 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Advanced service data provisioning in ROF-based mobile backhauls/fronthauls
Jan 31, 2022
A new cost-efficient concept to realize a real-time monitoring of quality-of-service metrics and other service data in 5G and beyond access network using a separate return channel based on a vertical cavity surface emitting laser in the optical injection locked mode that simultaneously operates as an optical transmitter and as a resonant cavity enhanced photodetector, is proposed and discussed. The feasibility and efficiency of the proposed approach are confirmed by a proof-of-concept experiment when optically transceiving high-speed digital signal with multi-position quadrature amplitude modulation of a radio-frequency carrier.
ZeroBERTo -- Leveraging Zero-Shot Text Classification by Topic Modeling
Jan 04, 2022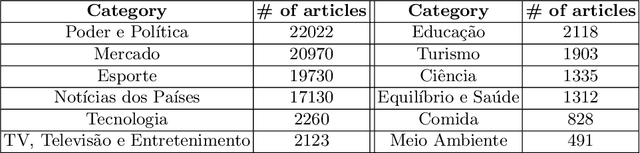

Traditional text classification approaches often require a good amount of labeled data, which is difficult to obtain, especially in restricted domains or less widespread languages. This lack of labeled data has led to the rise of low-resource methods, that assume low data availability in natural language processing. Among them, zero-shot learning stands out, which consists of learning a classifier without any previously labeled data. The best results reported with this approach use language models such as Transformers, but fall into two problems: high execution time and inability to handle long texts as input. This paper proposes a new model, ZeroBERTo, which leverages an unsupervised clustering step to obtain a compressed data representation before the classification task. We show that ZeroBERTo has better performance for long inputs and shorter execution time, outperforming XLM-R by about 12% in the F1 score in the FolhaUOL dataset. Keywords: Low-Resource NLP, Unlabeled data, Zero-Shot Learning, Topic Modeling, Transformers.
Myriad: a real-world testbed to bridge trajectory optimization and deep learning
Feb 22, 2022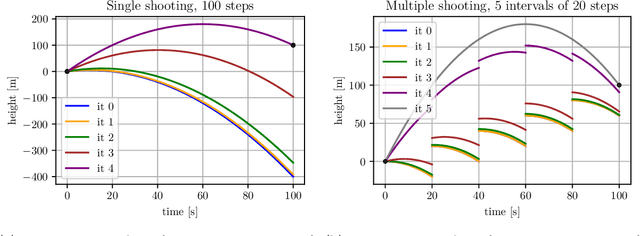
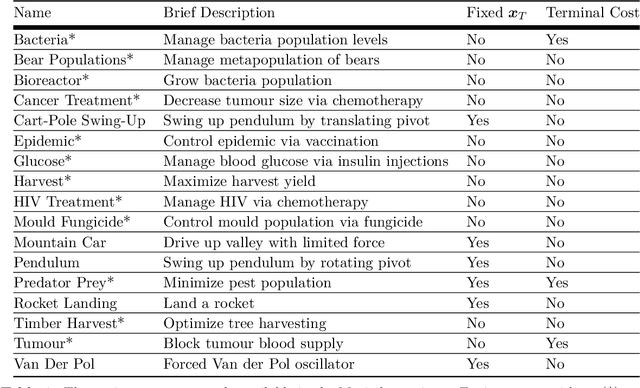
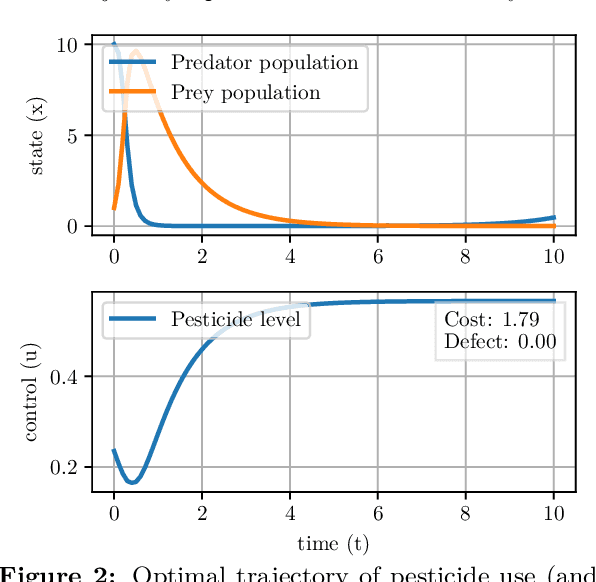

