 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ECG synthesis with Neural ODE and GAN models
Oct 30, 2021
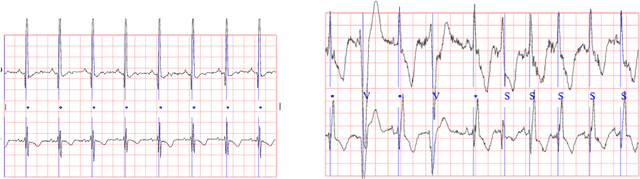

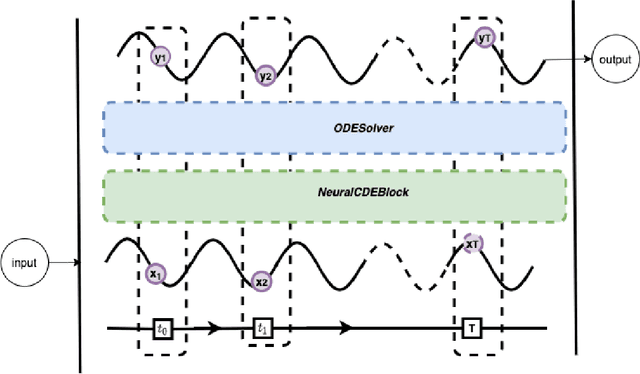
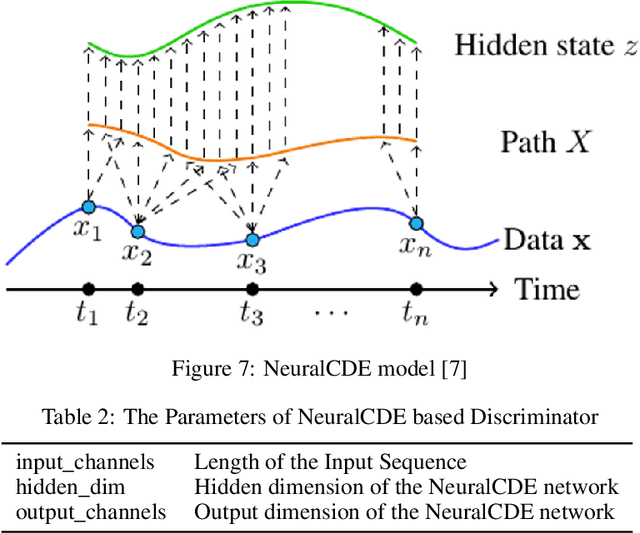
Continuous medical time series data such as ECG is one of the most complex time series due to its dynamic and high dimensional characteristics. In addition, due to its sensitive nature, privacy concerns and legal restrictions, it is often even complex to use actual data for different medical research. As a result, generating continuous medical time series is a very critical research area. Several research works already showed that the ability of generative adversarial networks (GANs) in the case of continuous medical time series generation is promising. Most medical data generation works, such as ECG synthesis, are mainly driven by the GAN model and its variation. On the other hand, Some recent work on Neural Ordinary Differential Equation (Neural ODE) demonstrates its strength against informative missingness, high dimension as well as dynamic nature of continuous time series. Instead of considering continuous-time series as a discrete-time sequence, Neural ODE can train continuous time series in real-time continuously. In this work, we used Neural ODE based model to generate synthetic sine waves and synthetic ECG. We introduced a new technique to design the generative adversarial network with Neural ODE based Generator and Discriminator. We developed three new models to synthesise continuous medical data. Different evaluation metrics are then used to quantitatively assess the quality of generated synthetic data for real-world applications and data analysis. Another goal of this work is to combine the strength of GAN and Neural ODE to generate synthetic continuous medical time series data such as ECG. We also evaluated both the GAN model and the Neural ODE model to understand the comparative efficiency of models from the GAN and Neural ODE family in medical data synthesis.
