 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ME-Net: Multi-Encoder Net Framework for Brain Tumor Segmentation
Mar 21, 2022
Glioma is the most common and aggressive brain tumor. Magnetic resonance imaging (MRI) plays a vital role to evaluate tumors for the arrangement of tumor surgery and the treatment of subsequent procedures. However, the manual segmentation of the MRI image is strenuous, which limits its clinical application. With the development of deep learning, a large number of automatic segmentation methods have been developed, but most of them stay in 2D images, which leads to subpar performance. Moreover, the serious voxel imbalance between the brain tumor and the background as well as the different sizes and locations of the brain tumor makes the segmentation of 3D images a challenging problem. Aiming at segmenting 3D MRI, we propose a model for brain tumor segmentation with multiple encoders. The structure contains four encoders and one decoder. The four encoders correspond to the four modalities of the MRI image, perform one-to-one feature extraction, and then merge the feature maps of the four modalities into the decoder. This method reduces the difficulty of feature extraction and greatly improves model performance. We also introduced a new loss function named "Categorical Dice", and set different weights for different segmented regions at the same time, which solved the problem of voxel imbalance. We evaluated our approach using the online BraTS 2020 Challenge verification. Our proposed method can achieve promising results in the validation set compared to the state-of-the-art approaches with Dice scores of 0.70249, 0.88267, and 0.73864 for the intact tumor, tumor core, and enhanced tumor, respectively.
Sampling with Riemannian Hamiltonian Monte Carlo in a Constrained Space
Feb 03, 2022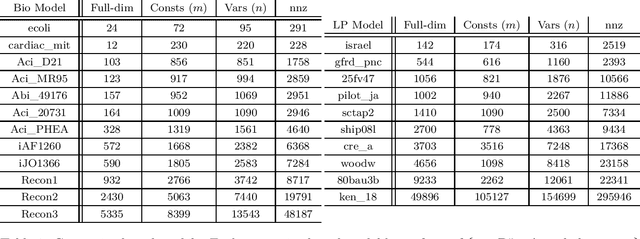
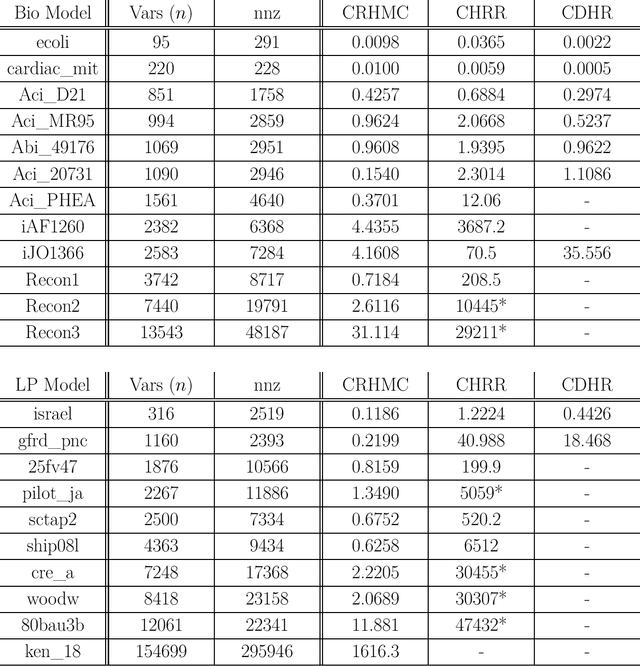
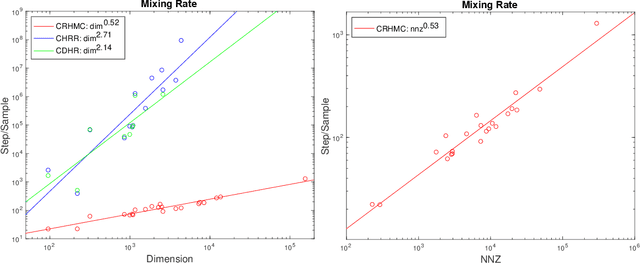
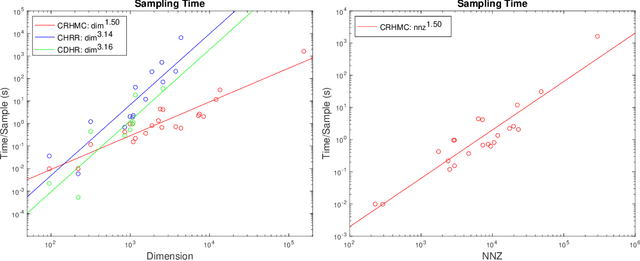
