 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards neoRL networks; the emergence of purposive graphs
Feb 25, 2022

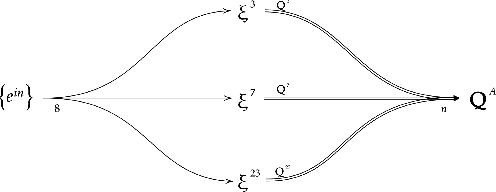
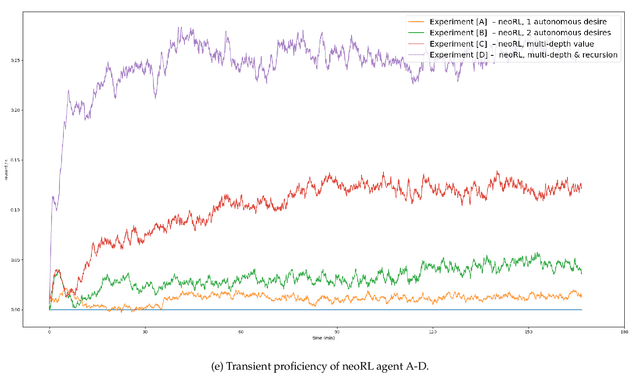
The neoRL framework for purposive AI implements latent learning by emulated cognitive maps, with general value functions (GVF) expressing operant desires toward separate states. The agent's expectancy of reward, expressed as learned projections in the considered space, allows the neoRL agent to extract purposive behavior from the learned map according to the reward hypothesis. We explore this allegory further, considering neoRL modules as nodes in a network with desire as input and state-action Q-value as output; we see that action sets with Euclidean significance imply an interpretation of state-action vectors as Euclidean projections of desire. Autonomous desire from neoRL nodes within the agent allows for deeper neoRL behavioral graphs. Experiments confirm the effect of neoRL networks governed by autonomous desire, verifying the four principles for purposive networks. A neoRL agent governed by purposive networks can navigate Euclidean spaces in real-time while learning, exemplifying how modern AI still can profit from inspiration from early psychology.
Reinforcement Learning in the Wild: Scalable RL Dispatching Algorithm Deployed in Ridehailing Marketplace
Feb 10, 2022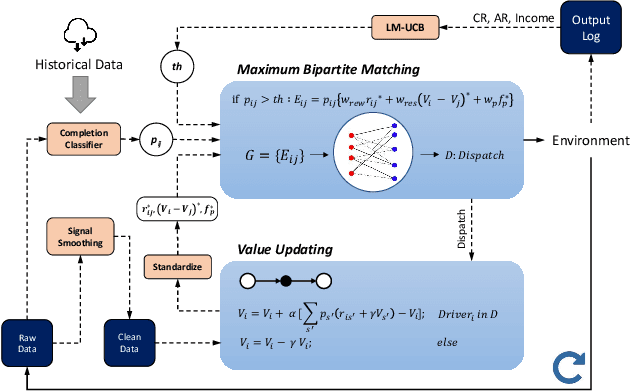
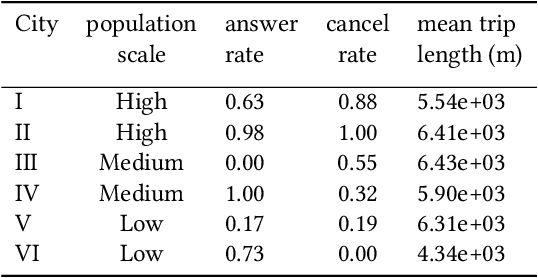
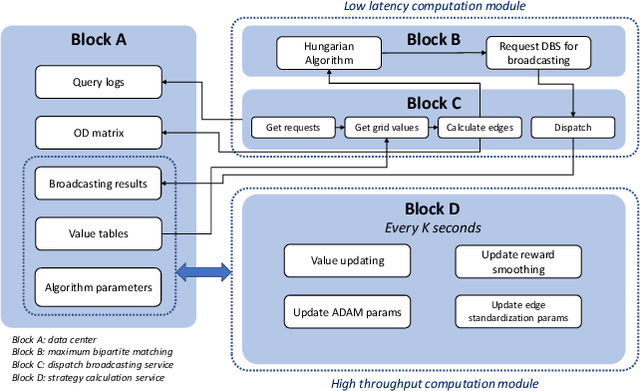
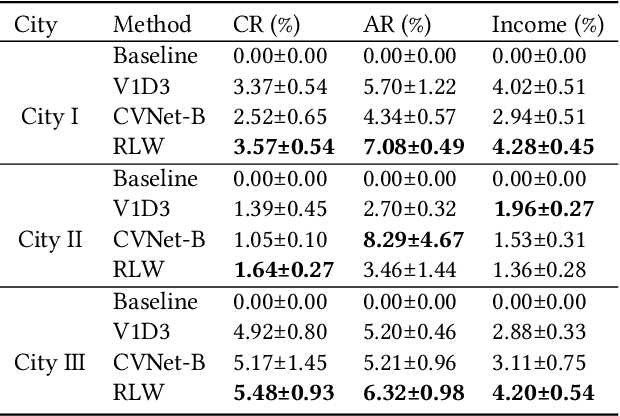
In this study, a real-time dispatching algorithm based on reinforcement learning is proposed and for the first time, is deployed in large scale. Current dispatching methods in ridehailing platforms are dominantly based on myopic or rule-based non-myopic approaches. Reinforcement learning enables dispatching policies that are informed of historical data and able to employ the learned information to optimize returns of expected future trajectories. Previous studies in this field yielded promising results, yet have