional Neural Network (CNN) model for the separation of astrophysical transients from image artifacts, a task known as "real-bogus" classification, that does not rely on Difference Image Analysis (DIA) which is a computationally expensive process involving image matching on small spatial scales in large volumes of data. We explore the use of CNNs to (1) automate the "real-bogus" classification, (2) reduce the computational costs of transient discovery. We compare the efficiency of two CNNs with similar architectures, one that uses "image triplets" (templates, search, and the corresponding difference image) and one that adopts a similar architecture but takes as input the template and search only. Without substantially changing the model architecture or retuning the hyperparameters to the new input, we observe only a small decrease in model efficiency (97% to 92% accuracy). We further investigate how the model that does not receive the difference image learns the required information from the template and search by exploring the saliency maps. Our work demonstrates that (1) CNNs are excellent models for "real-bogus" classification that rely exclusively on the imaging data and require no feature engineering task; (2) high-accuracy models can be built without the need to construct difference images. Since once trained, neural networks can generate predictions at minimal computational costs, we argue that future implementations of this methodology could dramatically reduce the computational costs in the detection of genuine transients in synoptic surveys like Rubin Observatory's Legacy Survey of Space and Time by bypassing the DIA step entirely.
Multi-class granular approximation by means of disjoint and adjacent fuzzy granules
Feb 15, 2022
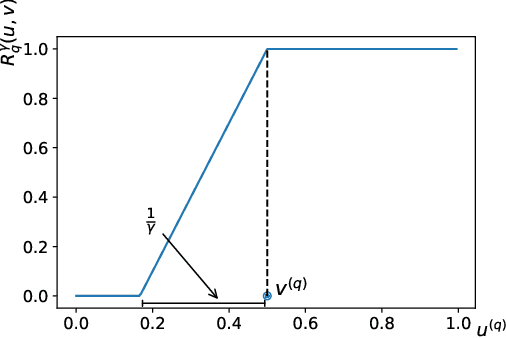
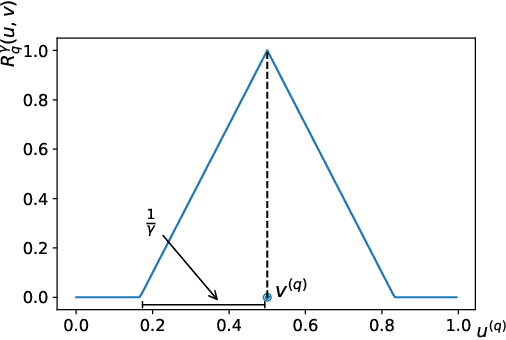
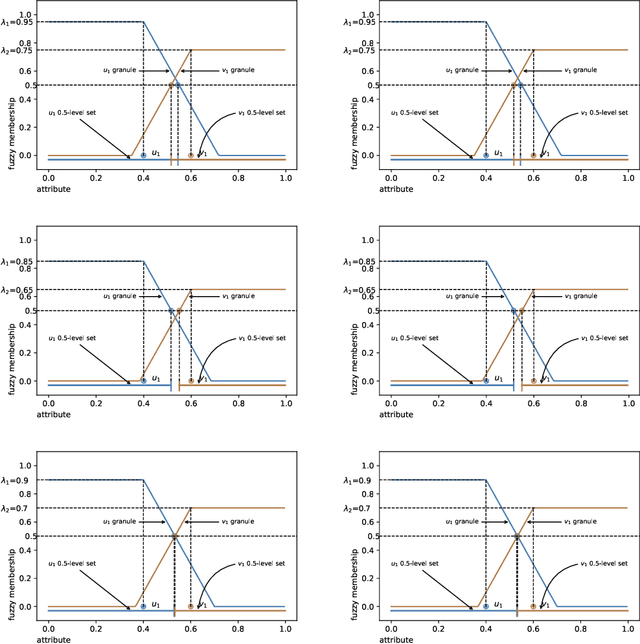
In granular computing, fuzzy sets can be approximated by granularly representable sets that are as close as possible to the original fuzzy set w.r.t. a given closeness measure. Such sets are called granular approximations. In this article, we introduce the concepts of disjoint and adjacent granules and we examine how the new definitions affect the granular approximations. First, we show that the new concepts are important for binary classification problems since they help to keep decision regions separated (disjoint granules) and at the same time to cover as much as possible of the attribute space (adjacent granules). Later, we consider granular approximations for multi-class classification problems leading to the definition of a multi-class granular approximation. Finally, we show how to efficiently calculate multi-class granular approximations for {\L}ukasiewicz fuzzy connectives. We also provide graphical illustrations for a better understanding of the introduced concepts.
