 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
UAV-Aided Decentralized Learning over Mesh Networks
Mar 02, 2022
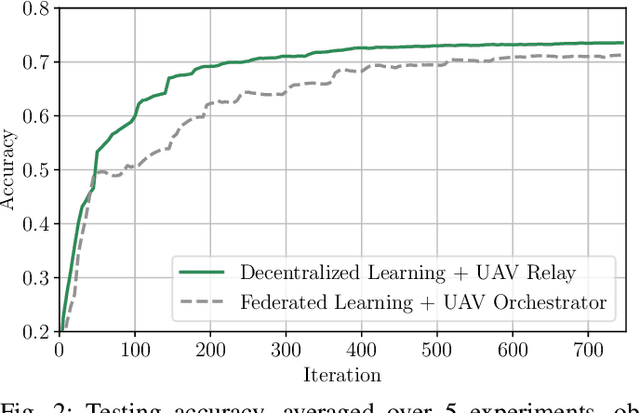
Decentralized learning empowers wireless network devices to collaboratively train a machine learning (ML) model relying solely on device-to-device (D2D) communication. It is known that the convergence speed of decentralized optimization algorithms severely depends on the degree of the network connectivity, with denser network topologies leading to shorter convergence time. Consequently, local connectivity of real world mesh networks, due to the limited communication range of its wireless nodes, undermines the efficiency of decentralized learning protocols, rendering them potentially impracticable. In this work we investigate the role of an unmanned aerial vehicle (UAV), used as flying relay, in facilitating decentralized learning procedures in such challenging conditions. We propose an optimized UAV trajectory, that is defined as a sequence of waypoints that the UAV visits sequentially in order to transfer intelligence across sparsely connected group of users. We then provide a series of experiments highlighting the essential role of UAVs in the context of decentralized learning over mesh networks.
Classification of Hyperspectral Images by Using Spectral Data and Fully Connected Neural Network
Jan 08, 2022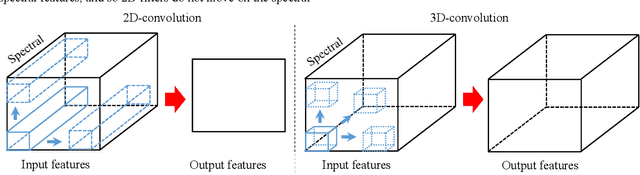
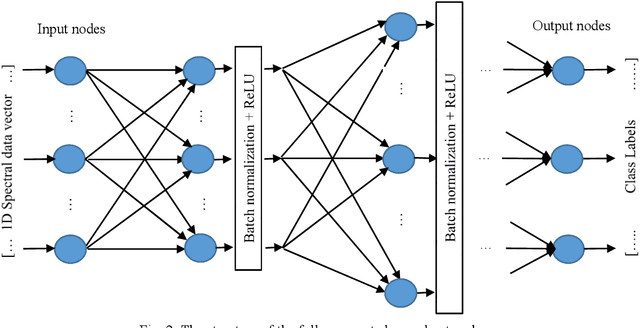
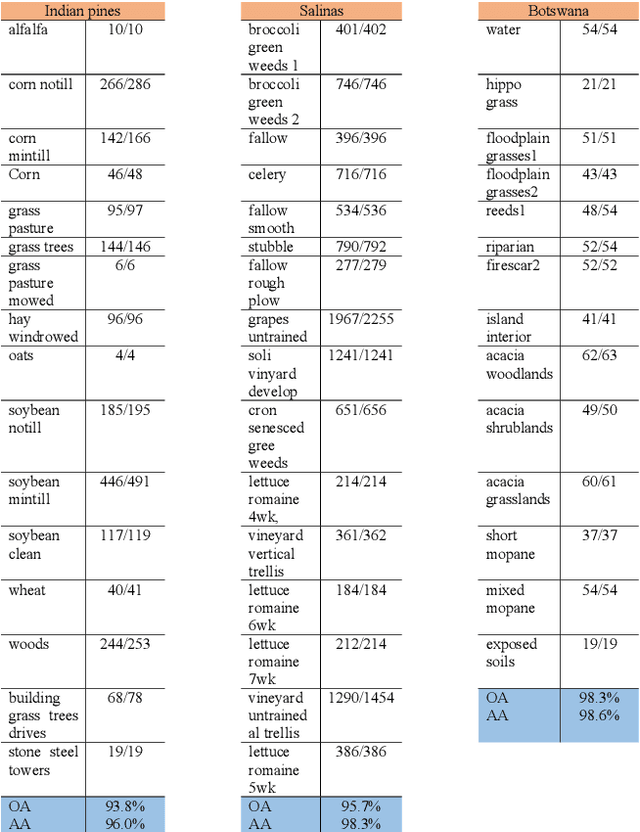
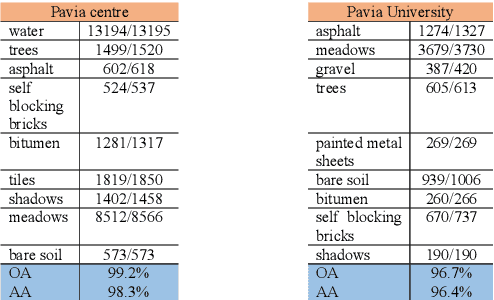
It is observed that high classification performance is achieved for one- and two-dimensional signals by using deep learning methods. In this context, most researchers have tried to classify hyperspectral images by using deep learning methods and classification success over 90% has been achieved for these images. Deep neural networks (DNN) actually consist of two parts: i) Convolutional neural network (CNN) and ii) fully connected neural network (FCNN). While CNN determines the features, FCNN is used in classification. In classification of the hyperspectral images, it is observed that almost all of the researchers used 2D or 