 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ChemTab: A Physics Guided Chemistry Modeling Framework
Feb 20, 2022
Modeling of turbulent combustion system requires modeling the underlying chemistry and the turbulent flow. Solving both systems simultaneously is computationally prohibitive. Instead, given the difference in scales at which the two sub-systems evolve, the two sub-systems are typically (re)solved separately. Popular approaches such as the Flamelet Generated Manifolds (FGM) use a two-step strategy where the governing reaction kinetics are pre-computed and mapped to a low-dimensional manifold, characterized by a few reaction progress variables (model reduction) and the manifold is then "looked-up" during the run-time to estimate the high-dimensional system state by the flow system. While existing works have focused on these two steps independently, we show that joint learning of the progress variables and the look-up model, can yield more accurate results. We propose a deep neural network architecture, called ChemTab, customized for the joint learning task and experimentally demonstrate its superiority over existing state-of-the-art methods.
Automatic deep learning for trend prediction in time series data
Sep 17, 2020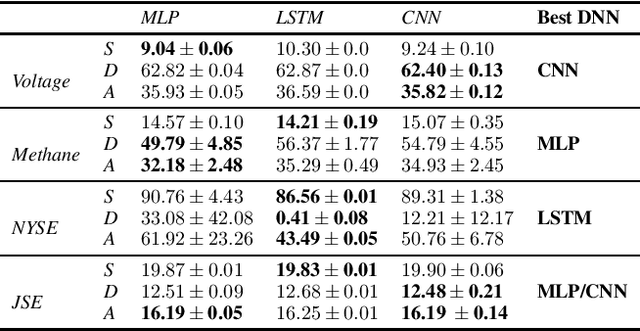

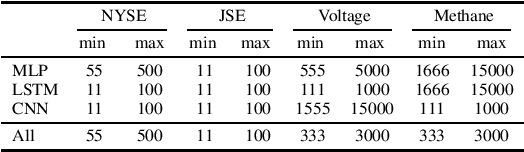
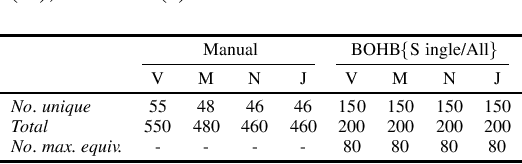
Recently, Deep Neural Network (DNN) algorithms have been explored for predicting trends in time series data. In many real world applications, time series data are captured from dynamic systems. DNN models must provide stable performance when they are updated and retrained as new observations becomes available. In this work we explore the use of automatic machine learning techniques to automate the algorithm selection and hyperparameter optimisation process for trend prediction. We demonstrate how a recent AutoML tool, specifically the HpBandSter framework, can be effectively used to automate DNN model development. Our AutoML experiments found optimal configurations that produced models that compared well against the average performance and stability levels of configurations found during the manual experiments across four data sets.
A low-rank ensemble Kalman filter for elliptic observations
Mar 10, 2022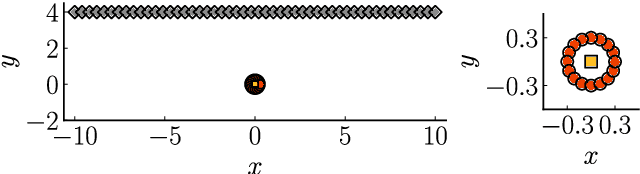
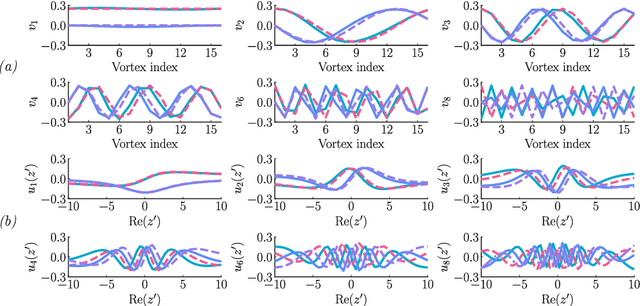
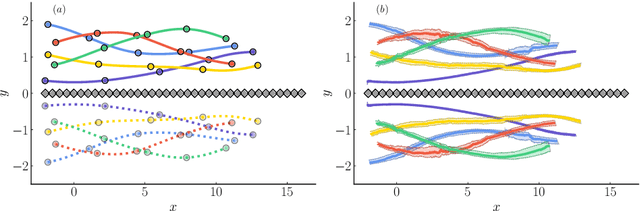
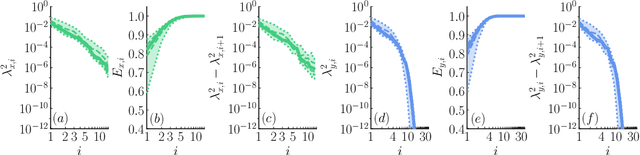
We propose a regularization method for ensemble Kalman filtering (EnKF) with elliptic observation operators. Commonly used EnKF regularization methods suppress state correlations at long distances. For observations described by elliptic partial differential equations, such as the pressure Poisson equation (PPE) in incompressible fluid flows, distance localization cannot be applied, as we cannot disentangle slowly decaying physical interactions from spurious long-range correlations. This is particularly true