 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HIPA: Hierarchical Patch Transformer for Single Image Super Resolution
Mar 19, 2022

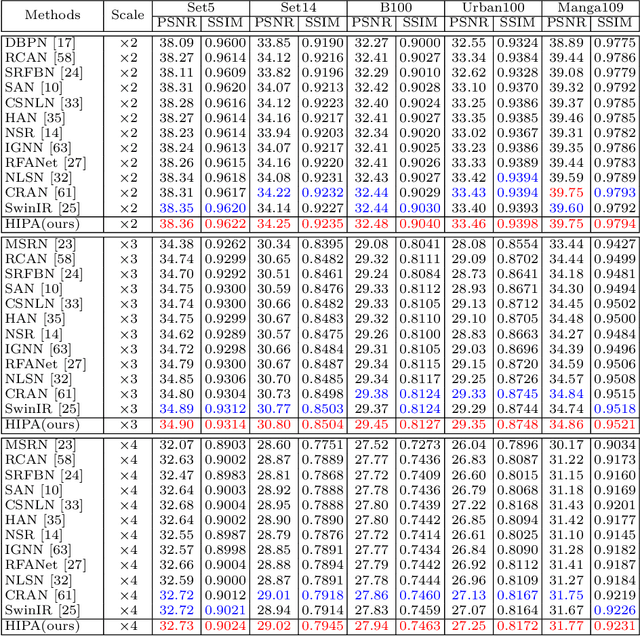
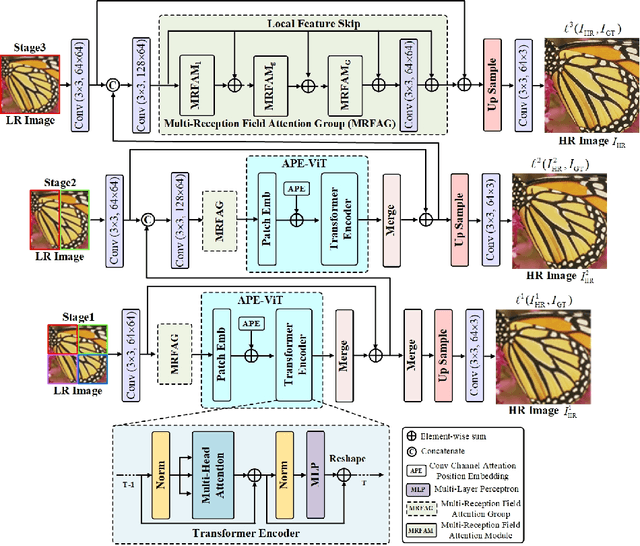

Transformer-based architectures start to emerge in single image super resolution (SISR) and have achieved promising performance. Most existing Vision Transformers divide images into the same number of patches with a fixed size, which may not be optimal for restoring patches with different levels of texture richness. This paper presents HIPA, a novel Transformer architecture that progressively recovers the high resolution image using a hierarchical patch partition. Specifically, we build a cascaded model that processes an input image in multiple stages, where we start with tokens with small patch sizes and gradually merge to the full resolution. Such a hierarchical patch mechanism not only explicitly enables feature aggregation at multiple resolutions but also adaptively learns patch-aware features for different image regions, e.g., using a smaller patch for areas with fine details and a larger patch for textureless regions. Meanwhile, a new attention-based position encoding scheme for Transformer is proposed to let the network focus on which tokens should be paid more attention by assigning different weights to different tokens, which is the first time to our best knowledge. Furthermore, we also propose a new multi-reception field attention module to enlarge the convolution reception field from different branches. The experimental results on several public datasets demonstrate the superior performance of the proposed HIPA over previous methods quantitatively and qualitatively.
PEg TRAnsfer Workflow recognition challenge report: Does multi-modal data improve recognition?