3D convolution filters on the spatial data beside spectral data (features). It is convenient to use convolution filters on images or time signals. In hyperspectral images, each pixel is represented by a signature vector which consists of individual features that are independent of each other. Since the order of the features in the vector can be changed, it doesn't make sense to use convolution filters on these features as on time signals. At the same time, since the hyperspectral images do not have a textural structure, there is no need to use spatial data besides spectral data. In this study, hyperspectral images of Indian pines, Salinas, Pavia centre, Pavia university and Botswana are classified by using only fully connected neural network and the spectral data with one dimensional. An average accuracy of 97.5% is achieved for the test sets of all hyperspectral images.
Towards Robust Online Dialogue Response Generation
Mar 07, 2022
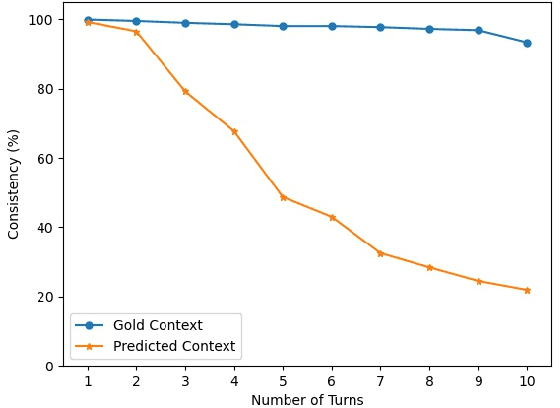

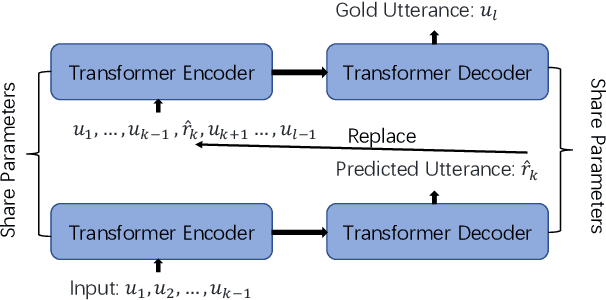
Although pre-trained sequence-to-sequence models have achieved great success in dialogue response generation, chatbots still suffer from generating inconsistent responses in real-world practice, especially in multi-turn settings. We argue that this can be caused by a discrepancy between training and real-world testing. At training time, chatbot generates the response with the golden context, while it has to generate based on the context consisting of both user utterances and the model predicted utterances during real-world testing. With the growth of the number of utterances, this discrepancy becomes more serious in the multi-turn settings. In this paper, we propose a hierarchical sampling-based method consisting of both utterance-level sampling and semi-utterance-level sampling, to alleviate the discrepancy, which implicitly increases the dialogue coherence. We further adopt reinforcement learning and re-ranking methods to explicitly optimize the dialogue coherence during training and inference, respectively. Empirical experiments show the effectiveness of the proposed methods for improving the robustness of chatbots in real practice.
