 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Evaluating State of the Art, Forecasting Ensembles- and Meta-learning Strategies for Model Fusion
Mar 07, 2022
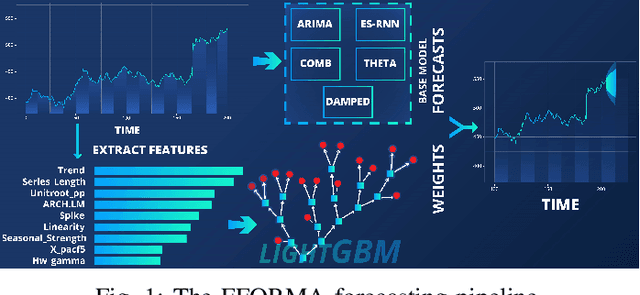
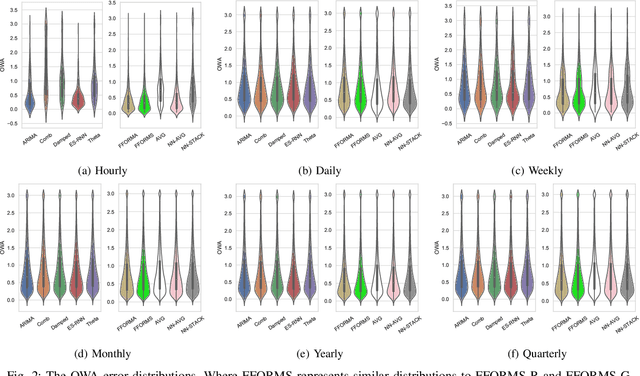
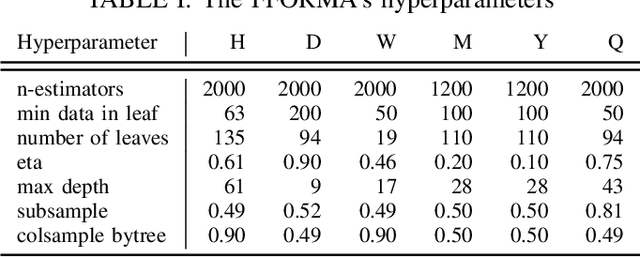
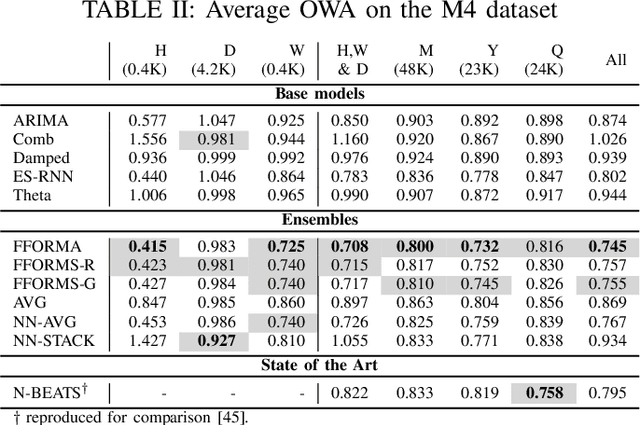
Techniques of hybridisation and ensemble learning are popular model fusion techniques for improving the predictive power of forecasting methods. With limited research that instigates combining these two promising approaches, this paper focuses on the utility of the Exponential-Smoothing-Recurrent Neural Network (ES-RNN) in the pool of base models for different ensembles. We compare against some state of the art ensembling techniques and arithmetic model averaging as a benchmark. We experiment with the M4 forecasting data set of 100,000 time-series, and the results show that the Feature-based Forecast Model Averaging (FFORMA), on average, is the best technique for late data fusion with the ES-RNN. However, considering the M4's Daily subset of data, stacking was the only successful ensemble at dealing with the case where all base model performances are similar. Our experimental results indicate that we attain state of the art forecasting results compared to N-BEATS as a benchmark. We conclude that model averaging is a more robust ensemble than model selection and stacking strategies. Further, the results show that gradient boosting is superior for implementing ensemble learning strategies.