for the PPE, in which distant vortex elements couple nonlinearly to induce pressure. Instead, these inverse problems have a low effective dimension: low-dimensional projections of the observations strongly inform a low-dimensional subspace of the state space. We derive a low-rank factorization of the Kalman gain based on the spectrum of the Jacobian of the observation operator. The identified eigenvectors generalize the source and target modes of the multipole expansion, independently of the underlying spatial distribution of the problem. Given rapid spectral decay, inference can be performed in the low-dimensional subspace spanned by the dominant eigenvectors. This low-rank EnKF is assessed on dynamical systems with Poisson observation operators, where we seek to estimate the positions and strengths of point singularities over time from potential or pressure observations. We also comment on the broader applicability of this approach to elliptic inverse problems outside the context of filtering.
Online Self-Calibration for Visual-Inertial Navigation Systems: Models, Analysis and Degeneracy
Jan 29, 2022

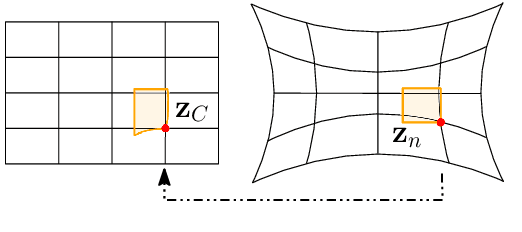
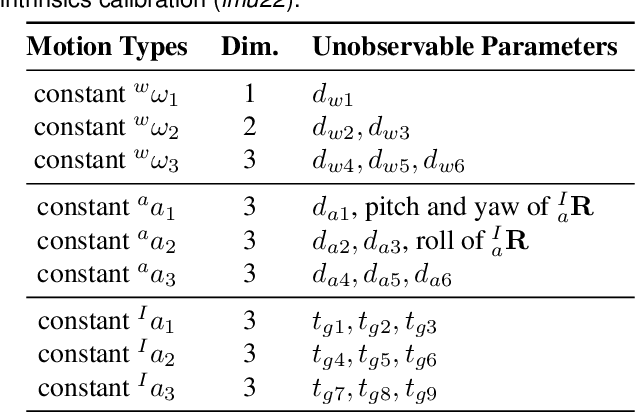
In this paper, we study in-depth the problem of online self-calibration for robust and accurate visual-inertial state estimation. In particular, we first perform a complete observability analysis for visual-inertial navigation systems (VINS) with full calibration of sensing parameters, including IMU and camera intrinsics and IMU-camera spatial-temporal extrinsic calibration, along with readout time of rolling shutter (RS) cameras (if used). We investigate different inertial model variants containing IMU intrinsic parameters that encompass most commonly used models for low-cost inertial sensors. The observability analysis results prove that VINS with full sensor calibration has four unobservable directions, corresponding to the system's global yaw and translation, while all sensor calibration parameters are observable given fully-excited 6-axis motion. Moreover, we, for the first time, identify primitive degenerate motions for IMU and camera intrinsic calibration. Each degenerate motion profile will cause a set of calibration parameters to be unobservable and any combination of these degenerate motions are still degenerate. Extensive Monte-Carlo simulations and real-world experiments are performed to validate both the observability analysis and identified degenerate motions, showing that online self-calibration improves system accuracy and robustness to calibration inaccuracies. We compare the proposed online self-calibration on commonly-used IMUs against the state-of-art offline calibration toolbox Kalibr, and show that the proposed system achieves better consistency and repeatability. Based on our analysis and experimental evaluations, we also provide practical guidelines for how to perform online IMU-camera sensor self-calibration.
