 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deciding cuspidality of manipulators through computer algebra and algorithms in real algebraic geometry
Mar 09, 2022
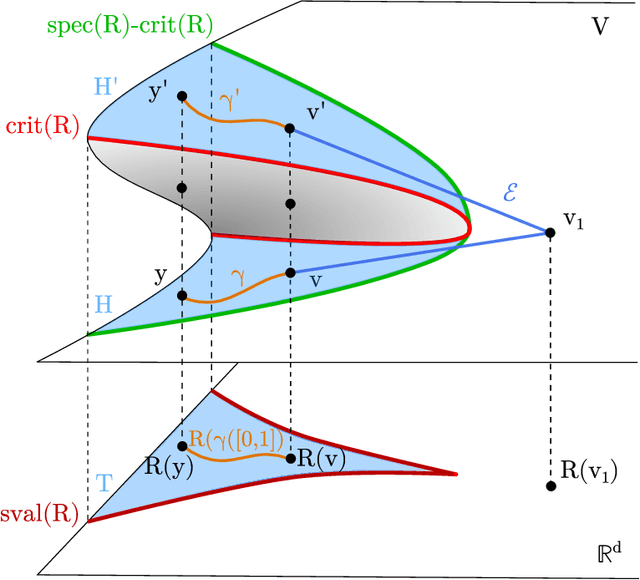
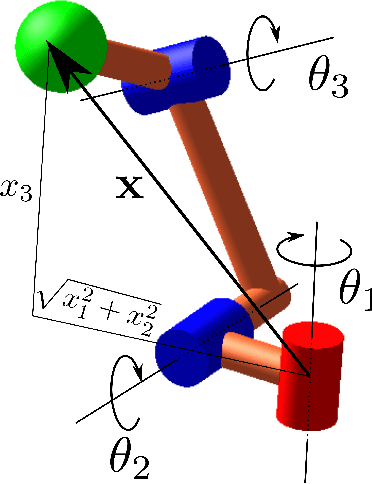
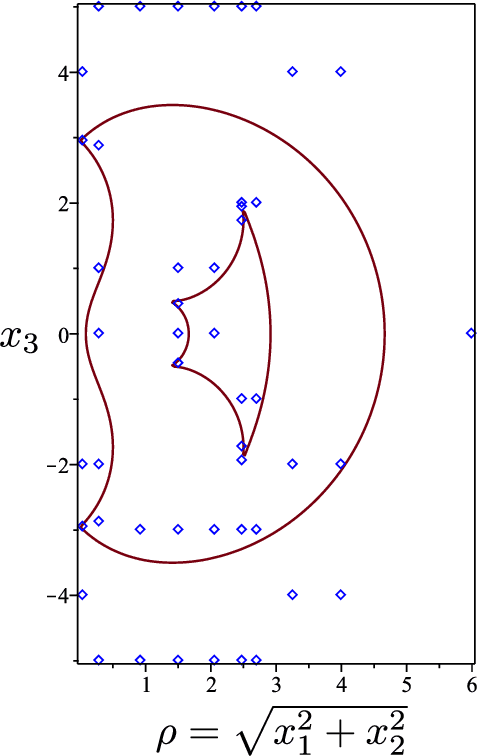
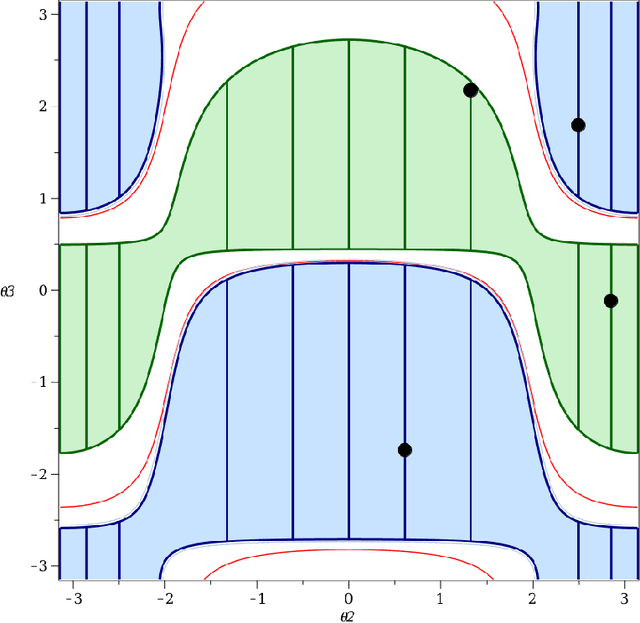
Cuspidal robots are robots with at least two inverse kinematic solutions that can be connected by a singularity-free path. Deciding the cuspidality of a generic 3R robots has been studied in the past, but extending the study to six-degree-of-freedom robots can be a challenging problem. Many robots can be modeled as a polynomial map together with a real algebraic set so that the notion of cuspidality can be extended to these data.In this paper we design an algorithm that, on input a polynomial map in $n$ indeterminates, and $s$ polynomials in the same indeterminates describing a real algebraic set of dimension $d$, decides the cuspidality of the restriction of the map to the real algebraic set under consideration. Moreover, if $D$ and $\tau$ are respectively the maximum degree and a bound on the bit size of the coefficients of the input polynomials, this algorithm runs in time log-linear in $\tau$ and polynomial in $((s+d)nD)^{O(n^2)}$.It relies on many high-level algorithms in computer algebra which use advanced methods on real algebraic sets and critical loci of polynomial maps. As far as we know, this is the first algorithm that tackles the cuspidality problem from a general point of view.
Bayesian Structure Learning with Generative Flow Networks
Feb 28, 2022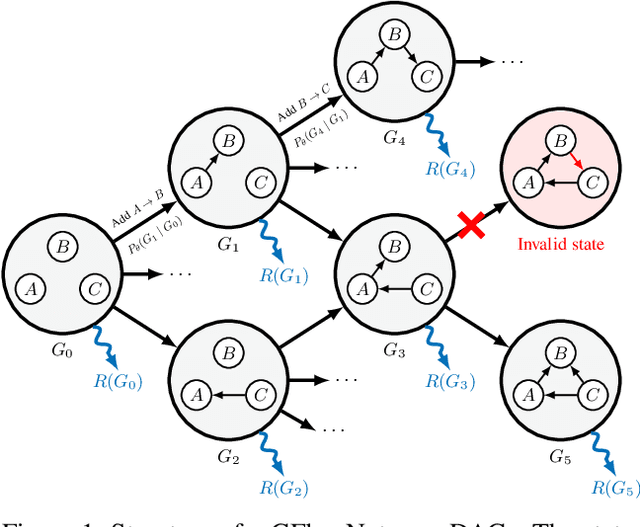
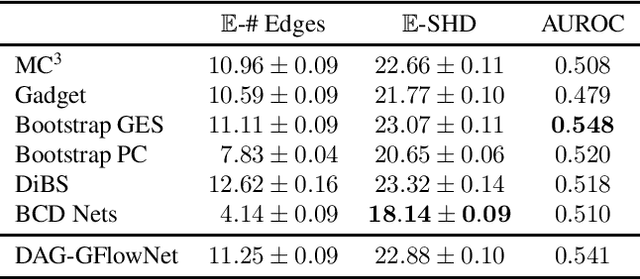
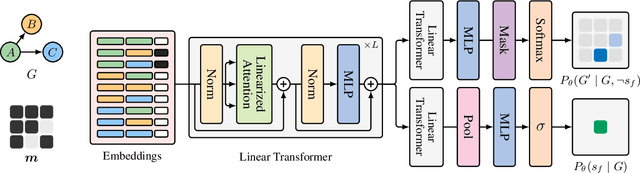
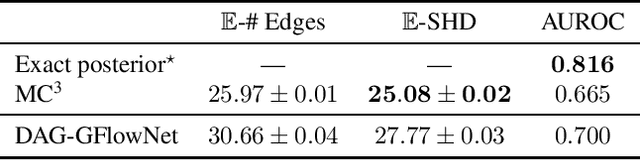
In Bayesian structure learning, we are interested in inferring a distribution over the directed acyclic graph (DAG) structure of Bayesian networks, from data. Defining such a distribution is very challenging, due to the combinatorially large sample space, and approximations based on MCMC are often required. Recently, a novel class of probabilistic models, called Generative Flow Networks (GFlowNets), have been introduced as a general framework for generative modeling of discrete and composite objects, such as graphs. In this work, we propose to use a GFlowNet as an alternative to MCMC for approximating the posterior distribution over the structure of Bayesian networks, given a dataset of