 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Few-shot Transfer Learning for Holographic Image Reconstruction using a Recurrent Neural Network
Jan 27, 2022
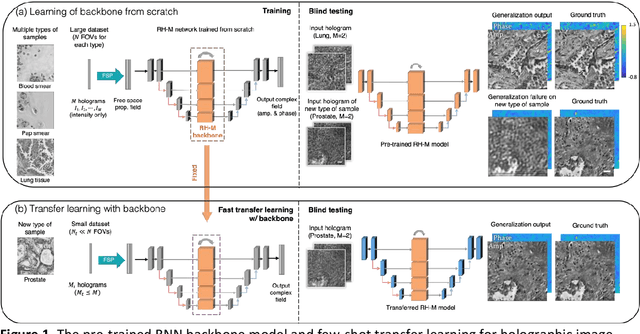
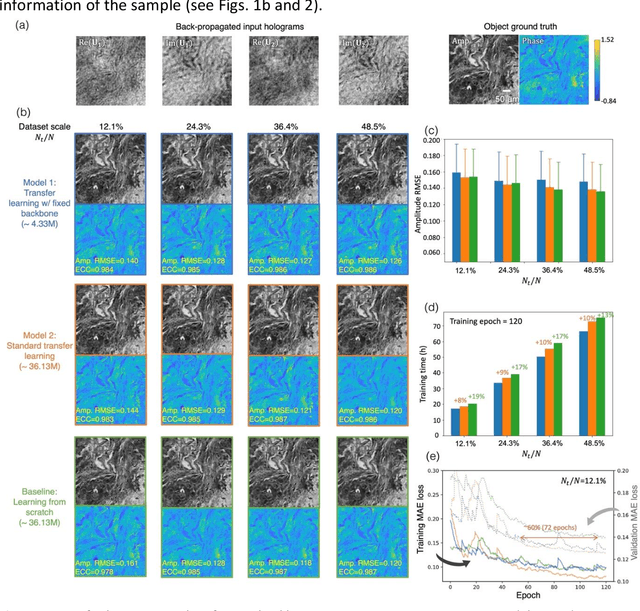
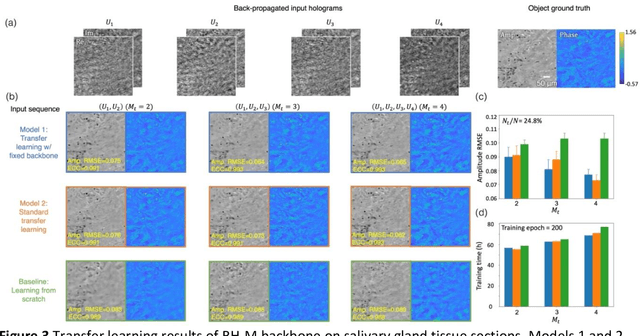
Deep learning-based methods in computational microscopy have been shown to be powerful but in general face some challenges due to limited generalization to new types of samples and requirements for large and diverse training data. Here, we demonstrate a few-shot transfer learning method that helps a holographic image reconstruction deep neural network rapidly generalize to new types of samples using small datasets. We pre-trained a convolutional recurrent neural network on a large dataset with diverse types of samples, which serves as the backbone model. By fixing the recurrent blocks and transferring the rest of the convolutional blocks of the pre-trained model, we reduced the number of trainable parameters by ~90% compared with standard transfer learning, while achieving equivalent generalization. We validated the effectiveness of this approach by successfully generalizing to new types of samples using small holographic datasets for training, and achieved (i) ~2.5-fold convergence speed acceleration, (ii) ~20% computation time reduction per epoch, and (iii) improved reconstruction performance over baseline network models trained from scratch. This few-shot transfer learning approach can potentially be applied in other microscopic imaging methods, helping to generalize to new types of samples without the need for extensive training time and data.
