 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PseCo: Pseudo Labeling and Consistency Training for Semi-Supervised Object Detection
Mar 30, 2022

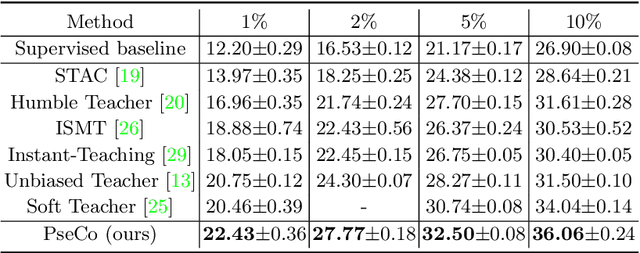
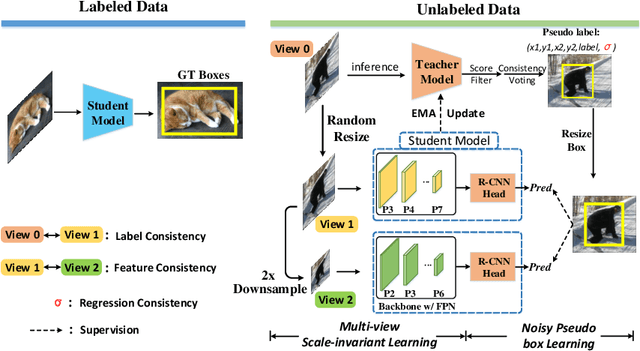
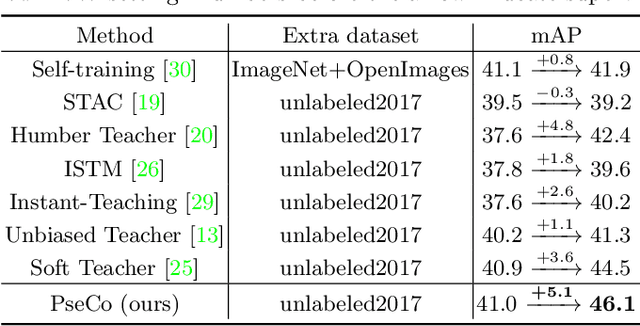
In this paper, we delve into two key techniques in Semi-Supervised Object Detection (SSOD), namely pseudo labeling and consistency training. We observe that these two techniques currently neglect some important properties of object detection, hindering efficient learning on unlabeled data. Specifically, for pseudo labeling, existing works only focus on the classification score yet fail to guarantee the localization precision of pseudo boxes; For consistency training, the widely adopted random-resize training only considers the label-level consistency but misses the feature-level one, which also plays an important role in ensuring the scale invariance. To address the problems incurred by noisy pseudo boxes, we design Noisy Pseudo box Learning (NPL) that includes Prediction-guided Label Assignment (PLA) and Positive-proposal Consistency Voting (PCV). PLA relies on model predictions to assign labels and makes it robust to even coarse pseudo boxes; while PCV leverages the regression consistency of positive proposals to reflect the localization quality of pseudo boxes. Furthermore, in consistency training, we propose Multi-view Scale-invariant Learning (MSL) that includes mechanisms of both label- and feature-level consistency, where feature consistency is achieved by aligning shifted feature pyramids between two images with identical content but varied scales. On COCO benchmark, our method, termed PSEudo labeling and COnsistency training (PseCo), outperforms the SOTA (Soft Teacher) by 2.0, 1.8, 2.0 points under 1%, 5%, and 10% labelling ratios, respectively. It also significantly improves the learning efficiency for SSOD, e.g., PseCo halves the training time of the SOTA approach but achieves even better performance.
