 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Tactile SLAM: Real-time inference of shape and pose from planar pushing
Nov 13, 2020


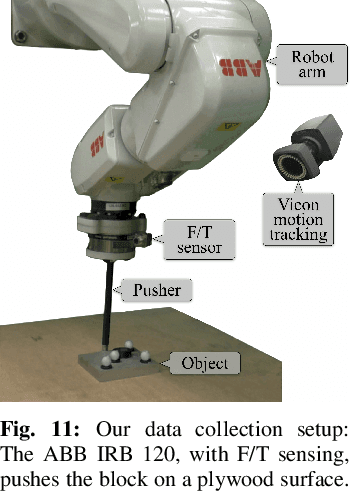
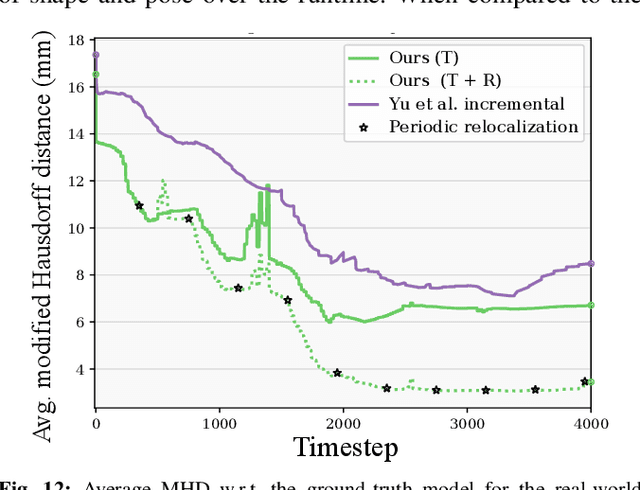
Tactile perception is central to robot manipulation in unstructured environments. However, it requires contact, and a mature implementation must infer object models while also accounting for the motion induced by the interaction. In this work, we present a method to estimate both object shape and pose in real-time from a stream of tactile measurements. This is applied towards tactile exploration of an unknown object by planar pushing. We consider this as an online SLAM problem with a nonparametric shape representation. Our formulation of tactile inference alternates between Gaussian process implicit surface regression and pose estimation on a factor graph. Through a combination of local Gaussian processes and fixed-lag smoothing, we infer object shape and pose in real-time. We evaluate our system across different objects in both simulated and real-world planar pushing tasks.
Can machines solve general queueing systems?
Feb 03, 2022
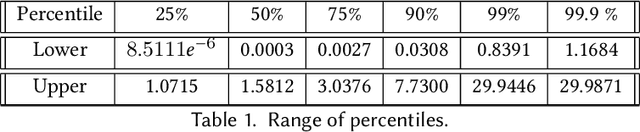
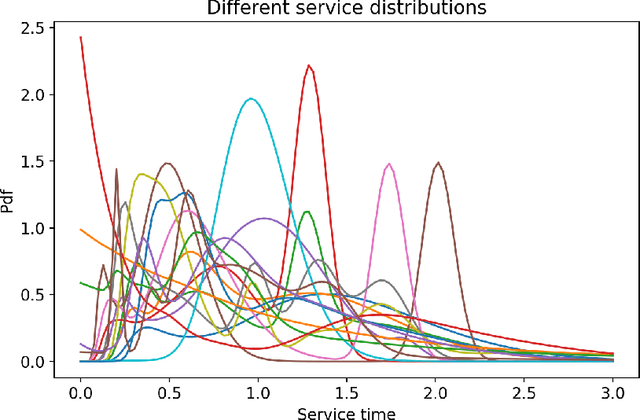

In this paper, we analyze how well a machine can solve a general problem in queueing theory. To answer this question, we use a deep learning model to predict the stationary queue-length distribution of an $M/G/1$ queue (Poisson arrivals, general service times, one server). To the best of our knowledge, this is the first time a machine learning model is applied to a general queueing theory problem. We chose $M/G/1$ queue for this paper because it lies "on the cusp" of the analytical frontier: on the one hand exact solution for this model is available, which is both computationally and mathematically complex. On the other hand, the problem (specifically the service time distribution) is general. This allows us to compare the accuracy and efficiency of the deep learning approach to the analytical solutions. The two key challenges in applying machine learning to this problem are (1) generating a diverse set of training examples that provide a good representation of a "generic" positive-valued distribution, and (2) representations of the continuous distribution of service times as an input. We show how we overcome these challenges. Our results show that our model is indeed able to predict the stationary behavior of the $M/G/1$ queue extremely accurately: the average value of our metric over the entire test set is $0.0009$. Moreover, our machine learning model is very efficient, computing very accurate stationary distributions in a fraction of a second (an approach based on simulation modeling would take much longer to converge). We also present a case-study that mimics a real-life setting and shows that our approach is more robust and provides more accurate solutions compared to the existing methods. This shows the promise of extending our approach beyond the analytically solvable systems (e.g., $G/G/1$ or $G/G/c$).