We demonstrate for the first time that ill-conditioned, non-smooth, constrained distributions in very high dimension, upwards of 100,000, can be sampled efficiently $\textit{in practice}$. Our algorithm incorporates constraints into the Riemannian version of Hamiltonian Monte Carlo and maintains sparsity. This allows us to achieve a mixing rate independent of smoothness and condition numbers. On benchmark data sets in systems biology and linear programming, our algorithm outperforms existing packages by orders of magnitude. In particular, we achieve a 1,000-fold speed-up for sampling from the largest published human metabolic network (RECON3D). Our package has been incorporated into the COBRA toolbox.
All in One: Exploring Unified Video-Language Pre-training
Mar 14, 2022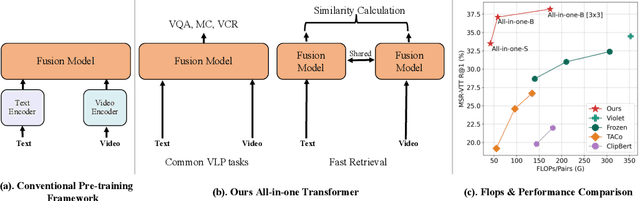
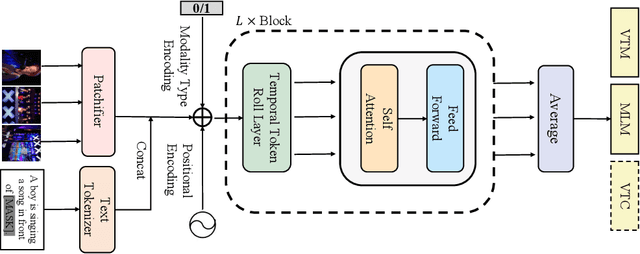
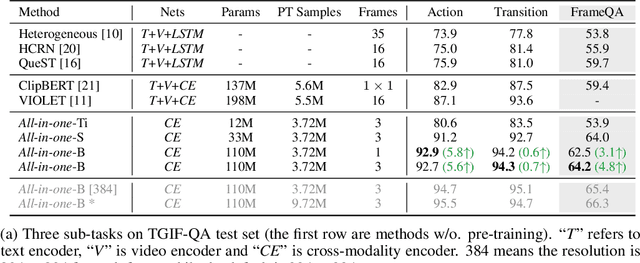
Mainstream Video-Language Pre-training models \cite{actbert,clipbert,violet} consist of three parts, a video encoder, a text encoder, and a video-text fusion Transformer. They pursue better performance via utilizing heavier unimodal encoders or multimodal fusion Transformers, resulting in increased parameters with lower efficiency in downstream tasks. In this work, we for the first time introduce an end-to-end video-language model, namely \textit{all-in-one Transformer}, that embeds raw video and textual signals into joint representations using a unified backbone architecture. We argue that the unique temporal information of video data turns out to be a key barrier hindering the design of a modality-agnostic Transformer. To overcome the challenge, we introduce a novel and effective token rolling operation to encode temporal representations from video clips in a non-parametric manner. The careful design enables the representation learning of both video-text multimodal inputs and unimodal inputs using a unified backbone model. Our pre-trained all-in-one Transformer is transferred to various downstream video-text tasks after fine-tuning, including text-video retrieval, video-question answering, multiple choice and visual commonsense reasoning. State-of-the-art performances with the minimal model FLOPs on nine datasets demonstrate the superiority of our method compared to the competitive counterparts. The code and pretrained model have been released in https://github.com/showlab/all-in-one.