Listen to Interpret: Post-hoc Interpretability for Audio Networks with NMF
Feb 23, 2022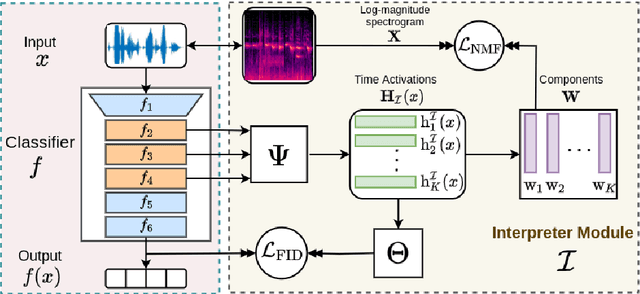
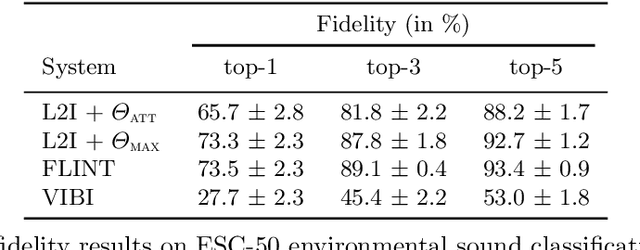

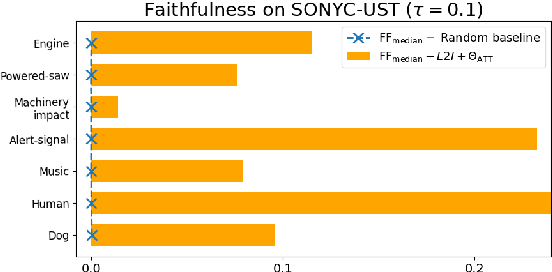
This paper tackles post-hoc interpretability for audio processing networks. Our goal is to interpret decisions of a network in terms of high-level audio objects that are also listenable for the end-user. To this end, we propose a novel interpreter design that incorporates non-negative matrix factorization (NMF). In particular, a carefully regularized interpreter module is trained to take hidden layer representations of the targeted network as input and produce time activations of pre-learnt NMF components as intermediate outputs. Our methodology allows us to generate intuitive audio-based interpretations that explicitly enhance parts of the input signal most relevant for a network's decision. We demonstrate our method's applicability on popular benchmarks, including a real-world multi-label classification task.
Analysis of Visual Reasoning on One-Stage Object Detection
Feb 26, 2022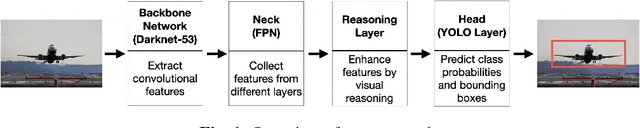
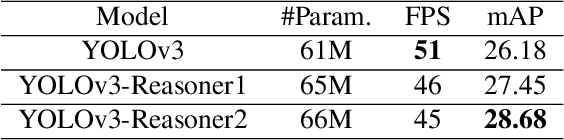
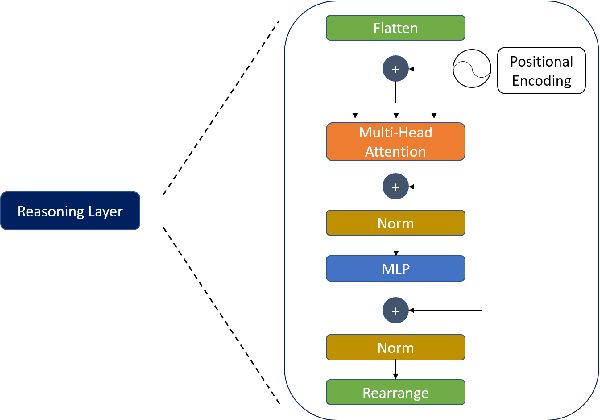
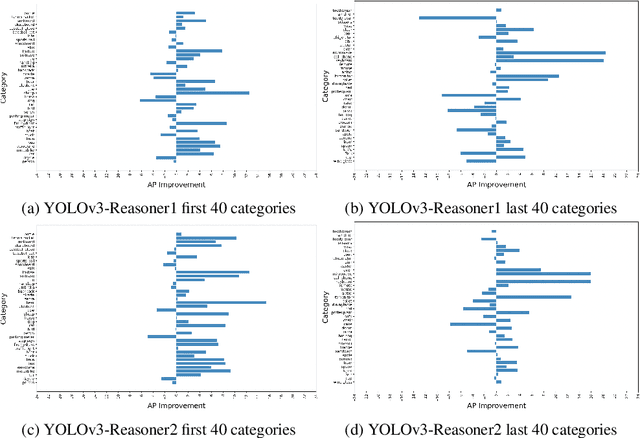
Current state-of-the-art one-stage object detectors are limited by treating each image region separately without considering possible relations of the objects. This causes dependency solely on high-quality convolutional feature representations for detecting objects successfully. However, this may not be possible sometimes due to some challenging conditions. In this paper, the usage of reasoning features on one-stage object detection is analyzed. We attempted different architectures that reason the relations of the image regions by using self-attention. YOLOv3-Reasoner2 model spatially and semantically enhances features in the reasoning layer and fuses them with the original convolutional features to improve performance. The YOLOv3-Reasoner2 model achieves around 2.5% absolute improvement with respect to baseline YOLOv3 on COCO in terms of mAP while still running in real-time.
