 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
S3T: Self-Supervised Pre-training with Swin Transformer for Music Classification
Feb 21, 2022
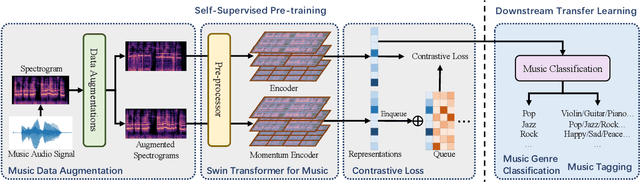
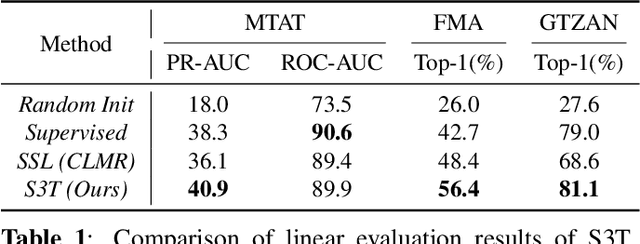
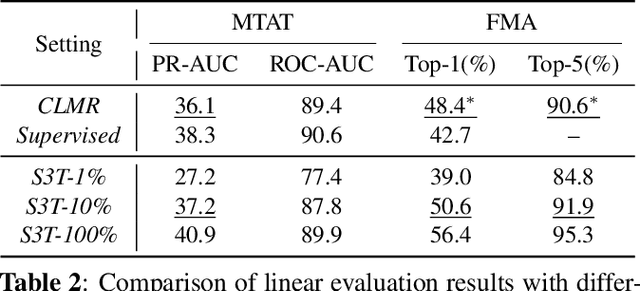
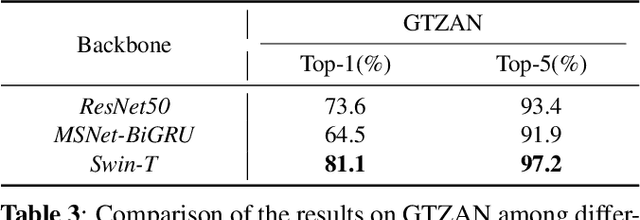
In this paper, we propose S3T, a self-supervised pre-training method with Swin Transformer for music classification, aiming to learn meaningful music representations from massive easily accessible unlabeled music data. S3T introduces a momentum-based paradigm, MoCo, with Swin Transformer as its feature extractor to music time-frequency domain. For better music representations learning, S3T contributes a music data augmentation pipeline and two specially designed pre-processors. To our knowledge, S3T is the first method combining the Swin Transformer with a self-supervised learning method for music classification. We evaluate S3T on music genre classification and music tagging tasks with linear classifiers trained on learned representations. Experimental results show that S3T outperforms the previous self-supervised method (CLMR) by 12.5 percents top-1 accuracy and 4.8 percents PR-AUC on two tasks respectively, and also surpasses the task-specific state-of-the-art supervised methods. Besides, S3T shows advances in label efficiency using only 10% labeled data exceeding CLMR on both tasks with 100% labeled data.
