 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PUTN: A Plane-fitting based Uneven Terrain Navigation Framework
Mar 09, 2022

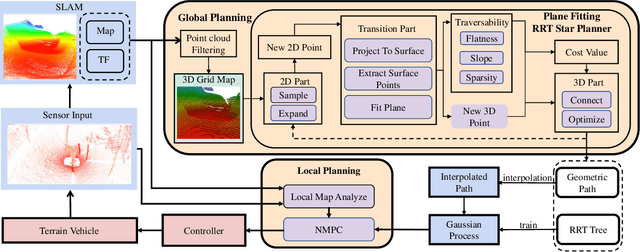
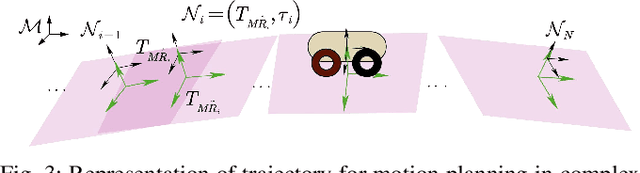
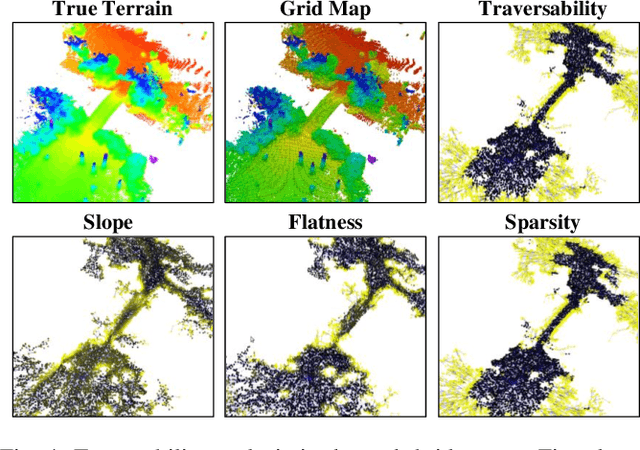
Autonomous navigation of ground robots has been widely used in indoor structured 2D environments, but there are still many challenges in outdoor 3D unstructured environments, especially in rough, uneven terrains. This paper proposed a plane-fitting based uneven terrain navigation framework (PUTN) to solve this problem. The implementation of PUTN is divided into three steps. First, based on Rapidly-exploring Random Trees (RRT), an improved sample-based algorithm called Plane Fitting RRT* (PF-RRT*) is proposed to obtain a sparse trajectory. Each sampling point corresponds to a custom traversability index and a fitted plane on the point cloud. These planes are connected in series to form a traversable strip. Second, Gaussian Process Regression is used to generate traversability of the dense trajectory interpolated from the sparse trajectory, and the sampling tree is used as the training set. Finally, local planning is performed using nonlinear model predictive control (NMPC). By adding the traversability index and uncertainty to the cost function, and adding obstacles generated by the real-time point cloud to the constraint function, a safe motion planning algorithm with smooth speed and strong robustness is available. Experiments in real scenarios are conducted to verify the effectiveness of the method.
Two-stage Deep Stacked Autoencoder with Shallow Learning for Network Intrusion Detection System
Dec 03, 2021
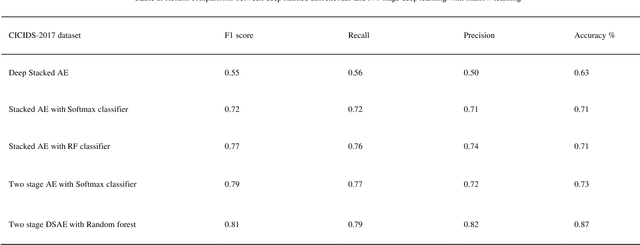
Sparse events, such as malign attacks in real-time network traffic, have caused big organisations an immense hike in revenue loss. This is due to the excessive growth of the network and its exposure to a plethora of people. The standard methods used to detect intrusions are not promising and have significant failure to identify new malware. Moreover, the challenges in handling high volume data with sparsity, high false positives, fewer detection rates in minor class, training time and feature engineering of the dimensionality of data has promoted deep learning to take over the task with less time and great results. The existing system needs improvement in solving real-time network traffic issues along with feature engineering. Our proposed work overcomes these challenges by giving promising results using deep-stacked autoencoders in two stages. The two-stage deep learning combines with shallow learning using the random forest for classification in the second stage. This made the model get well with the latest Canadian Institute for Cybersecurity - Intrusion Detection System 2017 (CICIDS-2017) dataset. Zero false positives with admirable detection accuracy were achieved.
