 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Domain Generalization using Pretrained Models without Fine-tuning
Mar 09, 2022
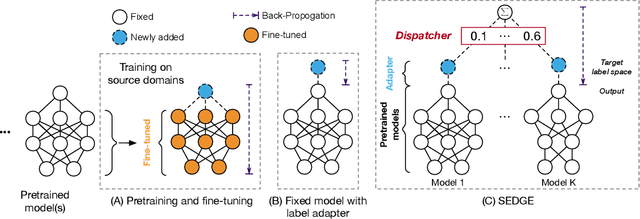
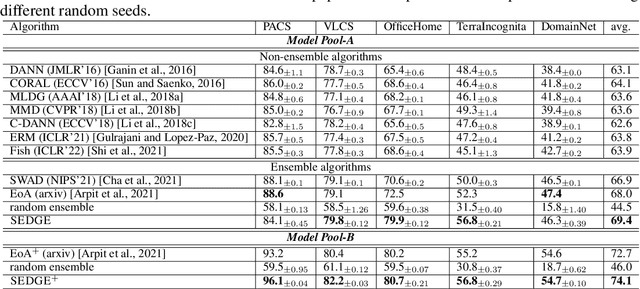
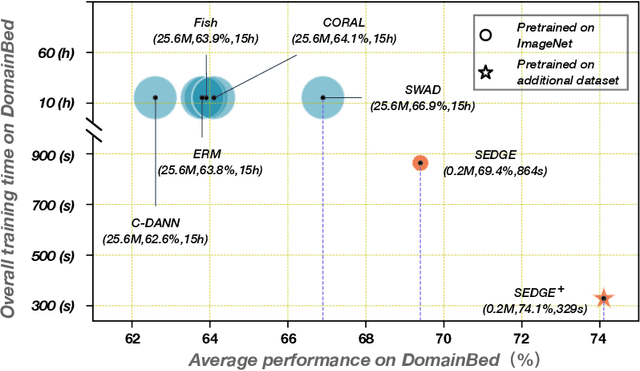

Fine-tuning pretrained models is a common practice in domain generalization (DG) tasks. However, fine-tuning is usually computationally expensive due to the ever-growing size of pretrained models. More importantly, it may cause over-fitting on source domain and compromise their generalization ability as shown in recent works. Generally, pretrained models possess some level of generalization ability and can achieve decent performance regarding specific domains and samples. However, the generalization performance of pretrained models could vary significantly over different test domains even samples, which raises challenges for us to best leverage pretrained models in DG tasks. In this paper, we propose a novel domain generalization paradigm to better leverage various pretrained models, named specialized ensemble learning for domain generalization (SEDGE). It first trains a linear label space adapter upon fixed pretrained models, which transforms the outputs of the pretrained model to the label space of the target domain. Then, an ensemble network aware of model specialty is proposed to dynamically dispatch proper pretrained models to predict each test sample. Experimental studies on several benchmarks show that SEDGE achieves significant performance improvements comparing to strong baselines including state-of-the-art method in DG tasks and reduces the trainable parameters by ~99% and the training time by ~99.5%.
