 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time-Variant Variational Transfer for Value Functions
Jun 18, 2020
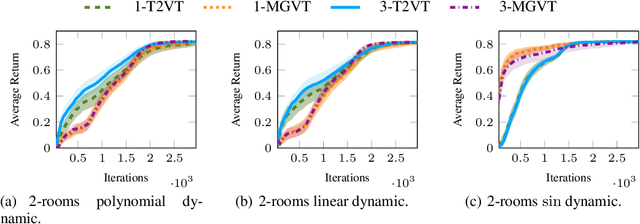
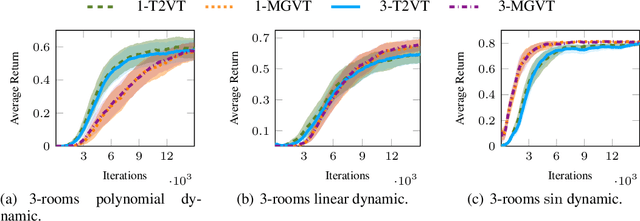
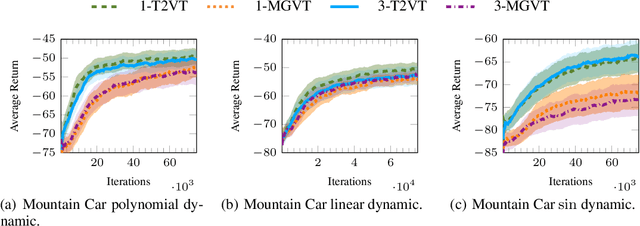
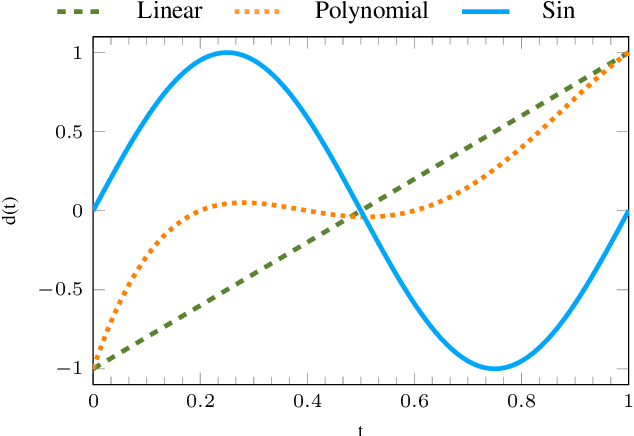
In most of the transfer learning approaches to reinforcement learning (RL) the distribution over the tasks is assumed to be stationary. Therefore, the target and source tasks are i.i.d. samples of the same distribution. In the context of this work, we consider the problem of transferring value functions through a variational method when the distribution that generates the tasks is time-variant, proposing a solution that leverages this temporal structure inherent in the task generating process. Furthermore, by means of a finite-sample analysis, the previously mentioned solution is theoretically compared to its time-invariant version. Finally, we will provide an experimental evaluation of the proposed technique with three distinct temporal dynamics in three different RL environments.
