 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Dynamic Model of a Skydiver With Validation in Wind Tunnel and Free Fall
Feb 16, 2022
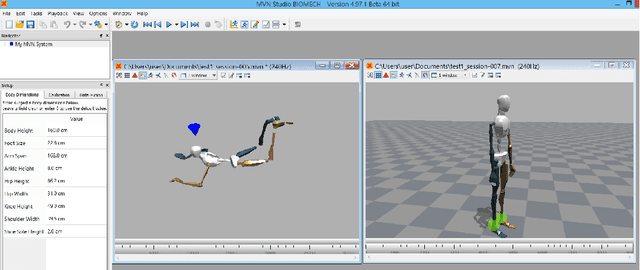
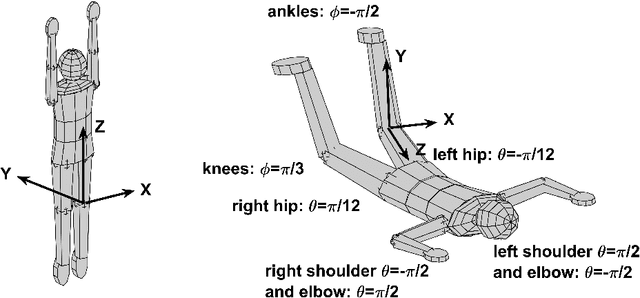
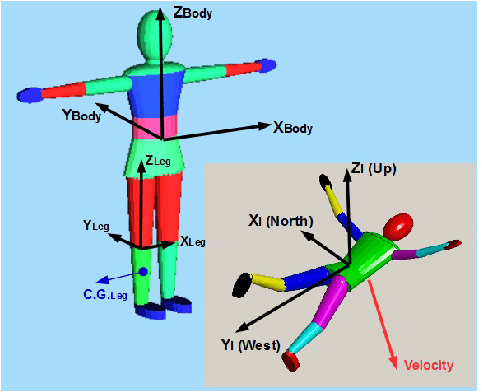
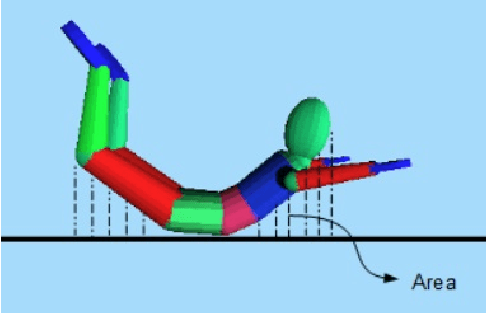
An innovative approach of gaining insight into motor skills involved in human body flight is proposed. The key idea is the creation of a model autonomous system capable of virtually performing skydiving maneuvers. A dynamic skydiver model and simulator is developed, comprising biomechanical, aerodynamic, and kinematic models, dynamic equations of motion, and a virtual reality environment. Limb relative orientations, and resulting inertial body angular position and velocity are measured in skydiving experiments in a vertical wind tunnel and in free fall. These experimental data are compared with corresponding simulation data to tune and verify the model for basic skydiving maneuvers. The model is further extended to reconstruct advanced aerial maneuvers, such as transitions between stable equilibria. The experimental data are used to estimate skydiver's conscious inputs as a function of time, via an Unscented Kalman Filter modified for this purpose.
Unsupervised Image Registration Towards Enhancing Performance and Explainability in Cardiac And Brain Image Analysis
Mar 07, 2022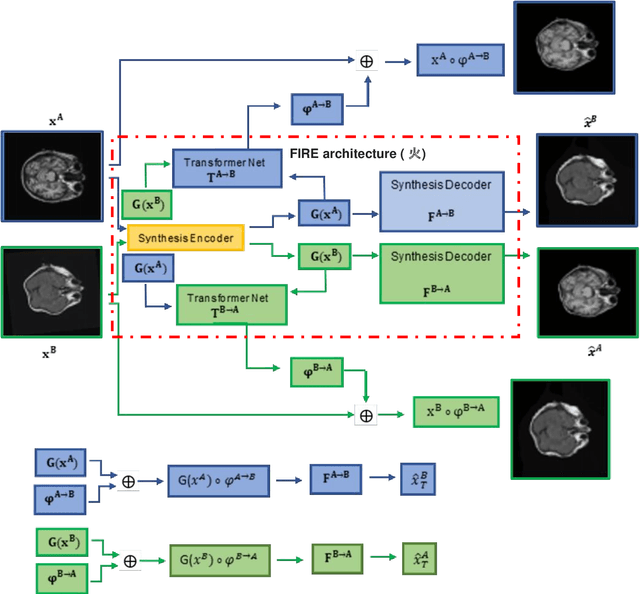
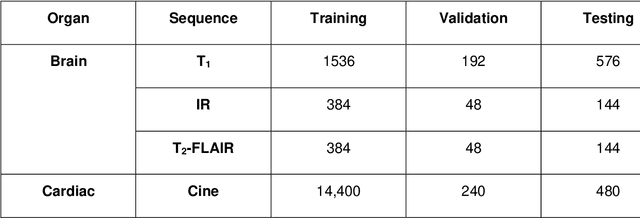
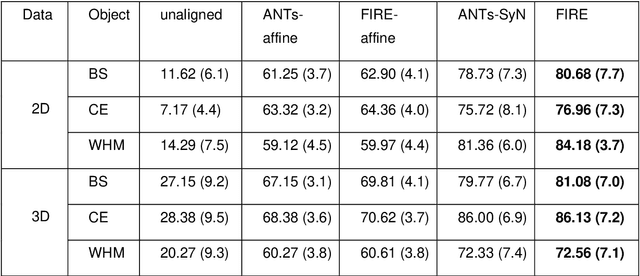