Scalable Sampling for Nonsymmetric Determinantal Point Processes
Jan 20, 2022
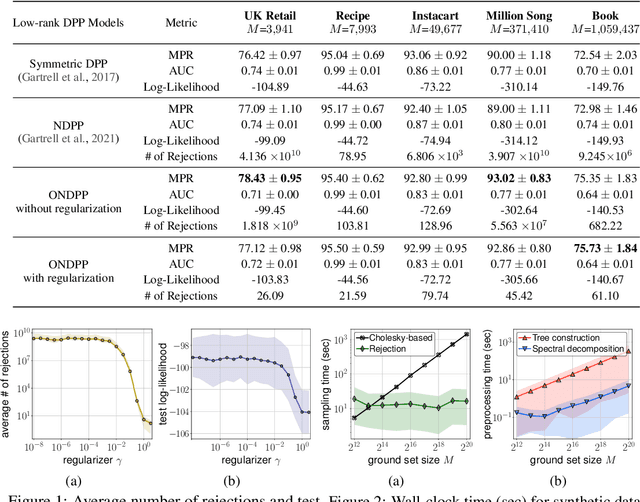
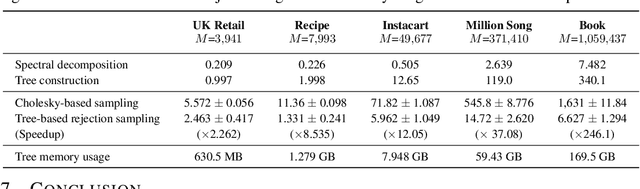
A determinantal point process (DPP) on a collection of $M$ items is a model, parameterized by a symmetric kernel matrix, that assigns a probability to every subset of those items. Recent work shows that removing the kernel symmetry constraint, yielding nonsymmetric DPPs (NDPPs), can lead to significant predictive performance gains for machine learning applications. However, existing work leaves open the question of scalable NDPP sampling. There is only one known DPP sampling algorithm, based on Cholesky decomposition, that can directly apply to NDPPs as well. Unfortunately, its runtime is cubic in $M$, and thus does not scale to large item collections. In this work, we first note that this algorithm can be transformed into a linear-time one for kernels with low-rank structure. Furthermore, we develop a scalable sublinear-time rejection sampling algorithm by constructing a novel proposal distribution. Additionally, we show that imposing certain structural constraints on the NDPP kernel enables us to bound the rejection rate in a way that depends only on the kernel rank. In our experiments we compare the speed of all of these samplers for a variety of real-world tasks.