left room for further improvements in terms of performance gain, self-dependency, transferability, and scalable deployment mechanisms. The present study proposes a standalone RL-based dispatching solution that is equipped with multiple mechanisms to ensure robust and efficient on-policy learning and inference while being adaptable for full-scale deployment. A new form of value updating based on temporal difference is proposed that is more adapted to the inherent uncertainty of the problem. For the driver-order assignment, a customized utility function is proposed that when tuned based on the statistics of the market, results in remarkable performance improvement and interpretability. In addition, for reducing the risk of cancellation after drivers' assignment, an adaptive graph pruning strategy based on the multi-arm bandit problem is introduced. The method is evaluated using offline simulation with real data and yields notable performance improvement. In addition, the algorithm is deployed online in multiple cities under DiDi's operation for A/B testing and is launched in one of the major international markets as the primary mode of dispatch. The deployed algorithm shows over 1.3% improvement in total driver income from A/B testing. In addition, by causal inference analysis, as much as 5.3% improvement in major performance metrics is detected after full-scale deployment.
DualFormer: Local-Global Stratified Transformer for Efficient Video Recognition
Dec 09, 2021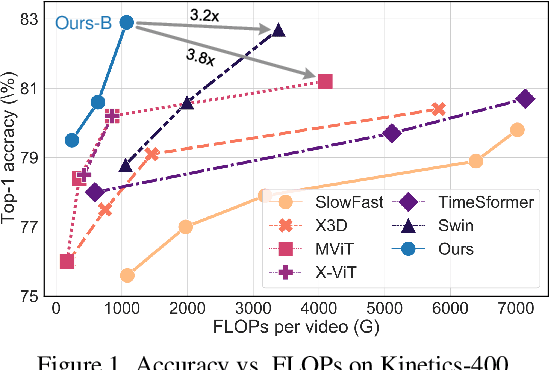
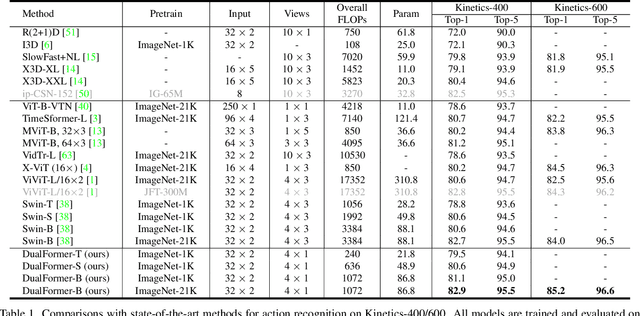
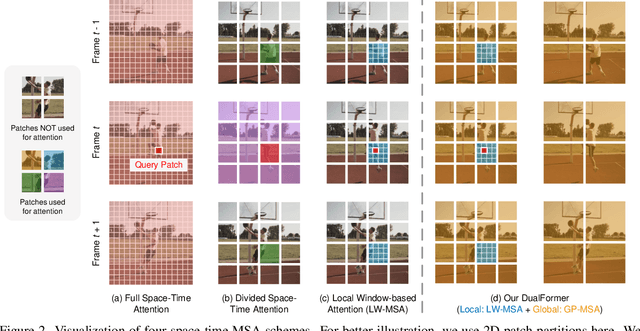
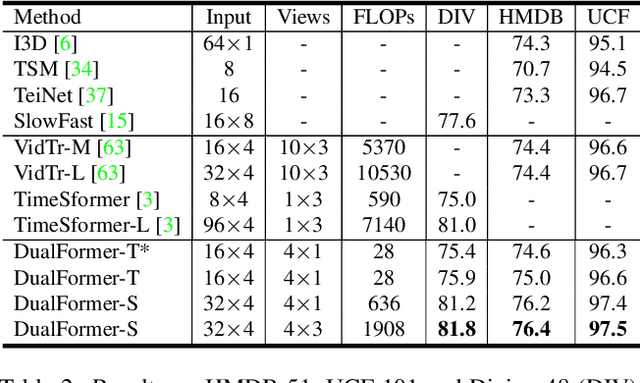
While transformers have shown great potential on video recognition tasks with their strong capability of capturing long-range dependencies, they often suffer high computational costs induced by self-attention operation on the huge number of 3D tokens in a video. In this paper, we propose a new transformer architecture, termed DualFormer, which can effectively and efficiently perform space-time attention for video