Algorithms that get old : the case of generative algorithms
Feb 07, 2022


Generative IA networks, like the Variational Auto-Encoders (VAE), and Generative Adversarial Networks (GANs) produce new objects each time when asked to do so. However, this behavior is unlike that of human artists that change their style as times go by and seldom return to the initial point. We investigate a situation where VAEs are requested to sample from a probability measure described by some empirical set. Based on recent works on Radon-Sobolev statistical distances, we propose a numerical paradigm, to be used in conjunction with a generative algorithm, that satisfies the two following requirements: the objects created do not repeat and evolve to fill the entire target probability measure.
A Finite-Time Technological Singularity Model With Artificial Intelligence Self-Improvement
Aug 31, 2020
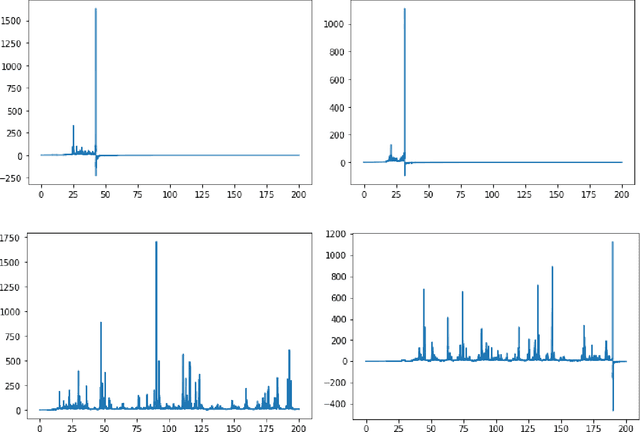
Recent advances in the development of artificial intelligence, technological progress acceleration, long-term trends of macroeconomic dynamics increase the relevance of technological singularity hypothesis. In this paper, we build a model of finite-time technological singularity assuming that artificial intelligence will replace humans for artificial intelligence engineers after some point in time when it is developed enough. This model implies the following: let A be the level of development of artificial intelligence. Then, the moment of technological singularity n is defined as the point in time where artificial intelligence development function approaches infinity. Thus, it happens in finite time. Although infinite level of development of artificial intelligence cannot be reached practically, this approximation is useful for several reasons, firstly because it allows modeling a phase transition or a change of regime. In the model, intelligence growth function appears to be hyperbolic function under relatively broad conditions which we list and compare. Subsequently, we also add a stochastic term (Brownian motion) to the model and investigate the changes in its behavior. The results can be applied for the modeling of dynamics of various processes characterized by multiplicative growth.
Sequence-To-Sequence Voice Conversion using F0 and Time Conditioning and Adversarial Learning
Oct 07, 2021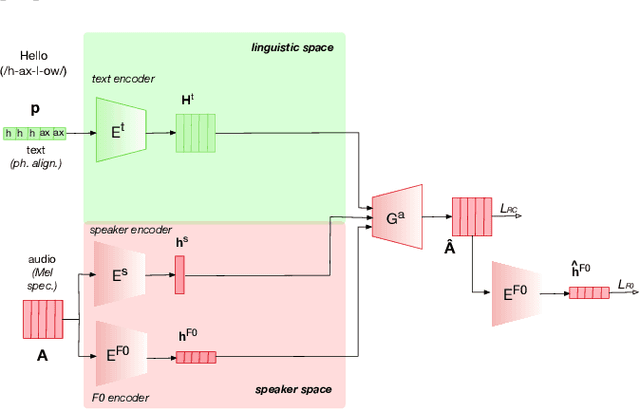
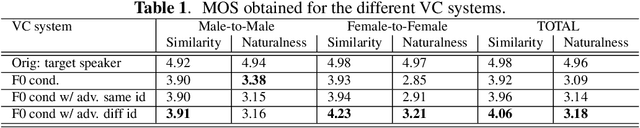
This paper presents a sequence-to-sequence voice conversion (S2S-VC) algorithm which allows to preserve some aspects of the source speaker during conversion, typically its prosody, which is useful in many real-life application of voice conversion. In S2S-VC, the decoder is usually conditioned on linguistic and speaker embeddings only, with the consequence that only the linguistic content is actually preserved during conversion. In the proposed S2S-VC architecture, the decoder is conditioned explicitly on the desired F0 sequence so that the converted speech has the same F0 as the one of the source speaker, or any F0 defined arbitrarily. Moreover, an adversarial module is further employed so that the S2S-VC is not only optimized on the available true speech samples, but can also take efficiently advantage of the converted speech samples that can be produced by using various conditioning such as speaker identity, F0, or timing.
