 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Survey on Model Compression for Natural Language Processing
Feb 15, 2022
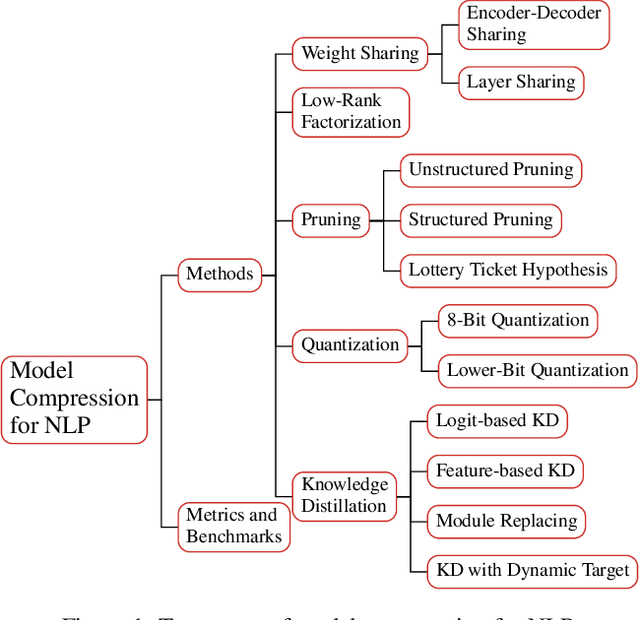

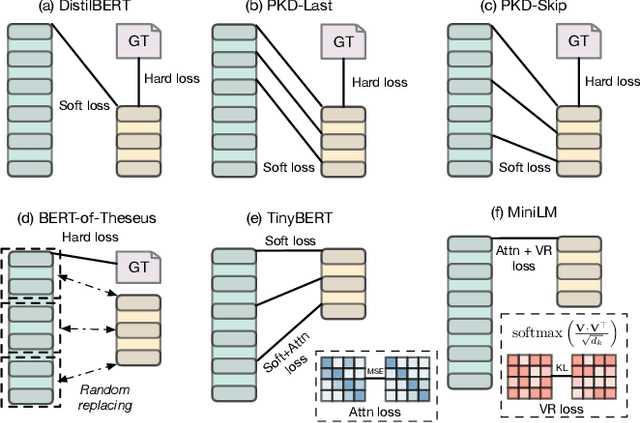
With recent developments in new architectures like Transformer and pretraining techniques, significant progress has been made in applications of natural language processing (NLP). However, the high energy cost and long inference delay of Transformer is preventing NLP from entering broader scenarios including edge and mobile computing. Efficient NLP research aims to comprehensively consider computation, time and carbon emission for the entire life-cycle of NLP, including data preparation, model training and inference. In this survey, we focus on the inference stage and review the current state of model compression for NLP, including the benchmarks, metrics and methodology. We outline the current obstacles and future research directions.
Alternative Paths Planner (APP) for Provably Fixed-time Manipulation Planning in Semi-structured Environments
Dec 29, 2020
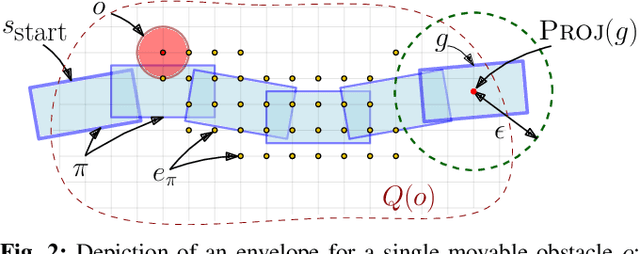
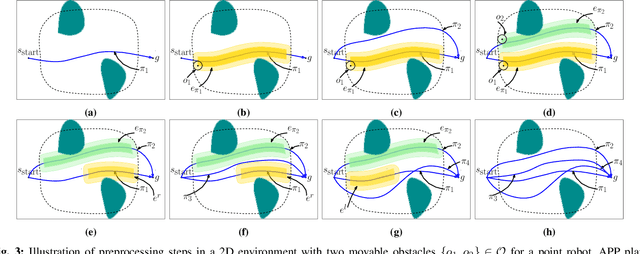
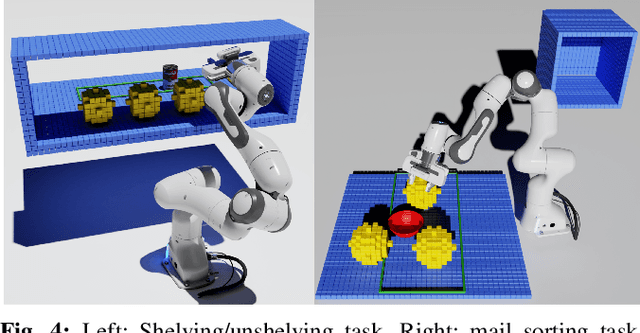
In many applications, including logistics and manufacturing, robot manipulators operate in semi-structured environments alongside humans or other robots. These environments are largely static, but they may contain some movable obstacles that the robot must avoid. Manipulation tasks in these applications are often highly repetitive, but require fast and reliable motion planning capabilities, often under strict time constraints. Existing preprocessing-based approaches are beneficial when the environments are highly-structured, but their performance degrades in the presence of movable obstacles, since these are not modelled a priori. We propose a novel preprocessing-based method called Alternative Paths Planner (APP) that provides