OSSID: Online Self-Supervised Instance Detection by (and for) Pose Estimation
Jan 18, 2022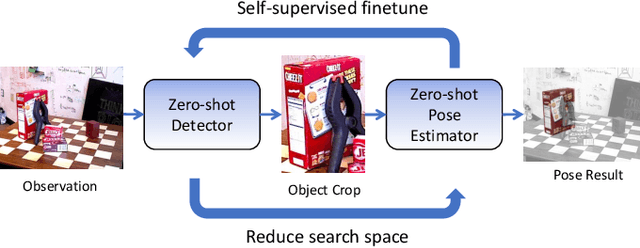
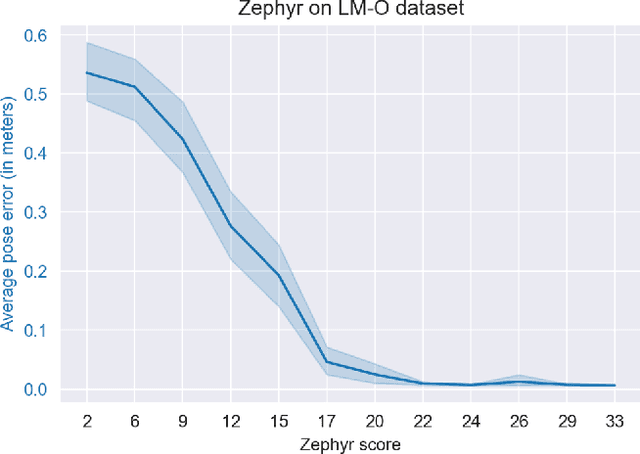
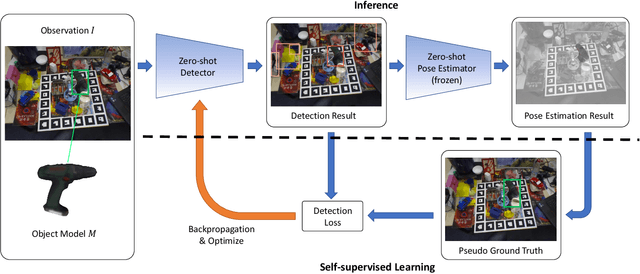
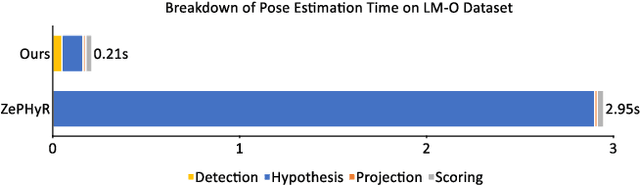
Real-time object pose estimation is necessary for many robot manipulation algorithms. However, state-of-the-art methods for object pose estimation are trained for a specific set of objects; these methods thus need to be retrained to estimate the pose of each new object, often requiring tens of GPU-days of training for optimal performance. \revisef{In this paper, we propose the OSSID framework,} leveraging a slow zero-shot pose estimator to self-supervise the training of a fast detection algorithm. This fast detector can then be used to filter the input to the pose estimator, drastically improving its inference speed. We show that this self-supervised training exceeds the performance of existing zero-shot detection methods on two widely used object pose estimation and detection datasets, without requiring any human annotations. Further, we show that the resulting method for pose estimation has a significantly faster inference speed, due to the ability to filter out large parts of the image. Thus, our method for self-supervised online learning of a detector (trained using pseudo-labels from a slow pose estimator) leads to accurate pose estimation at real-time speeds, without requiring human annotations. Supplementary materials and code can be found at https://georgegu1997.github.io/OSSID/
Reinforcement Learning with Time-dependent Goals for Robotic Musicians
Nov 11, 2020

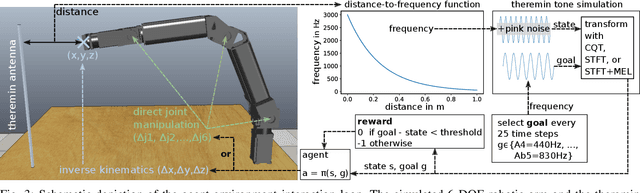

Reinforcement learning is a promising method to accomplish robotic control tasks. The task of playing musical instruments is, however, largely unexplored because it involves the challenge of achieving sequential goals - melodies - that have a temporal dimension. In this paper, we address robotic musicianship by introducing a temporal extension to goal-conditioned reinforcement learning: Time-dependent goals. We demonstrate that these can be used to train a robotic musician to play the theremin instrument. We train the robotic agent in simulation and transfer the acquired policy to a real-world robotic thereminist. Supplemental video: https://youtu.be/jvC9mPzdQN4