InsertionNet 2.0: Minimal Contact Multi-Step Insertion Using Multimodal Multiview Sensory Input
Mar 02, 2022
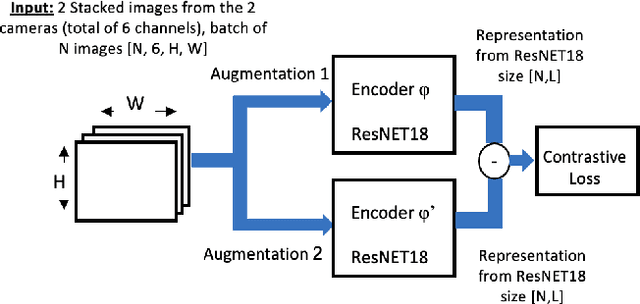
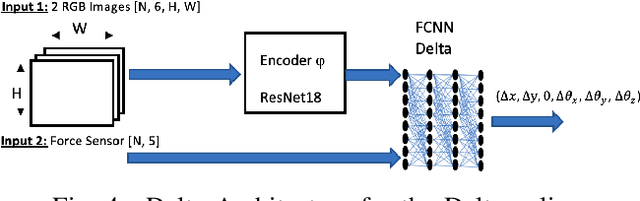
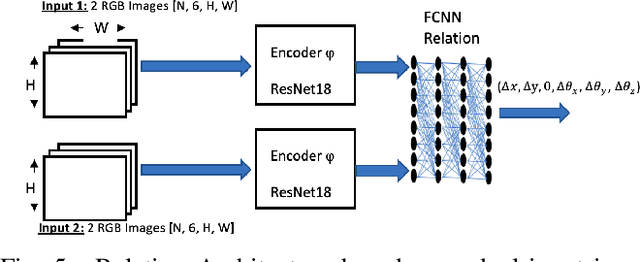
We address the problem of devising the means for a robot to rapidly and safely learn insertion skills with just a few human interventions and without hand-crafted rewards or demonstrations. Our InsertionNet version 2.0 provides an improved technique to robustly cope with a wide range of use-cases featuring different shapes, colors, initial poses, etc. In particular, we present a regression-based method based on multimodal input from stereo perception and force, augmented with contrastive learning for the efficient learning of valuable features. In addition, we introduce a one-shot learning technique for insertion, which relies on a relation network scheme to better exploit the collected data and to support multi-step insertion tasks. Our method improves on the results obtained with the original InsertionNet, achieving an almost perfect score (above 97.5$\%$ on 200 trials) in 16 real-life insertion tasks while minimizing the execution time and contact during insertion. We further demonstrate our method's ability to tackle a real-life 3-step insertion task and perfectly solve an unseen insertion task without learning.
Continuously Learning to Detect People on the Fly: A Bio-inspired Visual System for Drones
Feb 20, 2022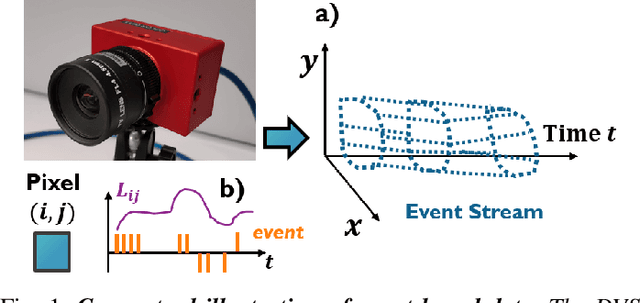
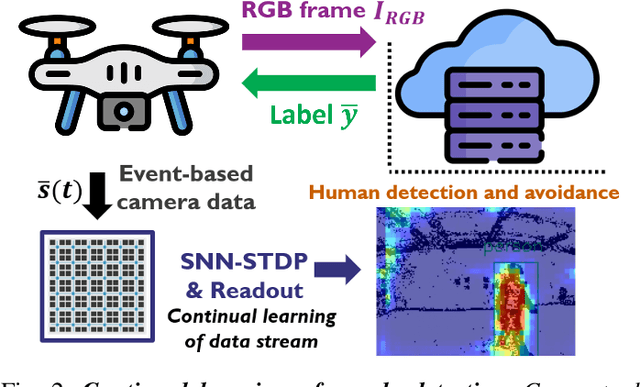
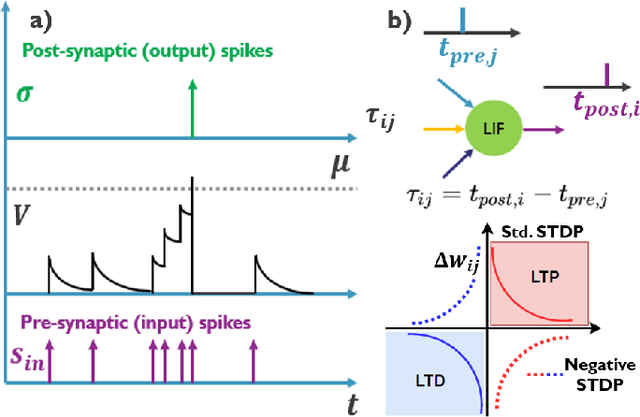
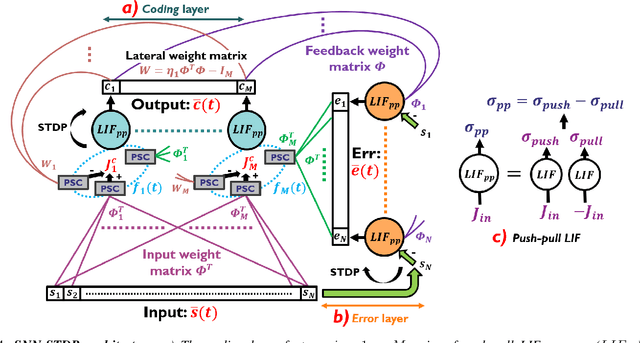
This paper demonstrates for the first time that a biologically-plausible spiking neural network (SNN) equipped with Spike-Timing-Dependent Plasticity (STDP) can continuously learn to detect walking people on the fly using retina-inspired, event-based cameras. Our pipeline works as follows. First, a short sequence of event data ($<2$ minutes), capturing a walking human by a flying drone, is forwarded to a convolutional SNNSTDP system which also receives teacher spiking signals from a readout (forming a semi-supervised system). Then, STDP adaptation is stopped and the learned system is assessed on testing sequences. We conduct several experiments to study the effect of key parameters in our system and to compare it against conventionally-trained CNNs. We show that our system reaches a higher peak $F_1$ score (+19%) compared to CNNs with event-based camera frames, while enabling on-line adaptation.