Real-Time Detection of Drowsiness Among Vehicle Drivers: A Machine Learning Algorithm for Embedded Systems
Nov 04, 2021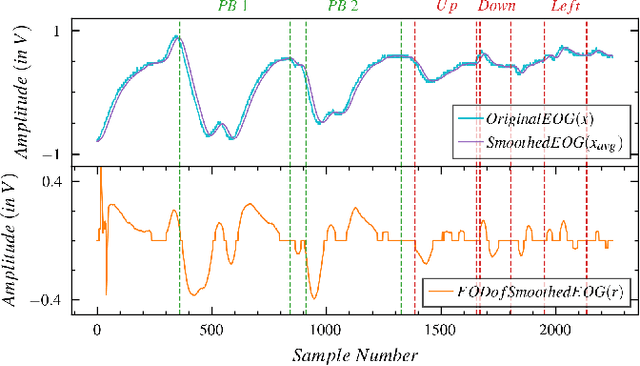
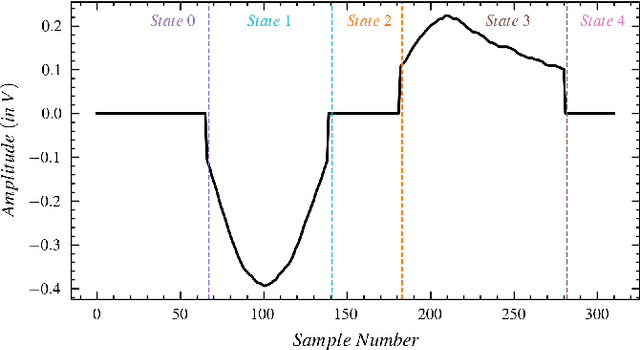
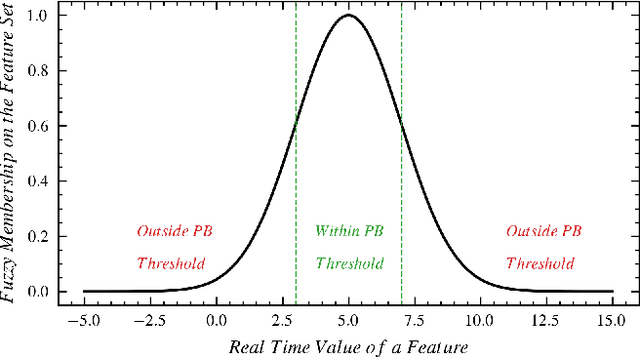

Numerous studies have established the necessity for developing safety equipment to detect drowsiness among vehicle drivers. However, for reliable implementations, such systems must employ dependable sources of stimuli; through Electrooculography (EOG), the tendencies of drowsiness can be directly sensed by measuring blinks of prolonged durations. While conventional machine learning (ML) algorithms can be utilized for the detection and classification of these prolonged blinks (PB), executing them on microcontroller units (MCU) may prove to be a laborious task. Hence, by keeping resource constraints and practicality in mind, an ML algorithm is proposed in this study to identify PBs executed by an individual with desirable accuracy and precision while being efficient enough to be deployed on portable wearables using economic MCUs. Furthermore, the suggested algorithm is subjected to multiple rounds of testing in this study thereby, establishing its possibility as a feasible drowsiness detection measure for wearable systems.