Do autoencoders need a bottleneck for anomaly detection?
Feb 25, 2022



A common belief in designing deep autoencoders (AEs), a type of unsupervised neural network, is that a bottleneck is required to prevent learning the identity function. Learning the identity function renders the AEs useless for anomaly detection. In this work, we challenge this limiting belief and investigate the value of non-bottlenecked AEs. The bottleneck can be removed in two ways: (1) overparameterising the latent layer, and (2) introducing skip connections. However, limited works have reported on the use of one of the ways. For the first time, we carry out extensive experiments covering various combinations of bottleneck removal schemes, types of AEs and datasets. In addition, we propose the infinitely-wide AEs as an extreme example of non-bottlenecked AEs. Their improvement over the baseline implies learning the identity function is not trivial as previously assumed. Moreover, we find that non-bottlenecked architectures (highest AUROC=0.857) can outperform their bottlenecked counterparts (highest AUROC=0.696) on the popular task of CIFAR (inliers) vs SVHN (anomalies), among other tasks, shedding light on the potential of developing non-bottlenecked AEs for improving anomaly detection.
Real Time Face Recognition Using Convoluted Neural Networks
Oct 09, 2020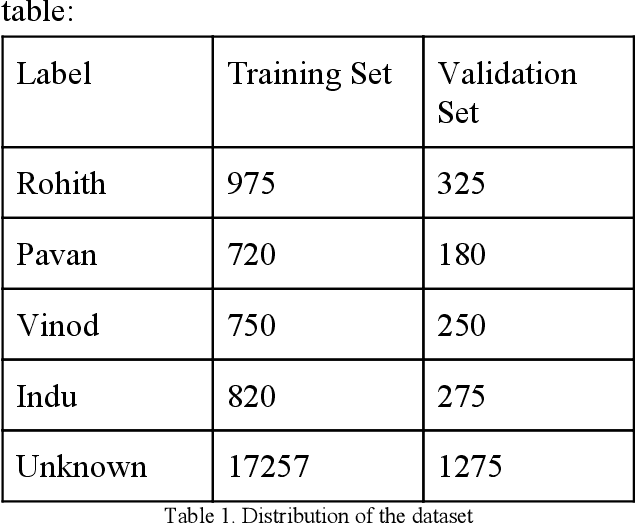
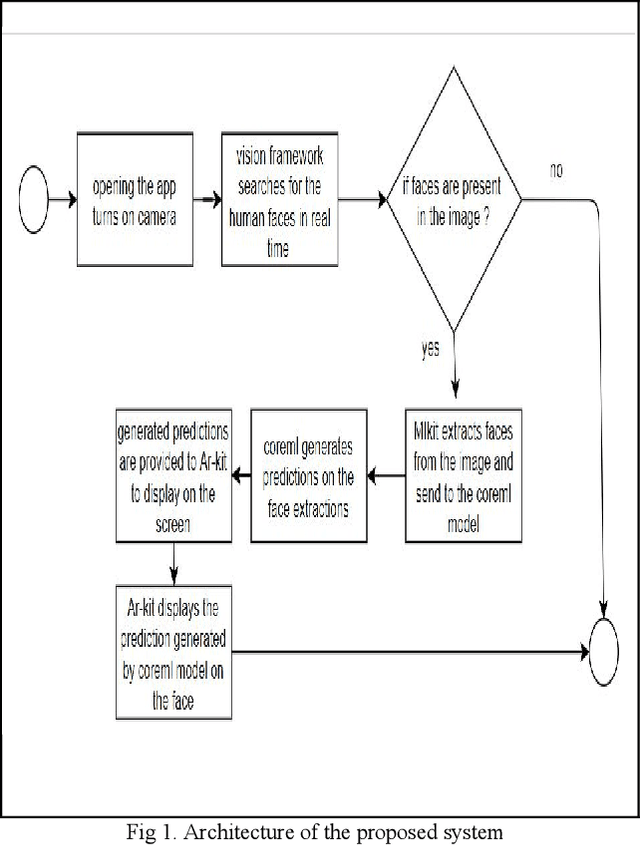
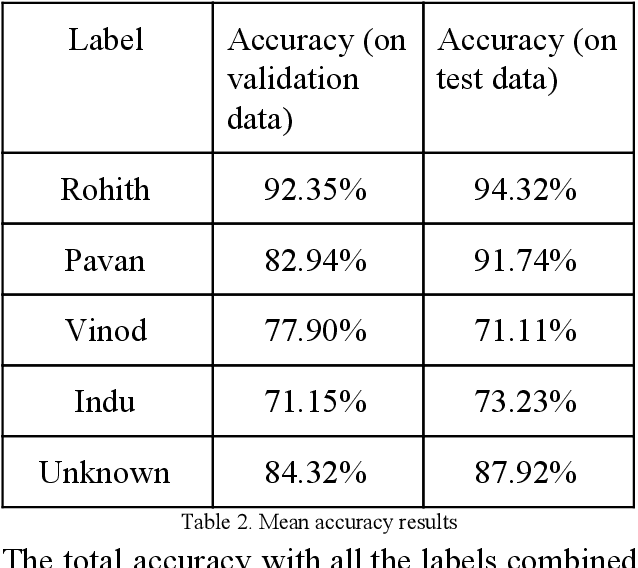

Face Recognition is one of the process of identifying people using their face, it has various applications like authentication systems, surveillance systems and law enforcement. Convolutional Neural Networks are proved to be best for facial recognition. Detecting faces using core-ml api and processing the