provably fixed-time planning guarantees in semi-structured environments. APP plans a set of alternative paths offline such that, for any configuration of the movable obstacles, at least one of the paths from this set is collision-free. During online execution, a collision-free path can be looked up efficiently within a few microseconds. We evaluate APP on a 7 DoF robot arm in semi-structured domains of varying complexity and demonstrate that APP is several orders of magnitude faster than state-of-the-art motion planners for each domain. We further validate this approach with real-time experiments on a robotic manipulator.
Multi-modal Brain Tumor Segmentation via Missing Modality Synthesis and Modality-level Attention Fusion
Mar 09, 2022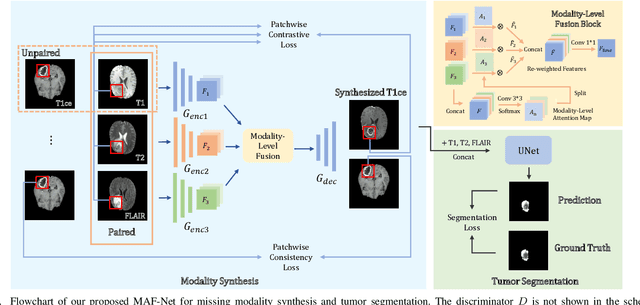
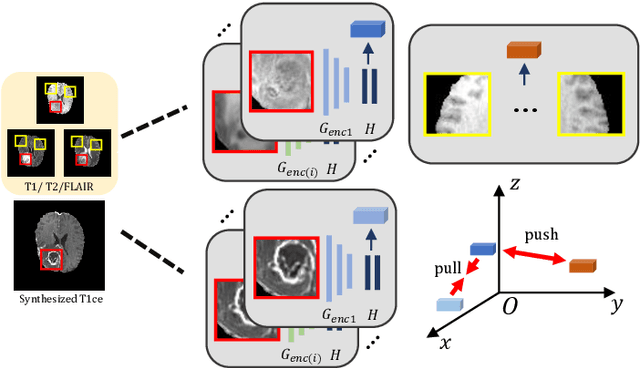
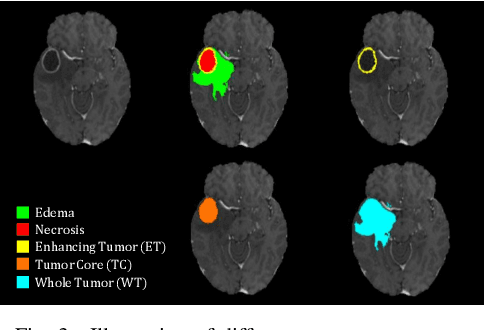
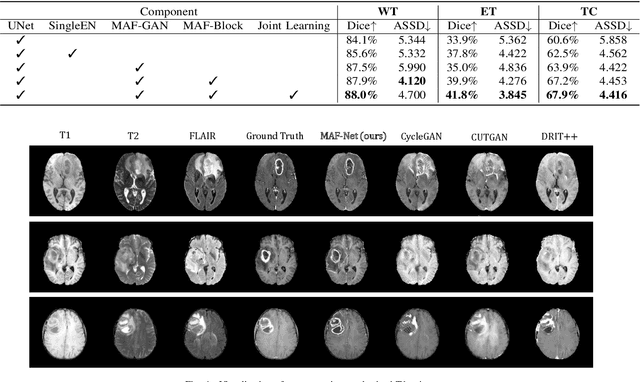
Multi-modal magnetic resonance (MR) imaging provides great potential for diagnosing and analyzing brain gliomas. In clinical scenarios, common MR sequences such as T1, T2 and FLAIR can be obtained simultaneously in a single scanning process. However, acquiring contrast enhanced modalities such as T1ce requires additional time, cost, and injection of contrast agent. As such, it is clinically meaningful to develop a method to synthesize unavailable modalities which can also be used as additional inputs to downstream tasks (e.g., brain tumor segmentation) for performance enhancing. In this work, we propose an end-to-end framework named Modality-Level Attention Fusion Network (MAF-Net), wherein we innovatively conduct patchwise contrastive learning for extracting multi-modal latent features and dynamically assigning attention weights to fuse different modalities. Through extensive experiments on BraTS2020, our proposed MAF-Net is found to yield superior T1ce synthesis performance (SSIM of 0.8879 and PSNR of 22.78) and accurate brain tumor segmentation (mean Dice scores of 67.9%, 41.8% and 88.0% on segmenting the tumor core, enhancing tumor and whole tumor).