We present Myriad, a testbed written in JAX for learning and planning in real-world continuous environments. The primary contributions of Myriad are threefold. First, Myriad provides machine learning practitioners access to trajectory optimization techniques for application within a typical automatic differentiation workflow. Second, Myriad presents many real-world optimal control problems, ranging from biology to medicine to engineering, for use by the machine learning community. Formulated in continuous space and time, these environments retain some of the complexity of real-world systems often abstracted away by standard benchmarks. As such, Myriad strives to serve as a stepping stone towards application of modern machine learning techniques for impactful real-world tasks. Finally, we use the Myriad repository to showcase a novel approach for learning and control tasks. Trained in a fully end-to-end fashion, our model leverages an implicit planning module over neural ordinary differential equations, enabling simultaneous learning and planning with complex environment dynamics.
Online Caching with Optimistic Learning
Feb 22, 2022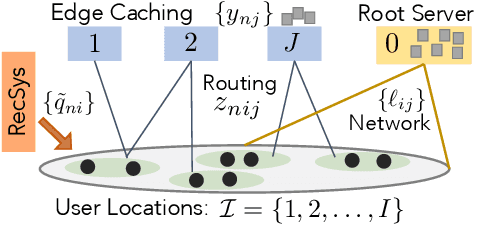
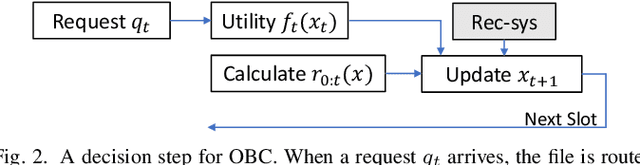
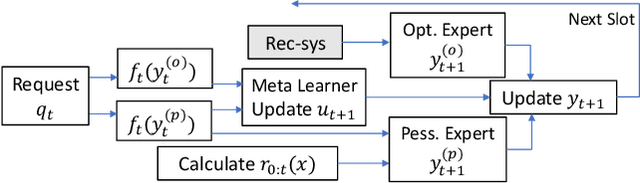
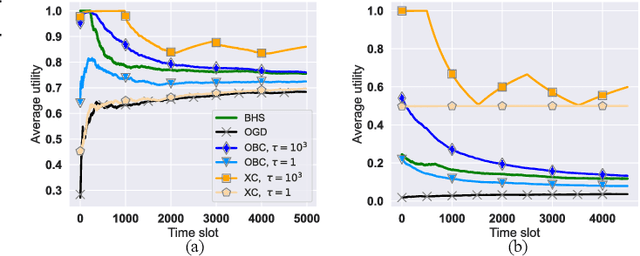
The design of effective online caching policies is an increasingly important problem for content distribution networks, online social networks and edge computing services, among other areas. This paper proposes a new algorithmic toolbox for tackling this problem through the lens of optimistic online learning. We build upon the Follow-the-Regularized-Leader (FTRL) framework which is developed further here to include predictions for the file requests, and we design online caching algorithms for bipartite networks with fixed-size caches or elastic leased caches subject to time-average budget constraints. The predictions are provided by a content recommendation system that influences the users viewing activity, and hence can naturally reduce the caching network's uncertainty about future requests. We prove that the proposed optimistic learning caching policies can achieve sub-zero performance loss (regret) for perfect predictions, and maintain the best achievable regret bound $O(\sqrt T)$ even for arbitrary-bad predictions. The performance of the proposed algorithms is evaluated with detailed trace-driven numerical tests.