Feb 11, 2022
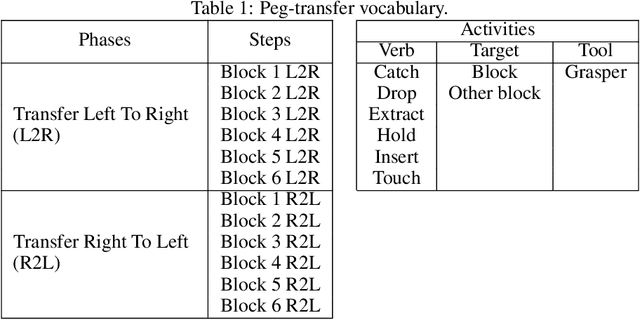
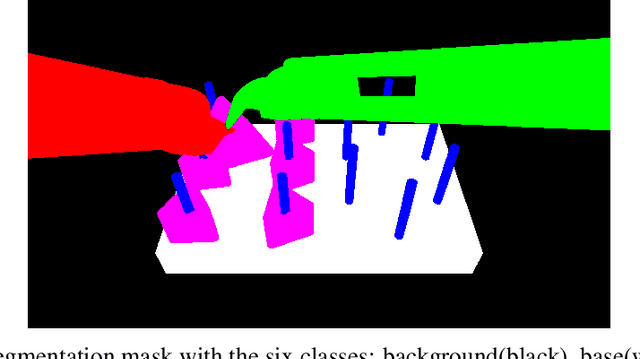
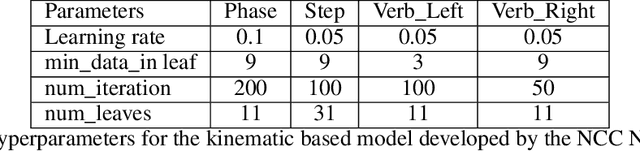
This paper presents the design and results of the "PEg TRAnsfert Workflow recognition" (PETRAW) challenge whose objective was to develop surgical workflow recognition methods based on one or several modalities, among video, kinematic, and segmentation data, in order to study their added value. The PETRAW challenge provided a data set of 150 peg transfer sequences performed on a virtual simulator. This data set was composed of videos, kinematics, semantic segmentation, and workflow annotations which described the sequences at three different granularity levels: phase, step, and activity. Five tasks were proposed to the participants: three of them were related to the recognition of all granularities with one of the available modalities, while the others addressed the recognition with a combination of modalities. Average application-dependent balanced accuracy (AD-Accuracy) was used as evaluation metric to take unbalanced classes into account and because it is more clinically relevant than a frame-by-frame score. Seven teams participated in at least one task and four of them in all tasks. Best results are obtained with the use of the video and the kinematics data with an AD-Accuracy between 93% and 90% for the four teams who participated in all tasks. The improvement between video/kinematic-based methods and the uni-modality ones was significant for all of the teams. However, the difference in testing execution time between the video/kinematic-based and the kinematic-based methods has to be taken into consideration. Is it relevant to spend 20 to 200 times more computing time for less than 3% of improvement? The PETRAW data set is publicly available at www.synapse.org/PETRAW to encourage further research in surgical workflow recognition.
A Parallel Approach for Real-Time Face Recognition from a Large Database
Nov 01, 2020
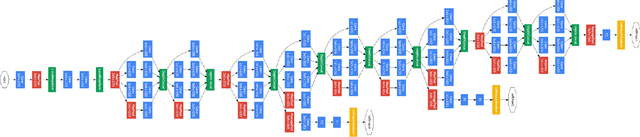

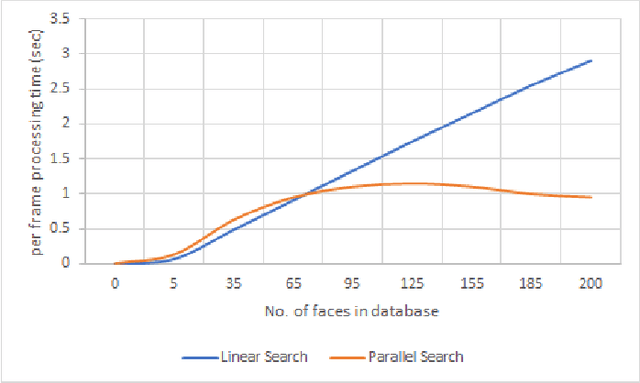
We present a new facial recognition system, capable of identifying a person, provided their likeness has been previously stored in the system, in real time. The system is based on storing and comparing facial embeddings of the subject, and identifying them later within a live video feed. This system is highly accurate, and is able to tag people with their ID in real time. It is able to do so, even when using a database containing thousands of facial embeddings, by using a parallelized searching technique. This makes the system quite fast and allows it to be highly scalable.
