 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Foveated Neural Radiance Fields for Real-Time and Egocentric Virtual Reality
Mar 30, 2021

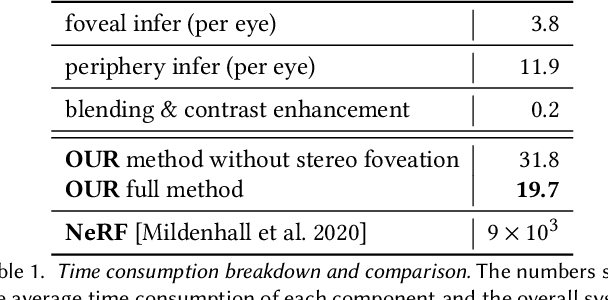
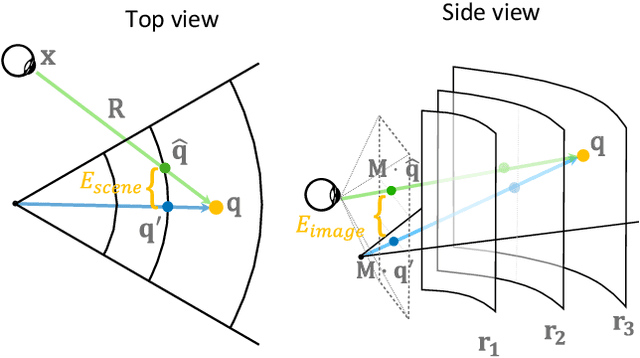

Traditional high-quality 3D graphics requires large volumes of fine-detailed scene data for rendering. This demand compromises computational efficiency and local storage resources. Specifically, it becomes more concerning for future wearable and portable virtual and augmented reality (VR/AR) displays. Recent approaches to combat this problem include remote rendering/streaming and neural representations of 3D assets. These approaches have redefined the traditional local storage-rendering pipeline by distributed computing or compression of large data. However, these methods typically suffer from high latency or low quality for practical visualization of large immersive virtual scenes, notably with extra high resolution and refresh rate requirements for VR applications such as gaming and design. Tailored for the future portable, low-storage, and energy-efficient VR platforms, we present the first gaze-contingent 3D neural representation and view synthesis method. We incorporate the human psychophysics of visual- and stereo-acuity into an egocentric neural representation of 3D scenery. Furthermore, we jointly optimize the latency/performance and visual quality, while mutually bridging human perception and neural scene synthesis, to achieve perceptually high-quality immersive interaction. Both objective analysis and subjective study demonstrate the effectiveness of our approach