Deciding cuspidality of manipulators through computer algebra and algorithms in real algebraic geometry
Mar 09, 2022
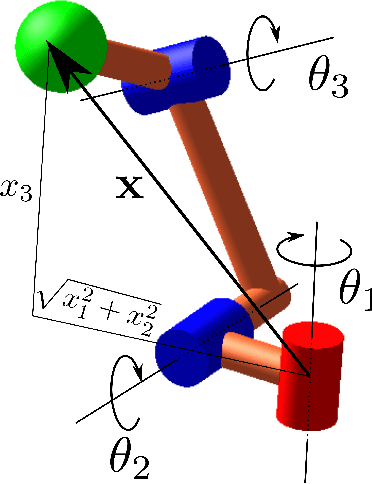
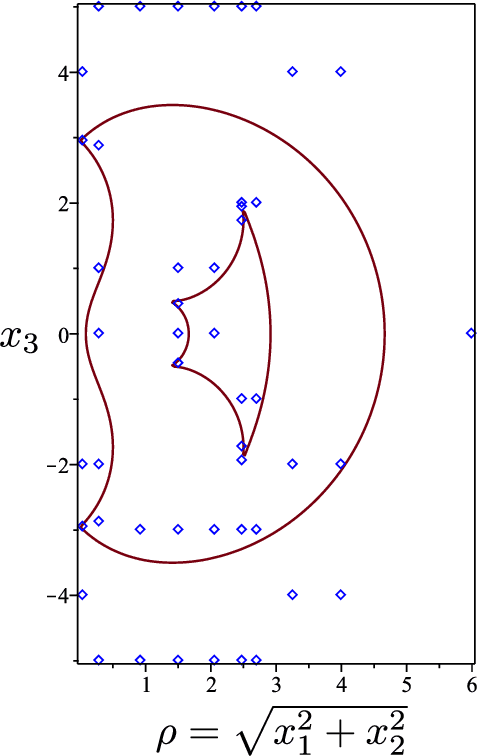
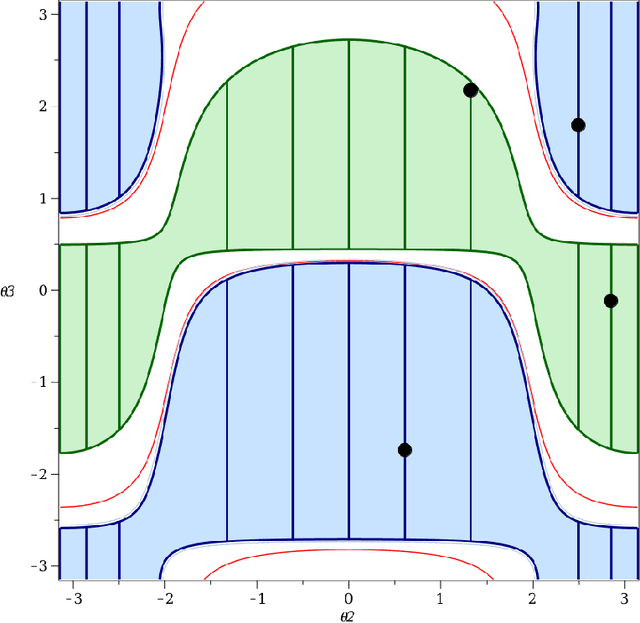
Cuspidal robots are robots with at least two inverse kinematic solutions that can be connected by a singularity-free path. Deciding the cuspidality of a generic 3R robots has been studied in the past, but extending the study to six-degree-of-freedom robots can be a challenging problem. Many robots can be modeled as a polynomial map together with a real algebraic set so that the notion of cuspidality can be extended to these data.In this paper we design an algorithm that, on input a polynomial map in $n$ indeterminates, and $s$ polynomials in the same indeterminates describing a real algebraic set of dimension $d$, decides the cuspidality of the restriction of the map to the real algebraic set under consideration. Moreover, if $D$ and $\tau$ are respectively the maximum degree and a bound on the bit size of the coefficients of the input polynomials, this algorithm runs in time log-linear in $\tau$ and polynomial in $((s+d)nD)^{O(n^2)}$.It relies on many high-level algorithms in computer algebra which use advanced methods on real algebraic sets and critical loci of polynomial maps. As far as we know, this is the first algorithm that tackles the cuspidality problem from a general point of view.
