 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Indy Autonomous Challenge -- Autonomous Race Cars at the Handling Limits
Feb 08, 2022
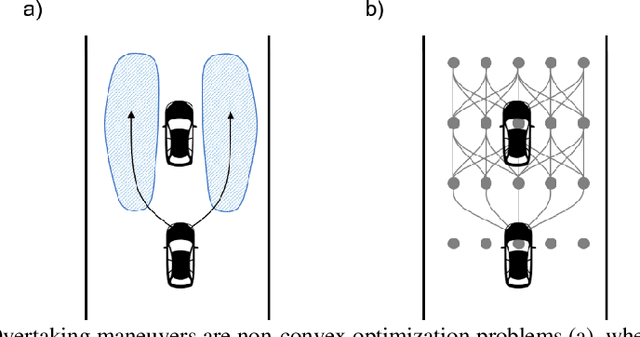
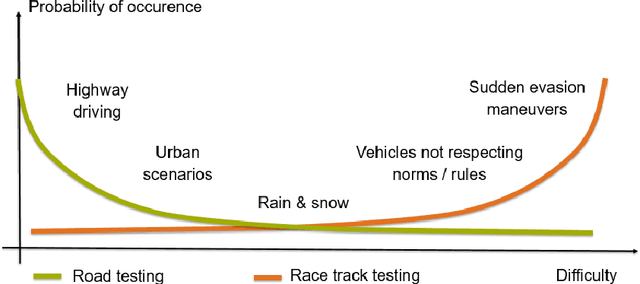

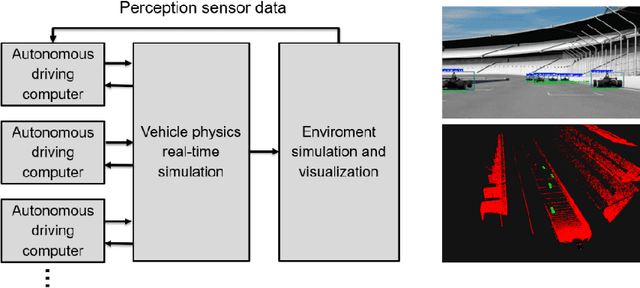
Motorsport has always been an enabler for technological advancement, and the same applies to the autonomous driving industry. The team TUM Auton-omous Motorsports will participate in the Indy Autonomous Challenge in Octo-ber 2021 to benchmark its self-driving software-stack by racing one out of ten autonomous Dallara AV-21 racecars at the Indianapolis Motor Speedway. The first part of this paper explains the reasons for entering an autonomous vehicle race from an academic perspective: It allows focusing on several edge cases en-countered by autonomous vehicles, such as challenging evasion maneuvers and unstructured scenarios. At the same time, it is inherently safe due to the motor-sport related track safety precautions. It is therefore an ideal testing ground for the development of autonomous driving algorithms capable of mastering the most challenging and rare situations. In addition, we provide insight into our soft-ware development workflow and present our Hardware-in-the-Loop simulation setup. It is capable of running simulations of up to eight autonomous vehicles in real time. The second part of the paper gives a high-level overview of the soft-ware architecture and covers our development priorities in building a high-per-formance autonomous racing software: maximum sensor detection range, relia-ble handling of multi-vehicle situations, as well as reliable motion control under uncertainty.