in significantly reducing local storage volume and synthesis latency (up to 99% reduction in both data size and computational time), while simultaneously presenting high-fidelity rendering, with perceptual quality identical to that of fully locally stored and rendered high-quality imagery.
Calculation of Sub-bands {1,2,5,6} for 64-Point Complex FFT and Its extension to N (=2^N) Point FFT
Mar 08, 2022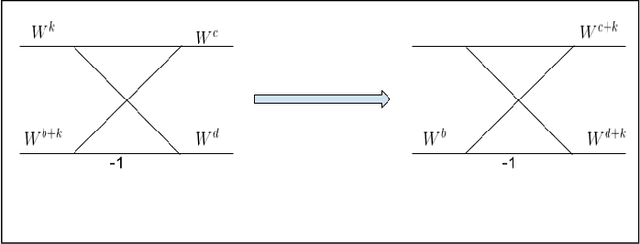
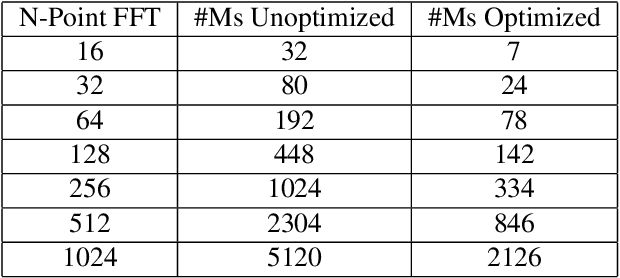
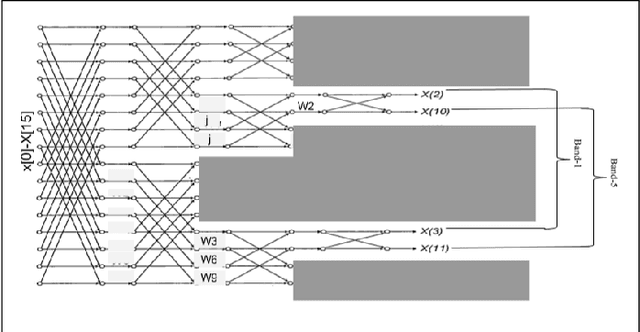
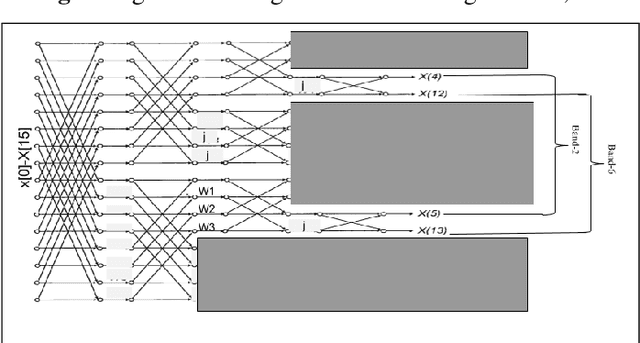
FFT algorithm is one of the most applied algorithmsin digital signal processing. Digital signal processing hasgradually become important in biomedical application. Herehardware implementation of FFTs have found useful appli-cations for bio-wearable devices. However, for these devices, low-power and low-area are of utmost importance.In this report, we investigate a sub-structure of decimation-in-frequency (DIF) FFT where a number of sub-bands areof interest to us. Specifically, we divide the range of frequencies into 8 sub-bands (0-7) and calculate 4 of them( 1,2,5,6). We show that using concepts likepushingandradix22, the number of complex multiplications can be dras-tically reduced for 16-point, 32-point and 64-point FFTswhile computing those specific bands. Later, we also extendit toN= 2n-point FFT based on optimized 64-point FFTstructure. The number of complex multiplications is furtherreduced usingmerge-FFT. Our results show that the numberof multiplications (and hence power) can be reduced greatlyusing our optimized structure compared to an unoptimizedstructure. This can find application in biomedical signal processing specifically while computingp ower spectral density of a physiological time series where reducing computational power is of utmost importance