Weakly-Supervised Salient Object Detection Using Point Supervison
Mar 22, 2022
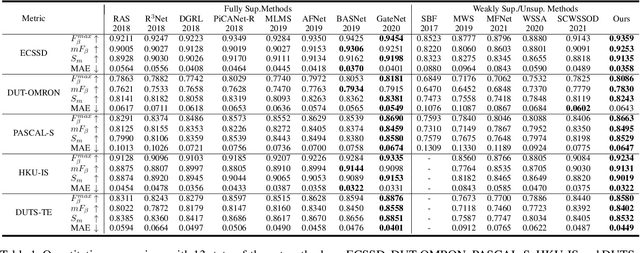
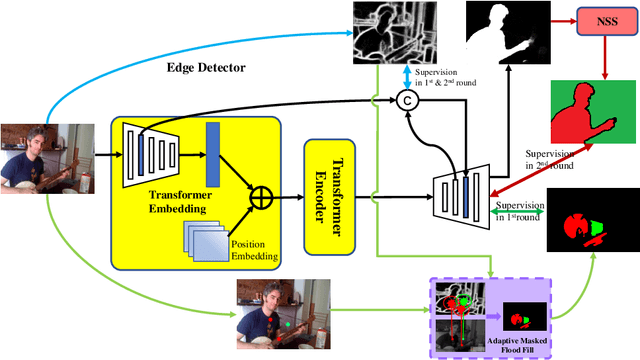
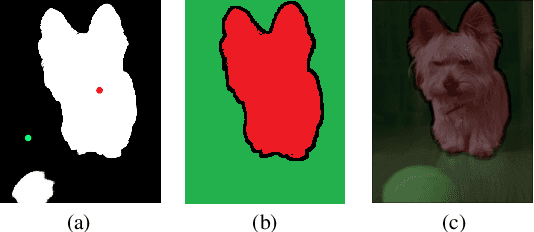
Current state-of-the-art saliency detection models rely heavily on large datasets of accurate pixel-wise annotations, but manually labeling pixels is time-consuming and labor-intensive. There are some weakly supervised methods developed for alleviating the problem, such as image label, bounding box label, and scribble label, while point label still has not been explored in this field. In this paper, we propose a novel weakly-supervised salient object detection method using point supervision. To infer the saliency map, we first design an adaptive masked flood filling algorithm to generate pseudo labels. Then we develop a transformer-based point-supervised saliency detection model to produce the first round of saliency maps. However, due to the sparseness of the label, the weakly supervised model tends to degenerate into a general foreground detection model. To address this issue, we propose a Non-Salient Suppression (NSS) method to optimize the erroneous saliency maps generated in the first round and leverage them for the second round of training. Moreover, we build a new point-supervised dataset (P-DUTS) by relabeling the DUTS dataset. In P-DUTS, there is only one labeled point for each salient object. Comprehensive experiments on five largest benchmark datasets demonstrate our method outperforms the previous state-of-the-art methods trained with the stronger supervision and even surpass several fully supervised state-of-the-art models. The code is available at: https://github.com/shuyonggao/PSOD.
Meta-Forecasting by combining Global DeepRepresentations with Local Adaptation
Nov 05, 2021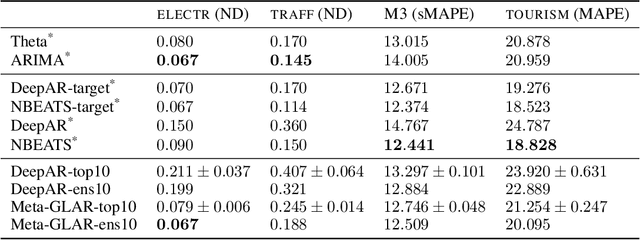
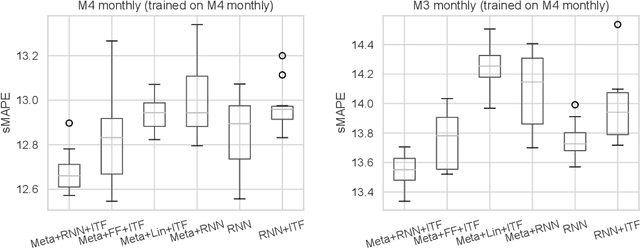
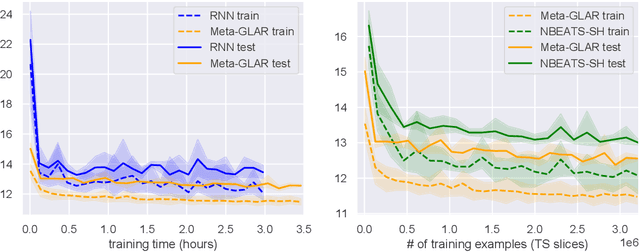

While classical time series forecasting considers individual time series in isolation, recent advances based on deep learning showed that jointly learning from a large pool of related time series can boost the forecasting accuracy. However, the accuracy of these methods suffers greatly when modeling out-of-sample time series, significantly limiting their applicability compared to classical forecasting methods. To bridge this gap, we adopt a meta-learning view of the time series forecasting problem. We introduce a novel forecasting method, called Meta Global-Local Auto-Regression (Meta-GLAR), that adapts to each time series by learning in closed-form the mapping from the representations produced by a recurrent neural network (RNN) to one-step-ahead forecasts. Crucially, the parameters ofthe RNN are learned across multiple time series by backpropagating through the closed-form adaptation mechanism. In our extensive empirical evaluation we show that our method is competitive with the state-of-the-art in out-of-sample forecasting accuracy reported in earlier work.