Human Response to an AI-Based Decision Support System: A User Study on the Effects of Accuracy and Bias
Mar 24, 2022
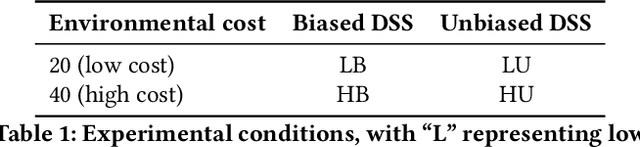
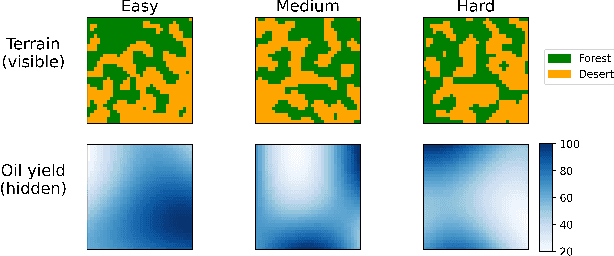
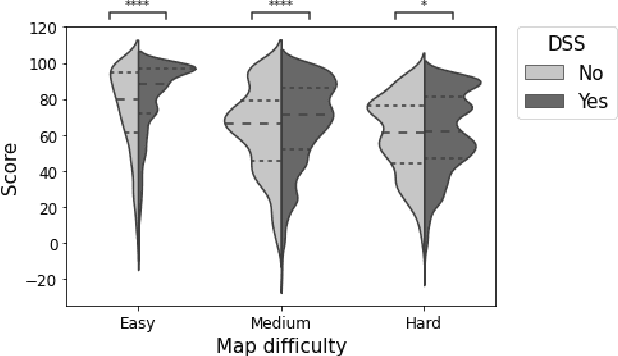
Artificial Intelligence (AI) is increasingly used to build Decision Support Systems (DSS) across many domains. This paper describes a series of experiments designed to observe human response to different characteristics of a DSS such as accuracy and bias, particularly the extent to which participants rely on the DSS, and the performance they achieve. In our experiments, participants play a simple online game inspired by so-called "wildcat" (i.e., exploratory) drilling for oil. The landscape has two layers: a visible layer describing the costs (terrain), and a hidden layer describing the reward (oil yield). Participants in the control group play the game without receiving any assistance, while in treatment groups they are assisted by a DSS suggesting places to drill. For certain treatments, the DSS does not consider costs, but only rewards, which introduces a bias that is observable by users. Between subjects, we vary the accuracy and bias of the DSS, and observe the participants' total score, time to completion, the extent to which they follow or ignore suggestions. We also measure the acceptability of the DSS in an exit survey. Our results show that participants tend to score better with the DSS, that the score increase is due to users following the DSS advice, and related to the difficulty of the game and the accuracy of the DSS. We observe that this setting elicits mostly rational behavior from participants, who place a moderate amount of trust in the DSS and show neither algorithmic aversion (under-reliance) nor automation bias (over-reliance).However, their stated willingness to accept the DSS in the exit survey seems less sensitive to the accuracy of the DSS than their behavior, suggesting that users are only partially aware of the (lack of) accuracy of the DSS.
