 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Passive and Active Learning of Driver Behavior from Electric Vehicles
Mar 04, 2022
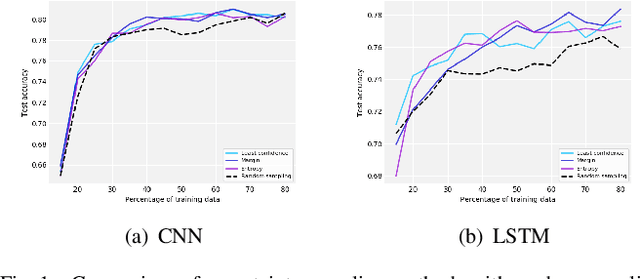
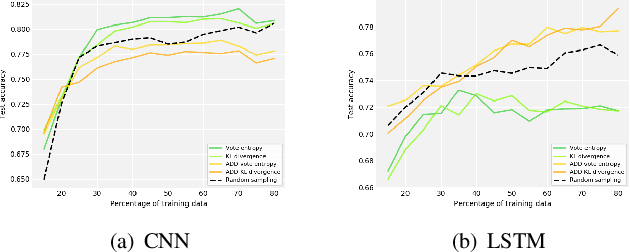
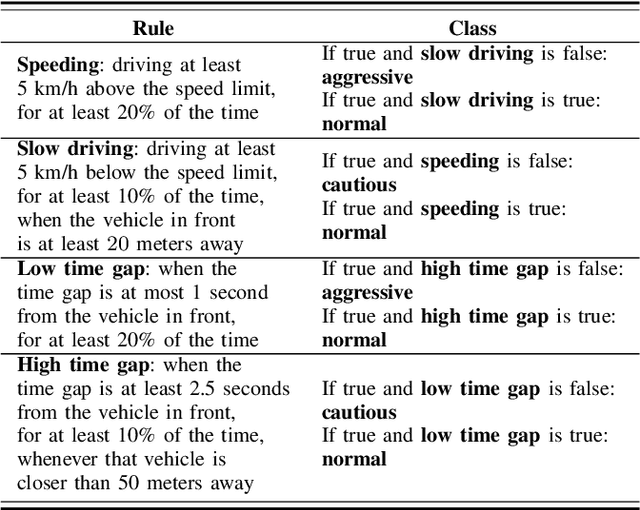
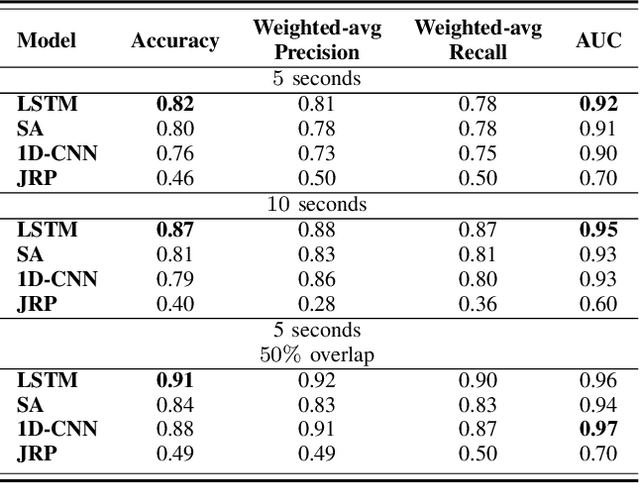
Modeling driver behavior provides several advantages in the automotive industry, including prediction of electric vehicle energy consumption. Studies have shown that aggressive driving can consume up to 30% more energy than moderate driving, in certain driving scenarios. Machine learning methods are widely used for driver behavior classification, which, however, may yield some challenges such as sequence modeling on long time windows and lack of labeled data due to expensive annotation. To address the first challenge, passive learning of driver behavior, we investigate non-recurrent architectures such as self-attention models and convolutional neural networks with joint recurrence plots (JRP), and compare them with recurrent models. We find that self-attention models yield good performance, while JRP does not exhibit any significant improvement. However, with the window lengths of 5 and 10 seconds used in our study, none of the non-recurrent models outperform the recurrent models. To address the second challenge, we investigate several active learning methods with different informativeness measures. We evaluate uncertainty sampling, as well as more advanced methods, such as query by committee and active deep dropout. Our experiments demonstrate that some active sampling techniques can outperform random sampling, and therefore decrease the effort needed for annotation.
Can machines solve general queueing systems?