ReenactNet: Real-time Full Head Reenactment
May 22, 2020Video-to-video synthesis is a challenging problem aiming at learning a translation function between a sequence of semantic maps and a photo-realistic video depicting the characteristics of a driving video. We propose a head-to-head system of our own implementation capable of fully transferring the human head 3D pose, facial expressions and eye gaze from a source to a target actor, while preserving the identity of the target actor. Our system produces high-fidelity, temporally-smooth and photo-realistic synthetic videos faithfully transferring the human time-varying head attributes from the source to the target actor. Our proposed implementation: 1) works in real time ($\sim 20$ fps), 2) runs on a commodity laptop with a webcam as the only input, 3) is interactive, allowing the participant to drive a target person, e.g. a celebrity, politician, etc, instantly by varying their expressions, head pose, and eye gaze, and visualising the synthesised video concurrently.
Exploring Structural Sparsity in Neural Image Compression
Feb 10, 2022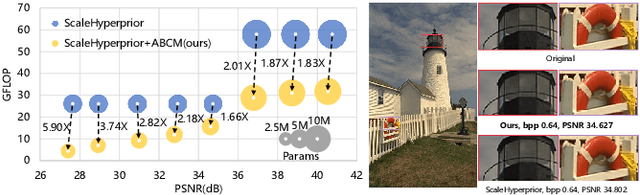
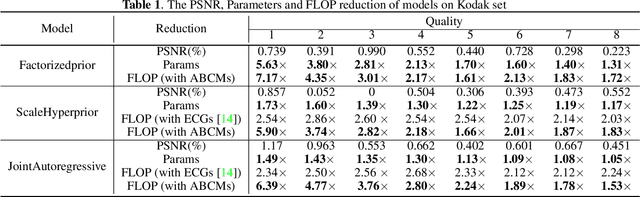
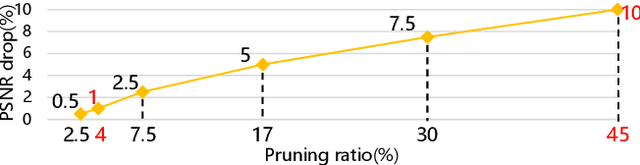

Neural image compression have reached or out-performed traditional methods (such as JPEG, BPG, WebP). However,their sophisticated network structures with cascaded convolution layers bring heavy computational burden for practical deployment. In this paper, we explore the structural sparsity in neural image compression network to obtain real-time acceleration without any specialized hardware design or algorithm. We propose a simple plug-in adaptive binary channel masking(ABCM) to judge the importance of each convolution channel and introduce sparsity during training. During inference, the unimportant channels are pruned to obtain slimmer network and less computation. We implement our method into three neural image compression networks with different entropy models to verify its effectiveness and generalization, the experiment results show that up to 7x computation reduction and 3x acceleration can be achieved with negligible performance drop.