A Simple Hash-Based Early Exiting Approach For Language Understanding and Generation
Mar 03, 2022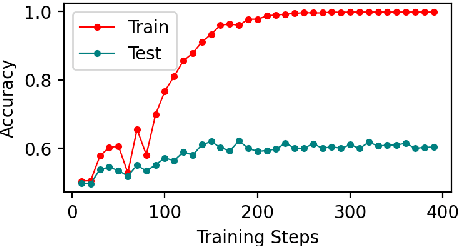
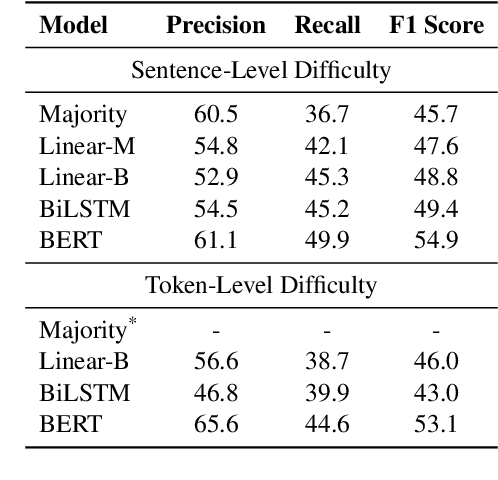
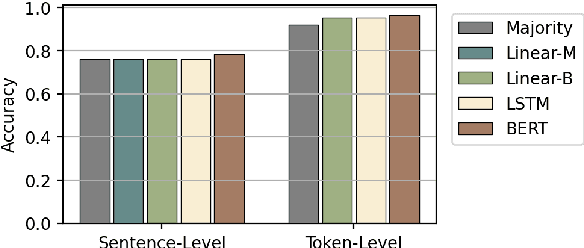
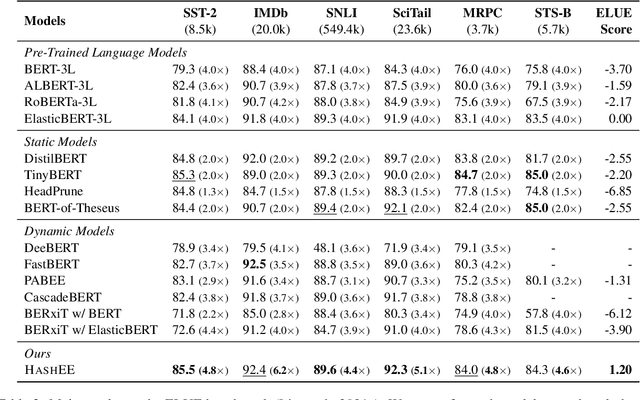
Early exiting allows instances to exit at different layers according to the estimation of difficulty. Previous works usually adopt heuristic metrics such as the entropy of internal outputs to measure instance difficulty, which suffers from generalization and threshold-tuning. In contrast, learning to exit, or learning to predict instance difficulty is a more appealing way. Though some effort has been devoted to employing such "learn-to-exit" modules, it is still unknown whether and how well the instance difficulty can be learned. As a response, we first conduct experiments on the learnability of instance difficulty, which demonstrates that modern neural models perform poorly on predicting instance difficulty. Based on this observation, we propose a simple-yet-effective Hash-based Early Exiting approach (HashEE) that replaces the learn-to-exit modules with hash functions to assign each token to a fixed exiting layer. Different from previous methods, HashEE requires no internal classifiers nor extra parameters, and therefore is more efficient. Experimental results on classification, regression, and generation tasks demonstrate that HashEE can achieve higher performance with fewer FLOPs and inference time compared with previous state-of-the-art early exiting methods.