Modeling Financial Time Series using LSTM with Trainable Initial Hidden States
Jul 14, 2020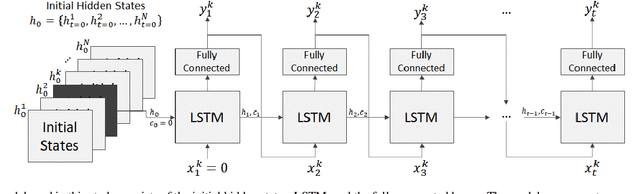
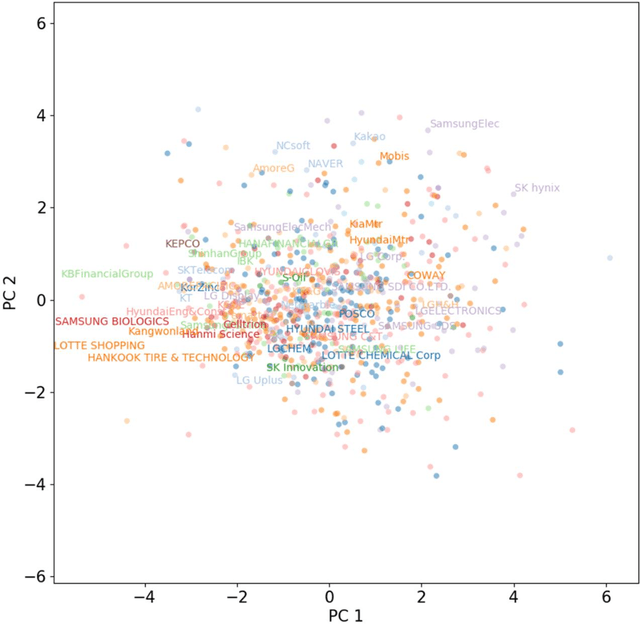
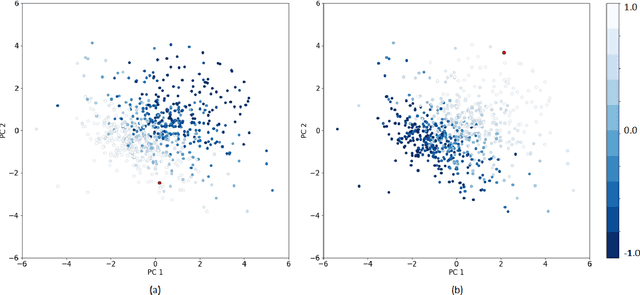
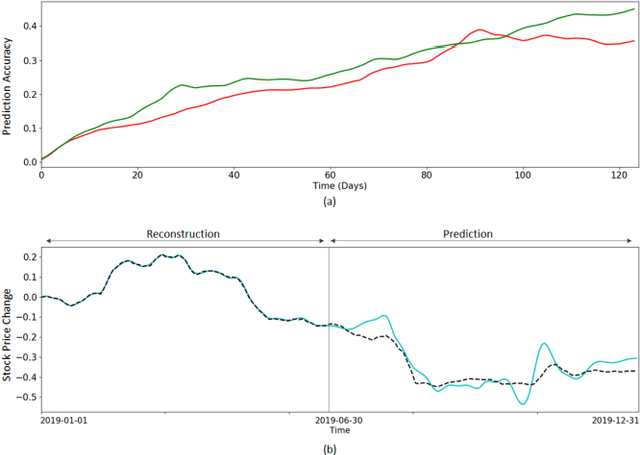
Extracting previously unknown patterns and information in time series is central to many real-world applications. In this study, we introduce a novel approach to modeling financial time series using a deep learning model. We use a Long Short-Term Memory (LSTM) network equipped with the trainable initial hidden states. By learning to reconstruct time series, the proposed model can represent high-dimensional time series data with its parameters. An experiment with the Korean stock market data showed that the model was able to capture the relative similarity between a large number of stock prices in its latent space. Besides, the model was also able to predict the future stock trends from the latent space. The proposed method can help to identify relationships among many time series, and it could be applied to financial applications, such as optimizing the investment portfolios.