Semantic-Aware Collaborative Deep Reinforcement Learning Over Wireless Cellular Networks
Nov 23, 2021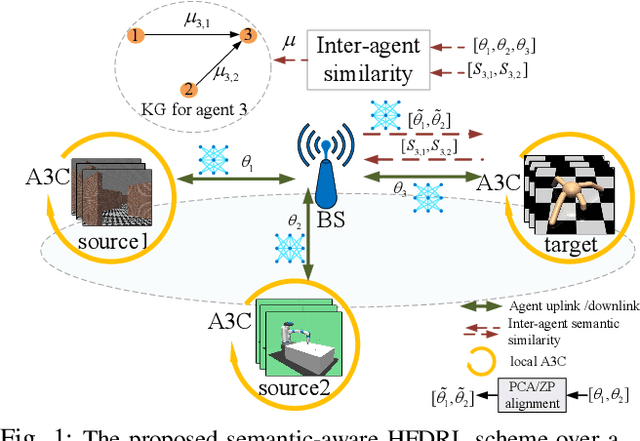
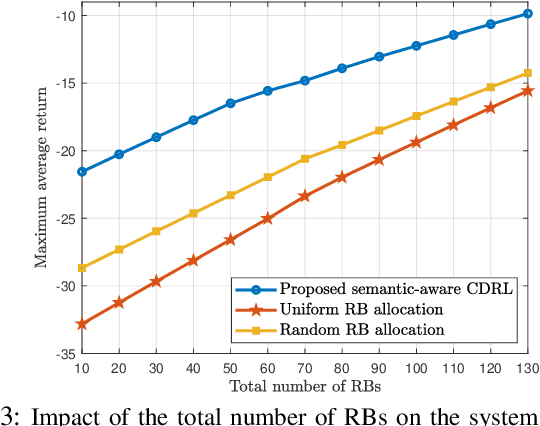
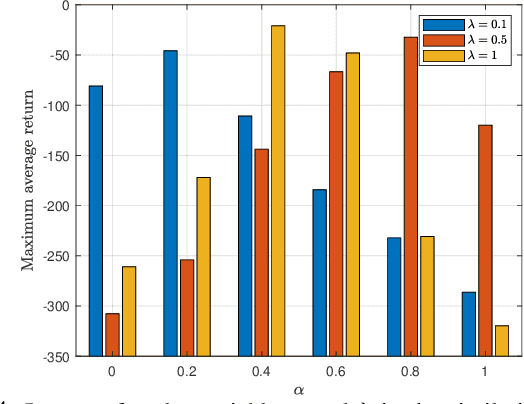
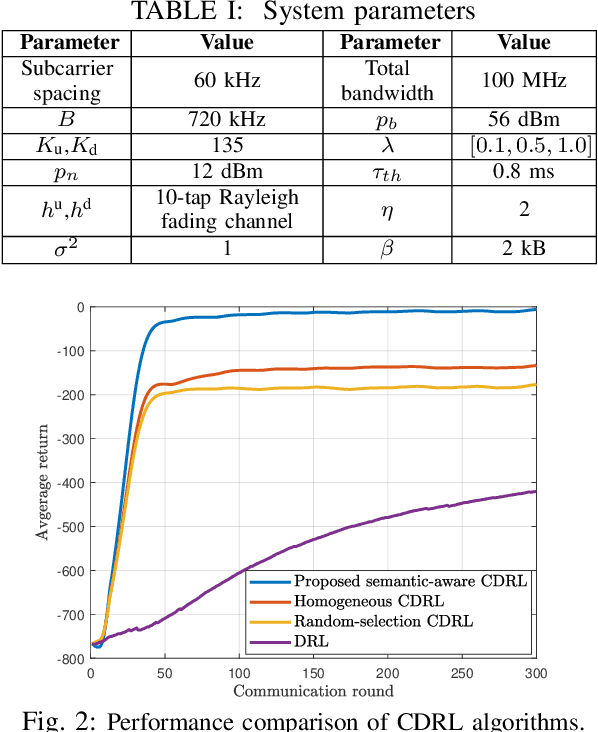
Collaborative deep reinforcement learning (CDRL) algorithms in which multiple agents can coordinate over a wireless network is a promising approach to enable future intelligent and autonomous systems that rely on real-time decision-making in complex dynamic environments. Nonetheless, in practical scenarios, CDRL faces many challenges due to the heterogeneity of agents and their learning tasks, different environments, time constraints of the learning, and resource limitations of wireless networks. To address these challenges, in this paper, a novel semantic-aware CDRL method is proposed to enable a group of heterogeneous untrained agents with semantically-linked DRL tasks to collaborate efficiently across a resource-constrained wireless cellular network. To this end, a new heterogeneous federated DRL (HFDRL) algorithm is proposed to select the best subset of semantically relevant DRL agents for collaboration. The proposed approach then jointly optimizes the training loss and wireless bandwidth allocation for the cooperating selected agents in order to train each agent within the time limit of its real-time task. Simulation results show the superior performance of the proposed algorithm compared to state-of-the-art baselines.