Convolutional Neural Network to Restore Low-Dose Digital Breast Tomosynthesis Projections in a Variance Stabilization Domain
Mar 22, 2022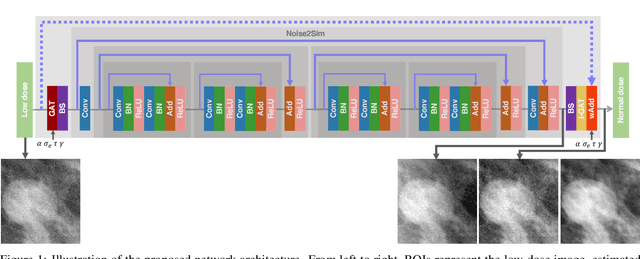
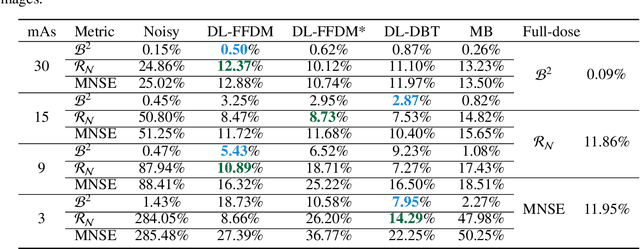

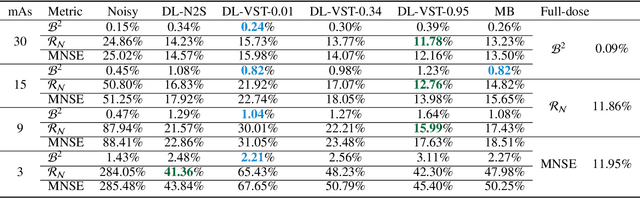
Digital breast tomosynthesis (DBT) exams should utilize the lowest possible radiation dose while maintaining sufficiently good image quality for accurate medical diagnosis. In this work, we propose a convolution neural network (CNN) to restore low-dose (LD) DBT projections to achieve an image quality equivalent to a standard full-dose (FD) acquisition. The proposed network architecture benefits from priors in terms of layers that were inspired by traditional model-based (MB) restoration methods, considering a model-based deep learning approach, where the network is trained to operate in the variance stabilization transformation (VST) domain. To accurately control the network operation point, in terms of noise and blur of the restored image, we propose a loss function that minimizes the bias and matches residual noise between the input and the output. The training dataset was composed of clinical data acquired at the standard FD and low-dose pairs obtained by the injection of quantum noise. The network was tested using real DBT projections acquired with a physical anthropomorphic breast phantom. The proposed network achieved superior results in terms of the mean normalized squared error (MNSE), training time and noise spatial correlation compared with networks trained with traditional data-driven methods. The proposed approach can be extended for other medical imaging application that requires LD acquisitions.
A pipeline and comparative study of 12 machine learning models for text classification
Apr 04, 2022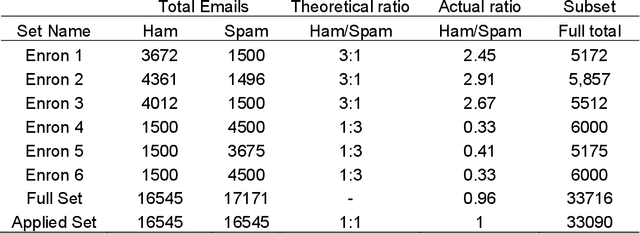
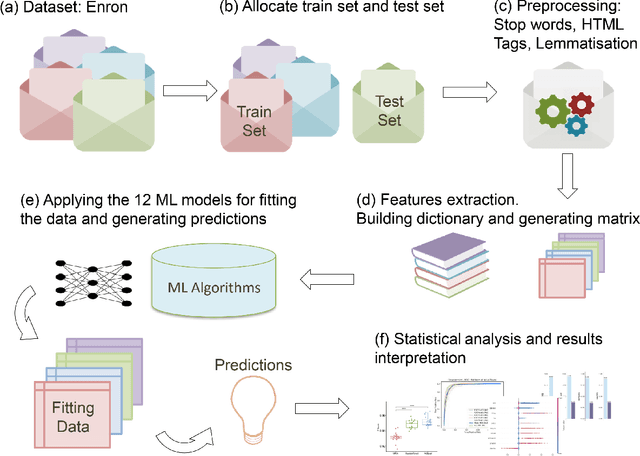
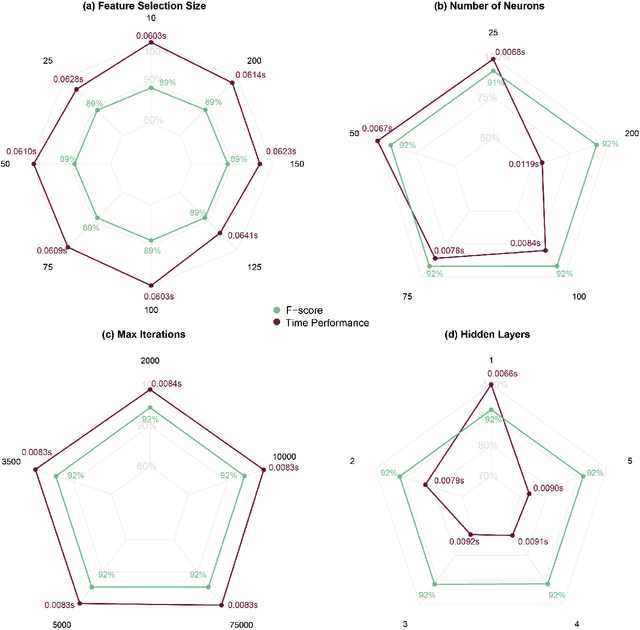