IFoodCloud: A Platform for Real-time Sentiment Analysis of Public Opinion about Food Safety in China
Feb 17, 2021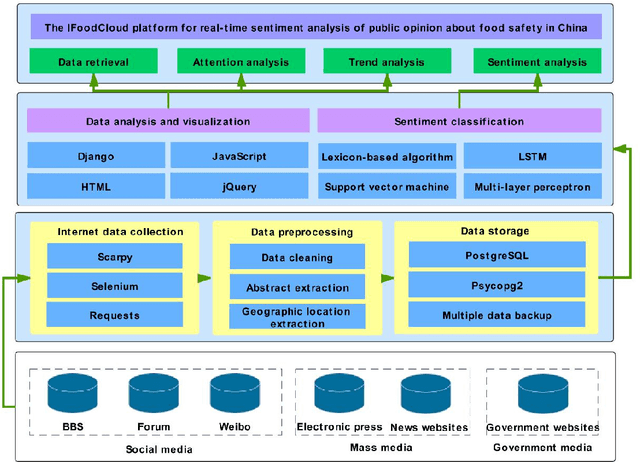
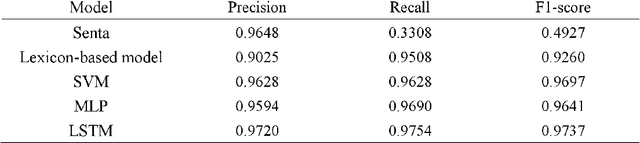
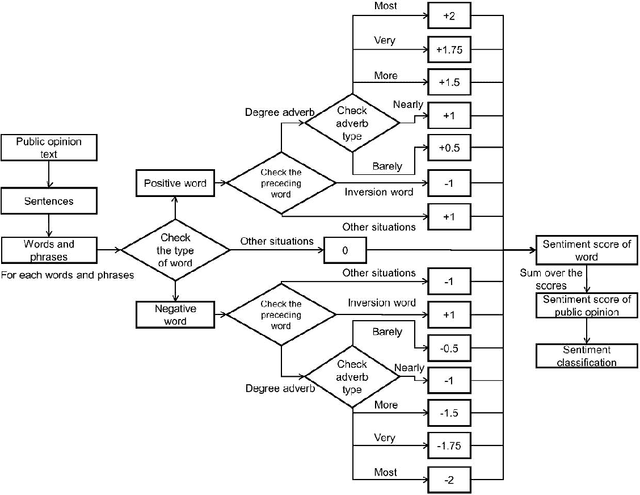
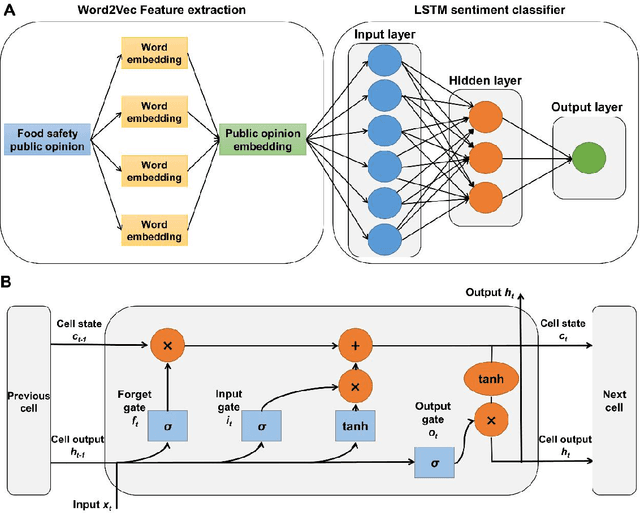
The Internet contains a wealth of public opinion on food safety, including views on food adulteration, food-borne diseases, agricultural pollution, irregular food distribution, and food production issues. In order to systematically collect and analyse public opinion on food safety, we developed IFoodCloud, a platform for the real-time sentiment analysis of public opinion on food safety in China. It collects data from more than 3,100 public sources that can be used to explore public opinion trends, public sentiment, and regional attention differences of food safety incidents. At the same time, we constructed a sentiment classification model using multiple lexicon-based and deep learning-based algorithms integrated with IFoodCloud that provide an unprecedented rapid means of understanding the public sentiment toward specific food safety incidents. Our best model's F1-score achieved 0.9737. Further, three real-world cases are presented to demonstrate the application and robustness. IFoodCloud could be considered a valuable tool for promote scientisation of food safety supervision and risk communication.