Interpretable Super-Resolution via a Learned Time-Series Representation
Jun 13, 2020
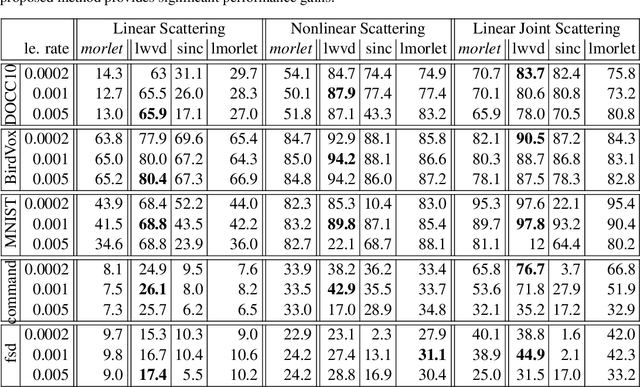
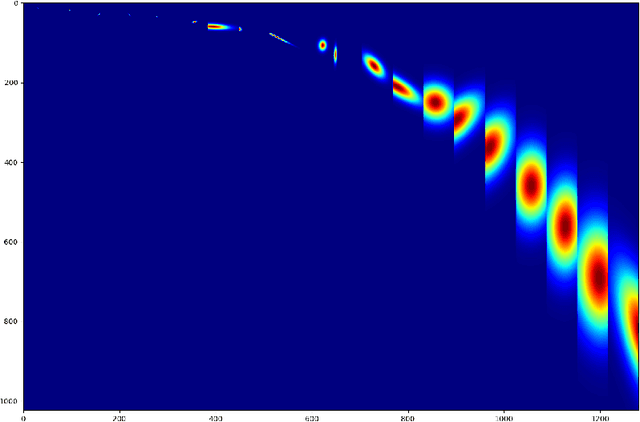

We develop an interpretable and learnable Wigner-Ville distribution that produces a super-resolved quadratic signal representation for time-series analysis. Our approach has two main hallmarks. First, it interpolates between known time-frequency representations (TFRs) in that it can reach super-resolution with increased time and frequency resolution beyond what the Heisenberg uncertainty principle prescribes and thus beyond commonly employed TFRs, Second, it is interpretable thanks to an explicit low-dimensional and physical parameterization of the Wigner-Ville distribution. We demonstrate that our approach is able to learn highly adapted TFRs and is ready and able to tackle various large-scale classification tasks, where we reach state-of-the-art performance compared to baseline and learned TFRs.
Audio-visual Generalised Zero-shot Learning with Cross-modal Attention and Language
Mar 07, 2022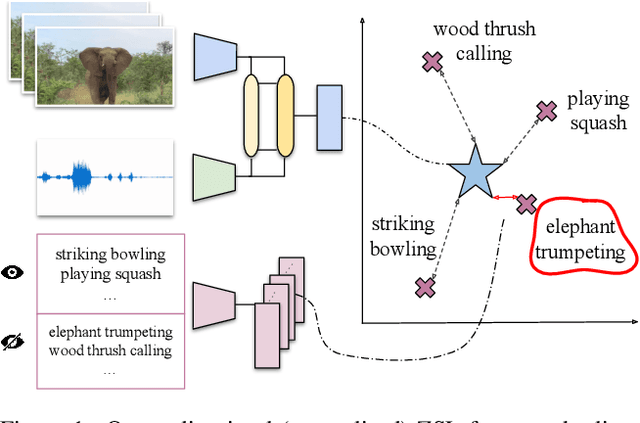
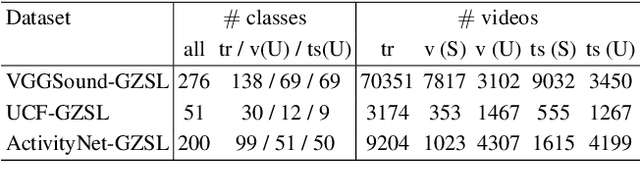
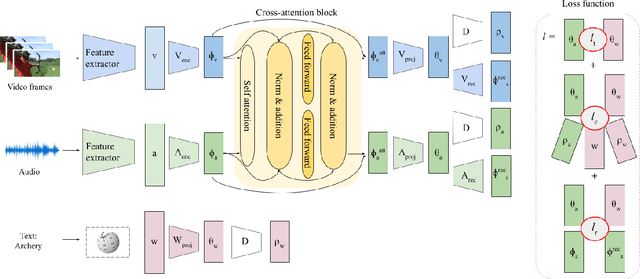
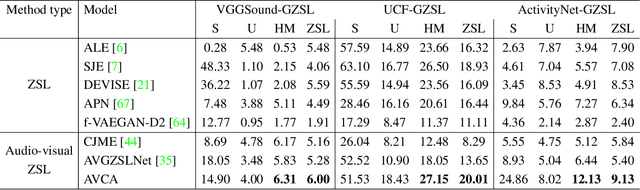
Learning to classify video data from classes not included in the training data, i.e. video-based zero-shot learning, is challenging. We conjecture that the natural alignment between the audio and visual modalities in video data provides a rich training signal for learning discriminative multi-modal representations. Focusing on the relatively underexplored task of audio-visual zero-shot learning, we propose to learn multi-modal representations from audio-visual data using cross-modal attention and exploit textual label embeddings for transferring knowledge from seen classes to unseen classes. Taking this one step further, in our generalised audio-visual zero-shot learning setting, we include all the training classes in the test-time search space which act as distractors and increase the difficulty while making the setting more realistic. Due to the lack of a unified benchmark in this domain, we introduce a (generalised) zero-shot learning benchmark on three audio-visual datasets of varying sizes and difficulty, VGGSound, UCF, and ActivityNet, ensuring that the unseen test classes do not appear in the dataset used for supervised training of the backbone deep models. Comparing multiple relevant and recent methods, we demonstrate that our proposed AVCA model achieves state-of-the-art performance on all three datasets. Code and data will be available at \url{https://github.com/ExplainableML/AVCA-GZSL}.