Text-based communication is highly favoured as a communication method, especially in business environments. As a result, it is often abused by sending malicious messages, e.g., spam emails, to deceive users into relaying personal information, including online accounts credentials or banking details. For this reason, many machine learning methods for text classification have been proposed and incorporated into the services of most email providers. However, optimising text classification algorithms and finding the right tradeoff on their aggressiveness is still a major research problem. We present an updated survey of 12 machine learning text classifiers applied to a public spam corpus. A new pipeline is proposed to optimise hyperparameter selection and improve the models' performance by applying specific methods (based on natural language processing) in the preprocessing stage. Our study aims to provide a new methodology to investigate and optimise the effect of different feature sizes and hyperparameters in machine learning classifiers that are widely used in text classification problems. The classifiers are tested and evaluated on different metrics including F-score (accuracy), precision, recall, and run time. By analysing all these aspects, we show how the proposed pipeline can be used to achieve a good accuracy towards spam filtering on the Enron dataset, a widely used public email corpus. Statistical tests and explainability techniques are applied to provide a robust analysis of the proposed pipeline and interpret the classification outcomes of the 12 machine learning models, also identifying words that drive the classification results. Our analysis shows that it is possible to identify an effective machine learning model to classify the Enron dataset with an F-score of 94%.
Conditional Sig-Wasserstein GANs for Time Series Generation
Jun 09, 2020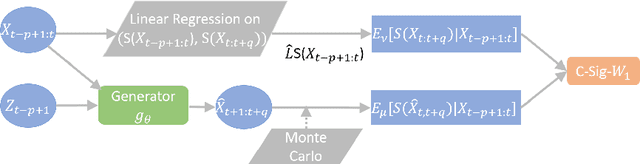
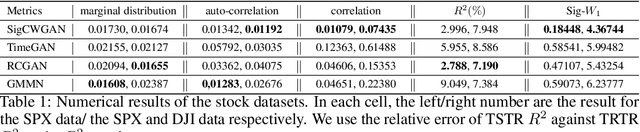
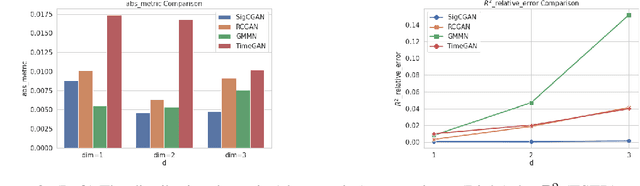
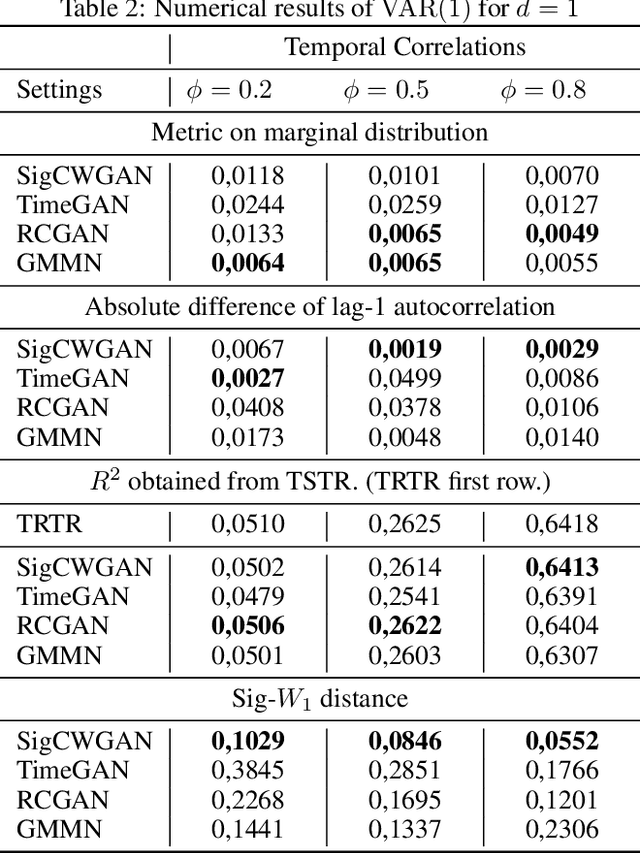