Correlation-Aware Deep Tracking
Mar 03, 2022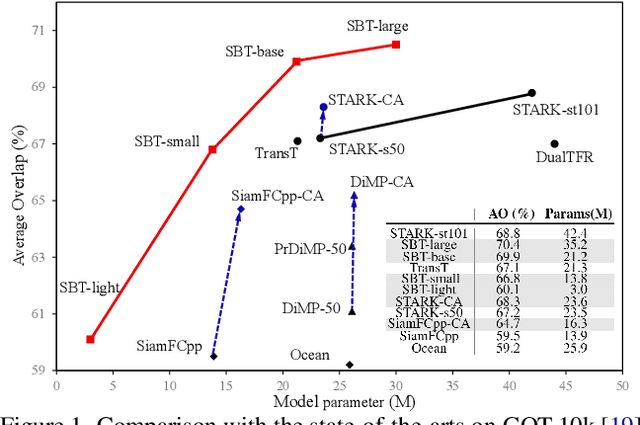

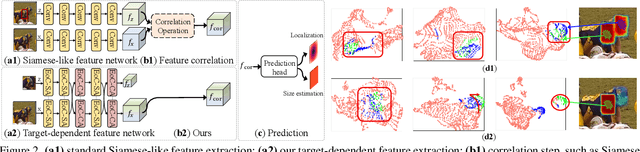
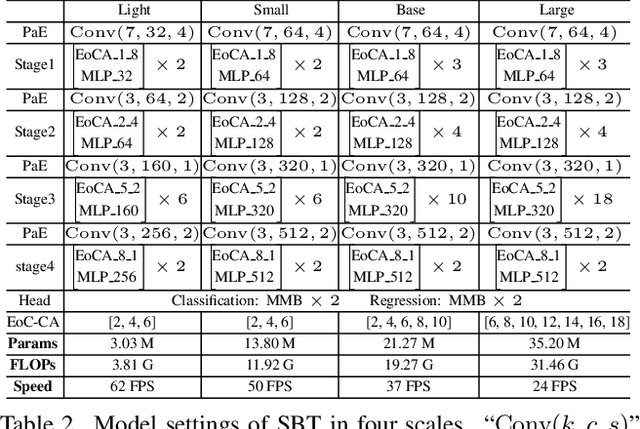
Robustness and discrimination power are two fundamental requirements in visual object tracking. In most tracking paradigms, we find that the features extracted by the popular Siamese-like networks cannot fully discriminatively model the tracked targets and distractor objects, hindering them from simultaneously meeting these two requirements. While most methods focus on designing robust correlation operations, we propose a novel target-dependent feature network inspired by the self-/cross-attention scheme. In contrast to the Siamese-like feature extraction, our network deeply embeds cross-image feature correlation in multiple layers of the feature network. By extensively matching the features of the two images through multiple layers, it is able to suppress non-target features, resulting in instance-varying feature extraction. The output features of the search image can be directly used for predicting target locations without extra correlation step. Moreover, our model can be flexibly pre-trained on abundant unpaired images, leading to notably faster convergence than the existing methods. Extensive experiments show our method achieves the state-of-the-art results while running at real-time. Our feature networks also can be applied to existing tracking pipelines seamlessly to raise the tracking performance. Code will be available.
UDAAN - Machine Learning based Post-Editing tool for Document Translation
Mar 03, 2022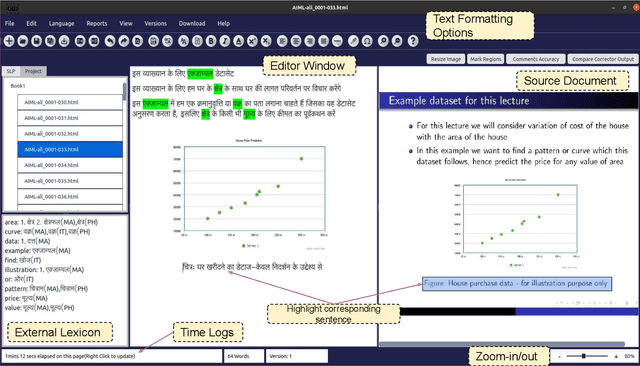
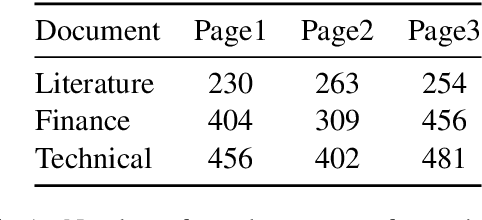
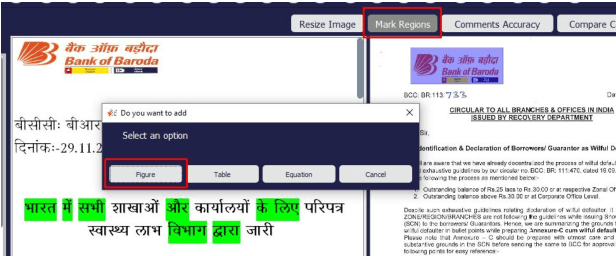
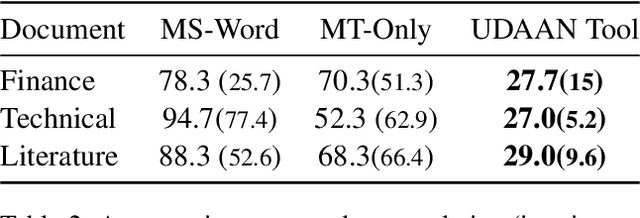