Hate Speech Classification Using SVM and Naive BAYES
Mar 21, 2022
The spread of hatred that was formerly limited to verbal communications has rapidly moved over the Internet. Social media and community forums that allow people to discuss and express their opinions are becoming platforms for the spreading of hate messages. Many countries have developed laws to avoid online hate speech. They hold the companies that run the social media responsible for their failure to eliminate hate speech. But as online content continues to grow, so does the spread of hate speech However, manual analysis of hate speech on online platforms is infeasible due to the huge amount of data as it is expensive and time consuming. Thus, it is important to automatically process the online user contents to detect and remove hate speech from online media. Many recent approaches suffer from interpretability problem which means that it can be difficult to understand why the systems make the decisions they do. Through this work, some solutions for the problem of automatic detection of hate messages were proposed using Support Vector Machine (SVM) and Na\"ive Bayes algorithms. This achieved near state-of-the-art performance while being simpler and producing more easily interpretable decisions than other methods. Empirical evaluation of this technique has resulted in a classification accuracy of approximately 99% and 50% for SVM and NB respectively over the test set. Keywords: classification; hate speech; feature extraction, algorithm, supervised learning
Modeling of time series using random forests: theoretical developments
Aug 06, 2020
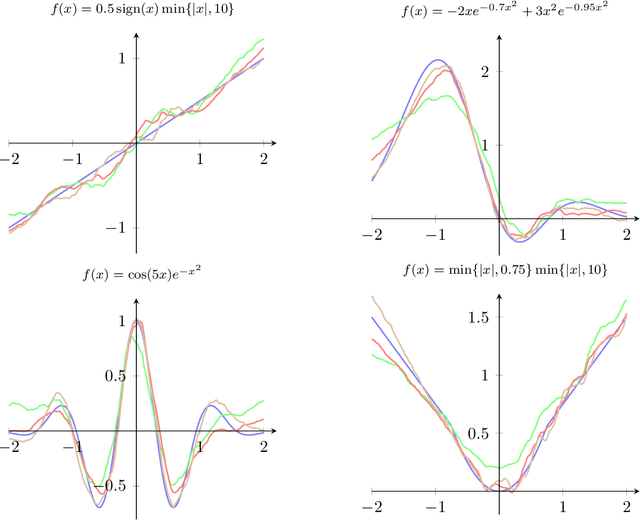
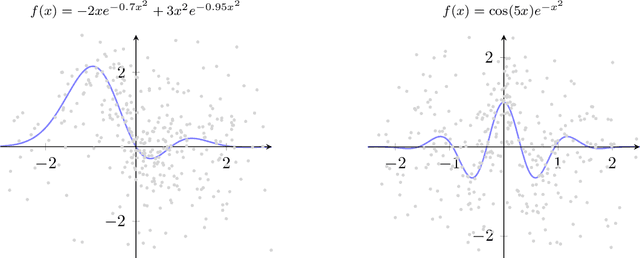
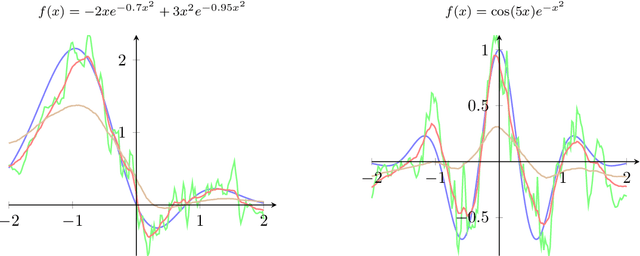