Feb 03, 2022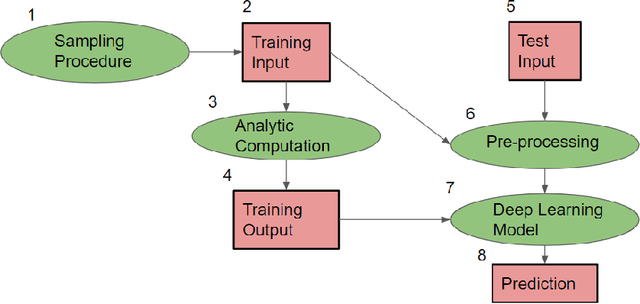
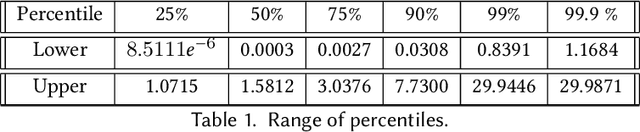
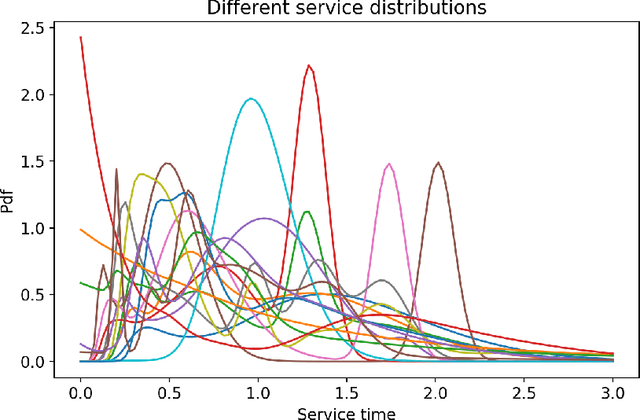

In this paper, we analyze how well a machine can solve a general problem in queueing theory. To answer this question, we use a deep learning model to predict the stationary queue-length distribution of an $M/G/1$ queue (Poisson arrivals, general service times, one server). To the best of our knowledge, this is the first time a machine learning model is applied to a general queueing theory problem. We chose $M/G/1$ queue for this paper because it lies "on the cusp" of the analytical frontier: on the one hand exact solution for this model is available, which is both computationally and mathematically complex. On the other hand, the problem (specifically the service time distribution) is general. This allows us to compare the accuracy and efficiency of the deep learning approach to the analytical solutions. The two key challenges in applying machine learning to this problem are (1) generating a diverse set of training examples that provide a good representation of a "generic" positive-valued distribution, and (2) representations of the continuous distribution of service times as an input. We show how we overcome these challenges. Our results show that our model is indeed able to predict the stationary behavior of the $M/G/1$ queue extremely accurately: the average value of our metric over the entire test set is $0.0009$. Moreover, our machine learning model is very efficient, computing very accurate stationary distributions in a fraction of a second (an approach based on simulation modeling would take much longer to converge). We also present a case-study that mimics a real-life setting and shows that our approach is more robust and provides more accurate solutions compared to the existing methods. This shows the promise of extending our approach beyond the analytically solvable systems (e.g., $G/G/1$ or $G/G/c$).
Exploring Structural Sparsity in Neural Image Compression
Feb 10, 2022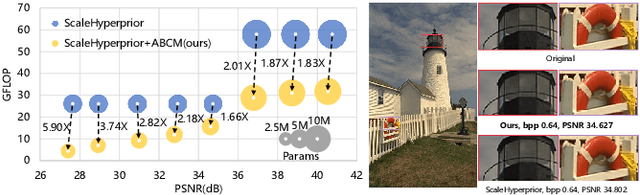
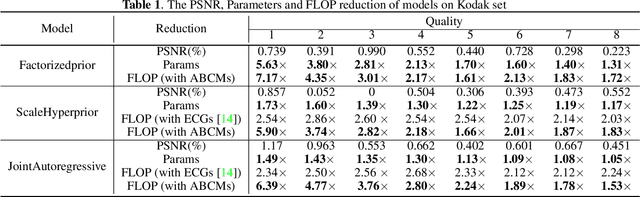
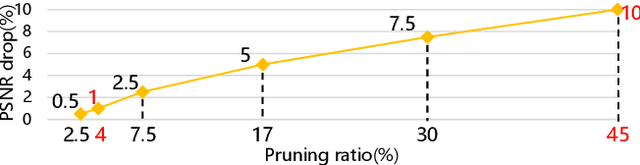

Neural image compression have reached or out-performed traditional methods (such as JPEG, BPG, WebP). However,their sophisticated network structures with cascaded convolution layers bring heavy computational burden for practical deployment. In this paper, we explore the structural sparsity in neural image compression network to obtain real-time acceleration without any specialized hardware design or algorithm. We propose a simple plug-in adaptive binary channel masking(ABCM) to judge the importance of each convolution channel and introduce sparsity during training. During inference, the unimportant channels are pruned to obtain slimmer network and less computation. We implement our method into three neural image compression networks with different entropy models to verify its effectiveness and generalization, the experiment results show that up to 7x computation reduction and 3x acceleration can be achieved with negligible performance drop.