We introduce UDAAN, an open-source post-editing tool that can reduce manual editing efforts to quickly produce publishable-standard documents in different languages. UDAAN has an end-to-end Machine Translation (MT) plus post-editing pipeline wherein users can upload a document to obtain raw MT output. Further, users can edit the raw translations using our tool. UDAAN offers several advantages: a) Domain-aware, vocabulary-based lexical constrained MT. b) source-target and target-target lexicon suggestions for users. Replacements are based on the source and target texts lexicon alignment. c) Suggestions for translations are based on logs created during user interaction. d) Source-target sentence alignment visualisation that reduces the cognitive load of users during editing. e) Translated outputs from our tool are available in multiple formats: docs, latex, and PDF. Although we limit our experiments to English-to-Hindi translation for the current study, our tool is independent of the source and target languages. Experimental results based on the usage of the tools and users feedback show that our tool speeds up the translation time approximately by a factor of three compared to the baseline method of translating documents from scratch.
Adaptive Path Planning for UAVs for Multi-Resolution Semantic Segmentation
Mar 03, 2022
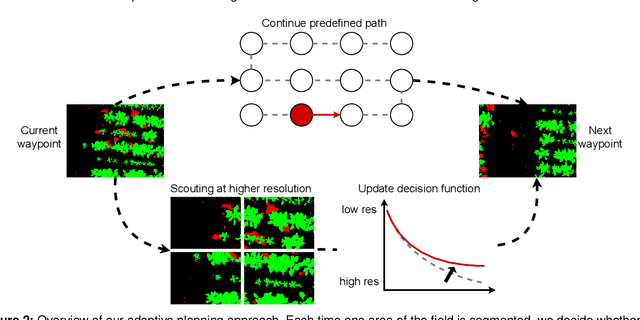
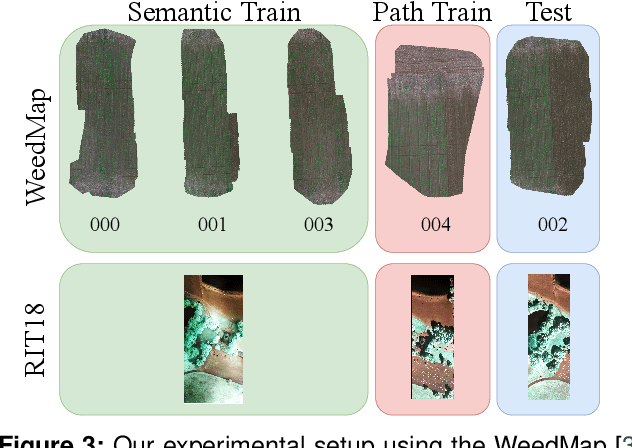
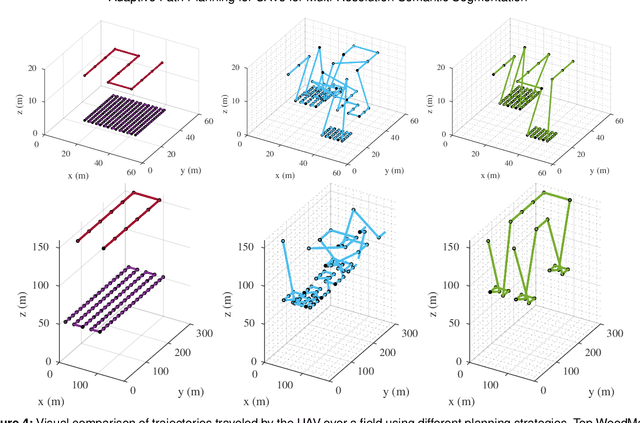
Efficient data collection methods play a major role in helping us better understand the Earth and its ecosystems. In many applications, the usage of unmanned aerial vehicles (UAVs) for monitoring and remote sensing is rapidly gaining momentum due to their high mobility, low cost, and flexible deployment. A key challenge is planning missions to maximize the value of acquired data in large environments given flight time limitations. This is, for example, relevant for monitoring agricultural fields. This paper addresses the problem of adaptive path planning for accurate semantic segmentation of using UAVs. We propose an online planning algorithm which adapts the UAV paths to obtain high-resolution semantic segmentations necessary in areas with fine details as they are detected in incoming images. This enables us to perform close inspections