DARER: Dual-task Temporal Relational Recurrent Reasoning Network for Joint Dialog Sentiment Classification and Act Recognition
Mar 08, 2022
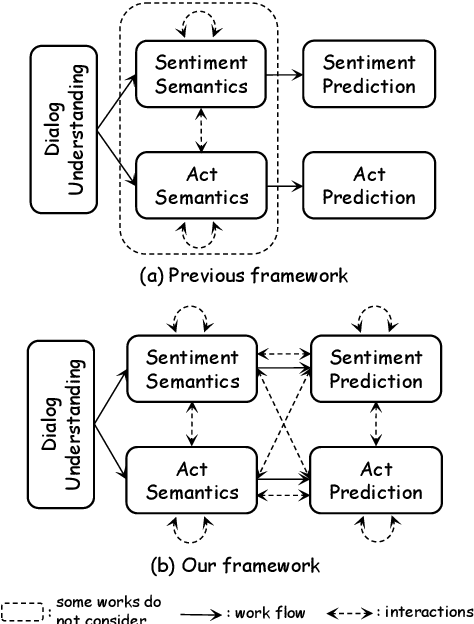
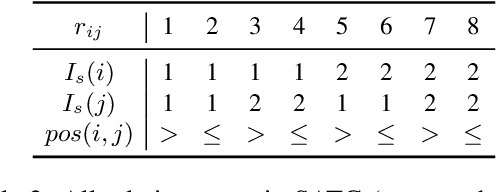
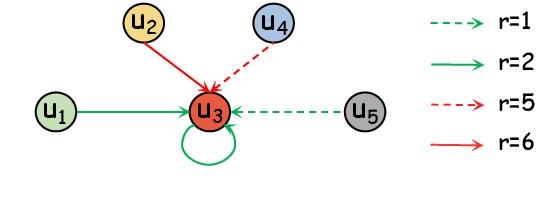
The task of joint dialog sentiment classification (DSC) and act recognition (DAR) aims to simultaneously predict the sentiment label and act label for each utterance in a dialog. In this paper, we put forward a new framework which models the explicit dependencies via integrating \textit{prediction-level interactions} other than semantics-level interactions, more consistent with human intuition. Besides, we propose a speaker-aware temporal graph (SATG) and a dual-task relational temporal graph (DRTG) to introduce \textit{temporal relations} into dialog understanding and dual-task reasoning. To implement our framework, we propose a novel model dubbed DARER, which first generates the context-, speaker- and temporal-sensitive utterance representations via modeling SATG, then conducts recurrent dual-task relational reasoning on DRTG, in which process the estimated label distributions act as key clues in prediction-level interactions. Experiment results show that DARER outperforms existing models by large margins while requiring much less computation resource and costing less training time. Remarkably, on DSC task in Mastodon, DARER gains a relative improvement of about 25% over previous best model in terms of F1, with less than 50% parameters and about only 60% required GPU memory.
A Multi-parameter Updating Fourier Online Gradient Descent Algorithm for Large-scale Nonlinear Classification