Cross-Layer Approximation For Printed Machine Learning Circuits
Mar 11, 2022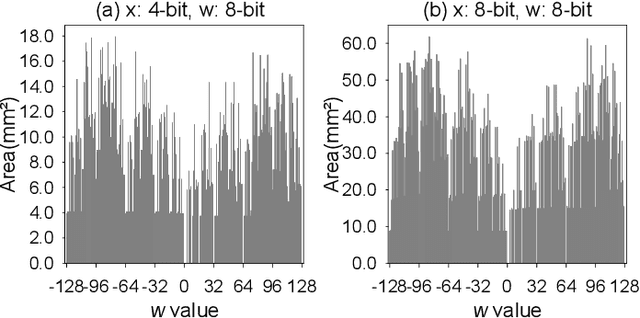
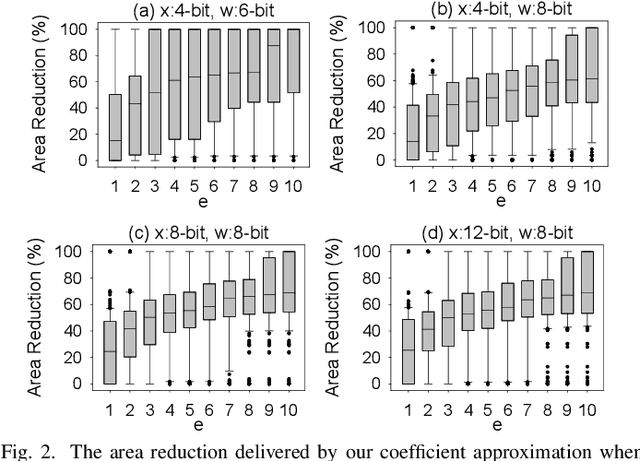
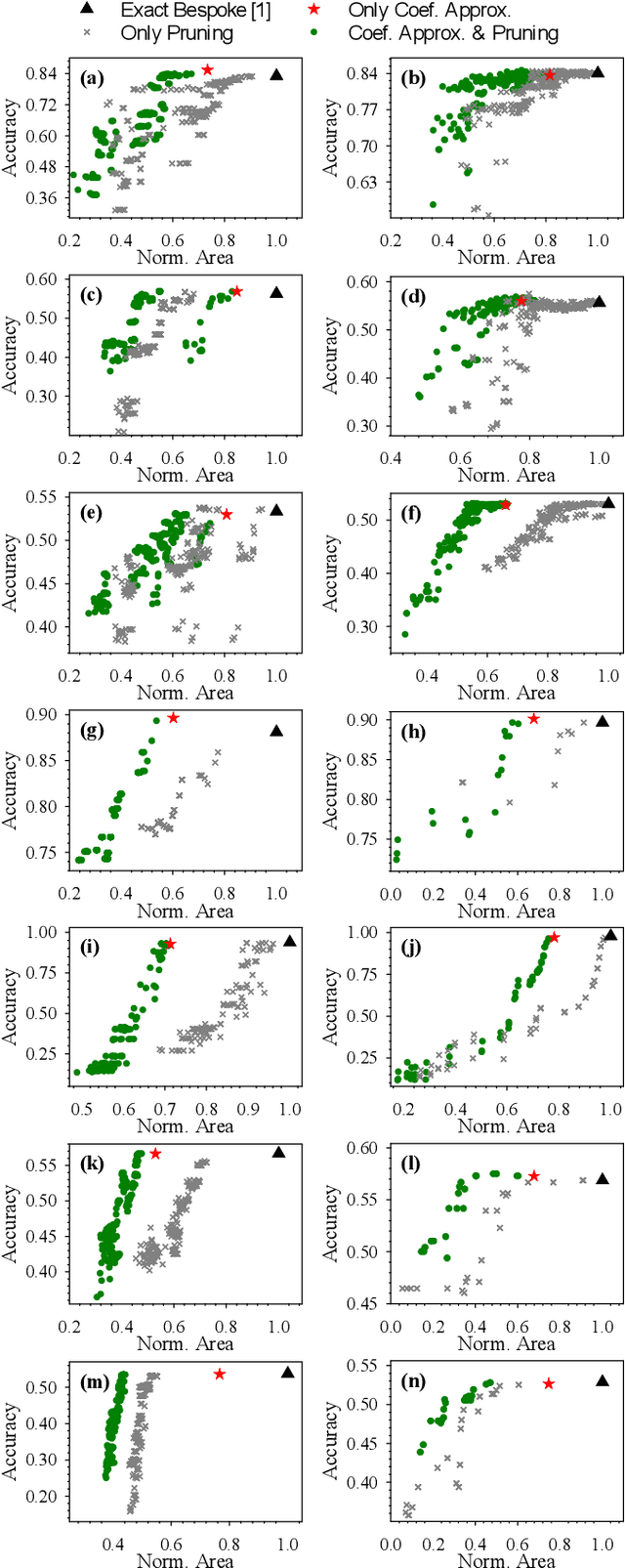
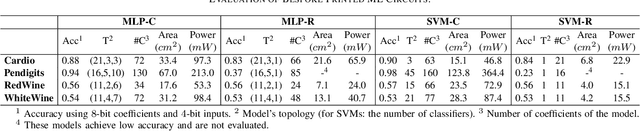
Printed electronics (PE) feature low non-recurring engineering costs and low per unit-area fabrication costs, enabling thus extremely low-cost and on-demand hardware. Such low-cost fabrication allows for high customization that would be infeasible in silicon, and bespoke architectures prevail to improve the efficiency of emerging PE machine learning (ML) applications. However, even with bespoke architectures, the large feature sizes in PE constraint the complexity of the ML models that can be implemented. In this work, we bring together, for the first time, approximate computing and PE design targeting to enable complex ML models, such as Multi-Layer Perceptrons (MLPs) and Support Vector Machines (SVMs), in PE. To this end, we propose and implement a cross-layer approximation, tailored for bespoke ML architectures. At the algorithmic level we apply a hardware-driven coefficient approximation of the ML model and at the circuit level we apply a netlist pruning through a full search exploration. In our extensive experimental evaluation we consider 14 MLPs and SVMs and evaluate more than 4300 approximate and exact designs. Our results demonstrate that our cross approximation delivers Pareto optimal designs that, compared to the state-of-the-art exact designs, feature 47% and 44% average area and power reduction, respectively, and less than 1% accuracy loss.