recognition. Specifically, our DualFormer stratifies the full space-time attention into dual cascaded levels, i.e., to first learn fine-grained local space-time interactions among nearby 3D tokens, followed by the capture of coarse-grained global dependencies between the query token and the coarse-grained global pyramid contexts. Different from existing methods that apply space-time factorization or restrict attention computations within local windows for improving efficiency, our local-global stratified strategy can well capture both short- and long-range spatiotemporal dependencies, and meanwhile greatly reduces the number of keys and values in attention computation to boost efficiency. Experimental results show the superiority of DualFormer on five video benchmarks against existing methods. In particular, DualFormer sets new state-of-the-art 82.9%/85.2% top-1 accuracy on Kinetics-400/600 with around 1000G inference FLOPs which is at least 3.2 times fewer than existing methods with similar performances.
Time Series Alignment with Global Invariances
Feb 10, 2020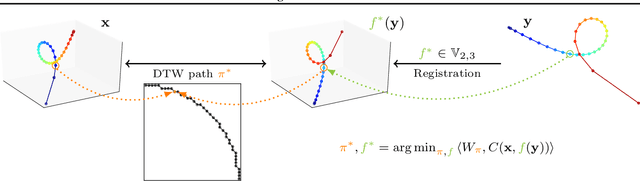

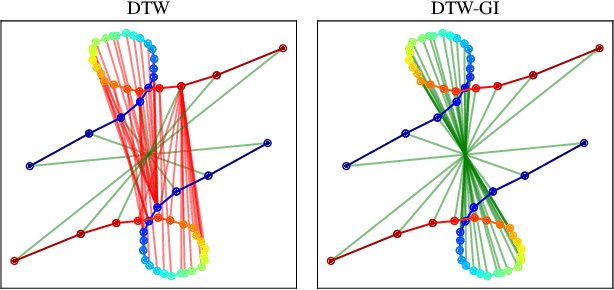
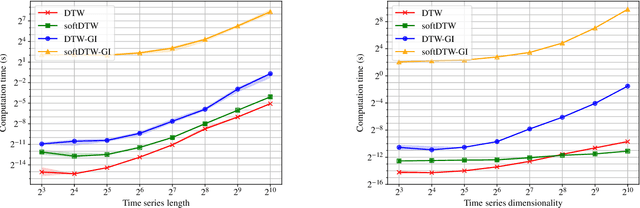
In this work we address the problem of comparing time series while taking into account both feature space transformation and temporal variability. The proposed framework combines a latent global transformation of the feature space with the widely used Dynamic Time Warping (DTW). The latent global transformation captures the feature invariance while the DTW (or its smooth counterpart soft-DTW) deals with the temporal shifts. We cast the problem as a joint optimization over the global transformation and the temporal alignments. The versatility of our framework allows for several variants depending on the invariance class at stake. Among our contributions we define a differentiable loss for time series and present two algorithms for the computation of time series barycenters under our new geometry. We illustrate the interest of our approach on both simulated and real world data.