Mar 16, 2022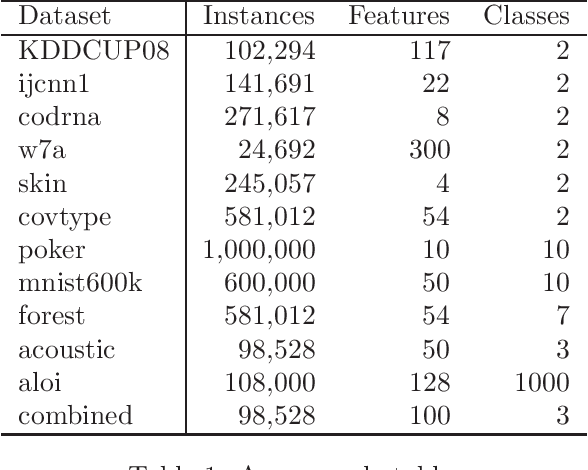
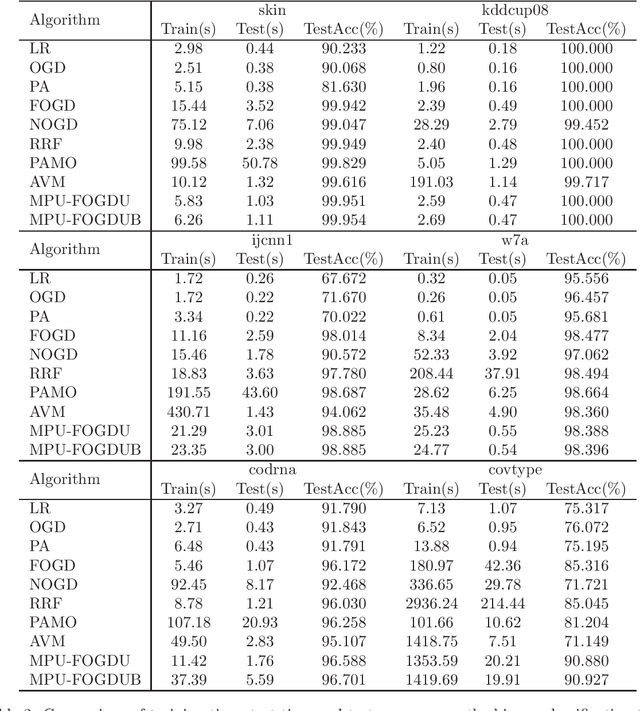
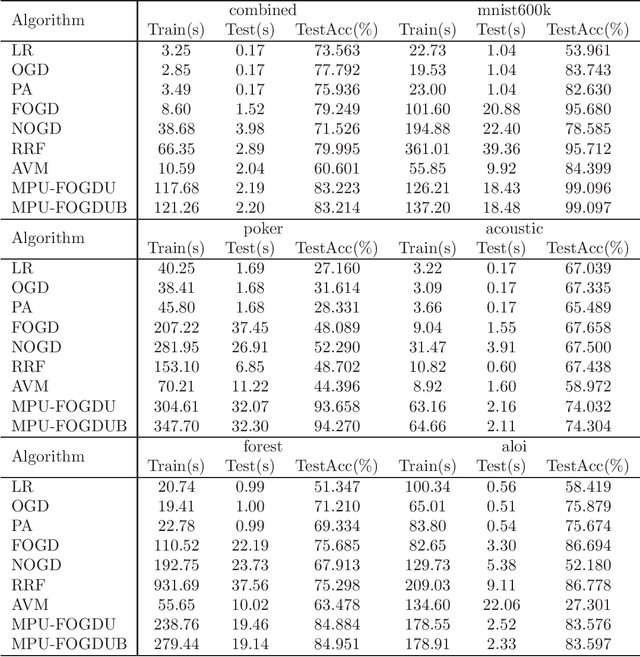
Large scale nonlinear classification is a challenging task in the field of support vector machine. Online random Fourier feature map algorithms are very important methods for dealing with large scale nonlinear classification problems. The main shortcomings of these methods are as follows: (1) Since only the hyperplane vector is updated during learning while the random directions are fixed, there is no guarantee that these online methods can adapt to the change of data distribution when the data is coming one by one. (2) The dimension of the random direction is often higher for obtaining better classification accuracy, which results in longer test time. In order to overcome these shortcomings, a multi-parameter updating Fourier online gradient descent algorithm (MPU-FOGD) is proposed for large-scale nonlinear classification problems based on a novel random feature map. In the proposed method, the suggested random feature map has lower dimension while the multi-parameter updating strategy can guarantee the learning model can better adapt to the change of data distribution when the data is coming one by one. Theoretically, it is proved that compared with the existing random Fourier feature maps, the proposed random feature map can give a tighter error bound. Empirical studies on several benchmark data sets demonstrate that compared with the state-of-the-art online random Fourier feature map methods, the proposed MPU-FOGD can obtain better test accuracy.