Super-Resolution Time-Resolved Imaging using Computational Sensor Fusion
Jan 08, 2021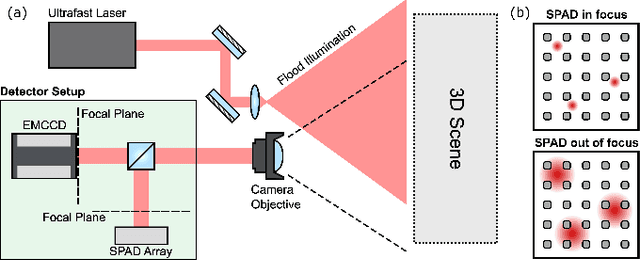

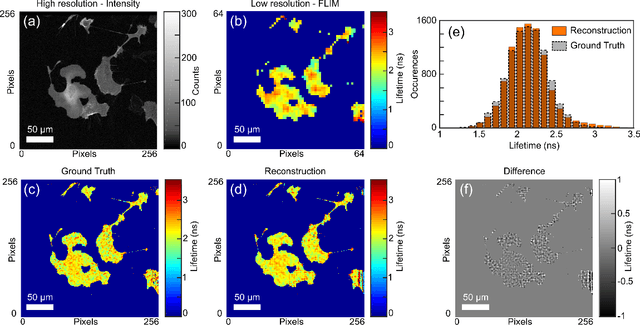
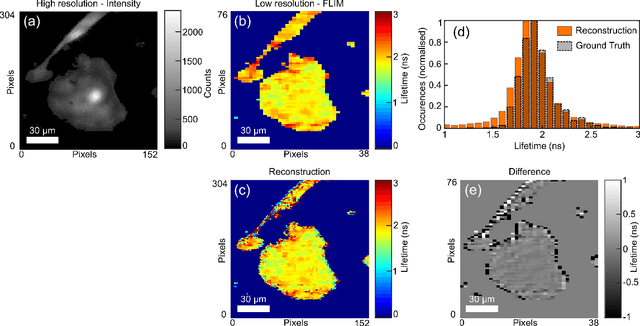
Imaging across both the full transverse spatial and temporal dimensions of a scene with high precision in all three coordinates is key to applications ranging from LIDAR to fluorescence lifetime imaging. However, compromises that sacrifice, for example, spatial resolution at the expense of temporal resolution are often required, in particular when the full 3-dimensional data cube is required in short acquisition times. We introduce a sensor fusion approach that combines data having low-spatial resolution but high temporal precision gathered with a single-photon-avalanche-diode (SPAD) array with set of data that has high spatial but no temporal resolution, such as that acquired with a standard CMOS camera. Our method, based on blurring the image on the SPAD array and computational sensor fusion, reconstructs time-resolved images at significantly higher spatial resolution than the SPAD input, upsampling numerical data by a factor 12x12, and demonstrating up to 4x4 upsampling of experimental data. We demonstrate the technique for both LIDAR applications and FLIM of fluorescent cancer cells. This technique paves the way to high spatial resolution SPAD imaging or, equivalently, FLIM imaging with conventional microscopes at frame rates accelerated by more than an order of magnitude.
The Concordance Index decomposition: a measure for a deeper understanding of survival prediction models
Mar 02, 2022
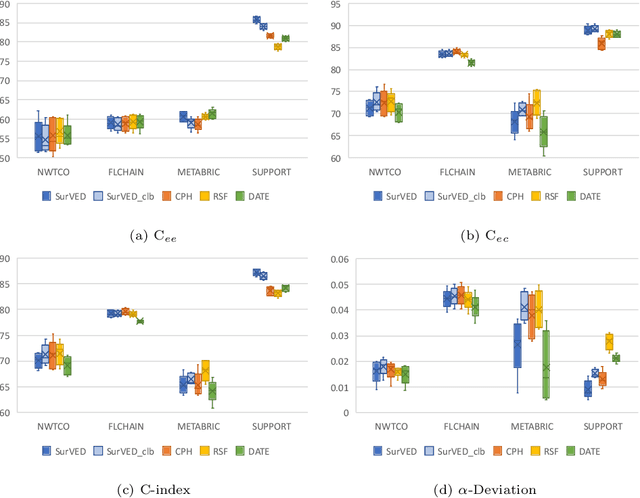
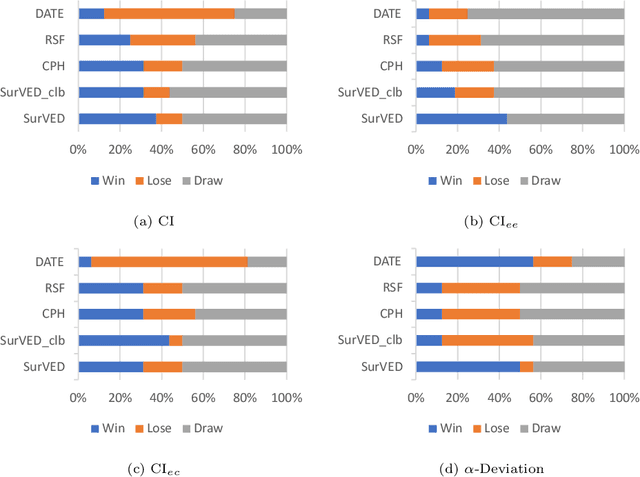

The Concordance Index (C-index) is a commonly used metric in Survival Analysis to evaluate how good a prediction model is. This paper proposes a decomposition of the C-Index into a weighted harmonic mean of two quantities: one for ranking observed events versus other observed events, and the other for ranking observed events versus censored cases. This decomposition allows a more fine-grained analysis of the pros and cons of survival prediction methods. The utility of the decomposition is demonstrated using three benchmark survival analysis models (Cox Proportional Hazard, Random Survival Forest, and Deep Adversarial Time-to-Event Network) together with a new variational generative neural-network-based method (SurVED), which is also proposed in this paper. The demonstration is done on four publicly available datasets with varying censoring levels. The analysis with the C-index decomposition shows that all methods essentially perform equally well when the censoring level is high because of the dominance of the term measuring the ranking of events versus censored cases. In contrast, some methods deteriorate when the censoring level decreases because they do not rank the events versus other events well.