Convolutional-Recurrent Neural Network Proxy for Robust Optimization and Closed-Loop Reservoir Management
Mar 14, 2022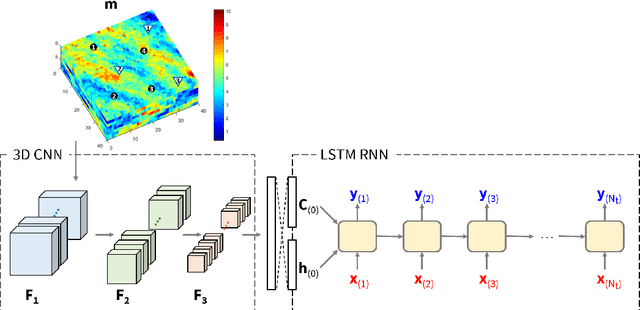

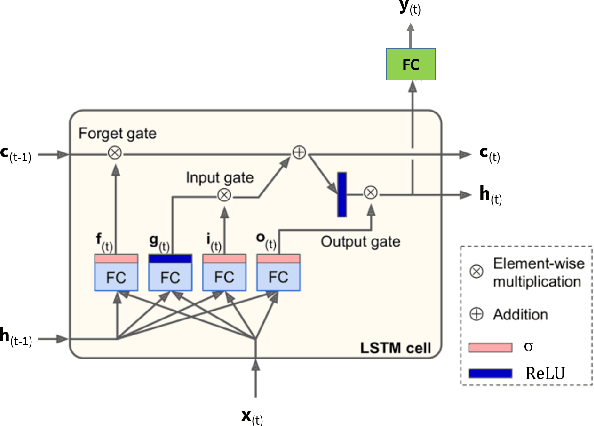
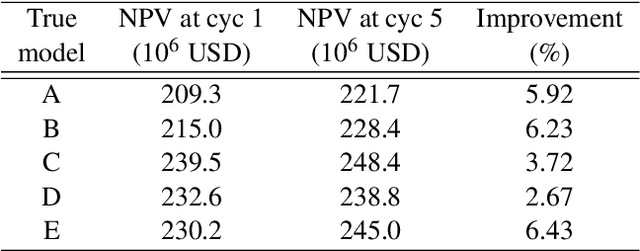
Production optimization under geological uncertainty is computationally expensive, as a large number of well control schedules must be evaluated over multiple geological realizations. In this work, a convolutional-recurrent neural network (CNN-RNN) proxy model is developed to predict well-by-well oil and water rates, for given time-varying well bottom-hole pressure (BHP) schedules, for each realization in an ensemble. This capability enables the estimation of the objective function and nonlinear constraint values required for robust optimization. The proxy model represents an extension of a recently developed long short-term memory (LSTM) RNN proxy designed to predict well rates for a single geomodel. A CNN is introduced here to processes permeability realizations, and this provides the initial states for the RNN. The CNN-RNN proxy is trained using simulation results for 300 different sets of BHP schedules and permeability realizations. We demonstrate proxy accuracy for oil-water flow through multiple realizations of 3D multi-Gaussian permeability models. The proxy is then incorporated into a closed-loop reservoir management (CLRM) workflow, where it is used with particle swarm optimization and a filter-based method for nonlinear constraint satisfaction. History matching is achieved using an adjoint-gradient-based procedure. The proxy model is shown to perform well in this setting for five different (synthetic) `true' models. Improved net present value along with constraint satisfaction and uncertainty reduction are observed with CLRM. For the robust production optimization steps, the proxy provides O(100) runtime speedup over simulation-based optimization.
Pay Attention to Evolution: Time Series Forecasting with Deep Graph-Evolution Learning
Aug 28, 2020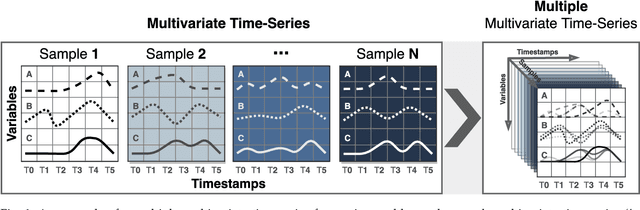
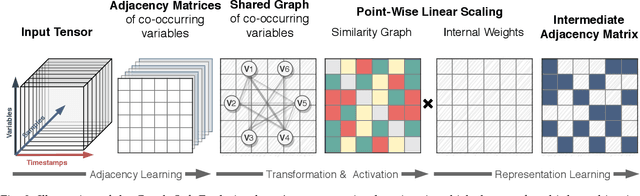

Time-series forecasting is one of the most active research topics in predictive analysis. A still open gap in that literature is that statistical and ensemble learning approaches systematically present lower predictive performance than deep learning methods as they generally disregard the data sequence aspect entangled with multivariate data represented in more than one time series. Conversely, this work presents a novel neural network architecture for time-series forecasting that combines the power of graph evolution with deep recurrent learning on distinct data distributions; we named our method Recurrent Graph Evolution Neural Network (ReGENN). The idea is to infer multiple multivariate relationships between co-occurring time-series by assuming that the temporal data depends not only on inner variables and intra-temporal relationships (i.e., observations from itself) but also on outer variables and inter-temporal relationships (i.e., observations from other-selves). An extensive set of experiments was conducted comparing ReGENN with dozens of ensemble methods and classical statistical ones, showing sound improvement of up to 64.87% over the competing algorithms. Furthermore, we present an analysis of the intermediate weights arising from ReGENN, showing that by looking at inter and intra-temporal relationships simultaneously, time-series forecasting is majorly improved if paying attention to how multiple multivariate data synchronously evolve.