Generative adversarial networks (GANs) have been extremely successful in generating samples, from seemingly high dimensional probability measures. However, these methods struggle to capture the temporal dependence of joint probability distributions induced by time-series data. Furthermore, long time-series data streams hugely increase the dimension of the target space, which may render generative modeling infeasible. To overcome these challenges, we integrate GANs with mathematically principled and efficient path feature extraction called the signature of a path. The signature of a path is a graded sequence of statistics that provides a universal description for a stream of data, and its expected value characterizes the law of the time-series model. In particular, we a develop new metric, (conditional) Sig-$W_1$, that captures the (conditional) joint law of time series models, and use it as a discriminator. The signature feature space enables the explicit representation of the proposed discriminators which alleviates the need for expensive training. Furthermore, we develop a novel generator, called the conditional AR-FNN, which is designed to capture the temporal dependence of time series and can be efficiently trained. We validate our method on both synthetic and empirical datasets and observe that our method consistently and significantly outperforms state-of-the-art benchmarks with respect to measures of similarity and predictive ability.
The Canonical Interval Forest (CIF) Classifier for Time Series Classification
Aug 20, 2020

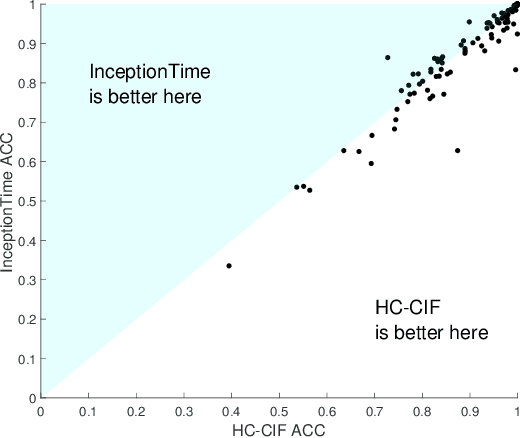
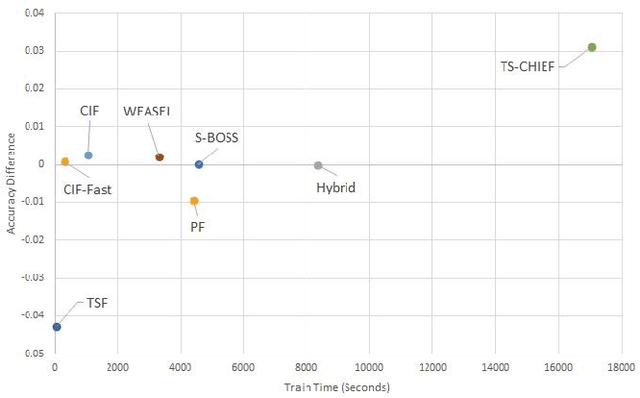
Time series classification (TSC) is home to a number of algorithm groups that utilise different kinds of discriminatory patterns. One of these groups describes classifiers that predict using phase dependant intervals. The time series forest (TSF) classifier is one of the most well known interval methods, and has demonstrated strong performance as well as relative speed in training and predictions. However, recent advances in other approaches have left TSF behind. TSF originally summarises intervals using three simple summary statistics. The `catch22' feature set of 22 time series features was recently proposed to aid time series