 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CodeReviewer: Pre-Training for Automating Code Review Activities
Mar 17, 2022
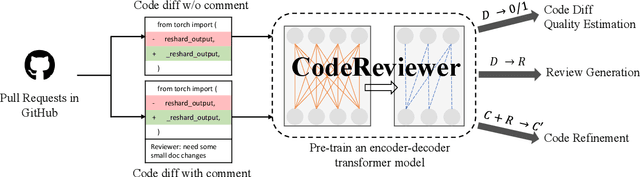

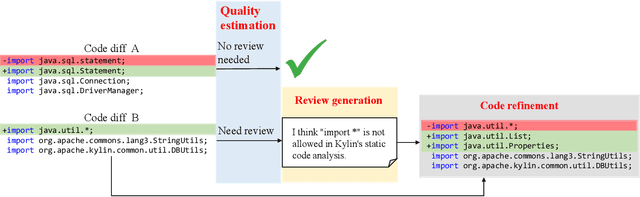
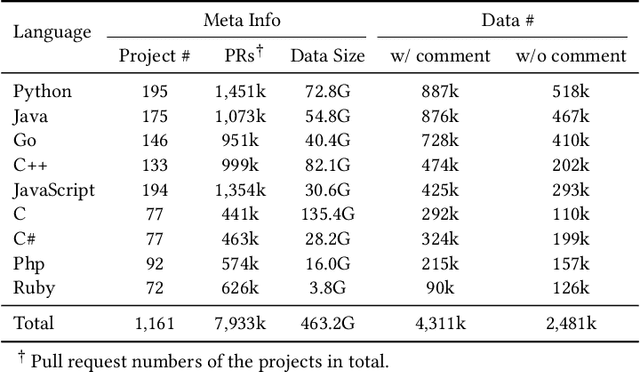
Code review is an essential part to software development lifecycle since it aims at guaranteeing the quality of codes. Modern code review activities necessitate developers viewing, understanding and even running the programs to assess logic, functionality, latency, style and other factors. It turns out that developers have to spend far too much time reviewing the code of their peers. Accordingly, it is in significant demand to automate the code review process. In this research, we focus on utilizing pre-training techniques for the tasks in the code review scenario. We collect a large-scale dataset of real world code changes and code reviews from open-source projects in nine of the most popular programming languages. To better understand code diffs and reviews, we propose CodeReviewer, a pre-trained model that utilizes four pre-training tasks tailored specifically for the code review senario. To evaluate our model, we focus on three key tasks related to code review activities, including code change quality estimation, review comment generation and code refinement. Furthermore, we establish a high-quality benchmark dataset based on our collected data for these three tasks and conduct comprehensive experiments on it. The experimental results demonstrate that our model outperforms the previous state-of-the-art pre-training approaches in all tasks. Further analysis show that our proposed pre-training tasks and the multilingual pre-training dataset benefit the model on the understanding of code changes and reviews.
Typography-MNIST (TMNIST): an MNIST-Style Image Dataset to Categorize Glyphs and Font-Styles
Feb 12, 2022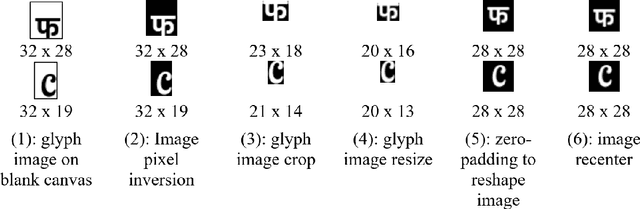
We present Typography-MNIST (TMNIST), a dataset comprising of 565,292 MNIST-style grayscale images representing 1,812 unique glyphs in varied styles of 1,355 Google-fonts. The glyph-list contains common characters from over 150 of the modern and historical language scripts with symbol sets, and each font-style represents varying subsets of the total unique glyphs. The dataset has been developed as part of the CognitiveType project which aims to develop eye-tracking tools for real-time mapping of type to cognition and to create computational tools that allow for the easy design of typefaces with cognitive properties such as readability. The dataset and scripts to generate MNIST-style images for glyphs in different font styles are freely available at https://github.com/aiskunks/CognitiveType.
