 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Prediction-Free, Real-Time Flexible Control of Tidal Lagoons through Proximal Policy Optimisation: A Case Study for the Swansea Lagoon
Jul 16, 2021
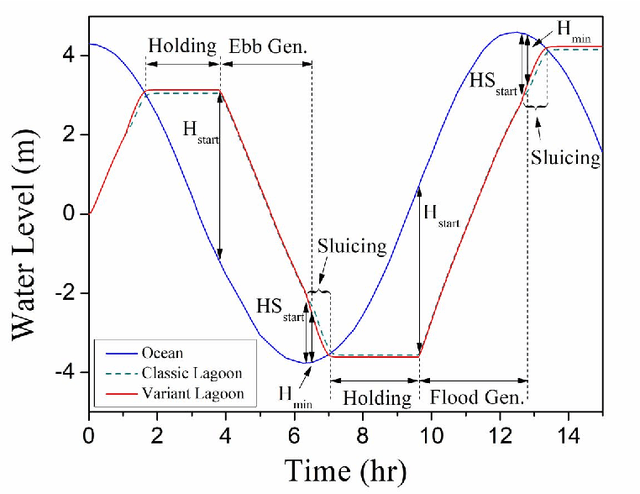


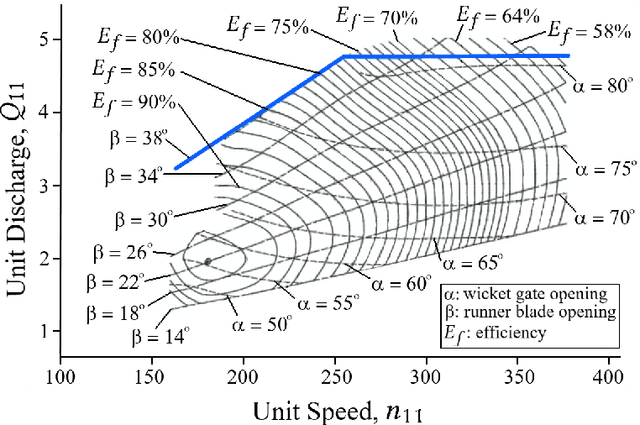
Tidal range structures have been considered for large scale electricity generation for their potential ability to produce reasonable predictable energy without the emission of greenhouse gases. Once the main forcing components for driving the tides have deterministic dynamics, the available energy in a given tidal power plant has been estimated, through analytical and numerical optimisation routines, as a mostly predictable event. This constraint imposes state-of-art flexible operation methods to rely on tidal predictions (concurrent with measured data and up to a multiple of half-tidal cycles into the future) to infer best operational strategies for tidal lagoons, with the additional cost of requiring to run optimisation routines for every new tide. In this paper, we propose a novel optimised operation of tidal lagoons with proximal policy optimisation through Unity ML-Agents. We compare this technique with 6 different operation optimisation approaches (baselines) devised from the literature, utilising the Swansea Bay Tidal Lagoon as a case study. We show that our approach is successful in maximising energy generation through an optimised operational policy of turbines and sluices, yielding competitive results with state-of-the-art methods of optimisation, regardless of test data used, requiring training once and performing real-time flexible control with measured ocean data only.