observations. Generating a sample DAG from this approximate distribution is viewed as a sequential decision problem, where the graph is constructed one edge at a time, based on learned transition probabilities. Through evaluation on both simulated and real data, we show that our approach, called DAG-GFlowNet, provides an accurate approximation of the posterior over DAGs, and it compares favorably against other methods based on MCMC or variational inference.
Reinforcement Learning with Time-dependent Goals for Robotic Musicians
Nov 11, 2020

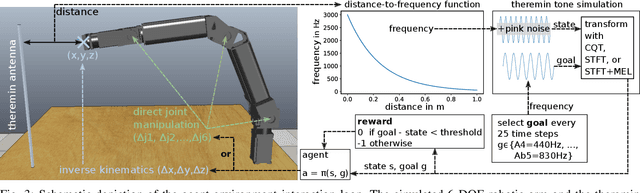

Reinforcement learning is a promising method to accomplish robotic control tasks. The task of playing musical instruments is, however, largely unexplored because it involves the challenge of achieving sequential goals - melodies - that have a temporal dimension. In this paper, we address robotic musicianship by introducing a temporal extension to goal-conditioned reinforcement learning: Time-dependent goals. We demonstrate that these can be used to train a robotic musician to play the theremin instrument. We train the robotic agent in simulation and transfer the acquired policy to a real-world robotic thereminist. Supplemental video: https://youtu.be/jvC9mPzdQN4