Meta Reinforcement Learning for Adaptive Control: An Offline Approach
Mar 17, 2022
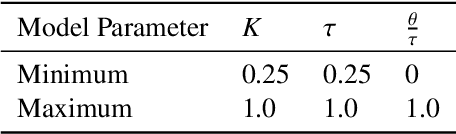
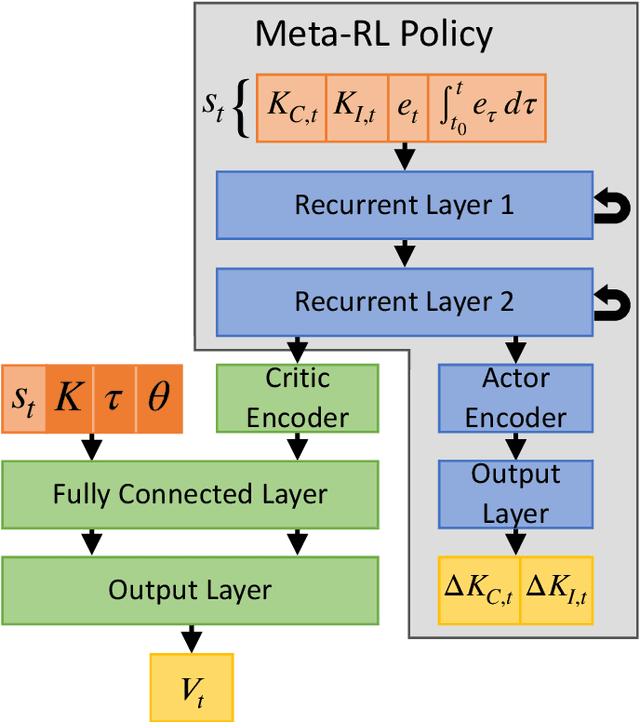
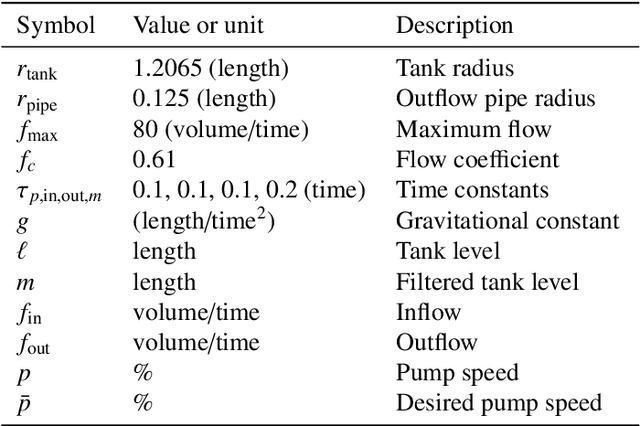
Meta-learning is a branch of machine learning which trains neural network models to synthesize a wide variety of data in order to rapidly solve new problems. In process control, many systems have similar and well-understood dynamics, which suggests it is feasible to create a generalizable controller through meta-learning. In this work, we formulate a meta reinforcement learning (meta-RL) control strategy that takes advantage of known, offline information for training, such as the system gain or time constant, yet efficiently controls novel systems in a completely model-free fashion. Our meta-RL agent has a recurrent structure that accumulates "context" for its current dynamics through a hidden state variable. This end-to-end architecture enables the agent to automatically adapt to changes in the process dynamics. Moreover, the same agent can be deployed on systems with previously unseen nonlinearities and timescales. In tests reported here, the meta-RL agent was trained entirely offline, yet produced excellent results in novel settings. A key design element is the ability to leverage model-based information offline during training, while maintaining a model-free policy structure for interacting with novel environments. To illustrate the approach, we take the actions proposed by the meta-RL agent to be changes to gains of a proportional-integral controller, resulting in a generalized, adaptive, closed-loop tuning strategy. Meta-learning is a promising approach for constructing sample-efficient intelligent controllers.