In this paper we study asymptotic properties of random forests within the framework of nonlinear time series modeling. While random forests have been successfully applied in various fields, the theoretical justification has not been considered for their use in a time series setting. Under mild conditions, we prove a uniform concentration inequality for regression trees built on nonlinear autoregressive processes and, subsequently, we use this result to prove consistency for a large class of random forests. The results are supported by various simulations.
Facial Expression Analysis Using Decomposed Multiscale Spatiotemporal Networks
Mar 21, 2022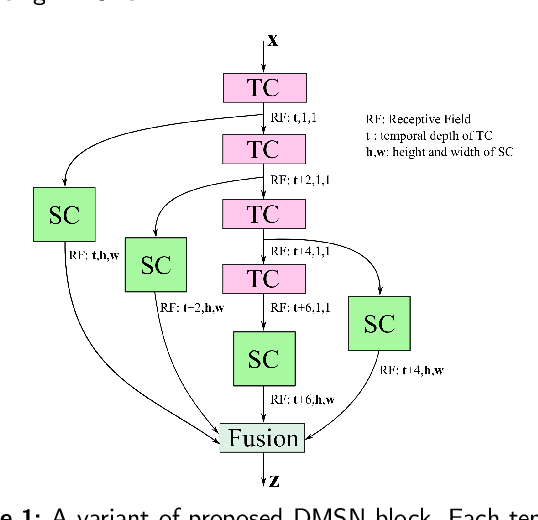
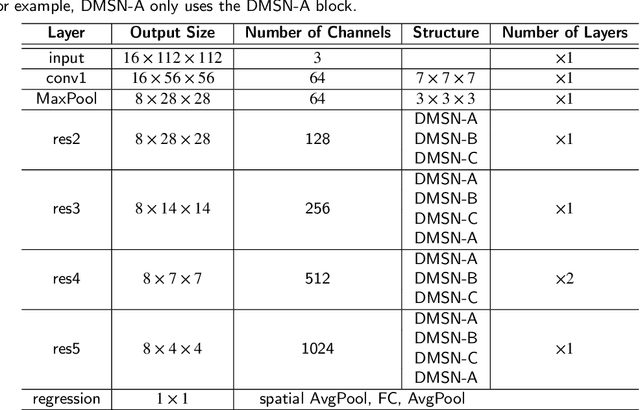
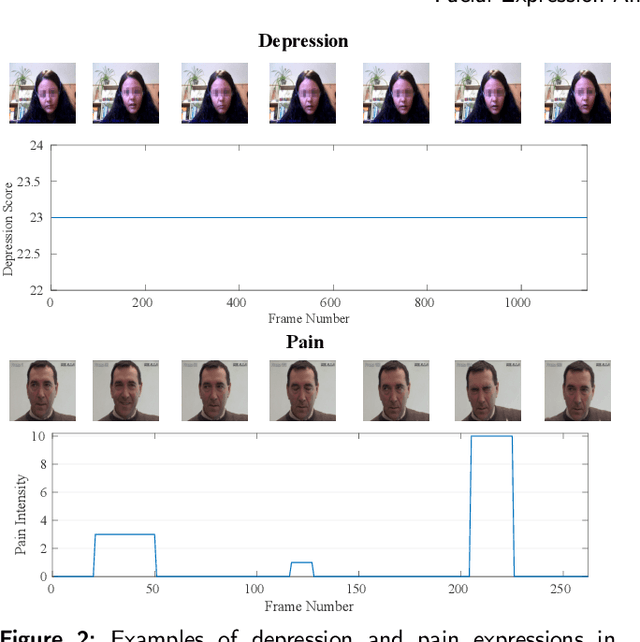
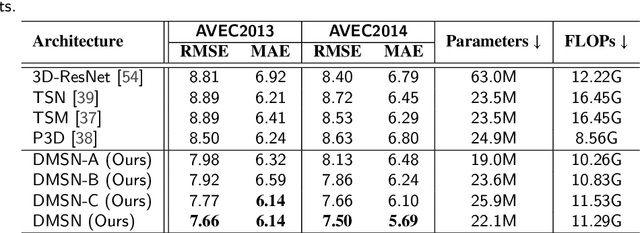
Video-based analysis of facial expressions has been increasingly applied to infer health states of individuals, such as depression and pain. Among the existing approaches, deep learning models composed of structures for multiscale spatiotemporal processing have shown strong potential for encoding facial dynamics. However, such models have high computational complexity, making for a difficult deployment of these solutions. To address this issue, we introduce a new technique to decompose the extraction of multiscale spatiotemporal features. Particularly, a building block structure called Decomposed Multiscale Spatiotemporal Network (DMSN) is presented along with three variants: DMSN-A, DMSN-B, and DMSN-C blocks. The DMSN-A block generates multiscale representations by analyzing spatiotemporal features at multiple temporal ranges, while the DMSN-B block analyzes spatiotemporal features at multiple ranges, and the DMSN-C block analyzes spatiotemporal features at multiple spatial sizes. Using these variants, we design our DMSN architecture which has the ability to explore a variety of multiscale spatiotemporal features, favoring the adaptation to different