Waveform Design Using Half-duplex Devices for 6G Joint Communications and Sensing
Jan 04, 2022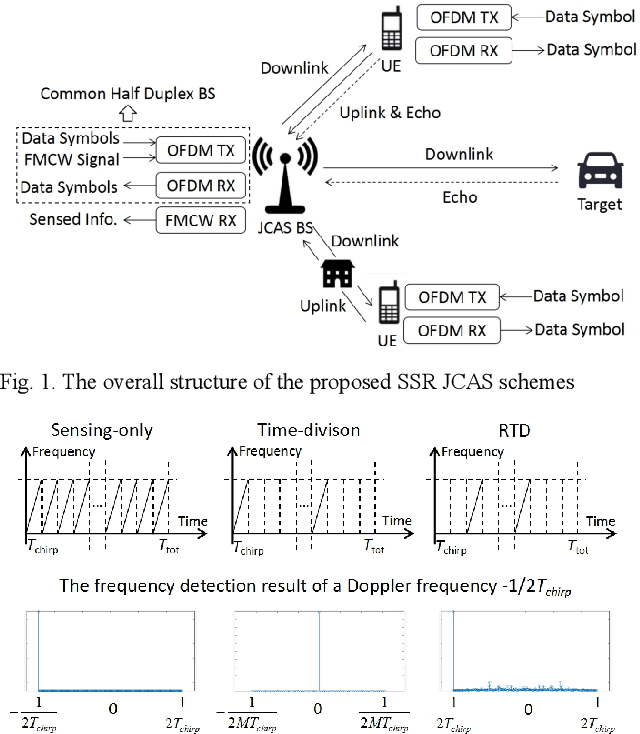
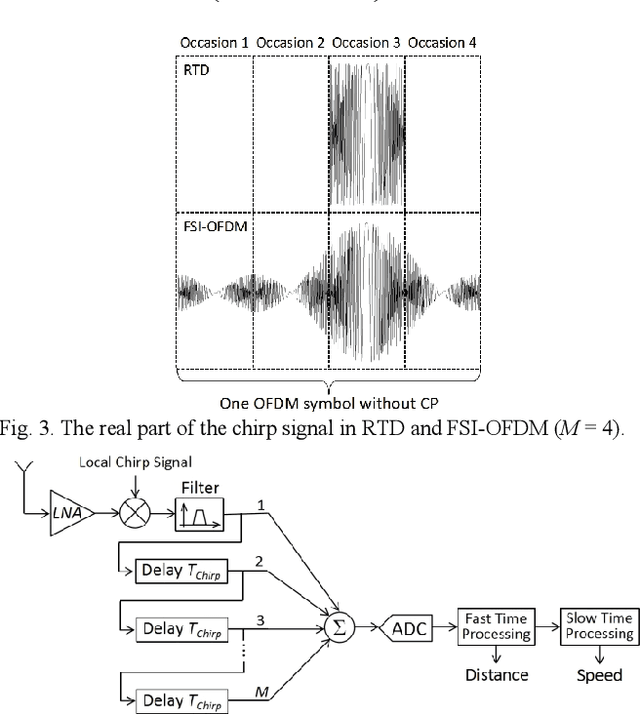
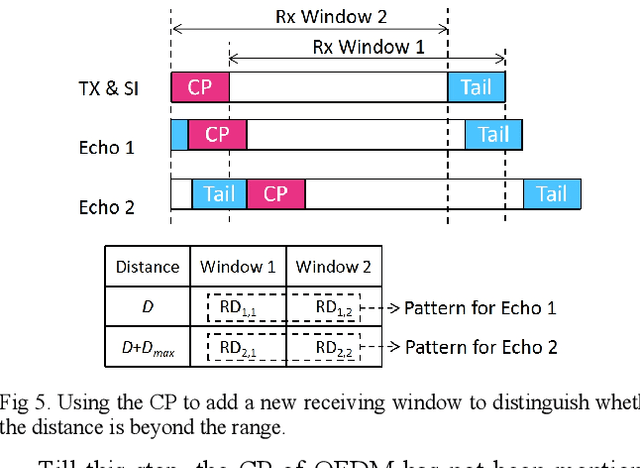
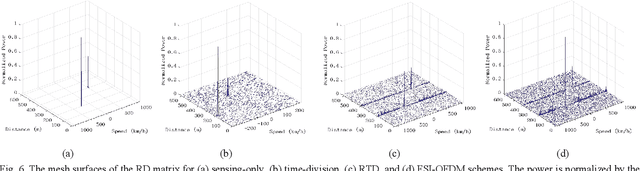
Joint communications and sensing is a promising 6G technology, and the challenge is how to integrate them efficiently. Existing frequency-division and time-division coexistence can hardly bring a gain of integration. Directly using orthogonal frequency-division multiplexing (OFDM) to sense requires complex in-band full-duplex to cancel the selfinterference (SI). To solve these problems, this paper proposes novel coexistence schemes to gain super sensing range (SSR) and simple SI cancellation. SSR enables JCS to gain a sensing range of a sensing-only scheme and shares the resources with communications. Random time-division is proposed to gain a super Doppler range. Flexible sensing implanted OFDM (FSIOFDM) is also proposed. FSI-OFDM uses random sensing occasions to gain super Doppler range, as well as utilizes the fixed tail sensing occasions to achieve supper distance range. The simulation results show that the proposed schemes can gain SSR with limited resources.