Reverse Back Propagation to Make Full Use of Derivative
Feb 13, 2022The development of the back-propagation algorithm represents a landmark in neural networks. We provide an approach that conducts the back-propagation again to reverse the traditional back-propagation process to optimize the input loss at the input end of a neural network for better effects without extra costs during the inference time. Then we further analyzed its principles and advantages and disadvantages, reformulated the weight initialization strategy for our method. And experiments on MNIST, CIFAR10, and CIFAR100 convinced our approaches could adapt to a larger range of learning rate and learn better than vanilla back-propagation.
Convergence of a robust deep FBSDE method for stochastic control
Jan 18, 2022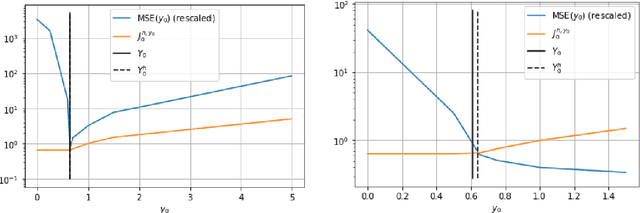
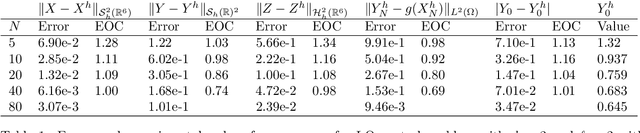
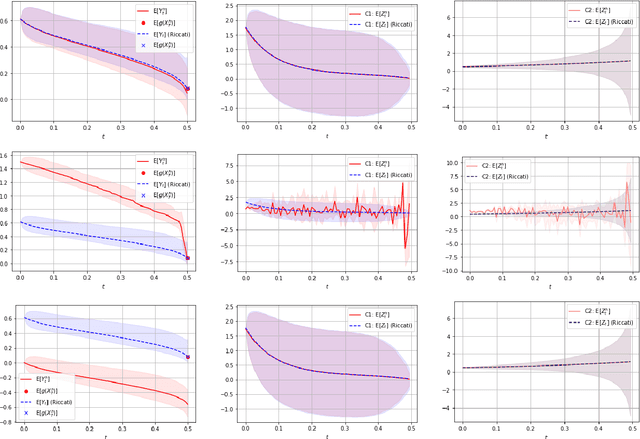

In this paper we propose a deep learning based numerical scheme for strongly coupled FBSDE, stemming from stochastic control. It is a modification of the deep BSDE method in which the initial value to the backward equation is not a free parameter, and with a new loss function being the weighted sum of the cost of the control problem, and a variance term which coincides with the means square error in the terminal condition. We show by a numerical example that a direct extension of the classical deep BSDE method to FBSDE, fails for a simple linear-quadratic control problem, and motivate why the new method works. Under regularity and boundedness assumptions on the exact controls of time continuous and time discrete control problems we provide an error analysis for our method. We show empirically that the method converges for three different problems, one being the one that failed for a direct extension of the deep BSDE method.