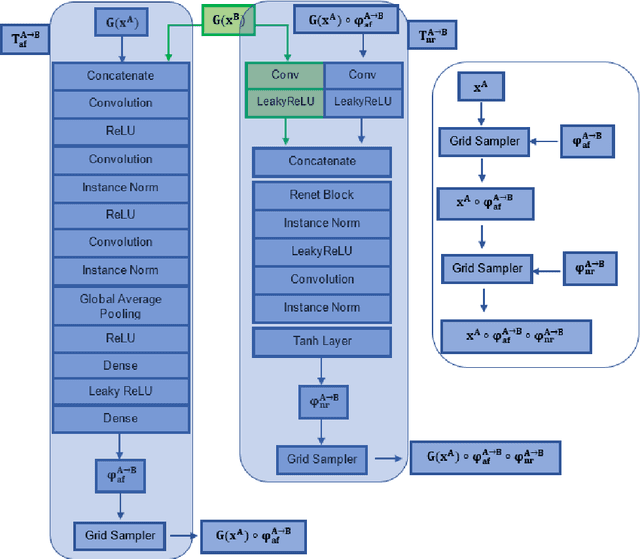
Magnetic Resonance Imaging (MRI) typically recruits multiple sequences (defined here as "modalities"). As each modality is designed to offer different anatomical and functional clinical information, there are evident disparities in the imaging content across modalities. Inter- and intra-modality affine and non-rigid image registration is an essential medical image analysis process in clinical imaging, as for example before imaging biomarkers need to be derived and clinically evaluated across different MRI modalities, time phases and slices. Although commonly needed in real clinical scenarios, affine and non-rigid image registration is not extensively investigated using a single unsupervised model architecture. In our work, we present an un-supervised deep learning registration methodology which can accurately model affine and non-rigid trans-formations, simultaneously. Moreover, inverse-consistency is a fundamental inter-modality registration property that is not considered in deep learning registration algorithms. To address inverse-consistency, our methodology performs bi-directional cross-modality image synthesis to learn modality-invariant latent rep-resentations, while involves two factorised transformation networks and an inverse-consistency loss to learn topology-preserving anatomical transformations. Overall, our model (named "FIRE") shows improved performances against the reference standard baseline method on multi-modality brain 2D and 3D MRI and intra-modality cardiac 4D MRI data experiments.