Benchmarking and Interpreting End-to-end Learning of MIMO and Multi-User Communication
Mar 15, 2022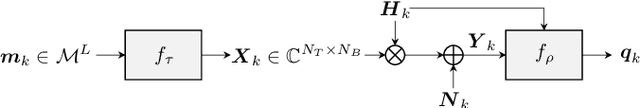
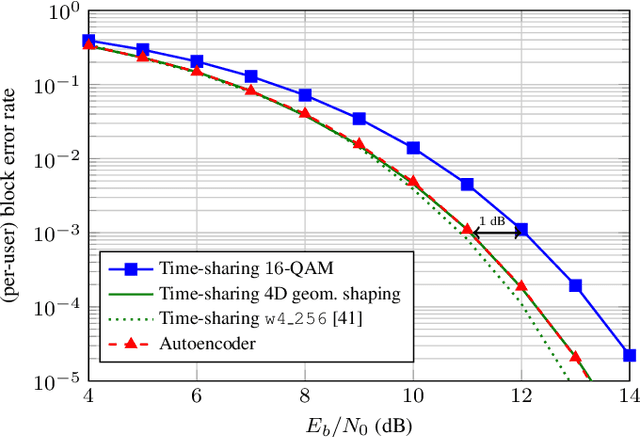
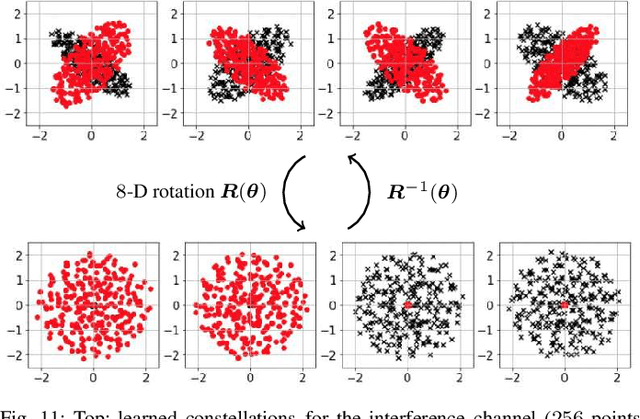
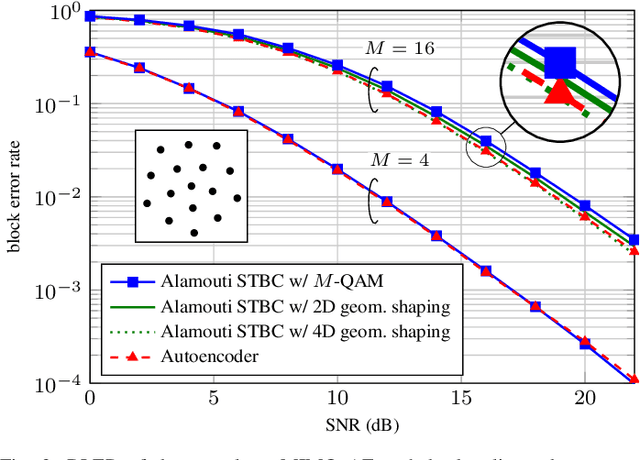
End-to-end autoencoder (AE) learning has the potential of exceeding the performance of human-engineered transceivers and encoding schemes, without a priori knowledge of communication-theoretic principles. In this work, we aim to understand to what extent and for which scenarios this claim holds true when comparing with fair benchmarks. Our particular focus is on memoryless multiple-input multiple-output (MIMO) and multi-user (MU) systems. Four case studies are considered: two point-to-point (closed-loop and open-loop MIMO) and two MU scenarios (MIMO broadcast and interference channels). For the point-to-point scenarios, we explain some of the performance gains observed in prior work through the selection of improved baseline schemes that include geometric shaping as well as bit and power allocation. For the MIMO broadcast channel, we demonstrate the feasibility of a novel AE method with centralized learning and decentralized execution. Interestingly, the learned scheme performs close to nonlinear vector-perturbation precoding and significantly outperforms conventional zero-forcing. Lastly, we highlight potential pitfalls when interpreting learned communication schemes. In particular, we show that the AE for the