An Empirical Survey of Data Augmentation for Time Series Classification with Neural Networks
Jul 31, 2020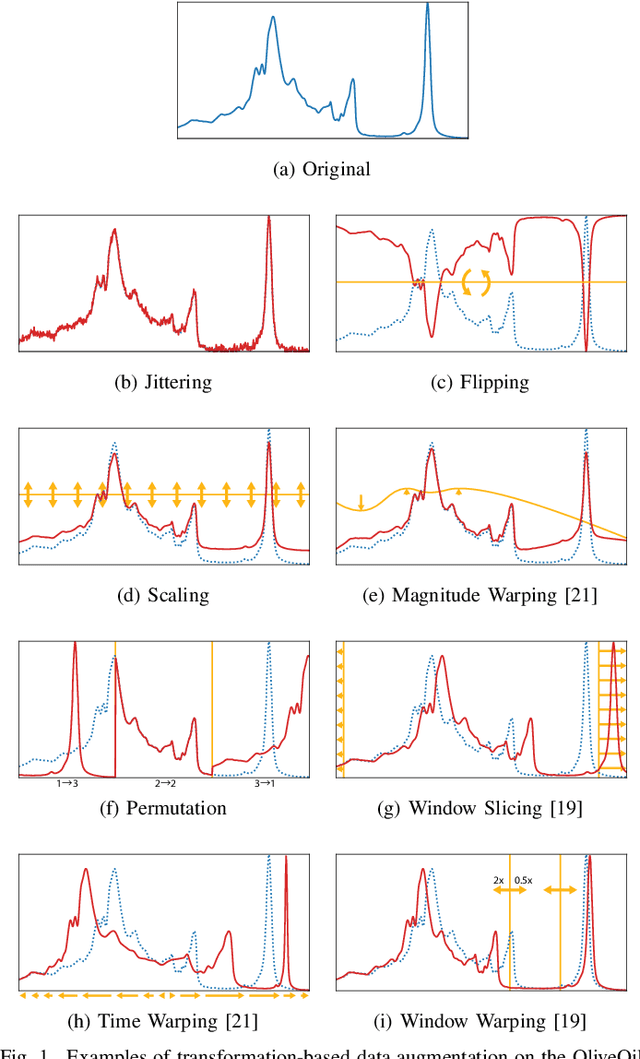
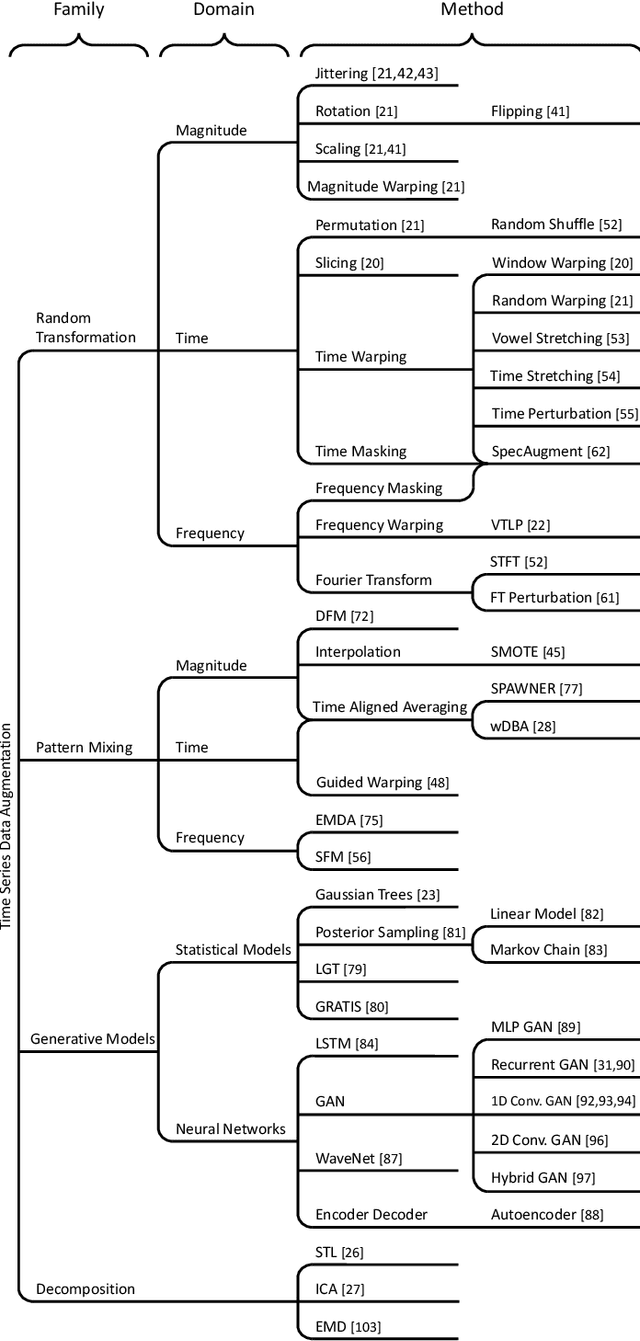
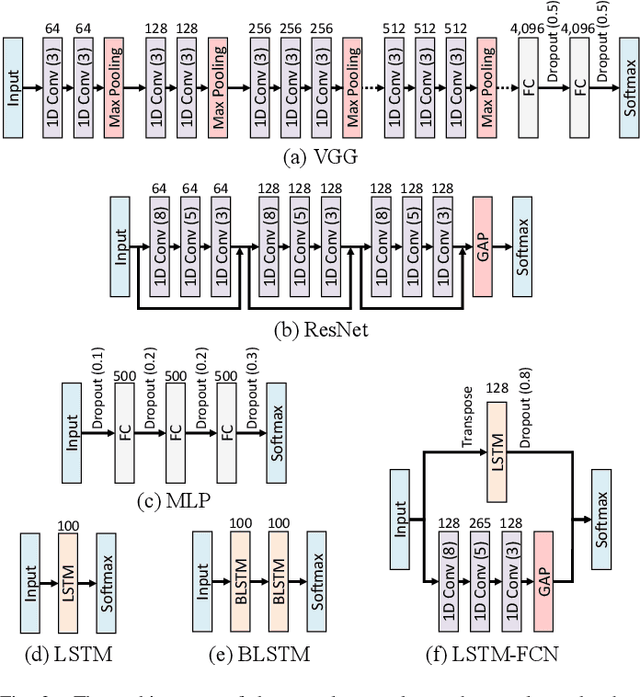
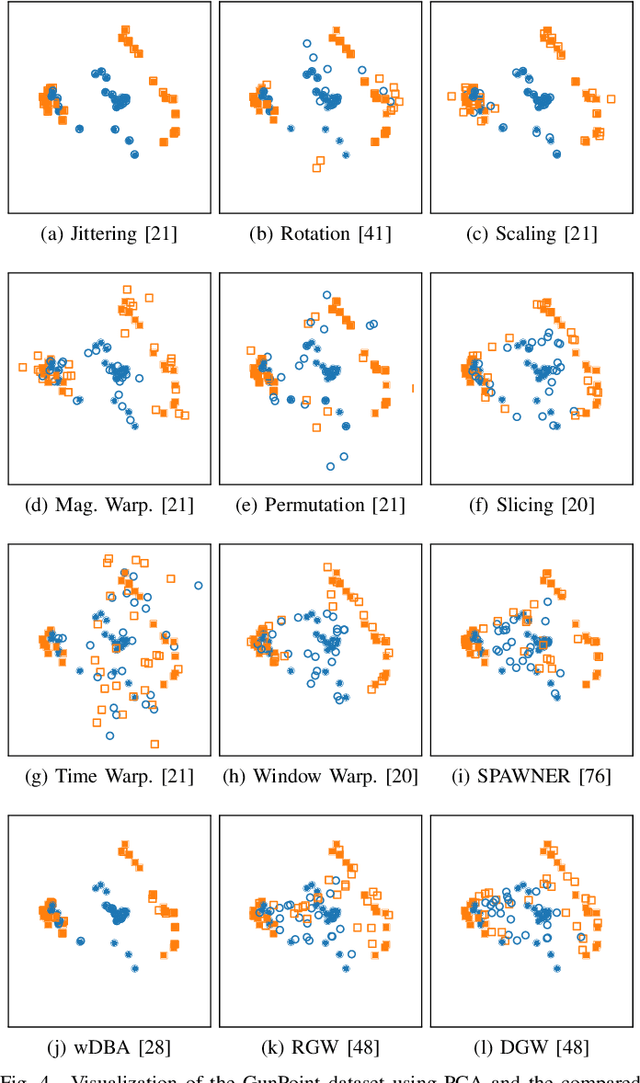
In recent times, deep artificial neural networks have achieved many successes in pattern recognition. Part of this success is the reliance on big data to increase generalization. However, in the field of time series recognition, many datasets are often very small. One method of addressing this problem is through the use of data augmentation. In this paper, we survey data augmentation techniques for time series and their application to time series classification with neural networks. We outline four families of time series data augmentation, including transformation-based methods, pattern mixing, generative models, and decomposition methods, and detail their taxonomy. Furthermore, we empirically evaluate 12 time series data augmentation methods on 128 time series classification datasets with 6 different types of neural networks. Through the results, we are able to analyze the characteristics, advantages and disadvantages, and recommendations of each data augmentation method. This survey aims to help in the selection of time series data augmentation for neural network applications.
Convolutional-Recurrent Neural Network Proxy for Robust Optimization and Closed-Loop Reservoir Management
Mar 14, 2022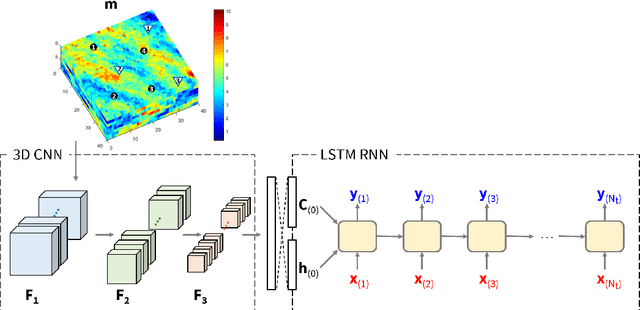

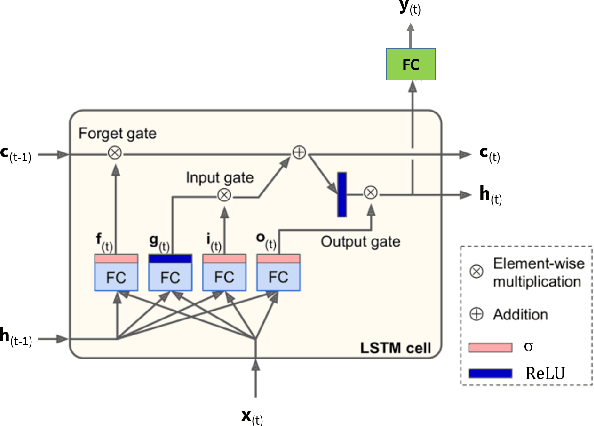
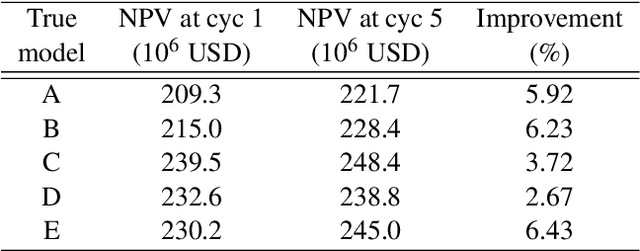