Indoor Environment Data Time-Series Reconstruction Using Autoencoder Neural Networks
Sep 17, 2020
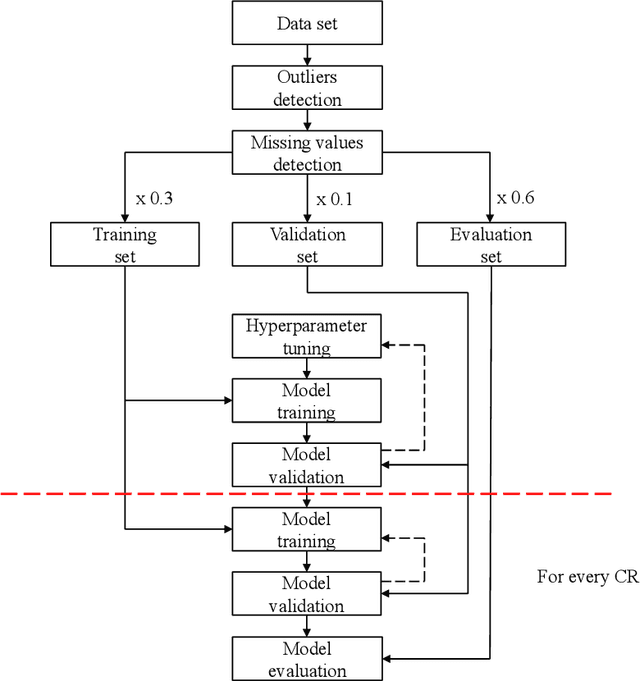

As the number of installed meters in buildings increases, there is a growing number of data time-series that could be used to develop data-driven models to support and optimize building operation. However, building data sets are often characterized by errors and missing values, which are considered, by the recent research, among the main limiting factors on the performance of the proposed models. Motivated by the need to address the problem of missing data in building operation, this work presents a data-driven approach to fill these gaps. In this study, three different autoencoder neural networks are trained to reconstruct missing indoor environment data time-series in a data set collected in an office building in Aachen, Germany. The models are applicable for different time-series obtained from room automation, such as indoor air temperature, relative humidity and $CO_{2}$ data streams. The results prove that the proposed methods outperform classic numerical approaches and they result in reconstructing the corresponding variables with average RMSEs of 0.42 {\deg}C, 1.30 % and 78.41 ppm, respectively.
Mugs: A Multi-Granular Self-Supervised Learning Framework
Mar 27, 2022
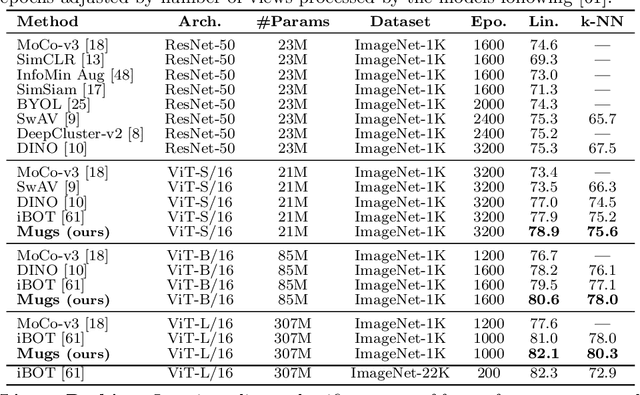
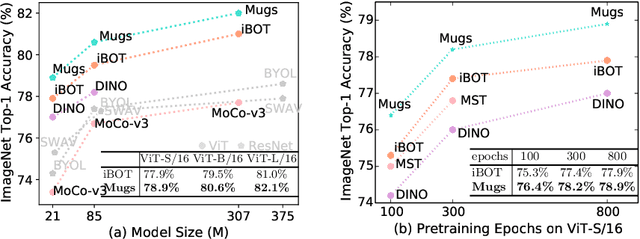
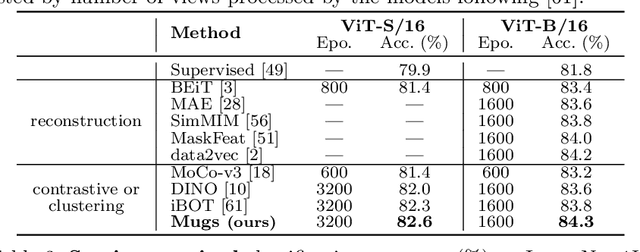
In self-supervised learning, multi-granular features are heavily desired though rarely investigated, as different downstream tasks (e.g., general and fine-grained classification) often require different or multi-granular features, e.g.~fine- or coarse-grained one or their mixture. In this work, for the first time, we propose an effective MUlti-Granular Self-supervised learning (Mugs) framework to explicitly learn multi-granular visual features. Mugs has three complementary granular supervisions: 1) an instance discrimination supervision (IDS), 2) a novel local-group discrimination supervision (LGDS), and 3) a group discrimination supervision (GDS). IDS distinguishes different instances to learn instance-level fine-grained features. LGDS aggregates features of an image and its neighbors into a local-group feature, and pulls local-group features from different crops of the same image together and push them away for others. It provides complementary instance supervision to IDS via an extra alignment on local neighbors, and scatters different local-groups separately to increase discriminability. Accordingly, it helps learn high-level fine-grained features at a local-group level. Finally, to prevent similar local-groups from being scattered randomly or far away, GDS brings similar samples close and thus pulls similar local-groups together, capturing coarse-grained features at a (semantic) group level. Consequently, Mugs can capture three granular features that often enjoy higher generality on diverse downstream tasks over single-granular features, e.g.~instance-level fine-grained features in contrastive learning. By only pretraining on ImageNet-1K, Mugs sets new SoTA linear probing accuracy 82.1$\%$ on ImageNet-1K and improves previous SoTA by $1.1\%$. It also surpasses SoTAs on other tasks, e.g. transfer learning, detection and segmentation.