Reachability Analysis for FollowerStopper: Safety Analysis and Experimental Results
Dec 29, 2021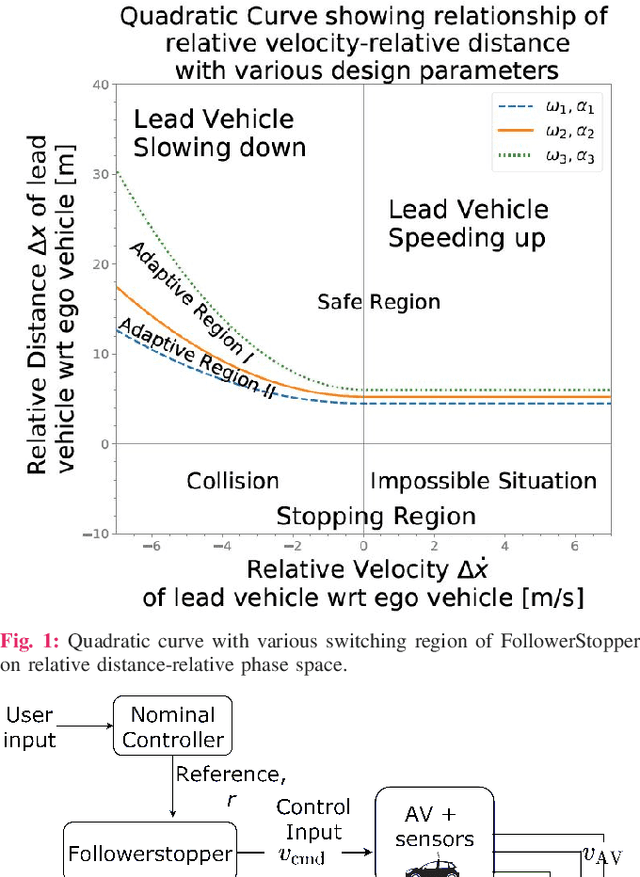
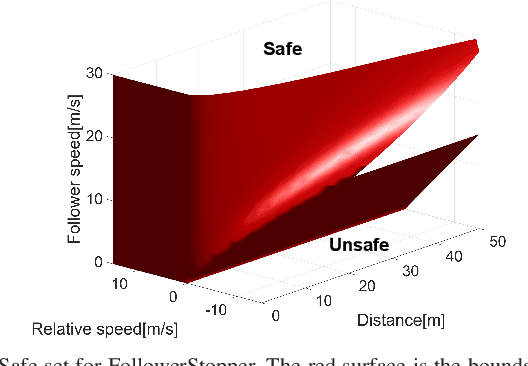
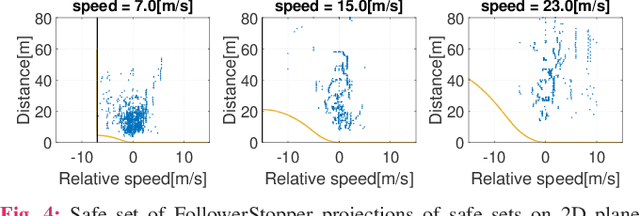
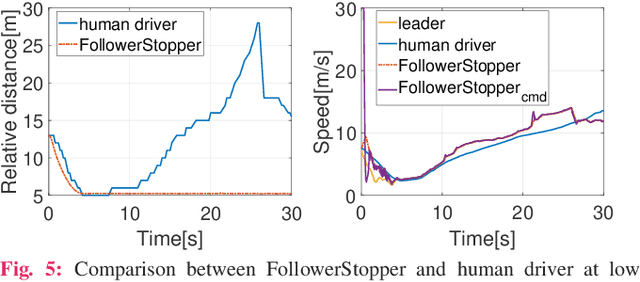
Motivated by earlier work and the developer of a new algorithm, the FollowerStopper, this article uses reachability analysis to verify the safety of the FollowerStopper algorithm, which is a controller designed for dampening stop- and-go traffic waves. With more than 1100 miles of driving data collected by our physical platform, we validate our analysis results by comparing it to human driving behaviors. The FollowerStopper controller has been demonstrated to dampen stop-and-go traffic waves at low speed, but previous analysis on its relative safety has been limited to upper and lower bounds of acceleration. To expand upon previous analysis, reachability analysis is used to investigate the safety at the speeds it was originally tested and also at higher speeds. Two formulations of safety analysis with different criteria are shown: distance-based and time headway-based. The FollowerStopper is considered safe with distance-based criterion. However, simulation results demonstrate that the FollowerStopper is not representative of human drivers - it follows too closely behind vehicles, specifically at a distance human would deem as unsafe. On the other hand, under the time headway-based safety analysis, the FollowerStopper is not considered safe anymore. A modified FollowerStopper is proposed to satisfy time-based safety criterion. Simulation results of the proposed FollowerStopper shows that its response represents human driver behavior better.