Bregman Deviations of Generic Exponential Families
Jan 18, 2022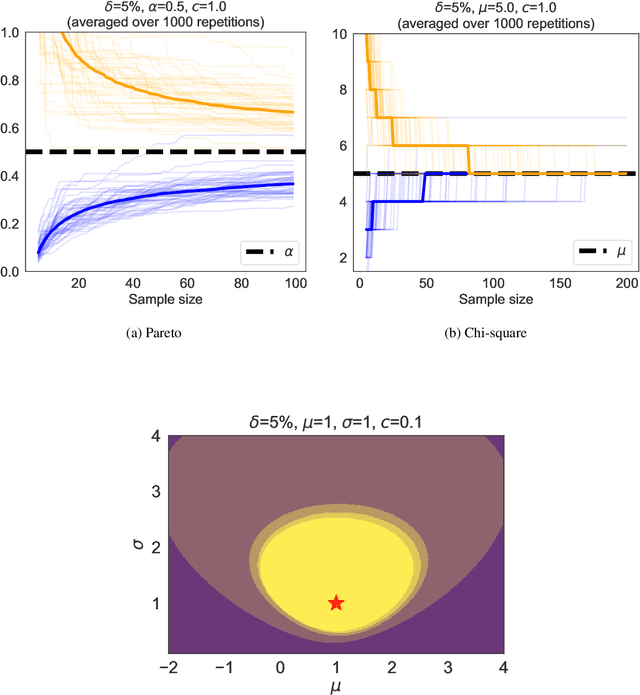
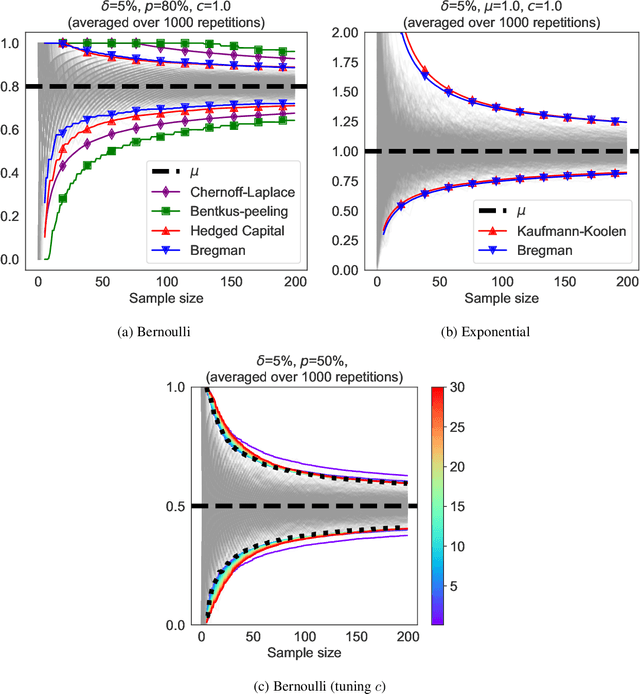
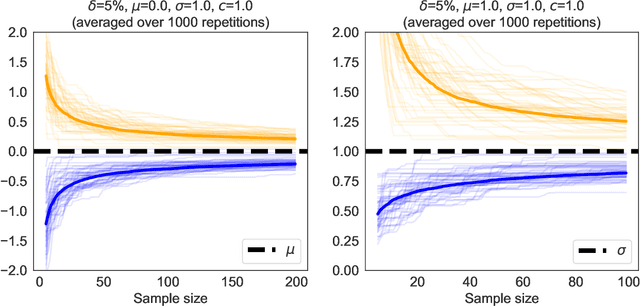
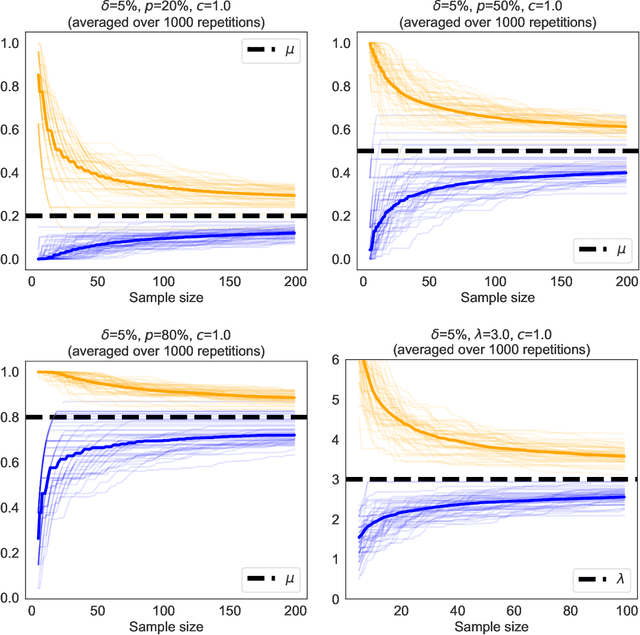
We revisit the method of mixture technique, also known as the Laplace method, to study the concentration phenomenon in generic exponential families. Combining the properties of Bregman divergence associated with log-partition function of the family with the method of mixtures for super-martingales, we establish a generic bound controlling the Bregman divergence between the parameter of the family and a finite sample estimate of the parameter. Our bound is time-uniform and makes appear a quantity extending the classical \textit{information gain} to exponential families, which we call the \textit{Bregman information gain}. For the practitioner, we instantiate this novel bound to several classical families, e.g., Gaussian, Bernoulli, Exponential and Chi-square yielding explicit forms of the confidence sets and the Bregman information gain. We further numerically compare the resulting confidence bounds to state-of-the-art alternatives for time-uniform concentration and show that this novel method yields competitive results. Finally, we highlight how our results can be applied in a linear contextual multi-armed bandit problem.