Production optimization under geological uncertainty is computationally expensive, as a large number of well control schedules must be evaluated over multiple geological realizations. In this work, a convolutional-recurrent neural network (CNN-RNN) proxy model is developed to predict well-by-well oil and water rates, for given time-varying well bottom-hole pressure (BHP) schedules, for each realization in an ensemble. This capability enables the estimation of the objective function and nonlinear constraint values required for robust optimization. The proxy model represents an extension of a recently developed long short-term memory (LSTM) RNN proxy designed to predict well rates for a single geomodel. A CNN is introduced here to processes permeability realizations, and this provides the initial states for the RNN. The CNN-RNN proxy is trained using simulation results for 300 different sets of BHP schedules and permeability realizations. We demonstrate proxy accuracy for oil-water flow through multiple realizations of 3D multi-Gaussian permeability models. The proxy is then incorporated into a closed-loop reservoir management (CLRM) workflow, where it is used with particle swarm optimization and a filter-based method for nonlinear constraint satisfaction. History matching is achieved using an adjoint-gradient-based procedure. The proxy model is shown to perform well in this setting for five different (synthetic) `true' models. Improved net present value along with constraint satisfaction and uncertainty reduction are observed with CLRM. For the robust production optimization steps, the proxy provides O(100) runtime speedup over simulation-based optimization.
