 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Predicting Bearings' Degradation Stages for Predictive Maintenance in the Pharmaceutical Industry
Mar 07, 2022


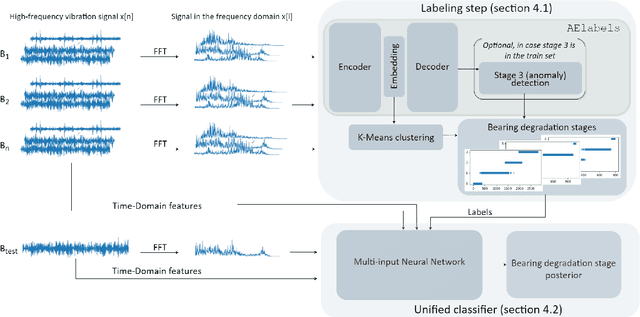

In the pharmaceutical industry, the maintenance of production machines must be audited by the regulator. In this context, the problem of predictive maintenance is not when to maintain a machine, but what parts to maintain at a given point in time. The focus shifts from the entire machine to its component parts and prediction becomes a classification problem. In this paper, we focus on rolling-elements bearings and we propose a framework for predicting their degradation stages automatically. Our main contribution is a k-means bearing lifetime segmentation method based on high-frequency bearing vibration signal embedded in a latent low-dimensional subspace using an AutoEncoder. Given high-frequency vibration data, our framework generates a labeled dataset that is used to train a supervised model for bearing degradation stage detection. Our experimental results, based on the FEMTO Bearing dataset, show that our framework is scalable and that it provides reliable and actionable predictions for a range of different bearings.
Automated Detection of Acute Promyelocytic Leukemia in Blood Films and Bone Marrow Aspirates with Annotation-free Deep Learning
Mar 20, 2022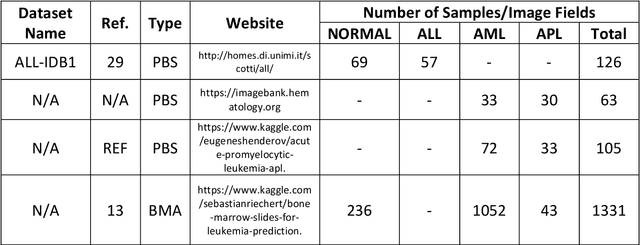
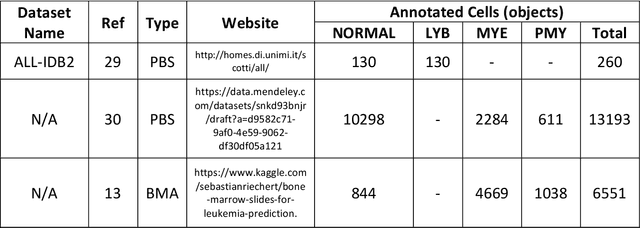
While optical microscopy inspection of blood films and bone marrow aspirates by a hematologist is a crucial step in establishing diagnosis of acute leukemia, especially in low-resource settings where other diagnostic modalities might not be available, the task remains time-consuming and prone to human inconsistencies. This has an impact especially in cases of Acute Promyelocytic Leukemia (APL) that require urgent treatment. Integration of automated computational hematopathology into clinical workflows can improve the throughput of these services and reduce cognitive human error. However, a major bottleneck in deploying such systems is a lack of sufficient cell morphological object-labels annotations to train deep learning models. We overcome this by leveraging patient diagnostic labels to train weakly-supervised models that detect different types of acute leukemia. We introduce a deep learning approach, Multiple Instance Learning for Leukocyte Identification (MILLIE), able to perform automated reliable analysis of blood films with minimal supervision. Without being trained to classify individual cells, MILLIE differentiates between acute lymphoblastic and myeloblastic leukemia in blood films. More importantly, MILLIE detects APL in blood films (AUC 0.94+/-0.04) and in bone marrow aspirates (AUC 0.99+/-0.01). MILLIE is a viable solution to augment the throughput of clinical pathways that require assessment of blood film microscopy.