Enhancement of Spatial Clustering-Based Time-Frequency Masks using LSTM Neural Networks
Dec 02, 2020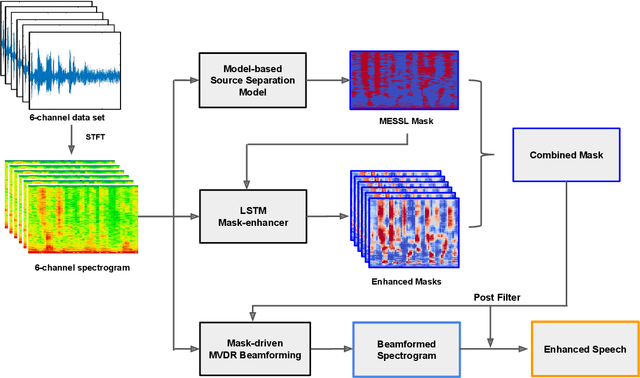

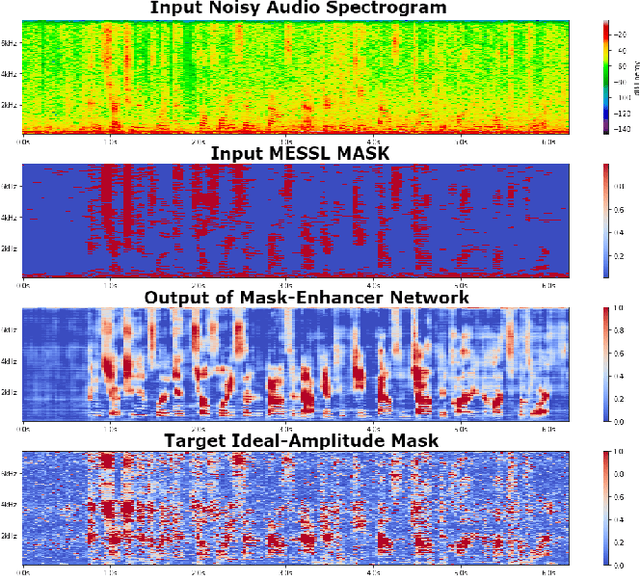
Recent works have shown that Deep Recurrent Neural Networks using the LSTM architecture can achieve strong single-channel speech enhancement by estimating time-frequency masks. However, these models do not naturally generalize to multi-channel inputs from varying microphone configurations. In contrast, spatial clustering techniques can achieve such generalization but lack a strong signal model. Our work proposes a combination of the two approaches. By using LSTMs to enhance spatial clustering based time-frequency masks, we achieve both the signal modeling performance of multiple single-channel LSTM-DNN speech enhancers and the signal separation performance and generality of multi-channel spatial clustering. We compare our proposed system to several baselines on the CHiME-3 dataset. We evaluate the quality of the audio from each system using SDR from the BSS\_eval toolkit and PESQ. We evaluate the intelligibility of the output of each system using word error rate from a Kaldi automatic speech recognizer.