Achieving Reliable Human Assessment of Open-Domain Dialogue Systems
Mar 11, 2022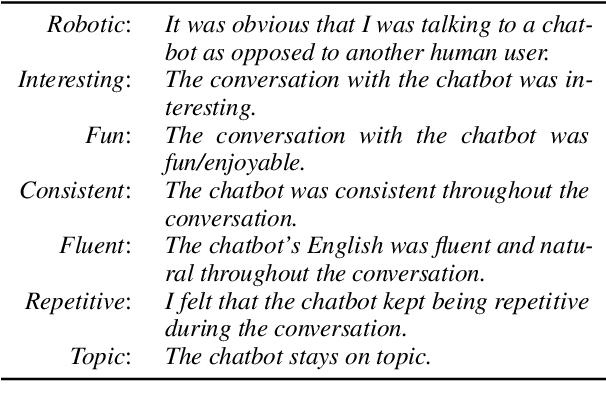

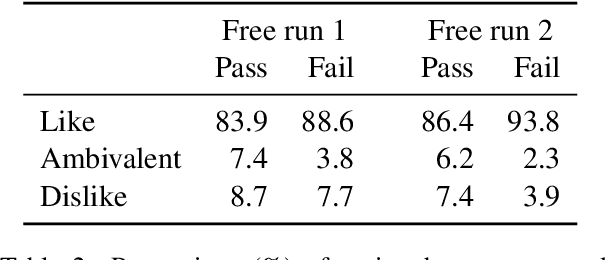
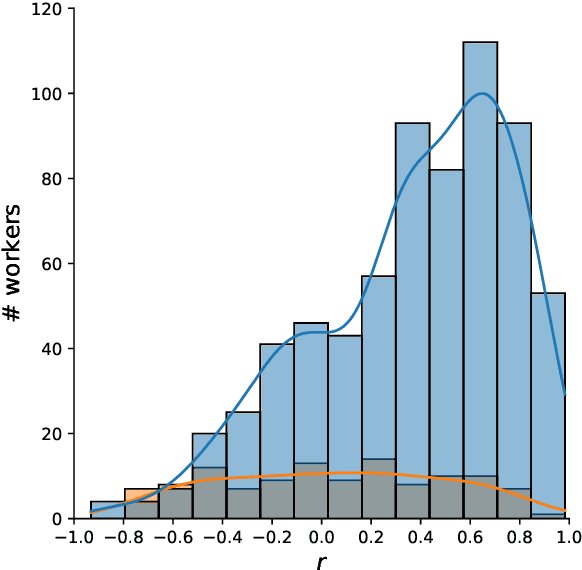
Evaluation of open-domain dialogue systems is highly challenging and development of better techniques is highlighted time and again as desperately needed. Despite substantial efforts to carry out reliable live evaluation of systems in recent competitions, annotations have been abandoned and reported as too unreliable to yield sensible results. This is a serious problem since automatic metrics are not known to provide a good indication of what may or may not be a high-quality conversation. Answering the distress call of competitions that have emphasized the urgent need for better evaluation techniques in dialogue, we present the successful development of human evaluation that is highly reliable while still remaining feasible and low cost. Self-replication experiments reveal almost perfectly repeatable results with a correlation of $r=0.969$. Furthermore, due to the lack of appropriate methods of statistical significance testing, the likelihood of potential improvements to systems occurring due to chance is rarely taken into account in dialogue evaluation, and the evaluation we propose facilitates application of standard tests. Since we have developed a highly reliable evaluation method, new insights into system performance can be revealed. We therefore include a comparison of state-of-the-art models (i) with and without personas, to measure the contribution of personas to conversation quality, as well as (ii) prescribed versus freely chosen topics. Interestingly with respect to personas, results indicate that personas do not positively contribute to conversation quality as expected.