Deep Graph Convolutional Network and LSTM based approach for predicting drug-target binding affinity
Jan 18, 2022Development of new drugs is an expensive and time-consuming process. Due to the world-wide SARS-CoV-2 outbreak, it is essential that new drugs for SARS-CoV-2 are developed as soon as possible. Drug repurposing techniques can reduce the time span needed to develop new drugs by probing the list of existing FDA-approved drugs and their properties to reuse them for combating the new disease. We propose a novel architecture DeepGLSTM, which is a Graph Convolutional network and LSTM based method that predicts binding affinity values between the FDA-approved drugs and the viral proteins of SARS-CoV-2. Our proposed model has been trained on Davis, KIBA (Kinase Inhibitor Bioactivity), DTC (Drug Target Commons), Metz, ToxCast and STITCH datasets. We use our novel architecture to predict a Combined Score (calculated using Davis and KIBA score) of 2,304 FDA-approved drugs against 5 viral proteins. On the basis of the Combined Score, we prepare a list of the top-18 drugs with the highest binding affinity for 5 viral proteins present in SARS-CoV-2. Subsequently, this list may be used for the creation of new useful drugs.
Backscatter-Aided NOMA V2X Communication under Channel Estimation Errors
Feb 03, 2022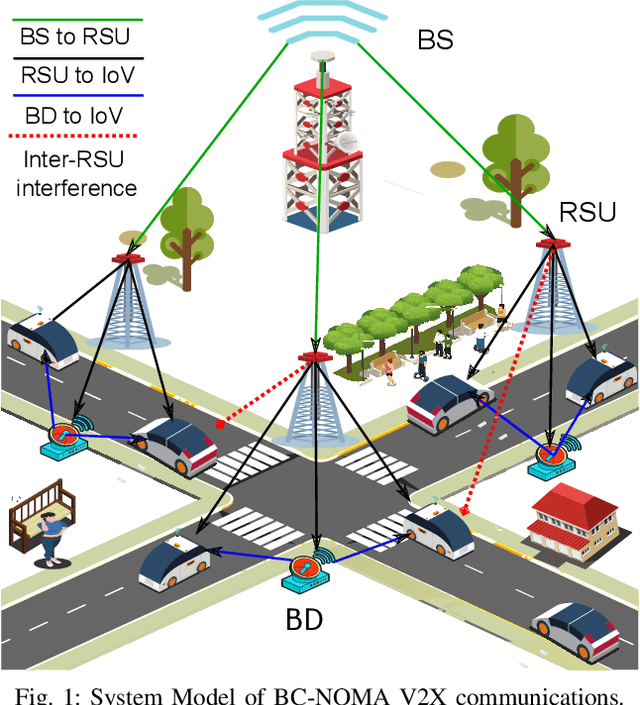
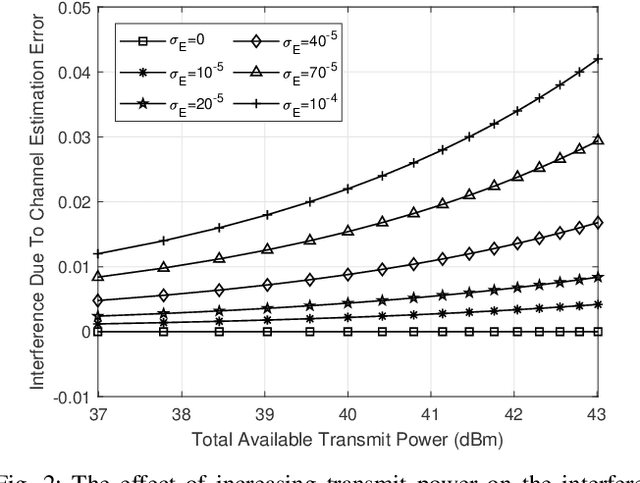
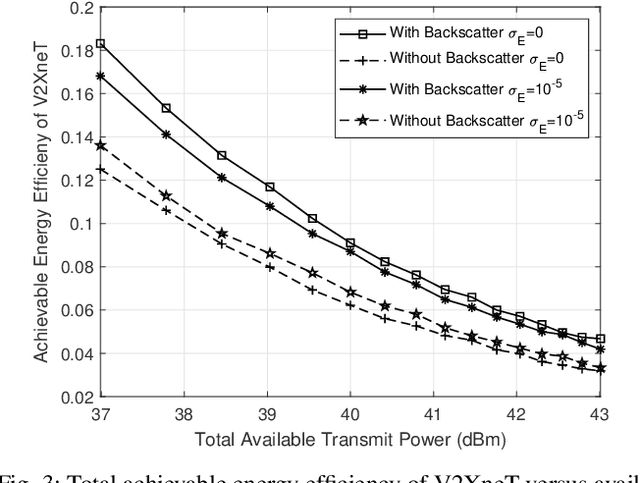
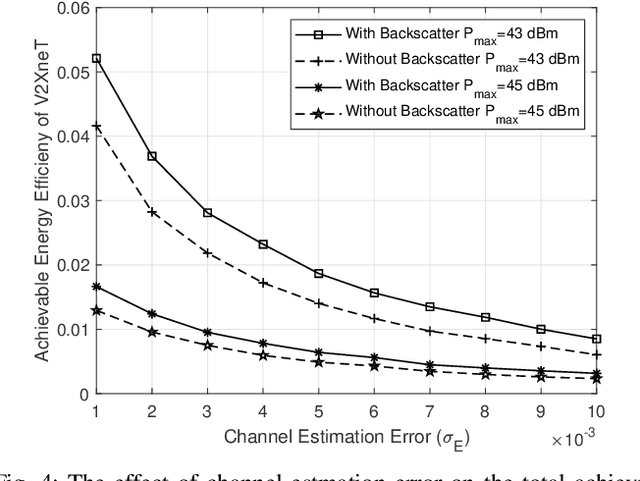