considered interference channel learns to avoid interference, albeit in a rotated reference frame. After de-rotating the learned signal constellation of each user, the resulting scheme corresponds to conventional time sharing with geometric shaping.
HCIL: Hierarchical Class Incremental Learning for Longline Fishing Visual Monitoring
Feb 25, 2022
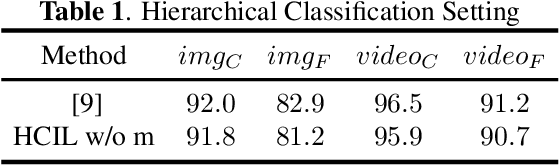
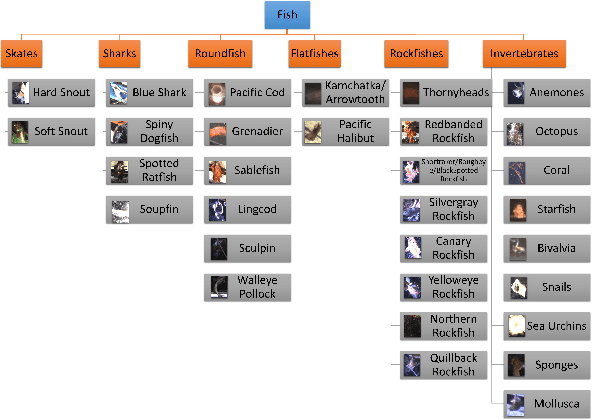
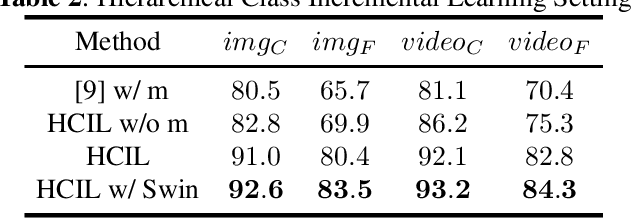
The goal of electronic monitoring of longline fishing is to visually monitor the fish catching activities on fishing vessels based on cameras, either for regulatory compliance or catch counting. The previous hierarchical classification method demonstrates efficient fish species identification of catches from longline fishing, where fishes are under severe deformation and self-occlusion during the catching process. Although the hierarchical classification mitigates the laborious efforts of human reviews by providing confidence scores in different hierarchical levels, its performance drops dramatically under the class incremental learning (CIL) scenario. A CIL system should be able to learn about more and more classes over time from a stream of data, i.e., only the training data for a small number of classes have to be present at the beginning and new classes can be added progressively. In this work, we introduce a Hierarchical Class Incremental Learning (HCIL) model, which significantly improves the state-of-the-art hierarchical classification methods under the CIL scenario.