Adversarial Examples in Deep Learning for Multivariate Time Series Regression
Sep 24, 2020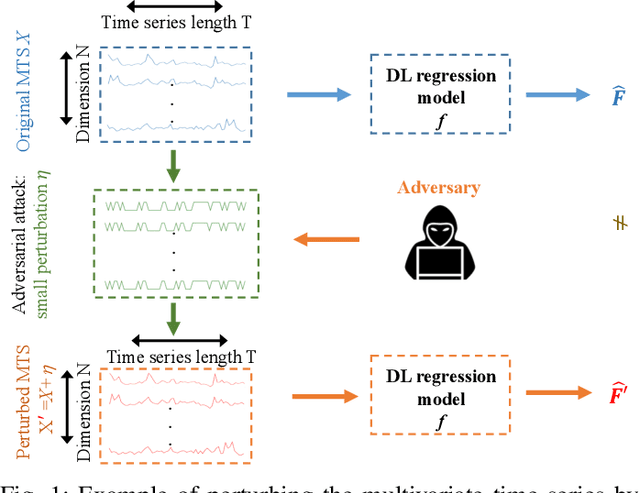
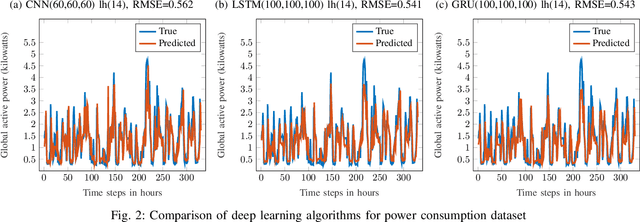
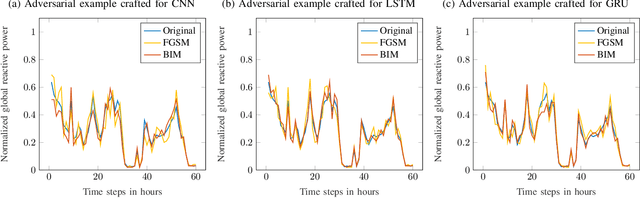
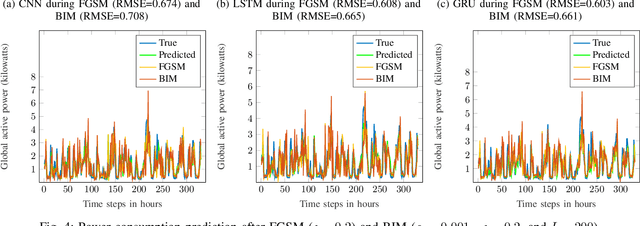
Multivariate time series (MTS) regression tasks are common in many real-world data mining applications including finance, cybersecurity, energy, healthcare, prognostics, and many others. Due to the tremendous success of deep learning (DL) algorithms in various domains including image recognition and computer vision, researchers started adopting these techniques for solving MTS data mining problems, many of which are targeted for safety-critical and cost-critical applications. Unfortunately, DL algorithms are known for their susceptibility to adversarial examples which also makes the DL regression models for MTS forecasting also vulnerable to those attacks. To the best of our knowledge, no previous work has explored the vulnerability of DL MTS regression models to adversarial time series examples, which is an important step, specifically when the forecasting from such models is used in safety-critical and cost-critical applications. In this work, we leverage existing adversarial attack generation techniques from the image classification domain and craft adversarial multivariate time series examples for three state-of-the-art deep learning regression models, specifically Convolutional Neural Network (CNN), Long Short-Term Memory (LSTM), and Gated Recurrent Unit (GRU). We evaluate our study using Google stock and household power consumption dataset. The obtained results show that all the evaluated DL regression models are vulnerable to adversarial attacks, transferable, and thus can lead to catastrophic consequences in safety-critical and cost-critical domains, such as energy and finance.