Dynamic Least-Squares Regression
Jan 01, 2022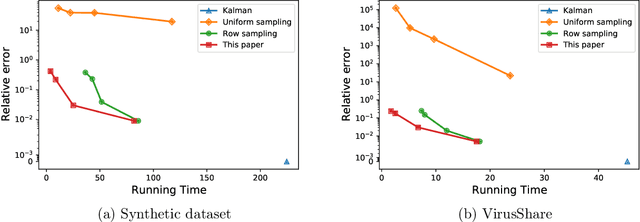
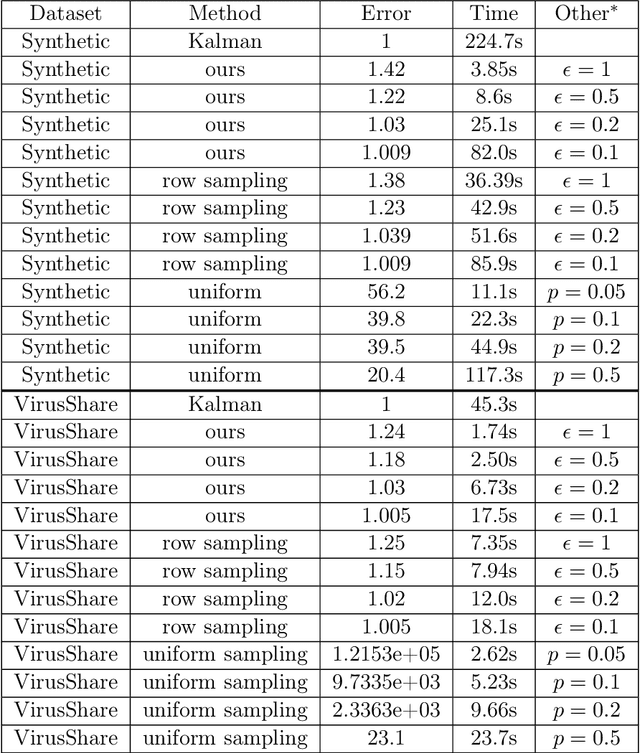
A common challenge in large-scale supervised learning, is how to exploit new incremental data to a pre-trained model, without re-training the model from scratch. Motivated by this problem, we revisit the canonical problem of dynamic least-squares regression (LSR), where the goal is to learn a linear model over incremental training data. In this setup, data and labels $(\mathbf{A}^{(t)}, \mathbf{b}^{(t)}) \in \mathbb{R}^{t \times d}\times \mathbb{R}^t$ evolve in an online fashion ($t\gg d$), and the goal is to efficiently maintain an (approximate) solution to $\min_{\mathbf{x}^{(t)}} \| \mathbf{A}^{(t)} \mathbf{x}^{(t)} - \mathbf{b}^{(t)} \|_2$ for all $t\in [T]$. Our main result is a dynamic data structure which maintains an arbitrarily small constant approximate solution to dynamic LSR with amortized update time $O(d^{1+o(1)})$, almost matching the running time of the static (sketching-based) solution. By contrast, for exact (or even $1/\mathrm{poly}(n)$-accuracy) solutions, we show a separation between the static and dynamic settings, namely, that dynamic LSR requires $\Omega(d^{2-o(1)})$ amortized update time under the OMv Conjecture (Henzinger et al., STOC'15). Our data structure is conceptually simple, easy to implement, and fast both in theory and practice, as corroborated by experiments over both synthetic and real-world datasets.
A novel audio representation using space filling curves
Jan 08, 2022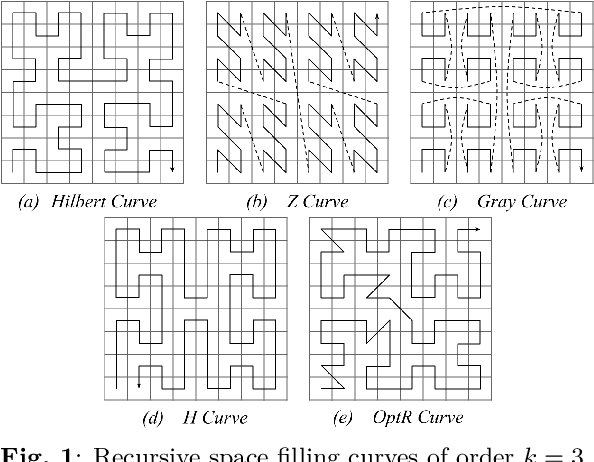
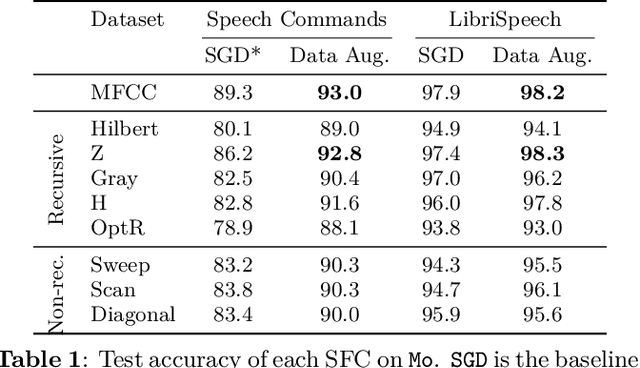
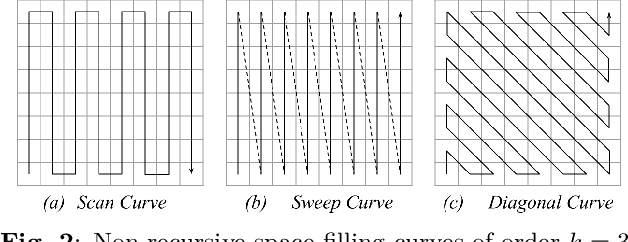
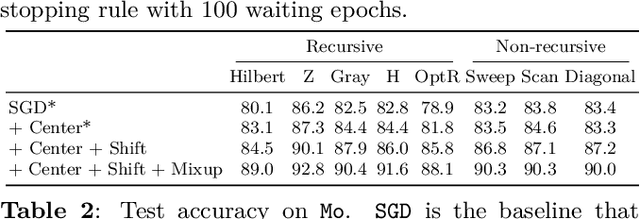