Evaluation of Time Series Forecasting Models for Estimation of PM2.5 Levels in Air
Apr 07, 2021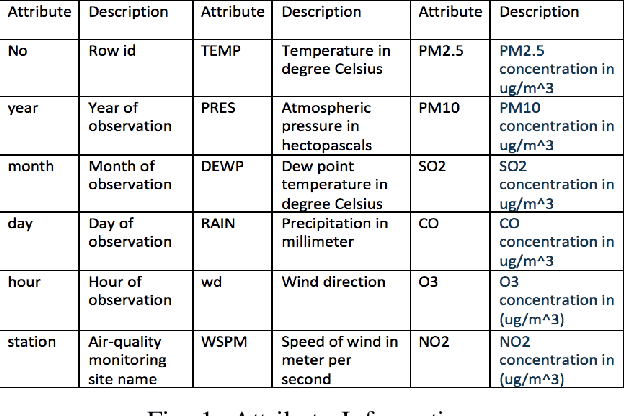
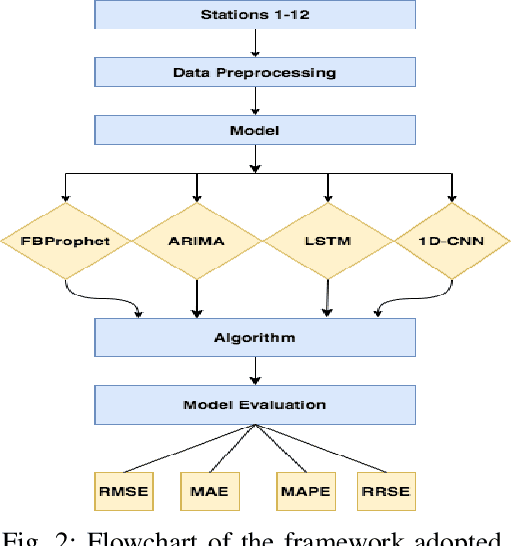
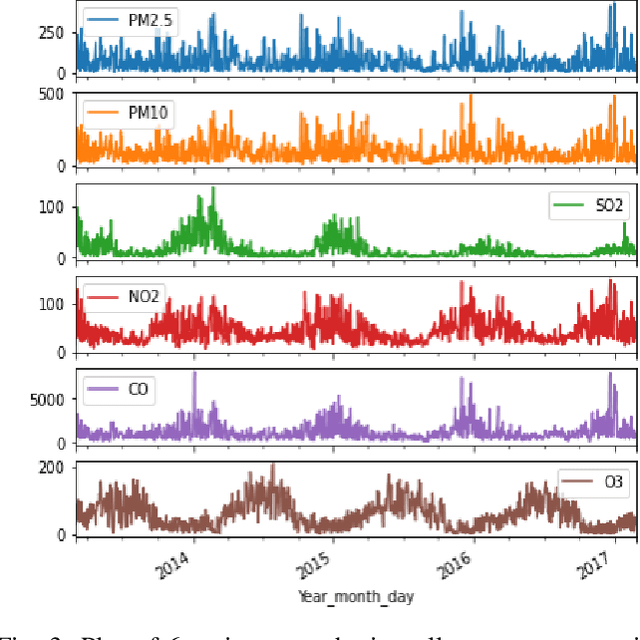
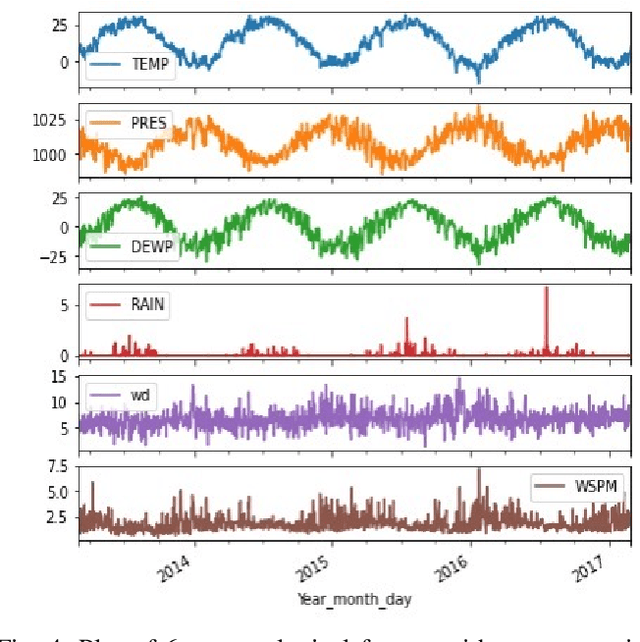
Air contamination in urban areas has risen consistently over the past few years. Due to expanding industrialization and increasing concentration of toxic gases in the climate, the air is getting more poisonous step by step at an alarming rate. Since the arrival of the Coronavirus pandemic, it is getting more critical to lessen air contamination to reduce its impact. The specialists and environmentalists are making a valiant effort to gauge air contamination levels. However, its genuinely unpredictable to mimic subatomic communication in the air, which brings about off base outcomes. There has been an ascent in using machine learning and deep learning models to foresee the results on time series data. This study adopts ARIMA, FBProphet, and deep learning models such as LSTM, 1D CNN, to estimate the concentration of PM2.5 in the environment. Our predicted results convey that all adopted methods give comparative outcomes in terms of average root mean squared error. However, the LSTM outperforms all other models with reference to mean absolute percentage error.
Context-Aware Drift Detection
Mar 16, 2022



When monitoring machine learning systems, two-sample tests of homogeneity form the foundation upon which existing approaches to drift detection build. They are used to test for evidence that the distribution underlying recent deployment data differs from that underlying the historical reference