Risk Bounds of Multi-Pass SGD for Least Squares in the Interpolation Regime
Mar 07, 2022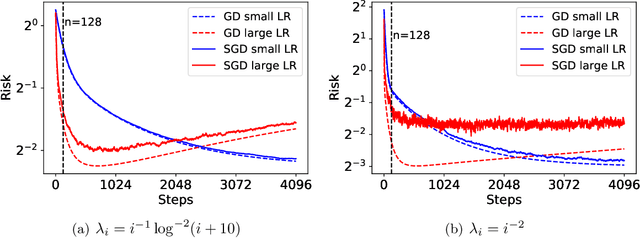
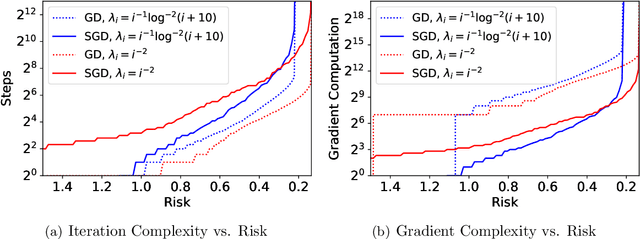
Stochastic gradient descent (SGD) has achieved great success due to its superior performance in both optimization and generalization. Most of existing generalization analyses are made for single-pass SGD, which is a less practical variant compared to the commonly-used multi-pass SGD. Besides, theoretical analyses for multi-pass SGD often concern a worst-case instance in a class of problems, which may be pessimistic to explain the superior generalization ability for some particular problem instance. The goal of this paper is to sharply characterize the generalization of multi-pass SGD, by developing an instance-dependent excess risk bound for least squares in the interpolation regime, which is expressed as a function of the iteration number, stepsize, and data covariance. We show that the excess risk of SGD can be exactly decomposed into the excess risk of GD and a positive fluctuation error, suggesting that SGD always performs worse, instance-wisely, than GD, in generalization. On the other hand, we show that although SGD needs more iterations than GD to achieve the same level of excess risk, it saves the number of stochastic gradient evaluations, and therefore is preferable in terms of computational time.
Rapid TAURUS for Relaxation-Based Color Magnetic Particle Imaging
Dec 09, 2021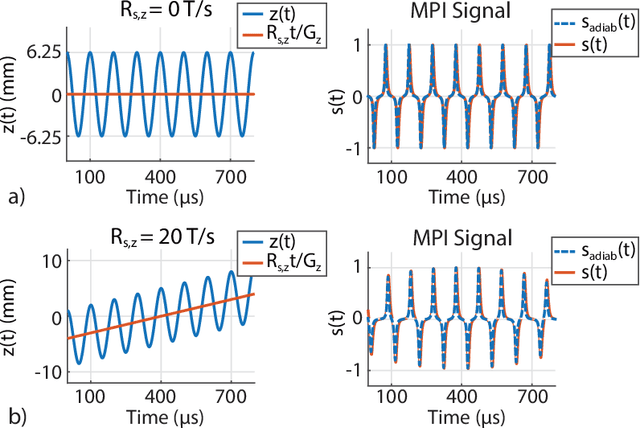
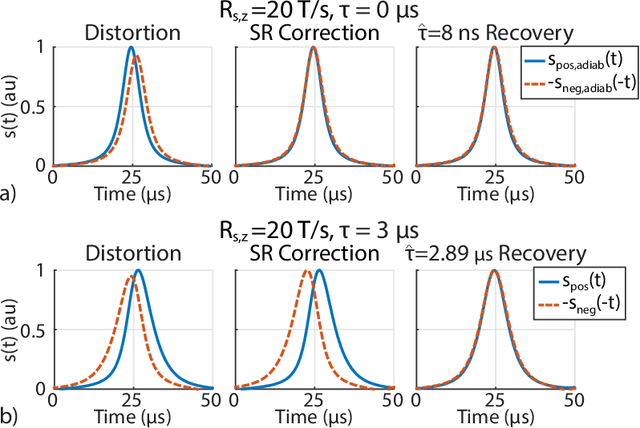
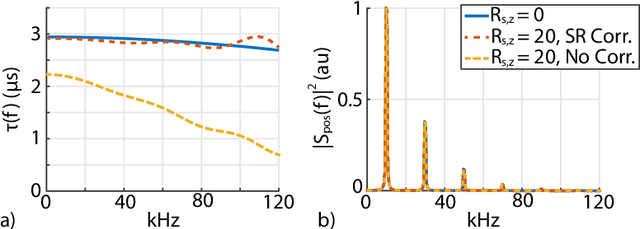
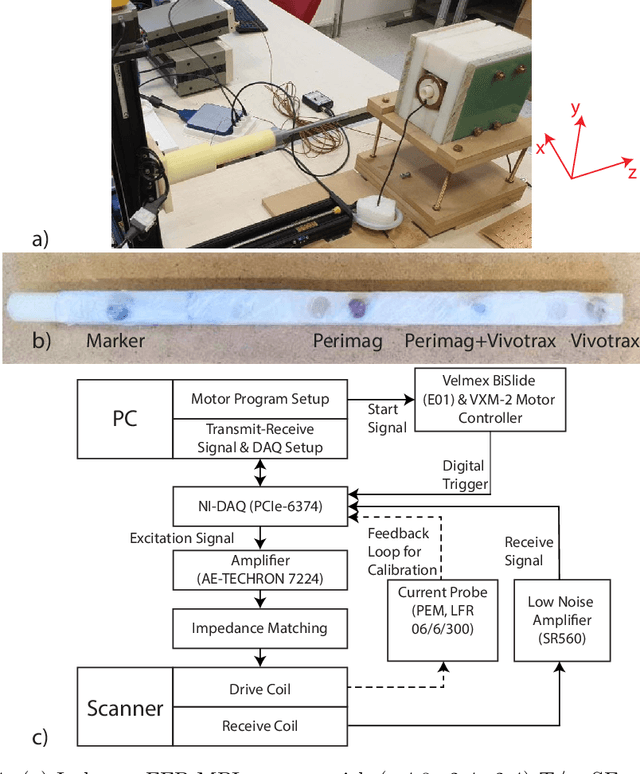
Magnetic particle imaging (MPI) is a rapidly developing medical imaging modality that exploits the non-linear response of magnetic nanoparticles (MNPs). Color MPI widens the functionality of MPI, empowering it with the capability to distinguish different MNPs and/or MNP environments. The system function approach for color MPI relies on extensive calibrations that capture the differences in the harmonic responses of the MNPs. An alternative calibration-free x-space-based method called TAURUS estimates a map of the relaxation time constant, by recovering the underlying mirror symmetry in the MPI signal. However, TAURUS requires a back and forth scanning of a given region, restricting its usage to slow trajectories with