Achieving Reliable Human Assessment of Open-Domain Dialogue Systems
Mar 11, 2022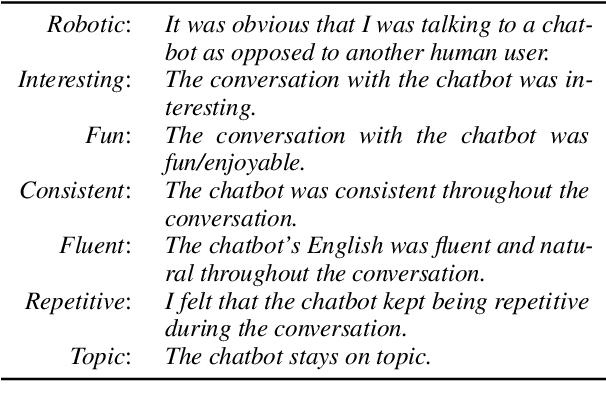

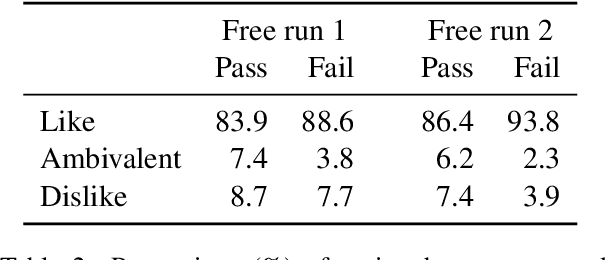
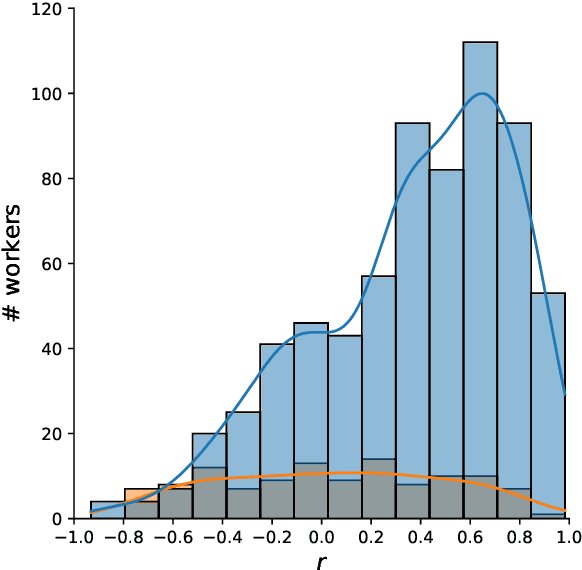
Evaluation of open-domain dialogue systems is highly challenging and development of better techniques is highlighted time and again as desperately needed. Despite substantial efforts to carry out reliable live evaluation of systems in recent competitions, annotations have been abandoned and reported as too unreliable to yield sensible results. This is a serious problem since automatic metrics are not known to provide a good indication of what may or may not be a high-quality conversation. Answering the distress call of competitions that have emphasized the urgent need for better evaluation techniques in dialogue, we present the successful development of human evaluation that is highly reliable while still remaining feasible and low cost. Self-replication experiments reveal almost perfectly repeatable results with a correlation of $r=0.969$. Furthermore, due to the lack of appropriate methods of statistical significance testing, the likelihood of potential improvements to systems occurring due to chance is rarely taken into account in dialogue evaluation, and the evaluation we propose facilitates application of standard tests. Since we have developed a highly reliable evaluation method, new insights into system performance can be revealed. We therefore include a comparison of state-of-the-art models (i) with and without personas, to measure the contribution of personas to conversation quality, as well as (ii) prescribed versus freely chosen topics. Interestingly with respect to personas, results indicate that personas do not positively contribute to conversation quality as expected.