Real-time Webcam Heart-Rate and Variability Estimation with Clean Ground Truth for Evaluation
Dec 31, 2020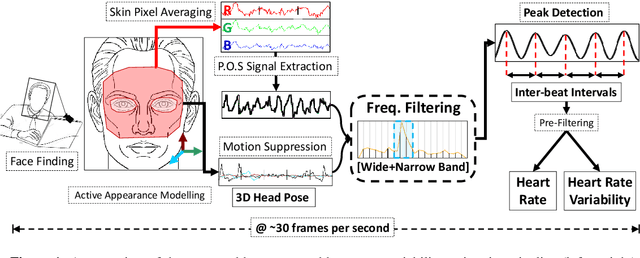
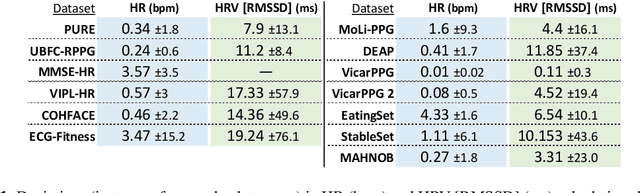
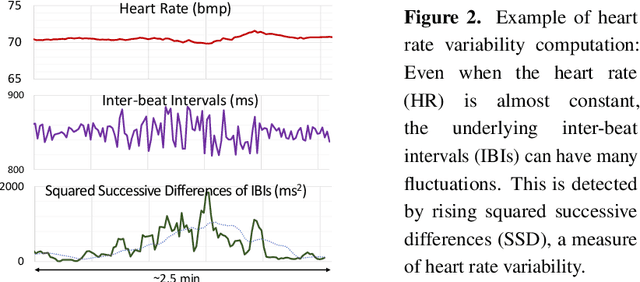
Remote photo-plethysmography (rPPG) uses a camera to estimate a person's heart rate (HR). Similar to how heart rate can provide useful information about a person's vital signs, insights about the underlying physio/psychological conditions can be obtained from heart rate variability (HRV). HRV is a measure of the fine fluctuations in the intervals between heart beats. However, this measure requires temporally locating heart beats with a high degree of precision. We introduce a refined and efficient real-time rPPG pipeline with novel filtering and motion suppression that not only estimates heart rates, but also extracts the pulse waveform to time heart beats and measure heart rate variability. This unsupervised method requires no rPPG specific training and is able to operate in real-time. We also introduce a new multi-modal video dataset, VicarPPG 2, specifically designed to evaluate rPPG algorithms on HR and HRV estimation. We validate and study our method under various conditions on a comprehensive range of public and self-recorded datasets, showing state-of-the-art results and providing useful insights into some unique aspects. Lastly, we make available CleanerPPG, a collection of human-verified ground truth peak/heart-beat annotations for existing rPPG datasets. These verified annotations should make future evaluations and benchmarking of rPPG algorithms more accurate, standardized and fair.