ABCNet v2: Adaptive Bezier-Curve Network for Real-time End-to-end Text Spotting
May 29, 2021
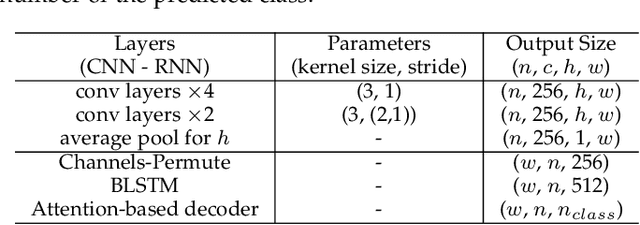


End-to-end text-spotting, which aims to integrate detection and recognition in a unified framework, has attracted increasing attention due to its simplicity of the two complimentary tasks. It remains an open problem especially when processing arbitrarily-shaped text instances. Previous methods can be roughly categorized into two groups: character-based and segmentation-based, which often require character-level annotations and/or complex post-processing due to the unstructured output. Here, we tackle end-to-end text spotting by presenting Adaptive Bezier Curve Network v2 (ABCNet v2). Our main contributions are four-fold: 1) For the first time, we adaptively fit arbitrarily-shaped text by a parameterized Bezier curve, which, compared with segmentation-based methods, can not only provide structured output but also controllable representation. 2) We design a novel BezierAlign layer for extracting accurate convolution features of a text instance of arbitrary shapes, significantly improving the precision of recognition over previous methods. 3) Different from previous methods, which often suffer from complex post-processing and sensitive hyper-parameters, our ABCNet v2 maintains a simple pipeline with the only post-processing non-maximum suppression (NMS). 4) As the performance of text recognition closely depends on feature alignment, ABCNet v2 further adopts a simple yet effective coordinate convolution to encode the position of the convolutional filters, which leads to a considerable improvement with negligible computation overhead. Comprehensive experiments conducted on various bilingual (English and Chinese) benchmark datasets demonstrate that ABCNet v2 can achieve state-of-the-art performance while maintaining very high efficiency.