TraceNet: Tracing and Locating the Key Elements in Sentiment Analysis
Feb 28, 2022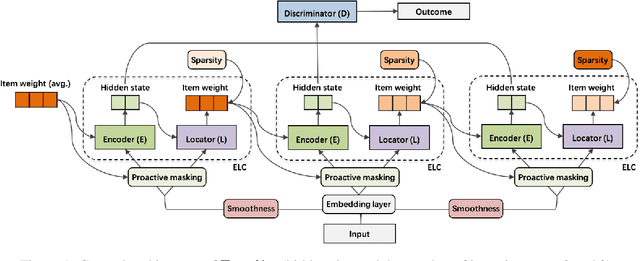
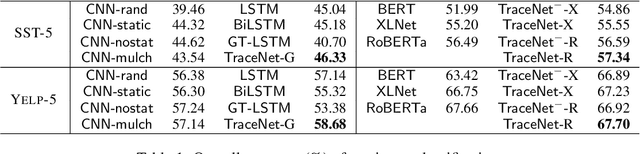
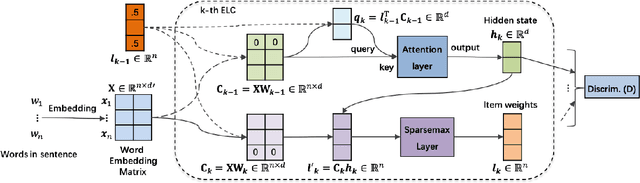
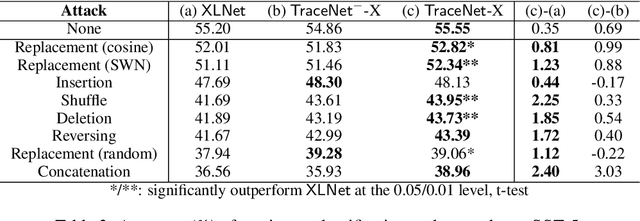
In this paper, we study sentiment analysis task where the outcomes are mainly contributed by a few key elements of the inputs. Motivated by the two-streams hypothesis, we propose a neural architecture, named TraceNet, to address this type of task. It not only learns discriminative representations for the target task via its encoders, but also traces key elements at the same time via its locators. In TraceNet, both encoders and locators are organized in a layer-wise manner, and a smoothness regularization is employed between adjacent encoder-locator combinations. Moreover, a sparsity constraints are enforced on locators for tracing purposes and items are proactively masked according to the item weights output by locators.A major advantage of TraceNet is that the outcomes are easier to understand, since the most responsible parts of inputs are identified. Also, under the guidance of locators, it is more robust to attacks due to its focus on key elements and the proactive masking training strategy. Experimental results show its effectiveness for sentiment classification. Moreover, we provide several case studies to demonstrate its robustness and interpretability.
Event-based Video Reconstruction via Potential-assisted Spiking Neural Network
Jan 25, 2022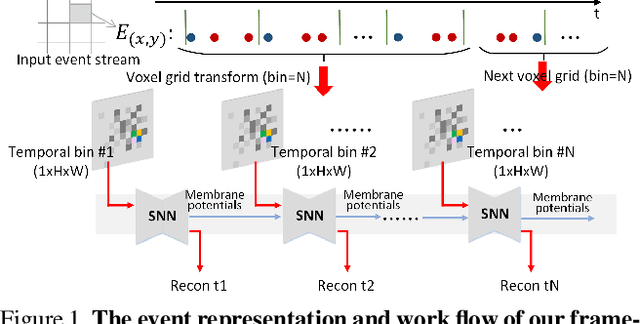
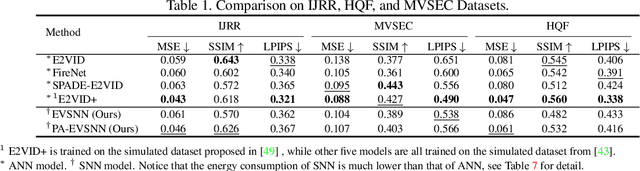
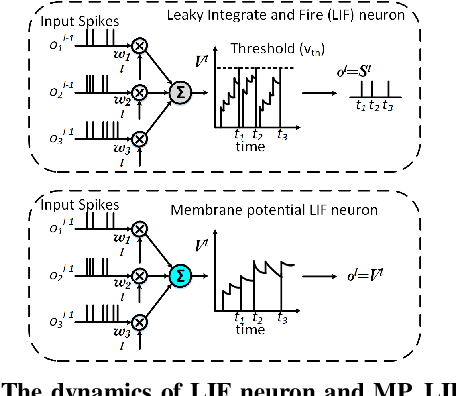