Instance-aware multi-object self-supervision for monocular depth prediction
Mar 02, 2022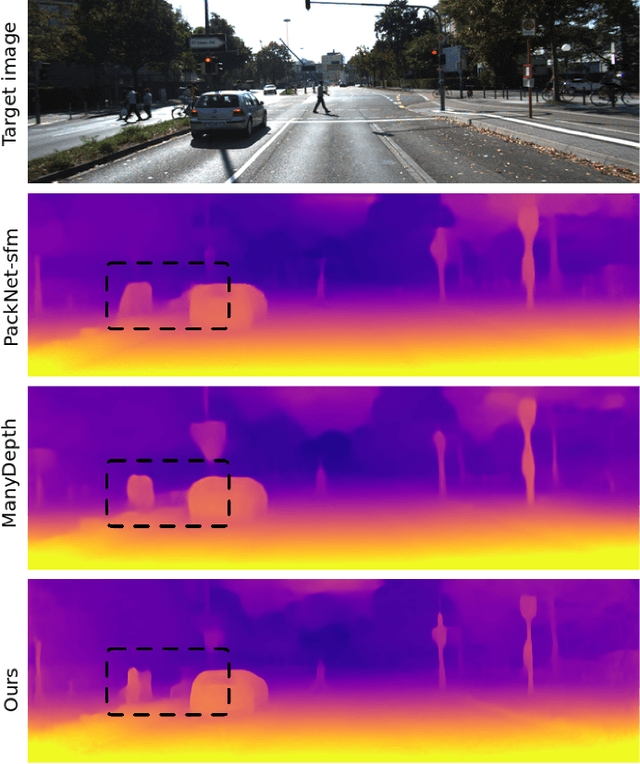
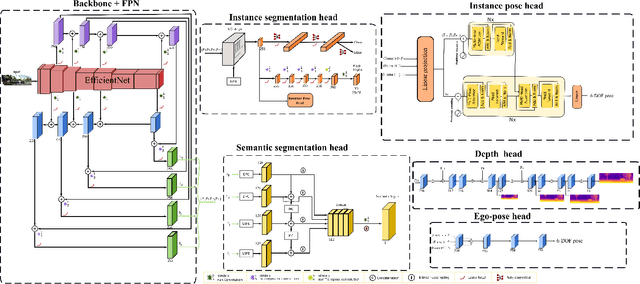
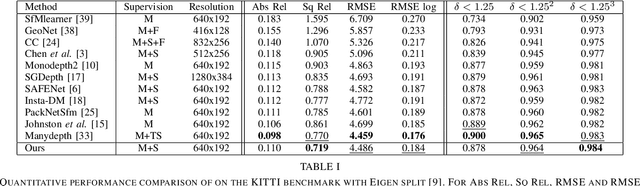
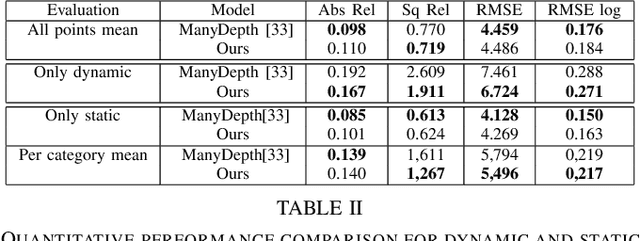
This paper proposes a self-supervised monocular image-to-depth prediction framework that is trained with an end-to-end photometric loss that handles not only 6-DOF camera motion but also 6-DOF moving object instances. Self-supervision is performed by warping the images across a video sequence using depth and scene motion including object instances. One novelty of the proposed method is the use of a multi-head attention of the transformer network that matches moving objects across time and models their interaction and dynamics. This enables accurate and robust pose estimation for each object instance. Most image-to-depth predication frameworks make the assumption of rigid scenes, which largely degrades their performance with respect to dynamic objects. Only a few SOTA papers have accounted for dynamic objects. The proposed method is shown to largely outperform these methods on standard benchmarks and the impact of the dynamic motion on these benchmarks is exposed. Furthermore, the proposed image-to-depth prediction framework is also shown to outperform SOTA video-to-depth prediction frameworks.