Reducing the Gibbs effect in multimodal medical imaging by the Fake Nodes Approach
Feb 21, 2022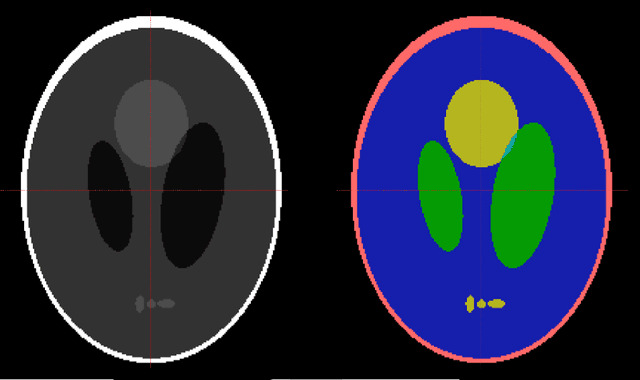
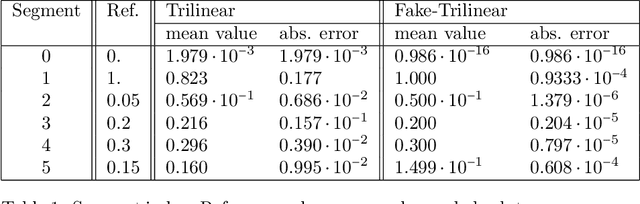

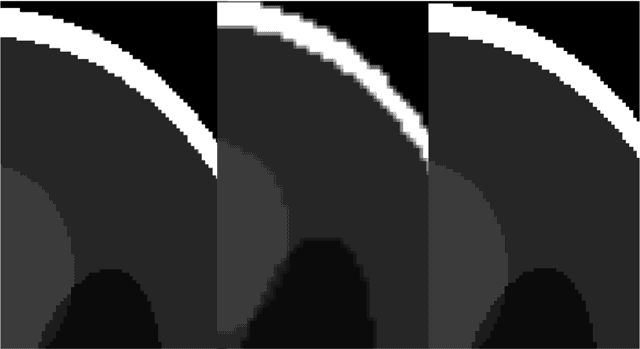
It is a common practice in multimodal medical imaging to undersample the anatomically-derived segmentation images to measure the mean activity of a co-acquired functional image. This practice avoids the resampling-related Gibbs effect that would occur in oversampling the functional image. As sides effect, waste of time and efforts are produced since the anatomical segmentation at full resolution is performed in many hours of computations or manual work. In this work we explain the commonly-used resampling methods and give errors bound in the cases of continuous and discontinuous signals. Then we propose a Fake Nodes scheme for image resampling designed to reduce the Gibbs effect when oversampling the functional image. This new approach is compared to the traditional counterpart in two significant experiments, both showing that Fake Nodes resampling gives smaller errors.
Demand Forecasting for Platelet Usage: from Univariate Time Series to Multivariate Models
Jan 06, 2021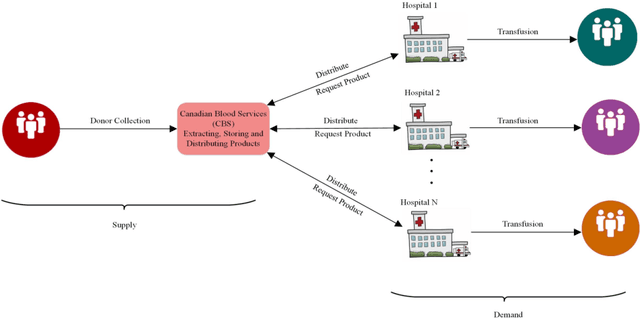
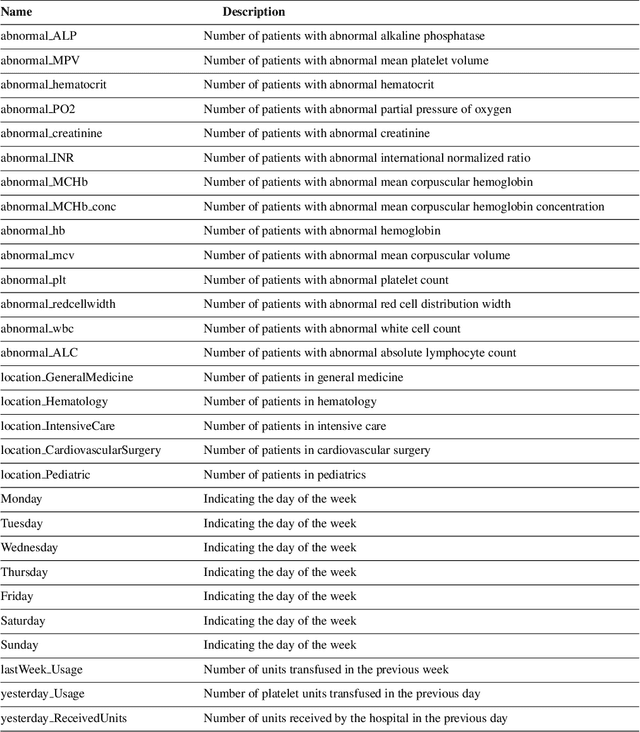
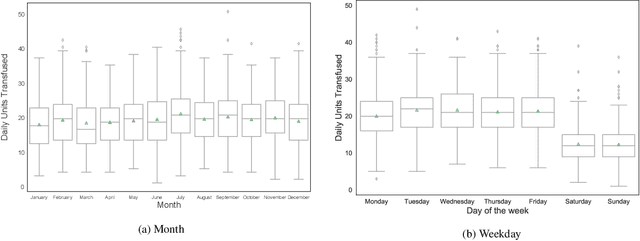

Platelet products are both expensive and have very short shelf lives. As usage rates for platelets are highly variable, the effective management of platelet demand and supply is very important yet challenging. The primary goal of this paper is to present an efficient forecasting model for platelet demand at Canadian Blood Services (CBS). To accomplish this goal, four different demand forecasting methods, ARIMA (Auto Regressive Moving Average), Prophet, lasso regression (least absolute shrinkage and selection operator) and LSTM (Long Short-Term Memory) networks are utilized and evaluated. We use a large clinical dataset for a centralized blood distribution centre for four hospitals in Hamilton, Ontario, spanning from 2010 to 2018 