at low altitudes only where required, without wasting energy on exhaustive mapping at maximum image resolution. A key feature of our approach is a new accuracy model for deep learning-based architectures that captures the relationship between UAV altitude and semantic segmentation accuracy. We evaluate our approach on different domains using real-world data, proving the efficacy and generability of our solution.
Learning Solution Manifolds for Control Problems via Energy Minimization
Mar 07, 2022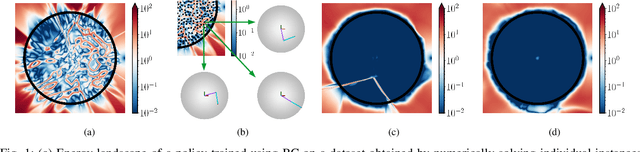
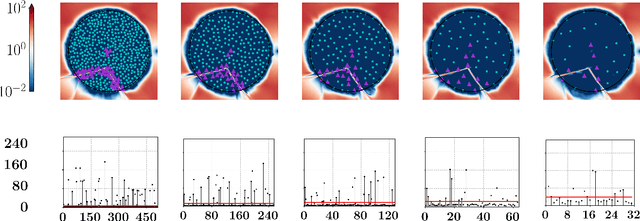
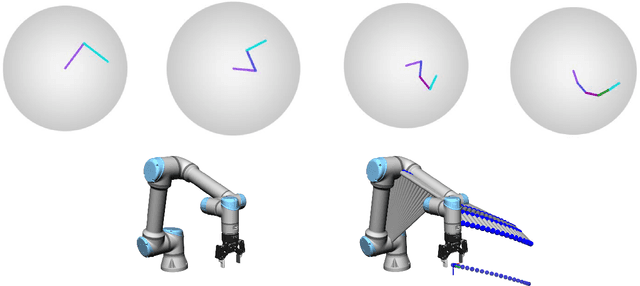
A variety of control tasks such as inverse kinematics (IK), trajectory optimization (TO), and model predictive control (MPC) are commonly formulated as energy minimization problems. Numerical solutions to such problems are well-established. However, these are often too slow to be used directly in real-time applications. The alternative is to learn solution manifolds for control problems in an offline stage. Although this distillation process can be trivially formulated as a behavioral cloning (BC) problem in an imitation learning setting, our experiments highlight a number of significant shortcomings arising due to incompatible local minima, interpolation artifacts, and insufficient coverage of the state space. In this paper, we propose an alternative to BC that is efficient and numerically robust. We formulate the learning of solution manifolds as a minimization of the energy terms of a control objective integrated over the space of problems of interest. We minimize this energy integral with a novel method that combines Monte Carlo-inspired adaptive sampling strategies with the derivatives used to solve individual instances of the control task. We evaluate the performance of our formulation on a series of robotic control problems of increasing complexity, and we highlight its benefits through comparisons against traditional methods such as behavioral cloning and Dataset aggregation (Dagger).