 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient conditioned face animation using frontally-viewed embedding
Mar 16, 2022
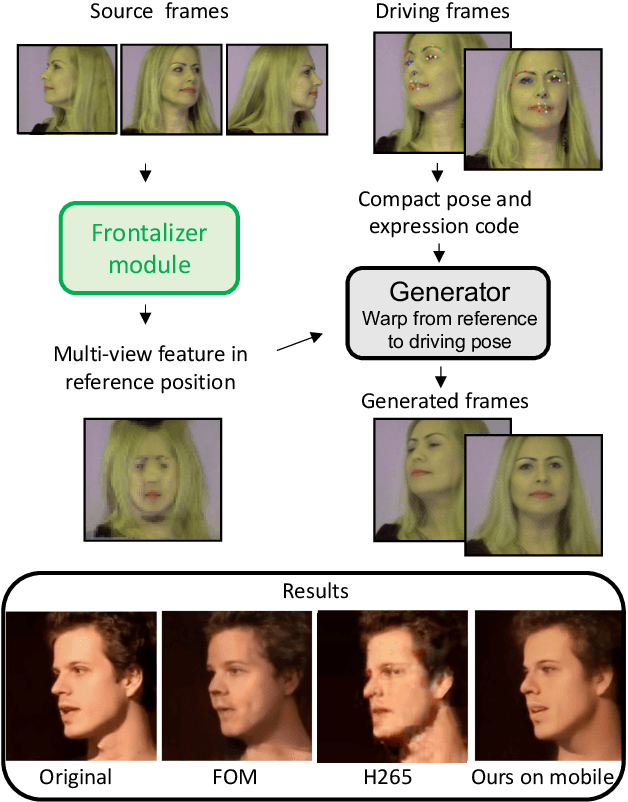


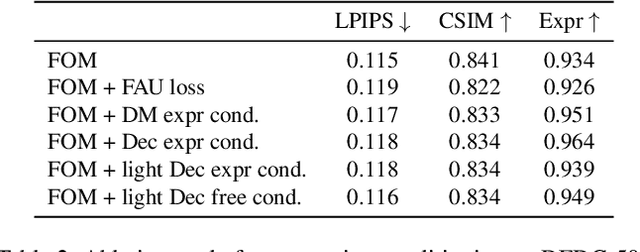
As the quality of few shot facial animation from landmarks increases, new applications become possible, such as ultra low bandwidth video chat compression with a high degree of realism. However, there are some important challenges to tackle in order to improve the experience in real world conditions. In particular, the current approaches fail to represent profile views without distortions, while running in a low compute regime. We focus on this key problem by introducing a multi-frames embedding dubbed Frontalizer to improve profile views rendering. In addition to this core improvement, we explore the learning of a latent code conditioning generations along with landmarks to better convey facial expressions. Our dense models achieves 22% of improvement in perceptual quality and 73% reduction of landmark error over the first order model baseline on a subset of DFDC videos containing head movements. Declined with mobile architectures, our models outperform the previous state-of-the-art (improving perceptual quality by more than 16% and reducing landmark error by more than 47% on two datasets) while running on real time on iPhone 8 with very low bandwidth requirements.