The Frost Hollow Experiments: Pavlovian Signalling as a Path to Coordination and Communication Between Agents
Mar 17, 2022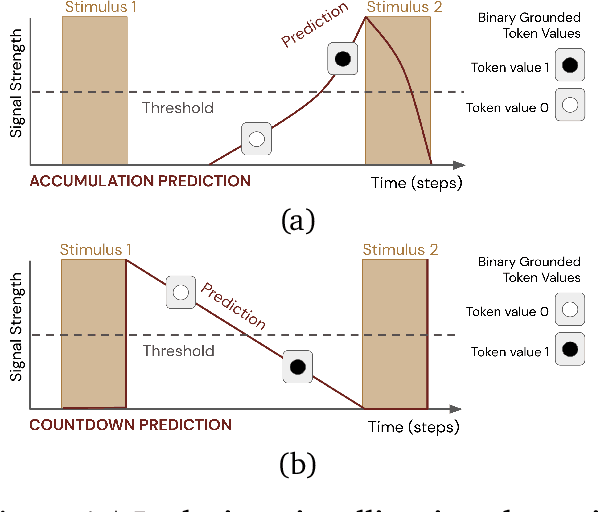

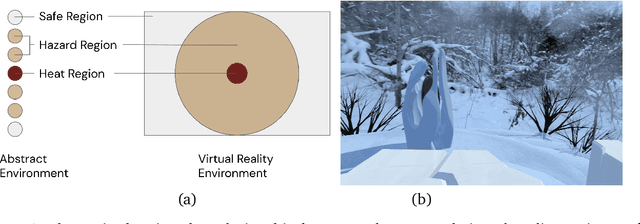
Learned communication between agents is a powerful tool when approaching decision-making problems that are hard to overcome by any single agent in isolation. However, continual coordination and communication learning between machine agents or human-machine partnerships remains a challenging open problem. As a stepping stone toward solving the continual communication learning problem, in this paper we contribute a multi-faceted study into what we term Pavlovian signalling -- a process by which learned, temporally extended predictions made by one agent inform decision-making by another agent with different perceptual access to their shared environment. We seek to establish how different temporal processes and representational choices impact Pavlovian signalling between learning agents. To do so, we introduce a partially observable decision-making domain we call the Frost Hollow. In this domain a prediction learning agent and a reinforcement learning agent are coupled into a two-part decision-making system that seeks to acquire sparse reward while avoiding time-conditional hazards. We evaluate two domain variations: 1) machine prediction and control learning in a linear walk, and 2) a prediction learning machine interacting with a human participant in a virtual reality environment. Our results showcase the speed of learning for Pavlovian signalling, the impact that different temporal representations do (and do not) have on agent-agent coordination, and how temporal aliasing impacts agent-agent and human-agent interactions differently. As a main contribution, we establish Pavlovian signalling as a natural bridge between fixed signalling paradigms and fully adaptive communication learning. Our results therefore point to an actionable, constructivist path towards continual communication learning between reinforcement learning agents, with potential impact in a range of real-world settings.