extracted face through a coreML model, which is trained to recognize specific persons. The creation of dataset is done by converting face videos of the persons to be recognized into Hundreds of images of person, which is further used for training and validation of the model to provide accurate real-time results.
An Empirical Study of Explainable AI Techniques on Deep Learning Models For Time Series Tasks
Dec 08, 2020Decision explanations of machine learning black-box models are often generated by applying Explainable AI (XAI) techniques. However, many proposed XAI methods produce unverified outputs. Evaluation and verification are usually achieved with a visual interpretation by humans on individual images or text. In this preregistration, we propose an empirical study and benchmark framework to apply attribution methods for neural networks developed for images and text data on time series. We present a methodology to automatically evaluate and rank attribution techniques on time series using perturbation methods to identify reliable approaches.
Multivariate Time Series Classification with Hierarchical Variational Graph Pooling
Oct 12, 2020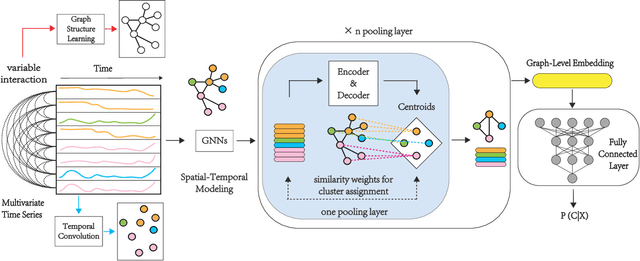
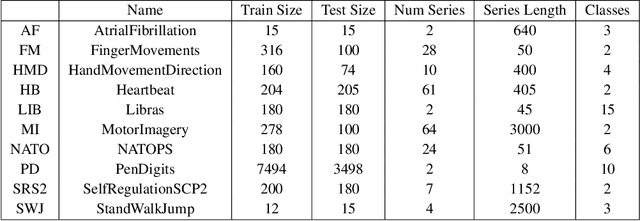
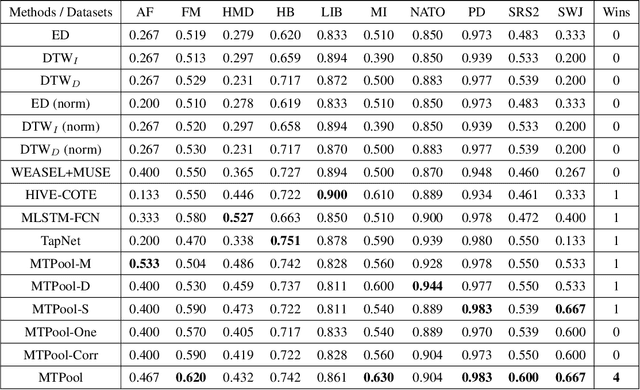
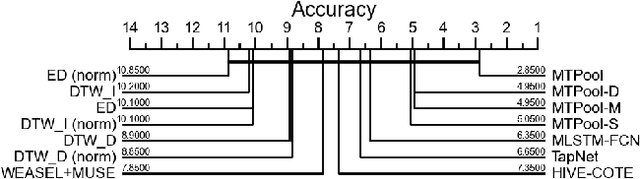
Over the past decade, multivariate time series classification (MTSC) has received great attention with the advance of sensing techniques. Current deep learning methods for MTSC are based on convolutional and recurrent neural network, with the assumption that time series variables have the same effect to each other. Thus they cannot model the pairwise dependencies among variables explicitly. What's more, current spatial-temporal modeling methods based on GNNs are