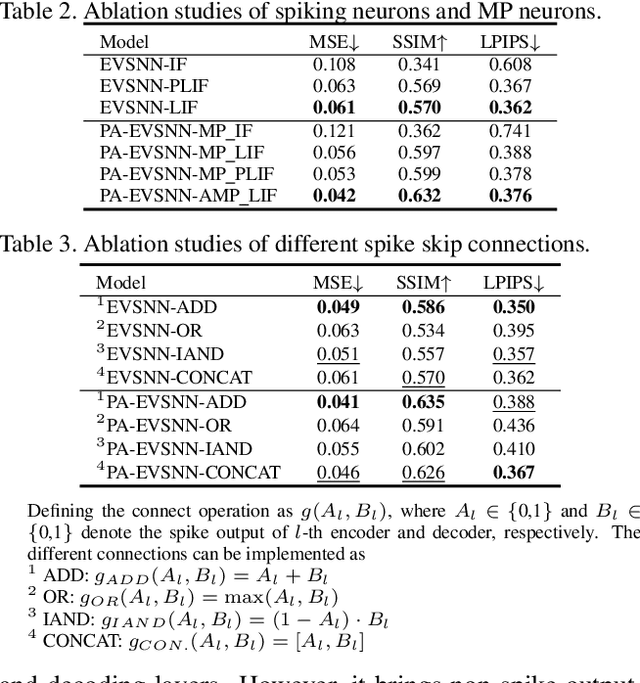
Neuromorphic vision sensor is a new bio-inspired imaging paradigm that reports asynchronous, continuously per-pixel brightness changes called `events' with high temporal resolution and high dynamic range. So far, the event-based image reconstruction methods are based on artificial neural networks (ANN) or hand-crafted spatiotemporal smoothing techniques. In this paper, we first implement the image reconstruction work via fully spiking neural network (SNN) architecture. As the bio-inspired neural networks, SNNs operating with asynchronous binary spikes distributed over time, can potentially lead to greater computational efficiency on event-driven hardware. We propose a novel Event-based Video reconstruction framework based on a fully Spiking Neural Network (EVSNN), which utilizes Leaky-Integrate-and-Fire (LIF) neuron and Membrane Potential (MP) neuron. We find that the spiking neurons have the potential to store useful temporal information (memory) to complete such time-dependent tasks. Furthermore, to better utilize the temporal information, we propose a hybrid potential-assisted framework (PA-EVSNN) using the membrane potential of spiking neuron. The proposed neuron is referred as Adaptive Membrane Potential (AMP) neuron, which adaptively updates the membrane potential according to the input spikes. The experimental results demonstrate that our models achieve comparable performance to ANN-based models on IJRR, MVSEC, and HQF datasets. The energy consumptions of EVSNN and PA-EVSNN are 19.36$\times$ and 7.75$\times$ more computationally efficient than their ANN architectures, respectively.