ReGNL: Rapid Prediction of GDP during Disruptive Events using Nightlights
Jan 19, 2022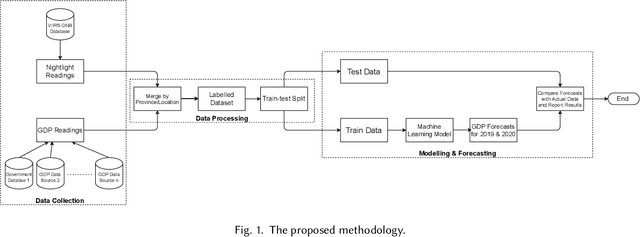

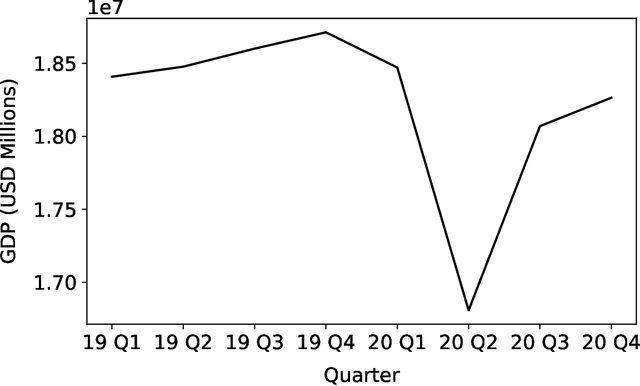
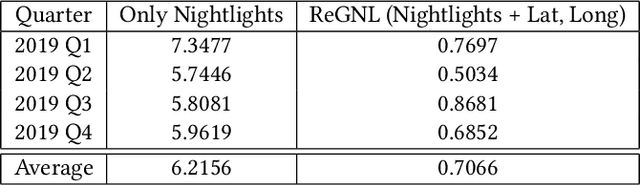
Policy makers often make decisions based on parameters such as GDP, unemployment rate, industrial output, etc. The primary methods to obtain or even estimate such information are resource intensive and time consuming. In order to make timely and well-informed decisions, it is imperative to be able to come up with proxies for these parameters which can be sampled quickly and efficiently, especially during disruptive events, like the COVID-19 pandemic. Recently, there has been a lot of focus on using remote sensing data for this purpose. The data has become cheaper to collect compared to surveys, and can be available in real time. In this work, we present Regional GDP NightLight (ReGNL), a neural network based model which is trained on a custom dataset of historical nightlights and GDP data along with the geographical coordinates of a place, and estimates the GDP of the place, given the other parameters. Taking the case of 50 US states, we find that ReGNL is disruption-agnostic and is able to predict the GDP for both normal years (2019) and for years with a disruptive event (2020). ReGNL outperforms timeseries ARIMA methods for prediction, even during the pandemic. Following from our findings, we make a case for building infrastructures to collect and make available granular data, especially in resource-poor geographies, so that these can be leveraged for policy making during disruptive events.