Modelling word learning and recognition using visually grounded speech
Mar 14, 2022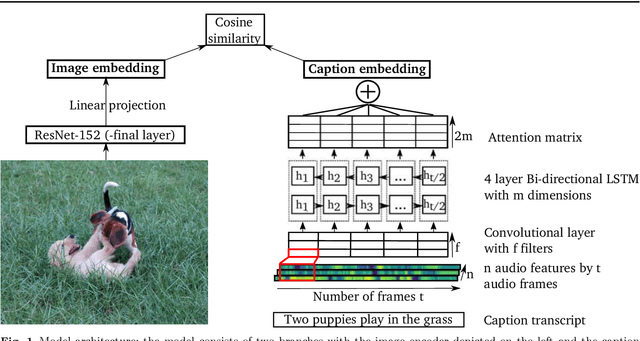
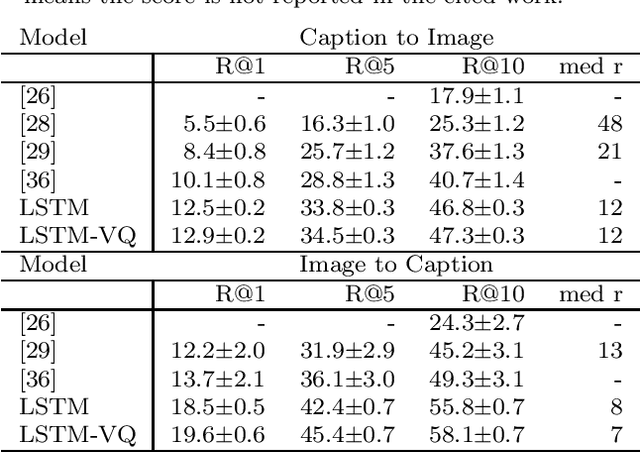
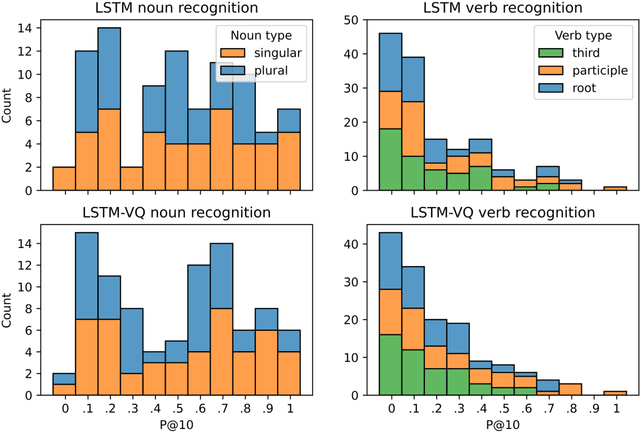
Background: Computational models of speech recognition often assume that the set of target words is already given. This implies that these models do not learn to recognise speech from scratch without prior knowledge and explicit supervision. Visually grounded speech models learn to recognise speech without prior knowledge by exploiting statistical dependencies between spoken and visual input. While it has previously been shown that visually grounded speech models learn to recognise the presence of words in the input, we explicitly investigate such a model as a model of human speech recognition. Methods: We investigate the time-course of word recognition as simulated by the model using a gating paradigm to test whether its recognition is affected by well-known word-competition effects in human speech processing. We furthermore investigate whether vector quantisation, a technique for discrete representation learning, aids the model in the discovery and recognition of words. Results/Conclusion: Our experiments show that the model is able to recognise nouns in isolation and even learns to properly differentiate between plural and singular nouns. We also find that recognition is influenced by word competition from the word-initial cohort and neighbourhood density, mirroring word competition effects in human speech comprehension. Lastly, we find no evidence that vector quantisation is helpful in discovering and recognising words. Our gating experiments even show that the vector quantised model requires more of the input sequence for correct recognition.