BEATS: An Open-Source, High-Precision, Multi-Channel EEG Acquisition Tool System
Mar 04, 2022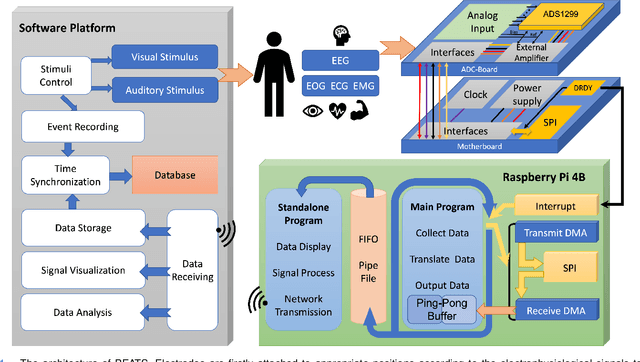
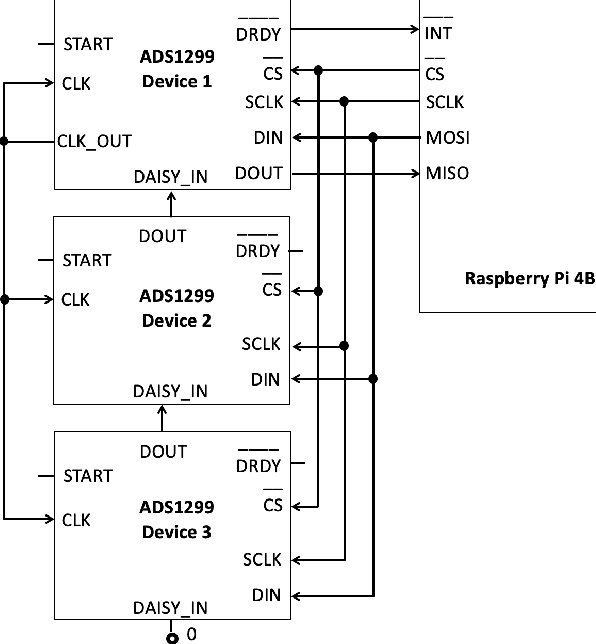

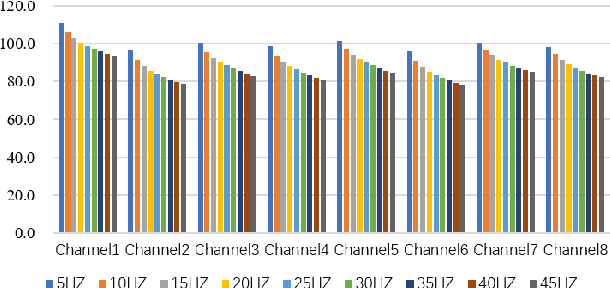
Stable and accurate electroencephalogram (EEG) signal acquisition is fundamental in non-invasive brain-computer interface (BCI) technology. Commonly used EEG acquisition system's hardware and software are usually closed-source. Its inability to flexible expansion and secondary development is a major obstacle to real-time BCI research. This paper presents an open-source, high-precision, multi-channel EEG Acquisition Tool System developed by Beijing University of Posts and Telecommunications named BEATS. It implements a comprehensive system from hardware to software, composes of analog front-end, microprocessor, and software platform. BEATS is capable of collecting multi-channel micro-volt EEG signals up to 4000 $Hz$ with wireless transmission. And it adopts a pluggable structure and easy-to-access materials, which can easily support rapid prototyping, portability, and scalability. Some underlying techniques like direct memory access, interrupt, first in first out are used to ensure the precision and stability of the program at the microsecond level. Compared to state-of-the-art systems, BEATS maintains a relatively high channel number when acquiring data at a high sampling rate, while being quick to set up and use, making it ideal for a wide range of BCI scenarios or long-term daily monitoring. Schematics, source code, and other materials of BEATS are available at https://github.com/bingzant/BEATS.
Efficient computation of the volume of a polytope in high-dimensions using Piecewise Deterministic Markov Processes
Feb 18, 2022
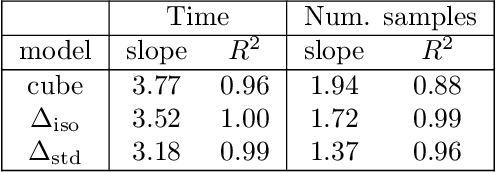
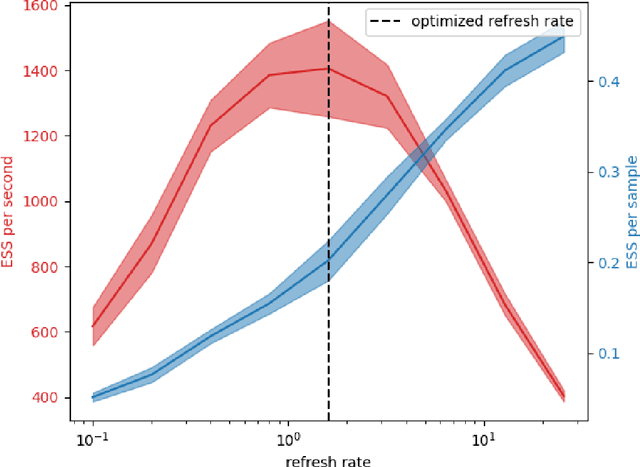
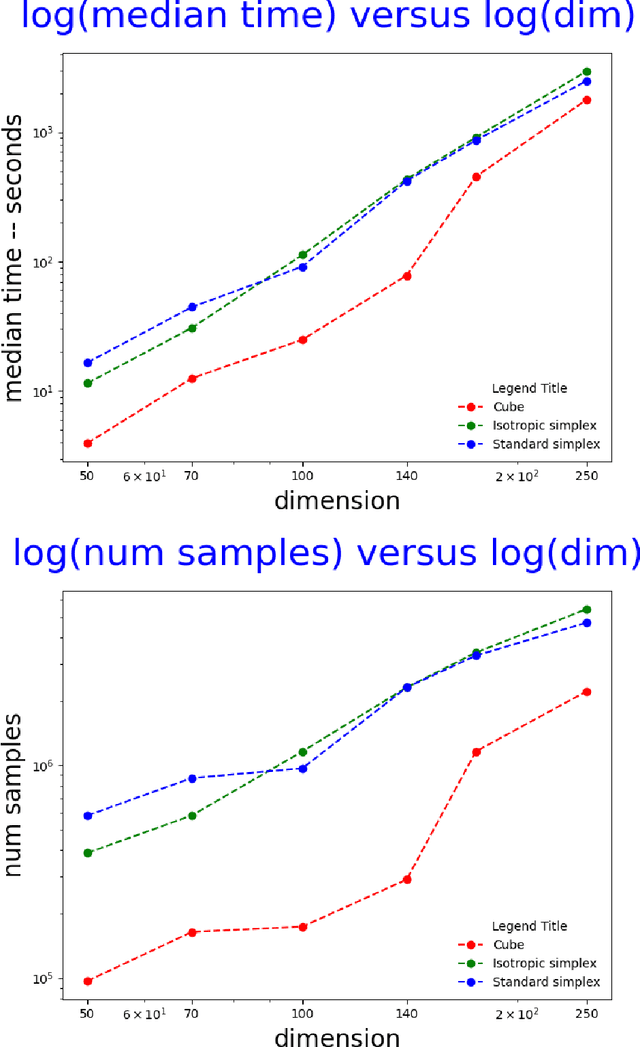
Computing the volume of a polytope in high dimensions is computationally challenging but has wide applications. Current state-of-the-art algorithms to compute such volumes rely on efficient sampling of a Gaussian distribution restricted to the polytope, using e.g. Hamiltonian Monte Carlo. We present a new sampling strategy that uses a Piecewise Deterministic Markov Process. Like Hamiltonian Monte Carlo, this new method involves simulating trajectories of a non-reversible process and inherits similar good mixing properties. However, importantly, the process can be simulated more easily due to its piecewise linear trajectories - and this leads to a reduction of the computational cost by a factor of the dimension of the space. Our experiments indicate that our method is numerically robust and is one order of magnitude faster (or better) than existing methods using Hamiltonian Monte Carlo. On a single core processor, we report computational time of a few minutes up to dimension 500.