An Empirical Survey of Data Augmentation for Time Series Classification with Neural Networks
Jul 31, 2020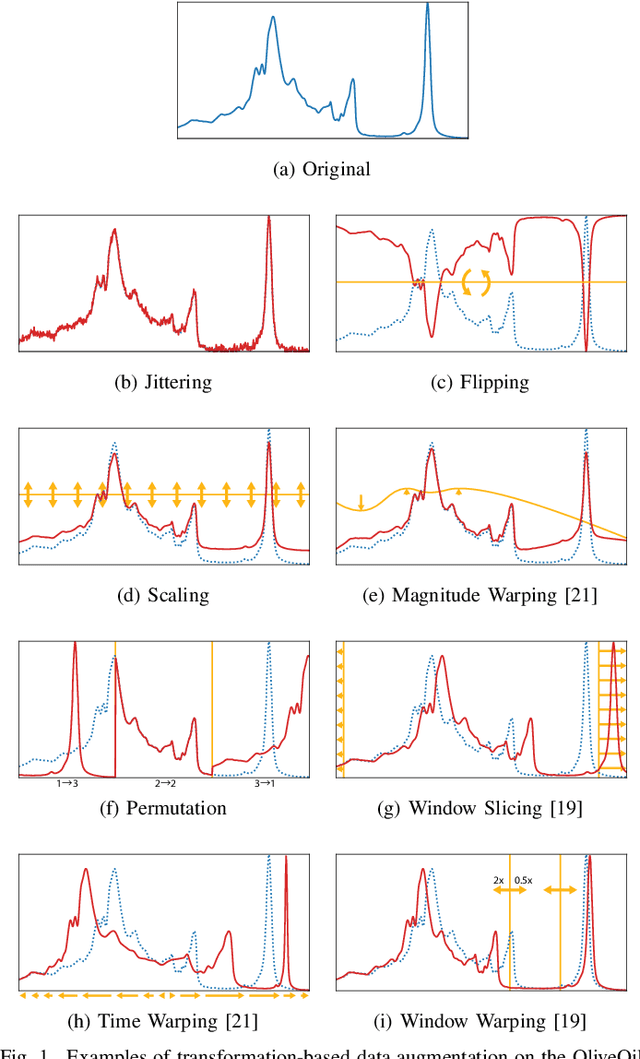
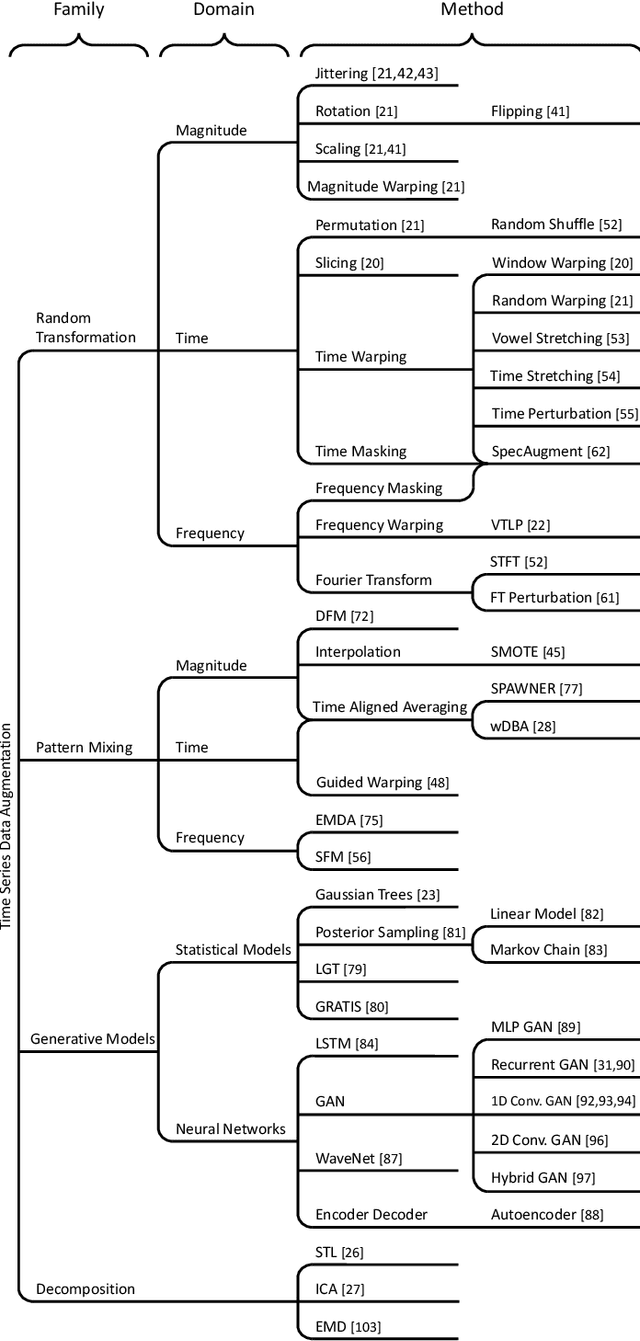
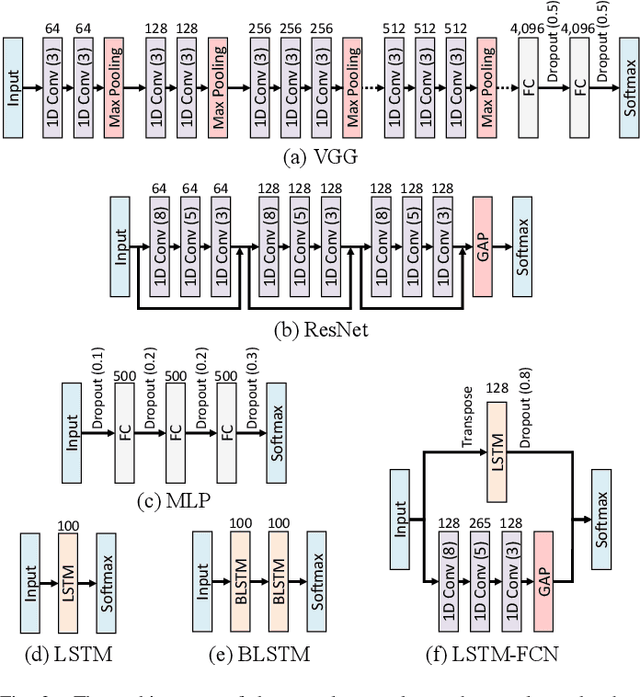
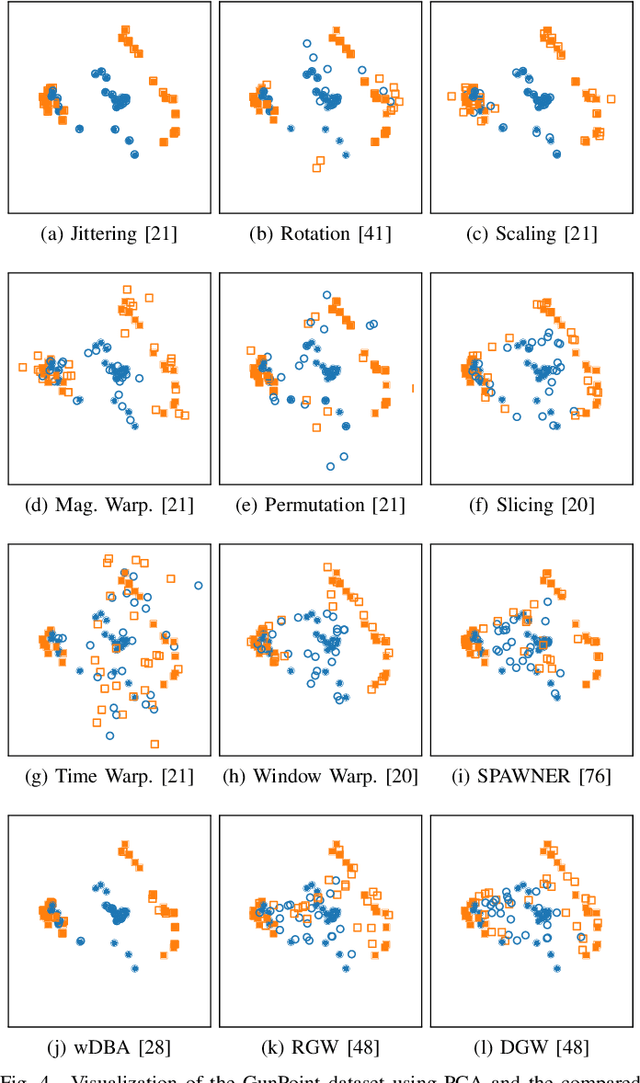
In recent times, deep artificial neural networks have achieved many successes in pattern recognition. Part of this success is the reliance on big data to increase generalization. However, in the field of time series recognition, many datasets are often very small. One method of addressing this problem is through the use of data augmentation. In this paper, we survey data augmentation techniques for time series and their application to time series classification with neural networks. We outline four families of time series data augmentation, including transformation-based methods, pattern mixing, generative models, and decomposition methods, and detail their taxonomy. Furthermore, we empirically evaluate 12 time series data augmentation methods on 128 time series classification datasets with 6 different types of neural networks. Through the results, we are able to analyze the characteristics, advantages and disadvantages, and recommendations of each data augmentation method. This survey aims to help in the selection of time series data augmentation for neural network applications.