data. Often, however, various factors such as time-induced correlation mean that batches of recent deployment data are not expected to form an i.i.d. sample from the historical data distribution. Instead we may wish to test for differences in the distributions conditional on \textit{context} that is permitted to change. To facilitate this we borrow machinery from the causal inference domain to develop a more general drift detection framework built upon a foundation of two-sample tests for conditional distributional treatment effects. We recommend a particular instantiation of the framework based on maximum conditional mean discrepancies. We then provide an empirical study demonstrating its effectiveness for various drift detection problems of practical interest, such as detecting drift in the distributions underlying subpopulations of data in a manner that is insensitive to their respective prevalences. The study additionally demonstrates applicability to ImageNet-scale vision problems.
Safe Learning-Based Feedback Linearization Tracking Control for Nonlinear System with Event-Triggered Model Update
Mar 07, 2022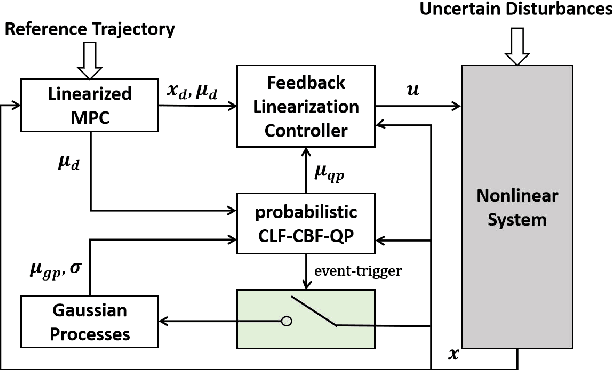
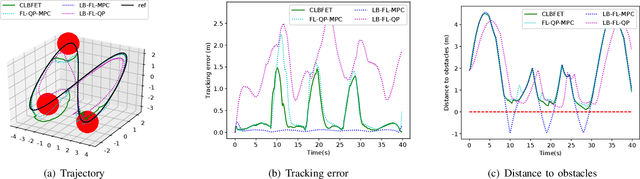
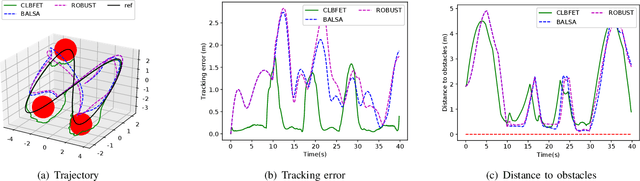
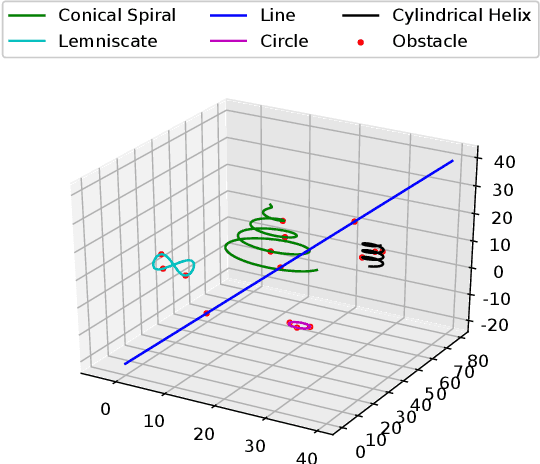
Learning-based methods are powerful in handling complex scenarios. However, it is still challenging to use learning-based methods under uncertain environments while stability, safety, and real-time performance of the system are desired to guarantee. In this paper, we propose a learning-based tracking control scheme based on a feedback linearization controller in which uncertain