Guided Imitation of Task and Motion Planning
Dec 06, 2021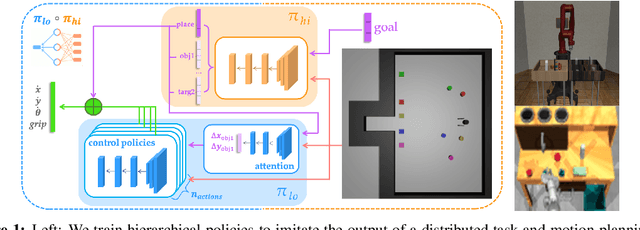
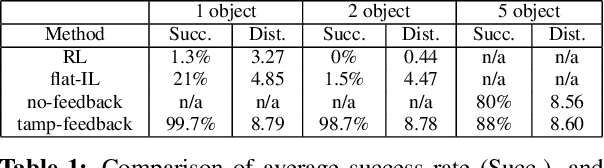
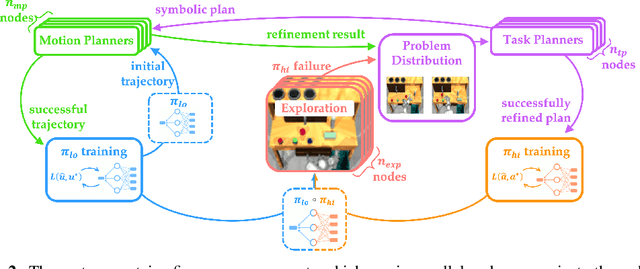
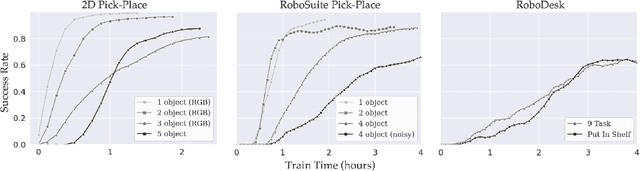
While modern policy optimization methods can do complex manipulation from sensory data, they struggle on problems with extended time horizons and multiple sub-goals. On the other hand, task and motion planning (TAMP) methods scale to long horizons but they are computationally expensive and need to precisely track world state. We propose a method that draws on the strength of both methods: we train a policy to imitate a TAMP solver's output. This produces a feed-forward policy that can accomplish multi-step tasks from sensory data. First, we build an asynchronous distributed TAMP solver that can produce supervision data fast enough for imitation learning. Then, we propose a hierarchical policy architecture that lets us use partially trained control policies to speed up the TAMP solver. In robotic manipulation tasks with 7-DoF joint control, the partially trained policies reduce the time needed for planning by a factor of up to 2.6. Among these tasks, we can learn a policy that solves the RoboSuite 4-object pick-place task 88% of the time from object pose observations and a policy that solves the RoboDesk 9-goal benchmark 79% of the time from RGB images (averaged across the 9 disparate tasks).
DVS: Deep Visibility Series and its Application in Construction Cost Index Forecasting
Nov 07, 2021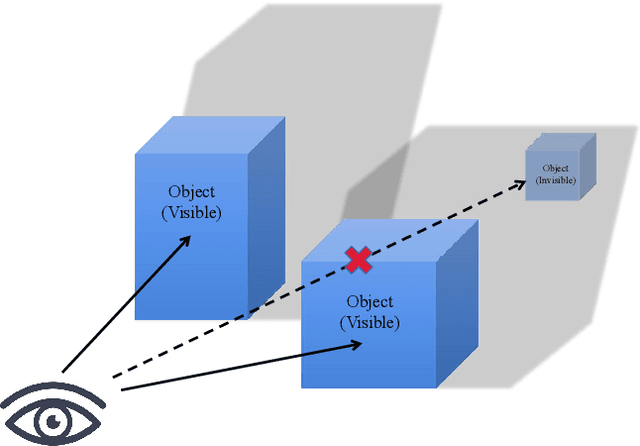
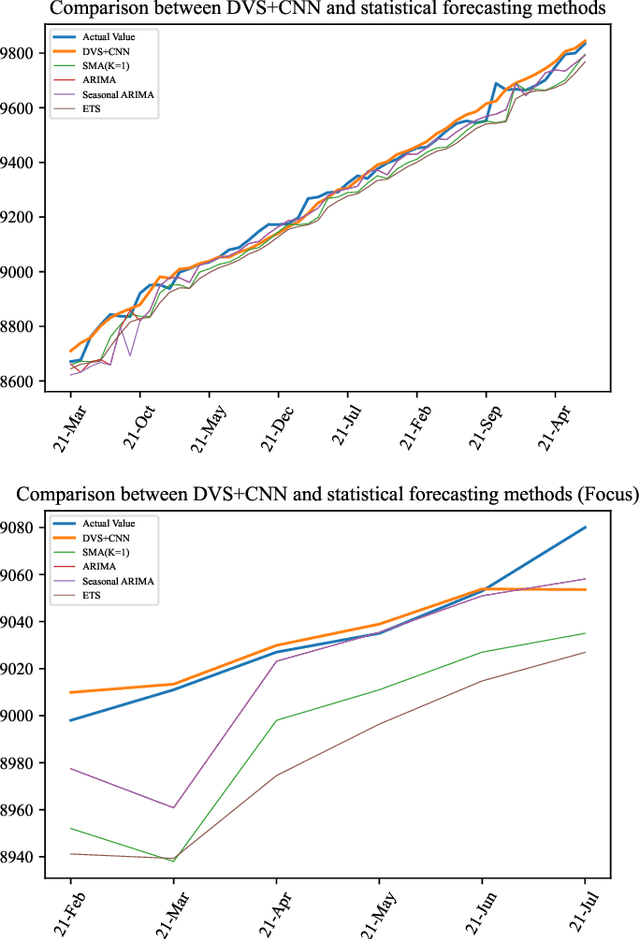
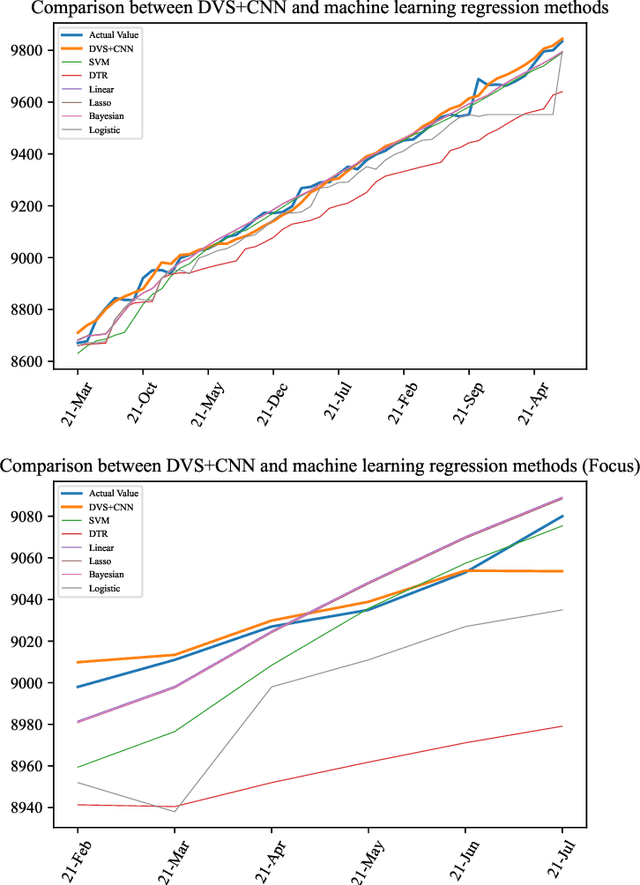
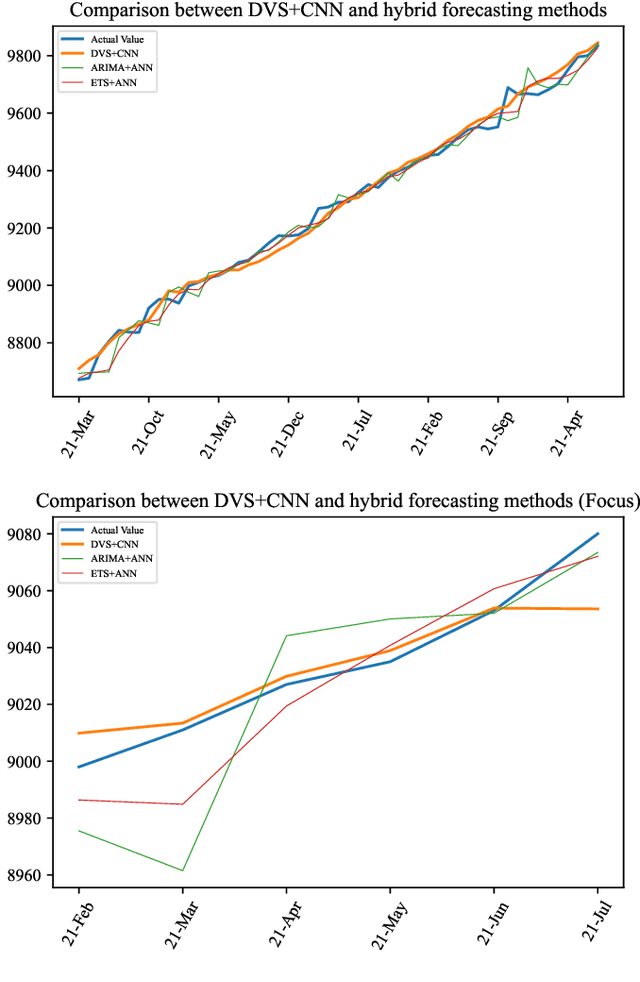