* Published in the MDPI Applied Sciences journal special issue Video Analysis for Health Monitoring on December 2, 2020. arXiv admin note: text overlap with arXiv:1909.01206
Churn prediction in online gambling
Jan 07, 2022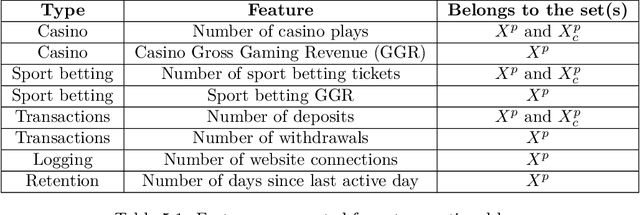
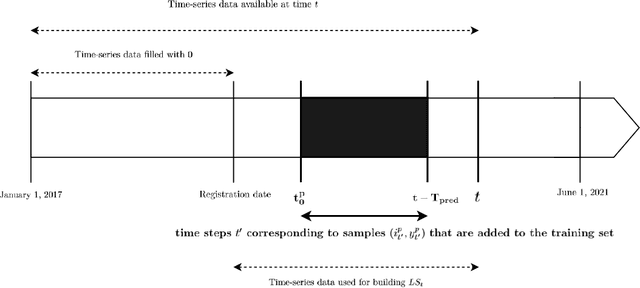

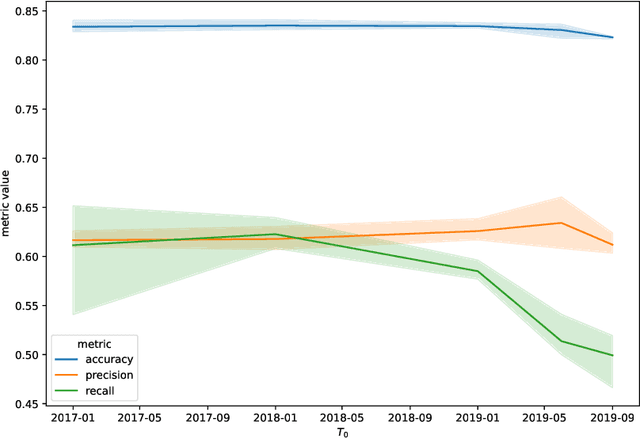
In business retention, churn prevention has always been a major concern. This work contributes to this domain by formalizing the problem of churn prediction in the context of online gambling as a binary classification task. We also propose an algorithmic answer to this problem based on recurrent neural network. This algorithm is tested with online gambling data that have the form of time series, which can be efficiently processed by recurrent neural networks. To evaluate the performances of the trained models, standard machine learning metrics were used, such as accuracy, precision and recall. For this problem in particular, the conducted experiments allowed to assess that the choice of a specific architecture depends on the metric which is given the greatest importance. Architectures using nBRC favour precision, those using LSTM give better recall, while GRU-based architectures allow a higher accuracy and balance two other metrics. Moreover, further experiments showed that using only the more recent time-series histories to train the networks decreases the quality of the results. We also study the performances of models learned at a specific instant $t$, at other times $t^{\prime} > t$. The results show that the performances of the models learned at time $t$ remain good at the following instants $t^{\prime} > t$, suggesting that there is no need to refresh the models at a high rate. However, the performances of the models were subject to noticeable variance due to one-off events impacting the data.