Sparsification of Decomposable Submodular Functions
Jan 18, 2022
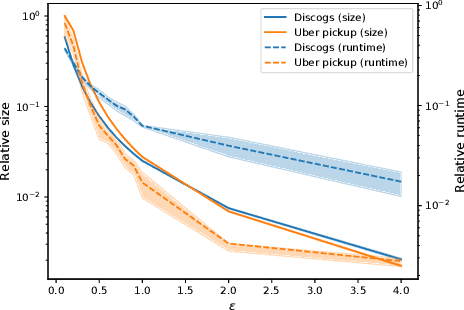
Submodular functions are at the core of many machine learning and data mining tasks. The underlying submodular functions for many of these tasks are decomposable, i.e., they are sum of several simple submodular functions. In many data intensive applications, however, the number of underlying submodular functions in the original function is so large that we need prohibitively large amount of time to process it and/or it does not even fit in the main memory. To overcome this issue, we introduce the notion of sparsification for decomposable submodular functions whose objective is to obtain an accurate approximation of the original function that is a (weighted) sum of only a few submodular functions. Our main result is a polynomial-time randomized sparsification algorithm such that the expected number of functions used in the output is independent of the number of underlying submodular functions in the original function. We also study the effectiveness of our algorithm under various constraints such as matroid and cardinality constraints. We complement our theoretical analysis with an empirical study of the performance of our algorithm.
One Network Doesn't Rule Them All: Moving Beyond Handcrafted Architectures in Self-Supervised Learning
Mar 15, 2022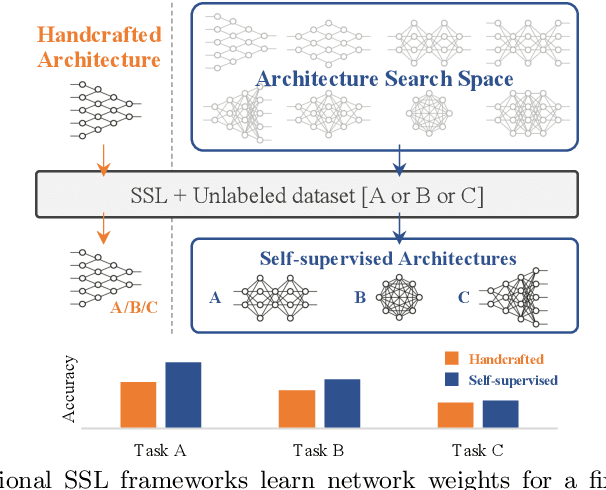
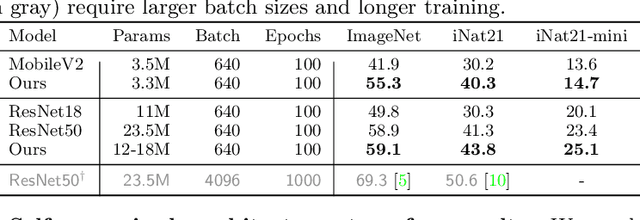
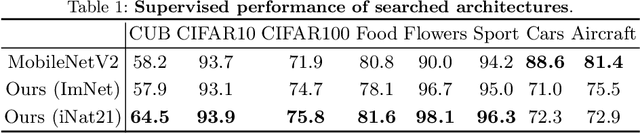
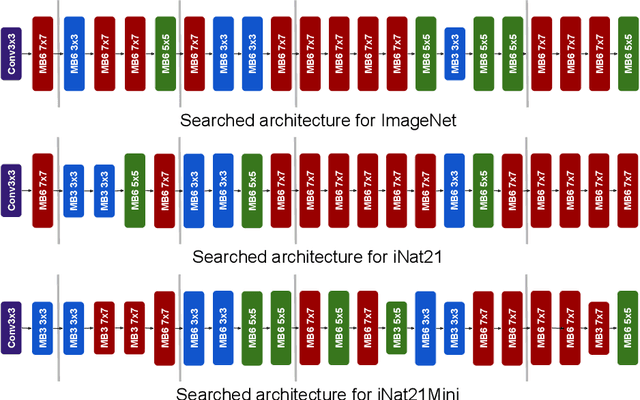
The current literature on self-supervised learning (SSL) focuses on developing learning objectives to train neural networks more effectively on unlabeled data. The typical development process involves taking well-established architectures, e.g., ResNet demonstrated on ImageNet, and using them to evaluate newly developed objectives on downstream scenarios. While convenient, this does not take into account the role of architectures which has been shown to be crucial in the supervised learning literature. In this work, we establish extensive empirical evidence showing that a network architecture plays a significant role in SSL. We conduct a large-scale study with over 100 variants of ResNet and MobileNet architectures and evaluate them across 11 downstream scenarios in the SSL setting. We show that there is no one network that performs consistently well across the scenarios. Based on this, we propose to learn not only network weights but also architecture topologies in the SSL regime. We