Adversarial Examples in Deep Learning for Multivariate Time Series Regression
Sep 24, 2020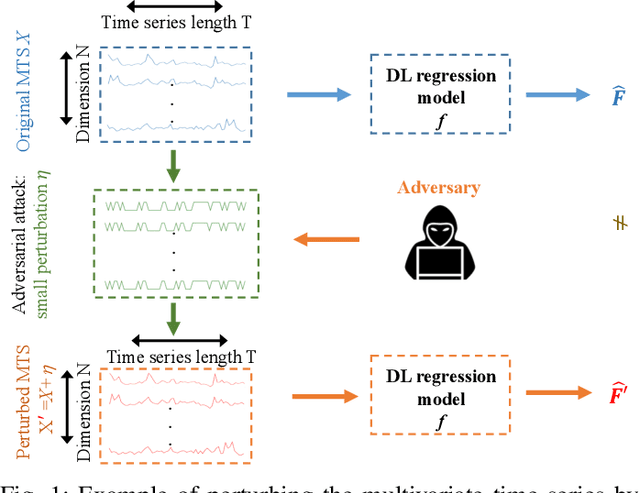
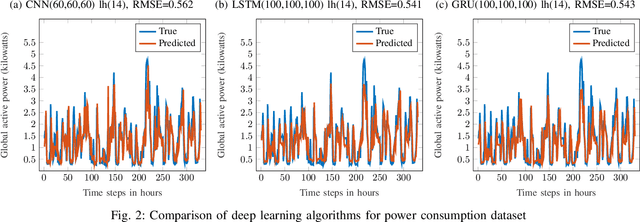
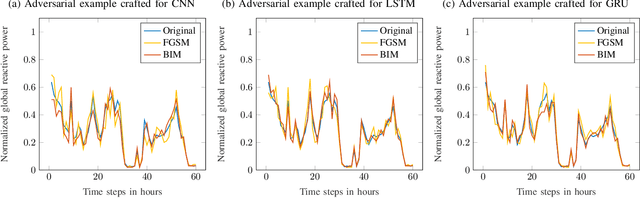
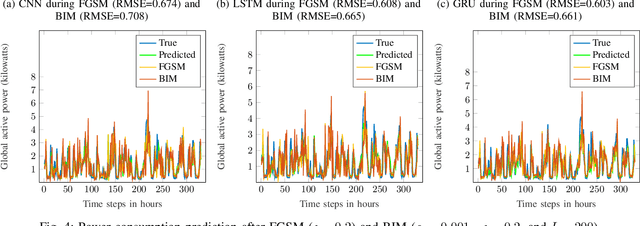
Multivariate time series (MTS) regression tasks are common in many real-world data mining applications including finance, cybersecurity, energy, healthcare, prognostics, and many others. Due to the tremendous success of deep learning (DL) algorithms in various domains including image recognition and computer vision, researchers started adopting these techniques for solving MTS data mining problems, many of which are targeted for safety-critical and cost-critical applications. Unfortunately, DL algorithms are known for their susceptibility to adversarial examples which also makes the DL regression models for MTS forecasting also vulnerable to those attacks. To the best of our knowledge, no previous work has explored the vulnerability of DL MTS regression models to adversarial time series examples, which is an important step, specifically when the forecasting from such models is used in safety-critical and cost-critical applications. In this work, we leverage existing adversarial attack generation techniques from the image classification domain and craft adversarial multivariate time series examples for three state-of-the-art deep learning regression models, specifically Convolutional Neural Network (CNN), Long Short-Term Memory (LSTM), and Gated Recurrent Unit (GRU). We evaluate our study using Google stock and household power consumption dataset. The obtained results show that all the evaluated DL regression models are vulnerable to adversarial attacks, transferable, and thus can lead to catastrophic consequences in safety-critical and cost-critical domains, such as energy and finance.