HAR-GCNN: Deep Graph CNNs for Human Activity Recognition From Highly Unlabeled Mobile Sensor Data
Mar 07, 2022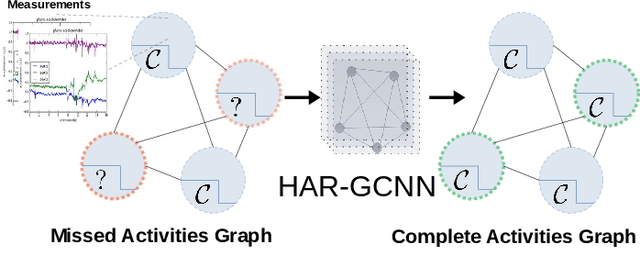
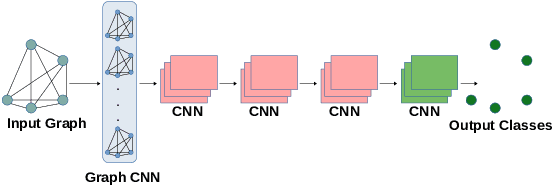
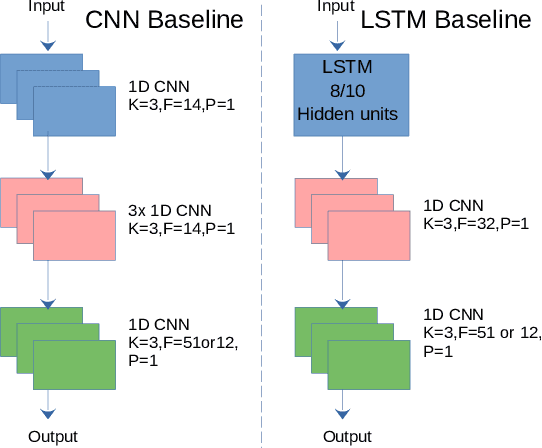
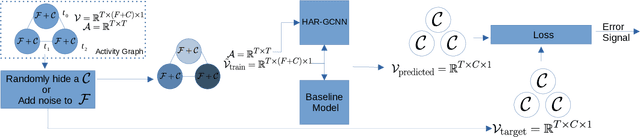
The problem of human activity recognition from mobile sensor data applies to multiple domains, such as health monitoring, personal fitness, daily life logging, and senior care. A critical challenge for training human activity recognition models is data quality. Acquiring balanced datasets containing accurate activity labels requires humans to correctly annotate and potentially interfere with the subjects' normal activities in real-time. Despite the likelihood of incorrect annotation or lack thereof, there is often an inherent chronology to human behavior. For example, we take a shower after we exercise. This implicit chronology can be used to learn unknown labels and classify future activities. In this work, we propose HAR-GCCN, a deep graph CNN model that leverages the correlation between chronologically adjacent sensor measurements to predict the correct labels for unclassified activities that have at least one activity label. We propose a new training strategy enforcing that the model predicts the missing activity labels by leveraging the known ones. HAR-GCCN shows superior performance relative to previously used baseline methods, improving classification accuracy by about 25% and up to 68% on different datasets. Code is available at \url{https://github.com/abduallahmohamed/HAR-GCNN}.