On Credit Assignment in Hierarchical Reinforcement Learning
Mar 07, 2022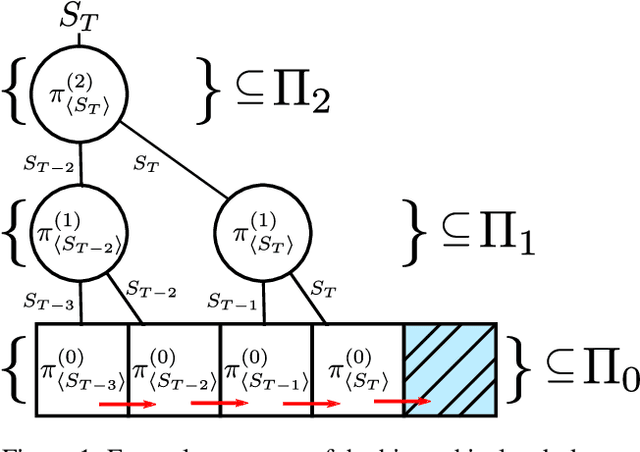
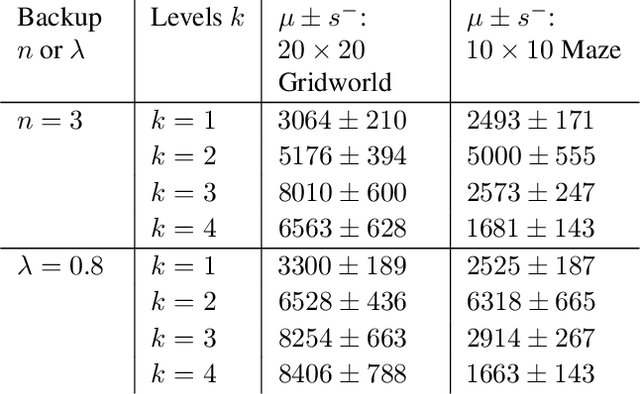
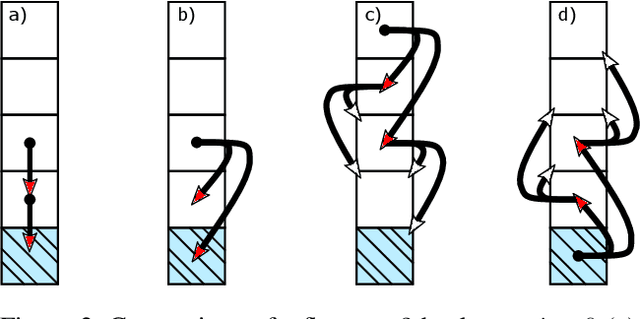
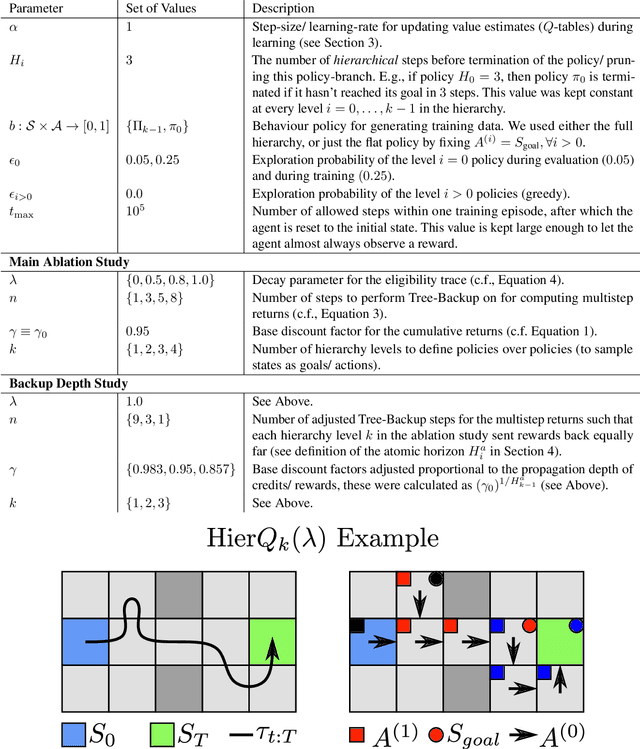
Hierarchical Reinforcement Learning (HRL) has held longstanding promise to advance reinforcement learning. Yet, it has remained a considerable challenge to develop practical algorithms that exhibit some of these promises. To improve our fundamental understanding of HRL, we investigate hierarchical credit assignment from the perspective of conventional multistep reinforcement learning. We show how e.g., a 1-step `hierarchical backup' can be seen as a conventional multistep backup with $n$ skip connections over time connecting each subsequent state to the first independent of actions inbetween. Furthermore, we find that generalizing hierarchy to multistep return estimation methods requires us to consider how to partition the environment trace, in order to construct backup paths. We leverage these insight to develop a new hierarchical algorithm Hier$Q_k(\lambda)$, for which we demonstrate that hierarchical credit assignment alone can already boost agent performance (i.e., when eliminating generalization or exploration). Altogether, our work yields fundamental insight into the nature of hierarchical backups and distinguishes this as an additional basis for reinforcement learning research.