ADVISE: ADaptive Feature Relevance and VISual Explanations for Convolutional Neural Networks
Mar 02, 2022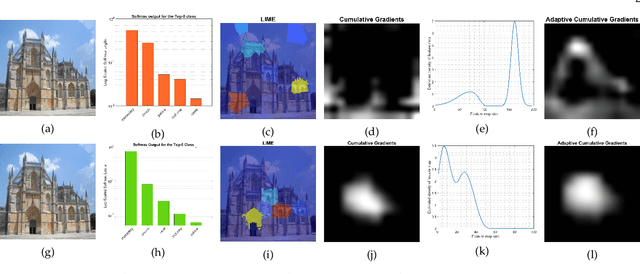
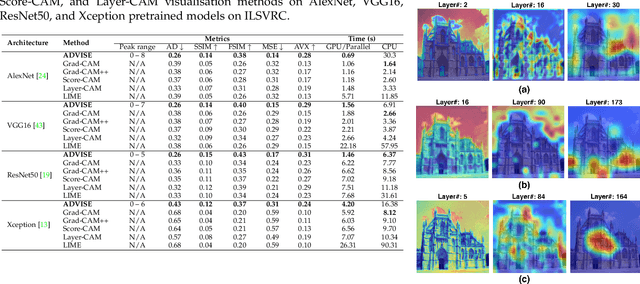
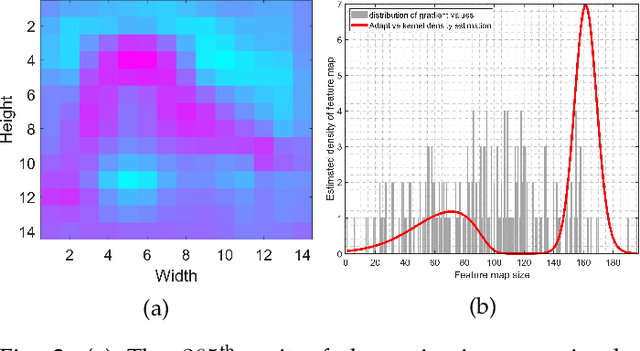
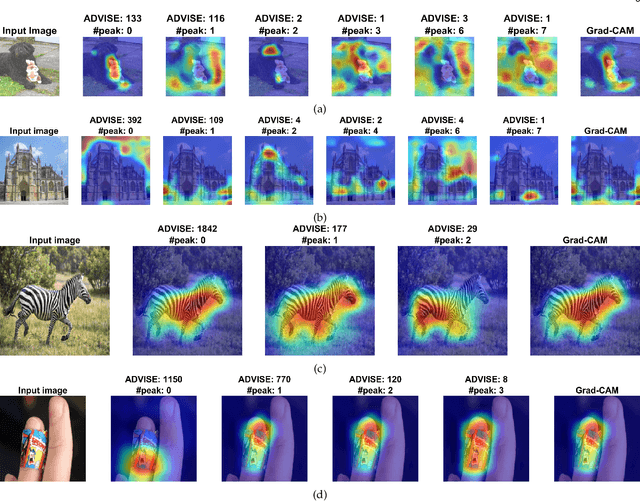
To equip Convolutional Neural Networks (CNNs) with explainability, it is essential to interpret how opaque models take specific decisions, understand what causes the errors, improve the architecture design, and identify unethical biases in the classifiers. This paper introduces ADVISE, a new explainability method that quantifies and leverages the relevance of each unit of the feature map to provide better visual explanations. To this end, we propose using adaptive bandwidth kernel density estimation to assign a relevance score to each unit of the feature map with respect to the predicted class. We also propose an evaluation protocol to quantitatively assess the visual explainability of CNN models. We extensively evaluate our idea in the image classification task using AlexNet, VGG16, ResNet50, and Xception pretrained on ImageNet. We compare ADVISE with the state-of-the-art visual explainable methods and show that the proposed method outperforms competing approaches in quantifying feature-relevance and visual explainability while maintaining competitive time complexity. Our experiments further show that ADVISE fulfils the sensitivity and implementation independence axioms while passing the sanity checks. The implementation is accessible for reproducibility purposes on https://github.com/dehshibi/ADVISE.