The Role of Time and Data: Online Conformance Checking in the Manufacturing Domain
May 04, 2021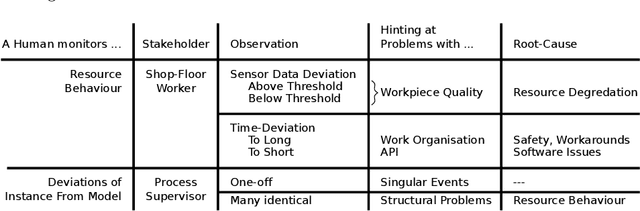
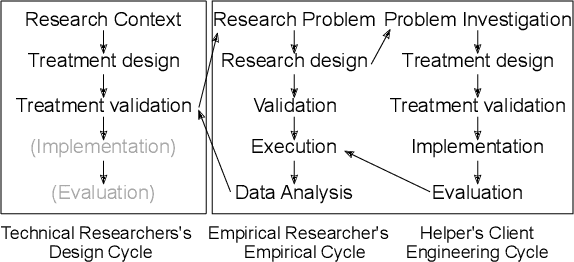
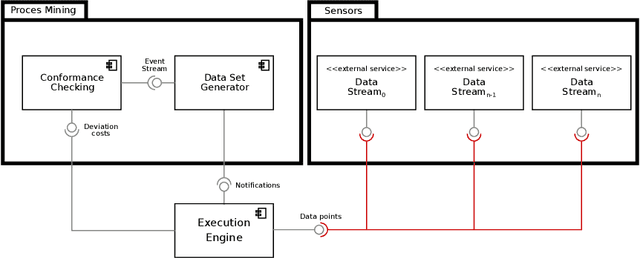
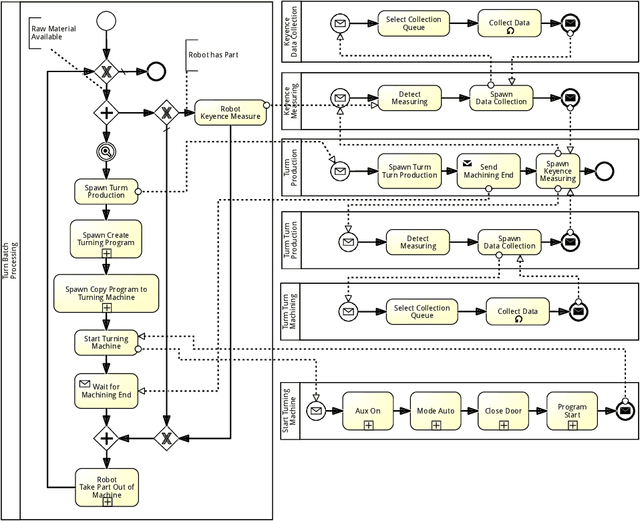
Process mining has matured as analysis instrument for process-oriented data in recent years. Manufacturing is a challenging domain that craves for process-oriented technologies to address digitalization challenges. We found that process mining creates high expectations, but its implementation and usage by manufacturing experts such as process supervisors and shopfloor workers remain unclear to a certain extent. Reason (1) is that even though manufacturing allows for well-structured processes, the actual workflow is rarely captured in a process model. Even if a model is available, a software for orchestrating and logging the execution is often missing. Reason (2) refers to the work reality in manufacturing: a process instance is started by a shopfloor worker who then turns to work on other things. Hence continuous monitoring of the process instances does not happen, i.e., process monitoring is merely a secondary task, and the shopfloor worker can only react to problems/errors that have already occurred. (1) and (2) motivate the goals of this study that is driven by Technical Action Research (TAR). Based on the experimental artifact TIDATE -- a lightweight process execution and mining framework -- it is studied how the correct execution of process instances can be ensured and how a data set suitable for process mining can be generated at run time in a real-world setting. Secondly, it is investigated whether and how process mining supports domain experts during process monitoring as a secondary task. The findings emphasize the importance of online conformance checking in manufacturing and show how appropriate data sets can be identified and generated.