analysis through a concise set of diverse and informative descriptive characteristics. We propose combining TSF and catch22 to form a new classifier, the Canonical Interval Forest (CIF). We outline additional enhancements to the training procedure, and extend the classifier to include multivariate classification capabilities. We demonstrate a large and significant improvement in accuracy over both TSF and catch22, and show it to be on par with top performers from other algorithmic classes. By upgrading the interval-based component from TSF to CIF, we also demonstrate a significant improvement in the hierarchical vote collective of transformation-based ensembles (HIVE-COTE) that combines different time series representations. HIVE-COTE using CIF is significantly more accurate on the UCR archive than any other classifier we are aware of and represents a new state of the art for TSC.
Structure Extraction in Task-Oriented Dialogues with Slot Clustering
Mar 03, 2022
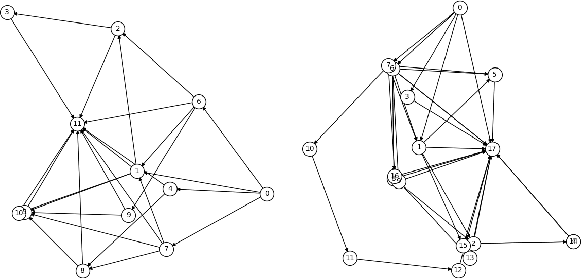


Extracting structure information from dialogue data can help us better understand user and system behaviors. In task-oriented dialogues, dialogue structure has often been considered as transition graphs among dialogue states. However, annotating dialogue states manually is expensive and time-consuming. In this paper, we propose a simple yet effective approach for structure extraction in task-oriented dialogues. We first detect and cluster possible slot tokens with a pre-trained model to approximate dialogue ontology for a target domain. Then we track the status of each identified token group and derive a state transition structure. Empirical results show that our approach outperforms unsupervised baseline models by far in dialogue structure extraction. In addition, we show that data augmentation based on extracted structures enriches the surface formats of training data and can achieve a significant performance boost in dialogue response generation.
Path Planning for the Dynamic UAV-Aided Wireless Systems using Monte Carlo Tree Search