Backscatter communications (BC) has emerged as a promising technology for providing low-powered transmissions in nextG (i.e., beyond 5G) wireless networks. The fundamental idea of BC is the possibility of communications among wireless devices by using the existing ambient radio frequency signals. Non-orthogonal multiple access (NOMA) has recently attracted significant attention due to its high spectral efficiency and massive connectivity. This paper proposes a new optimization framework to minimize total transmit power of BC-NOMA cooperative vehicle-to-everything networks (V2XneT) while ensuring the quality of services. More specifically, the base station (BS) transmits a superimposed signal to its associated roadside units (RSUs) in the first time slot. Then the RSUs transmit the superimposed signal to their serving vehicles in the second time slot exploiting decode and forward protocol. A backscatter device (BD) in the coverage area of RSU also receives the superimposed signal and reflect it towards vehicles by modulating own information. Thus, the objective is to simultaneously optimize the transmit power of BS and RSUs along with reflection coefficient of BDs under perfect and imperfect channel state information. The problem of energy efficiency is formulated as non-convex and coupled on multiple optimization variables which makes it very complex and hard to solve. Therefore, we first transform and decouple the original problem into two sub-problems and then employ iterative sub-gradient method to obtain an efficient solution. Simulation results demonstrate that the proposed BC-NOMA V2XneT provides high energy efficiency than the conventional NOMA V2XneT without BC.