Window Filtering Algorithm for Pulsed Light Coherent Combining of Low Repetition Frequency
Mar 03, 2022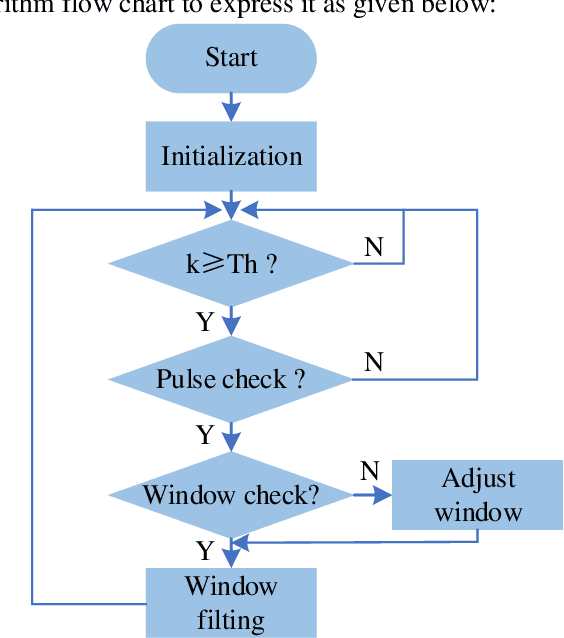
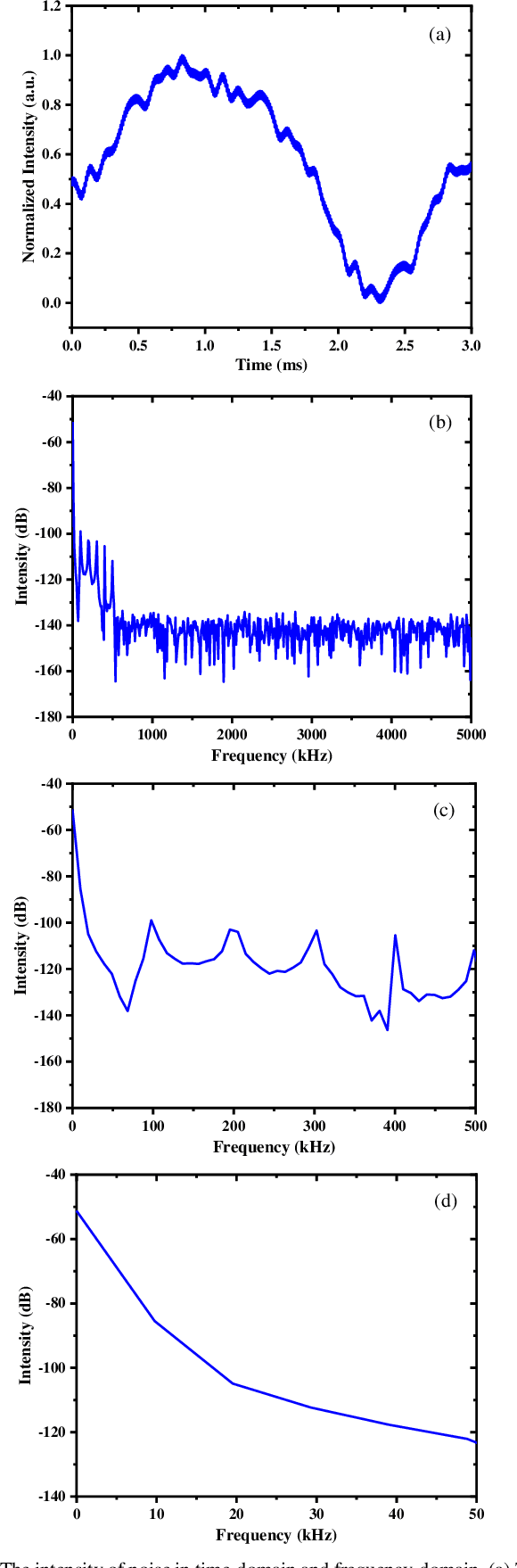
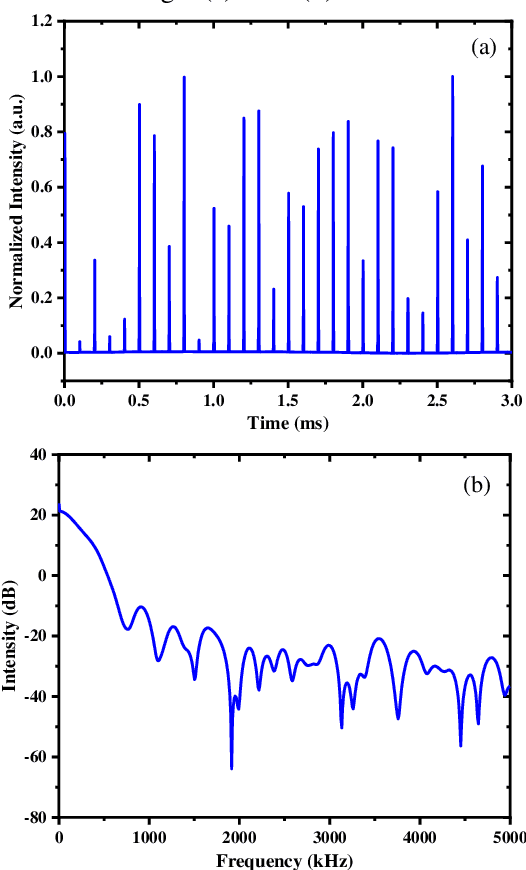
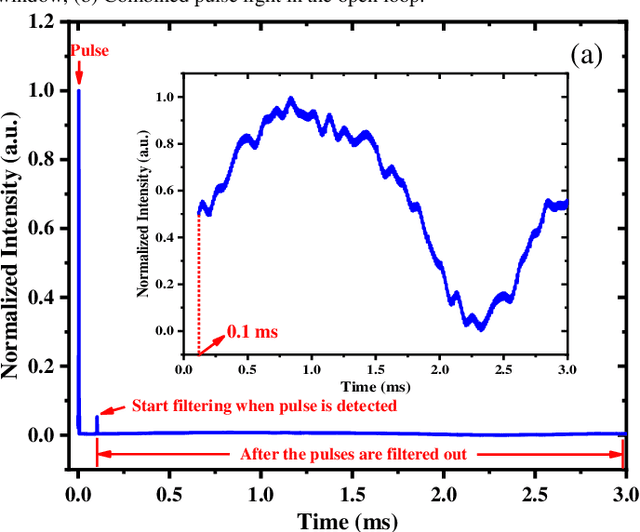
The multi-dithering method has been well verified in phase locking of polarization coherent combination experiment. However, it is hard to apply to low repetition frequency pulsed lasers, since there exists an overlap frequency domain between pulse laser and the amplitude phase noise and traditional filters cannot effectively separate phase noise. Aiming to solve the problem in this paper, we propose a novel method of pulse noise detection, identification, and filtering based on the autocorrelation characteristics between noise signals. In the proposed algorithm, a self-designed window algorithm is used to identify the pulse, and then the pulse signal group in the window is replaced by interpolation, which effectively filter the pulse signal doped in the phase noise within 0.1 ms. After filtering the pulses in the phase noise, the phase difference of two pulsed beams (10 kHz) is successfully compensated to zero in 1 ms, and the coherent combination of closed-loop phase lock is realized. At the same time, the phase correction times are few, the phase lock effect is stable, and the final light intensity increases to the ideal value (0.9 Imax).