inherently flat and lack the capability of aggregating node information in a hierarchical manner. To address this limitation and attain expressive global representation of MTS, we propose a graph pooling based framework MTPool and view MTSC task as graph classification task. With graph structure learning and temporal convolution, MTS slices are converted to graphs and spatial-temporal features are extracted. Then, we propose a novel graph pooling method, which uses an ``encoder-decoder'' mechanism to generate adaptive centroids for cluster assignments. GNNs and graph pooling layers are used for joint graph representation learning and graph coarsening. With multiple graph pooling layers, the input graphs are hierachically coarsened to one node. Finally, differentiable classifier takes this coarsened one-node graph as input to get the final predicted class. Experiments on 10 benchmark datasets demonstrate MTPool outperforms state-of-the-art methods in MTSC tasks.
BlazePose: On-device Real-time Body Pose tracking
Jun 17, 2020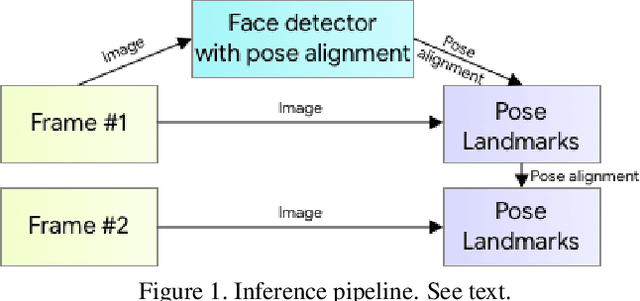
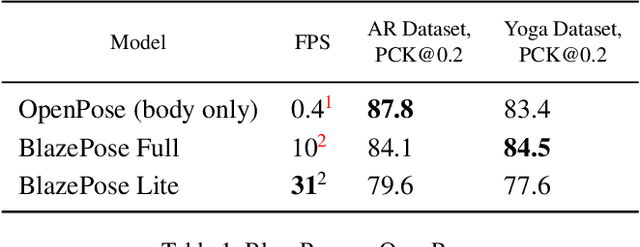
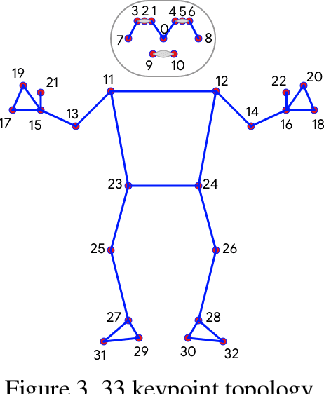
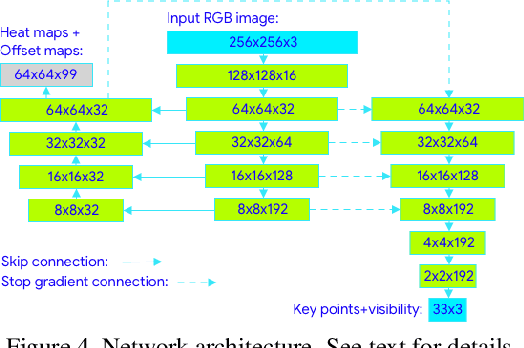
We present BlazePose, a lightweight convolutional neural network architecture for human pose estimation that is tailored for real-time inference on mobile devices. During inference, the network produces 33 body keypoints for a single person and runs at over 30 frames per second on a Pixel 2 phone. This makes it particularly suited to real-time use cases like fitness tracking and sign language recognition. Our main contributions include a novel body pose tracking solution and a lightweight body pose estimation neural network that uses both heatmaps and regression to keypoint coordinates.