Configuration Space Decomposition for Scalable Proxy Collision Checking in Robot Planning and Control
Jan 13, 2022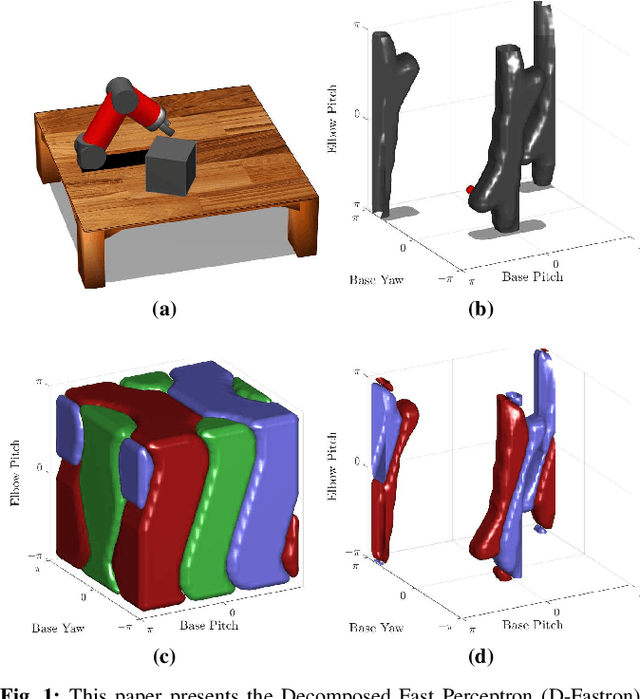
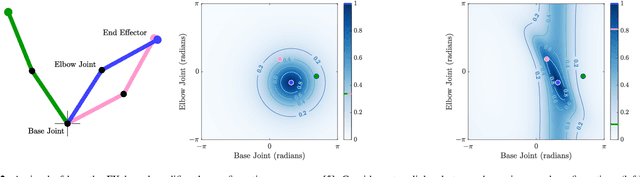


Real-time robot motion planning in complex high-dimensional environments remains an open problem. Motion planning algorithms, and their underlying collision checkers, are crucial to any robot control stack. Collision checking takes up a large portion of computational time in robot motion planning. Existing collision checkers make trade-offs between speed and accuracy and scale poorly to high-dimensional, complex environments. We present a novel space decomposition method using K-Means clustering in the Forward Kinematics space to accelerate proxy collision checking. We train individual configuration space models using Fastron, a kernel perceptron algorithm, on these decomposed subspaces, yielding lightweight yet highly accurate models that can be queried rapidly and scale better to more complex environments. We demonstrate this new method, called Decomposed Fast Perceptron (D-Fastron), on the 7-DOF Baxter robot producing on average 29x faster collision checks and up to 9.8x faster motion planning compared to state-of-the-art geometric collision checkers.
Churn prediction in online gambling
Jan 07, 2022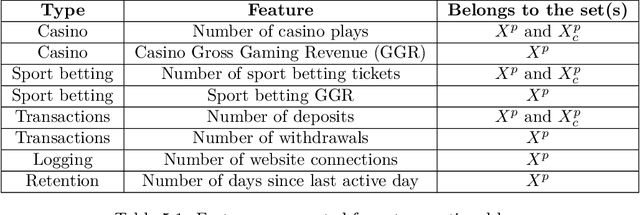
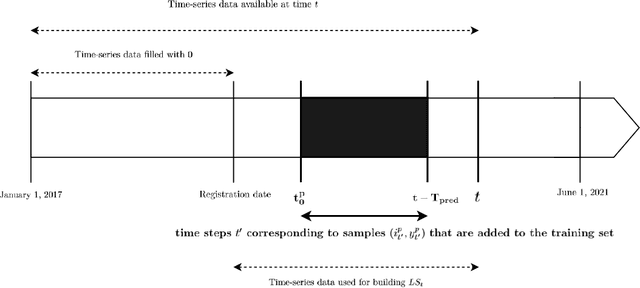

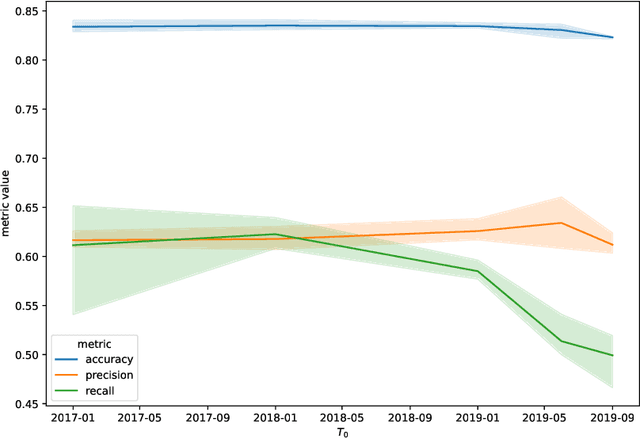
In business retention, churn prevention has always been a major concern. This work contributes to this domain by formalizing the problem of churn prediction in the context of online gambling as a binary classification task. We also propose an algorithmic answer to this problem based on recurrent neural network. This algorithm is tested with online gambling data that have the form of time series, which can be efficiently processed by recurrent neural networks. To evaluate the performances of the trained models, standard machine learning metrics were used, such as accuracy, precision and recall. For this problem in particular, the conducted experiments allowed to assess that the choice of a specific architecture depends on the metric which is given the greatest importance. Architectures using nBRC favour precision, those using LSTM give better recall, while GRU-based architectures allow a higher accuracy and balance two other metrics. Moreover, further experiments showed that using only the more recent time-series histories to train the networks decreases the quality of