Social-Implicit: Rethinking Trajectory Prediction Evaluation and The Effectiveness of Implicit Maximum Likelihood Estimation
Mar 06, 2022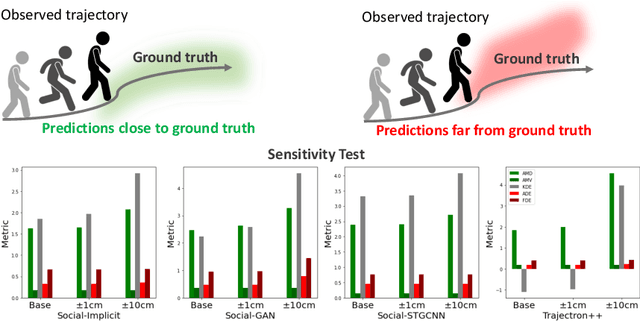
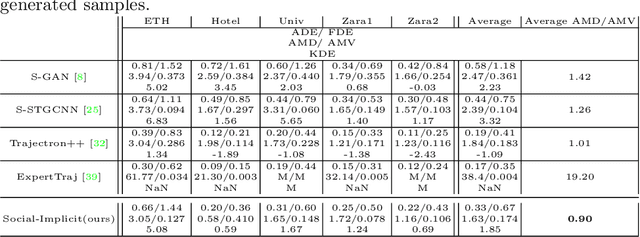
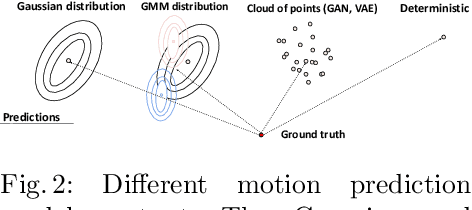
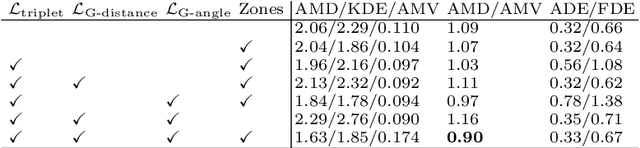
Best-of-N (BoN) Average Displacement Error (ADE)/ Final Displacement Error (FDE) is the most used metric for evaluating trajectory prediction models. Yet, the BoN does not quantify the whole generated samples, resulting in an incomplete view of the model's prediction quality and performance. We propose a new metric, Average Mahalanobis Distance (AMD) to tackle this issue. AMD is a metric that quantifies how close the whole generated samples are to the ground truth. We also introduce the Average Maximum Eigenvalue (AMV) metric that quantifies the overall spread of the predictions. Our metrics are validated empirically by showing that the ADE/FDE is not sensitive to distribution shifts, giving a biased sense of accuracy, unlike the AMD/AMV metrics. We introduce the usage of Implicit Maximum Likelihood Estimation (IMLE) as a replacement for traditional generative models to train our model, Social-Implicit. IMLE training mechanism aligns with AMD/AMV objective of predicting trajectories that are close to the ground truth with a tight spread. Social-Implicit is a memory efficient deep model with only 5.8K parameters that runs in real time of about 580Hz and achieves competitive results. Interactive demo of the problem can be seen here \url{https://www.abduallahmohamed.com/social-implicit-amdamv-adefde-demo}. Code is available at \url{https://github.com/abduallahmohamed/Social-Implicit}.
Signal Decomposition Using Masked Proximal Operators
Mar 02, 2022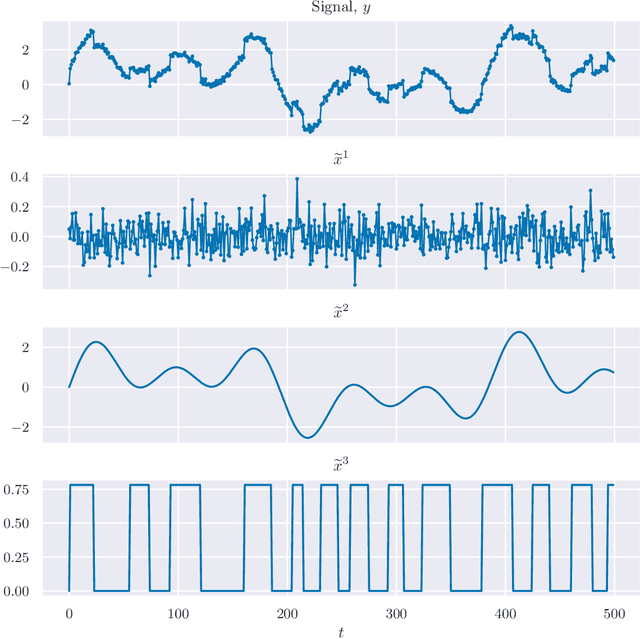
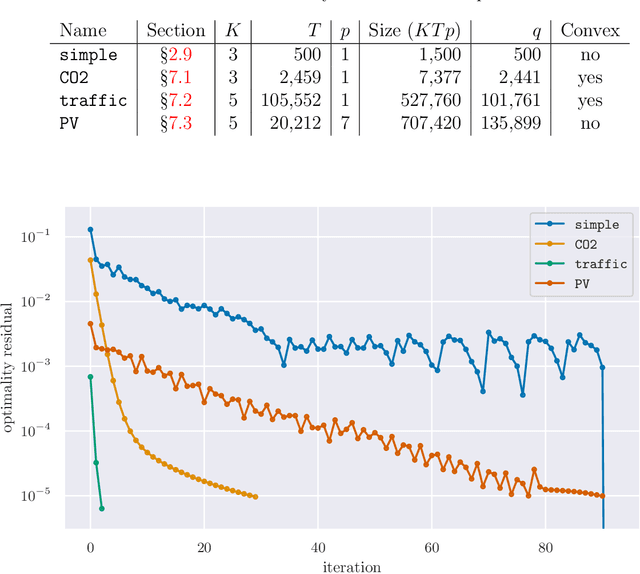
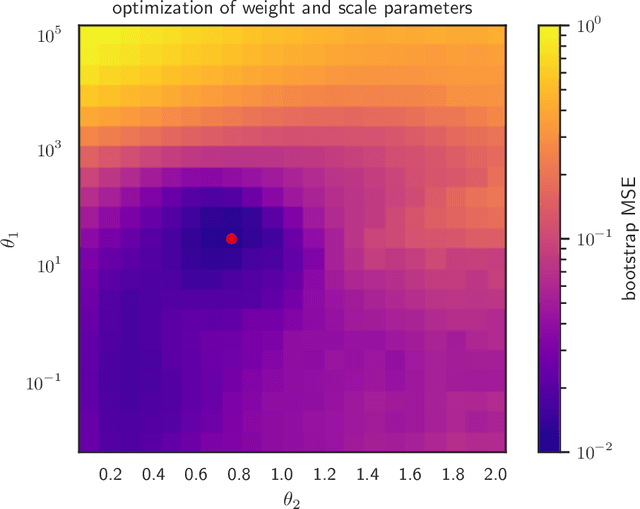
We consider the well-studied problem of decomposing a vector time series signal into components with different characteristics, such as smooth, periodic, nonnegative, or sparse. We propose a simple and general framework in which the components are defined by loss functions (which include constraints), and the signal decomposition is carried out by minimizing the sum of losses of the