A Novel Deep ML Architecture by Integrating Visual Simultaneous Localization and Mapping (vSLAM) into Mask R-CNN for Real-time Surgical Video Analysis
Mar 31, 2021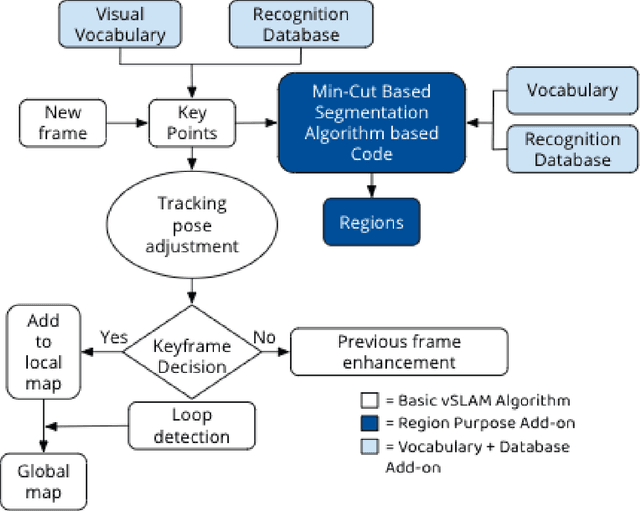
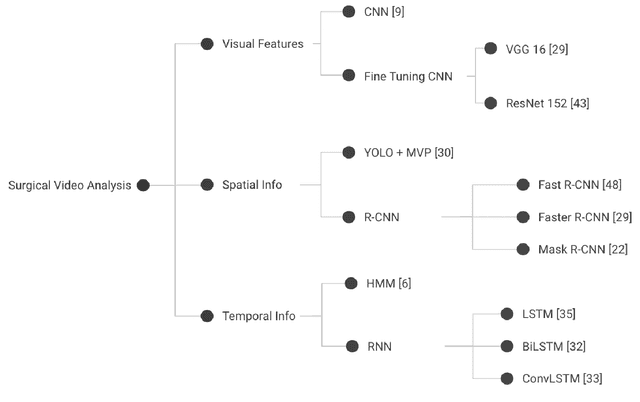
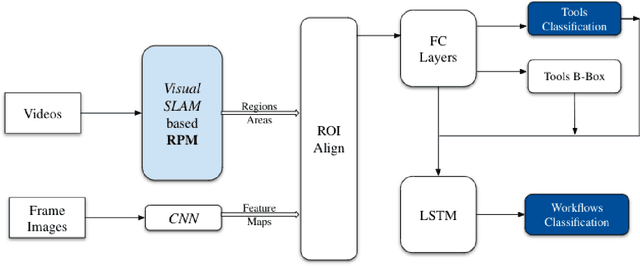
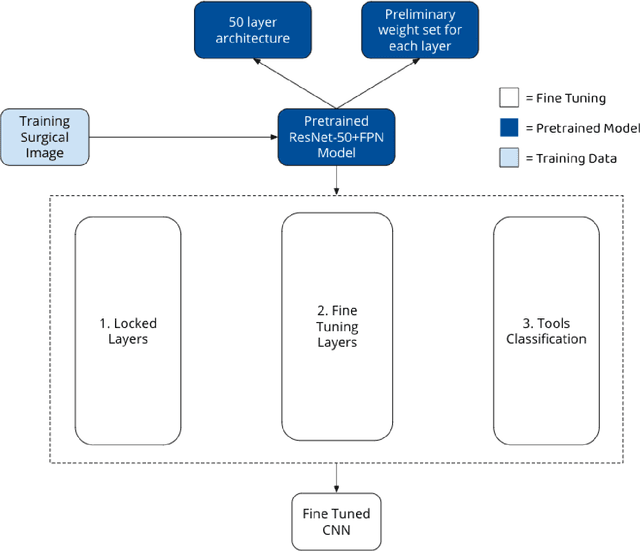
Seven million people suffer complications after surgery each year. With sufficient surgical training and feedback, half of these complications could be prevented. Automatic surgical video analysis, especially for minimally invasive surgery, plays a key role in training and review, with increasing interests from recent studies on tool and workflow detection. In this research, a novel machine learning architecture, RPM-CNN, is created to perform real-time surgical video analysis. This architecture, for the first time, integrates visual simultaneous localization and mapping (vSLAM) into Mask R-CNN. Spatio-temporal information, in addition to the visual features, is utilized to increase the accuracy to 96.8 mAP for tool detection and 97.5 mean Jaccard for workflow detection, surpassing all previous works via the same benchmark dataset. As a real-time prediction, the RPM-CNN model reaches a 50 FPS runtime performance speed, 10x faster than region based CNN, by modeling the spatio-temporal information directly from surgical videos during the vSLAM 3D mapping. Additionally, this novel Region Proposal Module (RPM) replaces the region proposal network (RPN) in Mask R-CNN, accurately placing bounding-boxes and lessening the annotation requirement. In principle, this architecture integrates the best of both worlds, inclusive of 1) vSLAM on object detection, through focusing on geometric information for region proposals and 2) CNN on object recognition, through focusing on semantic information for image classification; the integration of these two technologies into one joint training process opens a new door in computer vision. Furthermore, to apply RPM-CNN's real-time top performance to the real world, a Microsoft HoloLens 2 application is developed to provide an augmented reality (AR) based solution for both surgical training and assistance.