constant or piecewise constant focus fields (FFs). In this work, we propose a novel technique to increase the performance of TAURUS and enable $\tau$ map estimation for rapid and multi-dimensional trajectories. The proposed technique is based on correcting the mirror symmetry distortion induced by time-varying FFs. We demonstrate via simulations and experiments in our in-house MPI scanner that the proposed method successfully estimates high-fidelity time constant maps for rapid trajectories that provide orders of magnitude reduction in scanning time while preserving the calibration-free property of TAURUS.
Near-optimal Offline Reinforcement Learning with Linear Representation: Leveraging Variance Information with Pessimism
Mar 11, 2022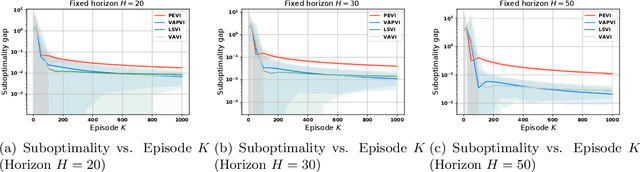
Offline reinforcement learning, which seeks to utilize offline/historical data to optimize sequential decision-making strategies, has gained surging prominence in recent studies. Due to the advantage that appropriate function approximators can help mitigate the sample complexity burden in modern reinforcement learning problems, existing endeavors usually enforce powerful function representation models (e.g. neural networks) to learn the optimal policies. However, a precise understanding of the statistical limits with function representations, remains elusive, even when such a representation is linear. Towards this goal, we study the statistical limits of offline reinforcement learning with linear model representations. To derive the tight offline learning bound, we design the variance-aware pessimistic value iteration (VAPVI), which adopts the conditional variance information of the value function for time-inhomogeneous episodic linear Markov decision processes (MDPs). VAPVI leverages estimated variances of the value functions to reweight the Bellman residuals in the least-square pessimistic value iteration and provides improved offline learning bounds over the best-known existing results (whereas the Bellman residuals are equally weighted by design). More importantly, our learning bounds are expressed in terms of system quantities, which provide natural instance-dependent characterizations that previous results are short of. We hope our results draw a clearer picture of what offline learning should look like when linear representations are provided.