show that "self-supervised architectures" outperform popular handcrafted architectures (ResNet18 and MobileNetV2) while performing competitively with the larger and computationally heavy ResNet50 on major image classification benchmarks (ImageNet-1K, iNat2021, and more). Our results suggest that it is time to consider moving beyond handcrafted architectures in SSL and start thinking about incorporating architecture search into self-supervised learning objectives.
Efficient Mean Estimation with Pure Differential Privacy via a Sum-of-Squares Exponential Mechanism
Nov 25, 2021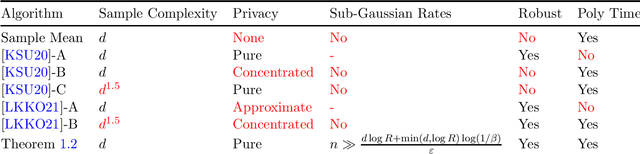
We give the first polynomial-time algorithm to estimate the mean of a $d$-variate probability distribution with bounded covariance from $\tilde{O}(d)$ independent samples subject to pure differential privacy. Prior algorithms for this problem either incur exponential running time, require $\Omega(d^{1.5})$ samples, or satisfy only the weaker concentrated or approximate differential privacy conditions. In particular, all prior polynomial-time algorithms require $d^{1+\Omega(1)}$ samples to guarantee small privacy loss with "cryptographically" high probability, $1-2^{-d^{\Omega(1)}}$, while our algorithm retains $\tilde{O}(d)$ sample complexity even in this stringent setting. Our main technique is a new approach to use the powerful Sum of Squares method (SoS) to design differentially private algorithms. SoS proofs to algorithms is a key theme in numerous recent works in high-dimensional algorithmic statistics -- estimators which apparently require exponential running time but whose analysis can be captured by low-degree Sum of Squares proofs can be automatically turned into polynomial-time algorithms with the same provable guarantees. We demonstrate a similar proofs to private algorithms phenomenon: instances of the workhorse exponential mechanism which apparently require exponential time but which can be analyzed with low-degree SoS proofs can be automatically turned into polynomial-time differentially private algorithms. We prove a meta-theorem capturing this phenomenon, which we expect to be of broad use in private algorithm design. Our techniques also draw new connections between differentially private and robust statistics in high dimensions. In particular, viewed through our proofs-to-private-algorithms lens, several well-studied SoS proofs from recent works in algorithmic robust statistics directly yield key components of our differentially private mean estimation algorithm.