the results. We also study the performances of models learned at a specific instant $t$, at other times $t^{\prime} > t$. The results show that the performances of the models learned at time $t$ remain good at the following instants $t^{\prime} > t$, suggesting that there is no need to refresh the models at a high rate. However, the performances of the models were subject to noticeable variance due to one-off events impacting the data.
Foveation-based Deep Video Compression without Motion Search
Mar 30, 2022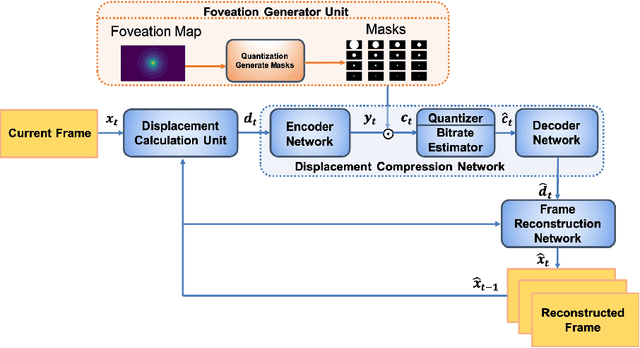
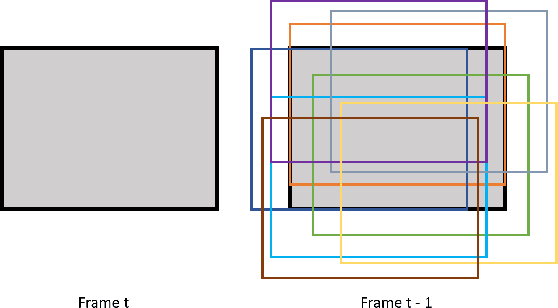

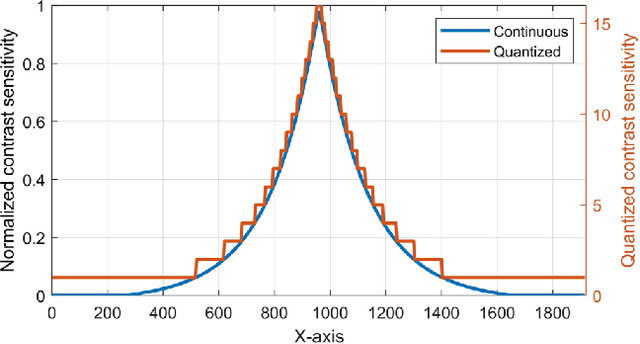
The requirements of much larger file sizes, different storage formats, and immersive viewing conditions of VR pose significant challenges to the goals of acquiring, transmitting, compressing, and displaying high-quality VR content. At the same time, the great potential of deep learning to advance progress on the video compression problem has driven a significant research effort. Because of the high bandwidth requirements of VR, there has also been significant interest in the use of space-variant, foveated compression protocols. We have integrated these techniques to create an end-to-end deep learning video compression framework. A feature of our new compression model is that it dispenses with the need for expensive search-based motion prediction computations. This is accomplished by exploiting statistical regularities inherent in video motion expressed by displaced frame differences. Foveation protocols are desirable since only a small portion of a video viewed in VR may be visible as a user gazes in any given direction. Moreover, even within a current field of view (FOV), the resolution of retinal neurons rapidly decreases with distance (eccentricity) from the projected point of gaze. In our learning based approach, we implement foveation by introducing a Foveation Generator Unit (FGU) that generates foveation masks which direct the allocation of bits, significantly increasing compression efficiency while making it possible to retain an impression of little to no additional visual loss given an appropriate viewing geometry. Our experiment results reveal that our new compression model, which we call the Foveated MOtionless VIdeo Codec (Foveated MOVI-Codec), is able to efficiently compress videos without computing motion, while outperforming foveated version of both H.264 and H.265 on the widely used UVG dataset and on the HEVC Standard Class B Test Sequences.