and consisting of daily platelet transfusions along with information such as the product specifications, the recipients' characteristics, and the recipients' laboratory test results. This study is the first to utilize different methods from statistical time series models to data-driven regression and a machine learning technique for platelet transfusion using clinical predictors and with different amounts of data. We find that the multivariate approaches have the highest accuracy in general, however, if sufficient data are available, a simpler time series approach such as ARIMA appears to be sufficient. We also comment on the approach to choose clinical indicators (inputs) for the multivariate models.
Hierarchically Structured Scheduling and Execution of Tasks in a Multi-Agent Environment
Mar 06, 2022
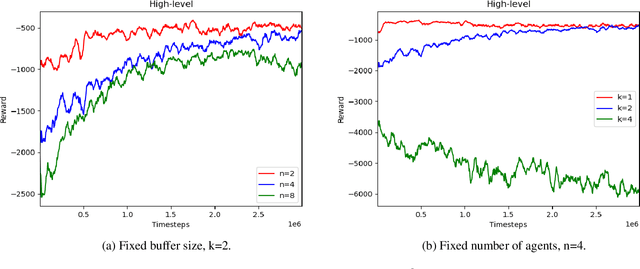
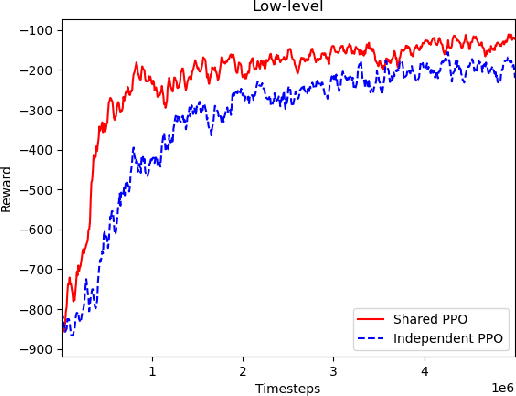
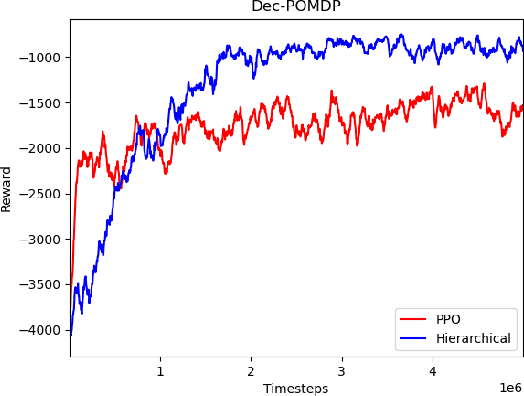
In a warehouse environment, tasks appear dynamically. Consequently, a task management system that matches them with the workforce too early (e.g., weeks in advance) is necessarily sub-optimal. Also, the rapidly increasing size of the action space of such a system consists of a significant problem for traditional schedulers. Reinforcement learning, however, is suited to deal with issues requiring making sequential decisions towards a long-term, often remote, goal. In this work, we set ourselves on a problem that presents itself with a hierarchical structure: the task-scheduling, by a centralised agent, in a dynamic warehouse multi-agent environment and the execution of one such schedule, by decentralised agents with only partial observability thereof. We propose to use deep reinforcement learning to solve both the high-level scheduling problem and the low-level multi-agent problem of schedule execution. Finally, we also conceive the case where centralisation is impossible at test time and workers must learn how to cooperate in executing the tasks in an environment with no schedule and only partial observability.