Temporal-MPI: Enabling Multi-Plane Images for Dynamic Scene Modelling via Temporal Basis Learning
Nov 20, 2021
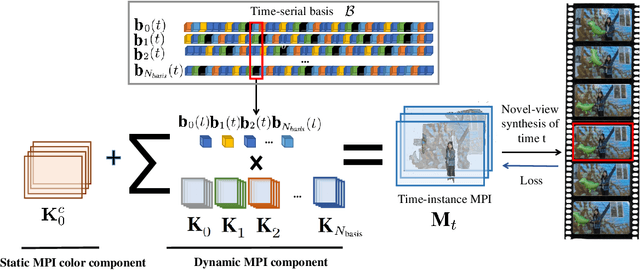

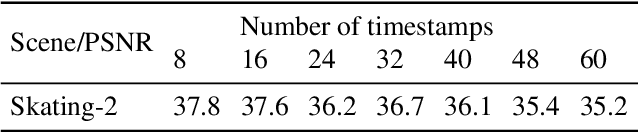
Novel view synthesis of static scenes has achieved remarkable advancements in producing photo-realistic results. However, key challenges remain for immersive rendering for dynamic contents. For example, one of the seminal image-based rendering frameworks, the multi-plane image (MPI) produces high novel-view synthesis quality for static scenes but faces difficulty in modeling dynamic parts. In addition, modeling dynamic variations through MPI may require huge storage space and long inference time, which hinders its application in real-time scenarios. In this paper, we propose a novel Temporal-MPI representation which is able to encode the rich 3D and dynamic variation information throughout the entire video as compact temporal basis. Novel-views at arbitrary time-instance will be able to be rendered real-time with high visual quality due to the highly compact and expressive latent basis and the coefficients jointly learned. We show that given comparable memory consumption, our proposed Temporal-MPI framework is able to generate a time-instance MPI with only 0.002 seconds, which is up to 3000 times faster, with 3dB higher average view-synthesis PSNR as compared with other state-of-the-art dynamic scene modelling frameworks.
Towards Lightweight Neural Animation : Exploration of Neural Network Pruning in Mixture of Experts-based Animation Models
Jan 11, 2022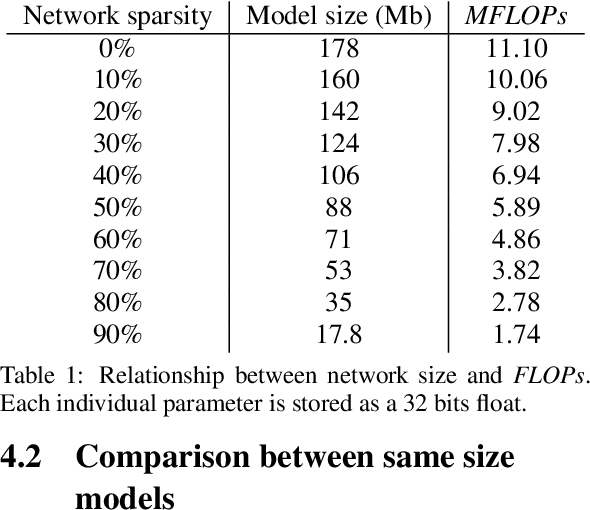
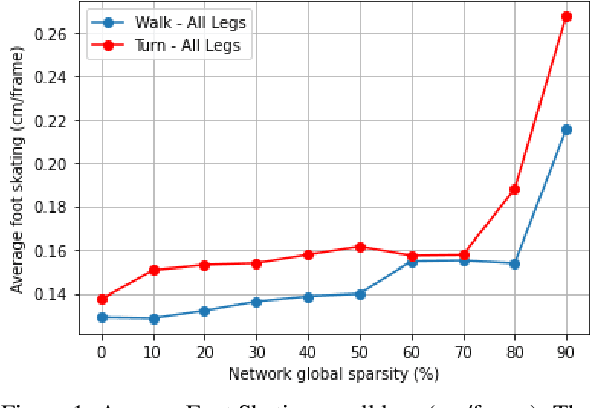


In the past few years, neural character animation has emerged and offered an automatic method for animating virtual characters. Their motion is synthesized by a neural network. Controlling this movement in real time with a user-defined control signal is also an important task in video games for example. Solutions based on fully-connected layers (MLPs) and Mixture-of-Experts (MoE) have given impressive results in generating and controlling various movements with close-range interactions between the environment and the virtual character. However, a major shortcoming of fully-connected layers is their computational and memory cost which may lead to sub-optimized solution. In this work, we apply pruning algorithms to compress an MLP- MoE neural network in the context of interactive character animation, which reduces its number of parameters and accelerates its computation time with a trade-off between this acceleration and the synthesized motion quality. This work demonstrates that, with the same number of experts and parameters, the pruned model produces less motion artifacts than the dense model and the learned high-level motion features are similar for both