Defect detection and segmentation in X-Ray images of magnesium alloy castings using the Detectron2 framework
Feb 28, 2022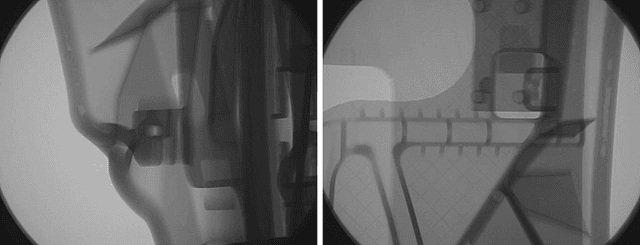
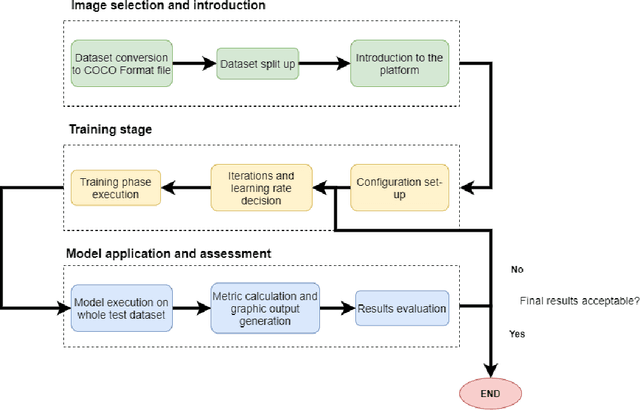
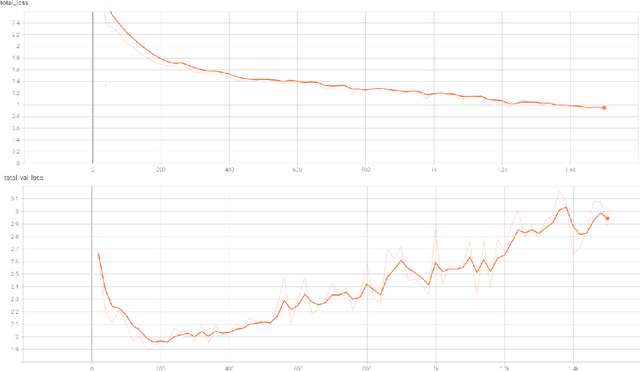
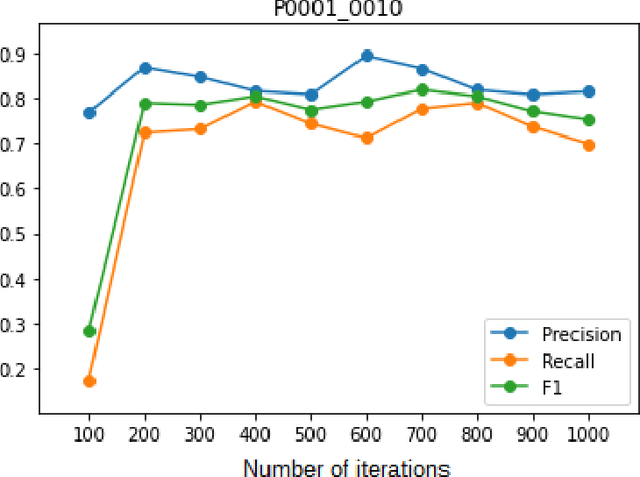
New production techniques have emerged that have made it possible to produce metal parts with more complex shapes, making the quality control process more difficult. This implies that the visual and superficial analysis has become even more inefficient. On top of that, it is also not possible to detect internal defects that these parts could have. The use of X-Ray images has made this process much easier, allowing not only to detect superficial defects in a much simpler way, but also to detect welding or casting defects that could represent a serious hazard for the physical integrity of the metal parts. On the other hand, the use of an automatic segmentation approach for detecting defects would help diminish the dependence of defect detection on the subjectivity of the factory operators and their time dependence variability. The aim of this paper is to apply a deep learning system based on Detectron2, a state-of-the-art library applied to object detection and segmentation in images, for the identification and segmentation of these defects on X-Ray images obtained mainly from automotive parts
Bayesian Structure Learning with Generative Flow Networks
Feb 28, 2022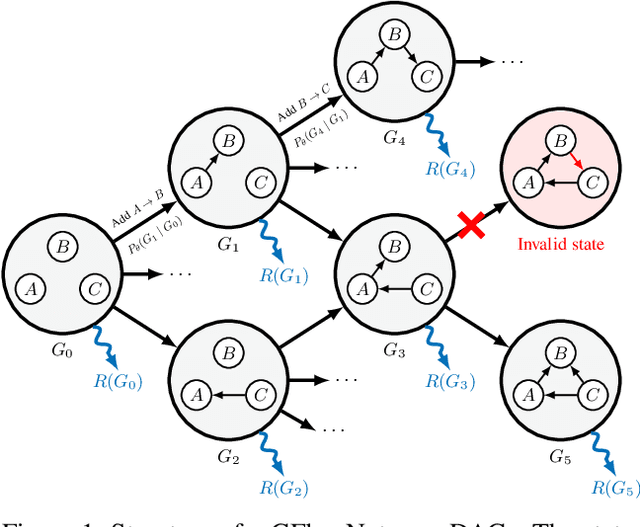
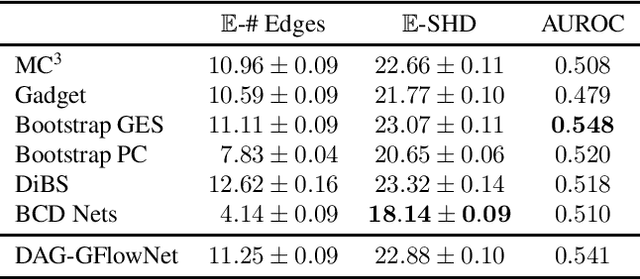
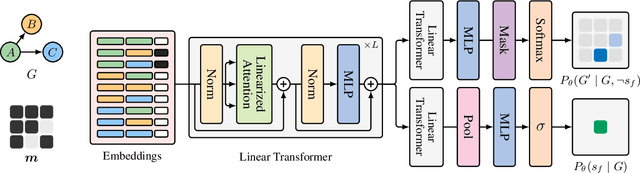
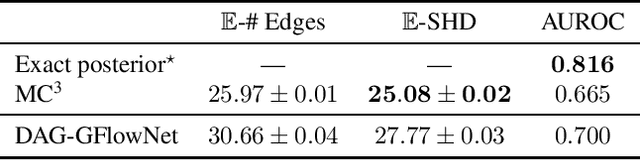
In Bayesian structure learning, we are interested in inferring a distribution over the directed acyclic graph (DAG) structure of Bayesian networks, from data. Defining such a distribution is very challenging, due to the combinatorially large sample space, and approximations based on MCMC are often required. Recently, a novel class of probabilistic models, called Generative Flow Networks (GFlowNets), have been introduced as a general framework for generative modeling of