Time series forecasting has always been a hot spot in scientific research. With the development of artificial intelligence, new time series forecasting methods have obtained better forecasting effects and forecasting performance through bionic research and improvements to the past methods. Visibility Graph (VG) algorithm is often used for time series prediction in previous research, but the prediction effect is not as good as deep learning prediction methods such as Artificial Neural Network (ANN), Convolutional Neural Network (CNN) and Long Short-Term Memory Network (LSTM) prediction. The VG algorithm contains a wealth of network information, but previous studies did not effectively use the network information to make predictions, resulting in relatively large prediction errors. In order to solve this problem, this paper proposes the Deep Visibility Series (DVS) module through the bionic design of VG and the expansion of the past research, which is the first time to combine VG with bionic design and deep network. By applying the bionic design of biological vision to VG, the time series of DVS has obtained superior forecast accuracy, which has made a contribution to time series forecasting. At the same time, this paper applies the DVS forecasting method to the construction cost index forecast, which has practical significance.
Dynamic radiomics: a new methodology to extract quantitative time-related features from tomographic images
Nov 01, 2020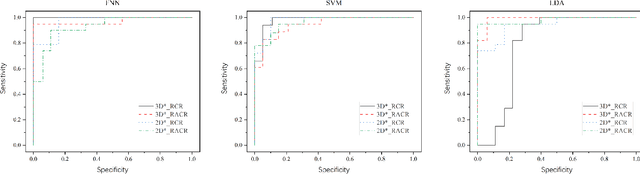
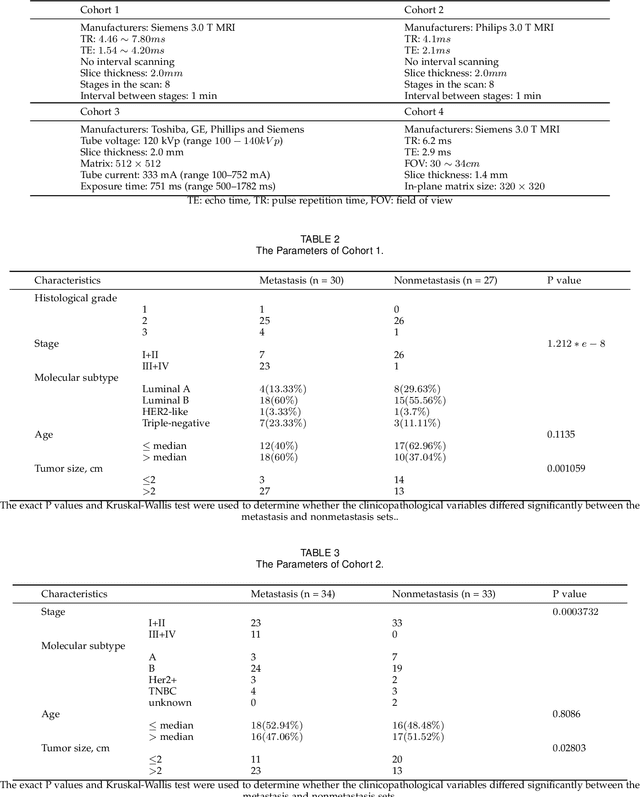
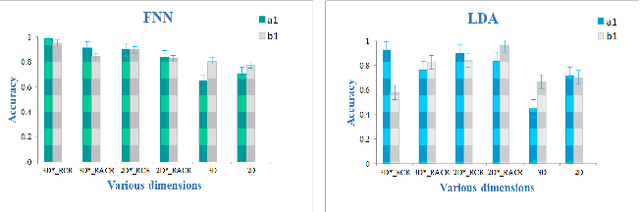
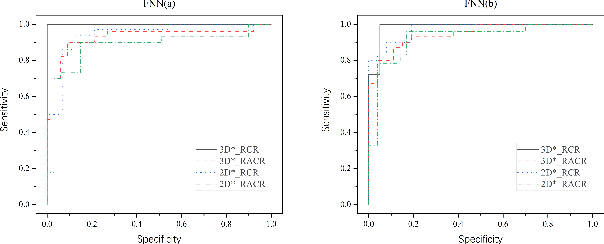