Standby-Based Deadlock Avoidance Method for Multi-Agent Pickup and Delivery Tasks
Jan 19, 2022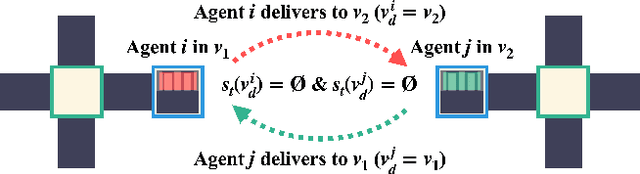
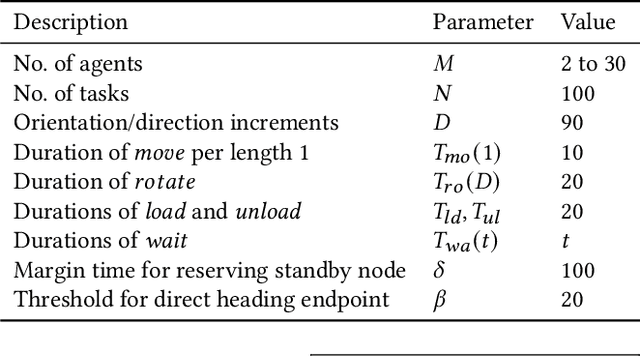
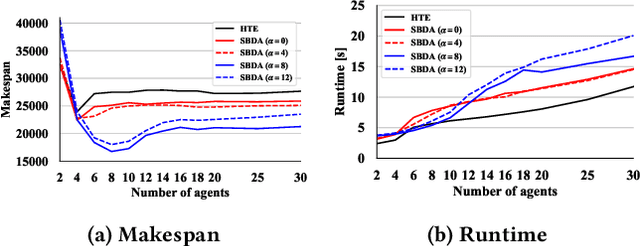
The multi-agent pickup and delivery (MAPD) problem, in which multiple agents iteratively carry materials without collisions, has received significant attention. However, many conventional MAPD algorithms assume a specifically designed grid-like environment, such as an automated warehouse. Therefore, they have many pickup and delivery locations where agents can stay for a lengthy period, as well as plentiful detours to avoid collisions owing to the freedom of movement in a grid. By contrast, because a maze-like environment such as a search-and-rescue or construction site has fewer pickup/delivery locations and their numbers may be unbalanced, many agents concentrate on such locations resulting in inefficient operations, often becoming stuck or deadlocked. Thus, to improve the transportation efficiency even in a maze-like restricted environment, we propose a deadlock avoidance method, called standby-based deadlock avoidance (SBDA). SBDA uses standby nodes determined in real-time using the articulation-point-finding algorithm, and the agent is guaranteed to stay there for a finite amount of time. We demonstrated that our proposed method outperforms a conventional approach. We also analyzed how the parameters used for selecting standby nodes affect the performance.
A Two-stage U-Net for high-fidelity denoising of historical recordings
Feb 17, 2022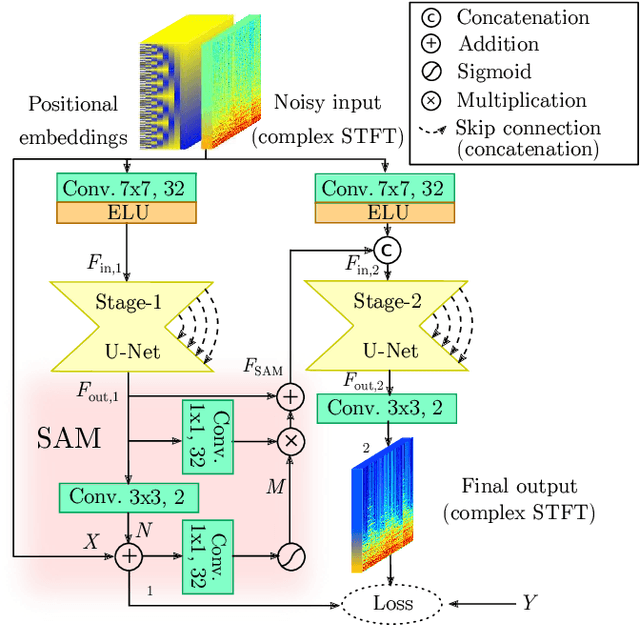
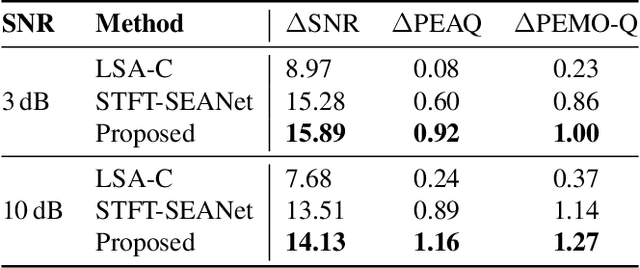
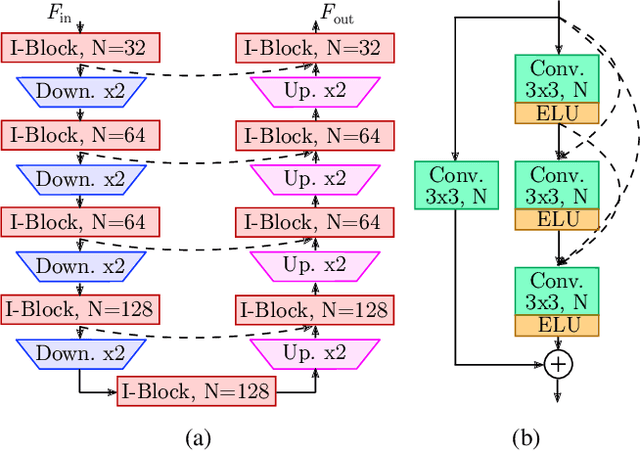
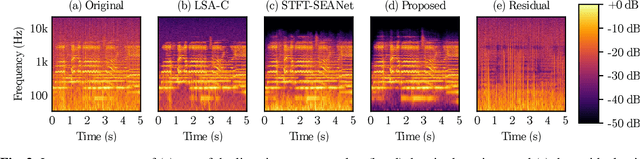
Enhancing the sound quality of historical music recordings is a long-standing problem. This paper presents a novel denoising method based on a fully-convolutional deep neural network. A two-stage U-Net model architecture is designed to model and suppress the degradations with high fidelity. The method processes the time-frequency