Since convolutional neural networks (CNNs) have revolutionized the image processing field, they have been widely applied in the audio context. A common approach is to convert the one-dimensional audio signal time series to two-dimensional images using a time-frequency decomposition method. Also it is common to discard the phase information. In this paper, we propose to map one-dimensional audio waveforms to two-dimensional images using space filling curves (SFCs). These mappings do not compress the input signal, while preserving its local structure. Moreover, the mappings benefit from progress made in deep learning and the large collection of existing computer vision networks. We test eight SFCs on two keyword spotting problems. We show that the Z curve yields the best results due to its shift equivariance under convolution operations. Additionally, the Z curve produces comparable results to the widely used mel frequency cepstral coefficients across multiple CNNs.
Extension of Convolutional Neural Network along Temporal and Vertical Directions for Precipitation Downscaling
Dec 13, 2021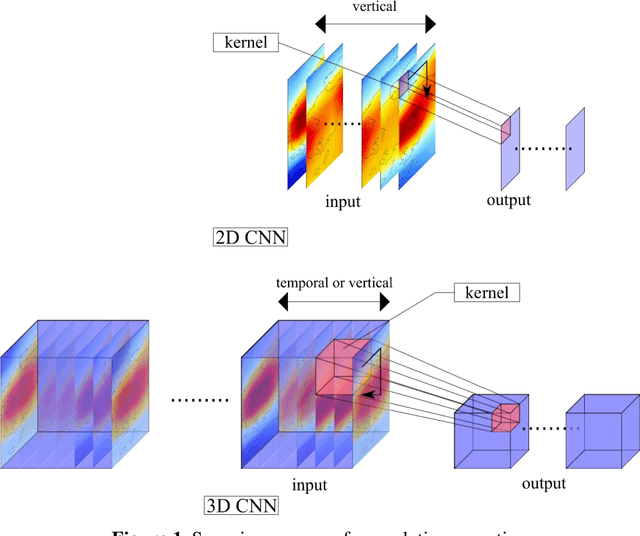

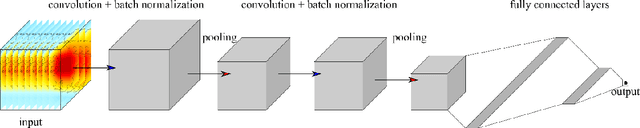
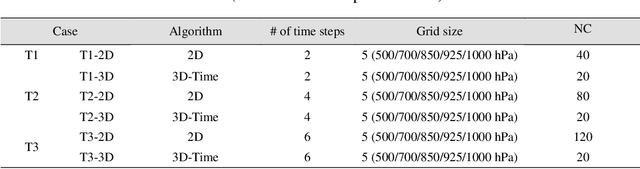
Deep learning has been utilized for the statistical downscaling of climate data. Specifically, a two-dimensional (2D) convolutional neural network (CNN) has been successfully applied to precipitation estimation. This study implements a three-dimensional (3D) CNN to estimate watershed-scale daily precipitation from 3D atmospheric data and compares the results with those for a 2D CNN. The 2D CNN is extended along the time direction (3D-CNN-Time) and the vertical direction (3D-CNN-Vert). The precipitation estimates of these extended CNNs are compared with those of the 2D CNN in terms of the root-mean-square error (RMSE), Nash-Sutcliffe efficiency (NSE), and 99th percentile RMSE. It is found that both 3D-CNN-Time and 3D-CNN-Vert improve the model accuracy for precipitation estimation compared to the 2D CNN. 3D-CNN-Vert provided the best estimates during the training and test periods in terms of RMSE and NSE.