PageRank Algorithm using Eigenvector Centrality -- New Approach
Jan 18, 2022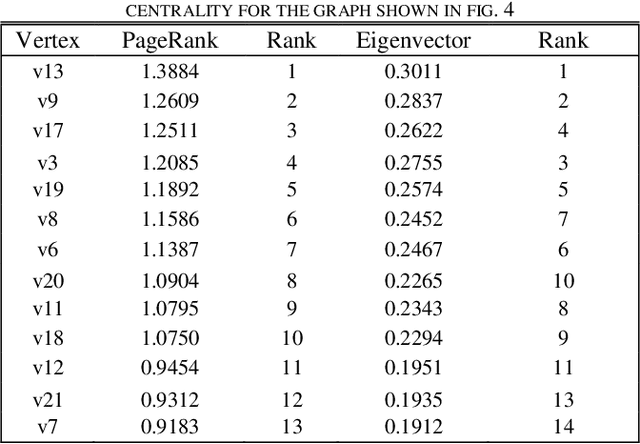
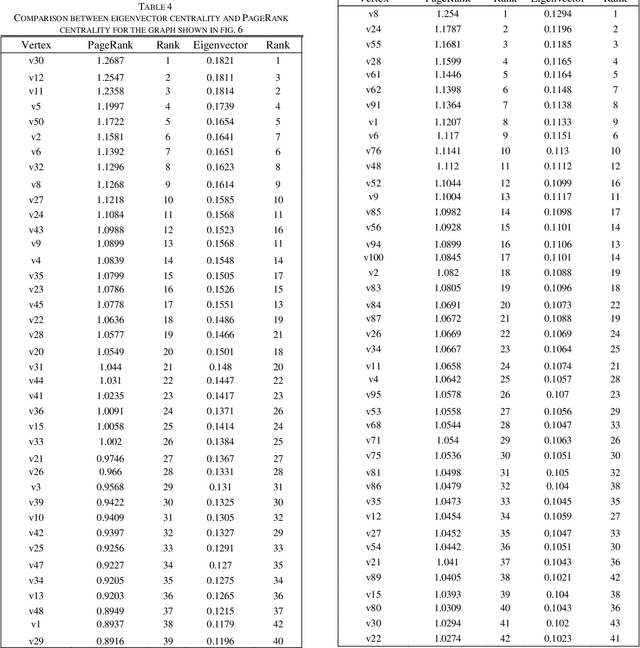
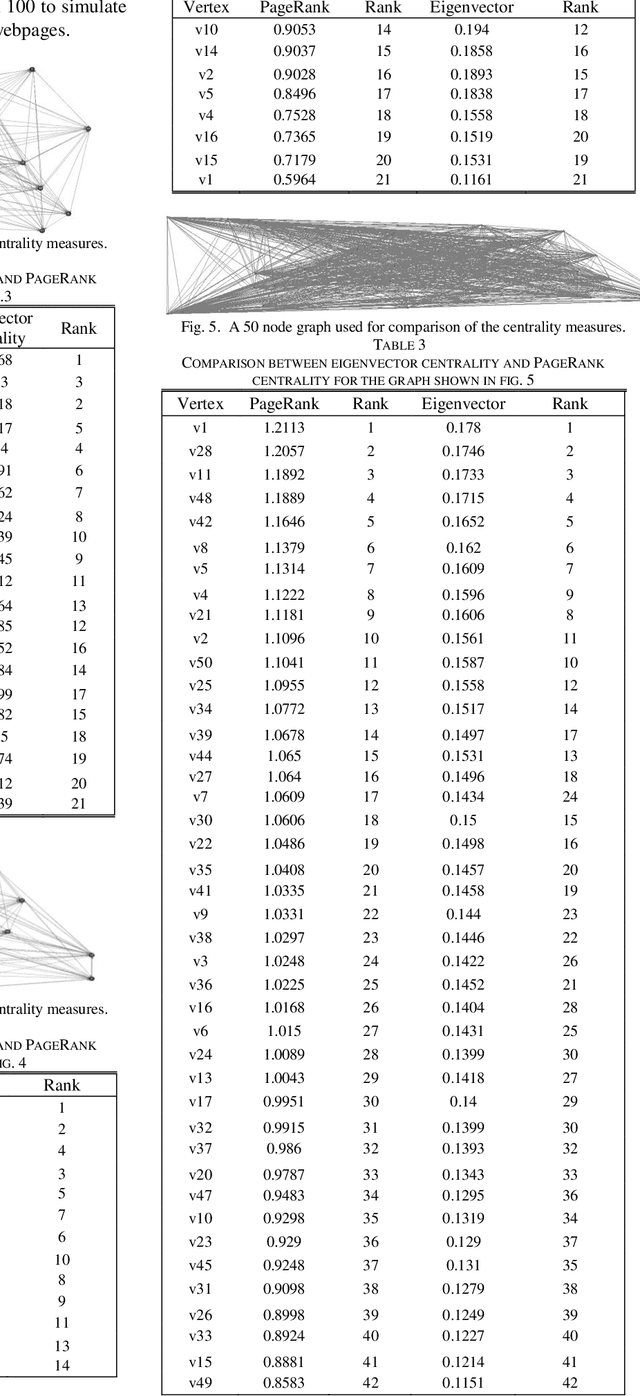
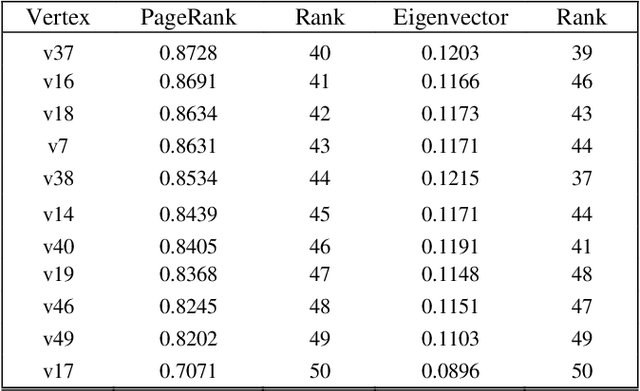
The purpose of the research is to find a centrality measure that can be used in place of PageRank and to find out the conditions where we can use it in place of PageRank. After analysis and comparison of graphs with a large number of nodes using Spearman's Rank Coefficient Correlation, the conclusion is evident that Eigenvector can be safely used in place of PageRank in directed networks to improve the performance in terms of the time complexity.
iToF2dToF: A Robust and Flexible Representation for Data-Driven Time-of-Flight Imaging
Mar 12, 2021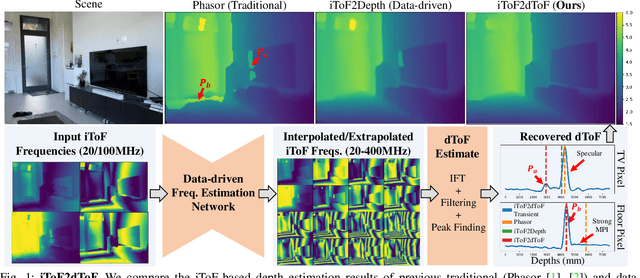
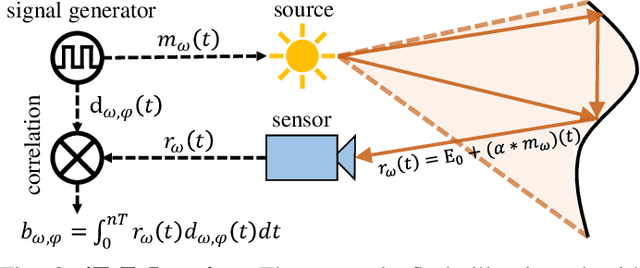
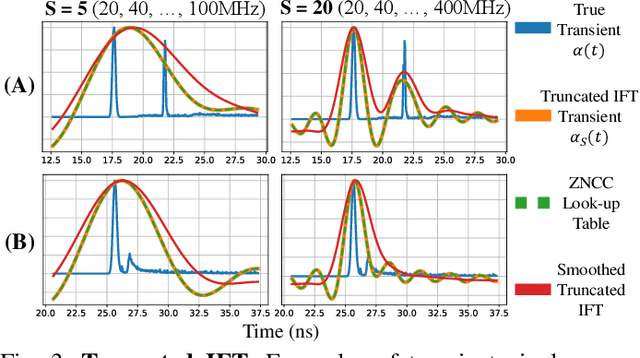
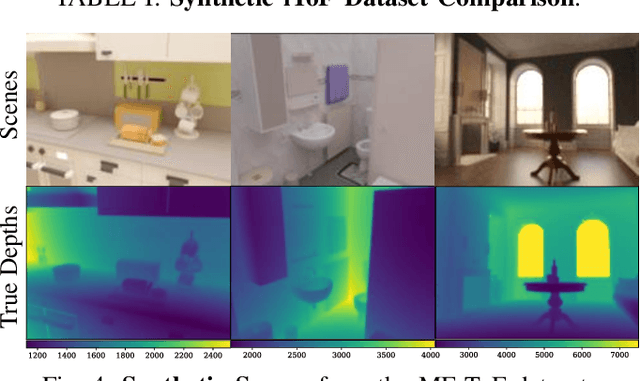
Indirect Time-of-Flight (iToF) cameras are a promising depth sensing technology. However, they are prone to errors caused by multi-path interference (MPI) and low signal-to-noise ratio (SNR). Traditional methods, after denoising, mitigate MPI by estimating a transient image that encodes depths. Recently, data-driven methods that jointly denoise and mitigate MPI have become state-of-the-art without using the intermediate transient representation. In this paper, we propose to revisit the transient representation. Using data-driven priors, we interpolate/extrapolate iToF frequencies and use them to estimate the transient image. Given direct ToF (dToF) sensors capture transient images, we name our method iToF2dToF. The transient representation is flexible. It can be integrated with different rule-based depth sensing algorithms that are robust to low SNR and can deal with ambiguous scenarios that arise in practice (e.g., specular MPI, optical cross-talk). We demonstrate the benefits of iToF2dToF over previous methods in real depth sensing scenarios.