Myriad: a real-world testbed to bridge trajectory optimization and deep learning
Feb 22, 2022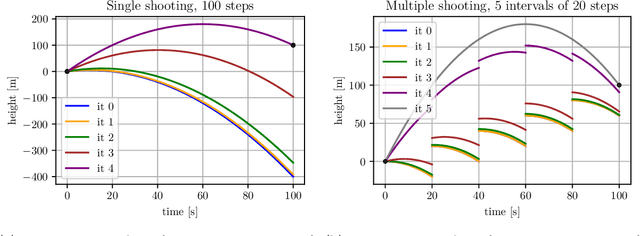
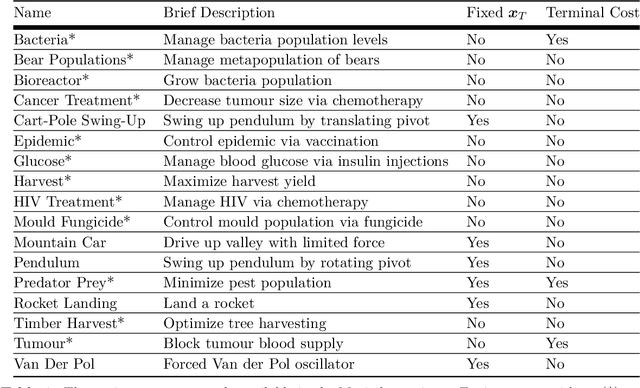
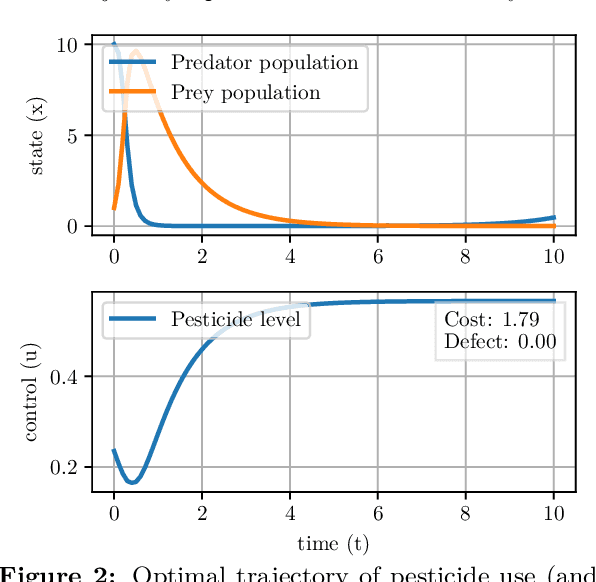

We present Myriad, a testbed written in JAX for learning and planning in real-world continuous environments. The primary contributions of Myriad are threefold. First, Myriad provides machine learning practitioners access to trajectory optimization techniques for application within a typical automatic differentiation workflow. Second, Myriad presents many real-world optimal control problems, ranging from biology to medicine to engineering, for use by the machine learning community. Formulated in continuous space and time, these environments retain some of the complexity of real-world systems often abstracted away by standard benchmarks. As such, Myriad strives to serve as a stepping stone towards application of modern machine learning techniques for impactful real-world tasks. Finally, we use the Myriad repository to showcase a novel approach for learning and control tasks. Trained in a fully end-to-end fashion, our model leverages an implicit planning module over neural ordinary differential equations, enabling simultaneous learning and planning with complex environment dynamics.
VISTA: Boosting 3D Object Detection via Dual Cross-VIew SpaTial Attention
Mar 18, 2022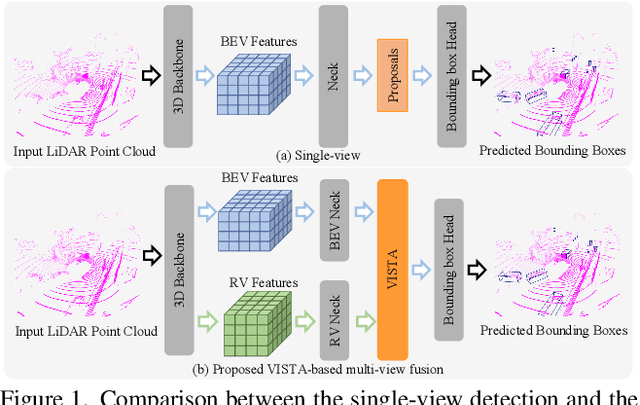
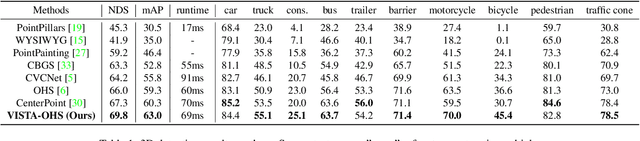
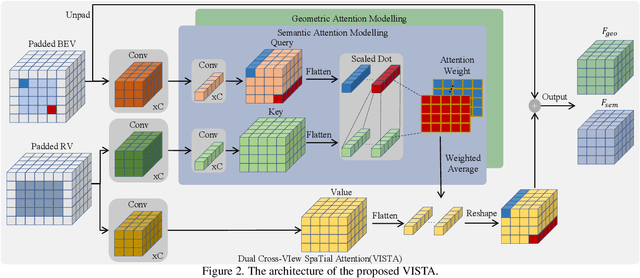

Detecting objects from LiDAR point clouds is of tremendous significance in autonomous driving. In spite of good progress, accurate and reliable 3D detection is yet to be achieved due to the sparsity and irregularity of LiDAR point clouds. Among existing strategies, multi-view methods have shown great promise by leveraging the more comprehensive information from both bird's eye view (BEV) and range view (RV). These multi-view methods either refine the proposals predicted from single view via fused features, or fuse the features without considering the global spatial context; their performance is limited consequently. In this paper, we propose to adaptively fuse multi-view features in a global spatial context via Dual Cross-VIew SpaTial Attention (VISTA). The proposed VISTA is a