facial behaviors. Our extensive experiments on challenging datasets show that the DMSN-C block is effective for depression detection, whereas the DMSN-A block is efficient for pain estimation. Results also indicate that our DMSN architecture provides a cost-effective solution for expressions that range from fewer facial variations over time, as in depression detection, to greater variations, as in pain estimation.
Automated Clinical Coding: What, Why, and Where We Are?
Mar 21, 2022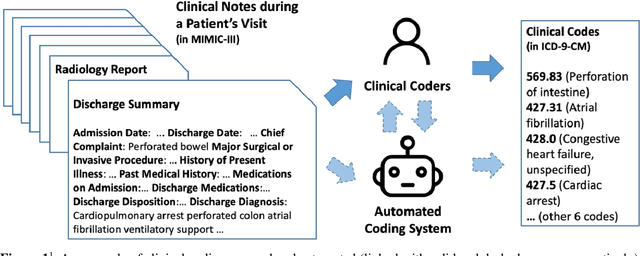
Clinical coding is the task of transforming medical information in a patient's health records into structured codes so that they can be used for statistical analysis. This is a cognitive and time-consuming task that follows a standard process in order to achieve a high level of consistency. Clinical coding could potentially be supported by an automated system to improve the efficiency and accuracy of the process. We introduce the idea of automated clinical coding and summarise its challenges from the perspective of Artificial Intelligence (AI) and Natural Language Processing (NLP), based on the literature, our project experience over the past two and half years (late 2019 - early 2022), and discussions with clinical coding experts in Scotland and the UK. Our research reveals the gaps between the current deep learning-based approach applied to clinical coding and the need for explainability and consistency in real-world practice. Knowledge-based methods that represent and reason the standard, explainable process of a task may need to be incorporated into deep learning-based methods for clinical coding. Automated clinical coding is a promising task for AI, despite the technical and organisational challenges. Coders are needed to be involved in the development process. There is much to achieve to develop and deploy an AI-based automated system to support coding in the next five years and beyond.