representation of audio, and is trained using realistic noisy data to jointly remove hiss, clicks, thumps, and other common additive disturbances from old analog discs. The proposed model outperforms previous methods in both objective and subjective metrics. The results of a formal blind listening test show that real gramophone recordings denoised with this method have significantly better quality than the baseline methods. This study shows the importance of realistic training data and the power of deep learning in audio restoration.
Finite-time disturbance reconstruction and robust fractional-order controller design for hybrid port-Hamiltonian dynamics of biped robots
Jan 13, 2021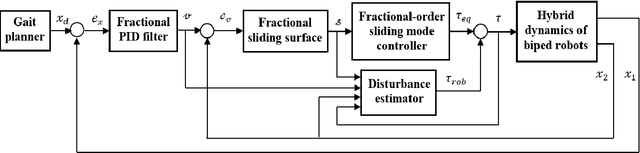

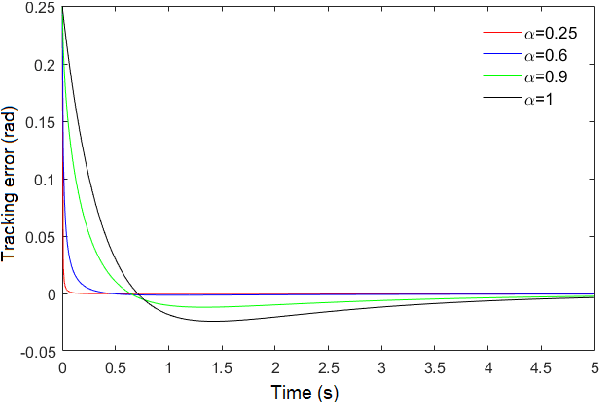

In this paper, disturbance reconstruction and robust trajectory tracking control of biped robots with hybrid dynamics in the port-Hamiltonian form is investigated. A new type of Hamiltonian function is introduced, which ensures the finite-time stability of the closed-loop system. The proposed control system consists of two loops: an inner and an outer loop. A fractional proportional-integral-derivative filter is used to achieve finite-time convergence for position tracking errors at the outer loop. A fractional-order sliding mode controller acts as a centralized controller at the inner-loop, ensuring the finite-time stability of the velocity tracking error. In this loop, the undesired effects of unknown external disturbance and parameter uncertainties are compensated using estimators. Two disturbance estimators are envisioned. The former is designed using fractional calculus. The latter is an adaptive estimator, and it is constructed using the general dynamic of biped robots. Stability analysis shows that the closed-loop system is finite-time stable in both contact-less and impact phases. Simulation studies on two types of biped robots (i.e., two-link walker and RABBIT biped robot) demonstrate the proposed controller's tracking performance and disturbance rejection capability.