novel plug-and-play fusion module, wherein the multi-layer perceptron widely adopted in standard attention modules is replaced with a convolutional one. Thanks to the learned attention mechanism, VISTA can produce fused features of high quality for prediction of proposals. We decouple the classification and regression tasks in VISTA, and an additional constraint of attention variance is applied that enables the attention module to focus on specific targets instead of generic points. We conduct thorough experiments on the benchmarks of nuScenes and Waymo; results confirm the efficacy of our designs. At the time of submission, our method achieves 63.0% in overall mAP and 69.8% in NDS on the nuScenes benchmark, outperforming all published methods by up to 24% in safety-crucial categories such as cyclist. The source code in PyTorch is available at https://github.com/Gorilla-Lab-SCUT/VISTA
Online Caching with Optimistic Learning
Feb 22, 2022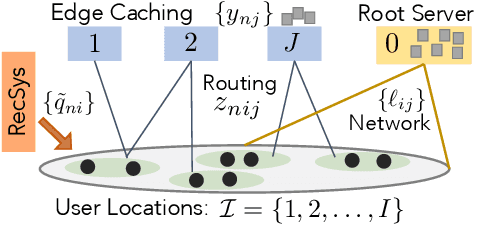
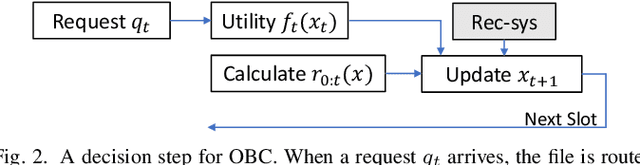
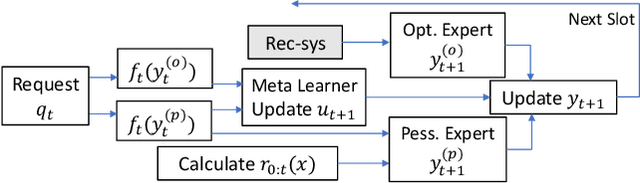
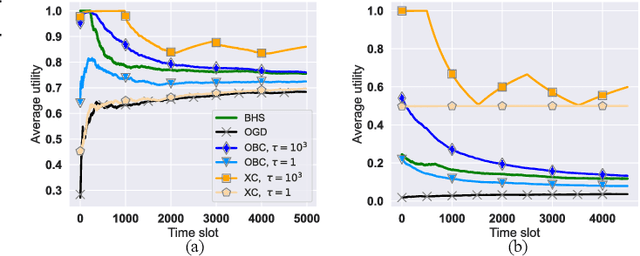
The design of effective online caching policies is an increasingly important problem for content distribution networks, online social networks and edge computing services, among other areas. This paper proposes a new algorithmic toolbox for tackling this problem through the lens of optimistic online learning. We build upon the Follow-the-Regularized-Leader (FTRL) framework which is developed further here to include predictions for the file requests, and we design online caching algorithms for bipartite networks with fixed-size caches or elastic leased caches subject to time-average budget constraints. The predictions are provided by a content recommendation system that influences the users viewing activity, and hence can naturally reduce the caching network's uncertainty about future requests. We prove that the proposed optimistic learning caching policies can achieve sub-zero performance loss (regret) for perfect predictions, and maintain the best achievable regret bound $O(\sqrt T)$ even for arbitrary-bad predictions. The performance of the proposed algorithms is evaluated with detailed trace-driven numerical tests.