Jan 13, 2022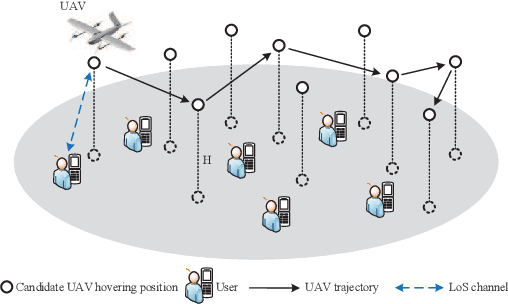
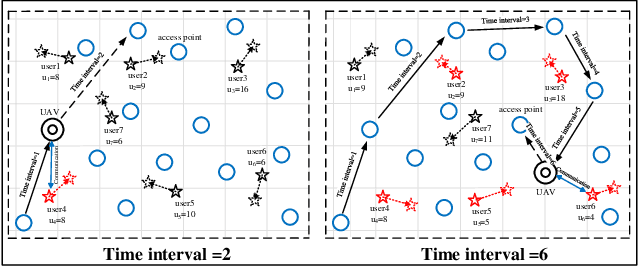
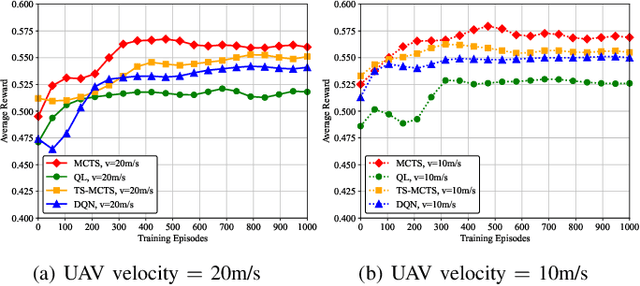
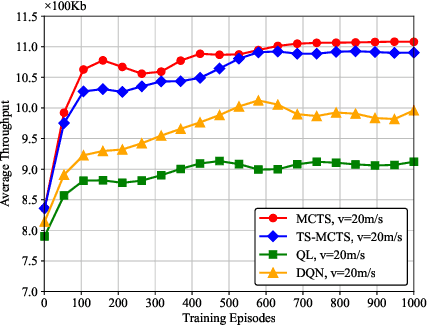
For UAV-aided wireless systems, online path planning attracts much attention recently. To better adapt to the real-time dynamic environment, we, for the first time, propose a Monte Carlo Tree Search (MCTS)-based path planning scheme. In details, we consider a single UAV acts as a mobile server to provide computation tasks offloading services for a set of mobile users on the ground, where the movement of ground users follows a Random Way Point model. Our model aims at maximizing the average throughput under energy consumption and user fairness constraints, and the proposed timesaving MCTS algorithm can further improve the performance. Simulation results show that the proposed algorithm achieves a larger average throughput and a faster convergence performance compared with the baseline algorithms of Q-learning and Deep Q-Network.
Projection-based Point Convolution for Efficient Point Cloud Segmentation
Feb 04, 2022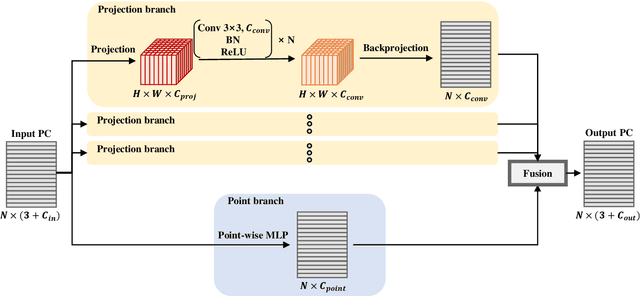
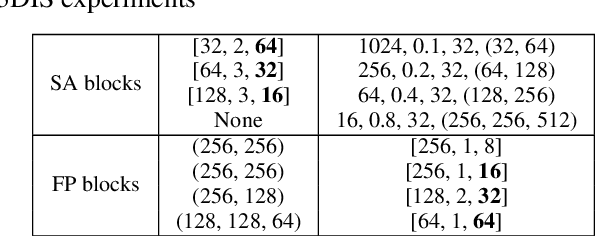
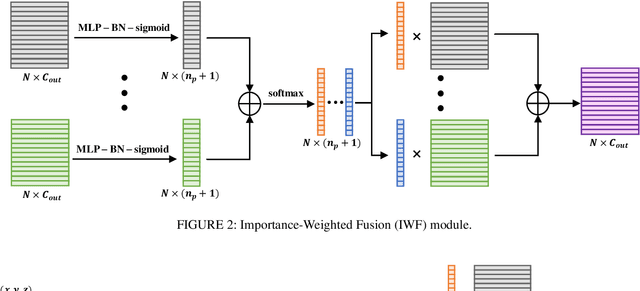
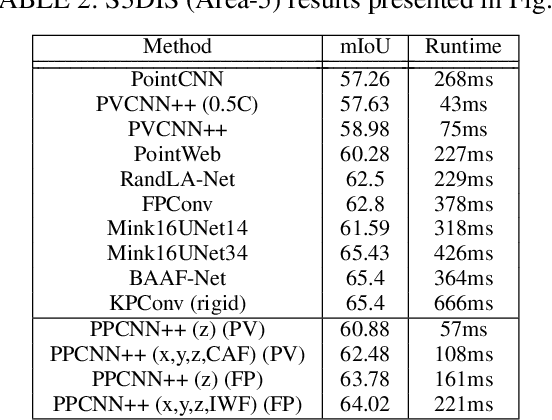
Understanding point cloud has recently gained huge interests following the development of 3D scanning devices and the accumulation of large-scale 3D data. Most point cloud processing algorithms can be classified as either point-based or voxel-based methods, both of which have severe limitations in processing time or memory, or both. To overcome these limitations, we propose Projection-based Point Convolution (PPConv), a point convolutional module that uses 2D convolutions and multi-layer perceptrons (MLPs) as its components. In PPConv, point features are processed through two branches: point branch and projection branch. Point branch consists of MLPs, while projection branch transforms point features into a 2D feature map and then apply 2D convolutions. As PPConv does not use point-based or voxel-based convolutions, it