A Two-Stage U-Net for High-Fidelity Denoising of Historical Recordings
Feb 19, 2022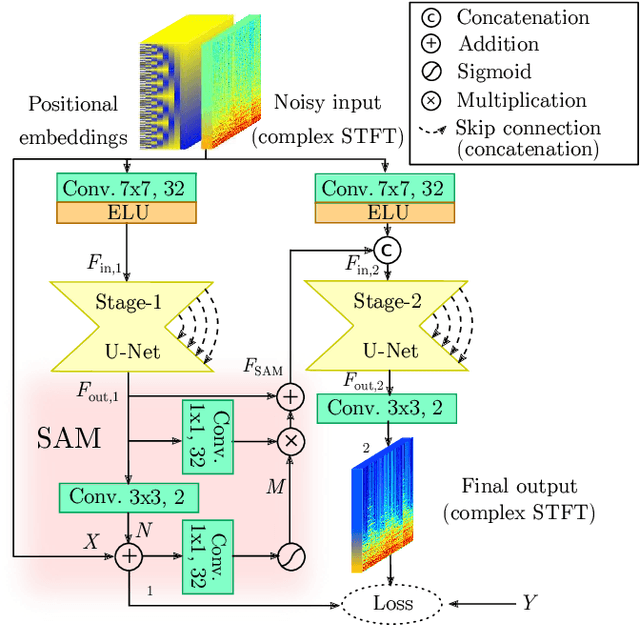
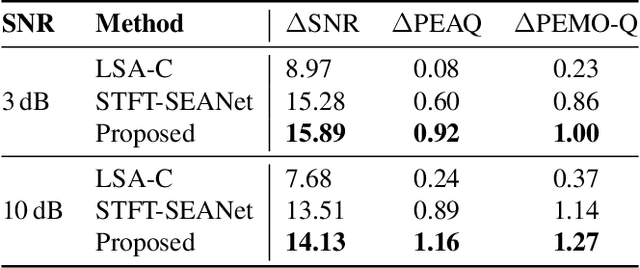
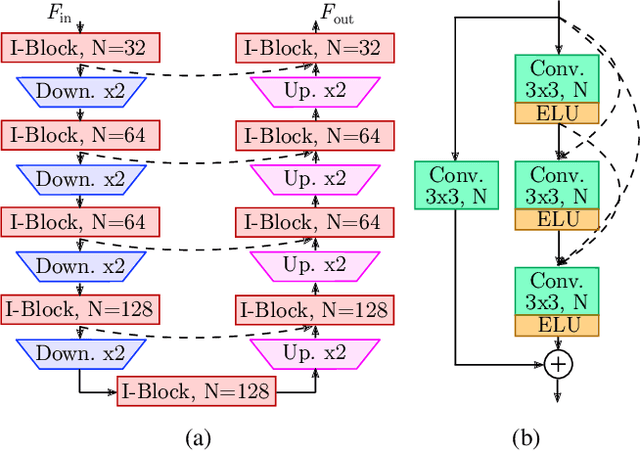
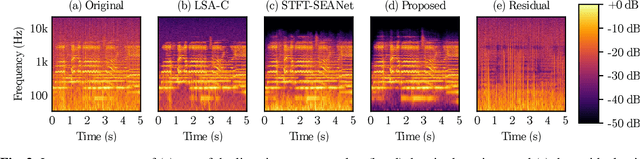
Enhancing the sound quality of historical music recordings is a long-standing problem. This paper presents a novel denoising method based on a fully-convolutional deep neural network. A two-stage U-Net model architecture is designed to model and suppress the degradations with high fidelity. The method processes the time-frequency representation of audio, and is trained using realistic noisy data to jointly remove hiss, clicks, thumps, and other common additive disturbances from old analog discs. The proposed model outperforms previous methods in both objective and subjective metrics. The results of a formal blind listening test show that real gramophone recordings denoised with this method have significantly better quality than the baseline methods. This study shows the importance of realistic training data and the power of deep learning in audio restoration.