Human Instance Segmentation and Tracking via Data Association and Single-stage Detector
Mar 31, 2022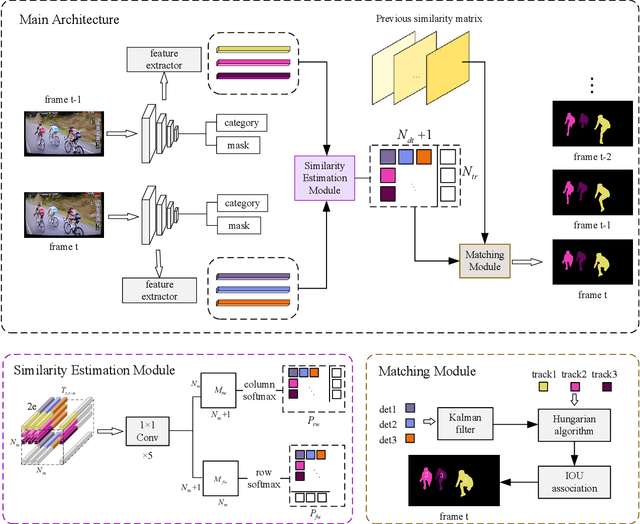


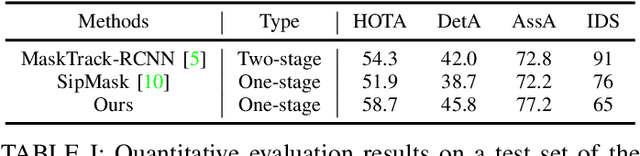
Human video instance segmentation plays an important role in computer understanding of human activities and is widely used in video processing, video surveillance, and human modeling in virtual reality. Most current VIS methods are based on Mask-RCNN framework, where the target appearance and motion information for data matching will increase computational cost and have an impact on segmentation real-time performance; on the other hand, the existing datasets for VIS focus less on all the people appearing in the video. In this paper, to solve the problems, we develop a new method for human video instance segmentation based on single-stage detector. To tracking the instance across the video, we have adopted data association strategy for matching the same instance in the video sequence, where we jointly learn target instance appearances and their affinities in a pair of video frames in an end-to-end fashion. We have also adopted the centroid sampling strategy for enhancing the embedding extraction ability of instance, which is to bias the instance position to the inside of each instance mask with heavy overlap condition. As a result, even there exists a sudden change in the character activity, the instance position will not move out of the mask, so that the problem that the same instance is represented by two different instances can be alleviated. Finally, we collect PVIS dataset by assembling several video instance segmentation datasets to fill the gap of the current lack of datasets dedicated to human video segmentation. Extensive simulations based on such dataset has been conduct. Simulation results verify the effectiveness and efficiency of the proposed work.
Quadruped Capturability and Push Recovery via a Switched-Systems Characterization of Dynamic Balance
Feb 07, 2022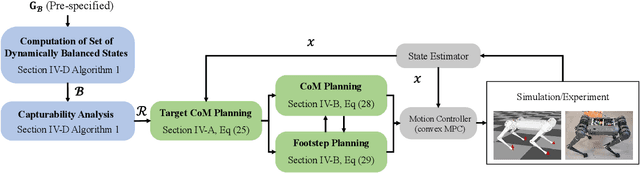

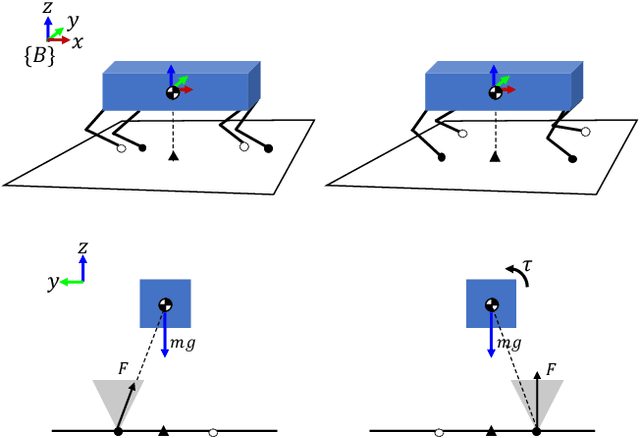
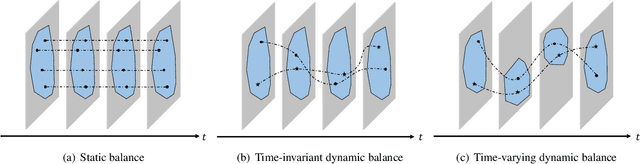
This paper studies capturability and push recovery for quadrupedal locomotion. Despite the rich literature on capturability analysis and push recovery control for legged robots, existing tools are developed mainly for bipeds or humanoids. Distinct quadrupedal features such as point contacts and multiple swinging legs prevent direct application of these methods. To address this gap, we propose a switched systems model for quadruped dynamics, and