PC-SwinMorph: Patch Representation for Unsupervised Medical Image Registration and Segmentation
Mar 10, 2022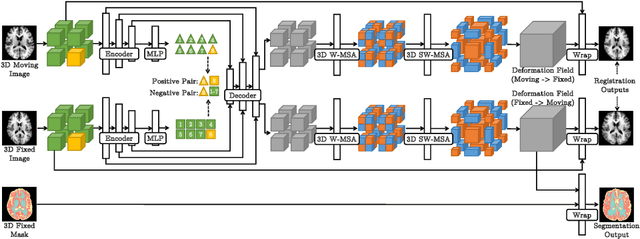
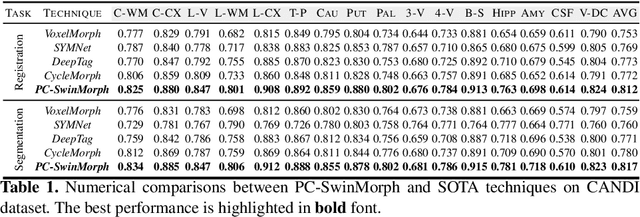
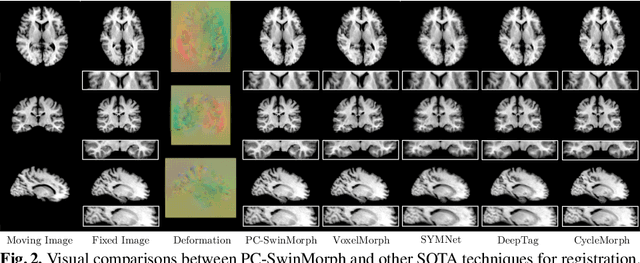
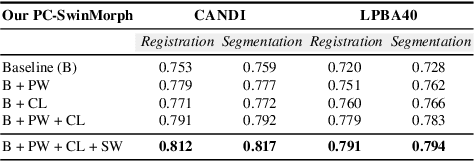
Medical image registration and segmentation are critical tasks for several clinical procedures. Manual realisation of those tasks is time-consuming and the quality is highly dependent on the level of expertise of the physician. To mitigate that laborious task, automatic tools have been developed where the majority of solutions are supervised techniques. However, in medical domain, the strong assumption of having a well-representative ground truth is far from being realistic. To overcome this challenge, unsupervised techniques have been investigated. However, they are still limited in performance and they fail to produce plausible results. In this work, we propose a novel unified unsupervised framework for image registration and segmentation that we called PC-SwinMorph. The core of our framework is two patch-based strategies, where we demonstrate that patch representation is key for performance gain. We first introduce a patch-based contrastive strategy that enforces locality conditions and richer feature representation. Secondly, we utilise a 3D window/shifted-window multi-head self-attention module as a patch stitching strategy to eliminate artifacts from the patch splitting. We demonstrate, through a set of numerical and visual results, that our technique outperforms current state-of-the-art unsupervised techniques.
Deep Space-Time Video Upsampling Networks
Apr 06, 2020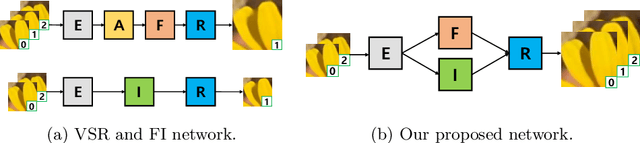
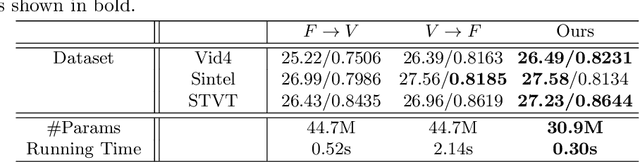

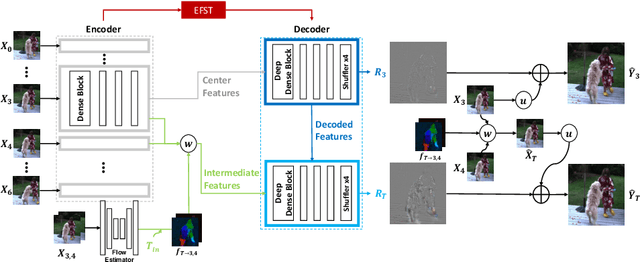
Video super-resolution (VSR) and frame interpolation (FI) are traditional computer vision problems, and the performance have been improving by incorporating deep learning recently. In this paper, we investigate the problem of jointly upsampling videos both in space and time, which is becoming more important with advances in display systems. One solution for this is to run VSR and FI, one by one, independently. This is highly inefficient as heavy deep neural networks (DNN) are involved in each solution. To this end, we propose an end-to-end DNN framework for the space-time video upsampling by efficiently merging VSR and FI into a joint framework. In our framework, a novel weighting scheme is proposed to fuse input frames effectively without explicit motion compensation for efficient processing of videos. The results show better results both quantitatively and qualitatively, while reducing the computation time (x7 faster) and the number of parameters (30%) compared to baselines.