Detection of Parasitic Eggs from Microscopy Images and the emergence of a new dataset
Mar 06, 2022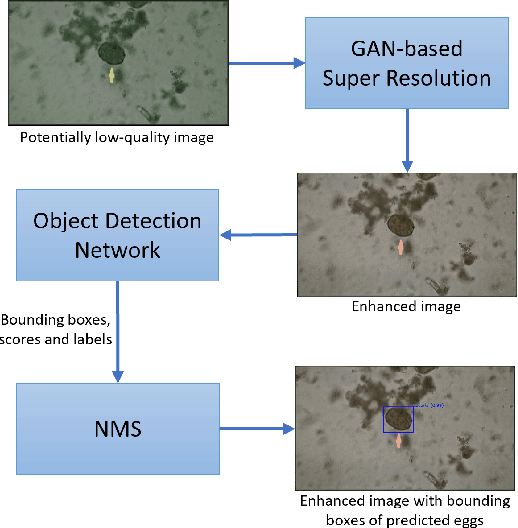
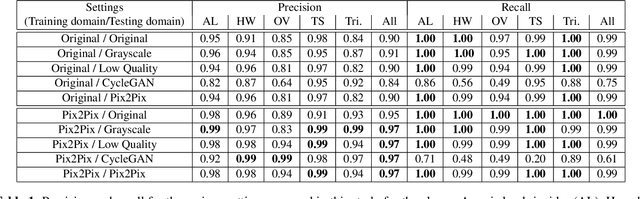


Automatic detection of parasitic eggs in microscopy images has the potential to increase the efficiency of human experts whilst also providing an objective assessment. The time saved by such a process would both help ensure a prompt treatment to patients, and off-load excessive work from experts' shoulders. Advances in deep learning inspired us to exploit successful architectures for detection, adapting them to tackle a different domain. We propose a framework that exploits two such state-of-the-art models. Specifically, we demonstrate results produced by both a Generative Adversarial Network (GAN) and Faster-RCNN, for image enhancement and object detection respectively, on microscopy images of varying quality. The use of these techniques yields encouraging results, though further improvements are still needed for certain egg types whose detection still proves challenging. As a result, a new dataset has been created and made publicly available, providing an even wider range of classes and variability.
Adaptively Re-weighting Multi-Loss Untrained Transformer for Sparse-View Cone-Beam CT Reconstruction
Mar 23, 2022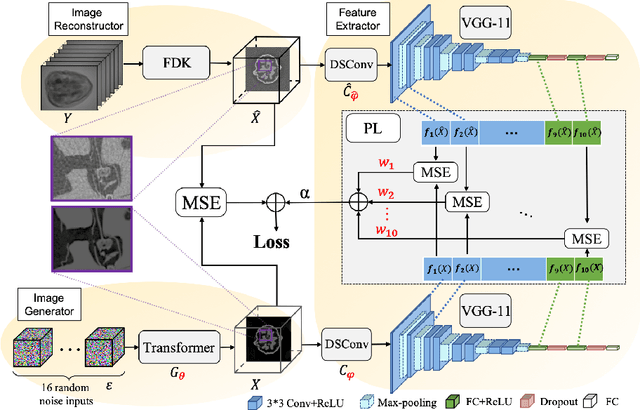
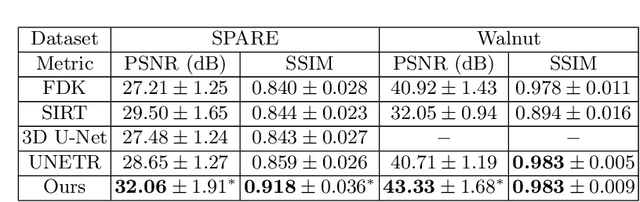
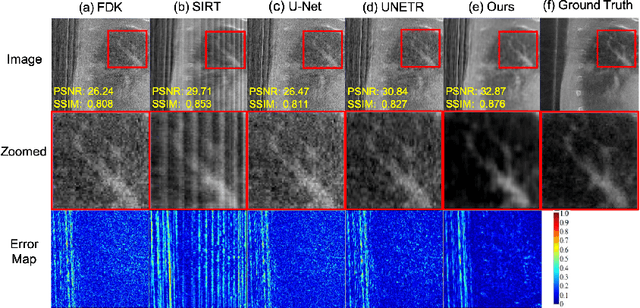
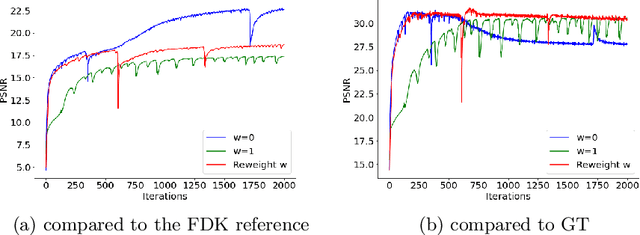