disturbances are approximated online using Gaussian Processes (GPs). Using the predicted distribution of disturbances given by GPs, a Control Lyapunov Function (CLF) and Control Barrier Function (CBF) based Quadratic Program is applied, with which probabilistic stability and safety are guaranteed. In addition, the trajectory is optimized first by Model Predictive Control (MPC) based on the linearized dynamics systems to further reduce the tracking error. We also design an event trigger for GPs updates to improve efficiency while stability and safety of the system are still guaranteed. The effectiveness of the proposed tracking control strategy is illustrated in numerical simulations.
* 8 pages, 8 figures
t-EVA: Time-Efficient t-SNE Video Annotation
Nov 26, 2020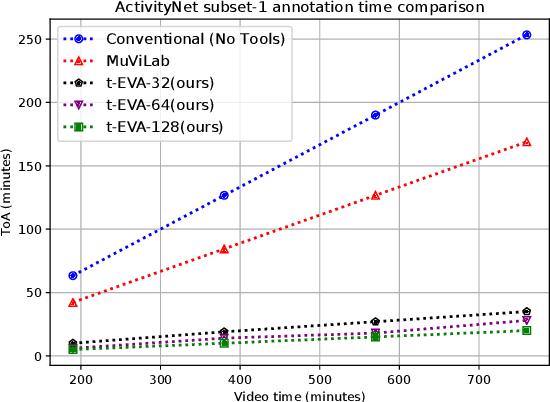
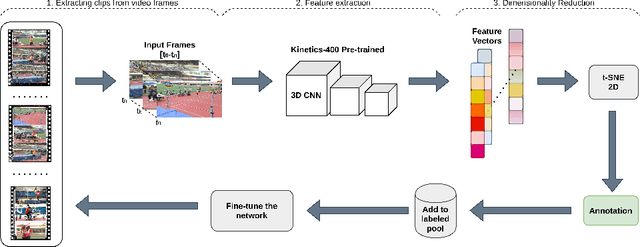

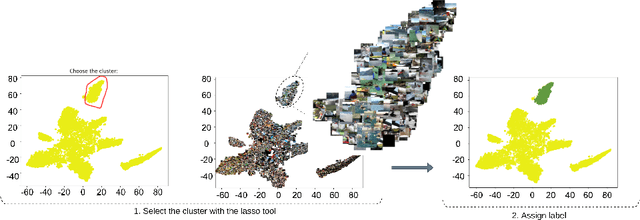
Video understanding has received more attention in the past few years due to the availability of several large-scale video datasets. However, annotating large-scale video datasets are cost-intensive. In this work, we propose a time-efficient video annotation method using spatio-temporal feature similarity and t-SNE dimensionality reduction to speed up the annotation process massively. Placing the same actions from different videos near each other in the two-dimensional space based on feature similarity helps the annotator to group-label video clips. We evaluate our method on two subsets of the ActivityNet (v1.3) and a subset of the Sports-1M dataset. We show that t-EVA can outperform other video annotation tools while maintaining test accuracy on video classification.