Solving Random Parity Games in Polynomial Time
Jul 16, 2020
We consider the problem of solving random parity games. We prove that parity games exibit a phase transition threshold above $d_P$, so that when the degree of the graph that defines the game has a degree $d > d_P$ then there exists a polynomial time algorithm that solves the game with high probability when the number of nodes goes to infinity. We further propose the SWCP (Self-Winning Cycles Propagation) algorithm and show that, when the degree is large enough, SWCP solves the game with high probability. Furthermore, the complexity of SWCP is polynomial $O\Big(|{\cal V}|^2 + |{\cal V}||{\cal E}|\Big)$. The design of SWCP is based on the threshold for the appearance of particular types of cycles in the players' respective subgraphs. We further show that non-sparse games can be solved in time $O(|{\cal V}|)$ with high probability, and emit a conjecture concerning the hardness of the $d=2$ case.
Learning Resource Allocation Policies from Observational Data with an Application to Homeless Services Delivery
Jan 25, 2022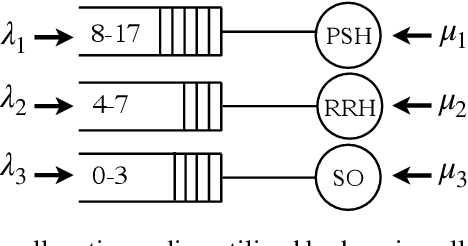
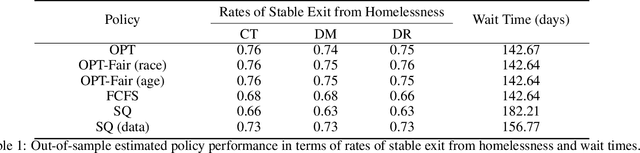
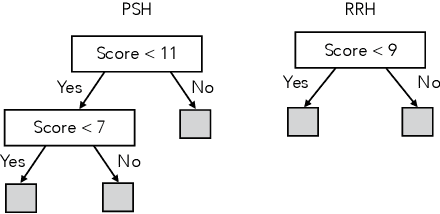
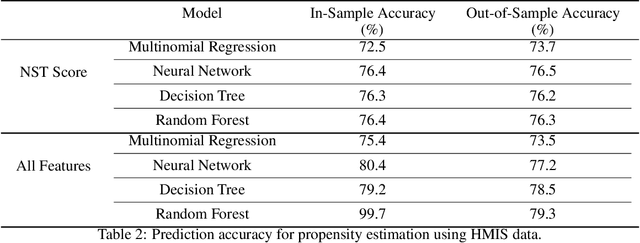
We study the problem of learning, from observational data, fair and interpretable policies that effectively match heterogeneous individuals to scarce resources of different types. We model this problem as a multi-class multi-server queuing system where both individuals and resources arrive stochastically over time. Each individual, upon arrival, is assigned to a queue where they wait to be matched to a resource. The resources are assigned in a first come first served (FCFS) fashion according to an eligibility structure that encodes the resource types that serve each queue. We propose a methodology based on techniques in modern causal inference to construct the individual queues as well as learn the matching outcomes and provide a mixed-integer optimization (MIO) formulation to optimize the eligibility structure. The MIO problem maximizes policy outcome subject to wait time and fairness constraints. It is very flexible, allowing for additional linear domain constraints. We conduct extensive analyses using synthetic and real-world data. In particular, we evaluate our framework using data from the U.S. Homeless Management Information System (HMIS). We obtain wait times as low as an FCFS policy while improving the rate of exit from homelessness for underserved or vulnerable groups (7% higher for the Black individuals and 15% higher for those below 17 years old) and overall.