has advantages in fast point cloud processing. When combined with a learnable projection and effective feature fusion strategy, PPConv achieves superior efficiency compared to state-of-the-art methods, even with a simple architecture based on PointNet++. We demonstrate the efficiency of PPConv in terms of the trade-off between inference time and segmentation performance. The experimental results on S3DIS and ShapeNetPart show that PPConv is the most efficient method among the compared ones. The code is available at github.com/pahn04/PPConv.
Domain Knowledge Aids in Signal Disaggregation; the Example of the Cumulative Water Heater
Mar 22, 2022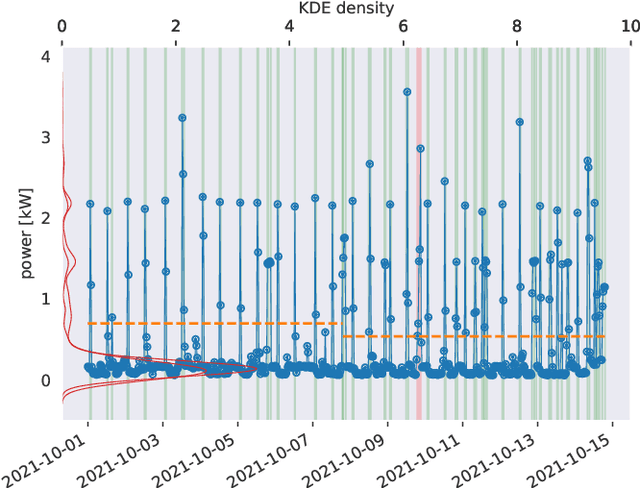

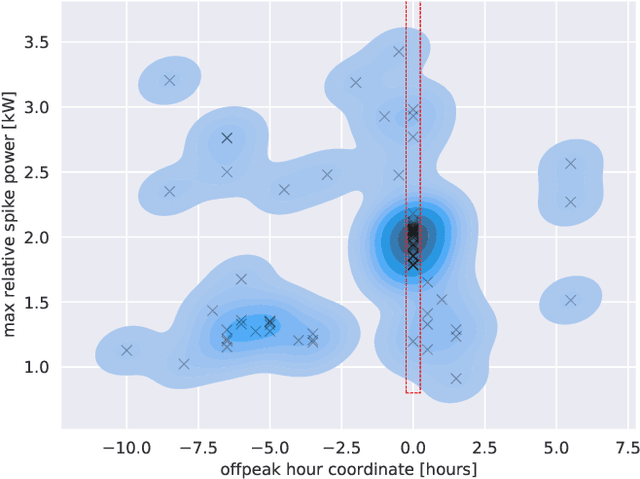
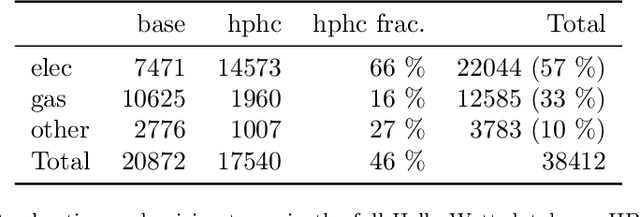
In this article we present an unsupervised low-frequency method aimed at detecting and disaggregating the power used by Cumulative Water Heaters (CWH) in residential homes. Our model circumvents the inherent difficulty of unsupervised signal disaggregation by using both the shape of a power spike and its time of occurrence to identify the contribution of CWH reliably. Indeed, many CHWs in France are configured to turn on automatically during off-peak hours only, and we are able to use this domain knowledge to aid peak identification despite the low sampling frequency. In order to test our model, we equipped a home with sensors to record the ground-truth consumption of a water heater. We then apply the model to a larger dataset of energy consumption of Hello Watt users consisting of one month of consumption data for 5k homes at 30-minute resolution. In this dataset we successfully identified CWHs in the majority of cases where consumers declared using them. The remaining part is likely due to possible misconfiguration of CWHs, since triggering them during off-peak hours requires specific wiring in the electrical panel of the house. Our model, despite its simplicity, offers promising applications: detection of mis-configured CWHs on off-peak contracts and slow performance degradation.