The feature extraction methods of radiomics are mainly based on static tomographic images at a certain moment, while the occurrence and development of disease is a dynamic process that cannot be fully reflected by only static characteristics. This study proposes a new dynamic radiomics feature extraction workflow that uses time-dependent tomographic images of the same patient, focuses on the changes in image features over time, and then quantifies them as new dynamic features for diagnostic or prognostic evaluation. We first define the mathematical paradigm of dynamic radiomics and introduce three specific methods that can describe the transformation process of features over time. Three different clinical problems are used to validate the performance of the proposed dynamic feature with conventional 2D and 3D static features.
Improving Real-time Score Following in Opera by Combining Music with Lyrics Tracking
Oct 06, 2021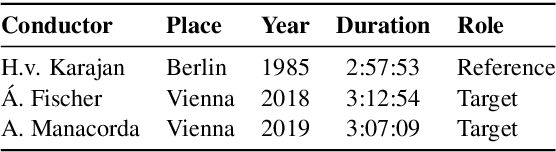
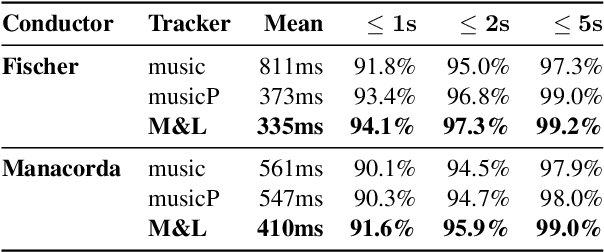
Fully automatic opera tracking is challenging because of the acoustic complexity of the genre, combining musical and linguistic information (singing, speech) in complex ways. In this paper, we propose a new pipeline for complete opera tracking. The pipeline is based on two trackers. A music tracker that has proven to be effective at tracking orchestral parts, will lead the tracking process. In addition, a lyrics tracker, that has recently been shown to reliably track the lyrics of opera songs, will correct the music tracker when tracking parts that have a text dominance over the music. We will demonstrate the efficiency of this method on the opera Don Giovanni, showing that this technique helps improving accuracy and robustness of a complete opera tracker.
STPLS3D: A Large-Scale Synthetic and Real Aerial Photogrammetry 3D Point Cloud Dataset
Mar 17, 2022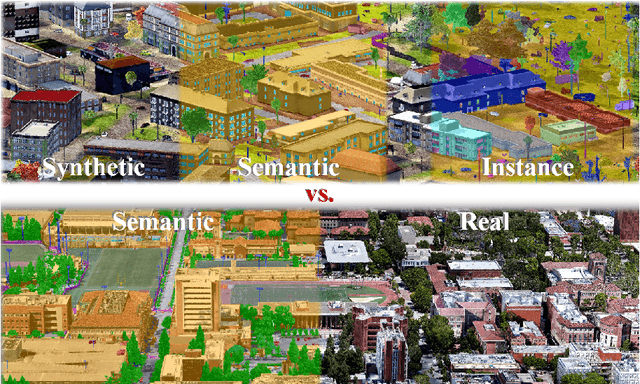