BEATS: An Open-Source, High-Precision, Multi-Channel EEG Acquisition Tool System
Mar 04, 2022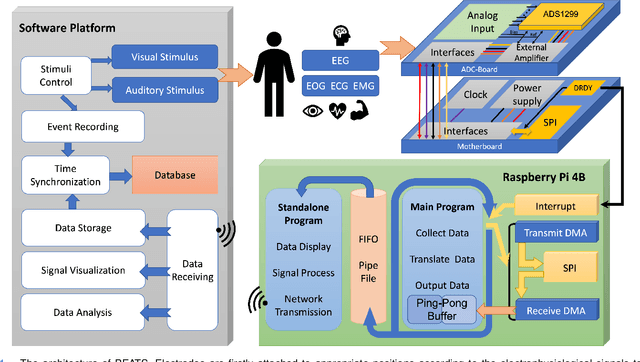
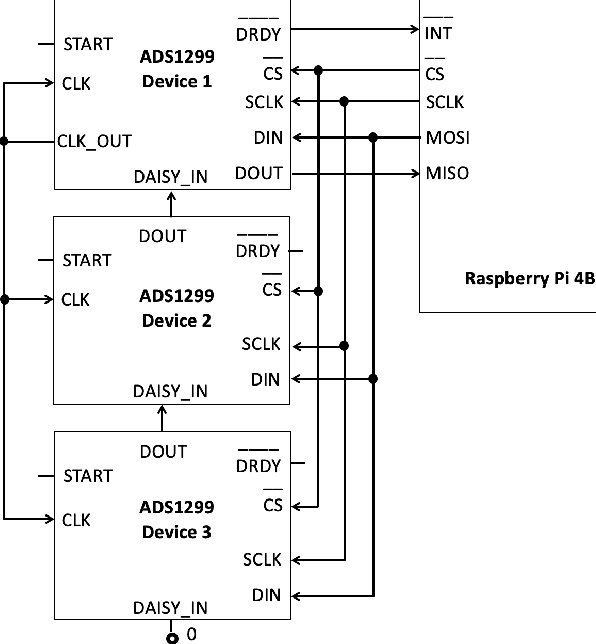

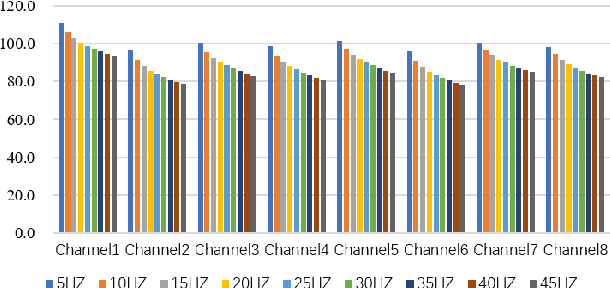
Stable and accurate electroencephalogram (EEG) signal acquisition is fundamental in non-invasive brain-computer interface (BCI) technology. Commonly used EEG acquisition system's hardware and software are usually closed-source. Its inability to flexible expansion and secondary development is a major obstacle to real-time BCI research. This paper presents an open-source, high-precision, multi-channel EEG Acquisition Tool System developed by Beijing University of Posts and Telecommunications named BEATS. It implements a comprehensive system from hardware to software, composes of analog front-end, microprocessor, and software platform. BEATS is capable of collecting multi-channel micro-volt EEG signals up to 4000 $Hz$ with wireless transmission. And it adopts a pluggable structure and easy-to-access materials, which can easily support rapid prototyping, portability, and scalability. Some underlying techniques like direct memory access, interrupt, first in first out are used to ensure the precision and stability of the program at the microsecond level. Compared to state-of-the-art systems, BEATS maintains a relatively high channel number when acquiring data at a high sampling rate, while being quick to set up and use, making it ideal for a wide range of BCI scenarios or long-term daily monitoring. Schematics, source code, and other materials of BEATS are available at https://github.com/bingzant/BEATS.