Instance-aware multi-object self-supervision for monocular depth prediction
Mar 02, 2022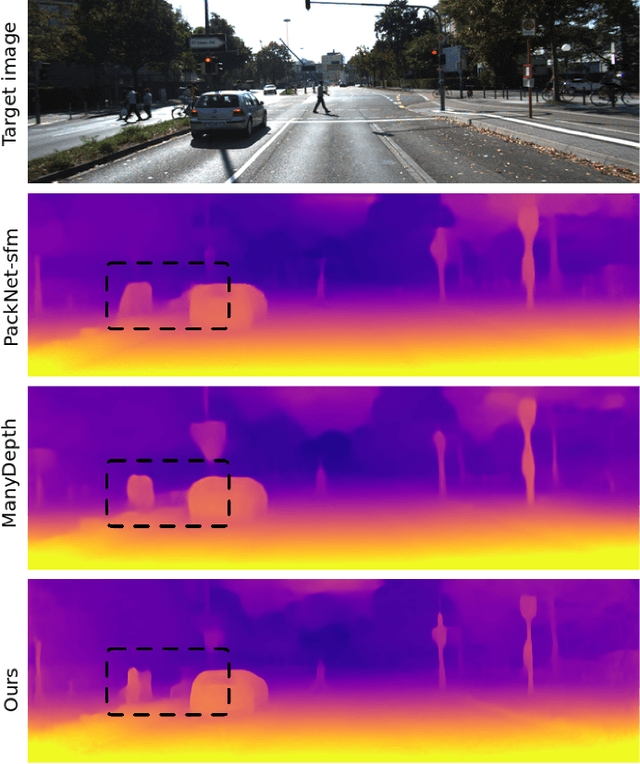
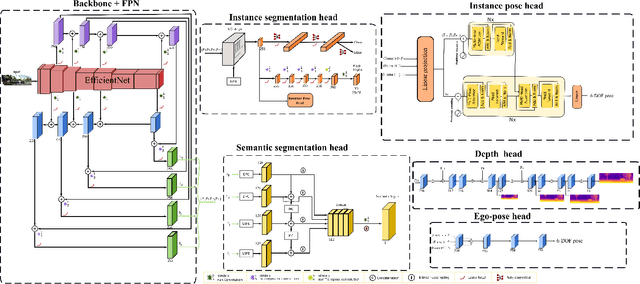
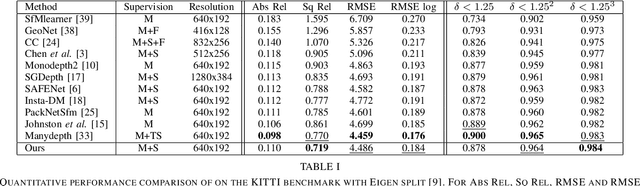
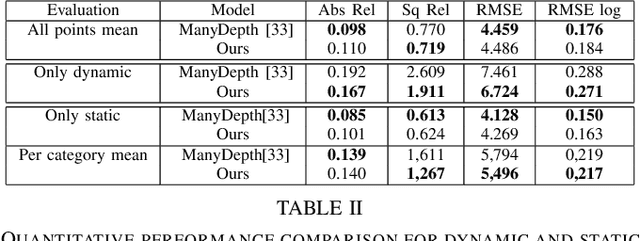
This paper proposes a self-supervised monocular image-to-depth prediction framework that is trained with an end-to-end photometric loss that handles not only 6-DOF camera motion but also 6-DOF moving object instances. Self-supervision is performed by warping the images across a video sequence using depth and scene motion including object instances. One novelty of the proposed method is the use of a multi-head attention of the transformer network that matches moving objects across time and models their interaction and dynamics. This enables accurate and robust pose estimation for each object instance. Most image-to-depth predication frameworks make the assumption of rigid scenes, which largely degrades their performance with respect to dynamic objects. Only a few SOTA papers have accounted for dynamic objects. The proposed method is shown to largely outperform these methods on standard benchmarks and the impact of the dynamic motion on these benchmarks is exposed. Furthermore, the proposed image-to-depth prediction framework is also shown to outperform SOTA video-to-depth prediction frameworks.