ILDAE: Instance-Level Difficulty Analysis of Evaluation Data
Mar 09, 2022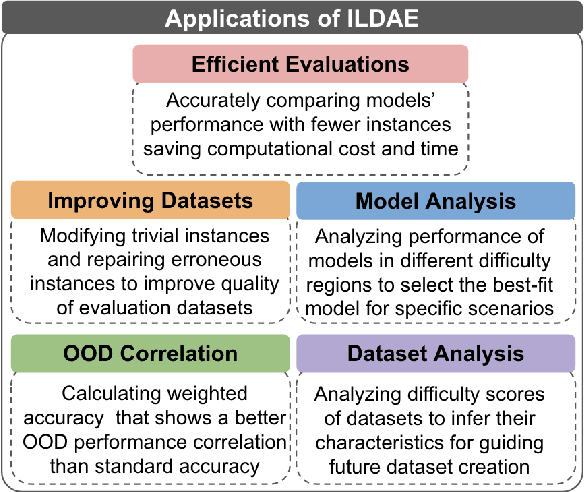
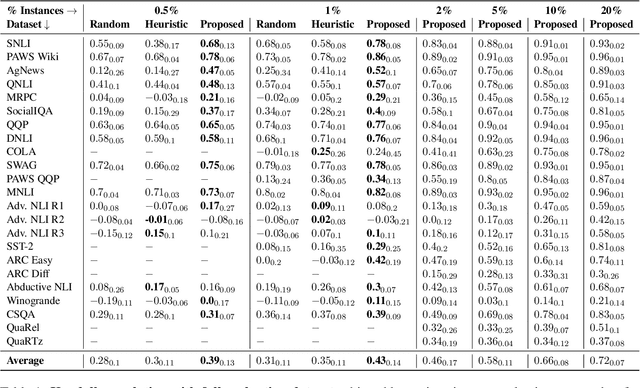
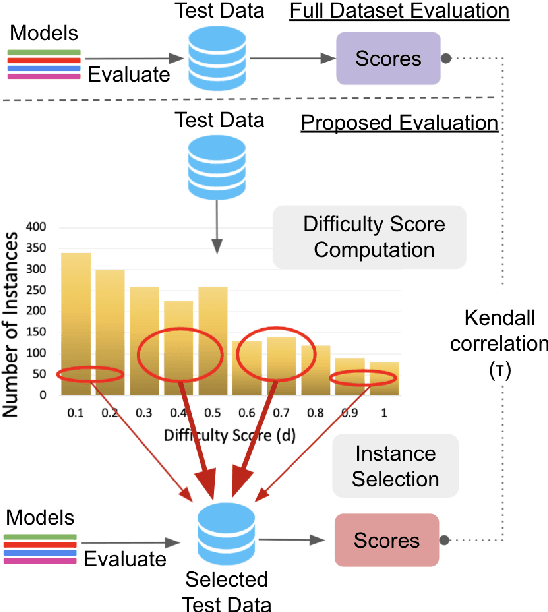

Knowledge of questions' difficulty level helps a teacher in several ways, such as estimating students' potential quickly by asking carefully selected questions and improving quality of examination by modifying trivial and hard questions. Can we extract such benefits of instance difficulty in NLP? To this end, we conduct Instance-Level Difficulty Analysis of Evaluation data (ILDAE) in a large-scale setup of 23 datasets and demonstrate its five novel applications: 1) conducting efficient-yet-accurate evaluations with fewer instances saving computational cost and time, 2) improving quality of existing evaluation datasets by repairing erroneous and trivial instances, 3) selecting the best model based on application requirements, 4) analyzing dataset characteristics for guiding future data creation, 5) estimating Out-of-Domain performance reliably. Comprehensive experiments for these applications result in several interesting findings, such as evaluation using just 5% instances (selected via ILDAE) achieves as high as 0.93 Kendall correlation with evaluation using complete dataset and computing weighted accuracy using difficulty scores leads to 5.2% higher correlation with Out-of-Domain performance. We release the difficulty scores and hope our analyses and findings will bring more attention to this important yet understudied field of leveraging instance difficulty in evaluations.