Evaluating BERT-based Pre-training Language Models for Detecting Misinformation
Mar 15, 2022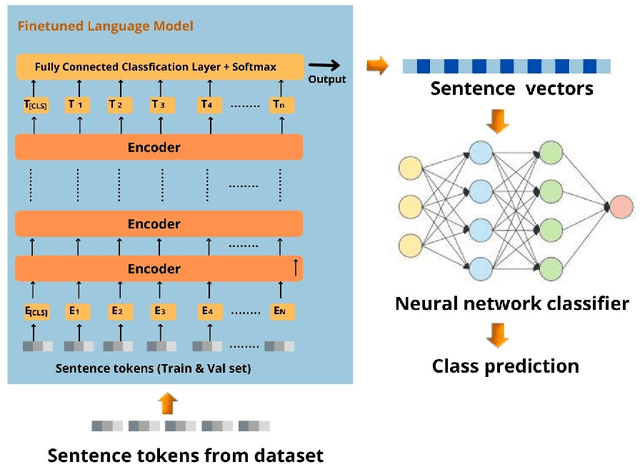
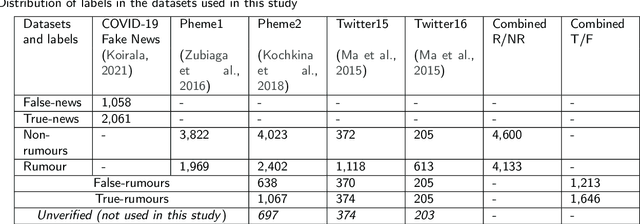
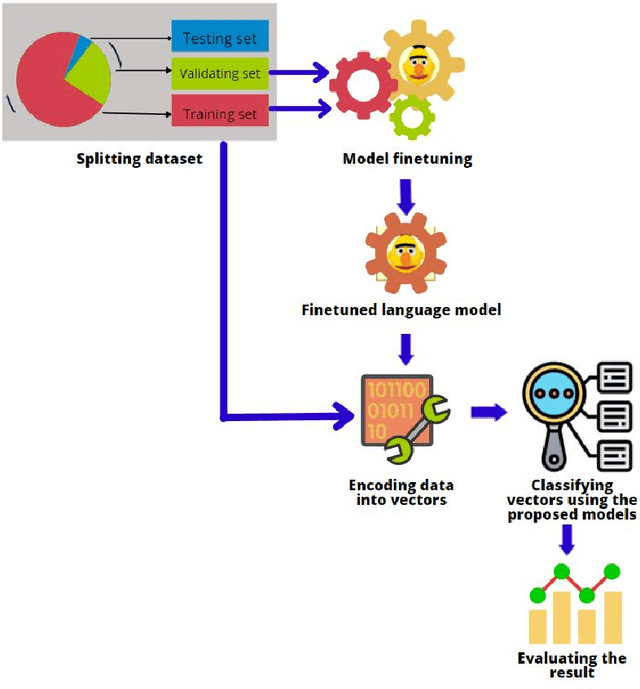
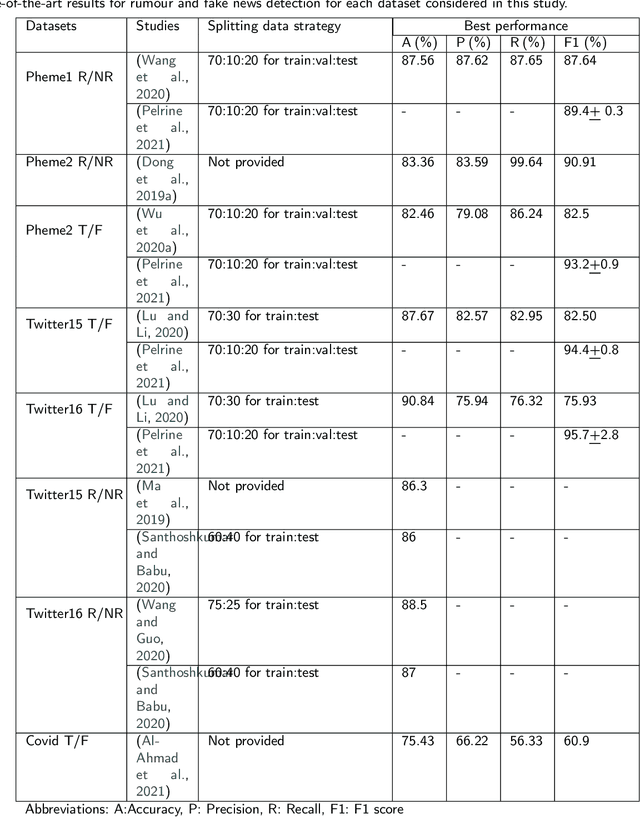
It is challenging to control the quality of online information due to the lack of supervision over all the information posted online. Manual checking is almost impossible given the vast number of posts made on online media and how quickly they spread. Therefore, there is a need for automated rumour detection techniques to limit the adverse effects of spreading misinformation. Previous studies mainly focused on finding and extracting the significant features of text data. However, extracting features is time-consuming and not a highly effective process. This study proposes the BERT- based pre-trained language models to encode text data into vectors and utilise neural network models to classify these vectors to detect misinformation. Furthermore, different language models (LM) ' performance with different trainable parameters was compared. The proposed technique is tested on different short and long text datasets. The result of the proposed technique has been compared with the state-of-the-art techniques on the same datasets. The results show that the proposed technique performs better than the state-of-the-art techniques. We also tested the proposed technique by combining the datasets. The results demonstrated that the large data training and testing size considerably improves the technique's performance.
Compactness Score: A Fast Filter Method for Unsupervised Feature Selection