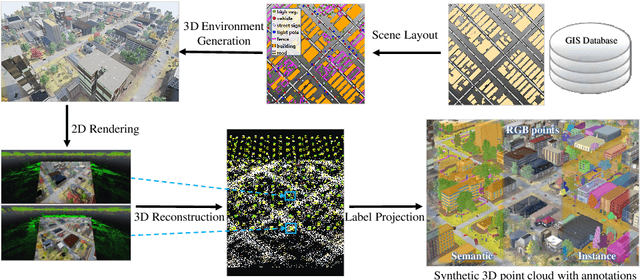

Although various 3D datasets with different functions and scales have been proposed recently, it remains challenging for individuals to complete the whole pipeline of large-scale data collection, sanitization, and annotation. Moreover, the created datasets usually suffer from extremely imbalanced class distribution or partial low-quality data samples. Motivated by this, we explore the procedurally synthetic 3D data generation paradigm to equip individuals with the full capability of creating large-scale annotated photogrammetry point clouds. Specifically, we introduce a synthetic aerial photogrammetry point clouds generation pipeline that takes full advantage of open geospatial data sources and off-the-shelf commercial packages. Unlike generating synthetic data in virtual games, where the simulated data usually have limited gaming environments created by artists, the proposed pipeline simulates the reconstruction process of the real environment by following the same UAV flight pattern on different synthetic terrain shapes and building densities, which ensure similar quality, noise pattern, and diversity with real data. In addition, the precise semantic and instance annotations can be generated fully automatically, avoiding the expensive and time-consuming manual annotation. Based on the proposed pipeline, we present a richly-annotated synthetic 3D aerial photogrammetry point cloud dataset, termed STPLS3D, with more than 16 $km^2$ of landscapes and up to 18 fine-grained semantic categories. For verification purposes, we also provide a parallel dataset collected from four areas in the real environment. Extensive experiments conducted on our datasets demonstrate the effectiveness and quality of the proposed synthetic dataset.