RRL:Regional Rotation Layer in Convolutional Neural Networks
Feb 25, 2022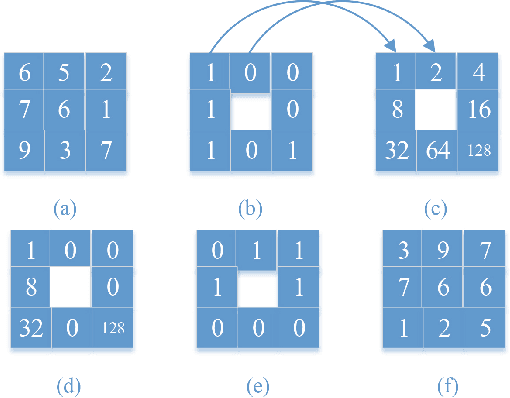
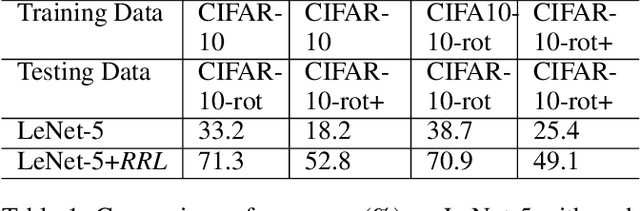
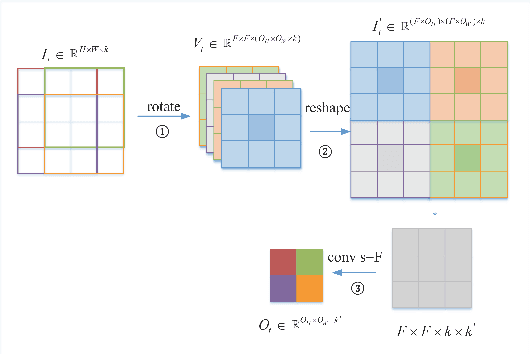
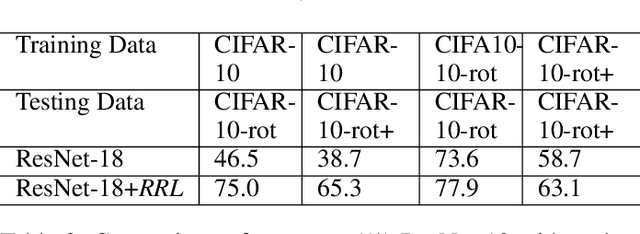
Convolutional Neural Networks (CNNs) perform very well in image classification and object detection in recent years, but even the most advanced models have limited rotation invariance. Known solutions include the enhancement of training data and the increase of rotation invariance by globally merging the rotation equivariant features. These methods either increase the workload of training or increase the number of model parameters. To address this problem, this paper proposes a module that can be inserted into the existing networks, and directly incorporates the rotation invariance into the feature extraction layers of the CNNs. This module does not have learnable parameters and will not increase the complexity of the model. At the same time, only by training the upright data, it can perform well on the rotated testing set. These advantages will be suitable for fields such as biomedicine and astronomy where it is difficult to obtain upright samples or the target has no directionality. Evaluate our module with LeNet-5, ResNet-18 and tiny-yolov3, we get impressive results.