Automated Detection of Acute Promyelocytic Leukemia in Blood Films and Bone Marrow Aspirates with Annotation-free Deep Learning
Mar 20, 2022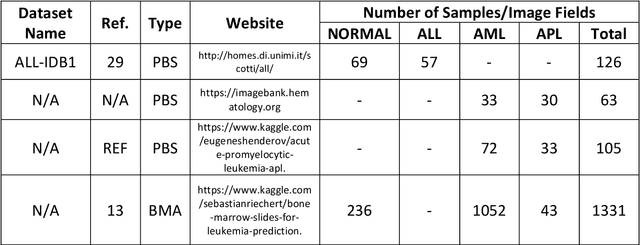
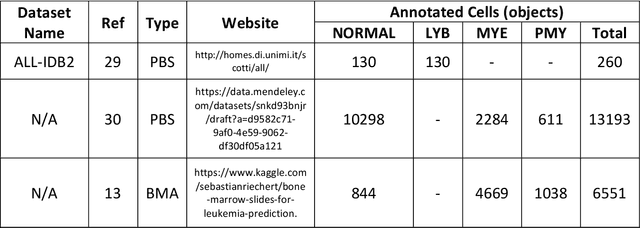
While optical microscopy inspection of blood films and bone marrow aspirates by a hematologist is a crucial step in establishing diagnosis of acute leukemia, especially in low-resource settings where other diagnostic modalities might not be available, the task remains time-consuming and prone to human inconsistencies. This has an impact especially in cases of Acute Promyelocytic Leukemia (APL) that require urgent treatment. Integration of automated computational hematopathology into clinical workflows can improve the throughput of these services and reduce cognitive human error. However, a major bottleneck in deploying such systems is a lack of sufficient cell morphological object-labels annotations to train deep learning models. We overcome this by leveraging patient diagnostic labels to train weakly-supervised models that detect different types of acute leukemia. We introduce a deep learning approach, Multiple Instance Learning for Leukocyte Identification (MILLIE), able to perform automated reliable analysis of blood films with minimal supervision. Without being trained to classify individual cells, MILLIE differentiates between acute lymphoblastic and myeloblastic leukemia in blood films. More importantly, MILLIE detects APL in blood films (AUC 0.94+/-0.04) and in bone marrow aspirates (AUC 0.99+/-0.01). MILLIE is a viable solution to augment the throughput of clinical pathways that require assessment of blood film microscopy.
Predicting Bearings' Degradation Stages for Predictive Maintenance in the Pharmaceutical Industry
Mar 07, 2022

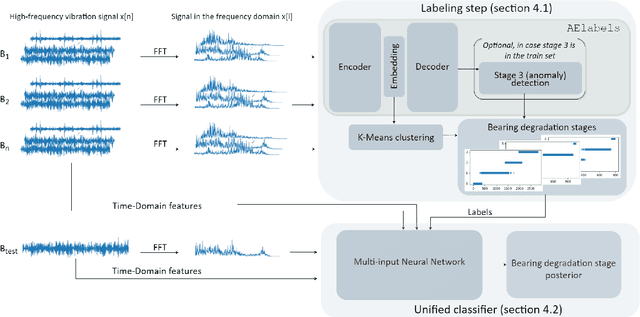

In the pharmaceutical industry, the maintenance of production machines must be audited by the regulator. In this context, the problem of predictive maintenance is not when to maintain a machine, but what parts to maintain at a given point in time. The focus shifts from the entire machine to its component parts and prediction becomes a classification problem. In this paper, we focus on rolling-elements bearings and we propose a framework for predicting their degradation stages automatically. Our main contribution is a k-means bearing lifetime segmentation method based on high-frequency bearing vibration signal embedded in a latent low-dimensional subspace using an AutoEncoder. Given high-frequency vibration data, our framework generates a labeled dataset that is used to train a supervised model for bearing degradation stage detection. Our experimental results, based on the FEMTO Bearing dataset, show that our framework is scalable and that it provides reliable and actionable predictions for a range of different bearings.