KC-TSS: An Algorithm for Heterogeneous Robot Teams Performing Resilient Target Search
Mar 02, 2022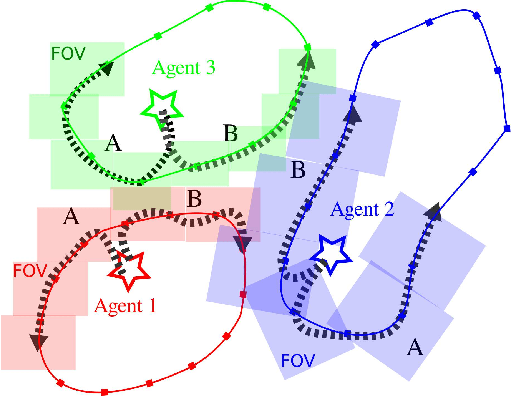
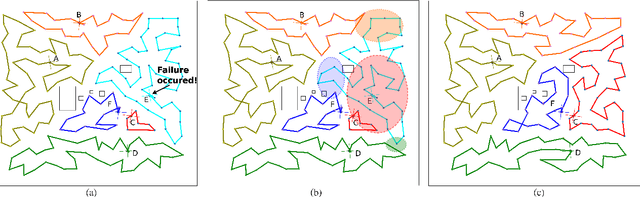
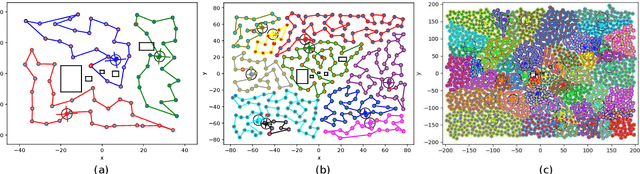
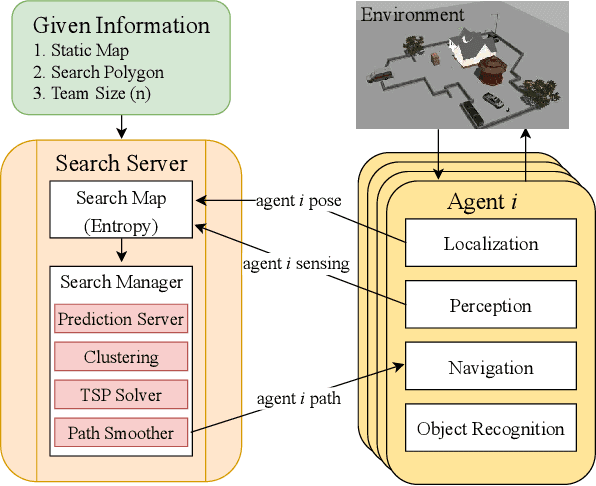
This paper proposes KC-TSS: K-Clustered-Traveling Salesman Based Search, a failure resilient path planning algorithm for heterogeneous robot teams performing target search in human environments. We separate the sample path generation problem into Heterogeneous Clustering and multiple Traveling Salesman Problems. This allows us to provide high-quality candidate paths (i.e. minimal backtracking, overlap) to an Information-Theoretic utility function for each agent. First, we generate waypoint candidates from map knowledge and a target prediction model. All of these candidates are clustered according to the number of agents and their ability to cover space, or coverage competency. Each agent solves a Traveling Salesman Problem (TSP) instance over their assigned cluster and then candidates are fed to a utility function for path selection. We perform extensive Gazebo simulations and preliminary deployment of real robots in indoor search and simulated rescue scenarios with static targets. We compare our proposed method against a state-of-the-art algorithm and show that ours is able to outperform it in mission time. Our method provides resilience in the event of single or multi teammate failure by recomputing global team plans online.
Enhancing Environmental Enforcement with Near Real-Time Monitoring: Likelihood-Based Detection of Structural Expansion of Intensive Livestock Farms
May 29, 2021
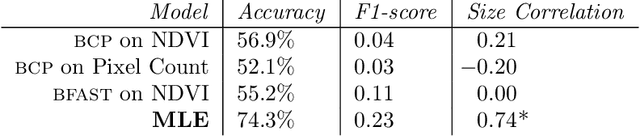
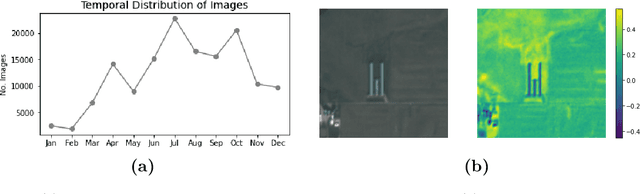

Environmental enforcement has historically relied on physical, resource-intensive, and infrequent inspections. Advances in remote sensing and computer vision have the potential to augment compliance monitoring, by providing early warning signals of permit violations. We demonstrate a process for rapid identification of significant structural expansion using satellite imagery and focusing on Concentrated Animal Feeding Operations (CAFOs) as a test case. Unpermitted expansion has been a particular challenge with CAFOs, which pose significant health and environmental risks. Using a new hand-labeled dataset of 175,736 images of 1,513 CAFOs, we combine state-of-the-art building segmentation with a likelihood-based change-point detection model to provide a robust signal of building expansion (AUC = 0.80). A major advantage of this approach is that it is able to work with high-cadence (daily to weekly), but lower resolution (3m/pixel), satellite imagery. It is also highly generalizable and thus provides a near real-time monitoring tool to prioritize enforcement resources to other settings where unpermitted construction poses environmental risk, e.g. zoning, habitat modification, or wetland protection.