Jan 31, 2022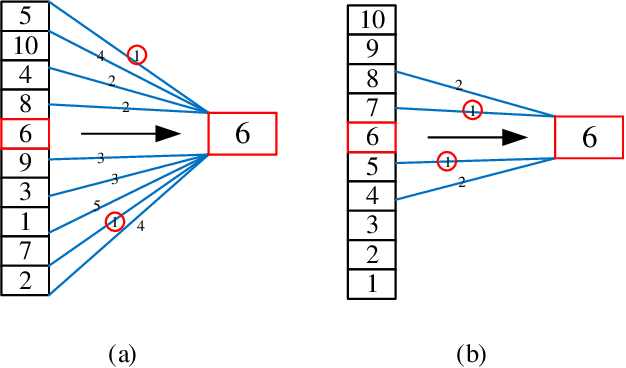
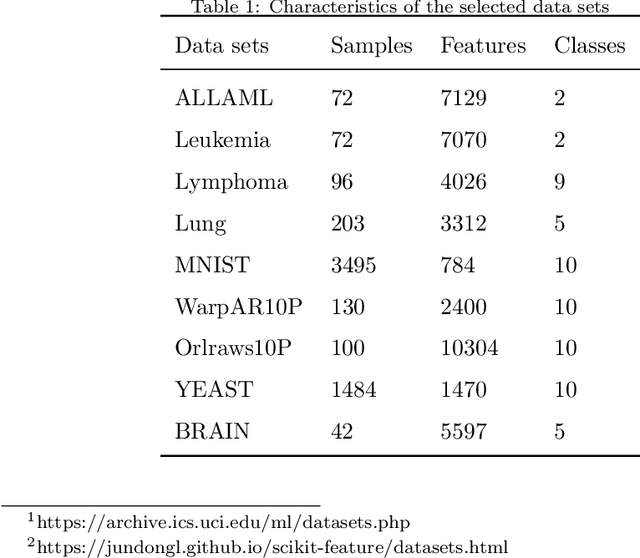
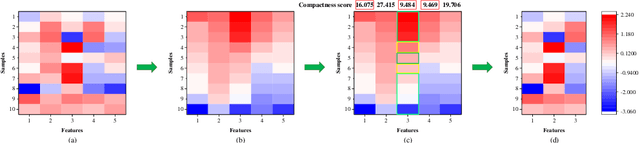
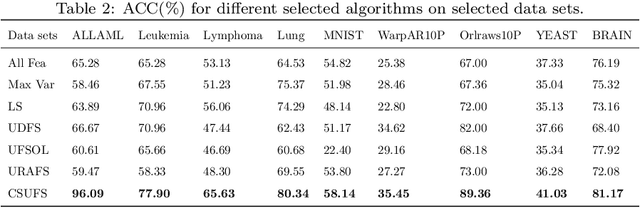
For feature engineering, feature selection seems to be an important research content in which is anticipated to select "excellent" features from candidate ones. Different functions can be realized through feature selection, such as dimensionality reduction, model effect improvement, and model performance improvement. Along with the flourish of the information age, huge amounts of high-dimensional data are generated day by day, while we need to spare great efforts and time to label such data. Therefore, various algorithms are proposed to address such data, among which unsupervised feature selection has attracted tremendous interests. In many classification tasks, researchers found that data seem to be usually close to each other if they are from the same class; thus, local compactness is of great importance for the evaluation of a feature. In this manuscript, we propose a fast unsupervised feature selection method, named as, Compactness Score (CSUFS), to select desired features. To demonstrate the efficiency and accuracy, several data sets are chosen with intensive experiments being performed. Later, the effectiveness and superiority of our method are revealed through addressing clustering tasks. Here, the performance is indicated by several well-known evaluation metrics, while the efficiency is reflected by the corresponding running time. As revealed by the simulation results, our proposed algorithm seems to be more accurate and efficient compared with existing algorithms.