Mitigating Misinformation Spread on Blockchain Enabled Social Media Networks
Feb 09, 2022
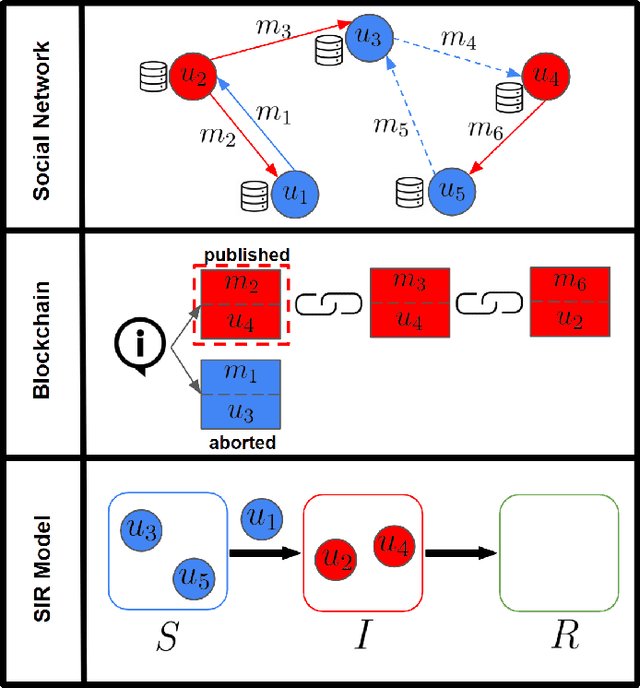
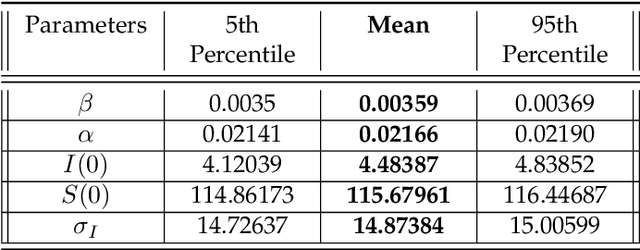
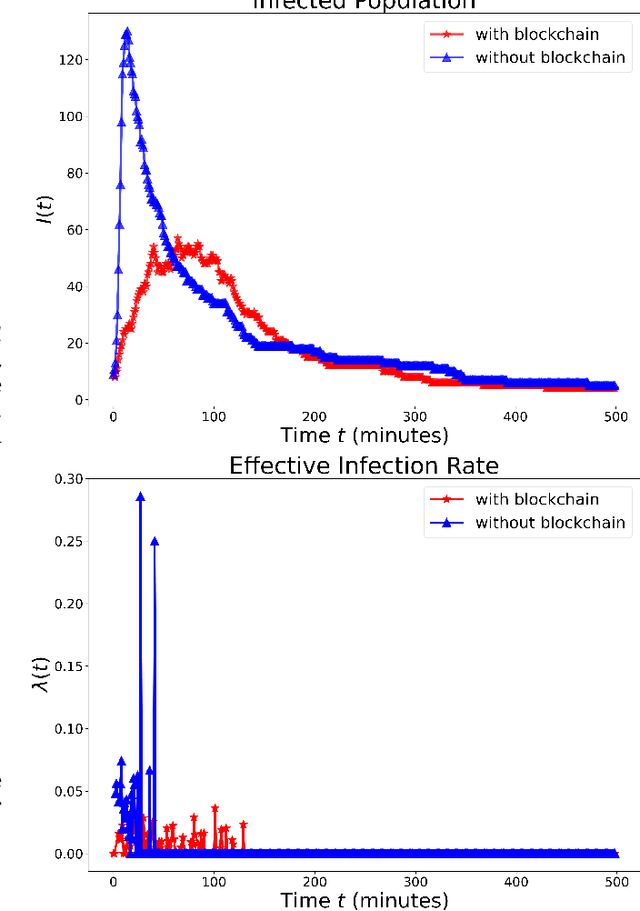
The paper develops a blockchain protocol for a social media network (BE-SMN) to mitigate the spread of misinformation. BE-SMN is derived based on the information transmission-time distribution by modeling the misinformation transmission as double-spend attacks on blockchain. The misinformation distribution is then incorporated into the SIR (Susceptible, Infectious, or Recovered) model, which substitutes the single rate parameter in the traditional SIR model. Then, on a multi-community network, we study the propagation of misinformation numerically and show that the proposed blockchain enabled social media network outperforms the baseline network in flattening the curve of the infected population.