Label conditioned segmentation
Mar 17, 2022



Semantic segmentation is an important task in computer vision that is often tackled with convolutional neural networks (CNNs). A CNN learns to produce pixel-level predictions through training on pairs of images and their corresponding ground-truth segmentation labels. For segmentation tasks with multiple classes, the standard approach is to use a network that computes a multi-channel probabilistic segmentation map, with each channel representing one class. In applications where the image grid size (e.g., when it is a 3D volume) and/or the number of labels is relatively large, the standard (baseline) approach can become prohibitively expensive for our computational resources. In this paper, we propose a simple yet effective method to address this challenge. In our approach, the segmentation network produces a single-channel output, while being conditioned on a single class label, which determines the output class of the network. Our method, called label conditioned segmentation (LCS), can be used to segment images with a very large number of classes, which might be infeasible for the baseline approach. We also demonstrate in the experiments that label conditioning can improve the accuracy of a given backbone architecture, likely, thanks to its parameter efficiency. Finally, as we show in our results, an LCS model can produce previously unseen fine-grained labels during inference time, when only coarse labels were available during training. We provide all of our code here: https://github.com/tym002/Label-conditioned-segmentation
Deep Learning for Underwater Fish-Habitat Monitoring: A Survey
Mar 14, 2022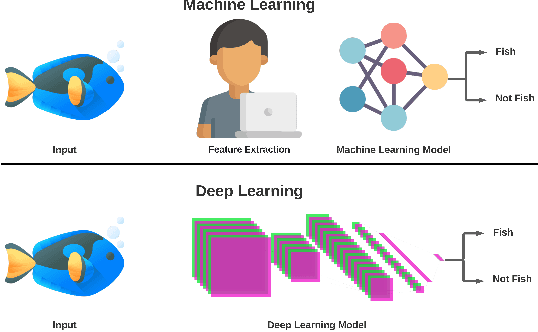
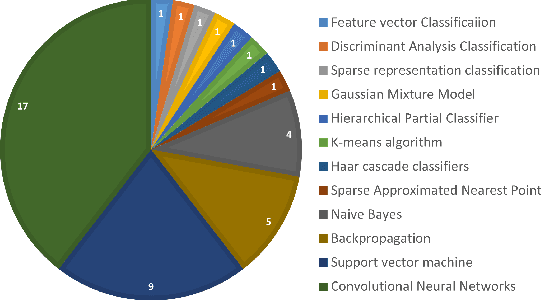
Marine scientists use remote underwater video recording to survey fish species in their natural habitats. This helps them understand and predict how fish respond to climate change, habitat degradation, and fishing pressure. This information is essential for developing sustainable fisheries for human consumption, and for preserving the environment. However, the enormous volume of collected videos makes extracting useful information a daunting and time-consuming task for a human. A promising method to address this problem is the cutting-edge Deep Learning (DL) technology.DL can help marine scientists parse large volumes of video promptly and efficiently, unlocking niche information that cannot be obtained using conventional manual monitoring methods. In this paper, we provide an overview of the key concepts of DL, while presenting a survey of literature on fish habitat monitoring with a focus on underwater fish classification. We also discuss the main challenges faced when developing DL for underwater image processing and propose approaches to address them. Finally, we provide insights into the marine habitat monitoring research domain and shed light on what the future of DL for underwater image processing may hold. This paper aims to inform a wide range of readers from marine scientists who would like to apply DL in their research to computer scientists who would like to survey state-of-the-art DL-based underwater fish habitat monitoring literature.