components (subject to the constraints). When each loss function is the negative log-likelihood of a density for the signal component, our method coincides with maximum a posteriori probability (MAP) estimation; but it also includes many other interesting cases. We give two distributed optimization methods for computing the decomposition, which find the optimal decomposition when the component class loss functions are convex, and are good heuristics when they are not. Both methods require only the masked proximal operator of each of the component loss functions, a generalization of the well-known proximal operator that handles missing entries in its argument. Both methods are distributed, i.e., handle each component separately. We derive tractable methods for evaluating the masked proximal operators of some loss functions that, to our knowledge, have not appeared in the literature.
Optimal Robust Linear Regression in Nearly Linear Time
Jul 16, 2020We study the problem of high-dimensional robust linear regression where a learner is given access to $n$ samples from the generative model $Y = \langle X,w^* \rangle + \epsilon$ (with $X \in \mathbb{R}^d$ and $\epsilon$ independent), in which an $\eta$ fraction of the samples have been adversarially corrupted. We propose estimators for this problem under two settings: (i) $X$ is L4-L2 hypercontractive, $\mathbb{E} [XX^\top]$ has bounded condition number and $\epsilon$ has bounded variance and (ii) $X$ is sub-Gaussian with identity second moment and $\epsilon$ is sub-Gaussian. In both settings, our estimators: (a) Achieve optimal sample complexities and recovery guarantees up to log factors and (b) Run in near linear time ($\tilde{O}(nd / \eta^6)$). Prior to our work, polynomial time algorithms achieving near optimal sample complexities were only known in the setting where $X$ is Gaussian with identity covariance and $\epsilon$ is Gaussian, and no linear time estimators were known for robust linear regression in any setting. Our estimators and their analysis leverage recent developments in the construction of faster algorithms for robust mean estimation to improve runtimes, and refined concentration of measure arguments alongside Gaussian rounding techniques to improve statistical sample complexities.