DPCCN: Densely-Connected Pyramid Complex Convolutional Network for Robust Speech Separation And Extraction
Dec 27, 2021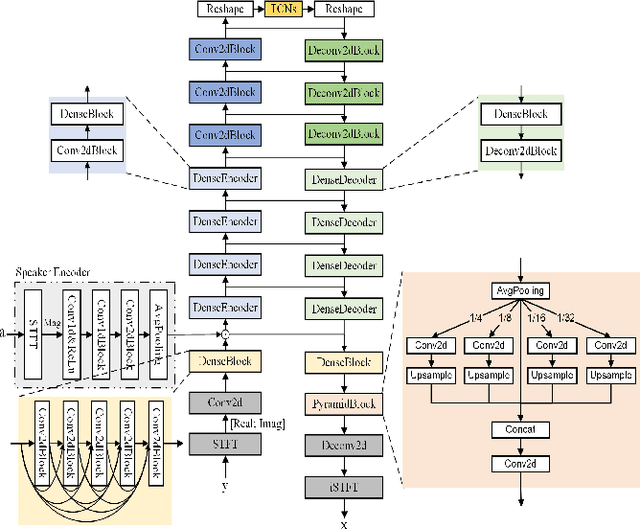
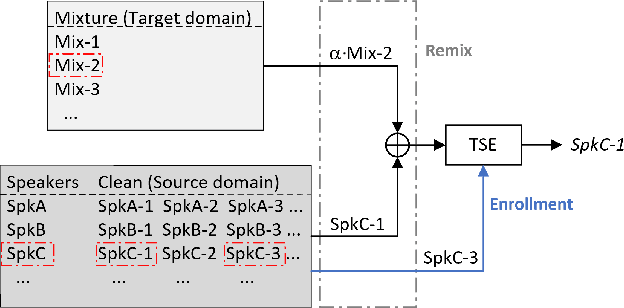

In recent years, a number of time-domain speech separation methods have been proposed. However, most of them are very sensitive to the environments and wide domain coverage tasks. In this paper, from the time-frequency domain perspective, we propose a densely-connected pyramid complex convolutional network, termed DPCCN, to improve the robustness of speech separation under complicated conditions. Furthermore, we generalize the DPCCN to target speech extraction (TSE) by integrating a new specially designed speaker encoder. Moreover, we also investigate the robustness of DPCCN to unsupervised cross-domain TSE tasks. A Mixture-Remix approach is proposed to adapt the target domain acoustic characteristics for fine-tuning the source model. We evaluate the proposed methods not only under noisy and reverberant in-domain condition, but also in clean but cross-domain conditions. Results show that for both speech separation and extraction, the DPCCN-based systems achieve significantly better performance and robustness than the currently dominating time-domain methods, especially for the cross-domain tasks. Particularly, we find that the Mixture-Remix fine-tuning with DPCCN significantly outperforms the TD-SpeakerBeam for unsupervised cross-domain TSE, with around 3.5 dB performance improvement on target domain test set, without any source domain performance degradation.