Meta-Forecasting by combining Global DeepRepresentations with Local Adaptation
Nov 05, 2021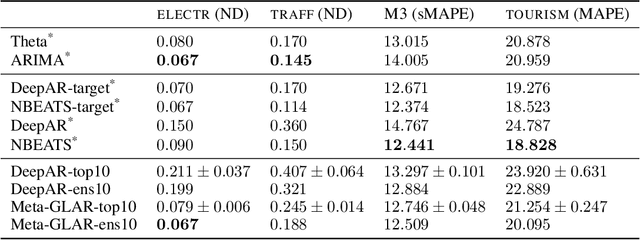
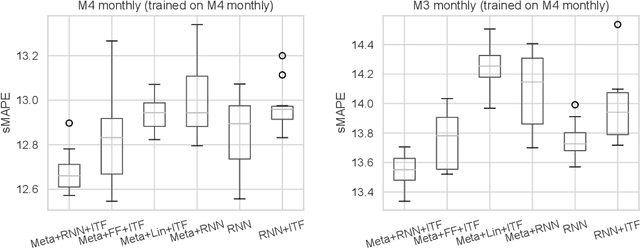
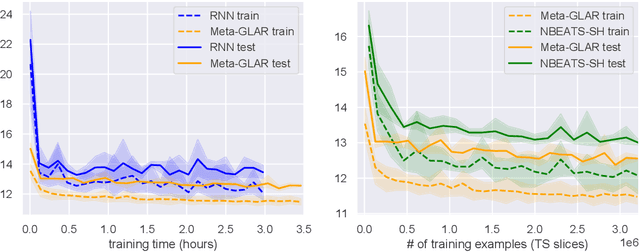

While classical time series forecasting considers individual time series in isolation, recent advances based on deep learning showed that jointly learning from a large pool of related time series can boost the forecasting accuracy. However, the accuracy of these methods suffers greatly when modeling out-of-sample time series, significantly limiting their applicability compared to classical forecasting methods. To bridge this gap, we adopt a meta-learning view of the time series forecasting problem. We introduce a novel forecasting method, called Meta Global-Local Auto-Regression (Meta-GLAR), that adapts to each time series by learning in closed-form the mapping from the representations produced by a recurrent neural network (RNN) to one-step-ahead forecasts. Crucially, the parameters ofthe RNN are learned across multiple time series by backpropagating through the closed-form adaptation mechanism. In our extensive empirical evaluation we show that our method is competitive with the state-of-the-art in out-of-sample forecasting accuracy reported in earlier work.