Configuration Space Decomposition for Scalable Proxy Collision Checking in Robot Planning and Control
Jan 13, 2022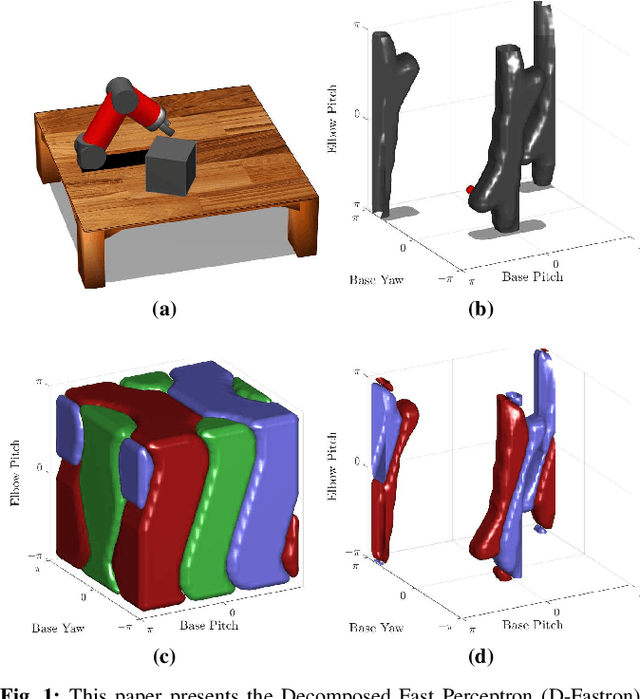
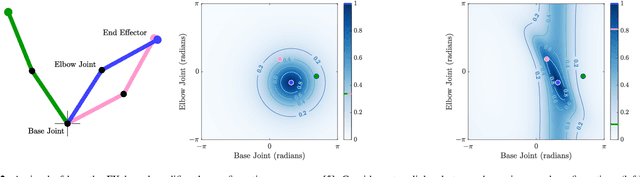


Real-time robot motion planning in complex high-dimensional environments remains an open problem. Motion planning algorithms, and their underlying collision checkers, are crucial to any robot control stack. Collision checking takes up a large portion of computational time in robot motion planning. Existing collision checkers make trade-offs between speed and accuracy and scale poorly to high-dimensional, complex environments. We present a novel space decomposition method using K-Means clustering in the Forward Kinematics space to accelerate proxy collision checking. We train individual configuration space models using Fastron, a kernel perceptron algorithm, on these decomposed subspaces, yielding lightweight yet highly accurate models that can be queried rapidly and scale better to more complex environments. We demonstrate this new method, called Decomposed Fast Perceptron (D-Fastron), on the 7-DOF Baxter robot producing on average 29x faster collision checks and up to 9.8x faster motion planning compared to state-of-the-art geometric collision checkers.