Real-time Prediction for Mechanical Ventilation in COVID-19 Patients using A Multi-task Gaussian Process Multi-objective Self-attention Network
Feb 01, 2021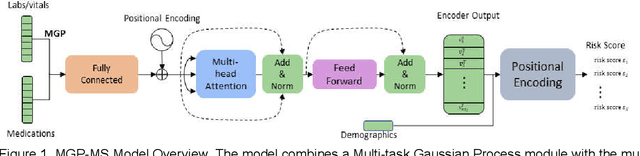
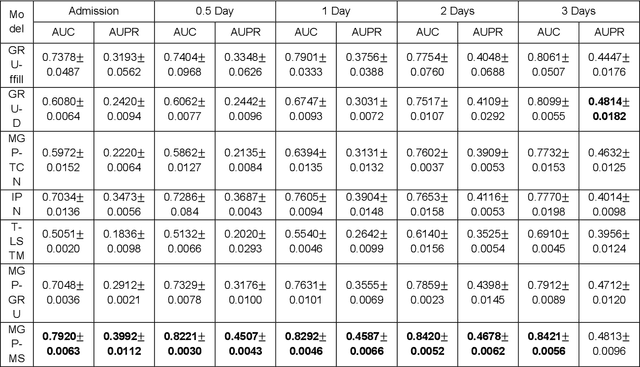
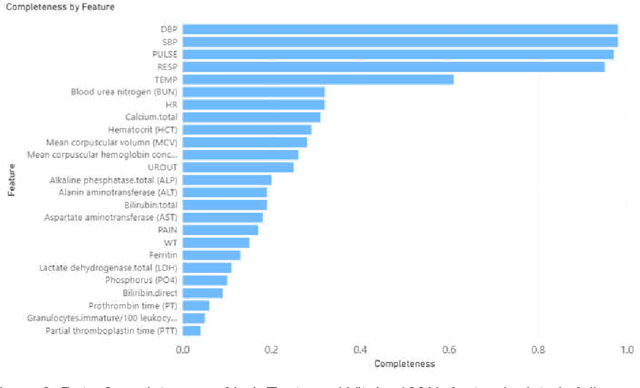
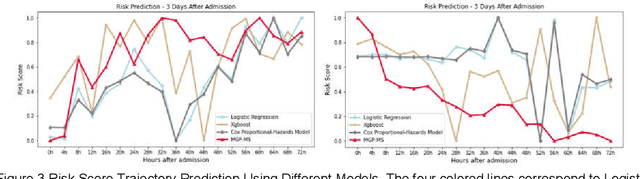
We propose a robust in-time predictor for in-hospital COVID-19 patient's probability of requiring mechanical ventilation. A challenge in the risk prediction for COVID-19 patients lies in the great variability and irregular sampling of patient's vitals and labs observed in the clinical setting. Existing methods have strong limitations in handling time-dependent features' complex dynamics, either oversimplifying temporal data with summary statistics that lose information or over-engineering features that lead to less robust outcomes. We propose a novel in-time risk trajectory predictive model to handle the irregular sampling rate in the data, which follows the dynamics of risk of performing mechanical ventilation for individual patients. The model incorporates the Multi-task Gaussian Process using observed values to learn the posterior joint multi-variant conditional probability and infer the missing values on a unified time grid. The temporal imputed data is fed into a multi-objective self-attention network for the prediction task. A novel positional encoding layer is proposed and added to the network for producing in-time predictions. The positional layer outputs a risk score at each user-defined time point during the entire hospital stay of an inpatient. We frame the prediction task into a multi-objective learning framework, and the risk scores at all time points are optimized altogether, which adds robustness and consistency to the risk score trajectory prediction. Our experimental evaluation on a large database with nationwide in-hospital patients with COVID-19 also demonstrates that it improved the state-of-the-art performance in terms of AUC (Area Under the receiver operating characteristic Curve) and AUPRC (Area Under the Precision-Recall Curve) performance metrics, especially at early times after hospital admission.