Extension of Convolutional Neural Network along Temporal and Vertical Directions for Precipitation Downscaling
Dec 13, 2021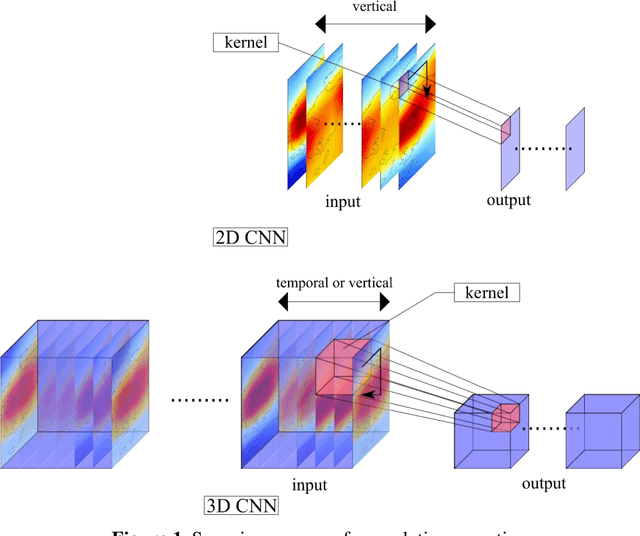

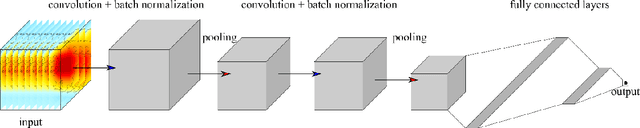
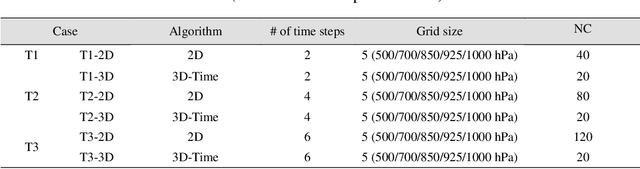
Deep learning has been utilized for the statistical downscaling of climate data. Specifically, a two-dimensional (2D) convolutional neural network (CNN) has been successfully applied to precipitation estimation. This study implements a three-dimensional (3D) CNN to estimate watershed-scale daily precipitation from 3D atmospheric data and compares the results with those for a 2D CNN. The 2D CNN is extended along the time direction (3D-CNN-Time) and the vertical direction (3D-CNN-Vert). The precipitation estimates of these extended CNNs are compared with those of the 2D CNN in terms of the root-mean-square error (RMSE), Nash-Sutcliffe efficiency (NSE), and 99th percentile RMSE. It is found that both 3D-CNN-Time and 3D-CNN-Vert improve the model accuracy for precipitation estimation compared to the 2D CNN. 3D-CNN-Vert provided the best estimates during the training and test periods in terms of RMSE and NSE.
A Parallel Approach for Real-Time Face Recognition from a Large Database
Nov 01, 2020

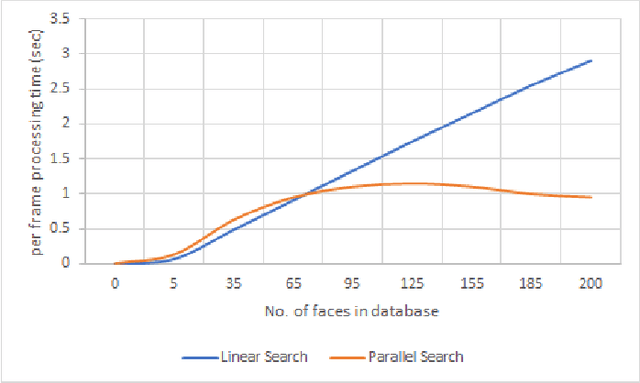
We present a new facial recognition system, capable of identifying a person, provided their likeness has been previously stored in the system, in real time. The system is based on storing and comparing facial embeddings of the subject, and identifying them later within a live video feed. This system is highly accurate, and is able to tag people with their ID in real time. It is able to do so, even when using a database containing thousands of facial embeddings, by using a parallelized searching technique. This makes the system quite fast and allows it to be highly scalable.