Real-Time Cardiac Cine MRI with Residual Convolutional Recurrent Neural Network
Aug 12, 2020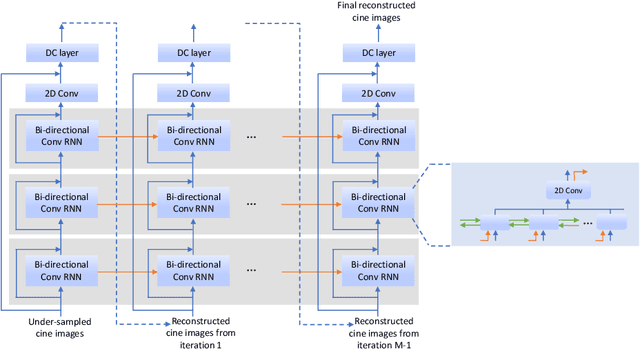
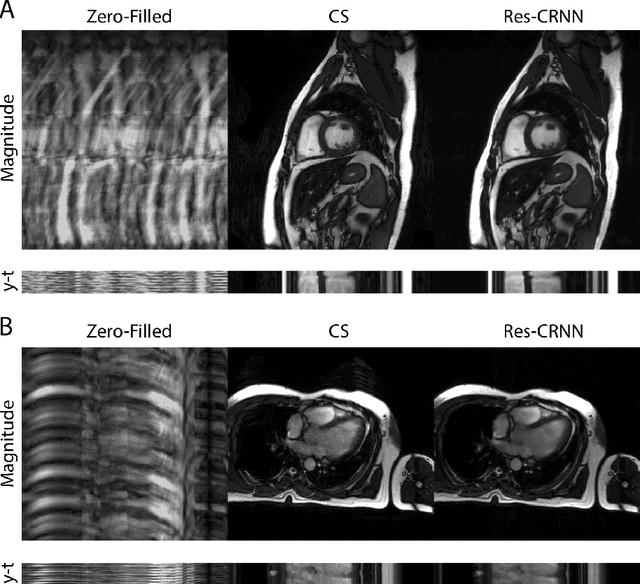
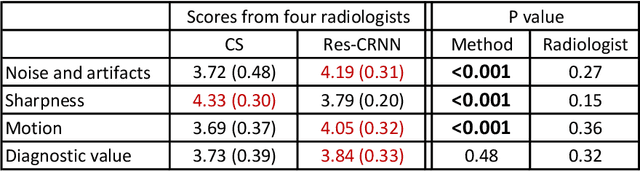

Real-time cardiac cine MRI does not require ECG gating in the data acquisition and is more useful for patients who can not hold their breaths or have abnormal heart rhythms. However, to achieve fast image acquisition, real-time cine commonly acquires highly undersampled data, which imposes a significant challenge for MRI image reconstruction. We propose a residual convolutional RNN for real-time cardiac cine reconstruction. To the best of our knowledge, this is the first work applying deep learning approach to Cartesian real-time cardiac cine reconstruction. Based on the evaluation from radiologists, our deep learning model shows superior performance than compressed sensing.
On One-Bit Quantization
Feb 10, 2022

We consider the one-bit quantizer that minimizes the mean squared error for a source living in a real Hilbert space. The optimal quantizer is a projection followed by a thresholding operation, and we provide methods for identifying the optimal direction along which to project. As an application of our methods, we characterize the optimal one-bit quantizer for a continuous-time random process that exhibits low-dimensional structure. We numerically show that this optimal quantizer is found by a neural-network-based compressor trained via stochastic gradient descent.
Context-Aware Drift Detection
Mar 16, 2022



When monitoring machine learning systems, two-sample tests of homogeneity form the foundation upon which existing approaches to drift detection build. They are used to test for evidence that the distribution underlying recent deployment data differs from that underlying the historical reference data. Often, however, various factors such as time-induced correlation mean that batches of recent deployment data are not expected to form an i.i.d. sample from the historical data distribution. Instead we may wish to test for differences in the distributions conditional on \textit{context} that is permitted to change. To facilitate this we borrow machinery from the causal inference domain to develop a more general drift detection framework built upon a foundation of two-sample tests for conditional distributional treatment effects. We recommend a particular instantiation of the framework based on maximum conditional mean discrepancies. We then provide an empirical study demonstrating its effectiveness for various drift detection problems of practical interest, such as detecting drift in the distributions underlying subpopulations of data in a manner that is insensitive to their respective prevalences. The study additionally demonstrates applicability to ImageNet-scale vision problems.