Nonconvex Stochastic Scaled-Gradient Descent and Generalized Eigenvector Problems
Jan 24, 2022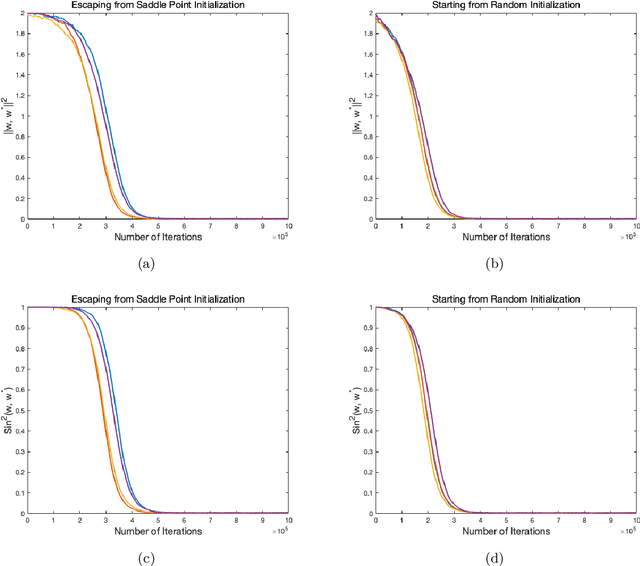
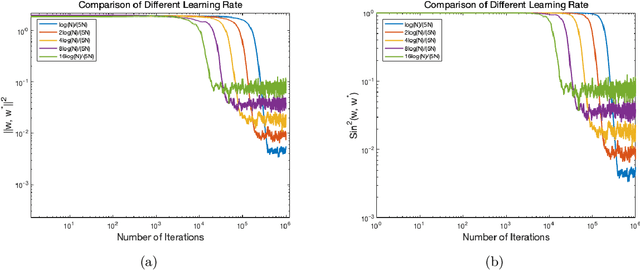
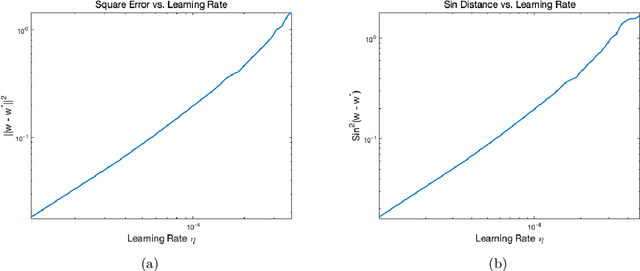
Motivated by the problem of online canonical correlation analysis, we propose the \emph{Stochastic Scaled-Gradient Descent} (SSGD) algorithm for minimizing the expectation of a stochastic function over a generic Riemannian manifold. SSGD generalizes the idea of projected stochastic gradient descent and allows the use of scaled stochastic gradients instead of stochastic gradients. In the special case of a spherical constraint, which arises in generalized eigenvector problems, we establish a nonasymptotic finite-sample bound of $\sqrt{1/T}$, and show that this rate is minimax optimal, up to a polylogarithmic factor of relevant parameters. On the asymptotic side, a novel trajectory-averaging argument allows us to achieve local asymptotic normality with a rate that matches that of Ruppert-Polyak-Juditsky averaging. We bring these ideas together in an application to online canonical correlation analysis, deriving, for the first time in the literature, an optimal one-time-scale algorithm with an explicit rate of local asymptotic convergence to normality. Numerical studies of canonical correlation analysis are also provided for synthetic data.