FVV Live: Real-Time, Low-Cost, Free Viewpoint Video
Jun 30, 2020

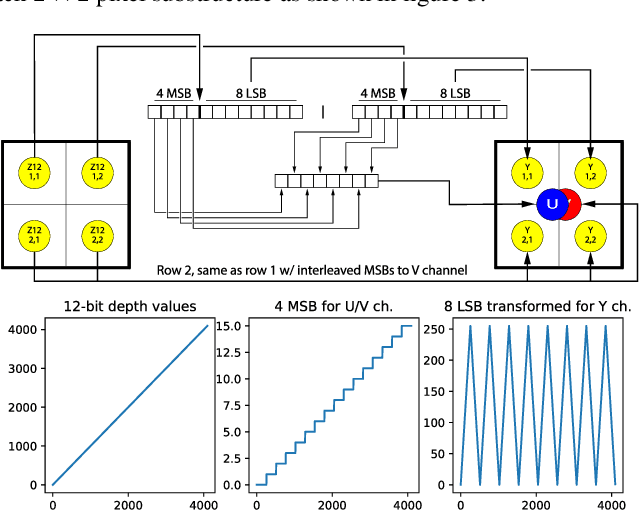
FVV Live is a novel real-time, low-latency, end-to-end free viewpoint system including capture, transmission, synthesis on an edge server and visualization and control on a mobile terminal. The system has been specially designed for low-cost and real-time operation, only using off-the-shelf components.
Phase Continuity: Learning Derivatives of Phase Spectrum for Speech Enhancement
Feb 24, 2022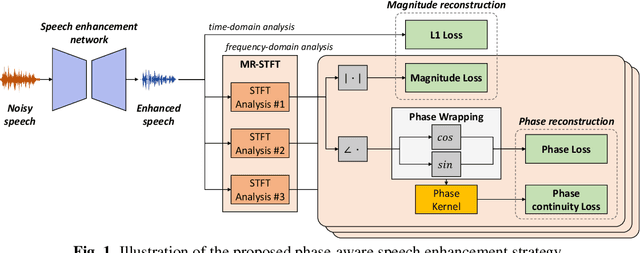
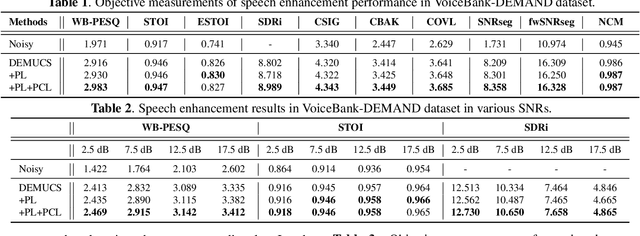
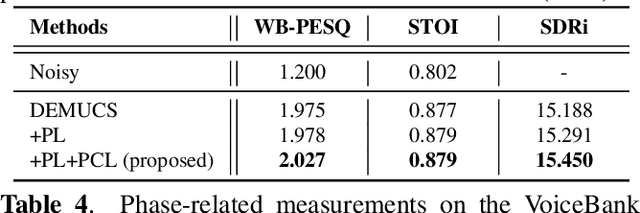
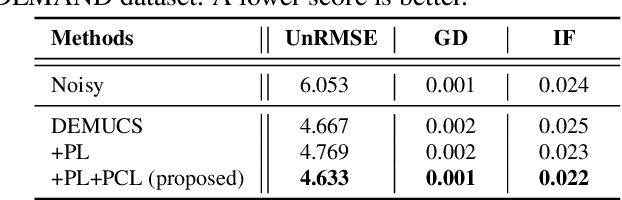
Modern neural speech enhancement models usually include various forms of phase information in their training loss terms, either explicitly or implicitly. However, these loss terms are typically designed to reduce the distortion of phase spectrum values at specific frequencies, which ensures they do not significantly affect the quality of the enhanced speech. In this paper, we propose an effective phase reconstruction strategy for neural speech enhancement that can operate in noisy environments. Specifically, we introduce a phase continuity loss that considers relative phase variations across the time and frequency axes. By including this phase continuity loss in a state-of-the-art neural speech enhancement system trained with reconstruction loss and a number of magnitude spectral losses, we show that our proposed method further improves the quality of enhanced speech signals over the baseline, especially when training is done jointly with a magnitude spectrum loss.