Real-time Forecast Models for TBM Load Parameters Based on Machine Learning Methods
Apr 12, 2021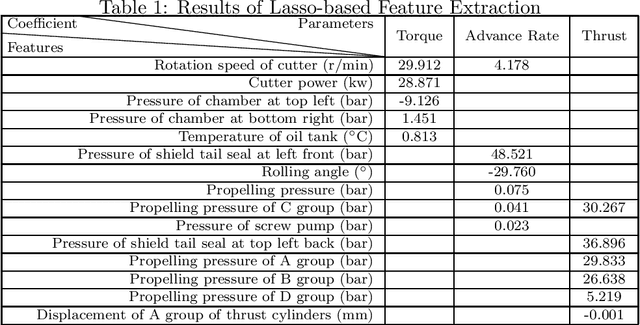
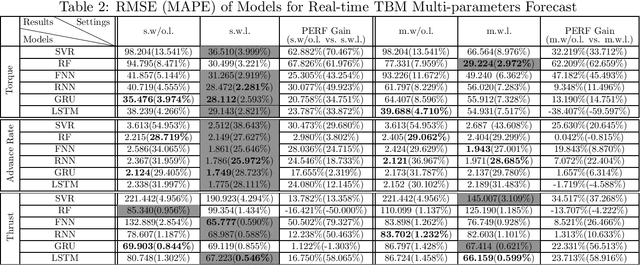
Because of the fast advance rate and the improved personnel safety, tunnel boring machines (TBMs) have been widely used in a variety of tunnel construction projects. The dynamic modeling of TBM load parameters (including torque, advance rate and thrust) plays an essential part in the design, safe operation and fault prognostics of this complex engineering system. In this paper, based on in-situ TBM operational data, we use the machine-learning (ML) methods to build the real-time forecast models for TBM load parameters, which can instantaneously provide the future values of the TBM load parameters as long as the current data are collected. To decrease the model complexity and improve the generalization, we also apply the least absolute shrinkage and selection (Lasso) method to extract the essential features of the forecast task. The experimental results show that the forecast models based on deep-learning methods, {\it e.g.}, recurrent neural network and its variants, outperform the ones based on the shallow-learning methods, {\it e.g.}, support vector regression and random forest. Moreover, the Lasso-based feature extraction significantly improves the performance of the resultant models.
NetRCA: An Effective Network Fault Cause Localization Algorithm
Feb 23, 2022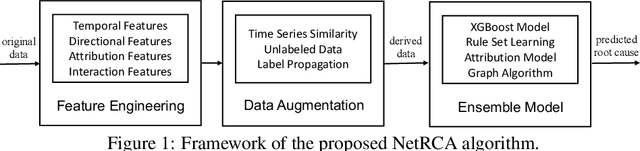
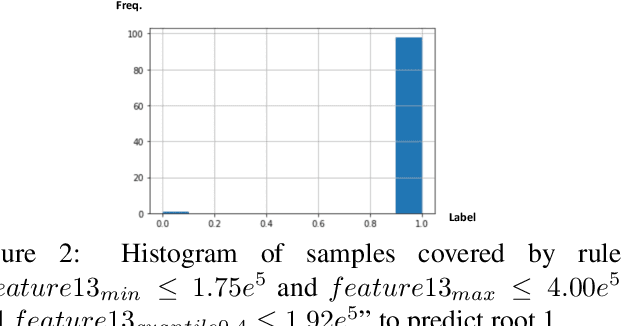
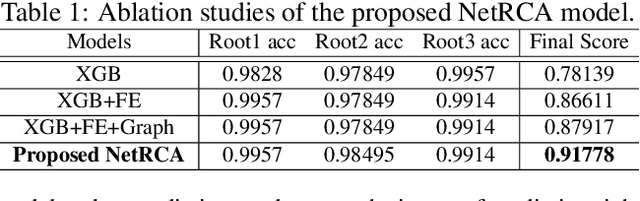
Localizing the root cause of network faults is crucial to network operation and maintenance. However, due to the complicated network architectures and wireless environments, as well as limited labeled data, accurately localizing the true root cause is challenging. In this paper, we propose a novel algorithm named NetRCA to deal with this problem. Firstly, we extract effective derived features from the original raw data by considering temporal, directional, attribution, and interaction characteristics. Secondly, we adopt multivariate time series similarity and label propagation to generate new training data from both labeled and unlabeled data to overcome the lack of labeled samples. Thirdly, we design an ensemble model which combines XGBoost, rule set learning, attribution model, and graph algorithm, to fully utilize all data information and enhance performance. Finally, experiments and analysis are conducted on the real-world dataset from ICASSP 2022 AIOps Challenge to demonstrate the superiority and effectiveness of our approach.