instantiate the abstract viability concept for quadrupedal locomotion with a time-based gait. Capturability is characterized through a novel specification of dynamically balanced states that addresses the time-varying nature of quadrupedal locomotion and balance. A linear inverted pendulum (LIP) model is adopted to demonstrate the theory and show how the newly developed quadrupedal capturability can be used in motion planning for quadrupedal push recovery. We formulate and solve an explicit model predictive control (EMPC) problem whose optimal solution fully characterizes quadrupedal capturability with the LIP. Given this analysis, an optimization-based planning scheme is devised for determining footsteps and center of mass references during push recovery. To validate the effectiveness of the overall framework, we conduct numerous simulation and hardware experiments. Simulation results illustrate the necessity of considering dynamic balance for quadrupedal capturability, and the significant improvement in disturbance rejection with the proposed strategy. Experimental validations on a replica of the Mini Cheetah quadruped demonstrate an up to 100% improvement as compared with state-of-the-art.
Whole-Body MPC and Dynamic Occlusion Avoidance: A Maximum Likelihood Visibility Approach
Mar 04, 2022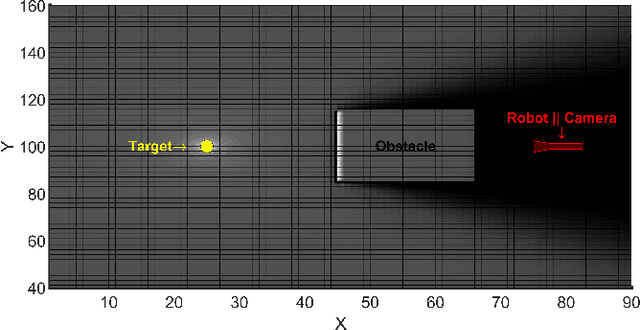

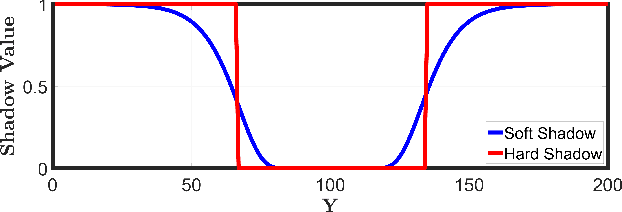
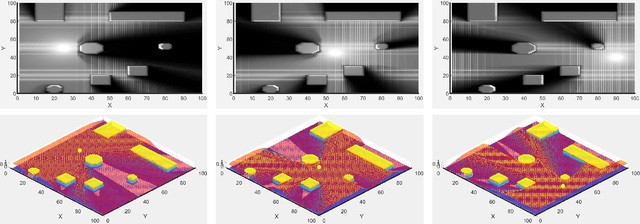
This paper introduces a novel approach for whole-body motion planning and dynamic occlusion avoidance. The proposed approach reformulates the visibility constraint as a likelihood maximization of visibility probability. In this formulation, we augment the primary cost function of a whole-body model predictive control scheme through a relaxed log barrier function yielding a relaxed log-likelihood maximization formulation of visibility probability. The visibility probability is computed through a probabilistic shadow field that quantifies point light source occlusions. We provide the necessary algorithms to obtain such a field for both 2D and 3D cases. We demonstrate 2D implementations of this field in simulation and 3D implementations through real-time hardware experiments. We show that due to the linear complexity of our shadow field algorithm to the map size, we can achieve high update rates, which facilitates onboard execution on mobile platforms with limited computational power. Lastly, we evaluate the performance of the proposed MPC reformulation in simulation for a quadrupedal mobile manipulator.