Safe Learning-Based Feedback Linearization Tracking Control for Nonlinear System with Event-Triggered Model Update
Mar 07, 2022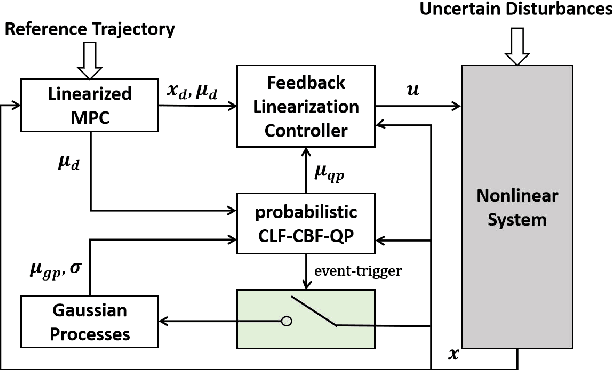
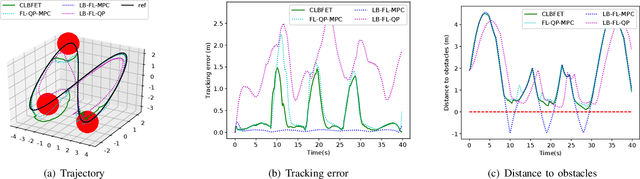
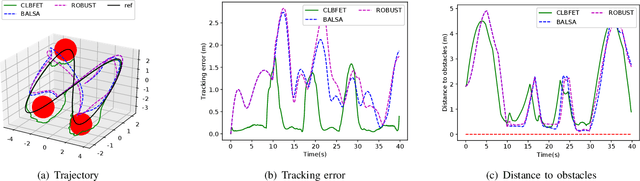
Learning-based methods are powerful in handling complex scenarios. However, it is still challenging to use learning-based methods under uncertain environments while stability, safety, and real-time performance of the system are desired to guarantee. In this paper, we propose a learning-based tracking control scheme based on a feedback linearization controller in which uncertain disturbances are approximated online using Gaussian Processes (GPs). Using the predicted distribution of disturbances given by GPs, a Control Lyapunov Function (CLF) and Control Barrier Function (CBF) based Quadratic Program is applied, with which probabilistic stability and safety are guaranteed. In addition, the trajectory is optimized first by Model Predictive Control (MPC) based on the linearized dynamics systems to further reduce the tracking error. We also design an event trigger for GPs updates to improve efficiency while stability and safety of the system are still guaranteed. The effectiveness of the proposed tracking control strategy is illustrated in numerical simulations.
* 8 pages, 8 figures
Meta-Forecasting by combining Global Deep Representations with Local Adaptation
Nov 12, 2021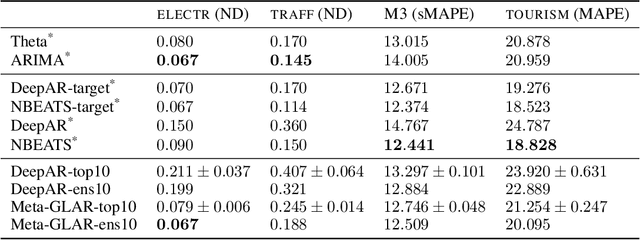
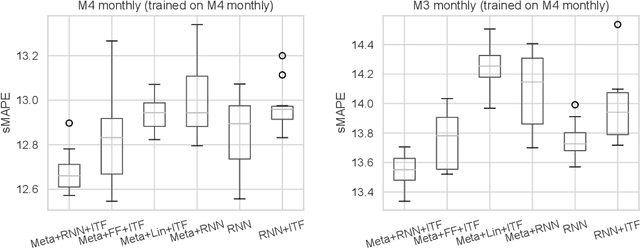
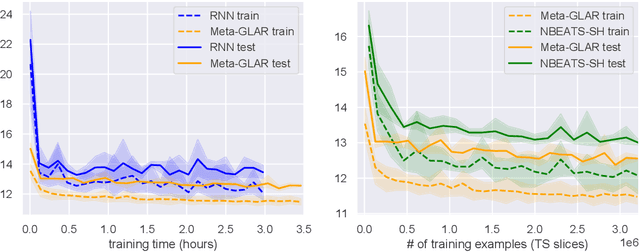

While classical time series forecasting considers individual time series in isolation, recent advances based on deep learning showed that jointly learning from a large pool of related time series can boost the forecasting accuracy. However, the accuracy of these methods suffers greatly when modeling out-of-sample time series, significantly limiting their applicability compared to classical forecasting methods. To bridge this gap, we adopt a meta-learning view of the time series forecasting problem. We introduce a novel forecasting method, called Meta Global-Local Auto-Regression (Meta-GLAR), that adapts to each time series by learning in closed-form the mapping from the representations produced by a recurrent neural network (RNN) to one-step-ahead forecasts. Crucially, the parameters ofthe RNN are learned across multiple time series by backpropagating through the closed-form adaptation mechanism. In our extensive empirical evaluation we show that our method is competitive with the state-of-the-art in out-of-sample forecasting accuracy reported in earlier work.