Accelerate Model Parallel Training by Using Efficient Graph Traversal Order in Device Placement
Jan 21, 2022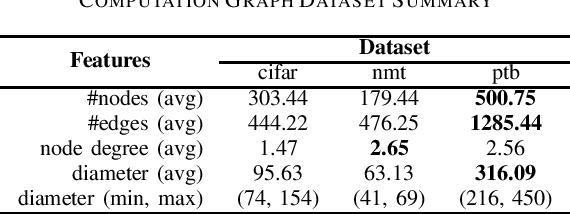
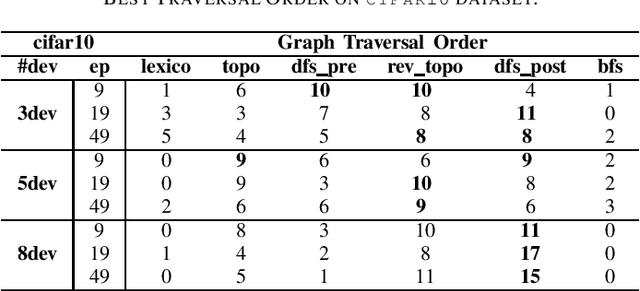
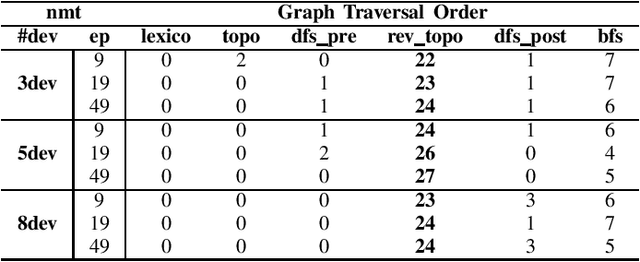
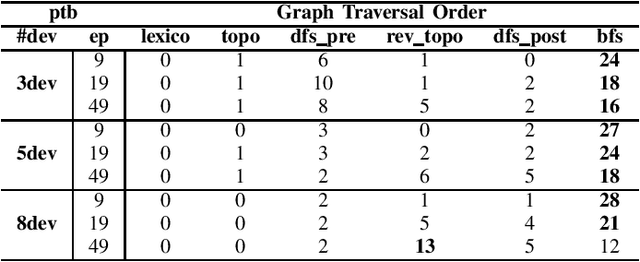
Modern neural networks require long training to reach decent performance on massive datasets. One common approach to speed up training is model parallelization, where large neural networks are split across multiple devices. However, different device placements of the same neural network lead to different training times. Most of the existing device placement solutions treat the problem as sequential decision-making by traversing neural network graphs and assigning their neurons to different devices. This work studies the impact of graph traversal order on device placement. In particular, we empirically study how different graph traversal order leads to different device placement, which in turn affects the training execution time. Our experiment results show that the best graph traversal order depends on the type of neural networks and their computation graphs features. In this work, we also provide recommendations on choosing graph traversal order in device placement for various neural network families to improve the training time in model parallelization.