Human-AI Collaboration Enables More Empathic Conversations in Text-based Peer-to-Peer Mental Health Support
Mar 28, 2022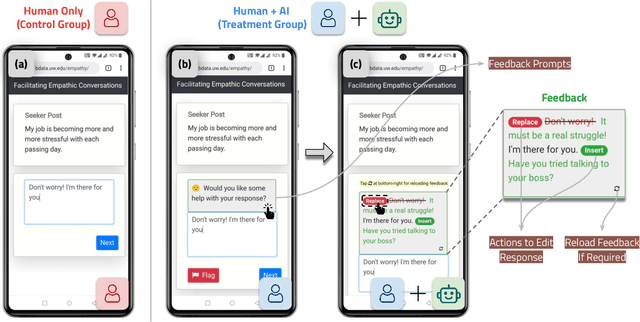
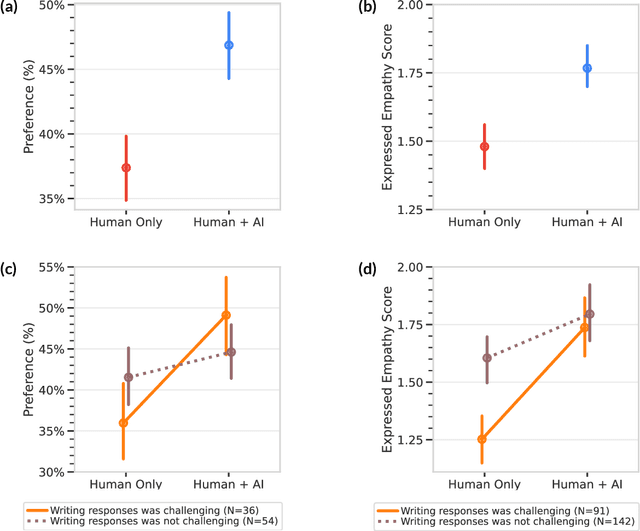
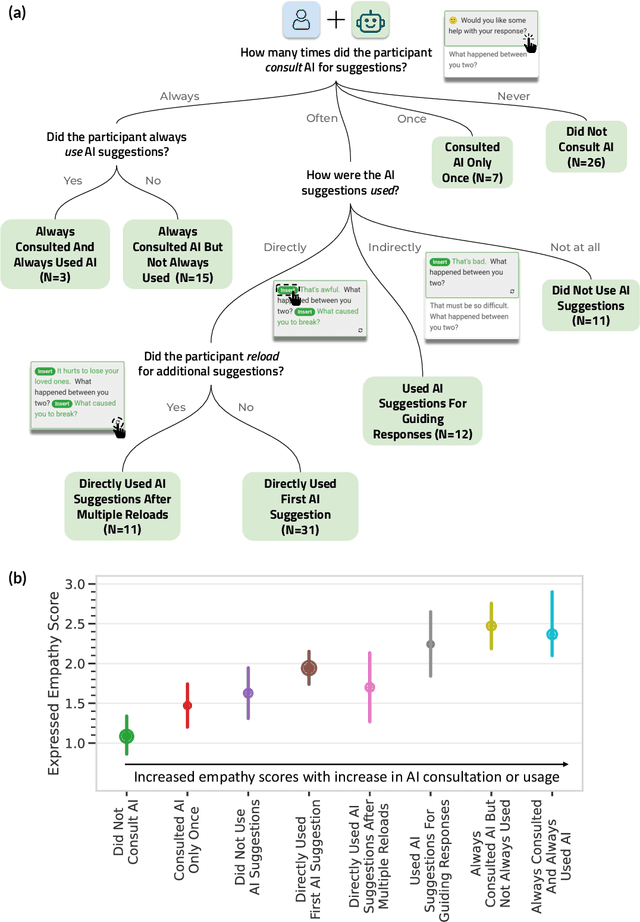
Advances in artificial intelligence (AI) are enabling systems that augment and collaborate with humans to perform simple, mechanistic tasks like scheduling meetings and grammar-checking text. However, such Human-AI collaboration poses challenges for more complex, creative tasks, such as carrying out empathic conversations, due to difficulties of AI systems in understanding complex human emotions and the open-ended nature of these tasks. Here, we focus on peer-to-peer mental health support, a setting in which empathy is critical for success, and examine how AI can collaborate with humans to facilitate peer empathy during textual, online supportive conversations. We develop Hailey, an AI-in-the-loop agent that provides just-in-time feedback to help participants who provide support (peer supporters) respond more empathically to those seeking help (support seekers). We evaluate Hailey in a non-clinical randomized controlled trial with real-world peer supporters on TalkLife (N=300), a large online peer-to-peer support platform. We show that our Human-AI collaboration approach leads to a 19.60% increase in conversational empathy between peers overall. Furthermore, we find a larger 38.88% increase in empathy within the subsample of peer supporters who self-identify as experiencing difficulty providing support. We systematically analyze the Human-AI collaboration patterns and find that peer supporters are able to use the AI feedback both directly and indirectly without becoming overly reliant on AI while reporting improved self-efficacy post-feedback. Our findings demonstrate the potential of feedback-driven, AI-in-the-loop writing systems to empower humans in open-ended, social, creative tasks such as empathic conversations.