Low-Rank Autoregressive Tensor Completion for Multivariate Time Series Forecasting
Jun 18, 2020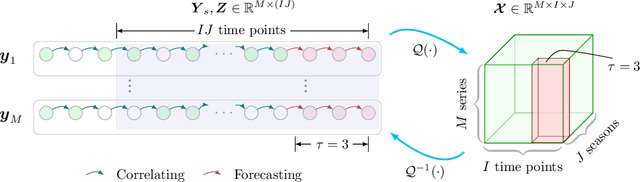
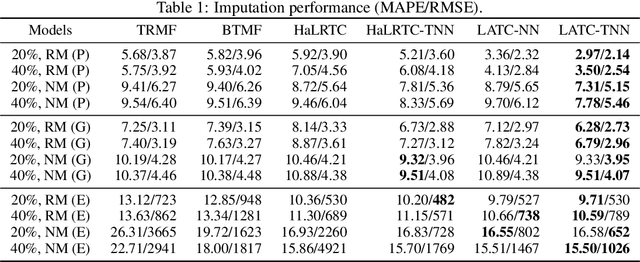
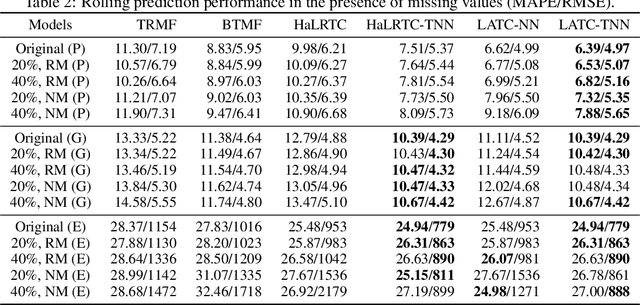
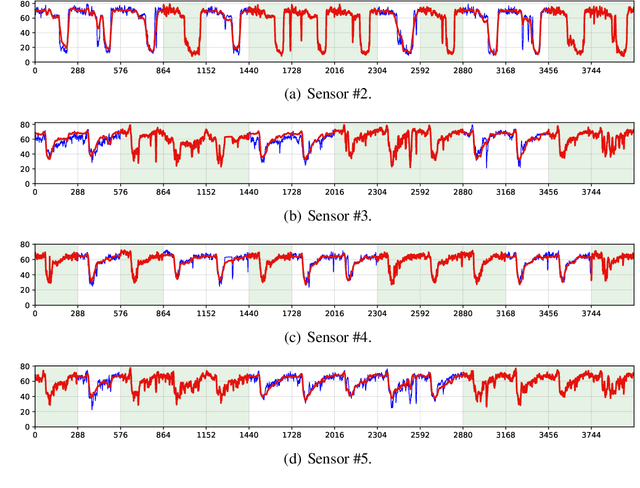
Time series prediction has been a long-standing research topic and an essential application in many domains. Modern time series collected from sensor networks (e.g., energy consumption and traffic flow) are often large-scale and incomplete with considerable corruption and missing values, making it difficult to perform accurate predictions. In this paper, we propose a low-rank autoregressive tensor completion (LATC) framework to model multivariate time series data. The key of LATC is to transform the original multivariate time series matrix (e.g., sensor$\times$time point) to a third-order tensor structure (e.g., sensor$\times$time of day$\times$day) by introducing an additional temporal dimension, which allows us to model the inherent rhythms and seasonality of time series as global patterns. With the tensor structure, we can transform the time series prediction and missing data imputation problems into a universal low-rank tensor completion problem. Besides minimizing tensor rank, we also integrate a novel autoregressive norm on the original matrix representation into the objective function. The two components serve different roles. The low-rank structure allows us to effectively capture the global consistency and trends across all the three dimensions (i.e., similarity among sensors, similarity of different days, and current time v.s. the same time of historical days). The autoregressive norm can better model the local temporal trends. Our numerical experiments on three real-world data sets demonstrate the superiority of the integration of global and local trends in LATC in both missing data imputation and rolling prediction tasks.