Exploring Smoothness and Class-Separation for Semi-supervised Medical Image Segmentation
Mar 02, 2022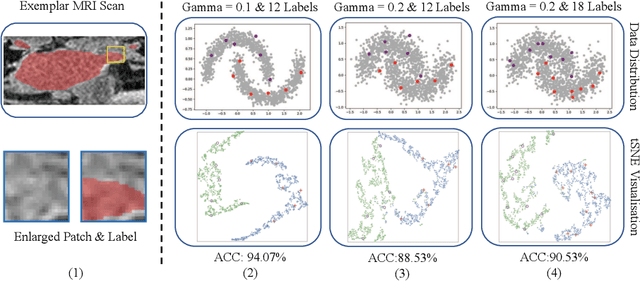
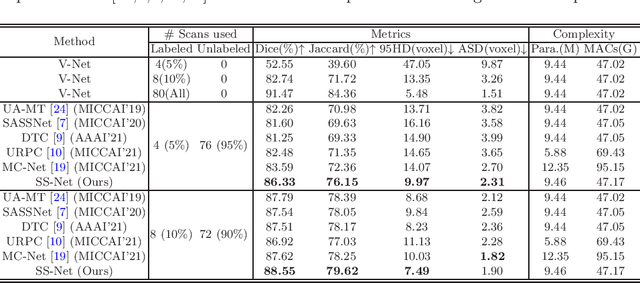
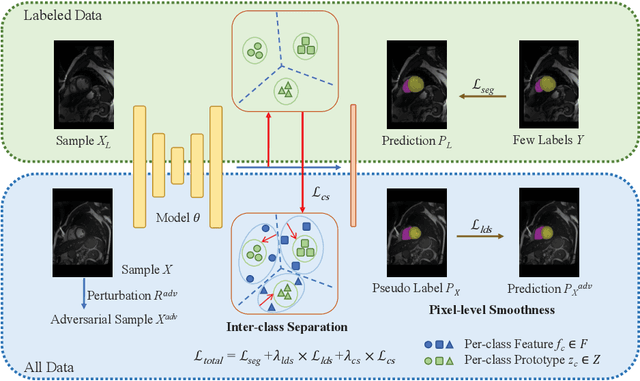
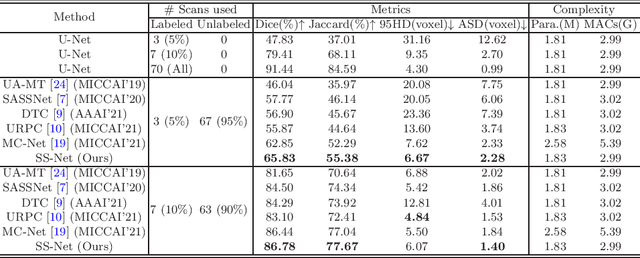
Semi-supervised segmentation remains challenging in medical imaging since the amount of annotated medical data is often limited and there are many blurred pixels near the adhesive edges or low-contrast regions. To address the issues, we advocate to firstly constrain the consistency of samples with and without strong perturbations to apply sufficient smoothness regularization and further encourage the class-level separation to exploit the unlabeled ambiguous pixels for the model training. Particularly, in this paper, we propose the SS-Net for semi-supervised medical image segmentation tasks, via exploring the pixel-level Smoothness and inter-class Separation at the same time. The pixel-level smoothness forces the model to generate invariant results under adversarial perturbations. Meanwhile, the inter-class separation constrains individual class features should approach their corresponding high-quality prototypes, in order to make each class distribution compact and separate different classes. We evaluated our SS-Net against five recent methods on the public LA and ACDC datasets. The experimental results under two semi-supervised settings demonstrate the superiority of our proposed SS-Net, achieving new state-of-the-art (SOTA) performance on both datasets. The codes will be released.