Block-Recurrent Transformers
Mar 11, 2022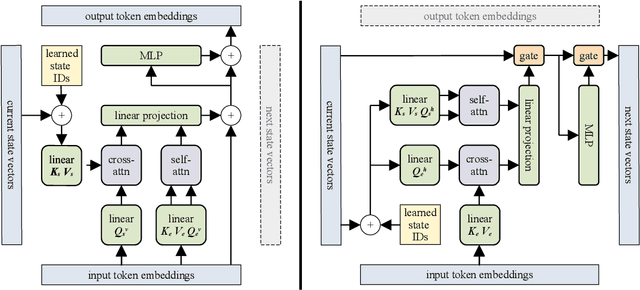
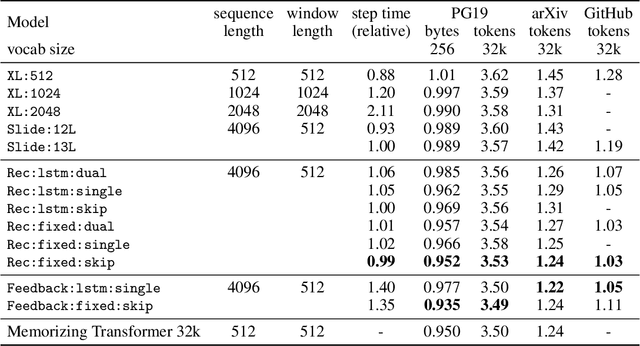
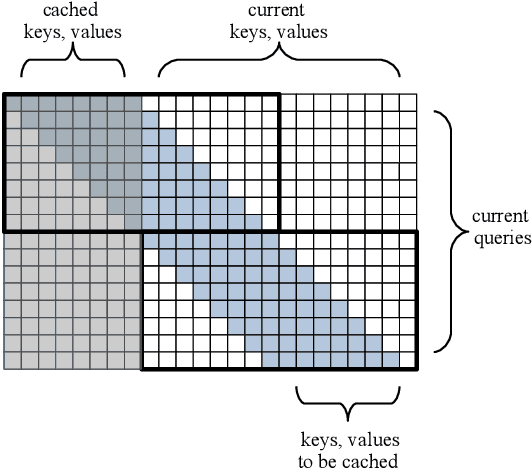
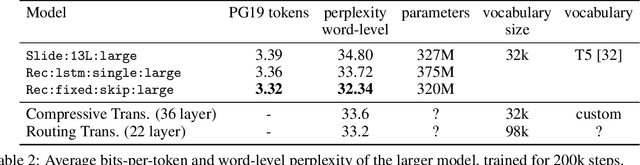
We introduce the Block-Recurrent Transformer, which applies a transformer layer in a recurrent fashion along a sequence, and has linear complexity with respect to sequence length. Our recurrent cell operates on blocks of tokens rather than single tokens, and leverages parallel computation within a block in order to make efficient use of accelerator hardware. The cell itself is strikingly simple. It is merely a transformer layer: it uses self-attention and cross-attention to efficiently compute a recurrent function over a large set of state vectors and tokens. Our design was inspired in part by LSTM cells, and it uses LSTM-style gates, but it scales the typical LSTM cell up by several orders of magnitude. Our implementation of recurrence has the same cost in both computation time and parameter count as a conventional transformer layer, but offers dramatically improved perplexity in language modeling tasks over very long sequences. Our model out-performs a long-range Transformer XL baseline by a wide margin, while running twice as fast. We demonstrate its effectiveness on PG19 (books), arXiv papers, and GitHub source code.