Learning Cross-Video Neural Representations for High-Quality Frame Interpolation
Feb 28, 2022
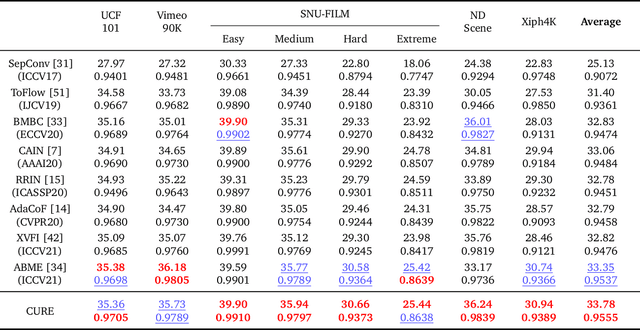
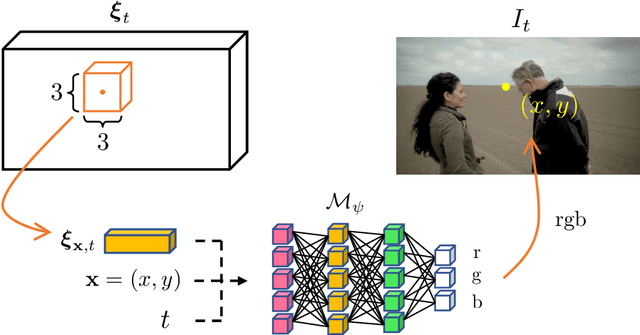
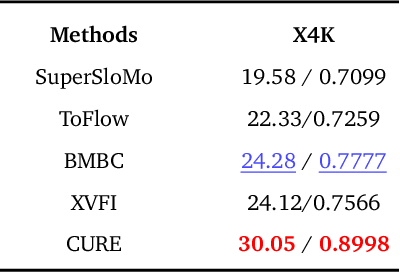
This paper considers the problem of temporal video interpolation, where the goal is to synthesize a new video frame given its two neighbors. We propose Cross-Video Neural Representation (CURE) as the first video interpolation method based on neural fields (NF). NF refers to the recent class of methods for the neural representation of complex 3D scenes that has seen widespread success and application across computer vision. CURE represents the video as a continuous function parameterized by a coordinate-based neural network, whose inputs are the spatiotemporal coordinates and outputs are the corresponding RGB values. CURE introduces a new architecture that conditions the neural network on the input frames for imposing space-time consistency in the synthesized video. This not only improves the final interpolation quality, but also enables CURE to learn a prior across multiple videos. Experimental evaluations show that CURE achieves the state-of-the-art performance on video interpolation on several benchmark datasets.