Deep Learning-Based Sparse Whole-Slide Image Analysis for the Diagnosis of Gastric Intestinal Metaplasia
Jan 05, 2022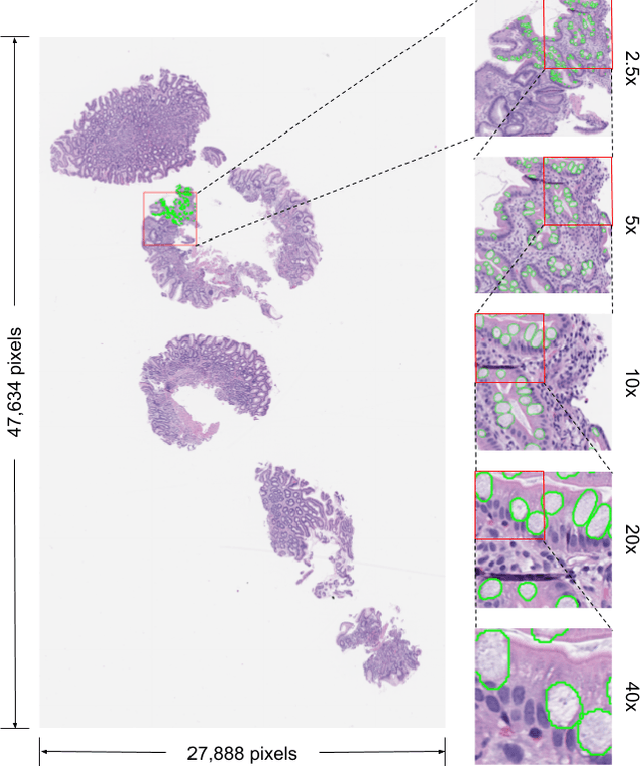
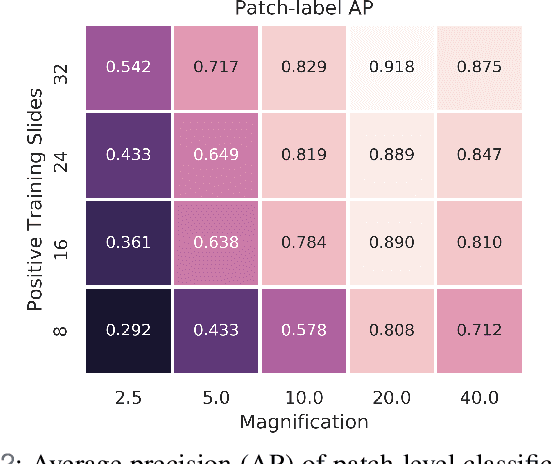
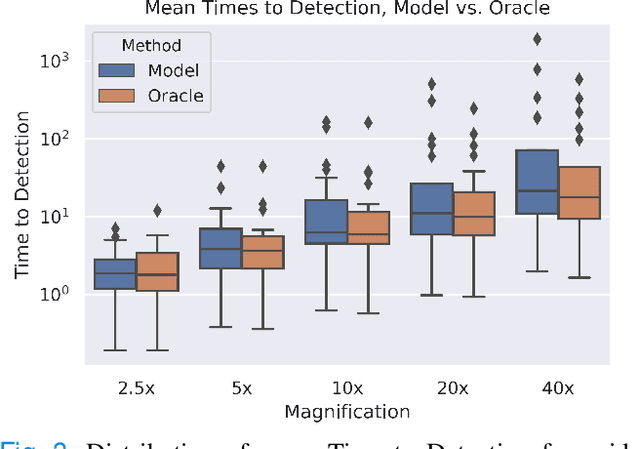
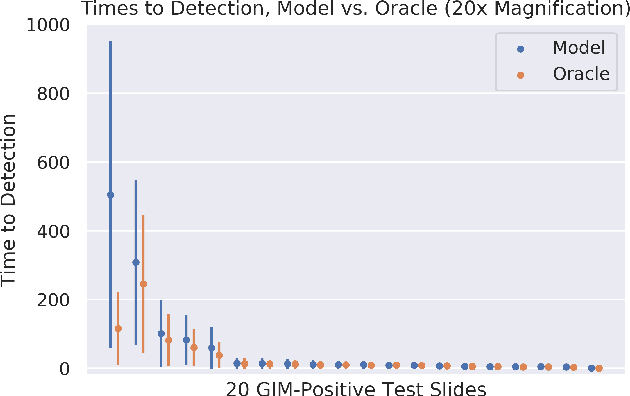
In recent years, deep learning has successfully been applied to automate a wide variety of tasks in diagnostic histopathology. However, fast and reliable localization of small-scale regions-of-interest (ROI) has remained a key challenge, as discriminative morphologic features often occupy only a small fraction of a gigapixel-scale whole-slide image (WSI). In this paper, we propose a sparse WSI analysis method for the rapid identification of high-power ROI for WSI-level classification. We develop an evaluation framework inspired by the early classification literature, in order to quantify the tradeoff between diagnostic performance and inference time for sparse analytic approaches. We test our method on a common but time-consuming task in pathology - that of diagnosing gastric intestinal metaplasia (GIM) on hematoxylin and eosin (H&E)-stained slides from endoscopic biopsy specimens. GIM is a well-known precursor lesion along the pathway to development of gastric cancer. We performed a thorough evaluation of the performance and inference time of our approach on a test set of GIM-positive and GIM-negative WSI, finding that our method successfully detects GIM in all positive WSI, with a WSI-level classification area under the receiver operating characteristic curve (AUC) of 0.98 and an average precision (AP) of 0.95. Furthermore, we show that our method can attain these metrics in under one minute on a standard CPU. Our results are applicable toward the goal of developing neural networks that can easily be deployed in clinical settings to support pathologists in quickly localizing and diagnosing small-scale morphologic features in WSI.
Joint Learning of Salient Object Detection, Depth Estimation and Contour Extraction
Mar 09, 2022



Benefiting from color independence, illumination invariance and location discrimination attributed by the depth map, it can provide important supplemental information for extracting salient objects in complex environments. However, high-quality depth sensors are expensive and can not be widely applied. While general depth sensors produce the noisy and sparse depth information, which brings the depth-based networks with irreversible interference. In this paper, we propose a novel multi-task and multi-modal filtered transformer (MMFT) network for RGB-D salient object detection (SOD). Specifically, we unify three complementary tasks: depth estimation, salient object detection and contour estimation. The multi-task mechanism promotes the model to learn the task-aware features from the auxiliary tasks. In this way, the depth information can be completed and purified. Moreover, we introduce a multi-modal filtered transformer (MFT) module, which equips with three modality-specific filters to generate the transformer-enhanced feature for each modality. The proposed model works in a depth-free style during the testing phase. Experiments show that it not only significantly surpasses the depth-based RGB-D SOD methods on multiple datasets, but also precisely predicts a high-quality depth map and salient contour at the same time. And, the resulted depth map can help existing RGB-D SOD methods obtain significant performance gain.