An application of the splitting-up method for the computation of a neural network representation for the solution for the filtering equations
Jan 10, 2022
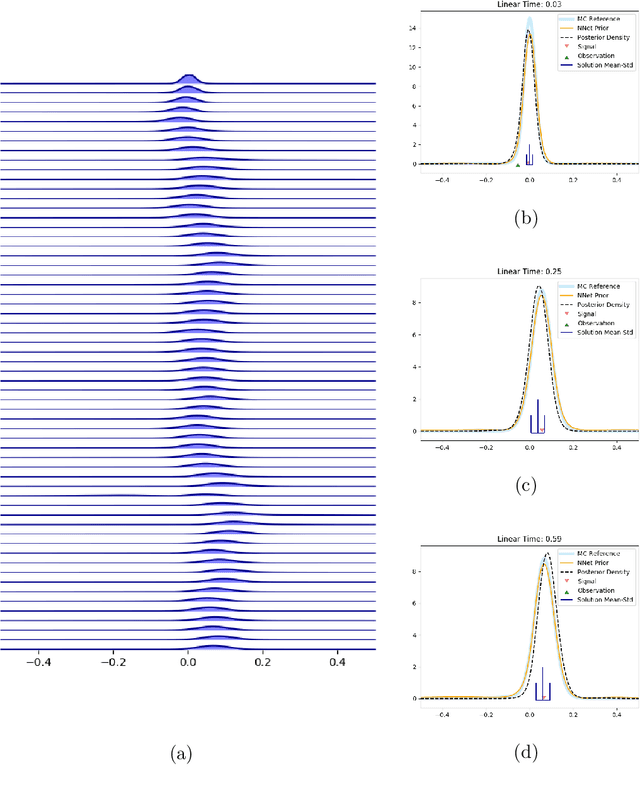
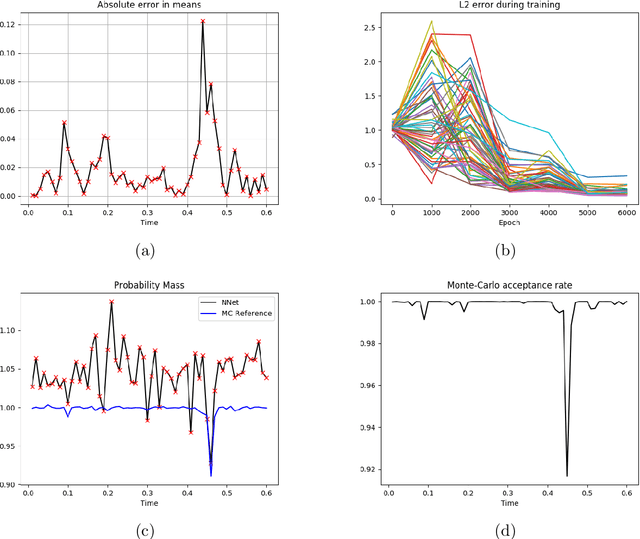
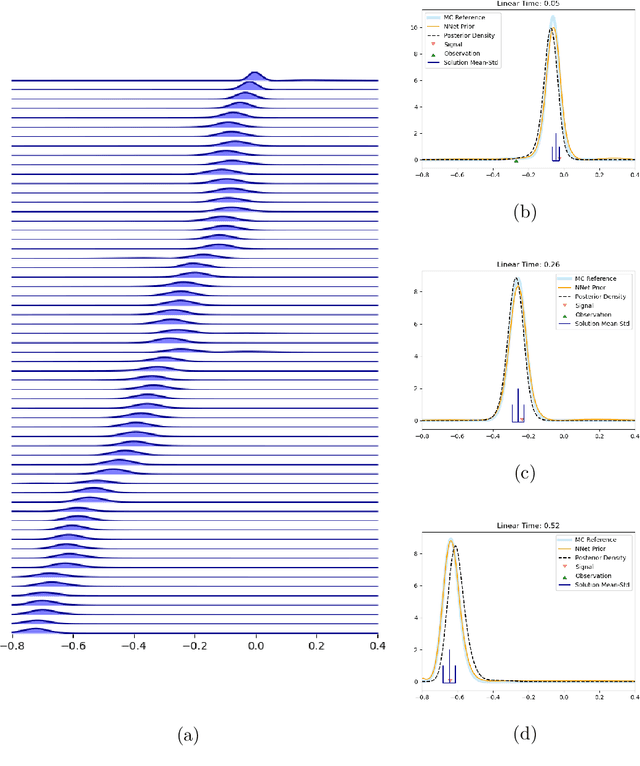
The filtering equations govern the evolution of the conditional distribution of a signal process given partial, and possibly noisy, observations arriving sequentially in time. Their numerical approximation plays a central role in many real-life applications, including numerical weather prediction, finance and engineering. One of the classical approaches to approximate the solution of the filtering equations is to use a PDE inspired method, called the splitting-up method, initiated by Gyongy, Krylov, LeGland, among other contributors. This method, and other PDE based approaches, have particular applicability for solving low-dimensional problems. In this work we combine this method with a neural network representation. The new methodology is used to produce an approximation of the unnormalised conditional distribution of the signal process. We further develop a recursive normalisation procedure to recover the normalised conditional distribution of the signal process. The new scheme can be iterated over multiple time steps whilst keeping its asymptotic unbiasedness property intact. We test the neural network approximations with numerical approximation results for the Kalman and Benes filter.
SODA: Self-organizing data augmentation in deep neural networks -- Application to biomedical image segmentation tasks
Feb 07, 2022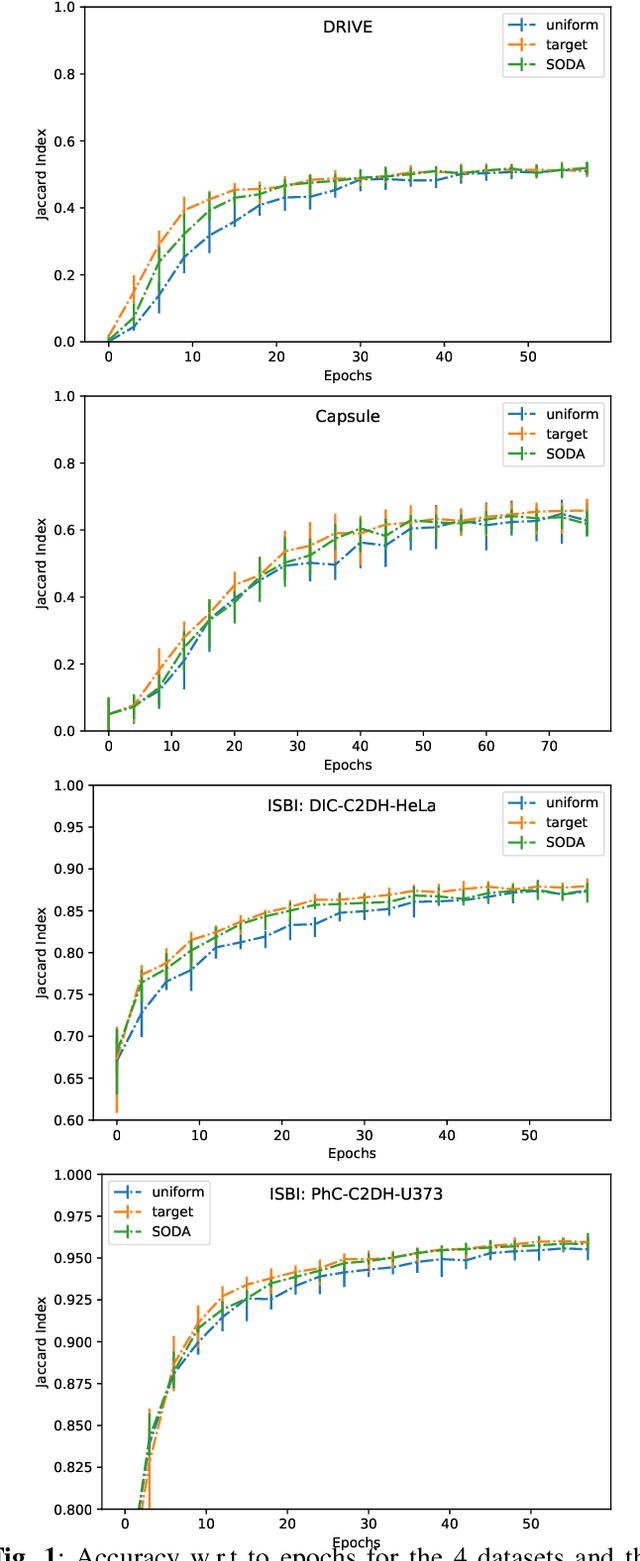

In practice, data augmentation is assigned a predefined budget in terms of newly created samples per epoch. When using several types of data augmentation, the budget is usually uniformly distributed over the set of augmentations but one can wonder if this budget should not be allocated to each type in a more efficient way. This paper leverages online learning to allocate on the fly this budget as part of neural network training. This meta-algorithm can be run at almost no extra cost as it exploits gradient based signals to determine which type of data augmentation should be preferred. Experiments suggest that this strategy can save computation time and thus goes in the way of greener machine learning practices.