discrete and composite objects, such as graphs. In this work, we propose to use a GFlowNet as an alternative to MCMC for approximating the posterior distribution over the structure of Bayesian networks, given a dataset of observations. Generating a sample DAG from this approximate distribution is viewed as a sequential decision problem, where the graph is constructed one edge at a time, based on learned transition probabilities. Through evaluation on both simulated and real data, we show that our approach, called DAG-GFlowNet, provides an accurate approximation of the posterior over DAGs, and it compares favorably against other methods based on MCMC or variational inference.
TraceNet: Tracing and Locating the Key Elements in Sentiment Analysis
Feb 28, 2022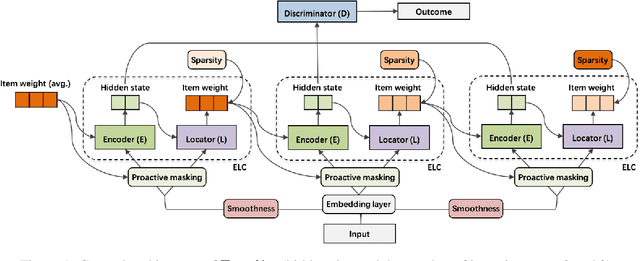
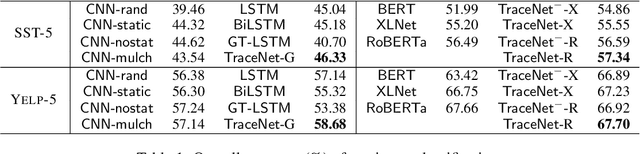
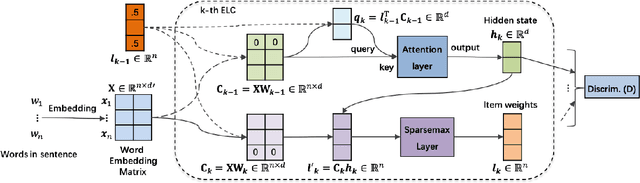
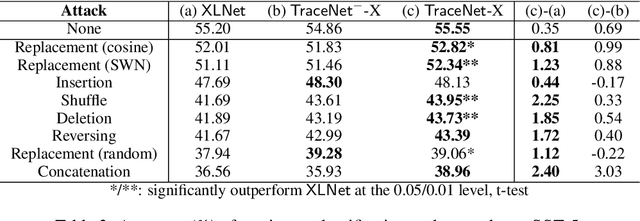
In this paper, we study sentiment analysis task where the outcomes are mainly contributed by a few key elements of the inputs. Motivated by the two-streams hypothesis, we propose a neural architecture, named TraceNet, to address this type of task. It not only learns discriminative representations for the target task via its encoders, but also traces key elements at the same time via its locators. In TraceNet, both encoders and locators are organized in a layer-wise manner, and a smoothness regularization is employed between adjacent encoder-locator combinations. Moreover, a sparsity constraints are enforced on locators for tracing purposes and items are proactively masked according to the item weights output by locators.A major advantage of TraceNet is that the outcomes are easier to understand, since the most responsible parts of inputs are identified. Also, under the guidance of locators, it is more robust to attacks due to its focus on key elements and the proactive masking training strategy. Experimental results show its effectiveness for sentiment classification. Moreover, we provide several case studies to demonstrate its robustness and interpretability.