Cone-Beam Computed Tomography (CBCT) has been proven useful in diagnosis, but how to shorten scanning time with lower radiation dosage and how to efficiently reconstruct 3D image remain as the main issues for clinical practice. The recent development of tomographic image reconstruction on sparse-view measurements employs deep neural networks in a supervised way to tackle such issues, whereas the success of model training requires quantity and quality of the given paired measurements/images. We propose a novel untrained Transformer to fit the CBCT inverse solver without training data. It is mainly comprised of an untrained 3D Transformer of billions of network weights and a multi-level loss function with variable weights. Unlike conventional deep neural networks (DNNs), there is no requirement of training steps in our approach. Upon observing the hardship of optimising Transformer, the variable weights within the loss function are designed to automatically update together with the iteration process, ultimately stabilising its optimisation. We evaluate the proposed approach on two publicly available datasets: SPARE and Walnut. The results show a significant performance improvement on image quality metrics with streak artefact reduction in the visualisation. We also provide a clinical report by an experienced radiologist to assess our reconstructed images in a diagnosis point of view. The source code and the optimised models are available from the corresponding author on request at the moment.
RTFN: A Robust Temporal Feature Network for Time Series Classification
Nov 24, 2020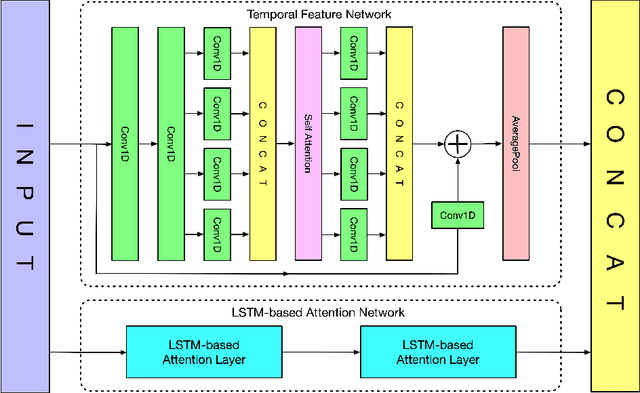
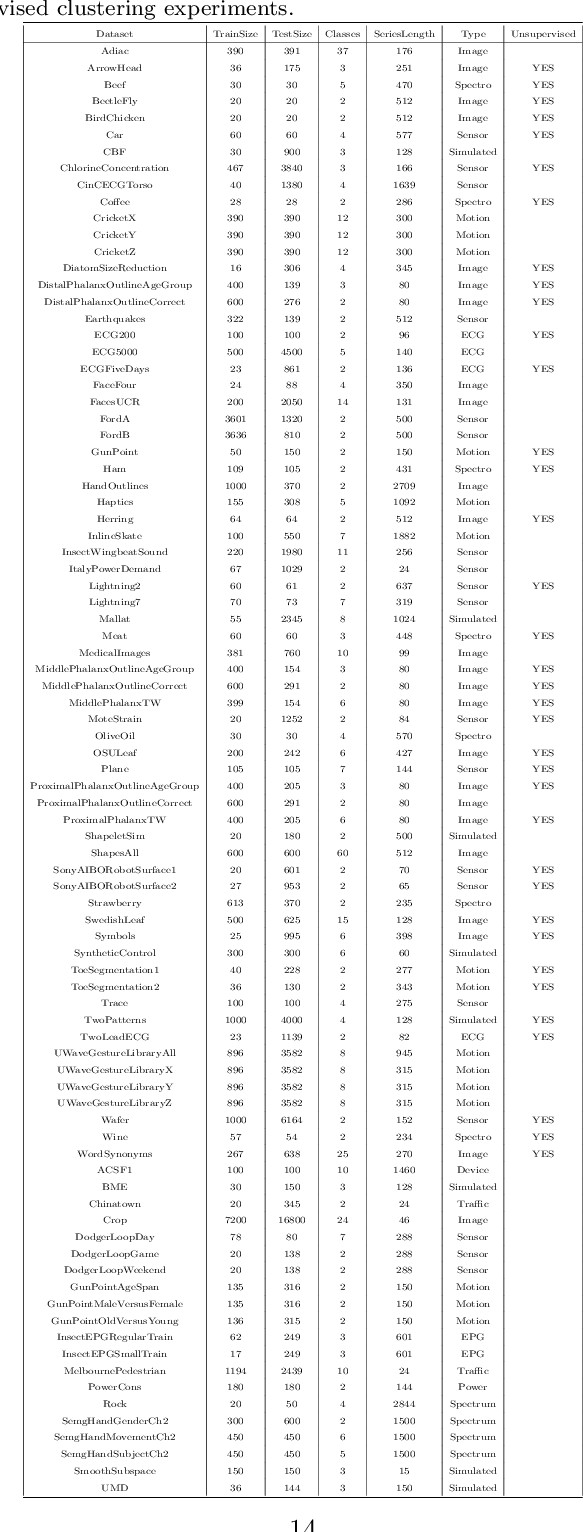
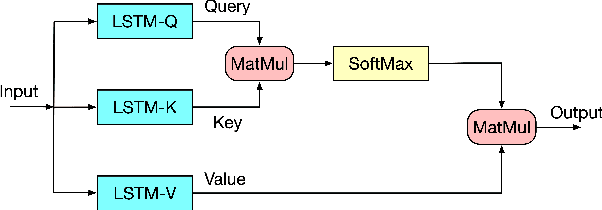
Time series data usually contains local and global patterns. Most of the existing feature networks pay more attention to local features rather than the relationships among them. The latter is, however, also important yet more difficult to explore. To obtain sufficient representations by a feature network is still challenging. To this end, we propose a novel robust temporal feature network (RTFN) for feature extraction in time series classification, containing a temporal feature network (TFN) and an LSTM-based attention network (LSTMaN). TFN is a residual structure with multiple convolutional layers. It functions as a local-feature extraction network to mine sufficient local features from data. LSTMaN is composed of two identical layers, where attention and long short-term memory (LSTM) networks are hybridized. This network acts as a relation extraction network to discover the intrinsic relationships among the extracted features at different positions in sequential data. In experiments, we embed RTFN into a supervised structure as a feature extractor and into an unsupervised structure as an encoder, respectively. The results show that the RTFN-based structures achieve excellent supervised and unsupervised performance on a large number of UCR2018 and UEA2018 datasets.