The RATTLE Motion Planning Algorithm for Robust Online Parametric Model Improvement with On-Orbit Validation
Mar 03, 2022
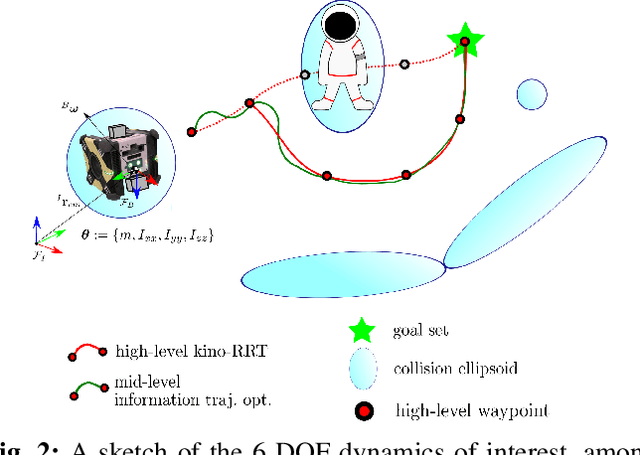
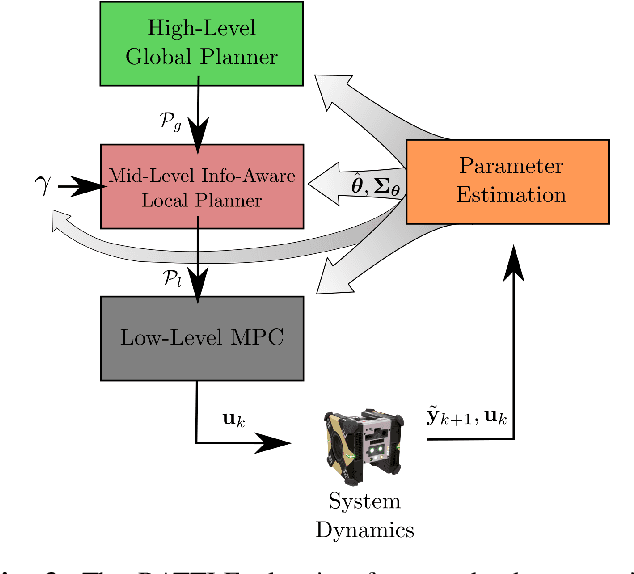
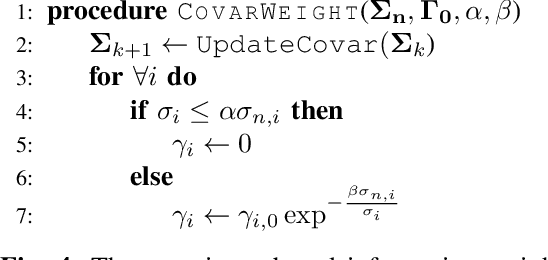
Certain forms of uncertainty that robotic systems encounter can be explicitly learned within the context of a known model, like parametric model uncertainties such as mass and moments of inertia. Quantifying such parametric uncertainty is important for more accurate prediction of the system behavior, leading to safe and precise task execution. In tandem, providing a form of robustness guarantee against prevailing uncertainty levels like environmental disturbances and current model knowledge is also desirable. To that end, the authors' previously proposed RATTLE algorithm, a framework for online information-aware motion planning, is outlined and extended to enhance its applicability to real robotic systems. RATTLE provides a clear tradeoff between information-seeking motion and traditional goal-achieving motion and features online-updateable models. Additionally, online-updateable low level control robustness guarantees and a new method for automatic adjustment of information content down to a specified estimation precision is proposed. Results of extensive experimentation in microgravity using the Astrobee robots aboard the International Space Station and practical implementation details are presented, demonstrating RATTLE's capabilities for real-time, robust, online-updateable, and model information-seeking motion planning capabilities under parametric uncertainty.