Training privacy-preserving video analytics pipelines by suppressing features that reveal information about private attributes
Mar 05, 2022

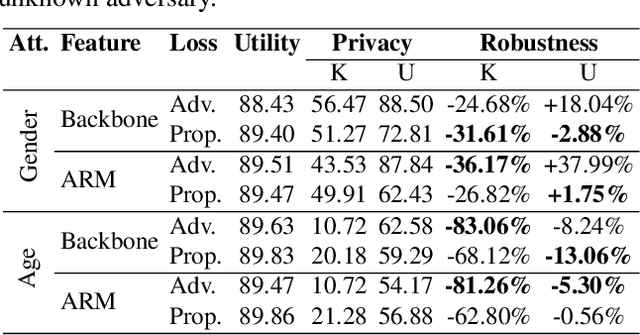
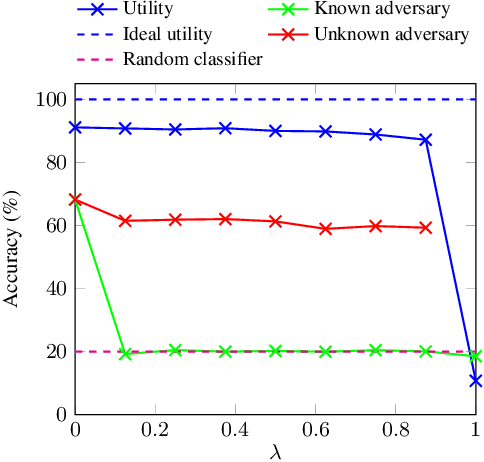
Deep neural networks are increasingly deployed for scene analytics, including to evaluate the attention and reaction of people exposed to out-of-home advertisements. However, the features extracted by a deep neural network that was trained to predict a specific, consensual attribute (e.g. emotion) may also encode and thus reveal information about private, protected attributes (e.g. age or gender). In this work, we focus on such leakage of private information at inference time. We consider an adversary with access to the features extracted by the layers of a deployed neural network and use these features to predict private attributes. To prevent the success of such an attack, we modify the training of the network using a confusion loss that encourages the extraction of features that make it difficult for the adversary to accurately predict private attributes. We validate this training approach on image-based tasks using a publicly available dataset. Results show that, compared to the original network, the proposed PrivateNet can reduce the leakage of private information of a state-of-the-art emotion recognition classifier by 2.88% for gender and by 13.06% for age group, with a minimal effect on task accuracy.
Online Learning with Knapsacks: the Best of Both Worlds
Feb 28, 2022
We study online learning problems in which a decision maker wants to maximize their expected reward without violating a finite set of $m$ resource constraints. By casting the learning process over a suitably defined space of strategy mixtures, we recover strong duality on a Lagrangian relaxation of the underlying optimization problem, even for general settings with non-convex reward and resource-consumption functions. Then, we provide the first best-of-both-worlds type framework for this setting, with no-regret guarantees both under stochastic and adversarial inputs. Our framework yields the same regret guarantees of prior work in the stochastic case. On the other hand, when budgets grow at least linearly in the time horizon, it allows us to provide a constant competitive ratio in the adversarial case, which improves over the $O(m \log T)$ competitive ratio of Immorlica at al. (2019). Moreover, our framework allows the decision maker to handle non-convex reward and cost functions. We provide two game-theoretic applications of our framework to give further evidence of its flexibility.