Video based real-time positional tracker
Sep 17, 2020
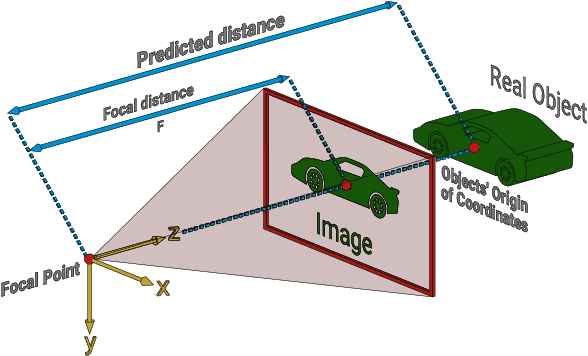
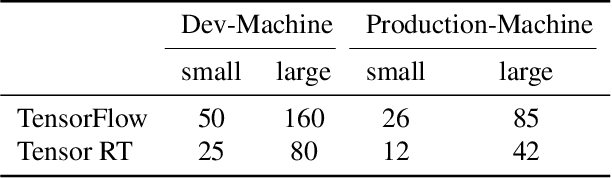
We propose a system that uses video as the input to track the position of objects relative to their surrounding environment in real-time. The neural network employed is trained on a 100% synthetic dataset coming from our own automated generator. The positional tracker relies on a range of 1 to n video cameras placed around an arena of choice. The system returns the positions of the tracked objects relative to the broader world by understanding the overlapping matrices formed by the cameras and therefore these can be extrapolated into real world coordinates. In most cases, we achieve a higher update rate and positioning precision than any of the existing GPS-based systems, in particular for indoor objects or those occluded from clear sky.
Echofilter: A Deep Learning Segmentation Model Improves the Automation, Standardization, and Timeliness for Post-Processing Echosounder Data in Tidal Energy Streams
Feb 19, 2022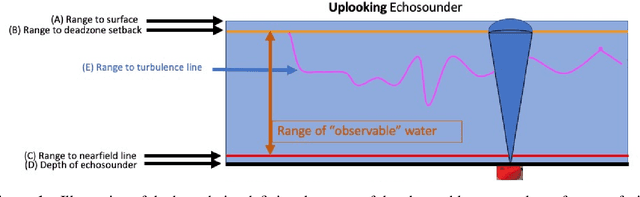

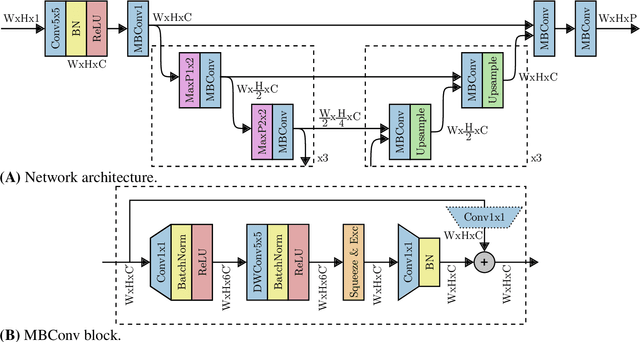

Understanding the abundance and distribution of fish in tidal energy streams is important for assessing the risk presented by the introduction of tidal energy devices into the habitat. However, the impressive tidal currents that make sites favorable for tidal energy development are often highly turbulent and entrain air into the water, complicating the interpretation of echosounder data. The portion of the water column contaminated by returns from entrained air must be excluded from data used for biological analyses. Application of a single algorithm to identify the depth-of-penetration of entrained-air is insufficient for a boundary that is discontinuous, depth-dynamic, porous, and widely variable across the tidal flow speeds which can range from 0 to 5m/s. Using a case study at a tidal energy demonstration site in the Bay of Fundy, we describe the development and application of deep learning models that produce a pronounced, consistent, substantial, and measurable improvement of the automated detection of the extent to which entrained-air has penetrated the water column. Our model, Echofilter, was highly responsive to the dynamic range of turbulence conditions and sensitive to the fine-scale nuances in the boundary position, producing an entrained-air boundary line with an average error of 0.32m on mobile downfacing and 0.5-1.0m on stationary upfacing data. The model's annotations had a high level of agreement with the human segmentation (mobile downfacing Jaccard index: 98.8%; stationary upfacing: 93-95%). This resulted in a 50% reduction in the time required for manual edits compared to the time required to manually edit the line placed by currently available algorithms. Because of the improved initial automated placement, the implementation of the models generated a marked increase in the standardization and repeatability of line placement.