Learning Conditional Variational Autoencoders with Missing Covariates
Mar 02, 2022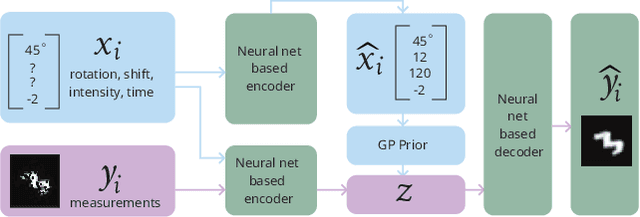
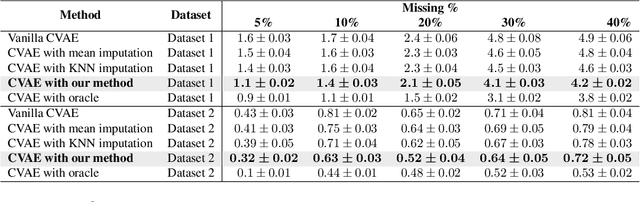
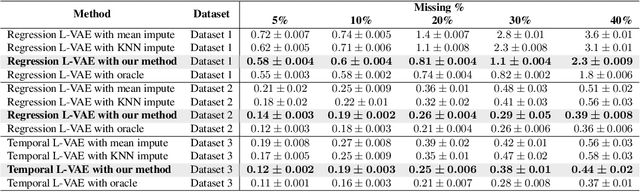
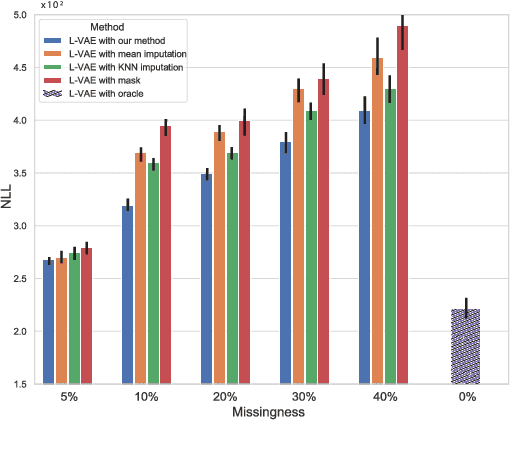
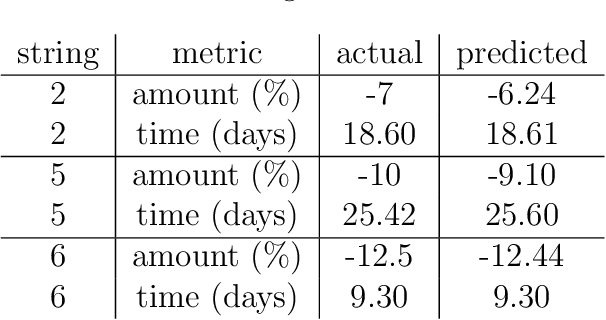
Conditional variational autoencoders (CVAEs) are versatile deep generative models that extend the standard VAE framework by conditioning the generative model with auxiliary covariates. The original CVAE model assumes that the data samples are independent, whereas more recent conditional VAE models, such as the Gaussian process (GP) prior VAEs, can account for complex correlation structures across all data samples. While several methods have been proposed to learn standard VAEs from partially observed datasets, these methods fall short for conditional VAEs. In this work, we propose a method to learn conditional VAEs from datasets in which auxiliary covariates can contain missing values as well. The proposed method augments the conditional VAEs with a prior distribution for the missing covariates and estimates their posterior using amortised variational inference. At training time, our method marginalises the uncertainty associated with the missing covariates while simultaneously maximising the evidence lower bound. We develop computationally efficient methods to learn CVAEs and GP prior VAEs that are compatible with mini-batching. Our experiments on simulated datasets as well as on a clinical trial study show that the proposed method outperforms previous methods in learning conditional VAEs from non-temporal, temporal, and longitudinal datasets.