On Dynamic Pricing with Covariates
Jan 19, 2022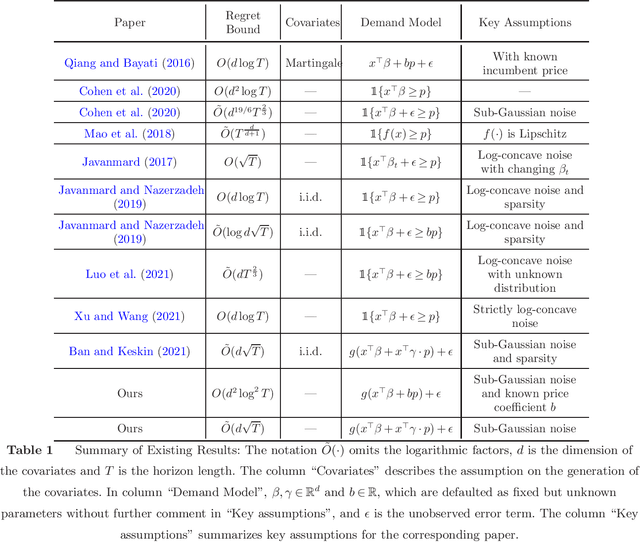
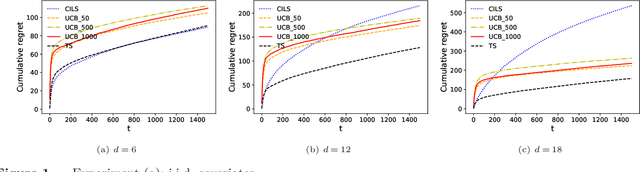
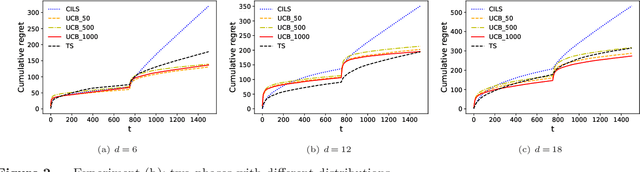
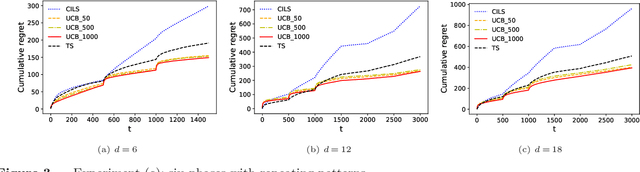
We consider the dynamic pricing problem with covariates under a generalized linear demand model: a seller can dynamically adjust the price of a product over a horizon of $T$ time periods, and at each time period $t$, the demand of the product is jointly determined by the price and an observable covariate vector $x_t\in\mathbb{R}^d$ through an unknown generalized linear model. Most of the existing literature assumes the covariate vectors $x_t$'s are independently and identically distributed (i.i.d.); the few papers that relax this assumption either sacrifice model generality or yield sub-optimal regret bounds. In this paper we show that a simple pricing algorithm has an $O(d\sqrt{T}\log T)$ regret upper bound without assuming any statistical structure on the covariates $x_t$ (which can even be arbitrarily chosen). The upper bound on the regret matches the lower bound (even under the i.i.d. assumption) up to logarithmic factors. Our paper thus shows that (i) the i.i.d. assumption is not necessary for obtaining low regret, and (ii) the regret bound can be independent of the (inverse) minimum eigenvalue of the covariance matrix of the $x_t$'s, a quantity present in previous bounds. Furthermore, we discuss a condition under which a better regret is achievable and how a Thompson sampling algorithm can be applied to give an efficient computation of the prices.
DARL1N: Distributed multi-Agent Reinforcement Learning with One-hop Neighbors
Feb 18, 2022



Most existing multi-agent reinforcement learning (MARL) methods are limited in the scale of problems they can handle. Particularly, with the increase of the number of agents, their training costs grow exponentially. In this paper, we address this limitation by introducing a scalable MARL method called Distributed multi-Agent Reinforcement Learning with One-hop Neighbors (DARL1N). DARL1N is an off-policy actor-critic method that breaks the curse of dimensionality by decoupling the global interactions among agents and restricting information exchanges to one-hop neighbors. Each agent optimizes its action value and policy functions over a one-hop neighborhood, significantly reducing the learning complexity, yet maintaining expressiveness by training with varying numbers and states of neighbors. This structure allows us to formulate a distributed learning framework to further speed up the training procedure. Comparisons with state-of-the-art MARL methods show that DARL1N significantly reduces training time without sacrificing policy quality and is scalable as the number of agents increases.