Deep Learning-Based Sparse Whole-Slide Image Analysis for the Diagnosis of Gastric Intestinal Metaplasia
Jan 05, 2022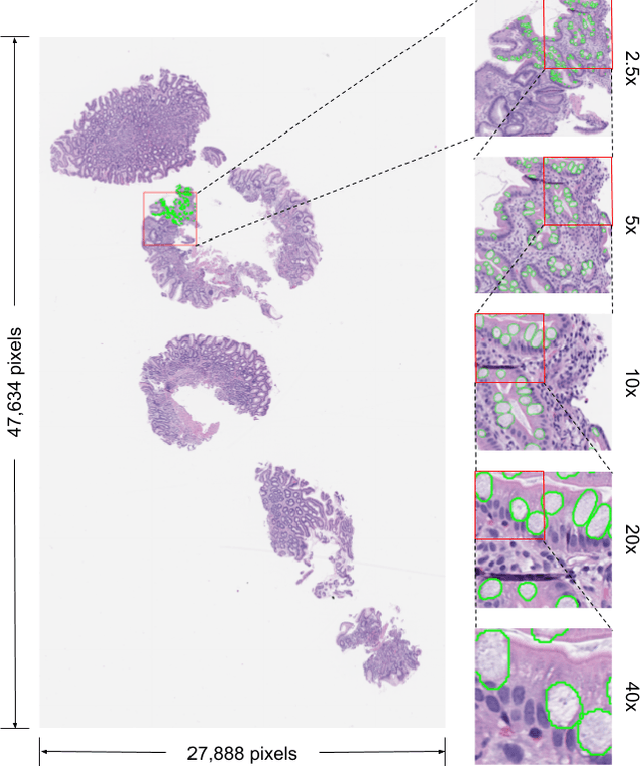
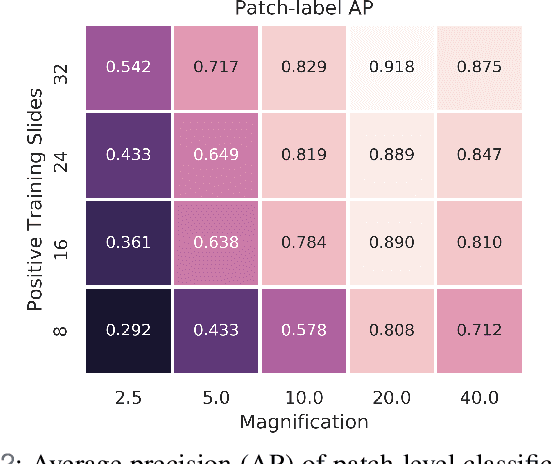
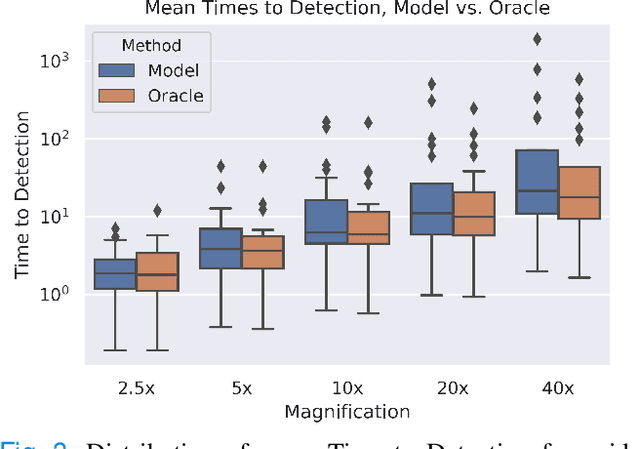
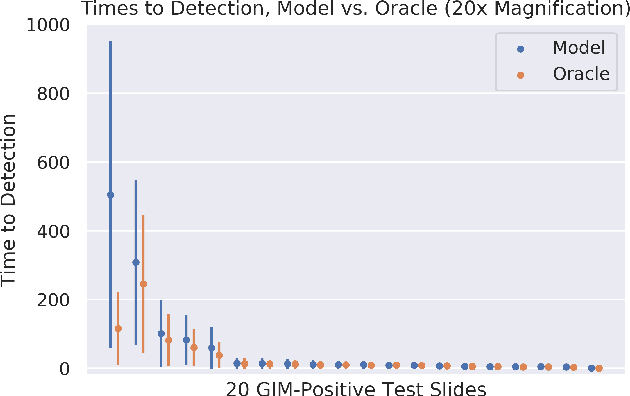
In recent years, deep learning has successfully been applied to automate a wide variety of tasks in diagnostic histopathology. However, fast and reliable localization of small-scale regions-of-interest (ROI) has remained a key challenge, as discriminative morphologic features often occupy only a small fraction of a gigapixel-scale whole-slide image (WSI). In this paper, we propose a sparse WSI analysis method for the rapid identification of high-power ROI for WSI-level classification. We develop an evaluation framework inspired by the early classification literature, in order to quantify the tradeoff between diagnostic performance and inference time for sparse analytic approaches. We test our method on a common but time-consuming task in pathology - that of diagnosing gastric intestinal metaplasia (GIM) on hematoxylin and eosin (H&E)-stained slides from endoscopic biopsy specimens. GIM is a well-known precursor lesion along the pathway to development of gastric cancer. We performed a thorough evaluation of the performance and inference time of our approach on a test set of GIM-positive and GIM-negative WSI, finding that our method successfully detects GIM in all positive WSI, with a WSI-level classification area under the receiver operating characteristic curve (AUC) of 0.98 and an average precision (AP) of 0.95. Furthermore, we show that our method can attain these metrics in under one minute on a standard CPU. Our results are applicable toward the goal of developing neural networks that can easily be deployed in clinical settings to support pathologists in quickly localizing and diagnosing small-scale morphologic features in WSI.