Automatic lane change scenario extraction and generation of scenarios in OpenX format from real-world data
Mar 14, 2022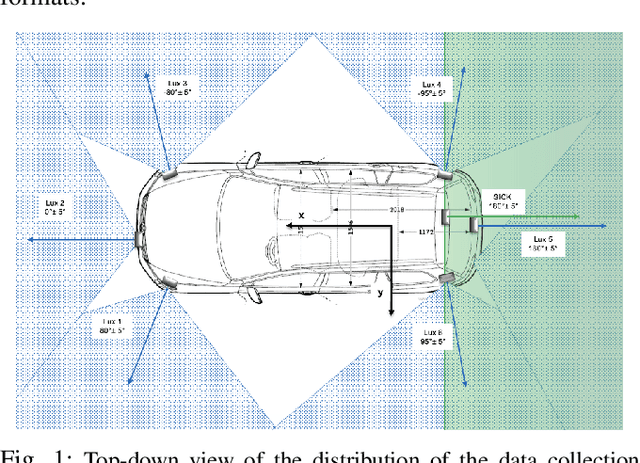
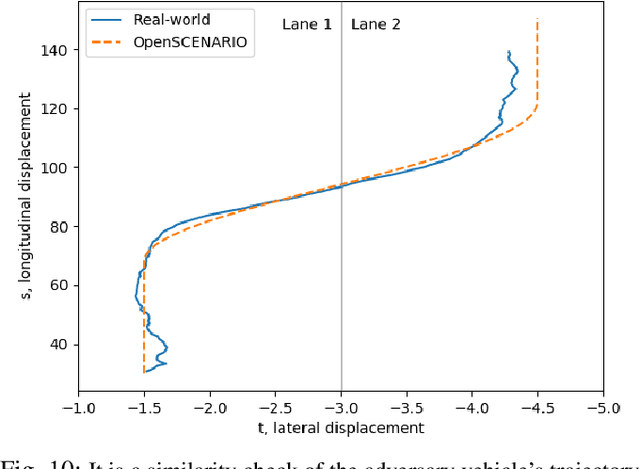
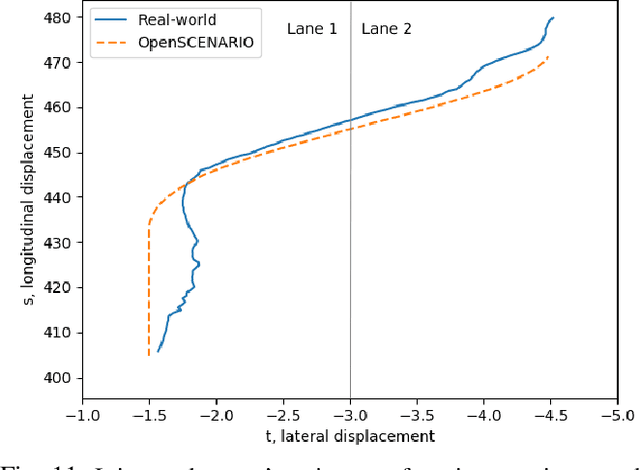
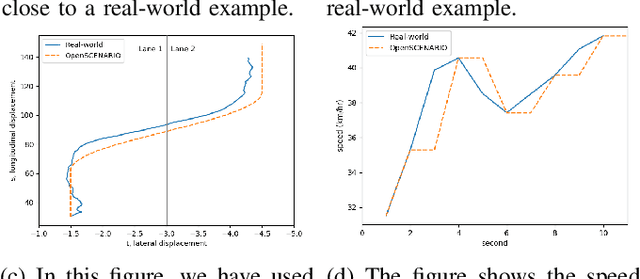
Autonomous Vehicles (AV)'s wide-scale deployment appears imminent despite many safety challenges yet to be resolved. The modern autonomous vehicles will undoubtedly include machine learning and probabilistic techniques that add significant complexity to the traditional verification and validation methods. Road testing is essential before the deployment, but scenarios are repeatable, and it's hard to collect challenging events. Exploring numerous, diverse and crucial scenarios is a time-consuming and expensive approach. The research community and industry have widely accepted scenario-based testing in the last few years. As it is focused directly on the relevant critical road situations, it can reduce the effort required in testing. The scenario-based testing in simulation requires the realistic behaviour of the traffic participants to assess the System Under Test (SUT). It is essential to capture the scenarios from the real world to encode the behaviour of actual traffic participants. This paper proposes a novel scenario extraction method to capture the lane change scenarios using point-cloud data and object tracking information. This method enables fully automatic scenario extraction compared to similar approaches in this area. The generated scenarios are represented in OpenX format to reuse them in the SUT evaluation easily. The motivation of this framework is to build a validation dataset to generate many critical concrete scenarios. The code is available online at https://github.com/dkarunakaran/scenario_extraction_framework.