6D Pose Estimation with Combined Deep Learning and 3D Vision Techniques for a Fast and Accurate Object Grasping
Nov 11, 2021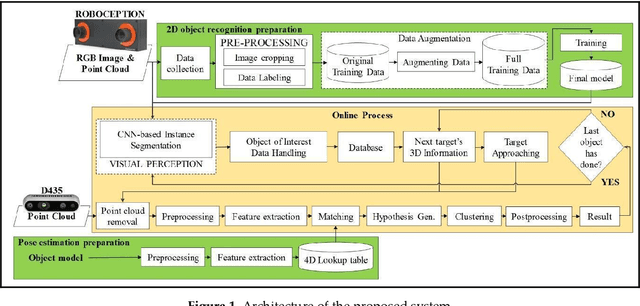
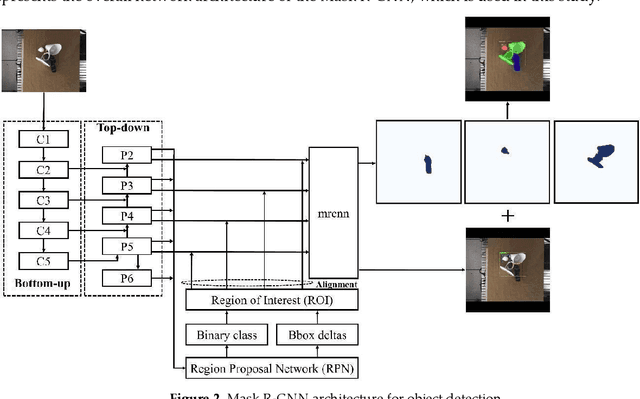
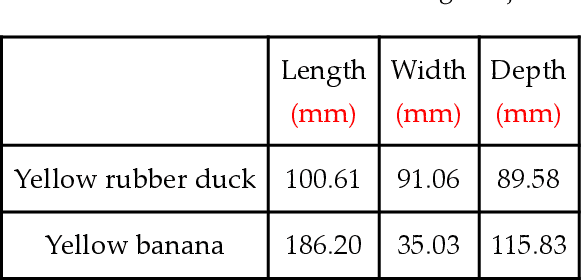
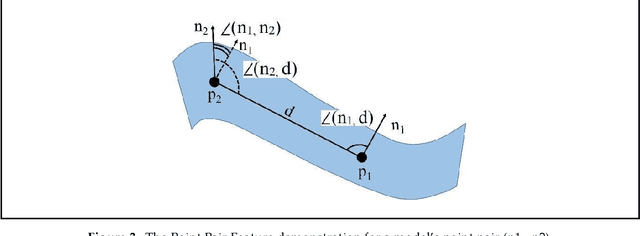
Real-time robotic grasping, supporting a subsequent precise object-in-hand operation task, is a priority target towards highly advanced autonomous systems. However, such an algorithm which can perform sufficiently-accurate grasping with time efficiency is yet to be found. This paper proposes a novel method with a 2-stage approach that combines a fast 2D object recognition using a deep neural network and a subsequent accurate and fast 6D pose estimation based on Point Pair Feature framework to form a real-time 3D object recognition and grasping solution capable of multi-object class scenes. The proposed solution has a potential to perform robustly on real-time applications, requiring both efficiency and accuracy. In order to validate our method, we conducted extensive and thorough experiments involving laborious preparation of our own dataset. The experiment results show that the proposed method scores 97.37% accuracy in 5cm5deg metric and 99.37% in Average Distance metric. Experiment results have shown an overall 62% relative improvement (5cm5deg metric) and 52.48% (Average Distance metric) by using the proposed method. Moreover, the pose estimation execution also showed an average improvement of 47.6% in running time. Finally, to illustrate the overall efficiency of the system in real-time operations, a pick-and-place robotic experiment is conducted and has shown a convincing success rate with 90% of accuracy. This experiment video is available at https://sites.google.com/view/dl-ppf6dpose/.