Training privacy-preserving video analytics pipelines by suppressing features that reveal information about private attributes
Mar 05, 2022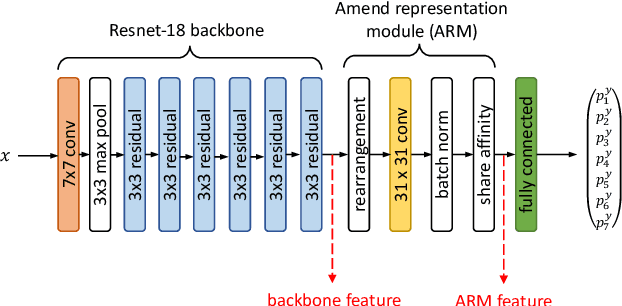

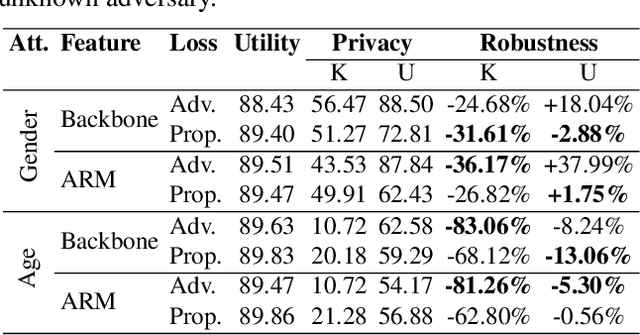
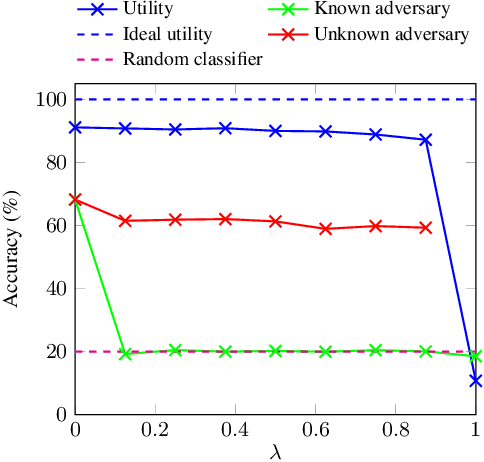
Deep neural networks are increasingly deployed for scene analytics, including to evaluate the attention and reaction of people exposed to out-of-home advertisements. However, the features extracted by a deep neural network that was trained to predict a specific, consensual attribute (e.g. emotion) may also encode and thus reveal information about private, protected attributes (e.g. age or gender). In this work, we focus on such leakage of private information at inference time. We consider an adversary with access to the features extracted by the layers of a deployed neural network and use these features to predict private attributes. To prevent the success of such an attack, we modify the training of the network using a confusion loss that encourages the extraction of features that make it difficult for the adversary to accurately predict private attributes. We validate this training approach on image-based tasks using a publicly available dataset. Results show that, compared to the original network, the proposed PrivateNet can reduce the leakage of private information of a state-of-the-art emotion recognition classifier by 2.88% for gender and by 13.06% for age group, with a minimal effect on task accuracy.