Paper Plain: Making Medical Research Papers Approachable to Healthcare Consumers with Natural Language Processing
Feb 28, 2022
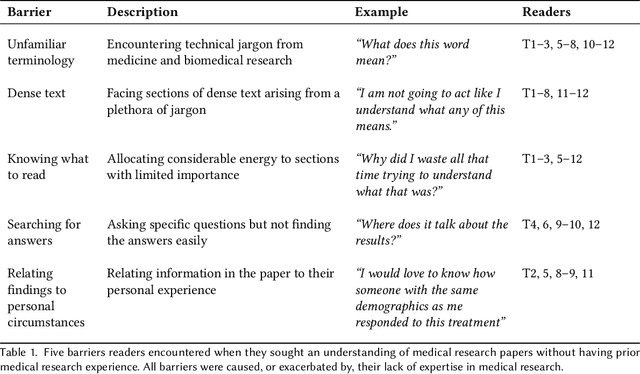

When seeking information not covered in patient-friendly documents, like medical pamphlets, healthcare consumers may turn to the research literature. Reading medical papers, however, can be a challenging experience. To improve access to medical papers, we introduce a novel interactive interface-Paper Plain-with four features powered by natural language processing: definitions of unfamiliar terms, in-situ plain language section summaries, a collection of key questions that guide readers to answering passages, and plain language summaries of the answering passages. We evaluate Paper Plain, finding that participants who use Paper Plain have an easier time reading and understanding research papers without a loss in paper comprehension compared to those who use a typical PDF reader. Altogether, the study results suggest that guiding readers to relevant passages and providing plain language summaries, or "gists," alongside the original paper content can make reading medical papers easier and give readers more confidence to approach these papers.
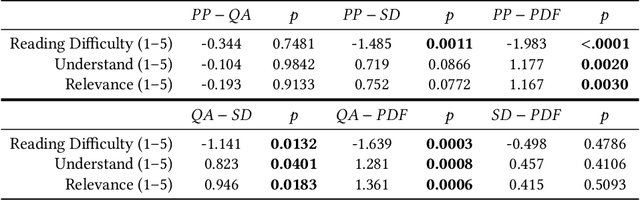
Calibration of Derivative Pricing Models: a Multi-Agent Reinforcement Learning Perspective
Mar 14, 2022
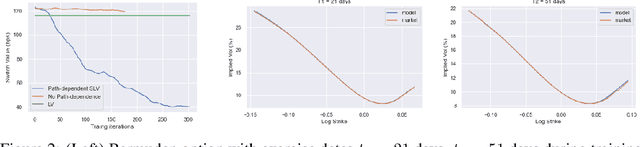
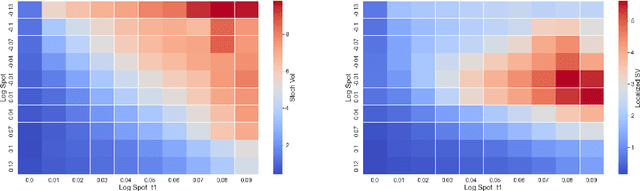
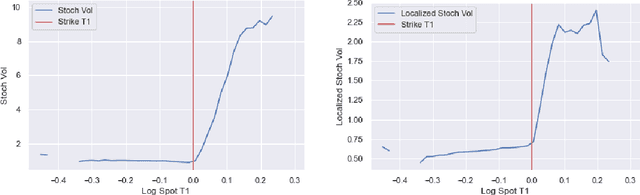
One of the most fundamental questions in quantitative finance is the existence of continuous-time diffusion models that fit market prices of a given set of options. Traditionally, one employs a mix of intuition, theoretical and empirical analysis to find models that achieve exact or approximate fits. Our contribution is to show how a suitable game theoretical formulation of this problem can help solve this question by leveraging existing developments in modern deep multi-agent reinforcement learning to search in the space of stochastic processes. More importantly, we hope that our techniques can be leveraged and extended by the community to solve important problems in that field, such as the joint SPX-VIX calibration problem. Our experiments show that we are able to learn local volatility, as well as path-dependence required in the volatility process to minimize the price of a Bermudan option. In one sentence, our algorithm can be seen as a particle method \`{a} la Guyon et Henry-Labordere where particles, instead of being designed to ensure $\sigma_{loc}(t,S_t)^2 = \mathbb{E}[\sigma_t^2|S_t]$, are learning RL-driven agents cooperating towards more general calibration targets. This is the first work bridging reinforcement learning with the derivative calibration problem.