Prediction of speech intelligibility with DNN-based performance measures
Mar 17, 2022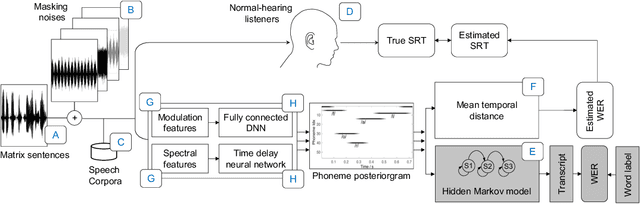


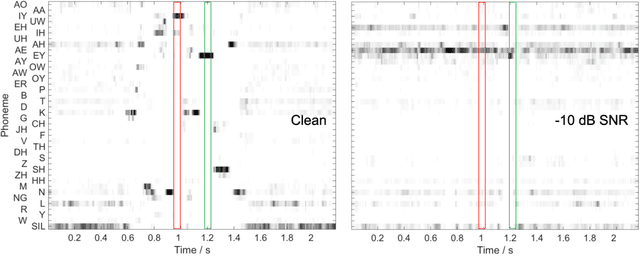
This paper presents a speech intelligibility model based on automatic speech recognition (ASR), combining phoneme probabilities from deep neural networks (DNN) and a performance measure that estimates the word error rate from these probabilities. This model does not require the clean speech reference nor the word labels during testing as the ASR decoding step, which finds the most likely sequence of words given phoneme posterior probabilities, is omitted. The model is evaluated via the root-mean-squared error between the predicted and observed speech reception thresholds from eight normal-hearing listeners. The recognition task consists of identifying noisy words from a German matrix sentence test. The speech material was mixed with eight noise maskers covering different modulation types, from speech-shaped stationary noise to a single-talker masker. The prediction performance is compared to five established models and an ASR-model using word labels. Two combinations of features and networks were tested. Both include temporal information either at the feature level (amplitude modulation filterbanks and a feed-forward network) or captured by the architecture (mel-spectrograms and a time-delay deep neural network, TDNN). The TDNN model is on par with the DNN while reducing the number of parameters by a factor of 37; this optimization allows parallel streams on dedicated hearing aid hardware as a forward-pass can be computed within the 10ms of each frame. The proposed model performs almost as well as the label-based model and produces more accurate predictions than the baseline models.
Time Series Forecasting with Stacked Long Short-Term Memory Networks
Nov 02, 2020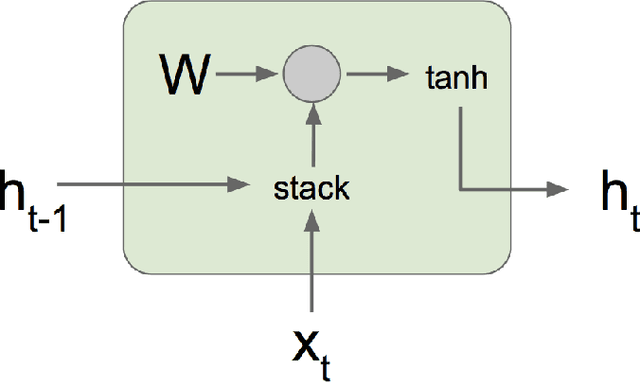