Efficient computation of the volume of a polytope in high-dimensions using Piecewise Deterministic Markov Processes
Feb 18, 2022
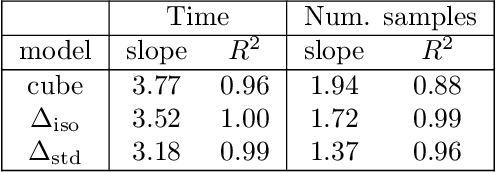
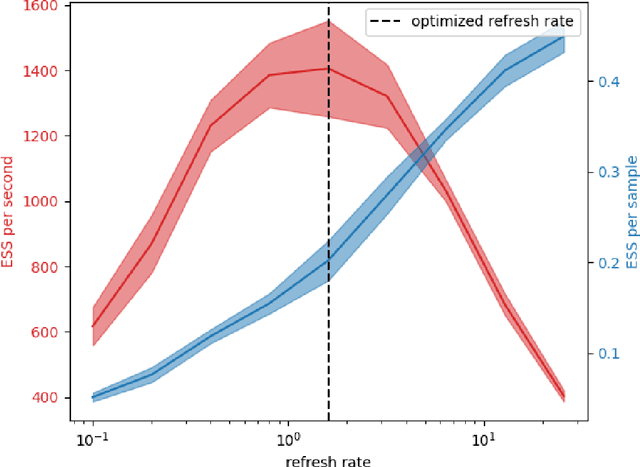
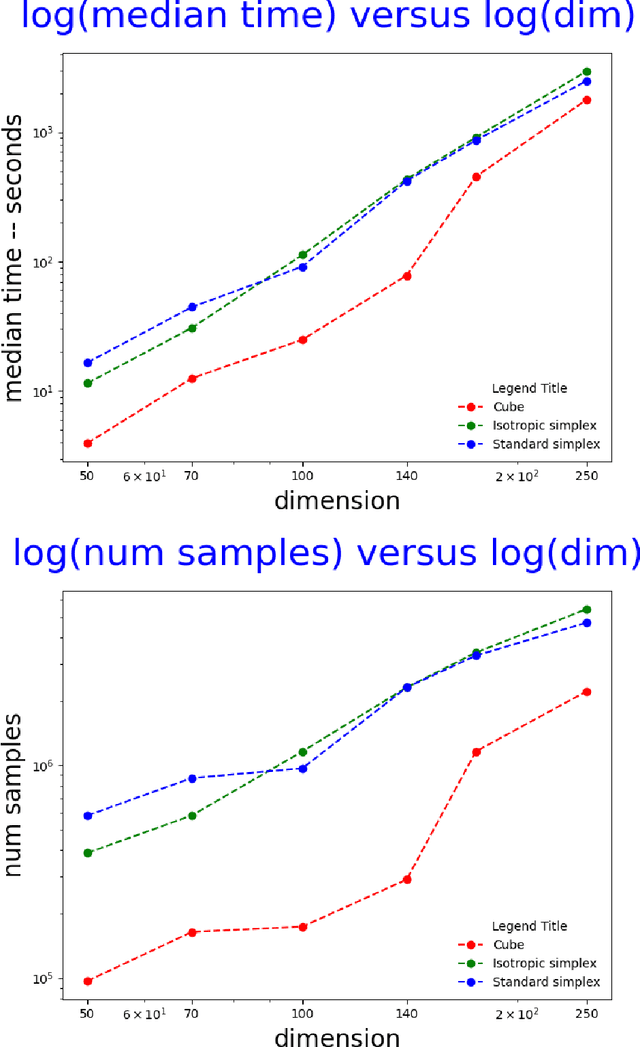
Computing the volume of a polytope in high dimensions is computationally challenging but has wide applications. Current state-of-the-art algorithms to compute such volumes rely on efficient sampling of a Gaussian distribution restricted to the polytope, using e.g. Hamiltonian Monte Carlo. We present a new sampling strategy that uses a Piecewise Deterministic Markov Process. Like Hamiltonian Monte Carlo, this new method involves simulating trajectories of a non-reversible process and inherits similar good mixing properties. However, importantly, the process can be simulated more easily due to its piecewise linear trajectories - and this leads to a reduction of the computational cost by a factor of the dimension of the space. Our experiments indicate that our method is numerically robust and is one order of magnitude faster (or better) than existing methods using Hamiltonian Monte Carlo. On a single core processor, we report computational time of a few minutes up to dimension 500.