Demand Forecasting for Platelet Usage: from Univariate Time Series to Multivariate Models
Jan 06, 2021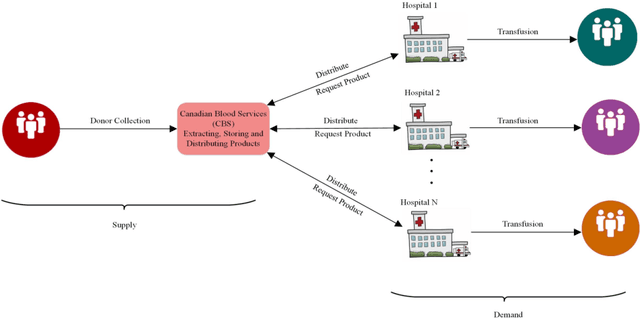
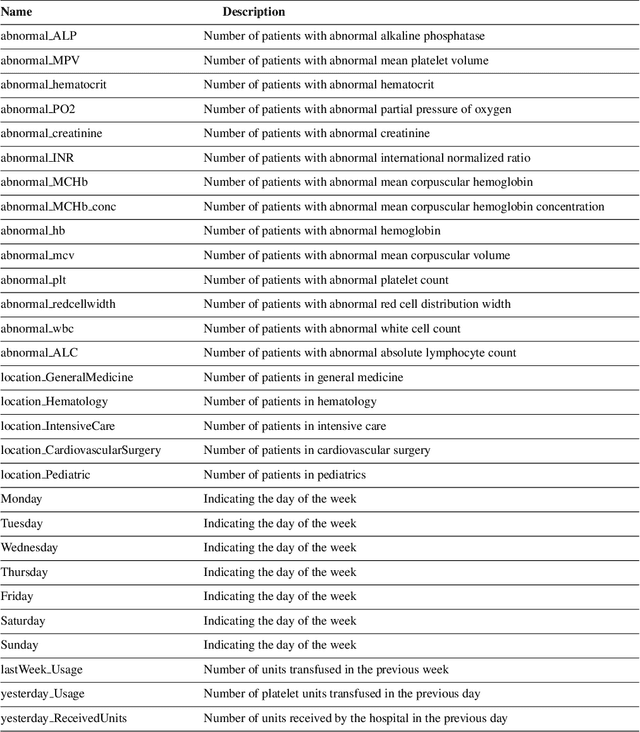
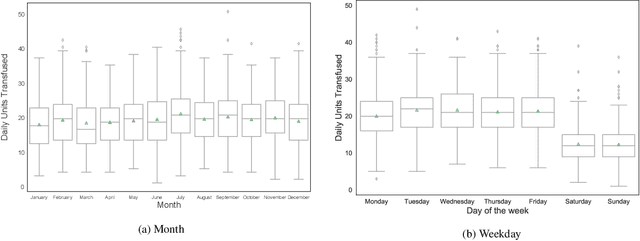

Platelet products are both expensive and have very short shelf lives. As usage rates for platelets are highly variable, the effective management of platelet demand and supply is very important yet challenging. The primary goal of this paper is to present an efficient forecasting model for platelet demand at Canadian Blood Services (CBS). To accomplish this goal, four different demand forecasting methods, ARIMA (Auto Regressive Moving Average), Prophet, lasso regression (least absolute shrinkage and selection operator) and LSTM (Long Short-Term Memory) networks are utilized and evaluated. We use a large clinical dataset for a centralized blood distribution centre for four hospitals in Hamilton, Ontario, spanning from 2010 to 2018 and consisting of daily platelet transfusions along with information such as the product specifications, the recipients' characteristics, and the recipients' laboratory test results. This study is the first to utilize different methods from statistical time series models to data-driven regression and a machine learning technique for platelet transfusion using clinical predictors and with different amounts of data. We find that the multivariate approaches have the highest accuracy in general, however, if sufficient data are available, a simpler time series approach such as ARIMA appears to be sufficient. We also comment on the approach to choose clinical indicators (inputs) for the multivariate models.
A Parallel Approach for Real-Time Face Recognition from a Large Database
Nov 01, 2020

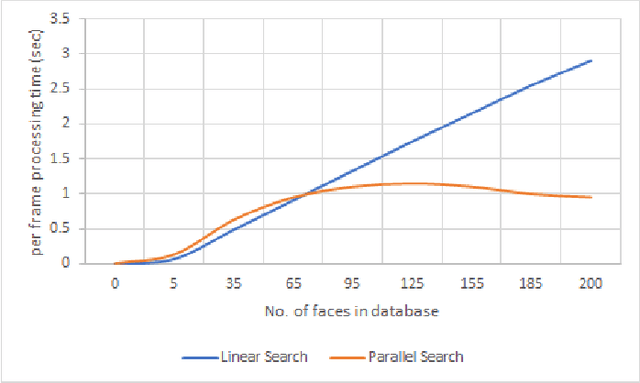
We present a new facial recognition system, capable of identifying a person, provided their likeness has been previously stored in the system, in real time. The system is based on storing and comparing facial embeddings of the subject, and identifying them later within a live video feed. This system is highly accurate, and is able to tag people with their ID in real time. It is able to do so, even when using a database containing thousands of facial embeddings, by using a parallelized searching technique. This makes the system quite fast and allows it to be highly scalable.