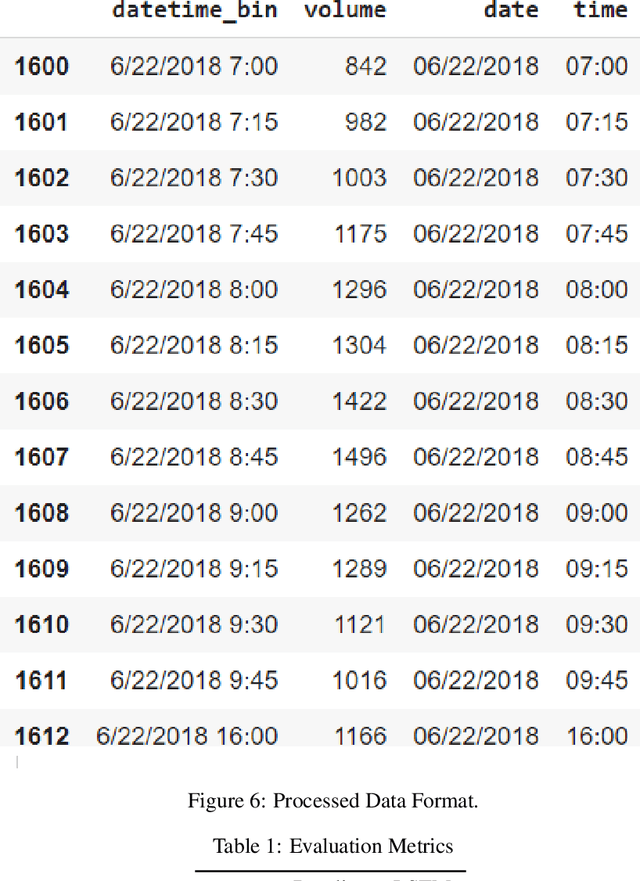
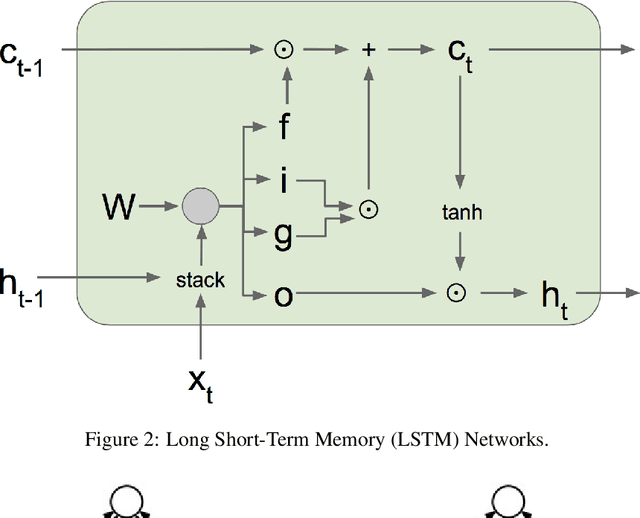
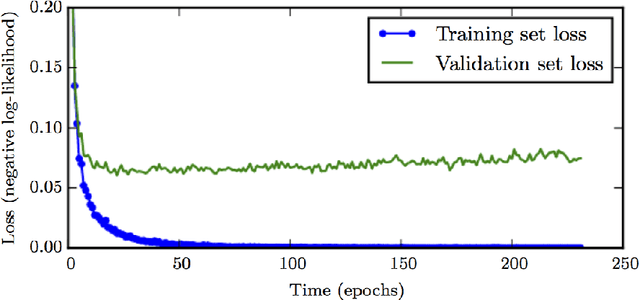
Long Short-Term Memory (LSTM) networks are often used to capture temporal dependency patterns. By stacking multi-layer LSTM networks, it can capture even more complex patterns. This paper explores the effectiveness of applying stacked LSTM networks in the time series prediction domain, specifically, the traffic volume forecasting. Being able to predict traffic volume more accurately can result in better planning, thus greatly reduce the operation cost and improve overall efficiency.
From Time Series to Euclidean Spaces: On Spatial Transformations for Temporal Clustering
Oct 02, 2020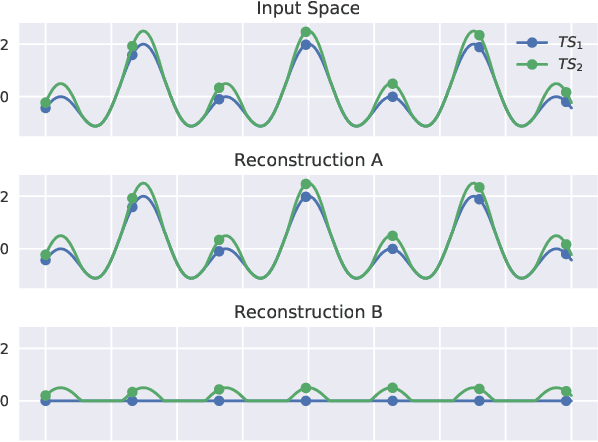
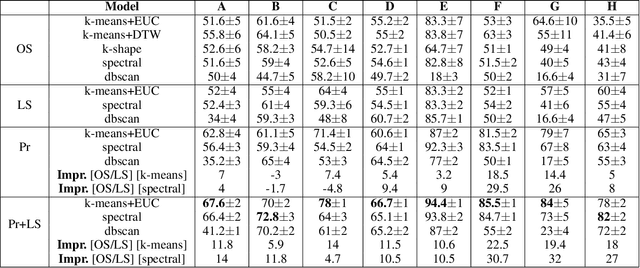
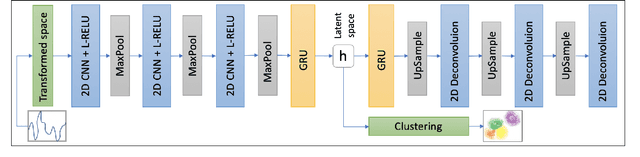
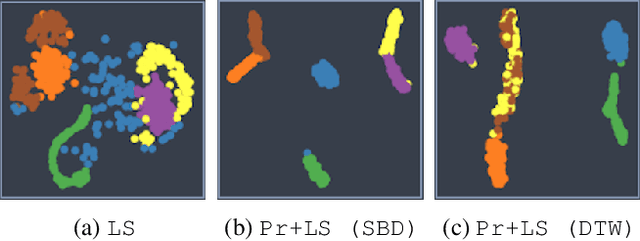
Unsupervised clustering of temporal data is both challenging and crucial in machine learning. In this paper, we show that neither traditional clustering methods, time series specific or even deep learning-based alternatives generalise well when both varying sampling rates and high dimensionality are present in the input data. We propose a novel approach to temporal clustering, in which we (1) transform the input time series into a distance-based projected representation by using similarity measures suitable for dealing with temporal data,(2) feed these projections into a multi-layer CNN-GRU autoencoder to generate meaningful domain-aware latent representations, which ultimately (3) allow for a natural separation of clusters beneficial for most important traditional clustering algorithms. We evaluate our approach on time series datasets from various domains and show that it not only outperforms existing methods in all cases, by up to 32%, but is also robust and incurs negligible computation overheads.