Motion-from-Blur: 3D Shape and Motion Estimation of Motion-blurred Objects in Videos
Nov 29, 2021
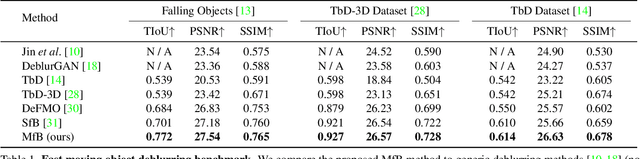
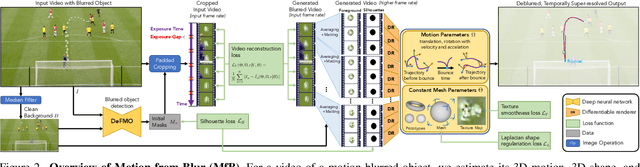
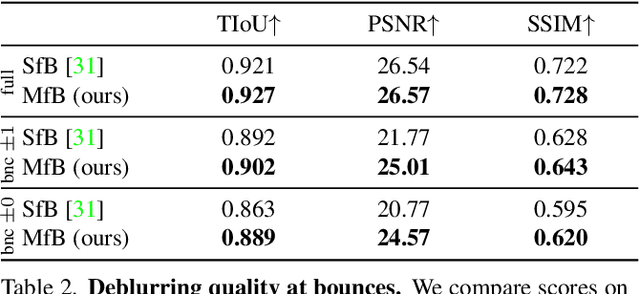
We propose a method for jointly estimating the 3D motion, 3D shape, and appearance of highly motion-blurred objects from a video. To this end, we model the blurred appearance of a fast moving object in a generative fashion by parametrizing its 3D position, rotation, velocity, acceleration, bounces, shape, and texture over the duration of a predefined time window spanning multiple frames. Using differentiable rendering, we are able to estimate all parameters by minimizing the pixel-wise reprojection error to the input video via backpropagating through a rendering pipeline that accounts for motion blur by averaging the graphics output over short time intervals. For that purpose, we also estimate the camera exposure gap time within the same optimization. To account for abrupt motion changes like bounces, we model the motion trajectory as a piece-wise polynomial, and we are able to estimate the specific time of the bounce at sub-frame accuracy. Experiments on established benchmark datasets demonstrate that our method outperforms previous methods for fast moving object deblurring and 3D reconstruction.
Online Learning with Knapsacks: the Best of Both Worlds
Feb 28, 2022
We study online learning problems in which a decision maker wants to maximize their expected reward without violating a finite set of $m$ resource constraints. By casting the learning process over a suitably defined space of strategy mixtures, we recover strong duality on a Lagrangian relaxation of the underlying optimization problem, even for general settings with non-convex reward and resource-consumption functions. Then, we provide the first best-of-both-worlds type framework for this setting, with no-regret guarantees both under stochastic and adversarial inputs. Our framework yields the same regret guarantees of prior work in the stochastic case. On the other hand, when budgets grow at least linearly in the time horizon, it allows us to provide a constant competitive ratio in the adversarial case, which improves over the $O(m \log T)$ competitive ratio of Immorlica at al. (2019). Moreover, our framework allows the decision maker to handle non-convex reward and cost functions. We provide two game-theoretic applications of our framework to give further evidence of its flexibility.