Softmax Policy Gradient Methods Can Take Exponential Time to Converge
Feb 22, 2021
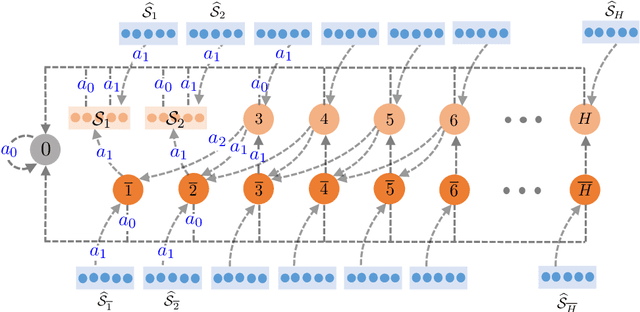
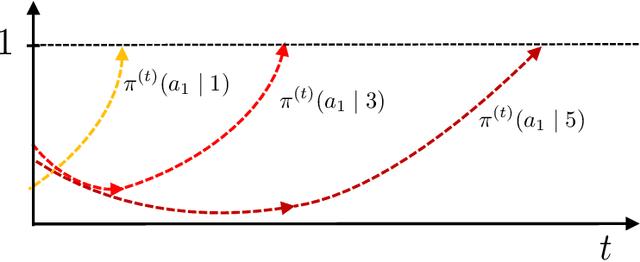
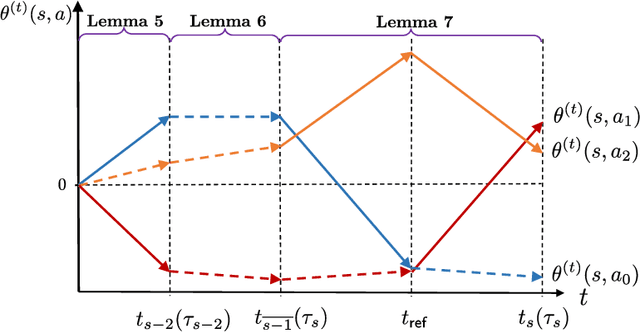
The softmax policy gradient (PG) method, which performs gradient ascent under softmax policy parameterization, is arguably one of the de facto implementations of policy optimization in modern reinforcement learning. For $\gamma$-discounted infinite-horizon tabular Markov decision processes (MDPs), remarkable progress has recently been achieved towards establishing global convergence of softmax PG methods in finding a near-optimal policy. However, prior results fall short of delineating clear dependencies of convergence rates on salient parameters such as the cardinality of the state space $\mathcal{S}$ and the effective horizon $\frac{1}{1-\gamma}$, both of which could be excessively large. In this paper, we deliver a pessimistic message regarding the iteration complexity of softmax PG methods, despite assuming access to exact gradient computation. Specifically, we demonstrate that softmax PG methods can take exponential time -- in terms of $|\mathcal{S}|$ and $\frac{1}{1-\gamma}$ -- to converge, even in the presence of a benign policy initialization and an initial state distribution amenable to exploration. This is accomplished by characterizing the algorithmic dynamics over a carefully-constructed MDP containing only three actions. Our exponential lower bound hints at the necessity of carefully adjusting update rules or enforcing proper regularization in accelerating PG methods.
Image-based material analysis of ancient historical documents
Mar 02, 2022



Researchers continually perform corroborative tests to classify ancient historical documents based on the physical materials of their writing surfaces. However, these tests, often performed on-site, requires actual access to the manuscript objects. The procedures involve a considerable amount of time and cost, and can damage the manuscripts. Developing a technique to classify such documents using only digital images can be very useful and efficient. In order to tackle this problem, this study uses images of a famous historical collection, the Dead Sea Scrolls, to propose a novel method to classify the materials of the manuscripts. The proposed classifier uses the two-dimensional Fourier Transform to identify patterns within the manuscript surfaces. Combining a binary classification system employing the transform with a majority voting process is shown to be effective for this classification task. This pilot study shows a successful classification percentage of up to 97% for a confined amount of manuscripts produced from either parchment or papyrus material. Feature vectors based on Fourier-space grid representation outperformed a concentric Fourier-space format.