No-Regret Learning in Dynamic Stackelberg Games
Feb 10, 2022In a Stackelberg game, a leader commits to a randomized strategy, and a follower chooses their best strategy in response. We consider an extension of a standard Stackelberg game, called a discrete-time dynamic Stackelberg game, that has an underlying state space that affects the leader's rewards and available strategies and evolves in a Markovian manner depending on both the leader and follower's selected strategies. Although standard Stackelberg games have been utilized to improve scheduling in security domains, their deployment is often limited by requiring complete information of the follower's utility function. In contrast, we consider scenarios where the follower's utility function is unknown to the leader; however, it can be linearly parameterized. Our objective then is to provide an algorithm that prescribes a randomized strategy to the leader at each step of the game based on observations of how the follower responded in previous steps. We design a no-regret learning algorithm that, with high probability, achieves a regret bound (when compared to the best policy in hindsight) which is sublinear in the number of time steps; the degree of sublinearity depends on the number of features representing the follower's utility function. The regret of the proposed learning algorithm is independent of the size of the state space and polynomial in the rest of the parameters of the game. We show that the proposed learning algorithm outperforms existing model-free reinforcement learning approaches.
Open Set Recognition using Vision Transformer with an Additional Detection Head
Mar 16, 2022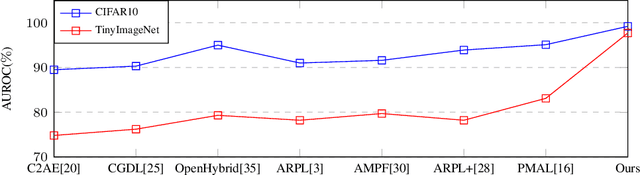
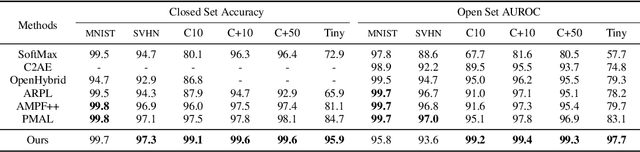
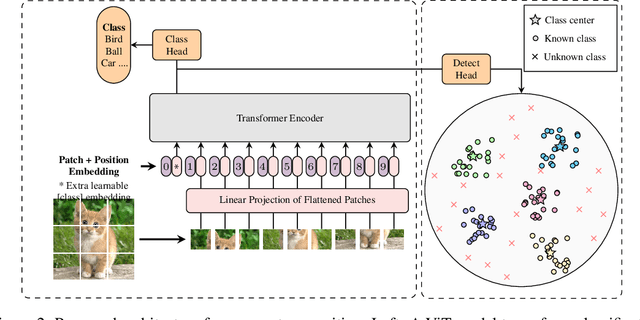
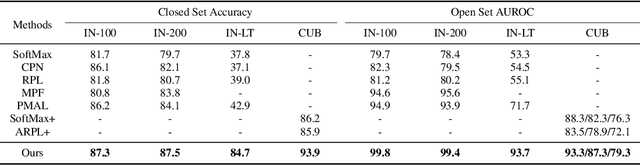
Deep neural networks have demonstrated prominent capacities for image classification tasks in a closed set setting, where the test data come from the same distribution as the training data. However, in a more realistic open set scenario, traditional classifiers with incomplete knowledge cannot tackle test data that are not from the training classes. Open set recognition (OSR) aims to address this problem by both identifying unknown classes and distinguishing known classes simultaneously. In this paper, we propose a novel approach to OSR that is based on the vision transformer (ViT) technique. Specifically, our approach employs two separate training stages. First, a ViT model is trained to perform closed set classification. Then, an additional detection head is attached to the embedded features extracted by the ViT, trained to force the representations of known data to class-specific clusters compactly. Test examples are identified as known or unknown based on their distance to the cluster centers. To the best of our knowledge, this is the first time to leverage ViT for the purpose of OSR, and our extensive evaluation against several OSR benchmark datasets reveals that our approach significantly outperforms other baseline methods and obtains new state-of-the-art performance.