TGL: A General Framework for Temporal GNN Training on Billion-Scale Graphs
Mar 28, 2022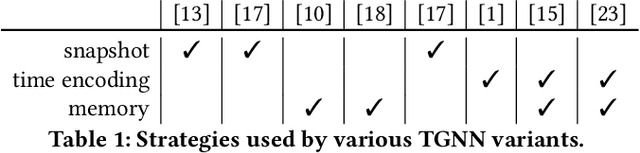
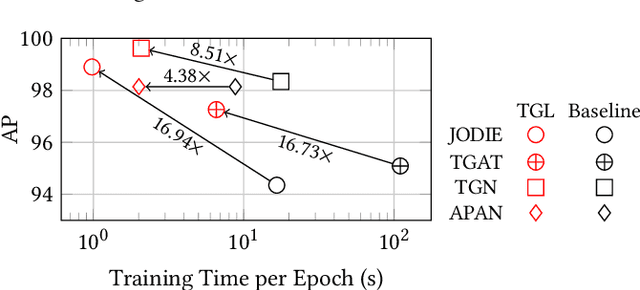
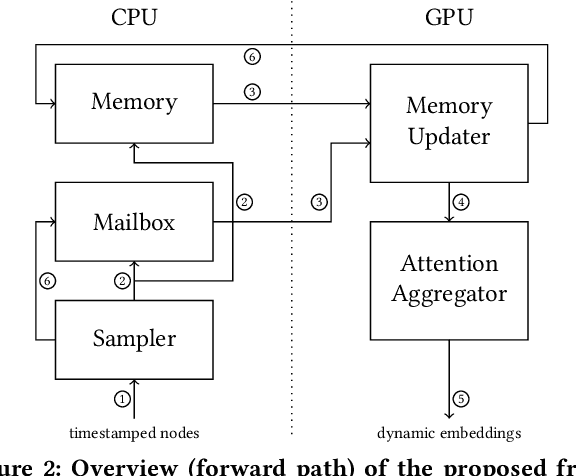
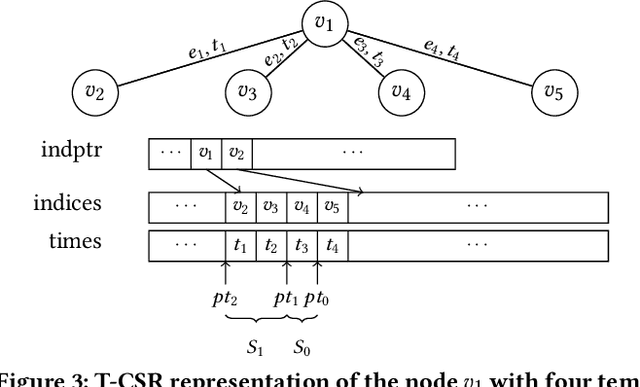
Many real world graphs contain time domain information. Temporal Graph Neural Networks capture temporal information as well as structural and contextual information in the generated dynamic node embeddings. Researchers have shown that these embeddings achieve state-of-the-art performance in many different tasks. In this work, we propose TGL, a unified framework for large-scale offline Temporal Graph Neural Network training where users can compose various Temporal Graph Neural Networks with simple configuration files. TGL comprises five main components, a temporal sampler, a mailbox, a node memory module, a memory updater, and a message passing engine. We design a Temporal-CSR data structure and a parallel sampler to efficiently sample temporal neighbors to formtraining mini-batches. We propose a novel random chunk scheduling technique that mitigates the problem of obsolete node memory when training with a large batch size. To address the limitations of current TGNNs only being evaluated on small-scale datasets, we introduce two large-scale real-world datasets with 0.2 and 1.3 billion temporal edges. We evaluate the performance of TGL on four small-scale datasets with a single GPU and the two large datasets with multiple GPUs for both link prediction and node classification tasks. We compare TGL with the open-sourced code of five methods and show that TGL achieves similar or better accuracy with an average of 13x speedup. Our temporal parallel sampler achieves an average of 173x speedup on a multi-core CPU compared with the baselines. On a 4-GPU machine, TGL can train one epoch of more than one billion temporal edges within 1-10 hours. To the best of our knowledge, this is the first work that proposes a general framework for large-scale Temporal Graph Neural Networks training on multiple GPUs.